
分布式事务seata
1.事务的4大基本特征。
1)原子性
2)一致性
3)隔离性
4)持久性
2.什么是分布式事务?
本地事务:单服务进程,单数据库资源,同一个连接conn多个事务操作。
分布式事务:多服务进程,多数据库资源(多个conn)。
3.seata_AT模式的工作流程。
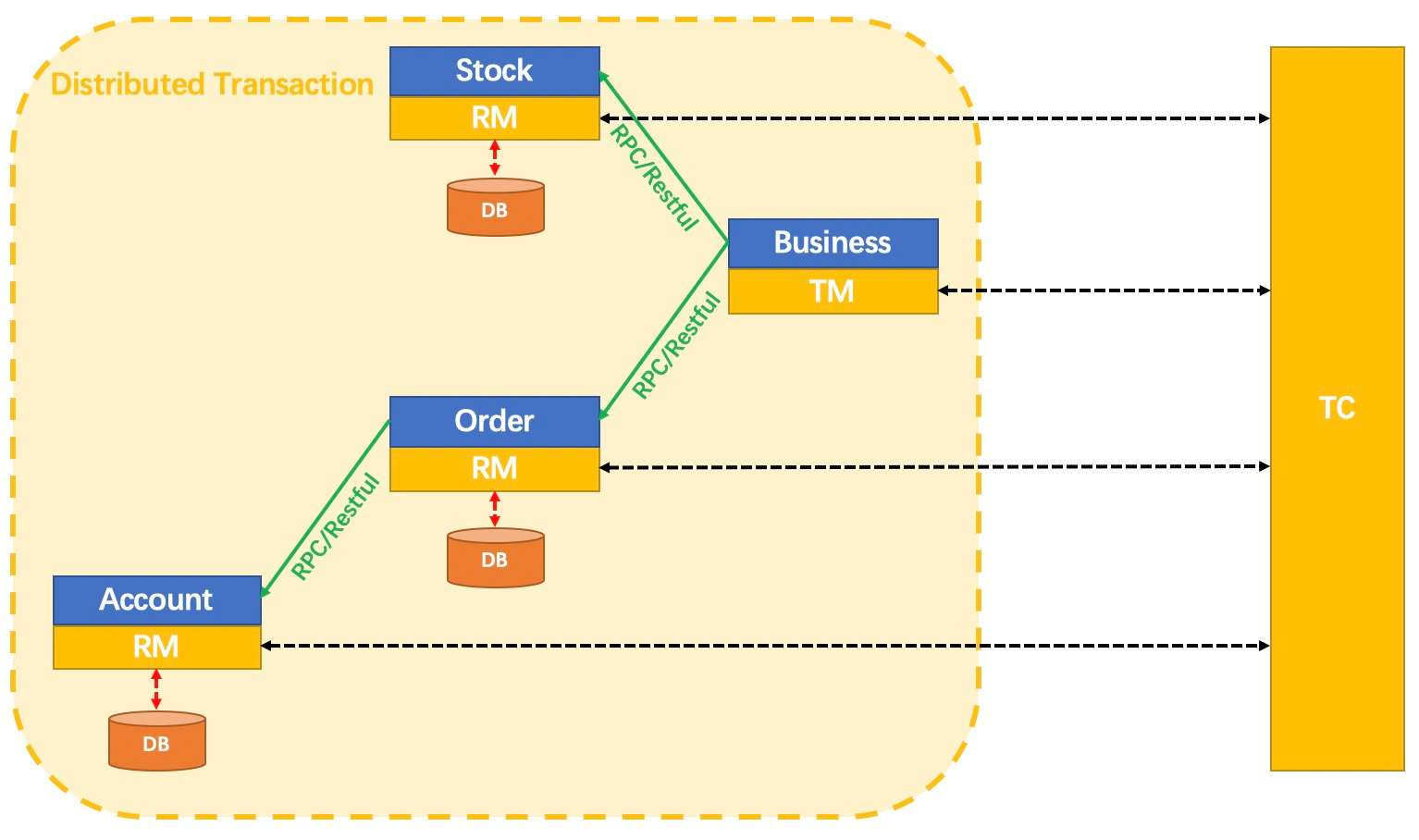
TC (Transaction Coordinator) - 事务协调者
维护全局和分支事务的状态,驱动全局事务提交或回滚。
TM (Transaction Manager) - 事务管理器
定义全局事务的范围:开始全局事务、提交或回滚全局事务。
RM (Resource Manager) - 资源管理器
管理分支事务处理的资源,与TC交谈以注册分支事务和报告分支事务的状态,并驱动分支事务提交或回滚。
4.seata整体机制(分成两阶段)
两阶段提交协议的演变:
-
一阶段:业务数据和回滚日志记录在同一个本地事务中提交,释放本地锁和连接资源。
-
二阶段:
- 提交异步化,非常快速地完成。
- 回滚通过一阶段的回滚日志进行反向补偿。
一阶段:
在一阶段中,seata会拦截“业务SQL”,首先解析SQL语义,找到要更新的业务数据,在数据被更新前,保存下来“undo”(undo_log日志),然后执行业务SQL更新数据,更新之后再次保存数据“redo”,最后生成行锁(行锁就是针对数据表中行记录的锁),这些操作都在数据库本地事务完成的,这样保证了数据的原子性。(并把本地事务的执行结果(即分支事务回滚的结果)上报给 TC)
二阶段:
负责整体的回滚和提交,如果之前的一阶段中有本地事务没有通过,那么就执行全局回滚,否则在执行全局提交,回滚用到的就是一阶段记录的“undo_log”,通过回滚记录生成反向更新SQL并执行,以完成分支的回滚。当事务完成后会释放所有的资源和删除所有的日志。(提交:如果事务边界没有发生任何异常,全局事务可以提交,TM通知TC进行全局事务的提交,TC释放全局锁,RM删除undo_log日志
回滚:如果事务边界发生任何异常,全局事务必须回滚,TM通知TC全局事务回滚,TC通知RM进行分支事务回滚,分支事务根据undo_log日志反向补偿(必须获取全局锁(全局锁就是对整个数据库实例加锁)))
5.seata(1.4)与springBoot的整合。
store.db.globalTable db模式全局事务表名
store.db.branchTable db模式分支事务表名
store.db.lockTable db模式全局锁表名
@GlobalTransactional
6.seata全局并发事务怎么隔离?
写隔离
- 一阶段本地事务提交前,需要确保先拿到 全局锁 。
- 拿不到 全局锁 ,不能提交本地事务。
- 拿 全局锁 的尝试被限制在一定范围内,超出范围将放弃,并回滚本地事务,释放本地锁。
读隔离
在数据库本地事务隔离级别 读已提交(Read Committed) 或以上的基础上,Seata(AT 模式)的默认全局隔离级别是 读未提交(Read Uncommitted)
7.CAP理论?
所谓CAP理论,说的是在分布式架构下的数据一致性问题和性能问题的平衡方案
C:Consistency 一致性 同一数据的多个副本是否实时相同。
A:Availability 可用性 可用性:一定时间内 & 系统返回一个明确的结果 则称为该系统可用。
P:Partition tolerance 分区容错性 将同一服务分布在多个系统中,从而保证某一个系统宕机,仍然有其他系统提供相同的服务。
在互联网行业竞争激烈的今天,相同领域的竞争者不甚枚举,系统的间歇性不可用会立马导致用户流向竞争对手。因此,我们只能通过牺牲一致性来换取系统的可用性和分区容错。
所以这才有了Zookeeper(cp)中的基于少数服从多数的2pc落地方案。因此,也引出了另外一个理论,叫Base理论。
8.Base理论?
CAP理论告诉我们一个悲惨但不得不接受的事实——我们只能在C、A、P中选择两个条件。而对于业务系统而言,我们往往选择牺牲一致性来换取系统的可用性和分区容错性。不过这里要指出的是,所谓的“牺牲一致性”并不是完全放弃数据一致性,而是牺牲强一致性换取弱一致性
BA:Basic Available 基本可用
S:Soft State:柔性状态 同一数据的不同副本的状态,可以不需要实时一致
E:Eventual Consisstency:最终一致性 同一数据的不同副本的状态,可以不需要实时一致,但一定要保证经过一定时间后仍然是一致的。
基于可靠性消息的最终一致性方案:
可靠性消息最终一致性方案,是指在多个事务中,当前事务发起方执行完本地事务后,发送一条数据同步消息给到事务参与方。
基于可靠性消息队列,需要保证这个消息一定能够被其他事务参与方接收并执行成功,从而实现多个事务参与者之间的数据最终一致性。
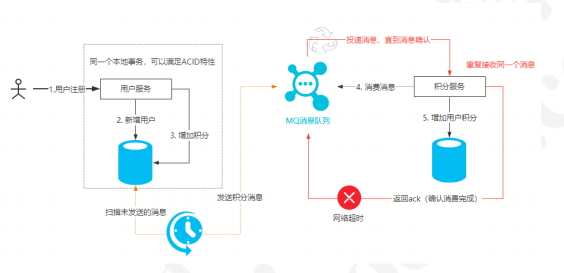
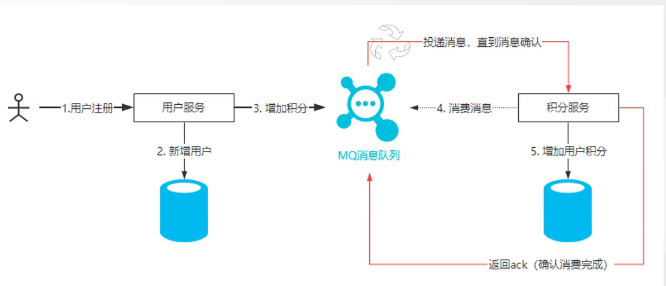
实现原理如下图所示:

这个方案存在两个问题:
1.本地事务与消息发送的原子性问题
-
-
![]()
- 解决方案:
![]()
-
基于本地消息表实现重发
本地消息表这个方案最初是 eBay提出的,此方案的核心是通过本地事务保证数据业务操作和
消息的一致性,然后通过定时任务将消息发送至消息中间件,待确认消息发送给消费方成功再
将消息删除。
下面以注册送积分为例来说明:下例共有两个微服务交互,用户服务和积分服务,用户服务负
责添加用户,积分服务负责增加积分。
![]()
- 2.事务参与方接收消息的可靠性
-
![]()
- 3.消息重复消费的问题
消息重复投递的幂等性保障!
在可靠性消息投递过程中,由于MQ的重试机制,有可能会出现消费者重复收到同一个消息的情
况。
因此,我们需要保证消息投递的幂等性,所谓的幂等性,就是MQ重复调用多次产生的业务结果
与调用一次产生的业务结果相同;
-
- 数据库唯一约束实现幂等
- 通过tokenid的方式去识别每次请求判断是否重复
- redis中的setNX
- 状态机幂等性
- 本地消息表生成md5实现唯一约束
-
-




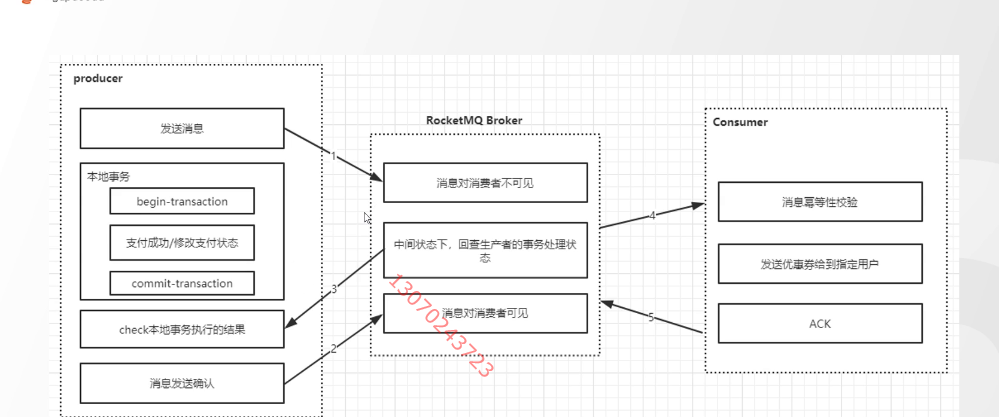
RocketMQ的本地事务:
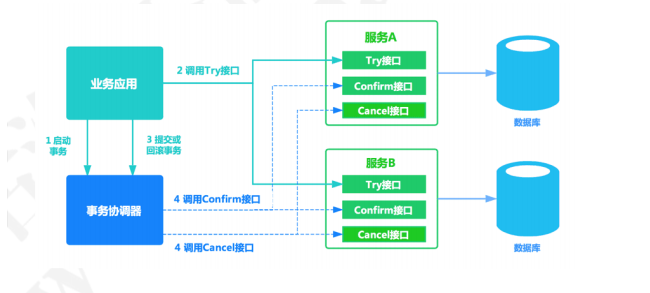
9.TCC的模式?
TCC事务解决方案
TCC的方案,在电商、金融领域落地也比较多,他是一种两阶段提交的基于应用层的改进方案。TCC将整个业务逻辑的每个分支分成了Try、Confirm、Cancel三个操作,try部分完成业务的准备工作, confirm部分完成业务的提交、cancel部分完成事务的回滚。
TCC事务解决方案本质上是一种补偿的思路,它把事务运行过程分成Try、Confirm/cancel两个阶段,每个阶段由业务代码控制,这样事务的锁力度可以完全自由控制。
需要注意的是,TCC事务和2pc的思想类似,但并不是2pc的实现,TCC不再是两阶段提交,而只是它对事务的提交/回滚是通过执行一段confirm/cancel业务逻辑来实现,并且也并没有
全局事务来把控整个事务逻辑。

posted on 2022-09-04 15:32 zhangshuaishuai 阅读(222) 评论(0) 收藏 举报

 浙公网安备 33010602011771号
浙公网安备 33010602011771号