

Android UVC Camera H.265帧序错乱问题
RK3588平台同时预览5路H265 4K摄像头,出现其中一路画面卡死异常,从log分析看出现了上层拿到的帧序乱了,先执行的uvc_video_next_buffers 先写的1890 后写的1891,但是add tail on buffer queue 是先执行的1891 后执行的1890:

01-07 19:12:38.608 0 0 I KERNEL: : [ C0] ==>jake uvc_video_next_buffers queue:cap-00000000b2d4e786, index:2, frame:1890 01-07 19:12:38.608 0 0 D KERNEL: [ C0] uvcvideo: frame 1891 stats: 0/11/11 packets, 0/0/0 pts (!early !initial), 0/0 scr, last pts/stc/sof 0/0/0,dev pid = 0xcb 01-07 19:12:38.608 0 0 D KERNEL: [ C0] uvcvideo: Frame complete (EOF found). 01-07 19:12:38.608 0 0 I KERNEL: : [ C0] ==>jake uvc_video_next_buffers queue:cap-00000000b2d4e786, index:3, frame:1891 01-07 19:12:38.608 4397 4397 I KERNEL: videobuf2_common: [cap-00000000b2d4e786] vb2_buffer_done: done processing on buffer queue:cap-00000000b2d4e786, index:3, state: done, seq:1891 01-07 19:12:38.608 4397 4397 I KERNEL: videobuf2_common: [cap-00000000b2d4e786] vb2_buffer_done: add tail on buffer queue:cap-00000000b2d4e786 index:3, state: done, seq:1891 01-07 19:12:38.608 4377 4377 D KERNEL: uvcvideo: uvc_v4l2_poll 01-07 19:12:38.608 4377 4377 I KERNEL: uvcvideo: ==>jake uvc_ioctl_dqbuf(804) uvc_ioctl_dqbuf queue:cap-00000000b2d4e786, index:0 sequence:0. 01-07 19:12:38.608 4377 4377 I KERNEL: videobuf2_common: [cap-00000000b2d4e786] vb2_core_dqbuf: returning done buffer 01-07 19:12:38.608 4377 4377 I KERNEL: videobuf2_common: [cap-00000000b2d4e786] vb2_core_dqbuf: dqbuf of buffer 3, state: dequeued 01-07 19:12:38.608 4377 4377 I KERNEL: uvcvideo: ==>jake uvc_ioctl_dqbuf(807) uvc_ioctl_dqbuf queue:cap-00000000b2d4e786, index:3 sequence:1891. 01-07 19:12:38.608 404 404 I KERNEL: videobuf2_common: [cap-00000000b2d4e786] vb2_buffer_done: done processing on buffer queue:cap-00000000b2d4e786, index:2, state: done, seq:1890 01-07 19:12:38.608 404 404 I KERNEL: videobuf2_common: [cap-00000000b2d4e786] vb2_buffer_done: add tail on buffer queue:cap-00000000b2d4e786 index:2, state: done, seq:1890 01-07 19:12:38.609 4377 4377 D KERNEL: uvcvideo: uvc_v4l2_mmap 01-07 19:12:38.609 4377 4377 I KERNEL: videobuf2_common: [cap-00000000b2d4e786] vb2_mmap: buffer 3, plane 0 successfully mapped 01-07 19:12:38.610 4377 4377 D KERNEL: uvcvideo: uvc_v4l2_poll 01-07 19:12:38.610 4377 4377 I KERNEL: uvcvideo: ==>jake uvc_ioctl_dqbuf(804) uvc_ioctl_dqbuf queue:cap-00000000b2d4e786, index:0 sequence:0. 01-07 19:12:38.610 4377 4377 I KERNEL: videobuf2_common: [cap-00000000b2d4e786] vb2_core_dqbuf: returning done buffer 01-07 19:12:38.610 4377 4377 I KERNEL: videobuf2_common: [cap-00000000b2d4e786] vb2_core_dqbuf: dqbuf of buffer 2, state: dequeued 01-07 19:12:38.610 4377 4377 I KERNEL: uvcvideo: ==>jake uvc_ioctl_dqbuf(807) uvc_ioctl_dqbuf queue:cap-00000000b2d4e786, index:2 sequence:1890.
而Camera HAL层从驱动video buffer队列中取到的帧序也对应错乱,先拿到了1891帧后是1890帧:
01-07 19:12:36.987 437 677 E ExtCamDevSsn@3.4: dequeueV4l2FrameLocked(4949) done. mCameraId:107 index:0, sequence:1888 01-07 19:12:37.020 437 677 E ExtCamDevSsn@3.4: dequeueV4l2FrameLocked(4949) done. mCameraId:107 index:1, sequence:1889 01-07 19:12:37.096 437 4377 E ExtCamDevSsn@3.4: dequeueV4l2FrameLocked(4949) done. mCameraId:107 index:3, sequence:1891 01-07 19:12:37.098 437 4377 E ExtCamDevSsn@3.4: dequeueV4l2FrameLocked(4949) done. mCameraId:107 index:2, sequence:1890 01-07 19:12:37.120 437 4377 E ExtCamDevSsn@3.4: dequeueV4l2FrameLocked(4949) done. mCameraId:107 index:0, sequence:1892 01-07 19:12:37.156 437 4378 E ExtCamDevSsn@3.4: dequeueV4l2FrameLocked(4949) done. mCameraId:107 index:1, sequence:1893 01-07 19:12:37.186 437 4358 E ExtCamDevSsn@3.4: dequeueV4l2FrameLocked(4949) done. mCameraId:107 index:2, sequence:1894
而平台的解码库对错序帧无法处理报异常,导致预览画面卡死。为什么驱动层的video buffer不是按顺序处理?这里引出Linux的内核工作队列---workqueue。
学习资料参考:https://www.modb.pro/db/236435 博主LinuxKernelStudy 此系列文章讲述了Linux内核从 task-queue 到 keventd/events 再到 CMWQ(Concurrency Managed Workqueue)的演变过程。
先看看启动摄像头预览时uvc驱动代码(uvc_driver.c)中创建工作队列的方式(alloc_workqueue):
static struct uvc_streaming *uvc_stream_new(struct uvc_device *dev, ¦ struct usb_interface *intf) { struct uvc_streaming *stream; stream = kzalloc(sizeof(*stream), GFP_KERNEL); if (stream == NULL) return NULL; mutex_init(&stream->mutex); stream->dev = dev; stream->intf = usb_get_intf(intf); stream->intfnum = intf->cur_altsetting->desc.bInterfaceNumber; /* Allocate a stream specific work queue for asynchronous tasks. */ stream->async_wq = alloc_workqueue("uvcvideo", WQ_UNBOUND | WQ_HIGHPRI, 0); //创建的队列是多线程并发执行
if (!stream->async_wq) { uvc_stream_delete(stream); return NULL; } return stream; }
alloc_workqueue("uvcvideo", WQ_UNBOUND | WQ_HIGHPRI, 0); //第一个参数是task名,第二个参数是工作队列flags,第三个参数是max_active:代表该队列最大并发处理work项的数目,0代表默认=256。
工作队列flags说明:
WQ_UNBOUND:指明wq为unbound队列,不会绑定到固定cpu上,可以在允许的cpu核上运行,可以通过taskset -p pid查看允许在哪些cpu核上运行。
WQ_MEM_RECLAIM:创建wq时会创建一个救援线程,nice=-20,常驻后台。
WQ_FREEZABLE:队列可以被冻结,用于CONFIG_FREEZER配置。
WQ_HIGHPRI:高优先级队列。nice=-20
WQ_CPU_INTENSIVE:队列定义为CPU消耗型。
WQ_SYSFS:在sysfs下创建wq设备节点。
WQ_POWERER_EFFICIENT:队列节能特性,表现为UNBOUND。
通过taskset -p 查看当前uvcvideo的内核线程affinity mask都是0xff (mask是二进制,0xff是8位均为1的bitmask,表示可在8个核上跑。如果是0xf0即高4位为1,一般代表是可在4个大核上跑):
1 2 3 4 5 6 7 8 9 | pid 3353's current affinity mask: ffribeye:/ # taskset -p 3355pid 3355's current affinity mask: ffribeye:/ # taskset -p 3352pid 3352's current affinity mask: ffribeye:/ # taskset -p 3350pid 3350's current affinity mask: ffribeye:/ # taskset -p 3347pid 3347's current affinity mask: ff |
以上可知默认创建的workqueue是运行在多核cpu,允许在多个cpu之间调度(WQ_UNBOUND)。而且每个cpu核上还会动态创建多个worker(max_active=0或大于1),也就是当前workqueue最多在每个cpu上并发的线程数。所以回到帧错序的问题,就可以理解在多核间调度、多线程处理时,会有几率发生其中某一帧会比前一帧先被处理,也就是1890和1891两帧很有可能不在同一个核上处理,而1891帧所在的核可能就是大核或者没1890帧所在核那么忙,所以1891帧更快的被处理入队,被上层取走。
那怎么处理多线程的并发问题?使用create_singlethread_workqueue!
如何理解create_singlethread_workqueue是严格按照顺序执行的?参考资料:https://blog.csdn.net/zhuyong006/article/details/83024889
通过资料可知create_singlethread_workqueue方法其实就是alloc_workqueue的封装,flags不一样:

参考create_singlethread_workqueue方法,修改alloc_workqueue的flags参数,让work能按顺序执行:
--- a/kernel-5.10/drivers/media/usb/uvc/uvc_driver.c +++ b/kernel-5.10/drivers/media/usb/uvc/uvc_driver.c @@ -490,8 +490,12 @@ static struct uvc_streaming *uvc_stream_new(struct uvc_device *dev, stream->intfnum = intf->cur_altsetting->desc.bInterfaceNumber; /* Allocate a stream specific work queue for asynchronous tasks. */ - stream->async_wq = alloc_workqueue("uvcvideo", WQ_UNBOUND | WQ_HIGHPRI, - 0); +// stream->async_wq = alloc_workqueue("uvcvideo", WQ_UNBOUND | WQ_HIGHPRI, +// 0); + stream->async_wq = alloc_workqueue("uvcvideo", WQ_UNBOUND + | WQ_HIGHPRI | __WQ_ORDERED | __WQ_ORDERED_EXPLICIT + | __WQ_LEGACY | WQ_MEM_RECLAIM , + 1); if (!stream->async_wq) { uvc_stream_delete(stream); return NULL;
注:内核对workqueue设置__WQ_ORDERED标记,并且设置max_active=1代表是按顺序执行。
另外从alloc_workqueue代码实现还可以看到如果是WQ_UNBOUND 且 max_active=1 也会按顺序执行:
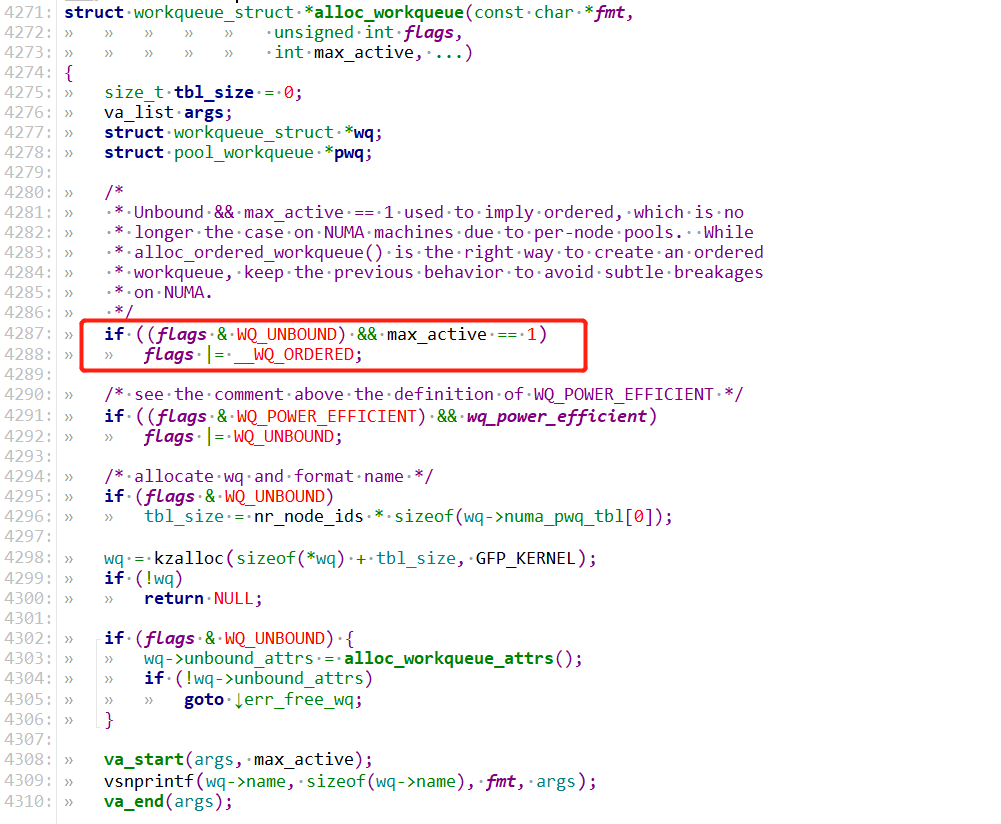
修改workqueue为单线程按顺序执行后,再测试验证Camera 5路同时预览时H265 video帧就不会错序了~
附个Elecard HEVC Analyzer查看的h265码流图:

posted on 2023-01-13 19:29 sheldon_blogs 阅读(804) 评论(0) 编辑 收藏 举报


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
2021-01-13 Android 9.0 导入GMS组件及Google Play Store