Java设计模式--工厂方法模式
工厂方法模式(Factory Method),是23种设计模式之一。DP中是这么定义工厂方法模式的:
工厂方法模式定义一个用于创建对象的接口,让子类决定实例化哪一个类。工厂方法使一个类的实例化延迟到其子类。
所谓工厂方法模式,其实也像我们现实生活中的工厂,也是用来生产东西的,只不过我们代码中的工厂是用来生产对象的,不要想歪,此对象非彼对象233。
我们在开发过程中,总是要编写许许多多的类,当我们需要一些类的实例化对象时,如果总是不管三七二十一在代码上直接去new的话,倒也不是说不行,只是会导致代码比较糟糕、不灵活。例如,有些通用的功能类或者需要隐藏得比较深的类(隐藏类是方便后期更换),你在你写的代码上去new它的对象,那么如果后期这个类更名了、移除了、功能增删了,那么你的写的代码就有可能会崩掉,需要重新去修改这些new对象的地方才能再次让你的代码正常运行。这就是一种耦合度高的体现,所以我们首先应该依赖的是一个抽象的接口或父类,而不是依赖具体的子类,这也是依赖倒转原则强调的,除此之外我们最好不要在一些容易发生变动的地方直接通过子类类名去new对象,不然的话依旧会出现这种情况。所以我们应该把子类对象的创建交给别人去完成,而这个 “别人” 就是工厂。
如果学过简单工厂模式,就应该知道,工厂的目的是为了帮我们解决创建对象实例的问题,并且工厂能够隐藏类名及对象创建的细节,让我们无需关心对象的创建。不过如果只是简单工厂模式的话不能算是设计模式,它只能算是工厂方法模式的入门模式。
可能直接介绍什么是工厂方法模式的话,没那么容易明白它比简单工厂模式好在哪,毕竟在代码上看起来工厂方法模式要比简单工厂模式麻烦,需要写更多的代码。所以我们先来看一个使用简单工厂模式设计的代码,然后再过渡到使用工厂方法模式来重构代码,以此来对比它们的区别以及工厂方法模式的好处。
例如使用简单工厂模式编写一个简单的计算器,结构图如下: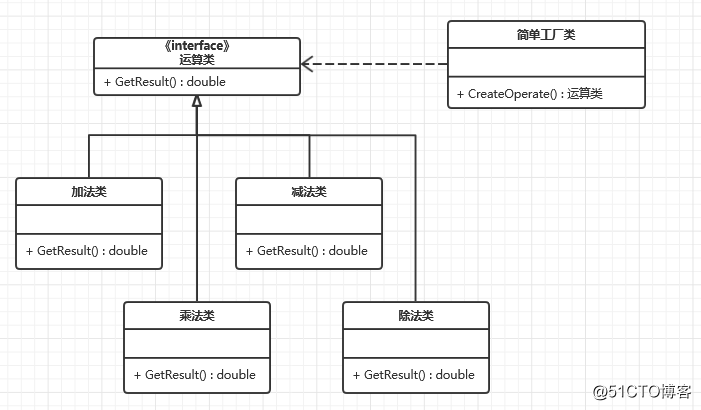
代码实现如下:
1. 定义一个接口:
public interface Operation { Double getResult(Double numberA, Double numberB) throws Exception; }
2. 定义具体的计算类:
public class Add implements Operation { @Override public Double getResult(Double numberA, Double numberB) { return numberA + numberB; } } public class Sub implements Operation { @Override public Double getResult(Double numberA, Double numberB) { return numberA - numberB; } } public class Mul implements Operation { @Override public Double getResult(Double numberA, Double numberB) { return numberA * numberB; } } public class Div implements Operation { @Override public Double getResult(Double numberA, Double numberB) throws Exception { if (numberB == 0) { throw new Exception("除数不能为0"); } return numberA / numberB; } }
3. 定义简单工厂类:
public class EasyFactory { public static Operation createOperation(String name) { Operation operation = null; switch (name) { case "+": operation = new Add(); break; case "-": operation = new Sub(); break; case "*": operation = new Mul(); break; case "/": operation = new Div(); break; } return operation; } }
4. 客户端代码:
public class Client { public static void main(String[] args) throws Exception { Operation add = EasyFactory.createOperation("+"); Operation sub = EasyFactory.createOperation("-"); Operation mul = EasyFactory.createOperation("*"); Operation div = EasyFactory.createOperation("/"); System.out.println(add.getResult(1.0, 1.0)); System.out.println(sub.getResult(1.0, 1.0)); System.out.println(mul.getResult(1.0, 1.0)); System.out.println(div.getResult(1.0, 1.0)); } }
运行结果:
2.0 0.0 1.0 1.0
如上,从客户端的代码上可以看到,我们无需提供具体的子类类名,只需要提供一个字符串即可得到相应的实例对象。这样的话,当子类的类名更换或者增加子类时我们都无需修改客户端代码,只需要在简单工厂类上增加一个分支判断代码即可。
而且由于业务的需要,我们可能还得在创建对象的过程中增加一些代码,例如增加打印语句、记录日志、条件判断等。业务代码比较多的话,我们还可以这些switch case里的代码都封装在一个个的方法里,那么在switch case里就只需要调用相应的方法即可,方法里的代码就任你写了。而这些细节代码是客户端所看不到的,客户端只需要知道最终得到一个实例对象即可,这就起到了隐藏对象创建过程的细节。例如,我们把简单工厂类的代码修改一下:
package org.zero01.test; public class EasyFactory { private static Operation operationObj = null; private static Operation add(){ System.out.println("加法运算"); return new Add(); } private static Operation sub(){ System.out.println("减法运算"); return new Sub(); } private static Operation mul(){ System.out.println("乘法运算"); return new Mul(); } private static Operation div(){ System.out.println("除法运算"); return new Div(); } // 简单工厂,根据字符串创建相应的对象 public static Operation createOperation(String name) { switch (name) { case "+": operationObj = add(); break; case "-": operationObj = sub(); break; case "*": operationObj = mul(); break; case "/": operationObj = div(); break; } return operationObj; } }
我把switch case里的创建对象语句都提取到了相应的方法中,并且增加了一些打印语句,而客户端以及其他类的代码完全不需要改动。客户端也不知道创建对象的过程有打印语句,我这么做的目的是为了说明一点,我们可以在创建对象的方法里写任意的代码,可以对创建的对象进行一些 “加工” ,而且客户端并不知道,因为工厂隐藏了这些细节。如果,没有工厂的话,那我们是不是就得自己在客户端上写这些代码,这就好比本来可以在工厂里生产的东西,拿来自己手工制作,不仅麻烦以后还不好维护。
虽然以上说得挺好的,好像没啥问题了,其实这时候简单工厂的问题才暴露出来了,以上的代码只是为了演示思路,所以方法里没写什么实际的代码。但想象一下,如果需要在方法里写很多与对象创建有关的业务代码,而且需要的创建的对象还不少的话,我们是不是要在这个简单工厂类里编写很多个方法,每个方法里是不是得写很多相应的业务代码,而每次增加子类或者删除子类对象的创建是不是都需要打开这简单工厂类来进行修改?这不就很明显的会导致这个简单工厂类很庞大臃肿、耦合性高吗,而且增加、删除某个子类对象的创建都需要打开简单工厂类来进行修改代码也违反了开-闭原则,如果这是客户端代码还好说,但简单工厂类也算是一个功能类,所以不能随便就去修改它。
所以为了解决以上所提到的问题,就需要使用到工厂方法模式了,工厂方法模式是对简单工厂模式进一步的解耦,因为在工厂方法模式中是一个子类对应一个工厂类,而这些工厂类都实现于一个抽象接口。这相当于是把原本会因为业务代码而庞大的简单工厂类,拆分成了一个个的工厂类,这样代码就不会都耦合在同一个类里了,就像把一个大蛋糕切成了多个小蛋糕。
工厂方法模式(Factory Method)结构图: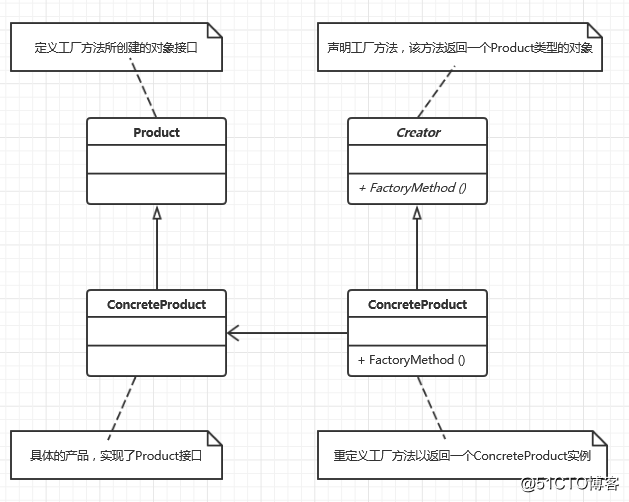
那么我们就来把之前的代码使用工厂方法模式进行重构,然后再对比一下它俩的区别:
代码结构图: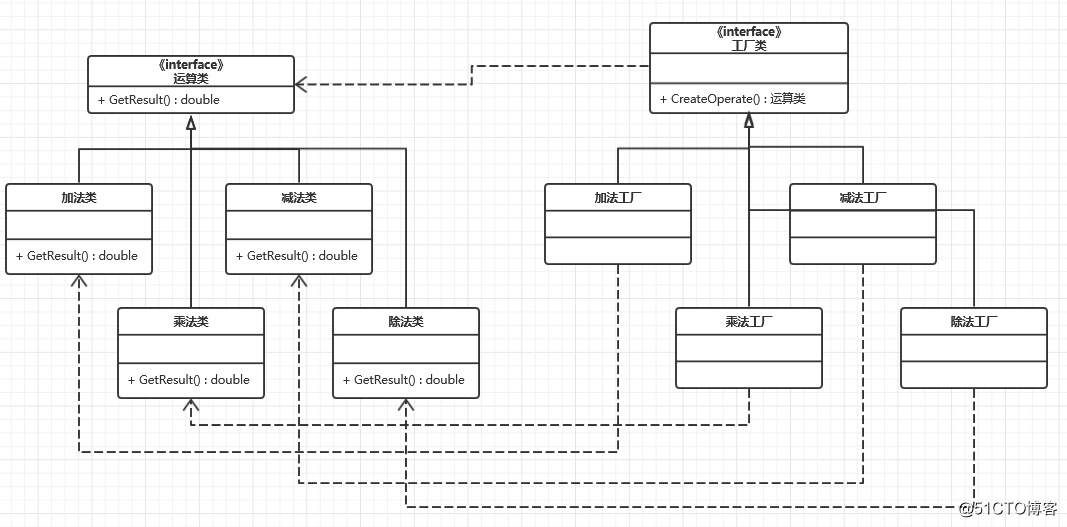
1. 定义一个工厂接口:
public interface Factory{ Operation createOperation(); }
2. 定义具体的工厂类:
public class AddFactory implements Factory { @Override public Operation createOperation() { return new Add(); } } public class SubFactory implements Factory{ public Operation createOperation() { return new Sub(); } } public class MulFactory implements Factory{ public Operation createOperation() { return new Mul(); } } public class DivFactory implements Factory{ public Operation createOperation() { return new Div(); } }
运算类与之前一致,略。
3. 客户端代码:
public class ClientTest { public static void main(String[] args) throws Exception { // 使用反射机制实例化工厂对象,因为字符串是可以通过变量改变的 Factory addFactory = (Factory) Class.forName("com.springboot.design_model.factory_method.AddFactory").newInstance(); Factory subFactory = (Factory) Class.forName("com.springboot.design_model.factory_method.SubFactory").newInstance(); Factory mulFactory = (Factory) Class.forName("com.springboot.design_model.factory_method.MulFactory").newInstance(); Factory divFactory = (Factory) Class.forName("com.springboot.design_model.factory_method.DivFactory").newInstance(); // 通过工厂对象创建相应的实例对象 Operation add = addFactory.createOperation(); Operation sub = subFactory.createOperation(); Operation mul = mulFactory.createOperation(); Operation div = divFactory.createOperation(); System.out.println(add.getResult(1.0, 1.0)); System.out.println(sub.getResult(1.0, 1.0)); System.out.println(mul.getResult(1.0, 1.0)); System.out.println(div.getResult(1.0, 1.0)); } }
从以上的编写的代码可以看到,工厂方法模式看起来要比起简单工厂要麻烦不少,一个产品类就要对应一个工厂类,要增加产品类时也要相应地增加工厂类,客户端的代码也增加了不少,这也是很多初学者不明白的地方。的确,简单工厂是要简便些,所以它不适合应用在比较大的项目里,而且大部分情况下也是简单工厂要常用些。但是,你得先事先考虑好简单工厂是否无法承受你的项目,如果不能承受,就应该考虑使用工厂方法模式。
所以,有些设计模式只有在接触到大型项目时才能体会到它们好在哪里。以上的代码也比较粗糙和简单,但是我觉得对于讲解设计模式来说,不需要用太复杂的代码去演示它,不然会让初学者的注意力集中在代码上,而不是设计模式的思想上。所以说代码是死的而思想是活的,代码是用于承载设计者的思想的,我们应该在写代码的过程中去活用这些设计模式。但也不要啥玩意都去用设计模式去写,不然就会导致代码设计过度。
简单工厂 VS 工厂方法:
简单工厂模式最大的优点在于工厂类中,包含了必要的逻辑判断,根据客户端的选择条件动态实例化相关的类,对于客户端来说,去除了与具体产品的依赖。就像之前使用简单工厂模式设计的计算器代码,客户端不用管该用哪个类的实例,只需要把相应的运算符号给工厂,工厂自动就给出了相应的实例,客户端只需要去做运算就可以了,不同的实例会实现不同的运算。当问题也就在这里,如果要加一个“求 M 数的 N 次方” 的功能,我们是一定需要给简单工厂类的方法里加分支条件的,这就等于说,我们不仅对扩展开发了,也对修改开放了,这样就违背了开-闭原则。而且如果简单工厂类里与创建对象相关的代码太多,也会导致耦合性高。
工厂方法模式实现时,客户端需要决定实例化哪一个工厂来实现运算类,选择判断的问题还是存在的,也就是说,工厂方法把简单工厂的内部逻辑判断转移到了客户端代码来进行。你想要加功能,本来是改工厂类的,而现在是修改客户端。而且各个不同功能的实例对象的创建代码,也没有耦合在同一个工厂类里,这也是工厂方法模式对简单工厂模式解耦的一个体现。工厂方法模式克服了简单工厂会违背开-闭原则的缺点,又保持了封装对象创建过程的优点。所以它们都是集中封装了对象的创建,使得要更换对象时,不需要做大的改动就可以实现,降低了客户程序与产品对象的耦合。工厂方法模式是简单工厂模式的进一步抽象和推广。由于使用了多态性,工厂方法模式保持了简单工厂模式的优点,而且克服了它的缺点。但工厂方法模式的缺点是每增加一个产品类,就需要增加一个对应的工厂类,增加了额外的开发量。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号