2020软件工程第二次作业(个人编程)
2020软件工程第二次作业(个人编程)
-
这个作业属于哪个课程 https://edu.cnblogs.com/campus/fzu/SE2020 这个作业要求在哪里 https://edu.cnblogs.com/campus/fzu/SE2020/homework/11167 这个作业的目标 学习从需求到实现的软件工程大致流程,学习代码的优化以及测试,学习大文件的读取优化 学号 031802127 -
PEP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 180 | 120 |
| Estimate | 估计这个任务需要多少时间 | 60 | 40 |
| Development | 开发 | 500 | 1200 |
| Analysis | 需求分析 (包括学习新技术) | 300 | 500 |
| Design Spec | 生成设计文档 | 60 | 58 |
| Design Review | 设计复审 | 60 | 70 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 120 | 110 |
| Design | 具体设计 | 240 | 150 |
| Coding | 具体编码 | 500 | 998 |
| Code Review | 代码复审 | 500 | 400 |
| Test | 测试(自我测试,修改代码,提交修改) | 500 | 400 |
| Reporting | 报告 | 200 | 140 |
| Test Report | 测试报告 | 200 | 100 |
| Size Measurement | 计算工作量 | 100 | 80 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 100 | 60 |
| 合计 | 3520 | 4426 |
一、思考历程
最初很困难,看完题目,除了知道要统计分析用户行为数据,其他的都是天书:
- 首先是GH Achieve是什么,怎么下载里面的数据;
- github actions又是什么;
- 最费解的是格式要求里的内容,究竟怎么用;
- 对于数据范围10Gb我没有很明确的概念,它所限制的是什么;
- github早前已用过,但fork与pull request依然令我不解;
- 要编写一个自己的代码规范,至少任务是明确的;
- 代码如何向github提交并编译;pep表格是什么;
- 单元测试覆盖率优化...
由于没有python基础,期间课多,在查资料、理解代码、写注释、直至弄懂参考代码的解题流程后,已经是第三天。运行代码也是问题,问了同学,费老大劲才明白是命令行。但这也成了切入点,由命令行的启发转去研究格式要求,初始化和查询是分开的、路径是文件夹是由参考代码写法决定的、-i -e等命令是由argparser命令行解析器来解析的...上述问题,虽然现在看起来颇为稚嫩,但在几天前,我明白一个写法,就好像要去发现一座新大陆。第五天我才开始考虑如何优化代码,使之能够支持大文件读入。
很容易想到,大文件读入可采取逐行读入并处理的方式进行优化。便修改了读入模块,但由于参考数据较小,优化没有明显效果。由于如何在GH Archive下载数据那时仍困扰着我,我就开始看大量的大数据处理方法的资料,意图重构代码逻辑,期间了解到处理数据用的第三方库,ijson、pandas、simplejson等,但没有获得有针对性的信息。
期间也纠结于是否换用其他语言,Java并不熟练,C++在命令行参数的处理以及字符串处理上似乎较繁琐,较之python的简洁,实在难以选择。参考代码已给出,只做优化似乎不需要花费太多时间学习python语法。因此最终选择如此。
即使是在GH Archive下载数据这样简单的操作,我也反复看了许多遍。偶然发现GH Achieve里的数据文件只需要通过url下载(之前因此浪费了许多时间)
二、设计实现过程
实现过程并不难:
1)初始化:将json文本(原文本是多个字典)读入 --> 提取关键信息 --> 整理后输出(此时的输出是单个字典)
2)查询:将整理后的文件读入 --> 按字典查询即可。
-
程序运行流程图:
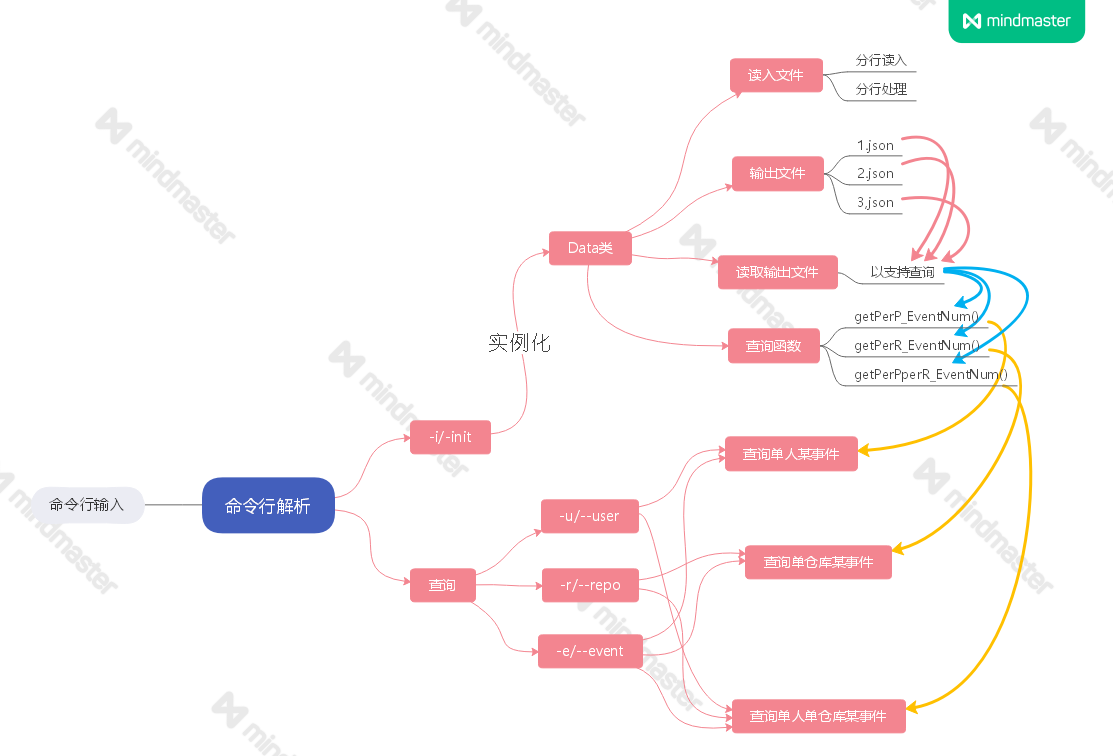
三、迭代过程描述
在最初仅进行逐行读入的优化基础上测试,效果并不明显... 当数据量达到10 GB,时间很难看到尽头。
接着考虑代码结构上修改,发现在将读入的 json 文件转换得到的字典处理过程中,原代码存在冗余的操作,于 是将其简化,每读入一行即进行一次关键信息筛选并统计。如此一来,在10 GB的测试数据下,能达到3分钟的 初始化速度,几乎不占用内存。
- V 1.0:
def _init(self, jsonAddress):
self.__4Events4PerP = {}
self.__4Events4PerR = {}
self.__4Events4PerPPerR = {}
for root, dic, files in os.walk(jsonAddress):
for f in files:
if f[-5:] == '.json':
with open(jsonAddress + '\\' + f, 'r', encoding = 'UTF-8') as f:
while True:
i = f.readline() # 读入优化
if not i:
break
line = json.loads(i)
rType = line['type']
if rType == 'PushEvent' or rType == 'IssueCommentEvent' or \
rType == 'IssueEvent' or rType == 'PullRequestEvent':
self._eventNumAdd(line)
...
def _eventNumAdd(self, dic: dict): # 结构优化
rId = dic['actor']['login']
rRepo = dic['repo']['name']
rType = dic['type']
if not self.__4Events4PerP.get(rId, 0): # *
self.__4Events4PerP.update({rId: {}})
self.__4Events4PerPPerR.update({rId: {}})
self.__4Events4PerP[rId][rType] \
= self.__4Events4PerP[rId].get(rType, 0) + 1
if not self.__4Events4PerR.get(rRepo, 0):
self.__4Events4PerR.update({rRepo: {}})
self.__4Events4PerR[rRepo][rType] \
= self.__4Events4PerR[rRepo].get(rType, 0) + 1
if not self.__4Events4PerPPerR[rId].get(rRepo, 0):
self.__4Events4PerPPerR[rId].update({rRepo: {}})
self.__4Events4PerPPerR[rId][rRepo][rType] \
= self.__4Events4PerPPerR[rId][rRepo].get(rType, 0) + 1
解决了内存问题后,接着进一步考虑速度优化,我想到了多线程与多进程。但由于此前还没有关于线程进程的概念,查找资料花了很多时间,在写的过程中又bug频出:
- V 2.0:下面是多进程分行的读入优化:
def __init__(self, jsonAddress: str = None, isInit: int = 0):
self.list = []
self.count = 0
self.num = 32
if isInit == 1:
self._init(jsonAddress)
return # 优化
if jsonAddress is None and not os.path.exists("1.json") and not os.path.exists("2.json") and not os.path.exists("3.path"):
raise RuntimeError("error: init failed")
x = open('1.json', 'r', encoding='utf-8').read()
self.__4Events4PerP = json.loads(x)
x = open('2.json', 'r', encoding='utf-8').read()
self.__4Events4PerR = json.loads(x)
x = open('3.json', 'r', encoding='utf-8').read()
self.__4Events4PerPPerR = json.loads(x)
def _handle(self, line):
rType = line['type']
# 控制仅读入4种关注事件
if rType == 'PushEvent' or rType == 'IssueCommentEvent' or \
rType == 'IssueEvent' or rType == 'PullRequestEvent':
self._eventNumAdd(line)
def _init(self, jsonAddress):
self.__4Events4PerP = {}
self.__4Events4PerR = {}
self.__4Events4PerPPerR = {}
pool = multiprocessing.Pool(self.num)
for root, dic, files in os.walk(jsonAddress):
for f in files:
if f[-5:] == '.json':
n = 0
with open(jsonAddress + '\\' + f, 'r', encoding = 'UTF-8') as f: # 优化
while True:
i = f.readline()
if not i:
break
line = json.loads(i)
if self.count == self.num:
for i in range(n - self.num, n):
pool.apply_async(self._handle, (self.list[i], ))
self.count = 0
self.list.append(line)
n += 1
self.count += 1
但事实上发现这种方式并不能解决问题,多进程情况下,根本跑不出结果。
- V 3.0 :下面是多线程分文件的读入优化
def _handle(self, jsonAddress, f):
with open(jsonAddress + '\\' + f, 'r', encoding='UTF-8') as af: # 优化
while True:
i = af.readline()
if not i:
break
line = json.loads(i)
rType = line['type']
# 控制仅读入4种关注事件
if rType == 'PushEvent' or rType == 'IssueCommentEvent' or \
rType == 'IssueEvent' or rType == 'PullRequestEvent':
self._eventNumAdd(line)
def _init(self, jsonAddress):
self.__4Events4PerP = {}
self.__4Events4PerR = {}
self.__4Events4PerPPerR = {}
for root, dic, files in os.walk(jsonAddress):
for f in files:
if f[-5:] == '.json':
t = threading.Thread(target= self._handle, args=(jsonAddress, f))
t.start()
self.threads.append(t)
if not self.threads:
with open('./1.json', 'w', encoding='utf-8') as f:
json.dump(self.__4Events4PerP, f) # 写入
with open('./2.json', 'w', encoding='utf-8') as f:
json.dump(self.__4Events4PerR, f)
with open('./3.json', 'w', encoding='utf-8') as f:
json.dump(self.__4Events4PerPPerR, f)
在多线程情况下对分文件开线程测试,速度反而变慢。也试了多线程的分行以及多进程的分文件,均告败。
查询资料分析原因:多线程读取同一文件时,如果并发执行,会导致读取出的数据有遗漏或重复。要保证不出 错,需要对线程进行同步,可以使用队列或加锁的方式实现。而且似乎python的多线程但这样做并不能提高效 率,我始终没能实现。
由于对python也是初次接触,各种语法问题也耗费我很多时间。我在线程的控制上也还存在问题,写法上bug 也存在,时间限制我没能解决之。
因此最终的版本仍然来自于V 1.0
四、测试(基于 0.99 GB数据):
- 1)单元测试:
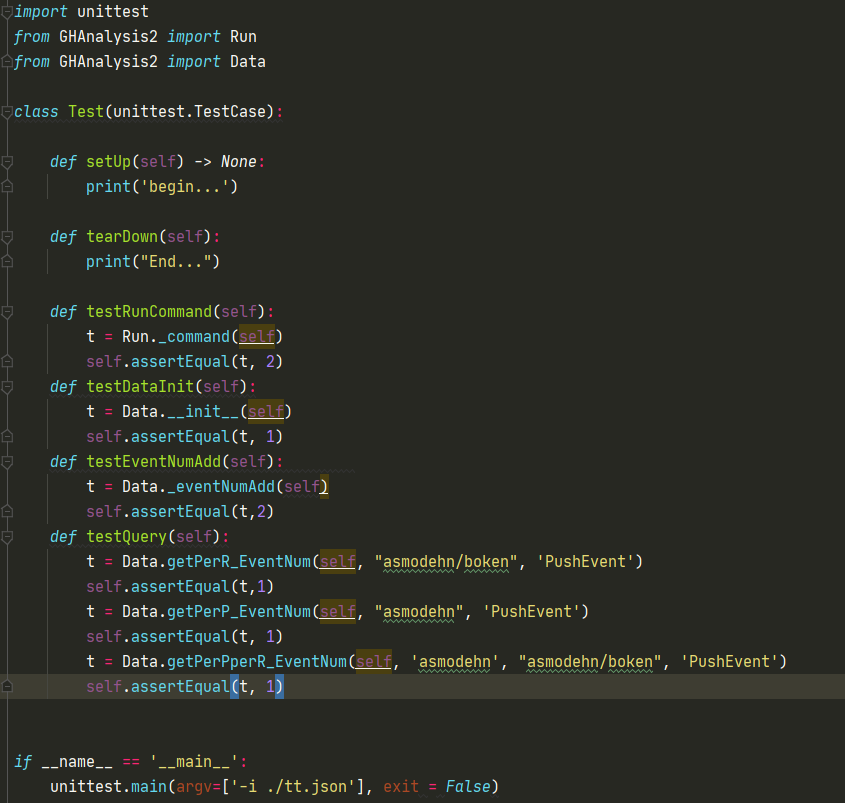
-
2)单元测试覆盖率:
初始化覆盖率:

查询覆盖率:

-
3)性能测试:
主要函数时间占比:

五、代码规范链接
https://github.com/rebuilder945/2020-personal-python/blob/master/codestyle.md
六、总结
时间与回报总是相宜的,在这次作业中,关于数据处理以及性能优化我有了更多的认识,也看到了自己的不足,接下去会继续学习,注意在这方面的提升。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号