


数据结构:哈希表例子
问题
如何存储字典里的所有单词能够让搜索、更新的效率快?
哈希表的解决方案
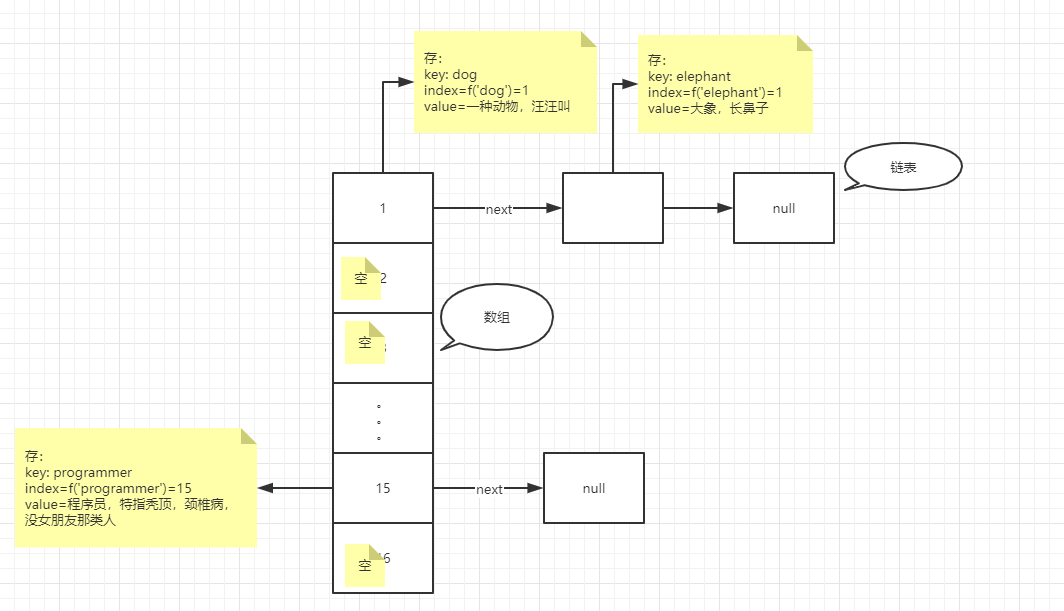
JDK中HashMap的实现就是参照了这种思路,我们可以自己写一个
package com.study.jdk; import java.io.Serializable; /** * @author mdl * @date 2019/12/10 */ public class SimpleHashMap<K, V> implements Serializable { /** * */ private static final long serialVersionUID = -7278101382866134374L; transient Node<K, V>[] table;// 存储头节点的数组 private int size;// 元素个数 private static int defaultCapacity = 16;// 默认容量 private static float defaultLoadFactor = 0.75f;// 扩展因子 public SimpleHashMap() {} public SimpleHashMap(int capacity, int loadFactor) { defaultCapacity = capacity; defaultLoadFactor = loadFactor; } public int hash(K key) { int h; return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16); } public V get(K key) { int n = table.length; int index = n - 1 & hash(key); Node<K, V> node; if ((node = table[index]) != null) { while (node != null && !node.key.equals(key)) { node = node.next; } return null == node ? null : node.value; } return null; } @SuppressWarnings("unchecked") public V put(K key, V value) { // 初始化数组 if (table == null) { // 并不是在构造函数中完成初始化,而是在put的时候 table = new Node[defaultCapacity]; } int n = table.length; int index = n - 1 & hash(key); // 计算存储数组的下标 // 获取到数组角标元素,可视为头结点 Node<K, V> node = table[index]; // 遍历链表中节点对象 while (node != null) { if (node.key.equals(key)) { // key存在相同的情况下,替换value,直接退出程序 node.value = value; return value; } else { // 不同的话,找下一个结点 node = node.next; } } // 走到这里,说明table[index]里没有找到相同key的链结点 // 在这里做扩容是因为,要加入的元素是作为新增元素的, // 比如容量16,扩容因子0.75,当前table里元素为12时,再添加元素的话,就扩容量至32(16 * 2), // 下一次扩容在(32 * 0.75)后继续添加元素时 if (size >= defaultCapacity * defaultLoadFactor) { resize(); } // 将新添加的数据作为头结点添加到数组中 table[index] = new Node<>(key, value, table[index]); size++; return value; } // 扩展数组 @SuppressWarnings("unchecked") public void resize() { // 扩容后要对元素重新put(重新散列),所以要将size置为0 size = 0; // 记录先之前的数组 Node<K, V>[] oldNodes = table; defaultCapacity = defaultCapacity << 1; table = new Node[defaultCapacity]; // 遍历散列表中每个元素 for (int i = 0; i < oldNodes.length; i++) { // 扩容后hash值会改变,所以要重新散列 // 当前数组的头结点 Node<K, V> node = oldNodes[i]; while (node != null) { Node<K, V> oldNode = node; put(node.key, node.value);// 重新散列 node = node.next;// 指针往后移 oldNode.next = null;// 将当前散列的节点next置为null } } } // 节点对象 public class Node<K, V> { K key; V value; Node<K, V> next; public Node(K key, V value, Node<K, V> next) { this.key = key; this.value = value; this.next = next; } } }
编写测试类


package com.study.jdk; /** * @author mdl * @date 2019/12/10 */ public class Dictionary { private String word; private String desc; /** * */ public Dictionary() { super(); } /** * @param word * @param desc */ public Dictionary(String word, String desc) { super(); this.word = word; this.desc = desc; } /** * @return the word */ public String getWord() { return word; } /** * @param word * the word to set */ public void setWord(String word) { this.word = word; } /** * @return the desc */ public String getDesc() { return desc; } /** * @param desc * the desc to set */ public void setDesc(String desc) { this.desc = desc; } /* (non-Javadoc) * @see java.lang.Object#toString() */ @Override public String toString() { return "Dictionary [word=" + word + ", desc=" + desc + "]"; } }
package com.study.jdk; /** * @author mdl * @date 2019/12/10 */ public class Test { public static void main(String[] args) { Dictionary dictionary1 =new Dictionary("dog", "一种动物,汪汪叫"); Dictionary dictionary2 =new Dictionary("elephant", "大象,长鼻子"); Dictionary dictionary3 =new Dictionary("programmer", "程序员,特指秃顶,颈椎病,没女朋友那类人"); SimpleHashMap<String, Dictionary> map =new SimpleHashMap<String, Dictionary>(); map.put("dog", dictionary1); map.put("elephant", dictionary2); map.put("programmer", dictionary3); System.out.println(map.get("dog")); System.out.println(map.get("elephant")); System.out.println(map.get("programmer")); } }

每一步脚印都要扎得深一点!
