MapReduce之知识整理
MapReduce知识整理
MapReduce简介
MapReduce是一个用于处理海量数据的分布式计算框架,解决了(数据分布式存储,作业调度,容错,机器间通信等复杂问题)
MapReduce计算框架和执行流程
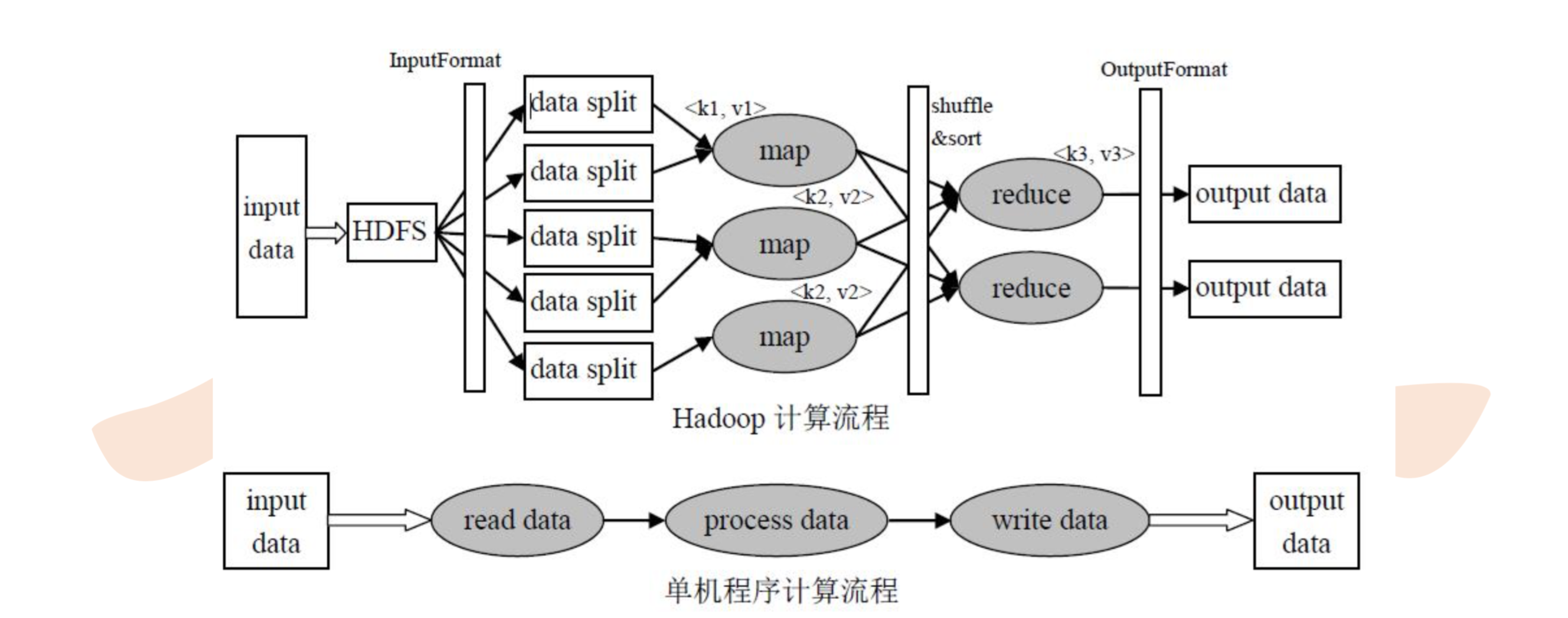

运行过程文字描述
1. Map任务处理
1.1 读取HDFS上的文件,每一行通过InputSplit解析成一个<k,v>,每个InputSplit都会分配一个Mapper任务,每个k,v会调用一次map函数。<line0, a b c c>,<line1, d e f>
1.2 覆盖map(),接收1.1的<k,v>,转换为新的<k,v>输出。<a,1>,<c,1>,<c,1>,<d,1>,<e,1>
1.2.1 上面的输出会先存放在缓存中,每个map都有一个环形内存缓冲区用于存储任务输出(默认大小100M,io.sort.mb属性指定),到达阈值0.8(io.sort.spill.percent)就溢写到指定的本地目录中
1.3 对1.2.1的输出溢写到磁盘前进行分区(partitioner),默认是一个分区,分区数量是根据reduce的数量来取模。<0,a,1>,<0,b,1>,<0,c,1>,<0,c,1>
1.4 分区后按照<k,v>中的k排序以及分组,分组是指相同key的value放到一个集合中。排序后:<a,1>,<b,1>,<c,1>,<c,1>,分组后:<a,{1}>,<b,{1}>,<c,{1,1}>
1.5 (可选)对分组后的数据进行归约,combiner
2. Reduce任务处理
2.1 多个map任务的输出,按照不同的分区,通过网络copy到不同的reduce节点上进行shuffle
2.2 从map端复制过来的数据首先会写到reduce端的缓存中,缓存占用到达一定的阈值后会写到磁盘中进行partition、combine、排序等过程,如果形成了多个磁盘文件还会进行合并,最后一次合并的结果作为reduce的输入而不是写入到磁盘中。
2.3 最后一次合并的结果作为输入传入到reduce任务中,当reduce输入文件确定后,整个shuffle操作才算最终结束,之后就是reduce的计算,并把结果存到hdfs上

 浙公网安备 33010602011771号
浙公网安备 33010602011771号