Cluster map 存储了整个集群的数据的分布以及成员包括mon map ,osd map, pg map,crush map。cluster map不仅存储在monitor节点,它被复制到集群中的每一个存储节点,以及和集群交互的client。当因为一些原因,比如设备崩溃、数据迁移等,cluster map的内容需要改变时,cluster map的版本号被增加,map的版本号可以使通信的双方确认自己的map是否是最新的,版本旧的一方会先将map更新成对方的map,然后才会进行后续操作。
一、Cluster map的实际内容包括:
1. Epoch,即版本号。cluster map的epoch是一个单调递增序列。epoch越大,则cluster map版本越新。因此,持有不同版本cluster map的OSD或client可以简单地通过比较epoch决定应该遵从谁手中的版本。而monitor手中必定有epoch最大、版本最新的cluster map。当任意两方在通信时发现彼此epoch值不同时,将默认先将cluster map同步至高版本一方的状态,再进行后续操作。
2. 各个OSD的网络地址。
3. 各个OSD的状态。OSD状态的描述分为两个维度:up或者down(表明OSD是否正常工作),in或者out(表明OSD是否在至少一个PG中)。因此,对于任意一个OSD,共有四种可能的状态:
-> up且in:说明该OSD正常运行,且已经承载至少一个PG的数据。这是一个OSD的标准工作状态;
-> up且out:说明该OSD正常运行,但并未承载任何PG,其中也没有数据。一个新的OSD刚刚被加入Ceph集群后,便会处于这一状态。而一个出现故障的OSD被修复后,重新加入Ceph集群时,也是处于这一状态;
-> down且in:说明该OSD发生异常,但仍然承载着至少一个PG,其中仍然存储着数据。这种状态下的OSD刚刚被发现存在异常,可能仍能恢复正常,也可能会彻底无法工作;
-> down且out:说明该OSD已经彻底发生故障,且已经不再承载任何PG。
4. CRUSH算法配置参数。表明了Ceph集群的物理层级关系位置映射规则。
二、Mon的作用:负责监控整个集群,维护集群的健康状态,维护展示集群状态的各种图表,如OSD Map、Monitor Map、PG Map和CRUSH Map、采集系统的日志。
Paxos:分布式一致性算法,算出一个主节点。通过mon节点的端口号和ip来计算主节点一般选取端口号小的为主如果端口号一样的情况那就选择ip地址小的为主节点。主要负责维护和传播集群表的权威副本,paxos要求集群中超过半数monitor处于活跃状态才能正常工作,以解决分布式系统常见的脑裂问题。为了防止一些临时性故障造成短时间内出现大量的集群表更新和传播,对集群的稳定性和性能造成影响,ceph将集群表的更新操作进行了串行化处理,即任何时刻只允许某个特定的monitor统一发起集群表更新,一段时间内的更新会被合并为一个请求提交,这个特殊的monitor称为leader,其他的monitor称为peon,leader通过选票产生,一旦某个monitor赢得超过半数的选票成为leader,leader通过续租的方式延长作为leader的租期(3秒更新租约,6秒超时),一旦集群中有任何的成员发生变化,整个集群就会重新触发leader选举。
Monitor 为ceph集群启动的第一个服务组件,如果第一个节点创建时monitor服务没有正常运行,后续的osd和其他和ceph集群相关的服务将不能正常创建,Monitor使用public网络进行对外提供服务,如果public网络异常将导致无法访问集群
注意:集群中monitor的数量部署为奇数个一般部署三个,如果要增加就一次性增加俩个,mon必须存活一般以上比如三个mon只允许down一个5个只允许down2个这样以此类推不然会出问题。
三、Mon常用命令:
Ceph quorum_status //查看mon的选取状态
Ceph quorum_status -f json-pretty|grep “leader” //-f指定以json的形式显示过滤出主mon
Ceph mon dump //查看mon的map
Ceph mon stat //查看mon的状态
Systemctl stop ceph-mon.target //停止mon进程
Systemctl stop ceph-mon@Node1 //停止Node1的mon进程
Ceph mon getmap -o /mnt/a.txt //将mon的map输出到/mnt/a/txt
Monmaptool –-print /mnt/a.txt //用monmaptool这个工具查看a.txt这个map
ceph-mon -i Node1 --extract-monmap /mnt/mon_map //-i指定的节点是Node1 –extract-monmap表示将mon的map输出到/mnt/mon_map
ceph-mon -i Node1 –-inject-monmap /mnt/mon_map //将/mnt/mon_map写入到本地的monmap中
查询单个监视器的状态ceph -m Node1:6789 mon_status -f josn-pretty
四、Mon的相关告警配置:
1、mon_data
Ceph daemon mon.Node1 config get mon_data //可以看到/var/lib/ceph/mon/ceph-Node1 说明mon的数据存放在这里
2、mon_data_size_warn
Ceph daemon mon.Node1 config get mon_data_size_warn
这个参数显示的数值表示当监视器的数据存储超过显示的数值就会在集群的日志文件中显示health_warn, 这个数值默认时15G也就是15*1024kb*1024M*1024G
3、mon_data_avail_warn
Ceph daemon mon.Node1 config get mon_data_avail_warn
这个参数表示监视器的可用存储空间低于显示的百分比的时候就会在日志文件显示health_warn 默认30%
4、mon_data_avail_crit
Ceph daemon mon.Node1 config get mon_data_avail_crit
这个参数表示监视器的可用空间低于或者等于显示的百分比时就会在日志文件中显示hearth_err 默认5%
五、集群容量相关参数:
1、Mon_osd_nearfull_ratio
Ceph daemon mon.Node1 config get mon_osd_nearfull_ratio
表示osd的磁盘使用率接近显示的值 默认85%
2、mon_osd_backfillfull_ratio
Ceph daemon mon.Node1 config get mon_osd_backfillfull_ratio
表示osd的使用率如果大于显示的值默认是90%就难以回填也就是说不能在将副本传递到其他osd
3、mon_osd_full_ratio
Ceph daemon mon.Node1 config get mon_osd_full_ratio
表示osd的使用率以及达到显示的值默认是95%
Systemctstatus ceph-mon.target//查看mon的状态
Systemctl status ceph-mon@Node1 //查看node1的mon状态但是必须登录到Node1上查
六、通过套接检查mon的进程是否正常:
Ceph –-admin-daemon /var/run/ceph/ceph-mon.Node1.asok mon_status
里面的state:有五种状态正常的状态是leader(主mon)peon:非主,不正常的状态有三种:probing、electing、synchronizing
Probing表示mon正在搜索其他的mon每次你启动一个monitor,它会去搜寻 monmap 中的其他 monitors ,所以会有一段时间处于该状态。此段时间的长短不一。例如,单节点 monitor环境, monitor 几乎会立即通过该阶段。在多 monitor 环境中,monitors 在找到足够的节点形成法定人数之前,都会处于该状态,这意味着如果 3 个 monitor 中的 2 个 down 了,剩下的 1 个会一直处于该状态,直到你再启动一个 monitor 。
electing:该 monitor 处于选举过程中。如果长时间处于这个状态可能是 monitors 节点时钟偏移。
Synchronizing:该 monitor 正在和集群中的其他 monitor 进行同步以便加入法定人数。Monitor 的数据库越小,同步过程的耗时就越短。
七、如果一个mon有问题有俩种解决办法:
1、可以尝试去删除它完后再创建但是要注意的是删除它以后剩余的mon能不能形成一个有效的法定人数,如果不能形成可能会导致无法访问。
2、也可以通过手动注入的方式去修改monmap
ceph mon getmap -o /tmp/monmap或者
ceph-mon -i Node1--extract-monmap /tmp/monmap
monmaptool --print /tmp/monmap 查看monmap
monmaptool monmap --rm Node1 //删除monmap中的一个地址
monmaptool --add Node1 10.255.0.197:6789 monmap //添加monmap一个地址
ceph-mon -i Node1 --inject-monmap /tmp/monmap //注入集群(需要停止集群中所有的mon进程)注入后启动对应的mon进程即可
八、时间同步问题:
通过ceph daemon mon.Node1 config get mon_clock_drift_allowed可以看到默认是0.05也就是说每个节点自建的时间偏差不能超过0.05s如果时间同步出现问题可以用ceph -s 和ceph health detail 来看到完后再看日志
通过grep “MON_CLOCK_SKEW” ceph.conf 来过滤出时间偏移的日志
也可以用ceph time_sync_status来查看
九、当执行ceph -s 异常时

1、其他的存储节点是否可用,如果其他的节点可用,则说明该节点的ceph.conf文件的mon ip不对(如果是多副本的情况下,此情况业务可以正常访问),如果所有的节点执行ceph -s都出现如上图,则说明集群中的mon已经不足以形成法定人数,导致集群无法运行(此情况业务将不可访问)
当执行ceph -s 卡顿无输出的时候一般是public网络的异常,或则防火墙的问题
十、mon的数据库问题
monitor 的 log 日志中应该会有如下错误信息:
Corruption: error in middle of record
或:
Corruption: 1 missing files; e.g.:
Mon会把数据都存放再/var/lib/ceph/mon/ceph-Node1/store.db 下
一般可以通过界面取消监控角色后重新添加回来,建议用户在部署集群时至少安装 3 个 monitors,同时失效的可能性较小。
十一、系统盘空间不足导致mon进程退出
说明Monitor系统盘的使用量小于(mon_data_avail_crit)5%,导致mon进程退出,此时清理本地磁盘,增大可用空间,重启 monitor 进程,即可恢复正常。

十二、Mon 告警“MON out of quorum”
可以用下面的命令过滤mon的日志文件如果有相关的关键字说明进程退出了
grep -rnE "FAILED assert|suicide|Seg|queue async shutdown|Shutdown via Data Health Service" ceph-mon.Node1.log
a)FAILED assert 关键字:一般是由于某些assert条件不满足,触发了逻辑bug
b)suicide 关键字: 一般是内部线程超时超过设置阈值(默认为150s),(底层IO慢)导致进程主动退出
c)Seg 关键字:程序访问了非法内存导致crash(程序问题)
d)queue async shutdown 关键字:可能是网卡down 或 连续多次(默认10)选举失败 导致
e) shutdown via Data Health Service关键字: 说明Monitor系统盘的使用量小于(mon_data_avail_crit)5%,
检查是否为慢io
grep -rnE "slow request|stuck" ceph-mon.Node1.log
十三:检查是否为慢io卡掉mon线程
grep -rnE "slow request|stuck" ceph-mon.xx.log
若在故障时间段,有关键字输出需要查看页面上该系统盘的型号和IO利用率;如果IO利用率偏高(一直100%),说明是系统盘忙导致mon下io慢,从而导致未回复其他mon的lease消息,而被剔出quorum
解决方法
1、增大所有mon节点mon sync超时时间默认6s超时

# ceph daemon mon.Node1 config set mon_sync_timeout 180 改为18s超时
2、改小mon每次同步数据的大小(由1M改成128K)
# ceph tell mon.Node1 injectargs –mon_sync_max_payload_size=131072
检查网络是否有丢包
一般在mon间隔比较久后再次加入到mon集群,会先进行数据同步
如果网络有问题,会导致数据同步异常,进而引起一直卡住,从而该mon一直是out of quorum
使用 ping -f $ip 来检查 out of quorum的mon与其他mon之间的网络质量,看是否有丢包
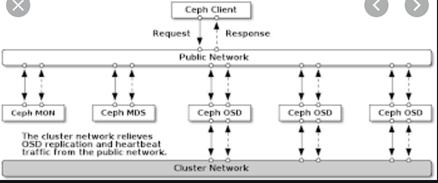
ceph网络拓扑