
Java并发编程 - 线程池的认识(二)
核心线程池的内部实现
依然参考 JDK 对线程池的支持,各个接口、相关类之间的关系: 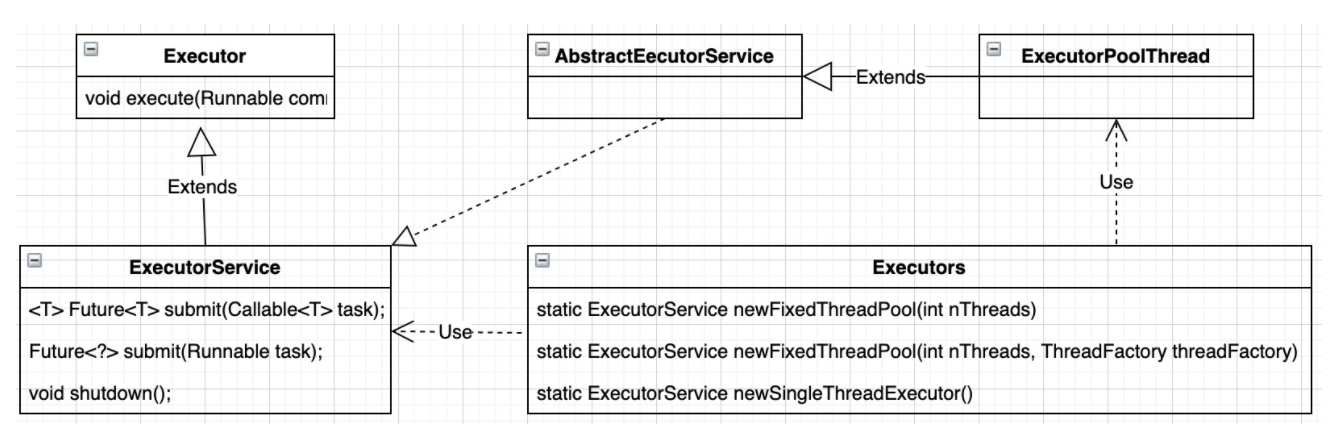
(1)对于Executors中几个创建线程池方法底层实现:
// 创建固定线程数量的线程池 public static ExecutorService newFixedThreadPool(int nThreads) { return new ThreadPoolExecutor(nThreads, nThreads, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>()); } // 创建单一线程数量的线程池 public static ExecutorService newSingleThreadExecutor() { return new FinalizableDelegatedExecutorService (new ThreadPoolExecutor(1, 1, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>())); } // 创建缓存线程数量的线程池 public static ExecutorService newCachedThreadPool() { return new ThreadPoolExecutor(0, Integer.MAX_VALUE, 60L, TimeUnit.SECONDS, new SynchronousQueue<Runnable>()); }
由以上线程池的实现代码可以看到,它们都只是 ThreadPoolExecutor 类的封装。为何 ThreadPoolExecutor 有如此强大的功能呢?来看一下 ThreadPoolExecutor 最重要的构造函数:
public ThreadPoolExecutor(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue, ThreadFactory threadFactory, RejectedExecutionHandler handler)
(2)ThreadPoolExecutor 核心构造函数的参数含义如下:
1)coolPoolSize:指定了线程池中的线程数量;
2)maximumPoolSize:指定了线程池中的最大线程数量;
3)keepAliveTime:当线程池线程数量超过 corePoolSize 时,多余的空闲线程的存活时间。即:超过 corePoolSize 的空闲线程,在多长时间内会被销毁;
4)unit:keepAliveTime 的单位;
5)workQueue:任务队列,被提交但未被执行的任务;
6)threadFactory:线程工厂,用户创建线程,一般使用默认的即可;
7)handler:拒绝策略。当任务太多来不及处理,如何拒绝任务执行。
以上参数中,大部分都很简单,只有 workQueue 和 handler 需要进行详细说明!
(3)workQueue 任务队列详解
参数 workQueue 指被提交但未执行的任务队列,它是一个 BlockingQueue 接口的对象,仅用于存放 Runnable 实例对象。根据队列功能分类,在 ThreadPoolExecutor 的构造函数中可使用一下几种 BlockingQueue
1)直接提交的队列:该功能由 SynchronousQueue 对象提供。SynchronousQueue 是一个特殊的 BlockingQueue。SynchronousQueue 没有容量,每一个插入操作都要等待一个相应的删除操作,反之,每一个删除操作都要等待对应的插入操作。如果使用 SynchronousQueue,提交的任务不会被真实的保存,而总是将新任务提交给线程执行,如果没有空闲的线程,则尝试创建新的线程,如果线程数量已经达到最大值,则执行拒绝策略。因此,使用 SynhronousQueue 队列,通常要设置很大的 maximumPoolSize 值,否则很容易执行拒绝策略。
2)有界的任务队列:有界的任务队列可以使用 ArrayBlockingQueue 实现。ArrayBlockingQueue 的构造函数必须带一个容量参数,表示该队列的最大容量,如下所示:
public ArrayBlockingQueue(int capacity)
当使用有界的任务队列时,若有新的任务需要执行,如果线程池的实际线程数小于 corePoolSize,则会优先创建新的线程,若大于 corePoolSize,则会将新任务加入等待队列。若等待队列已满,无法加入,则在总线程数不大于 maximumPoolSize 的前提下,创建新的线程执行任务。若大于 maximumPoolSize,则执行拒绝策略。可见,有界队列仅当在任务队列装满时,才可以将线程数提升到 corePoolSize 以上,换言之,除非系统非常繁忙,否则确保核心线程数维持在 corePoolSize。
3)无界的任务队列:无界任务队列可以通过 LinkedBlockingQueue 类实现。与有界队列相比,除非系统资源耗尽,否则无界队列不存在入队失败的情况。当有新的任务到来,系统的线程数小于 corePoolSize 时,线程池会创建新的线程执行任务,但当系统的线程数达到 corePoolSize 后,就不会继续增加。若后续仍有新的任务加入,而又没有空闲的线程资源,则任务直接进入队列等待。若任务创建和处理的速度差异很大,无界队列会保持快速增长,直到耗尽系统内存。
注意:LinkedBlockingQueue无界的任务队列,是一个单向链表!线程池的初始化容量为:Integer.MAX_VALUE
4)优先任务队列:优先任务队列是带有执行优先级的队列。它通过 PriorityBlockingQueue 实现,可以控制任务的执行先后顺序。它是一个特殊的无界队列。无论是有界队列 ArrayBlockingQueue,还是未指定大小的无界队列 LinkedBlockingQueue,都是按照先进先出算法处理任务的。而 PriorityBlockingQueue 则可以根据任务自身的优先级顺序先后执行,在确保系统性能的同时,也能有很好的质量保证(总是确保高优先级的任务先执行)。
(4)这里给出 ThreadPoolExecutor 线程池的核心调度代码,这段代码也充分体现了上述线程池的工作逻辑

(5)拒绝策略
ThreadPoolExecutor 的最后一个参数指定了拒绝策略。也就是当任务数量超过系统实际承载能力时,该如何处理?拒绝策略可以说是系统超负荷运行时的补救措施,通常由于压力太大而引起的,也就是线程池中的线程已经用完了,无法继续为新任务服务,同时,等待队列中也已经排满了,再也塞不下新任务了。这时,我们就需要一套机制合理地处理这个问题。
JDK内置提供了四种拒绝策略:
1)AbortPolicy 策略:该策略会直接抛出异常,阻止系统正常工作;
2)CallerRunsPolicy 策略:只要线程池未关闭,该策略直接在调用者线程中,运行当前被丢弃的任务【调用线程中执行该任务】。显然这样做不会真的丢弃任务,但是任务提交线程的性能极有可能会急剧下降;
3)DiscardOledestPolicy 策略:该策略将丢弃最老的一个请求,也就是即将被执行的一个任务,并尝试再次提交当前任务;
4)DiscardPolicy 策略:该策略默默地丢弃无法处理的任务,不予任何处理。如果允许任务丢弃,我觉得这可能是最好的一种方案吧!
以上就是线程池的详细解释,写了近两天,终于理清楚了,这下面试就可以侃侃而谈了,欢迎大家学习一起进步!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号