软工实践寒假作业(2/2)
软件工程实践寒假作业(2/2)
| 这个作业属于哪个课程 | 2020春s班 |
|---|---|
| 这个作业要求在哪里 | 寒假作业(2/2) |
| 这个作业的目标 | 新型冠状病毒疫情统计 |
| 作业正文 | 软件工程实践2020第一次作业 |
| 其他参考文献 | 知乎, csdn相关问题 |
part1. Github仓库
本次代码和测试数据所在仓库:仓库地址
part2.PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 35 | 50 |
| Estimate | 估计这个任务需要多少时间 | 50 | 40 |
| Development | 开发 | 600 | 700 |
| Analysis | 需求分析 (包括学习新技术) | 40 | 35 |
| Design Spec | 生成设计文档 | 20 | 20 |
| Design Review | 设计复审 | 20 | 25 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 15 | 20 |
| Design | 具体设计 | 20 | 25 |
| Coding | 具体编码 | 400 | 450 |
| Code Review | 代码复审 | 60 | 90 |
| Test | 测试(自我测试,修改代码,提交修改) | 50 | 40 |
| Reporting | 报告 | 40 | 50 |
| Test Repor | 测试报告 | 20 | 25 |
| Size Measurement | 计算工作量 | 30 | 40 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 50 | 60 |
| 合计 | 800 | 900 |
part3.解题思路
首先要理清这次作业的要求,就是先把相关日期的疫情变化情况写进日志文件。然后读取日志文件统计疫情情况。最后
根据输入的选项,按要求读取文件内的具体信息,存入指定文件。其实就是文件读写问题。
因为下学期要学习Java部分内容,所以代码语言的话这里也用了Java来完成这次作业。
一个省出现的病情一共有四种,分别为感染患者,疑似患者,治愈和死亡。这几种病况是会发生变化或者转换的,一个
日志文件中会出现一下几种情况:
该日志中出现以下几种情况:
1、<省> 新增 感染患者 n人
2、<省> 新增 疑似患者 n人
3、<省1> 感染患者 流入 <省2> n人
4、<省1> 疑似患者 流入 <省2> n人
5、<省> 死亡 n人
6、<省> 治愈 n人
7、<省> 疑似患者 确诊感染 n人
8、<省> 排除 疑似患者 n人
关于各种病况人数变化的详细描述如下:
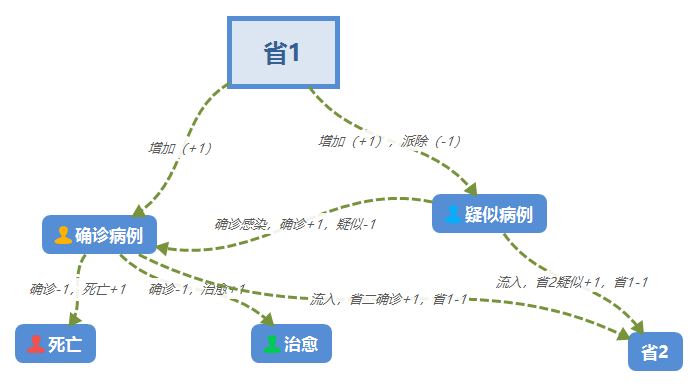
关于日志文件得先规则的排好,一行储存一个省份变化信息存储格式如下所示:

这是为了方便文件读取。
然后是要解决按要求读取文件信息的问题,根据指令读出文件信息,再将信息排序号,写进指定文档,文档每一行位一个省份信息。
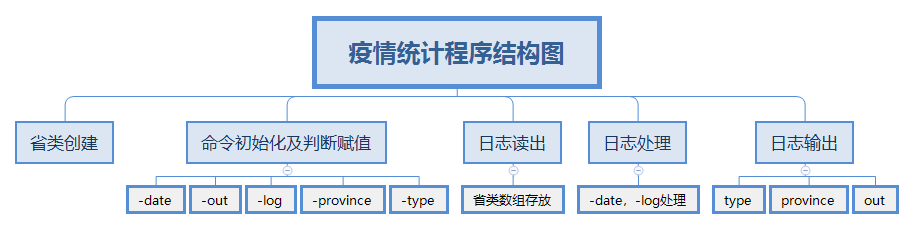
part4.设计实现过程
结构图:
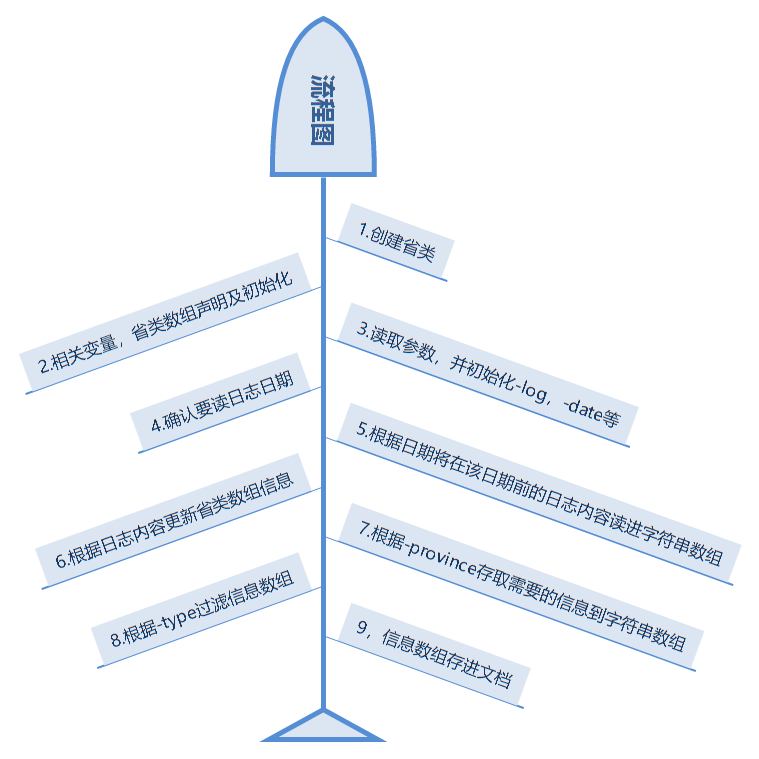
流程图:
part5.代码说明
province类(省名,确诊,疑似,死亡,治愈人数):
class Provin {
String name;// 省名
int ip;// 确诊人数
int sp;// 疑似人数
int cure;// 治愈人数
int death;// 死亡人数
public Provin(String name) {
this.name = name;
ip = 0;
sp = 0;
cure = 0;
death = 0;
}
}
命令参数处理:
if (request.equals("list")) {
// System.out.println(args[0]);
for (int i = 0; i < args.length; i++) {
if (args[i].equals("-date"))
date = args[i + 1];
else if (args[i].equals("-log"))
path = args[i + 1];
else if (args[i].equals("-out"))
output = args[i + 1];
else if (args[i].equals("-province")) {
for (int k = i + 1; k < args.length; k++) {
if (isChinese(args[k])) {
if (args[k].equals("全国"))
allctry = args[k];
else {
prvin[pnum] = args[k];
pnum++;
}
}
}
}
else if (args[i].equals("-type")) {
for (int k = i + 1; k < args.length; k++) {
if (args[k].equals("ip")) {
types[tnum] = "感染";
tnum++;
}
else if (args[k].equals("sp")) {
types[tnum] = "疑似";
tnum++;
}
else if (args[k].equals("cure")) {
types[tnum] = "治愈";
tnum++;
}
else if (args[k].equals("death")) {
types[tnum] = "死亡";
tnum++;
}
}
}
}
}
else {
System.out.println("input the ritght request");
System.exit(1);
}
if (output == null || path == null) {
System.out.println("input the ritght request");
System.exit(1);
}
读取日志文件:
FileInputStream f1 = new FileInputStream(path + ss[ss.length - 1 - ki]);
InputStreamReader reader = new InputStreamReader(f1, "UTF-8");
BufferedReader bf = new BufferedReader(reader);
BufferedReader bf2 = new BufferedReader(reader);
String str = null;
// String[] line = new String[8];
// num = 0;
while ((str = bf.readLine()) != null) {
line[num] = str;
// System.out.println(str);
num++;
}
更新省类数组信息:
for (int k = 0; k < num; k++) {
String[] as = line[k].split(" ");
if (as[1].equals("新增")) {
String mes = as[0];
if (as[2].equals("感染患者")) {
int ki = 0;
String coun = as[3].substring(0, as[3].length() - 1);
int count = Integer.parseInt(coun);
for (ki = 0; ki < 34; ki++) {
if (provinces[ki].name.equals(mes)) {
provinces[ki].ip += count;
break;
}
}
}
else if (as[2].equals("疑似患者")) {
int ki = 0;
String coun = as[3].substring(0, as[3].length() - 1);
int count = Integer.parseInt(coun);
for (ki = 0; ki < 34; ki++) {
if (provinces[ki].name.equals(mes)) {
provinces[ki].sp += count;
break;
}
}
}
}
else if (as.length==3) {
String coun = as[2].substring(0, as[2].length() - 1);
int count = Integer.parseInt(coun);
for (int ki = 0; ki < 34; ki++) {
if (provinces[ki].name.equals(as[0])) {
if(as[1].equals("死亡"))
provinces[ki].death += count;
else
provinces[ki].cure += count;
provinces[ki].ip -= count;
break;
}
}
}
else if (as[1].equals("排除")) {
String coun = as[3].substring(0, as[3].length() - 1);
int count = Integer.parseInt(coun);
for (int ki = 0; ki < 34; ki++) {
if (provinces[ki].name.equals(as[0])) {
provinces[ki].sp -= count;
break;
}
}
}
if (as[2].equals("流入")) {
int num1 = 0;
String coun = as[4].substring(0, as[4].length() - 1);
int count = Integer.parseInt(coun);
for (int ki = 0; ki < 34; ki++) {
if (provinces[ki].name.equals(as[0])) {
if (as[1].equals("感染患者"))
provinces[ki].ip -= count;
else
provinces[ki].sp -= count;
num1++;
}
if (provinces[ki].name.equals(as[3])) {
if (as[1].equals("感染患者"))
provinces[ki].ip += count;
else
provinces[ki].sp += count;
num1++;
}
if (num1 == 2)
break;
}
}
根据type修改信息数组
// 指明类型的情况下
if (tnum != 0) {
// boolean flag=true;
String pr = "";
for (int j = 0; j < pcout; j++) {
String[] si = message[j].split(" ");
pr = "";
pr = pr + si[0] + " ";
for (int ji = 1; ji < si.length; ji++) {
boolean flag = true;
for (int ki = 0; ki < tnum; ki++) {
if (si[ji].contains(types[ki])) {
pr = pr + si[ji] + " ";
break;
}
}
}
message[j] = pr;
}
}
判中文,排序字符串数组函数
public static boolean isChinese(String string) {
int n = 0;
for (int i = 0; i < string.length(); i++) {
n = (int) string.charAt(i);
if (!(19968 <= n && n < 40869)) {
return false;
}
}
return true;
}
public static void arraySort(String[] input) {
for (int i = 0; i < input.length - 1; i++) {
for (int j = 0; j < input.length - i - 1; j++) {
if (input[j].compareTo(input[j + 1]) < 0) {
String temp = input[j];
input[j] = input[j + 1];
input[j + 1] = temp;
}
}
}
}
part6.单元测试截图和描述
测试1:
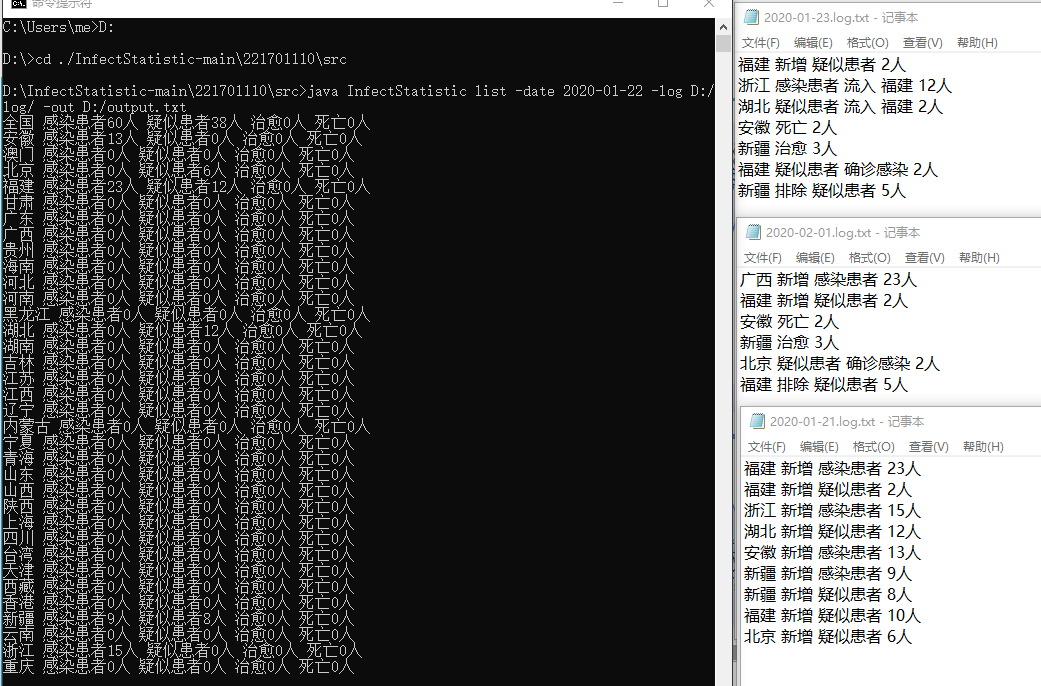

测试2:
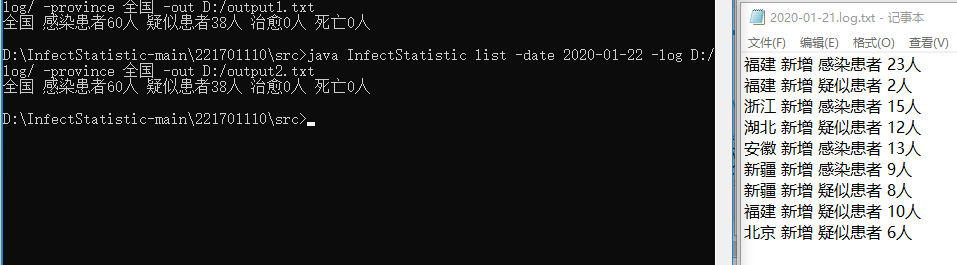
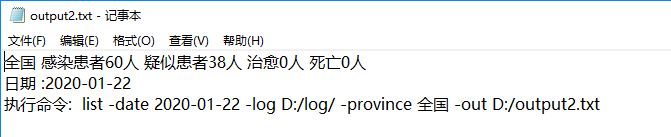
测试3:
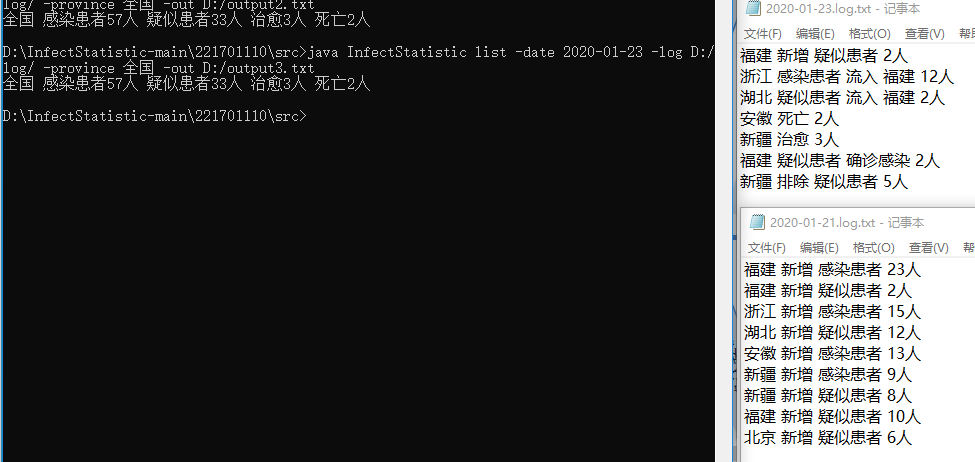
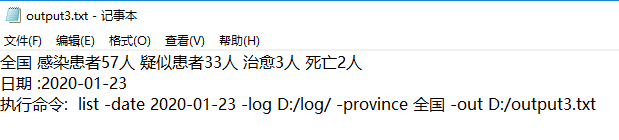
测试4:
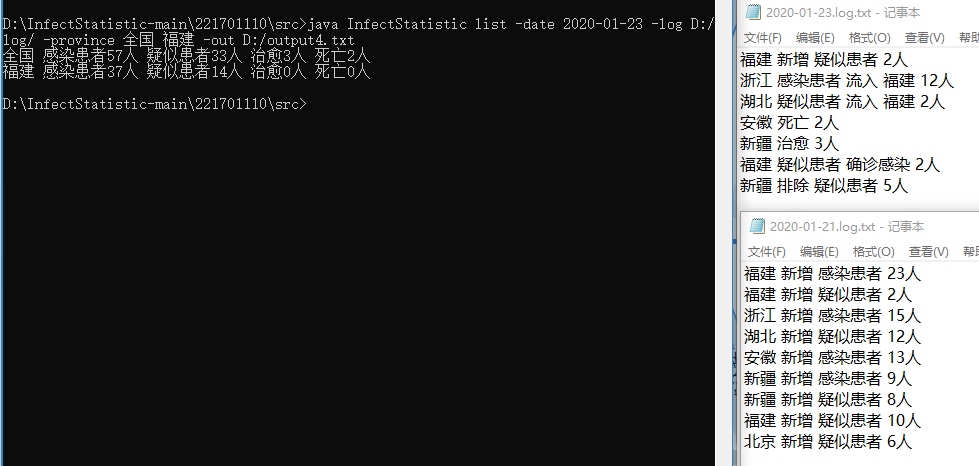
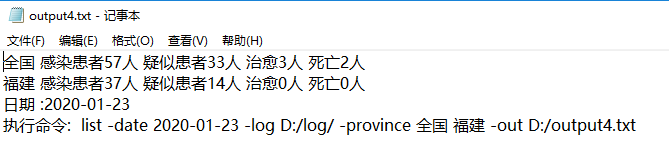
测试5:
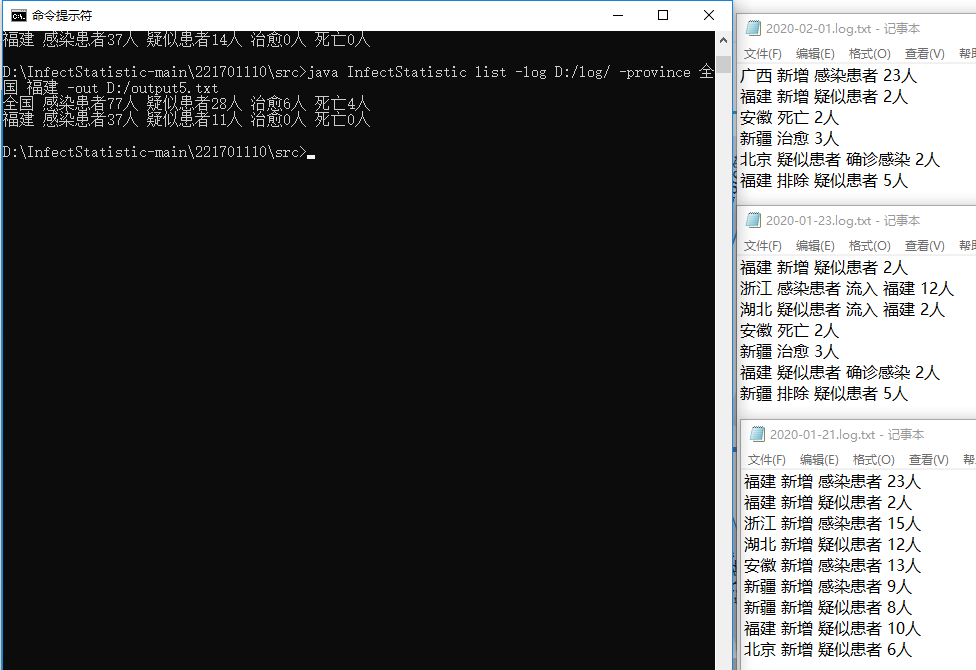

测试6:
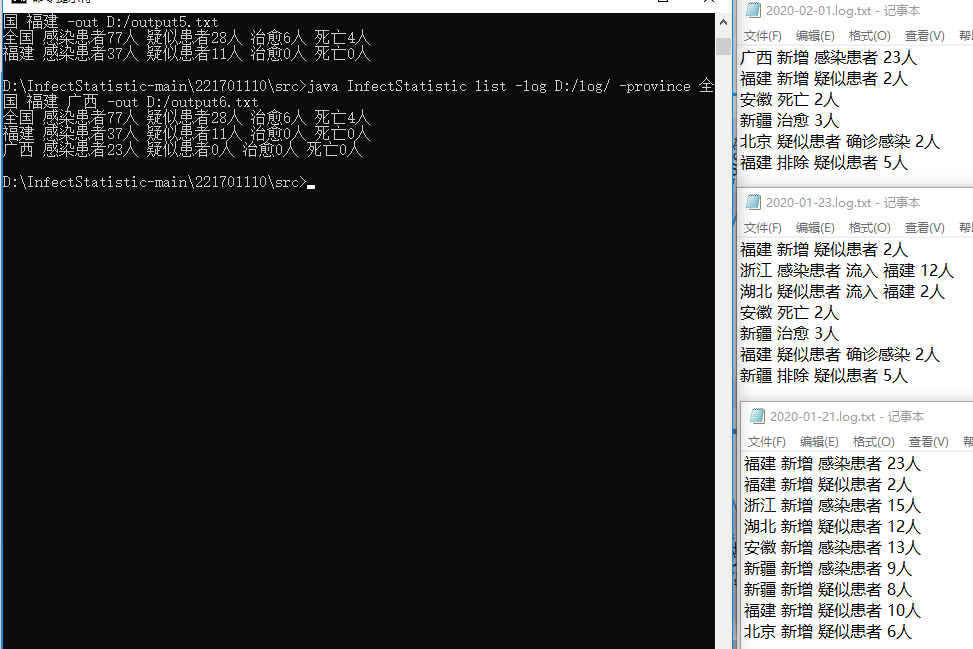

测试7:
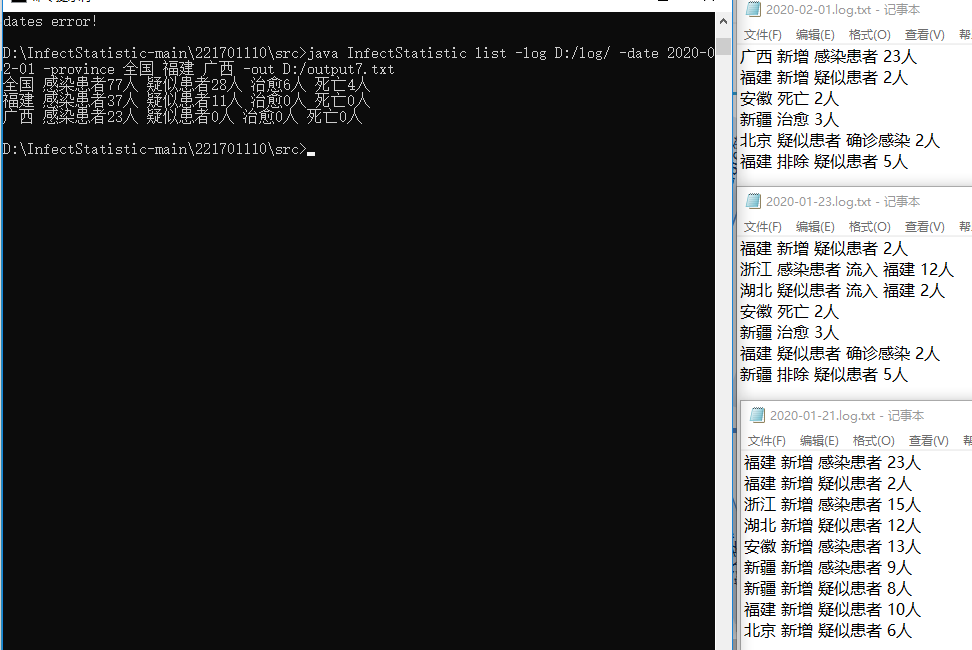
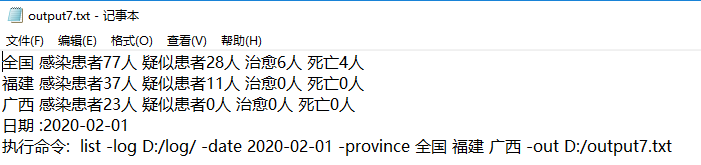
测试8:
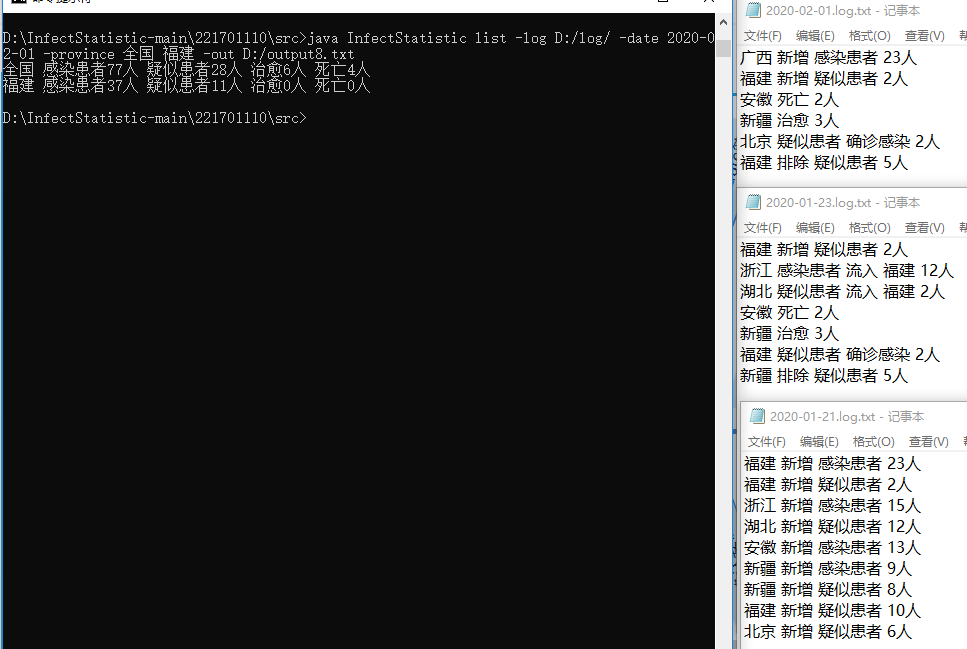
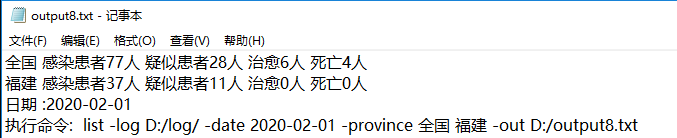
测试9:
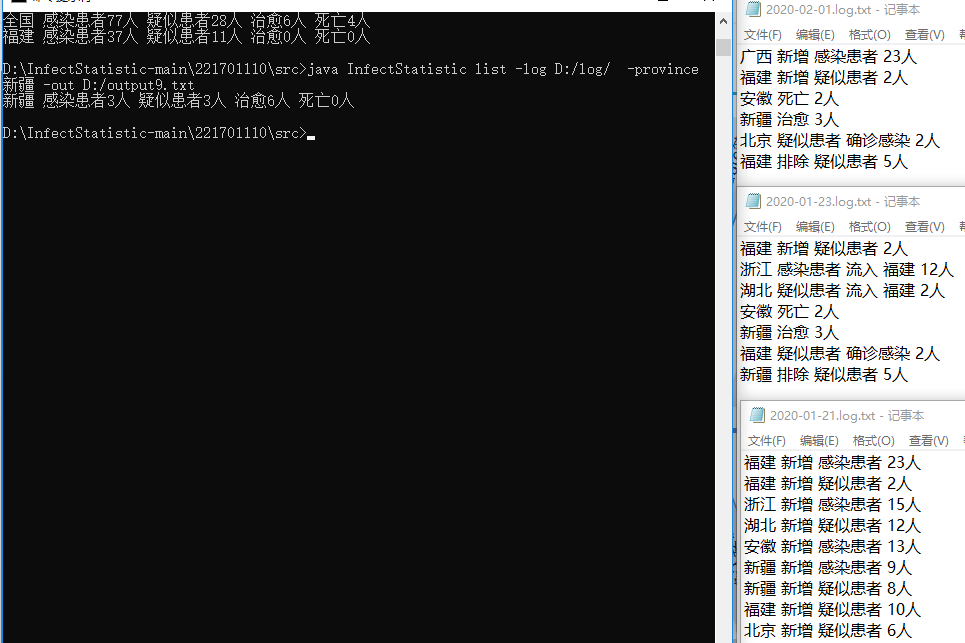
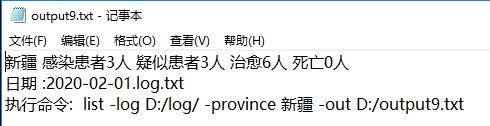
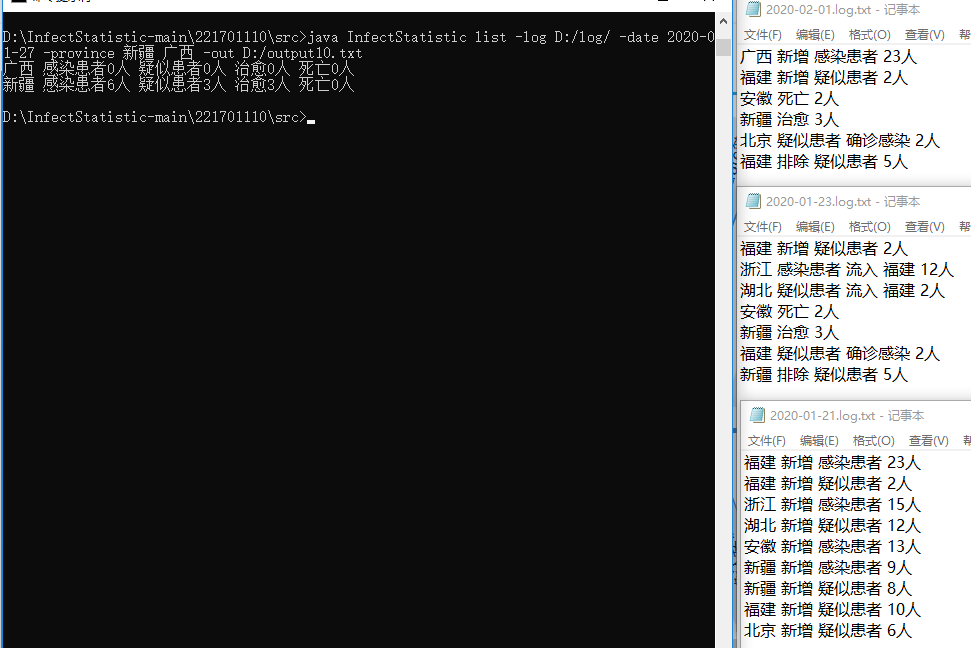
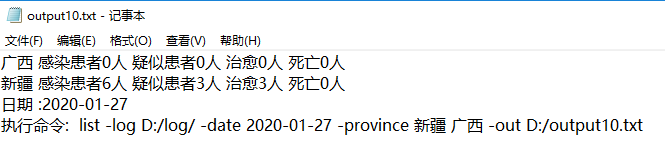
测试10:
part7.单元测试覆盖率优化和性能测试
执行命令:java InfectStatistic list -date 2020-01-22 -log D:/log/ -out D:/output.txt
修改前单元覆盖率:
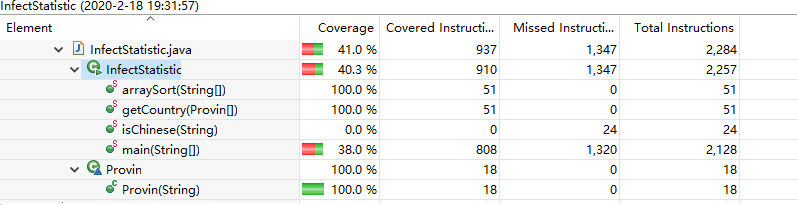
修改后:
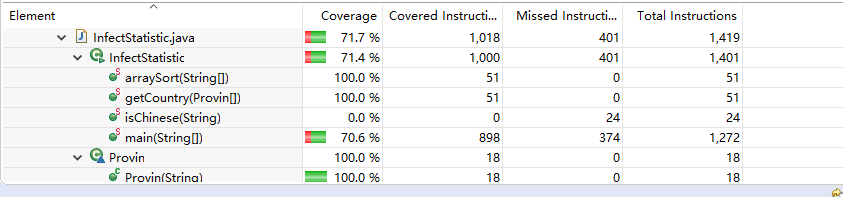
性能:
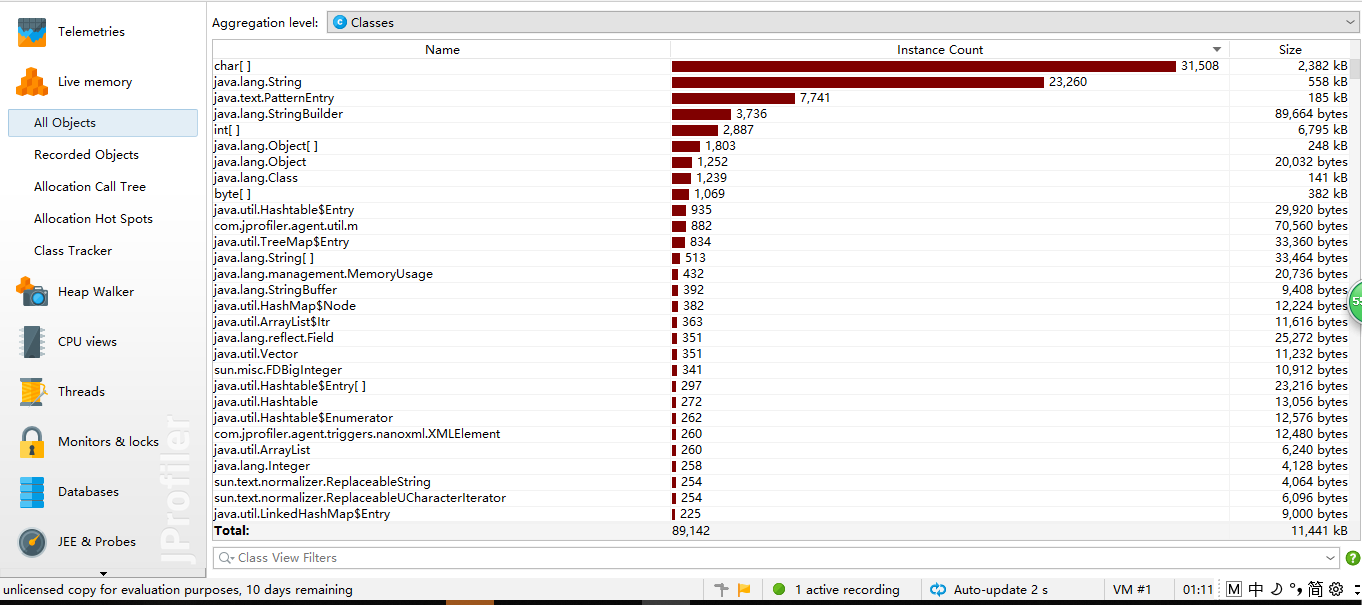
part8.代码规范
详见:Github仓库:codestyle.md
part9.心路历程
- 写代码时的坎坷
其实一开始拿到这个题目,真的很头疼,一时半会理解不了在干嘛。

- 收获
1.学会了Github地使用,包括创建仓库,fork,clone和代码的commit,push等操作
2.下载了Github Desktop,多学会了一门软件的使用
3.学会了利用eclipse统计单元覆盖率及下载和学习使用了Jprofile。
4.懂得了一个项目开发需要很大的工程量,需要提取做好需求分析工作。我们的代码应该尽可能地贴近需求,同时代码要
做到简略,即用最少的代码,花最小地内存去完成好的作品,不能就简简单单地为了完成任务。
part10.与技术路线图相关的五个仓库
1.Java学习+模式指南
链接:https://github.com/Snailclimb/JavaGuide
简介:涵盖大部分Java程序员所需要掌握的核心知识,无论新手老手都能学习接触,同时还提供面试技巧。
2.springboot指南
链接:https://github.com/Snailclimb/springboot-guide
提供spring的基础及进阶知识,,通过相应面试题,适合新手从零开始学习springboot。
3.Java设计模式
链接:https://github.com/iluwatar/java-design-patterns
简介:该站点展示了Java设计模式,在解决方案中可以通过高级描述或查看其源代码来浏览这些模式。
4.javaee8-samples
链接:https://github.com/javaee-samples/javaee8-samples
简介:该工作空间由Java EE 8示例和单元测试组成。它们分类在不同的目录中,每个目录用于每个Technology / JSR。
5.Apache Tomcat
链接:https://github.com/apache/tomcat
简介:Apache Tomcat软件为各种行业和组织中的众多大型,关键任务Web应用程序提供支持。
