K8s部署轻量级日志收集系统EFK(elasticsearch + filebeat + kibana)
K8s部署EFK(elasticsear + filebeat + kibana)日志收集
一.准备镜像
# 在本机拉取镜像
docker pull docker.elastic.co/elasticsearch/elasticsearch:7.17.2
docker pull docker.elastic.co/kibana/kibana:7.17.2
docker pull docker.elastic.co/beats/filebeat:7.17.2
# 对镜像重打标签 将${harbor_url}和${harbor_project}换成自己的harbor私服地址和目录
docker tag docker.elastic.co/elasticsearch/elasticsearch:7.17.2 ${harbor_url}/${harbor_project}/elasticsearch:7.17.2
docker tag docker.elastic.co/kibana/kibana:7.17.2 ${harbor_url}/${harbor_project}/kibana:7.17.2
docker tag docker.elastic.co/beats/filebeat:7.17.2 ${harbor_url}/${harbor_project}/filebeat:7.17.2
# 登陆自己的harbor服务器
docker login -u admin -p ${password} ${harbor_url}
# 上传至harbor仓库
docker push ${harbor_url}/${harbor_project}/elasticsearch:7.17.2
docker push ${harbor_url}/${harbor_project}/kibana:7.17.2
docker push ${harbor_url}/${harbor_project}/filebeat:7.17.2
此处的目的是避免某些服务器从docker外网仓库拉取不了镜像,从而导致pod一直运行不了,当然也可以不用这一步,可以直接使用官方的镜像地址
如果此处的Harbor目录是私有的,则需要在k8s集群中创建docker拉取harbor私库的密钥
# -n 后是指定的空间,根据自己的情况去更改,不加-n,默认是default空间,因为本次EFK安装在kube-system命名空间下,所以-n为kube-system。
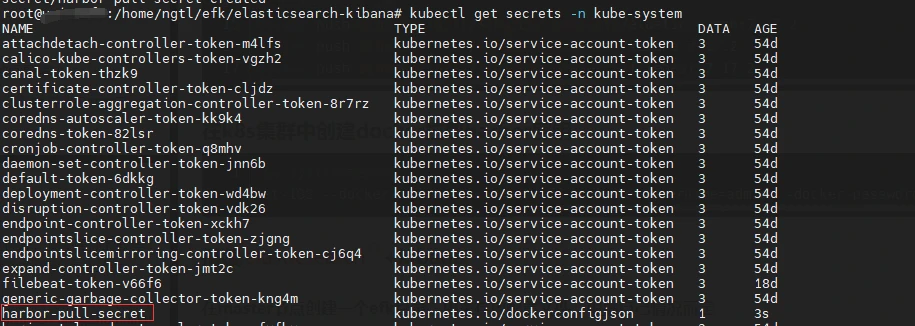
kubectl create secret docker-registry harbor-pull-secret --docker-server=${harbor_url} --docker-username=admin --docker-password=${password} -n kube-system
kube-system为集群默认存在的空间,不用手动创建
#检查密钥是否创建成功
kubectl get secrets -n kube-system
二.搭建Elasticsearch + kibana
1.在可执行kubectl命令的服务器准备安装的yml文件
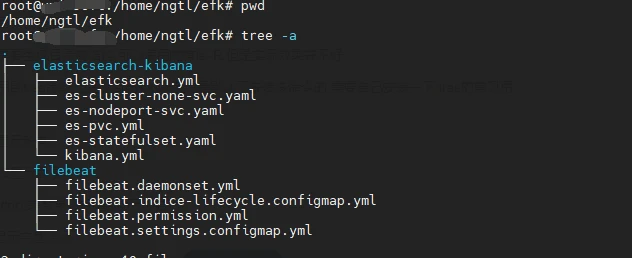
2.在elasticsearch-kibana目录下创建配置文件elasticsearch.yml
cluster.name: my-es
node.name: "node-1"
path.data: /usr/share/elasticsearch/data
#path.logs: /var/log/elasticsearch
bootstrap.memory_lock: false
network.host: 0.0.0.0
http.port: 9200
discovery.seed_hosts: ["127.0.0.1", "[::1]"]
cluster.initial_master_nodes: ["node-1"]
#增加参数,使head插件可以访问es
http.cors.enabled: true
http.cors.allow-origin: "*"
http.cors.allow-headers: Authorization,X-Requested-With,Content-Length,Content-Type
xpack.monitoring.collection.enabled: true
3.创建kibana配置文件kibana.yml
server.port: 5601
server.host: "0.0.0.0"
elasticsearch.hosts: "http://es-kibana-0.es-kibana.kube-system:9200"
kibana.index: ".kibana"
i18n.locale: "zh-CN"
monitoring.ui.elasticsearch.hosts: ["http://es-kibana-0.es-kibana.kube-system:9200"]
monitoring.ui.enabled: true
其中elasticsearch.hosts的地址构成为pod名:es-kibana-0,service名:es-kibana,命名空间:kube-system,以及service中配置的端口号9200
4.在k8s中创建elasticsearch和kibana的配置文件configmap
#在编写yml配置文件的目录执行该命令
kubectl create configmap es-config -n kube-system --from-file=elasticsearch.yml
kubectl create configmap kibana-config -n kube-system --from-file=kibana.yml
5.检查是否有StorageClass
kubectl get sc
#如下图所示是有StorageClass的

如果有则跳过第三步,没有则需要按照第三步配置NFS服务器
创建es存储pvc,pv配置文件:es-pvc.yaml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: es-pv-claim
namespace: kube-system
labels:
app: es
spec:
accessModes:
- ReadWriteMany
storageClassName: "nfs-storage"
resources:
requests:
storage: 20Gi
kubectl apply -f es-pvc.yaml
6.创建es-kibana的yaml配置文件: es-statefulset.yaml
apiVersion: apps/v1
kind: StatefulSet
metadata:
labels:
app: es-kibana
name: es-kibana
namespace: kube-system
spec:
replicas: 1
selector:
matchLabels:
app: es-kibana
serviceName: "es-kibana"
template:
metadata:
labels:
app: es-kibana
spec:
containers:
- image: [ Harbor私库地址 ]/elasticsearch:7.17.2
imagePullPolicy: IfNotPresent
name: elasticsearch
resources:
requests:
memory: "800Mi"
cpu: "800m"
limits:
memory: "1Gi"
cpu: "1000m"
volumeMounts:
- name: es-config
mountPath: /usr/share/elasticsearch/config/elasticsearch.yml
subPath: elasticsearch.yml
- name: es-persistent-storage
mountPath: /usr/share/elasticsearch/data
env:
- name: TZ
value: Asia/Shanghai
- image: [ Harbor私库地址 ]/kibana:7.17.2
imagePullPolicy: IfNotPresent
name: kibana
env:
- name: TZ
value: Asia/Shanghai
volumeMounts:
- name: kibana-config
mountPath: /usr/share/kibana/config/kibana.yml
subPath: kibana.yml
volumes:
- name: es-config
configMap:
name: es-config
- name: kibana-config
configMap:
name: kibana-config
- name: es-persistent-storage
persistentVolumeClaim:
claimName: es-pv-claim
#hostNetwork: true
#dnsPolicy: ClusterFirstWithHostNet
nodeSelector:
kubernetes.io/hostname: k8s-uni-node3
#创建pod
kubectl create -f es-statefulset.yaml
# 查看
kubectl get pod -o wide -n kube-system|grep es
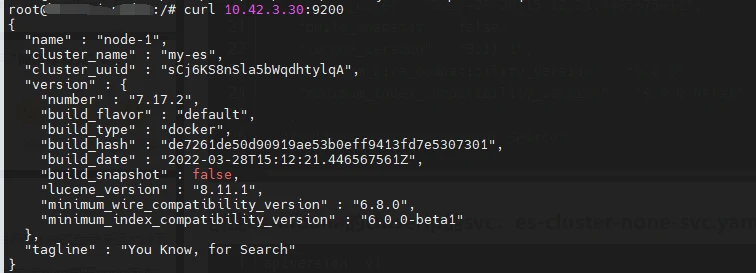
# 使用curl命令测试elasticsearch是否正常
kubectl get pod -o wide -n kube-system|grep es

然后在集群内部服务器上测试是否能通信
当然也可以在Rancher上查看pod是否运行成功
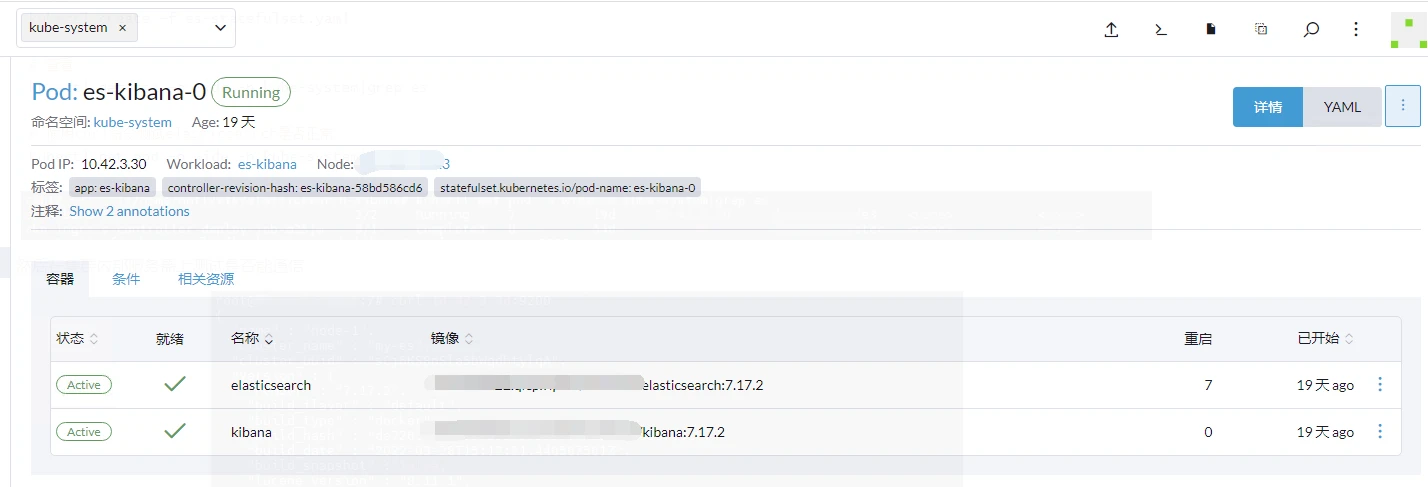
这个pod一次运行了两个容器,分别是kibanah和elasticsearch,并且把elasticsearch容器中的/usr/share/elasticsearch/data目录下的内容,挂载到了es-pv-claim下,我们可以在第三步中的NFS服务器共享目录中找到挂载的数据。

7.创建es-kibana cluserip的svc
vi es-cluster-none-svc.yaml
apiVersion: v1
kind: Service
metadata:
labels:
app: es-kibana
name: es-kibana
namespace: kube-system
spec:
ports:
- name: es9200
port: 9200
protocol: TCP
targetPort: 9200
- name: es9300
port: 9300
protocol: TCP
targetPort: 9300
clusterIP: None
selector:
app: es-kibana
type: ClusterIP
kubectl apply -f es-cluster-none-svc.yaml
这个配置文件描述了一个名为
es-kibana的 Kubernetes Service,该 Service 不分配 Cluster IP(ClusterIP: None),它会将流量路由到具有特定标签app: es-kibana的 Pod,这些 Pod 的端口 9200 和 9300 将被公开,并且可以通过相应的targetPort进行访问。用于集群内部访问
8.创建es-kibana的nodeport类型的svc
vi es-nodeport-svc.yaml
apiVersion: v1
kind: Service
metadata:
labels:
app: es-kibana
name: es-kibana-nodeport-svc
namespace: kube-system
spec:
ports:
- name: 9200-9200
port: 9200
protocol: TCP
targetPort: 9200
#nodePort: 9200
- name: 5601-5601
port: 5601
protocol: TCP
targetPort: 5601
#nodePort: 5601
selector:
app: es-kibana
type: NodePort
kubectl apply -f es-nodeport-svc.yaml
这个配置文件创建了一个名为 "es-kibana-nodeport-svc" 的 Kubernetes Service。该 Service 使用 NodePort 类型,允许从集群外部访问服务。Service 公开了两个端口,9200 和 5601,分别将流量路由到具有相应标签的 Pod 的对应端口。Pod 的选择基于标签
app: es-kibana。用于暴露端口,从集群外部访问es和kibana
外网暴露的端口是k8s随机分配的,有两种办法可以查看
#在服务器使用命令查看
kubectl get svc -n kube-system|grep es-kibana

Rancher上查看
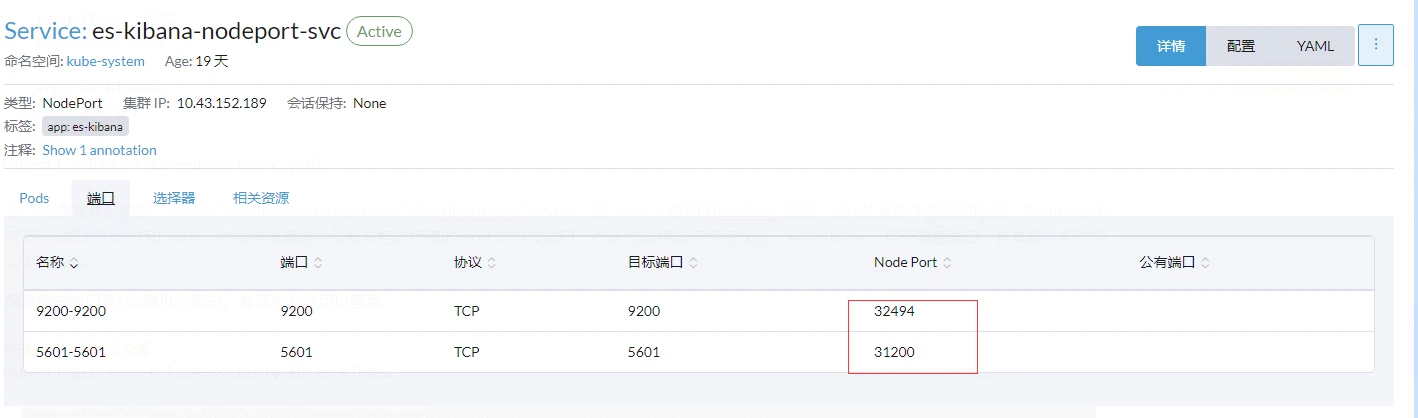
可以看到Kibana的端口为31200,然后就能使用nodeip+port访问
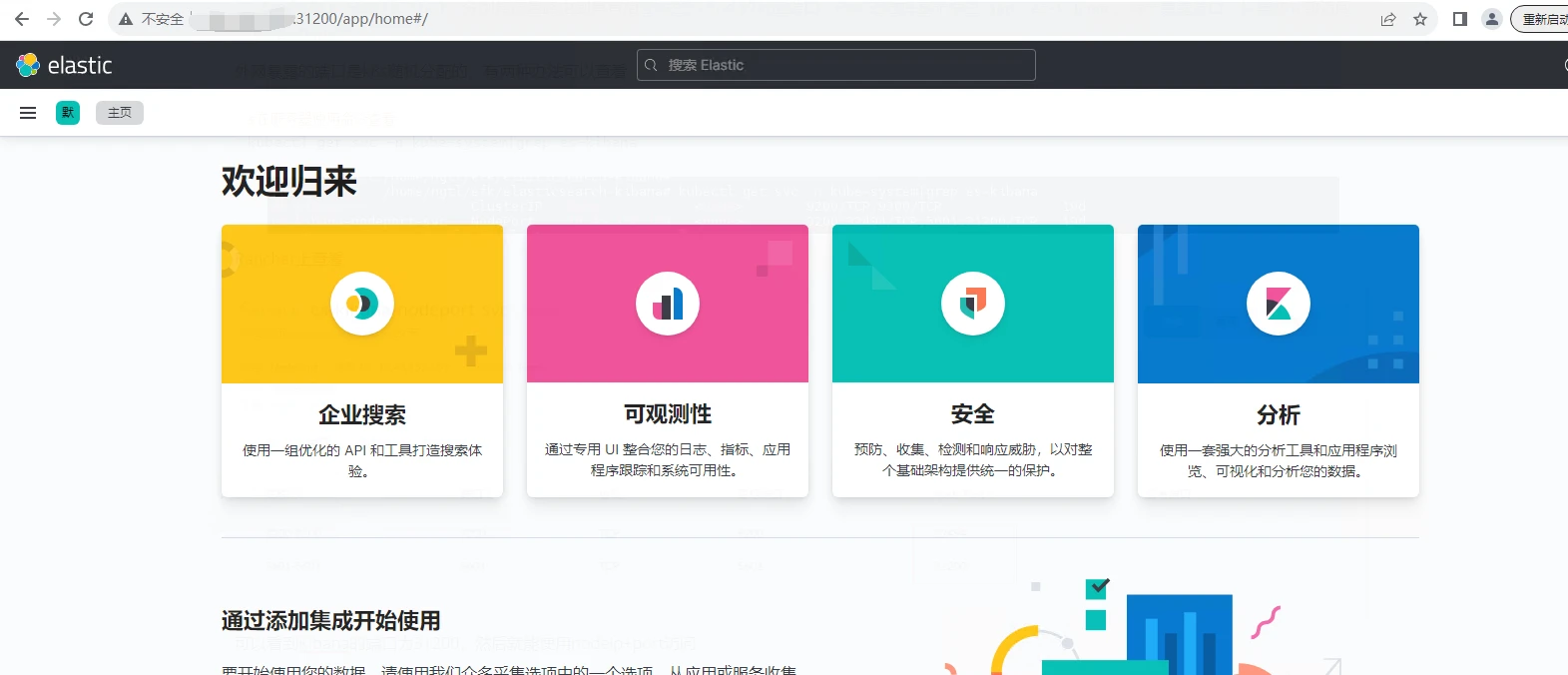
检查es是否注册上Kibana,点击侧边栏找到堆栈检测,然后点Nodes
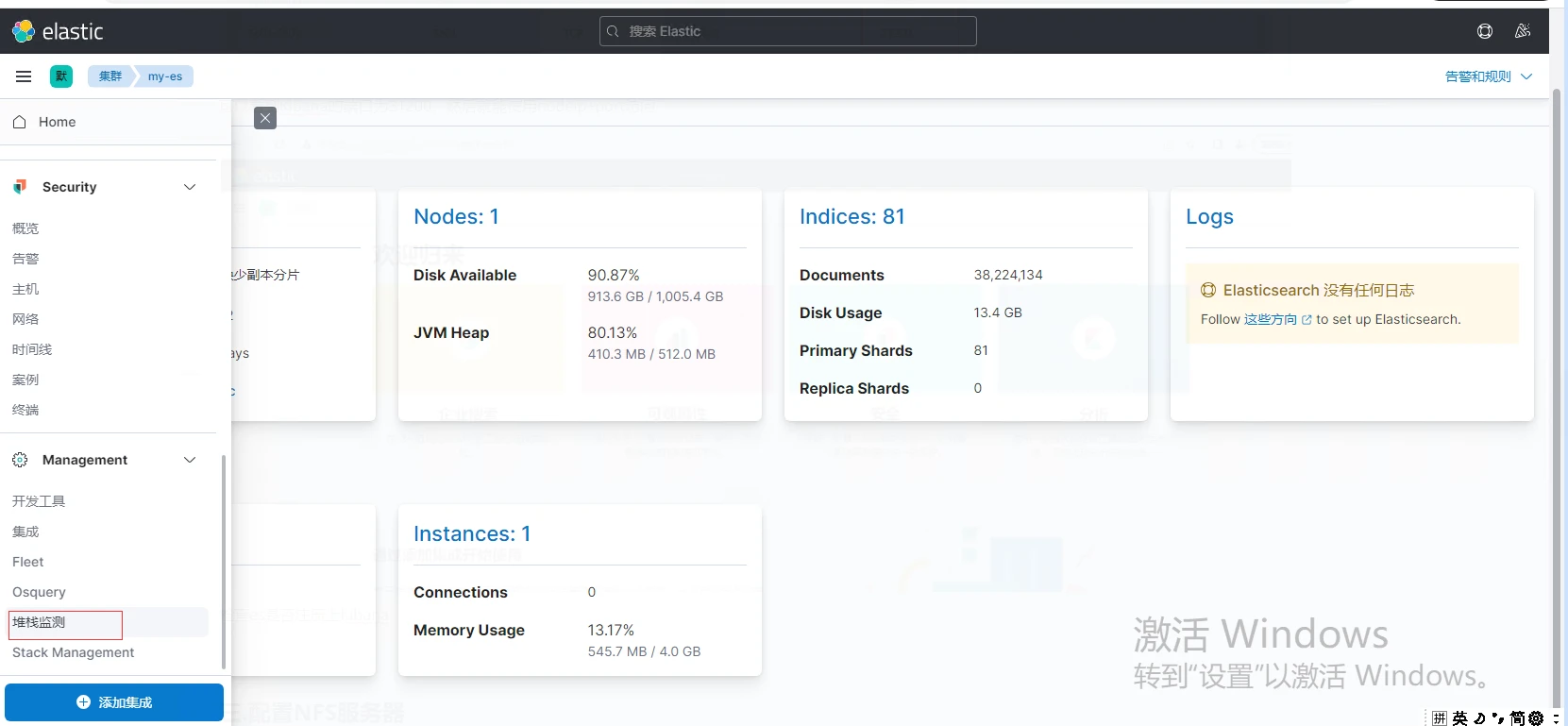
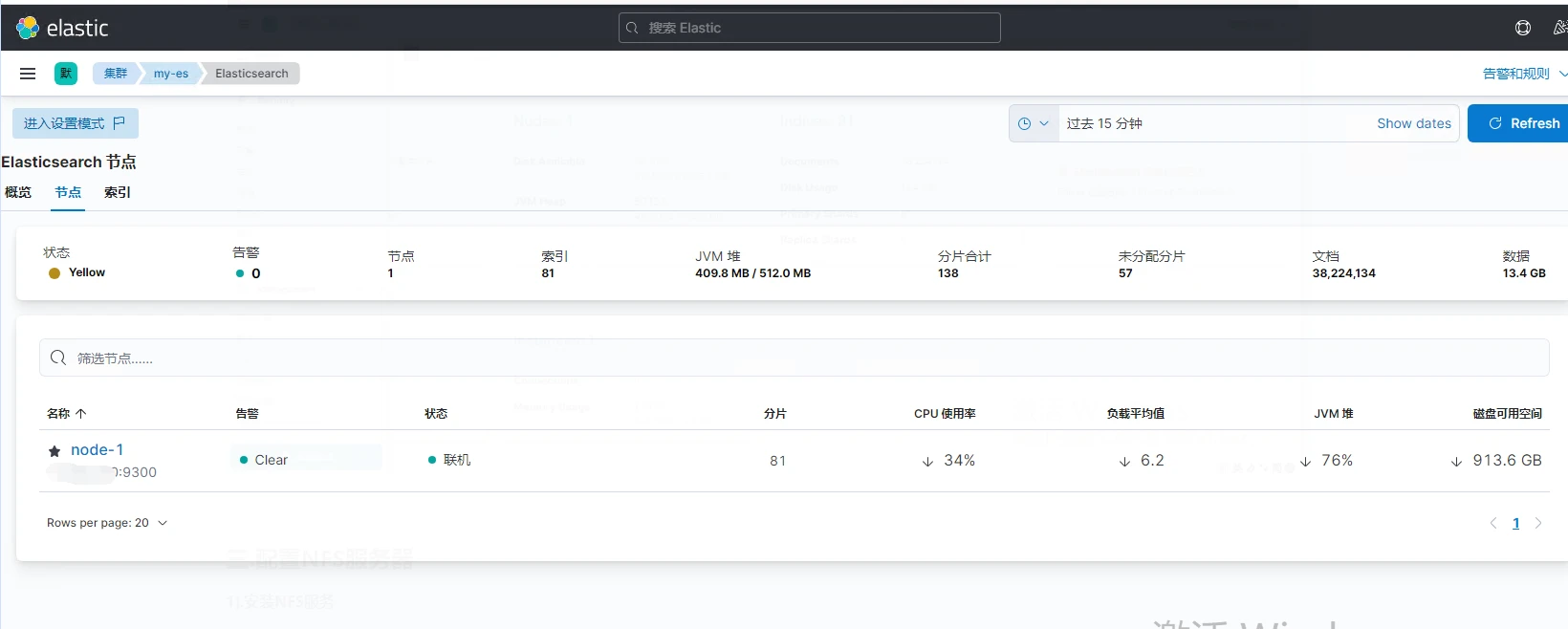
至此,Elasticsearch + kibana已经搭建完成,可以进行第四步。
三.配置NFS服务器
1).安装NFS服务
Ubuntu:
sudo apt update
sudo apt install nfs-kernel-server
Centos:
yum update
yum -y install nfs-utils
# 创建或使用用已有的文件夹作为nfs文件存储点
mkdir -p /home/data/nfs/share
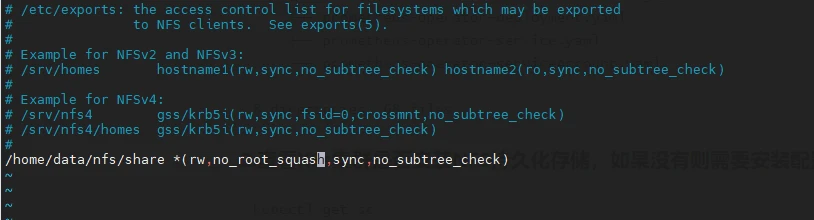
vi /etc/exports
写入如下内容
/home/data/nfs/share *(rw,no_root_squash,sync,no_subtree_check)
# 配置生效并查看是否生效
exportfs -r
exportfs

# 启动rpcbind、nfs服务
#Centos
systemctl restart rpcbind && systemctl enable rpcbind
systemctl restart nfs && systemctl enable nfs
#Ubuntu
systemctl restart rpcbind && systemctl enable rpcbind
systemctl start nfs-kernel-server && systemctl enable nfs-kernel-server
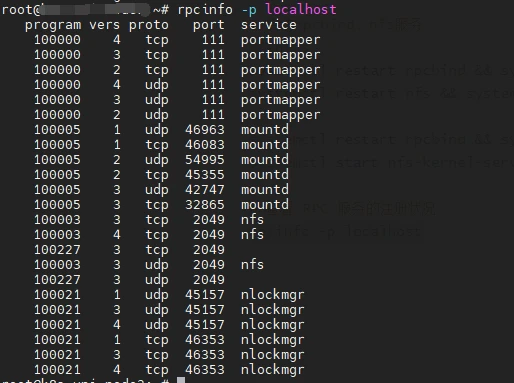
# 查看 RPC 服务的注册状况
rpcinfo -p localhost
# showmount测试
showmount -e localhost

以上都没有问题则说明安装成功
2).k8s注册nfs服务
新建storageclass-nfs.yaml文件,粘贴如下内容:
## 创建了一个存储类
apiVersion: storage.k8s.io/v1
kind: StorageClass #存储类的资源名称
metadata:
name: nfs-storage #存储类的名称,自定义
annotations:
storageclass.kubernetes.io/is-default-class: "true" #注解,是否是默认的存储,注意:KubeSphere默认就需要个默认存储,因此这里注解要设置为“默认”的存储系统,表示为"true",代表默认。
provisioner: k8s-sigs.io/nfs-subdir-external-provisioner #存储分配器的名字,自定义
parameters:
archiveOnDelete: "true" ## 删除pv的时候,pv的内容是否要备份
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: nfs-client-provisioner
labels:
app: nfs-client-provisioner
# replace with namespace where provisioner is deployed
namespace: default
spec:
replicas: 1 #只运行一个副本应用
strategy: #描述了如何用新的POD替换现有的POD
type: Recreate #Recreate表示重新创建Pod
selector: #选择后端Pod
matchLabels:
app: nfs-client-provisioner
template:
metadata:
labels:
app: nfs-client-provisioner
spec:
serviceAccountName: nfs-client-provisioner #创建账户
containers:
- name: nfs-client-provisioner
image: registry.cn-hangzhou.aliyuncs.com/lfy_k8s_images/nfs-subdir-external-provisioner:v4.0.2 #使用NFS存储分配器的镜像
volumeMounts:
- name: nfs-client-root #定义个存储卷,
mountPath: /persistentvolumes #表示挂载容器内部的路径
env:
- name: PROVISIONER_NAME #定义存储分配器的名称
value: k8s-sigs.io/nfs-subdir-external-provisioner #需要和上面定义的保持名称一致
- name: NFS_SERVER #指定NFS服务器的地址,你需要改成你的NFS服务器的IP地址
value: 192.168.0.0 ## 指定自己nfs服务器地址
- name: NFS_PATH
value: /home/data/nfs/share ## nfs服务器共享的目录 #指定NFS服务器共享的目录
volumes:
- name: nfs-client-root #存储卷的名称,和前面定义的保持一致
nfs:
server: 192.168.0.0 #NFS服务器的地址,和上面保持一致,这里需要改为你的IP地址
path: /home/data/nfs/share #NFS共享的存储目录,和上面保持一致
---
apiVersion: v1
kind: ServiceAccount #创建个SA账号
metadata:
name: nfs-client-provisioner #和上面的SA账号保持一致
# replace with namespace where provisioner is deployed
namespace: default
---
#以下就是ClusterRole,ClusterRoleBinding,Role,RoleBinding都是权限绑定配置,不在解释。直接复制即可。
kind: ClusterRole
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: nfs-client-provisioner-runner
rules:
- apiGroups: [ "" ]
resources: [ "nodes" ]
verbs: [ "get", "list", "watch" ]
- apiGroups: [ "" ]
resources: [ "persistentvolumes" ]
verbs: [ "get", "list", "watch", "create", "delete" ]
- apiGroups: [ "" ]
resources: [ "persistentvolumeclaims" ]
verbs: [ "get", "list", "watch", "update" ]
- apiGroups: [ "storage.k8s.io" ]
resources: [ "storageclasses" ]
verbs: [ "get", "list", "watch" ]
- apiGroups: [ "" ]
resources: [ "events" ]
verbs: [ "create", "update", "patch" ]
---
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: run-nfs-client-provisioner
subjects:
- kind: ServiceAccount
name: nfs-client-provisioner
# replace with namespace where provisioner is deployed
namespace: default
roleRef:
kind: ClusterRole
name: nfs-client-provisioner-runner
apiGroup: rbac.authorization.k8s.io
---
kind: Role
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: leader-locking-nfs-client-provisioner
# replace with namespace where provisioner is deployed
namespace: default
rules:
- apiGroups: [ "" ]
resources: [ "endpoints" ]
verbs: [ "get", "list", "watch", "create", "update", "patch" ]
---
kind: RoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: leader-locking-nfs-client-provisioner
# replace with namespace where provisioner is deployed
namespace: default
subjects:
- kind: ServiceAccount
name: nfs-client-provisioner
# replace with namespace where provisioner is deployed
namespace: default
roleRef:
kind: Role
name: leader-locking-nfs-client-provisioner
apiGroup: rbac.authorization.k8s.io
需要修改的就只有服务器地址和共享的目录
创建StorageClass
kubectl apply -f storageclass-nfs.yaml
# 查看是否存在
kubectl get sc

四.创建filebeat服务
1.创建filebeat主配置文件filebeat.settings.configmap.yml
vi filebeat.settings.configmap.yml
apiVersion: v1
kind: ConfigMap
metadata:
namespace: kube-system
name: filebeat-config
labels:
app: filebeat
data:
filebeat.yml: |-
filebeat.inputs:
- type: container
enabled: true
paths:
- /var/log/containers/*.log
include_lines: ['ERROR', 'WARN']
multiline:
pattern: ^\d{4}-\d{1,2}-\d{1,2}\s\d{1,2}:\d{1,2}:\d{1,2}
negate: true
match: after
processors:
- add_kubernetes_metadata:
in_cluster: true
host: ${NODE_NAME}
matchers:
- logs_path:
logs_path: "/var/log/containers/"
- add_cloud_metadata:
- add_kubernetes_metadata:
matchers:
- logs_path:
logs_path: "/var/log/containers/"
- add_docker_metadata:
output.elasticsearch:
hosts: ["http://[k8s节点ip]:32494"]
index: "filebeat-demo-%{[agent.version]}-%{+yyyy.MM.dd}"
setup.template.name: "filebeat-demo"
setup.template.pattern: "filebeat-demo-*"
setup.ilm.rollover_alias: "filebeat-demo"
setup.ilm:
policy_file: /etc/indice-lifecycle.json
#执行
kubectl apply -f filebeat.settings.configmap.yml
filebeat.inputs: 定义输入配置,这里配置了从容器日志中收集数据。
type: 定义输入类型为 container,表示从容器日志中收集数据。
enabled: 启用该输入配置。
paths: 指定要监视的日志文件路径,这里是容器日志路径。k8s容器的日志默认是保存在在服务器的/var/log/containers/下的。
multiline: 多行日志配置,用于将多行日志合并为单个事件。正则表示如果前面几个数字不是4个数字开头,那么就会合并到一行,解决Java堆栈错误日志收集问题
processors: 定义处理器,用于添加元数据。add_kubernetes_metadata:为日志事件添加 Kubernetes 相关的元数据信息,例如 Pod 名称、命名空间、标签等。
output.elasticsearch: 定义输出配置,将收集到的日志发送到 Elasticsearch。
hosts: 指定 Elasticsearch 节点的地址和端口。端口号为第二步安装es时,nodeport暴露的端口号。indices: 定义索引模式,这里以日期为后缀,创建每日索引。
setup.ilm: 配置索引生命周期管理 (ILM),用于管理索引的生命周期。
- policy_file:后面定义的是生命周期配置文件的地址
此处禁用了filebeat默认的索引格式。默认的索引格式为filebeat-%{[agent.version]}-%{+yyyy.MM.dd},在Kibana上呈现的就是filebeat-2023.10.21-000001这样的索引命名格式,而且默认的索引模板和索引生命周期都与index中设置的filebeat-demo-%{[agent.version]}-%{+yyyy.MM.dd}无关。故出现的问题就是我们所需的日志内容在索引filebeat-demo-%{[agent.version]}-%{+yyyy.MM.dd}中,但是并不能被准确分片和使用索引生命周期管理。
#相关模板字段意义
setup.template.name: “filebeat-demo” # 设置一个新的模板,模板的名称为filebeat-demo
setup.template.pattern: “filebeat-demo-*” # 模板匹配那些索引,这里表示以filebeat-demo开头的所有的索引
setup.ilm.rollover_alias: "filebeat-demo" #索引生命周期写别名。默认值为
filebeat-%{[agent.version]}。设置此选项将更改别名为filebeat-demo。用以滚动更新大索引文件的分片
同时该配置过滤了其他info级别的日志,只收集了'ERROR', 'WARN'级别的日志,相关配置:
include_lines: ['ERROR', 'WARN'] 该配置可根据实际使用情况进行删改
下图为,索引格式配置正确的示范截图:
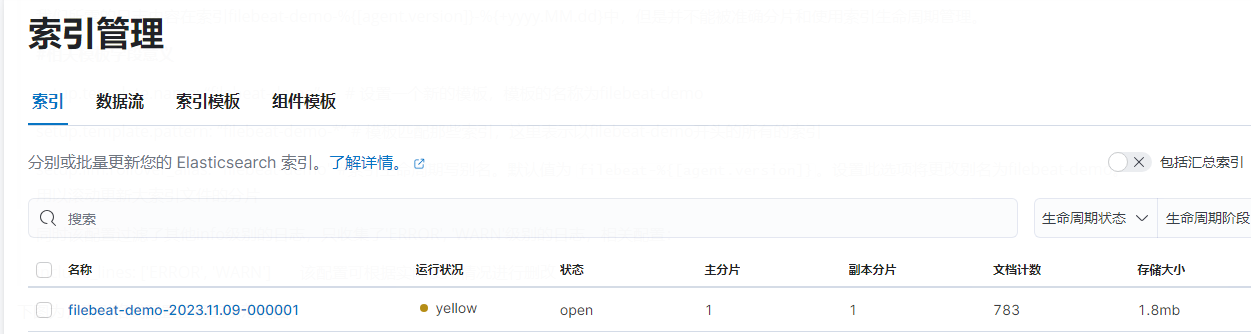
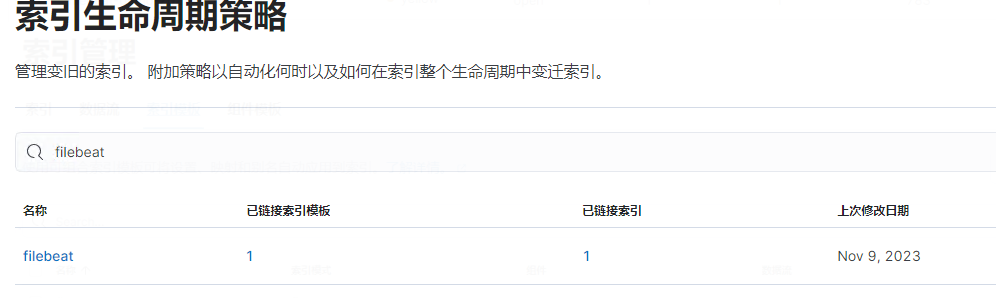
2.创建Filebeat索引生命周期策略配置文件
为了防止大量的数据存储,可以利用 indice 的生命周期来配置数据保留。 如下所示的文件中,配置成每天或每次超过5GB的时候就对 indice 进行轮转,并删除所有超过30天的 indice 文件。
vi filebeat.indice-lifecycle.configmap.yml
---
apiVersion: v1
kind: ConfigMap
metadata:
namespace: kube-system
name: filebeat-indice-lifecycle
labels:
app: filebeat
data:
indice-lifecycle.json: |-
{
"policy": {
"phases": {
"hot": {
"actions": {
"rollover": {
"max_size": "5GB" ,
"max_age": "1d"
}
}
},
"delete": {
"min_age": "30d",
"actions": {
"delete": {}
}
}
}
}
}
#执行
kubectl apply -f filebeat.indice-lifecycle.configmap.yml
3.Filebeat操作权限
vi filebeat.permission.yml
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: filebeat
rules:
- apiGroups: [ "" ]
resources:
- namespaces
- pods
- nodes
verbs:
- get
- watch
- list
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: filebeat
subjects:
- kind: ServiceAccount
name: filebeat
namespace: kube-system
roleRef:
kind: ClusterRole
name: filebeat
apiGroup: rbac.authorization.k8s.io
---
apiVersion: v1
kind: ServiceAccount
metadata:
namespace: kube-system
name: filebeat
#执行
kubectl apply -f filebeat.permission.yml
- ClusterRole:
- 作用:定义了一个 ClusterRole,它是一种权限集合,指定了 Filebeat 在集群范围内可以执行的操作,如获取(get)、监视(watch)、列出(list)等。
- 权限:
- 可以对命名空间执行 get、watch、list 操作。
- 可以对 Pod 执行 get、watch、list 操作。
- 可以对节点执行 get、watch、list 操作。
- ClusterRoleBinding:
- 作用:定义了一个 ClusterRoleBinding,将 ClusterRole (
filebeat) 绑定到特定的 ServiceAccount (filebeat)。- 意义:将 ClusterRole 与 ServiceAccount 绑定,以使 Filebeat 具有在 Kubernetes 中执行相应操作的权限。
- ServiceAccount:
- 作用:定义了一个 ServiceAccount (
filebeat),它是 Kubernetes 中用于身份验证和授权的实体。- 意义:创建了一个用于 Filebeat 的身份实体,使得 Filebeat 在 Kubernetes 中能够以其身份运行。
4.Filebeat Daemonset配置文件
vi filebeat.daemonset.yml
---
apiVersion: apps/v1
kind: DaemonSet
metadata:
namespace: kube-system
name: filebeat
labels:
app: filebeat
spec:
selector:
matchLabels:
app: filebeat
template:
metadata:
labels:
app: filebeat
spec:
serviceAccountName: filebeat
terminationGracePeriodSeconds: 30
containers:
- name: filebeat
image: [ Harbor私服地址 ]/filebeat:7.17.2
args: [
"-c", "/etc/filebeat.yml",
"-e",
]
env:
- name: NODE_NAME
valueFrom:
fieldRef:
fieldPath: spec.nodeName
securityContext:
runAsUser: 0
resources:
limits:
memory: 200Mi
requests:
cpu: 100m
memory: 100Mi
volumeMounts:
- name: config
mountPath: /etc/filebeat.yml
readOnly: true
subPath: filebeat.yml
- name: filebeat-indice-lifecycle
mountPath: /etc/indice-lifecycle.json
readOnly: true
subPath: indice-lifecycle.json
- name: data
mountPath: /usr/share/filebeat/data
- name: varlog
mountPath: /var/log
readOnly: true
- name: varlibdockercontainers
mountPath: /var/lib/docker/containers
readOnly: true
- name: dockersock
mountPath: /var/run/docker.sock
volumes:
- name: config
configMap:
defaultMode: 0600
name: filebeat-config
- name: filebeat-indice-lifecycle
configMap:
defaultMode: 0600
name: filebeat-indice-lifecycle
- name: varlog
hostPath:
path: /var/log
- name: varlibdockercontainers
hostPath:
path: /var/lib/docker/containers
- name: dockersock
hostPath:
path: /var/run/docker.sock
- name: data
hostPath:
path: /var/lib/filebeat-data
type: DirectoryOrCreate
#执行
kubectl apply -f filebeat.daemonset.yml
volumeMounts配置示意:
- name: config:
- 作用: 创建一个挂载点,将 ConfigMap 中的
filebeat.yml配置文件挂载到容器中的/etc/filebeat.yml路径。- readOnly: 设置为 true,表示只读访问该配置文件。
- name: filebeat-indice-lifecycle:
- 作用: 创建一个挂载点,将 ConfigMap 中的
indice-lifecycle.json文件挂载到容器中的/etc/indice-lifecycle.json路径。- readOnly: 设置为 true,表示只读访问该文件。
- name: data:
- 作用: 创建一个挂载点,将宿主机的
/var/lib/filebeat-data目录挂载到容器中的/usr/share/filebeat/data路径。- type: DirectoryOrCreate: 指定挂载类型为目录,如果该目录不存在则创建。
- name: varlog:
- 作用: 创建一个挂载点,将宿主机的
/var/log目录挂载到容器中的/var/log路径。- readOnly: 设置为 true,表示只读访问该目录。
- name: varlibdockercontainers:
- 作用: 创建一个挂载点,将宿主机的
/var/lib/docker/containers目录挂载到容器中的/var/lib/docker/containers路径。- readOnly: 设置为 true,表示只读访问该目录。
- name: dockersock:
- 作用: 创建一个挂载点,将宿主机的 Docker socket 文件
/var/run/docker.sock挂载到容器中的/var/run/docker.sock路径。
volumes配置示意:
- name: config:
- 作用: 与volumeMounts中的name: config相对应。
- defaultMode: 0600: 表示只有文件所有者可读写,其他用户无权限。
- name:filebeat-config对应第一步创建的filebeat.settings.configmap.yml中的Configmap的名字
- name: filebeat-indice-lifecycle:
- 作用: 与volumeMounts中的filebeat-indice-lifecycle相对应。
- defaultMode: 0600: 表示只有文件所有者可读写,其他用户无权限。
- name:filebeat-indice-lifecycle对应第二步创建的filebeat.indice-lifecycle.configmap.yml中的Configmap的名字
- name: data
- 作用:与volumeMounts中的name: data相对应。
- path:需要挂载的目录路径
- type:DirectoryOrCreatea表示容器启动时会检查宿主机是否存在该目录,不存在则创建。因为Filebeat在每个节点的宿主机上都会运行,所以直接挂载到宿主机目录
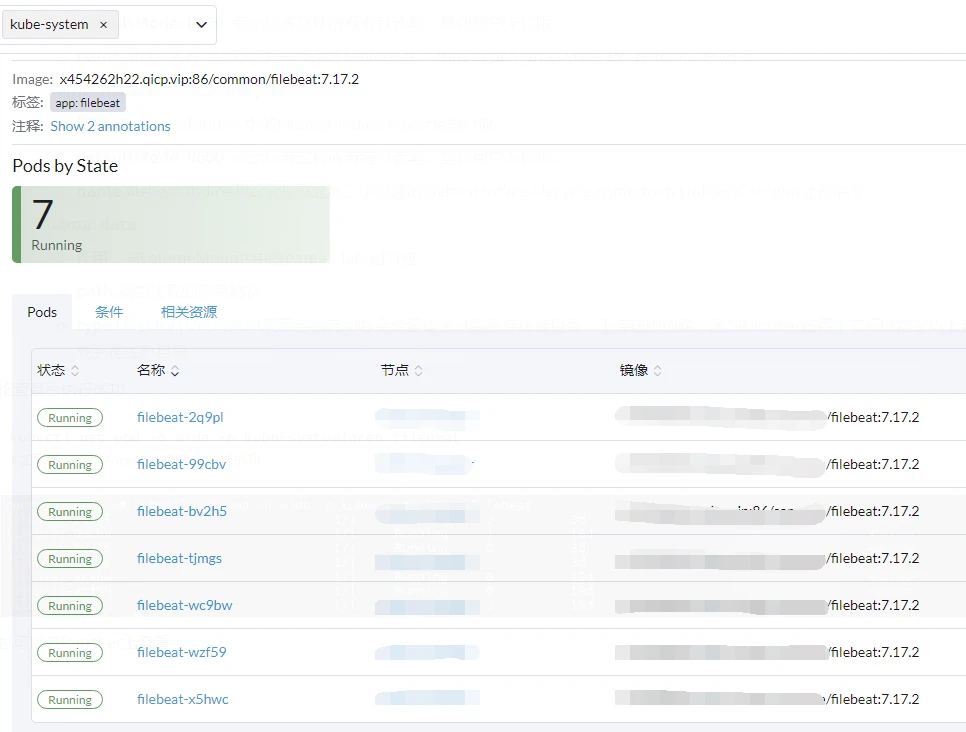
检查是否执行成功
kubectl get pod -o wide -n kube-system|grep filebeat
#如下图,全为Running则表示运行成功

也可以在Rancher上查看
五.检查File beat与es,Kibana是否配置成功
1.首先在侧边栏找到Stack Management
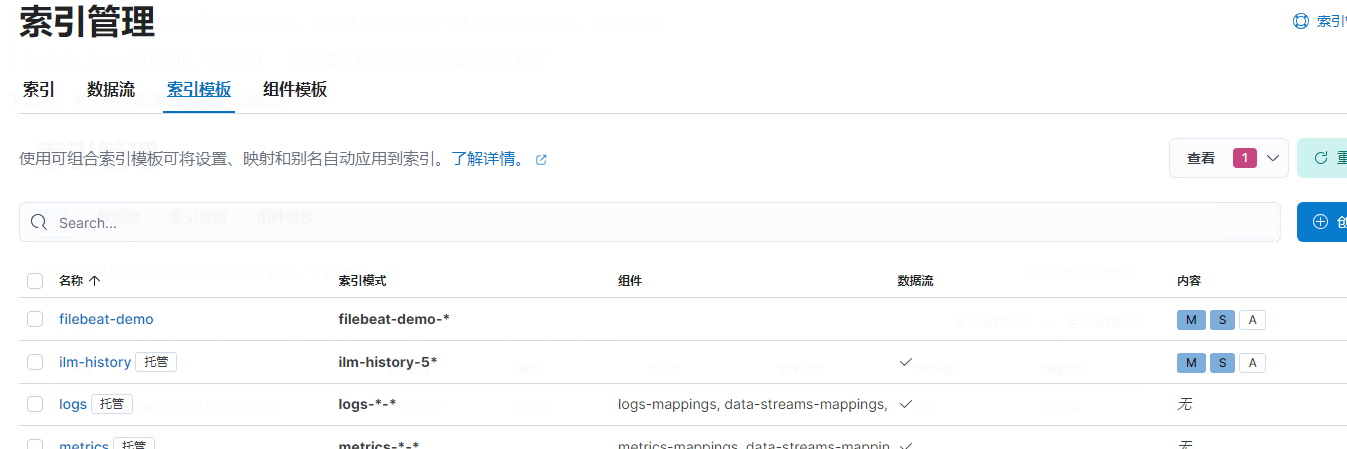
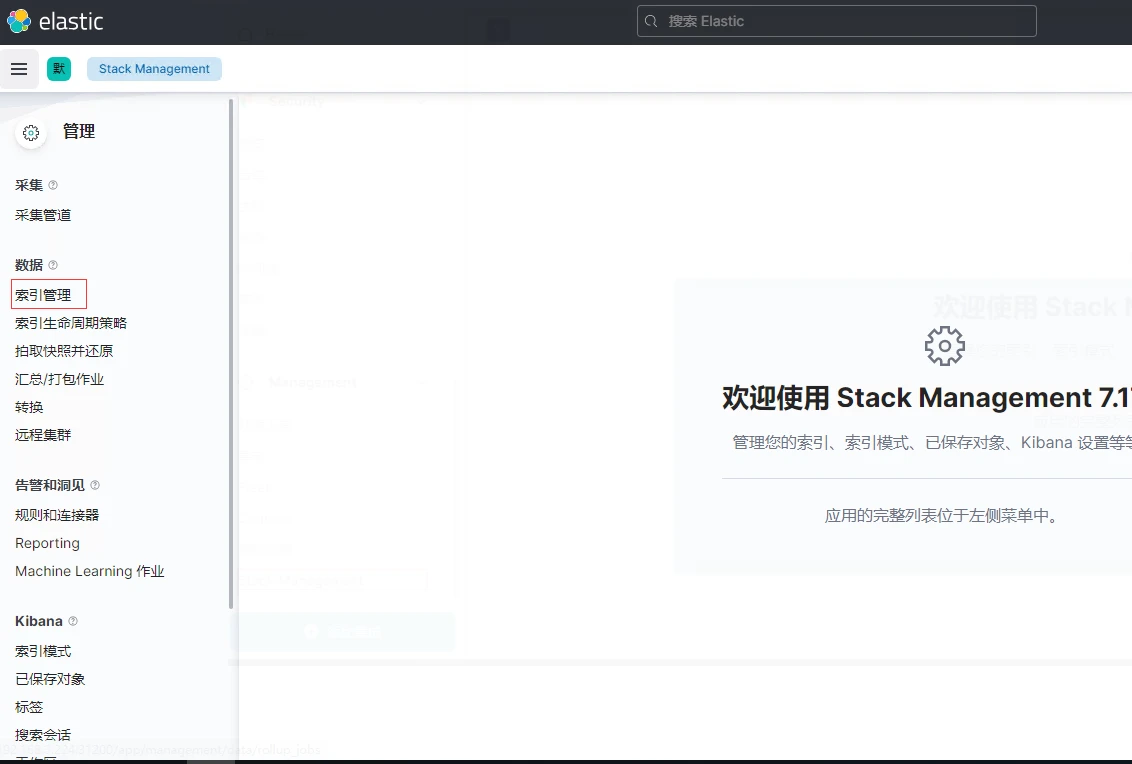
2.选择索引管理,查看是否有以filebeat-demo加时间戳为名的索引
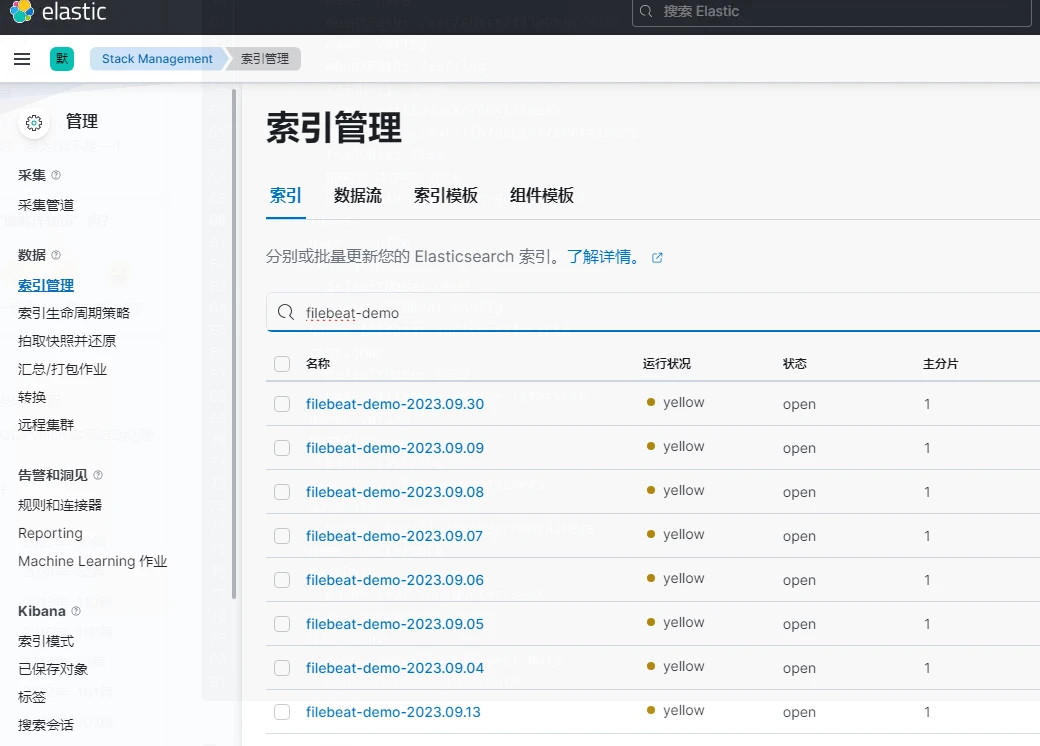
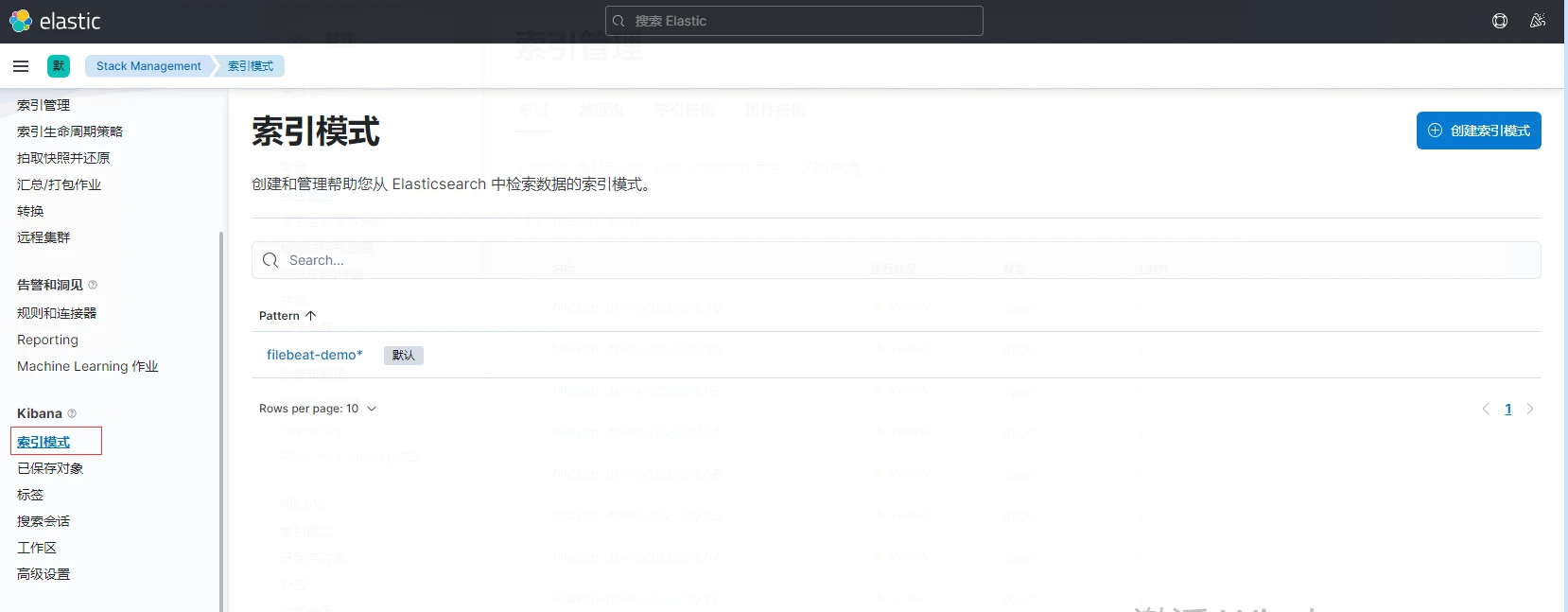
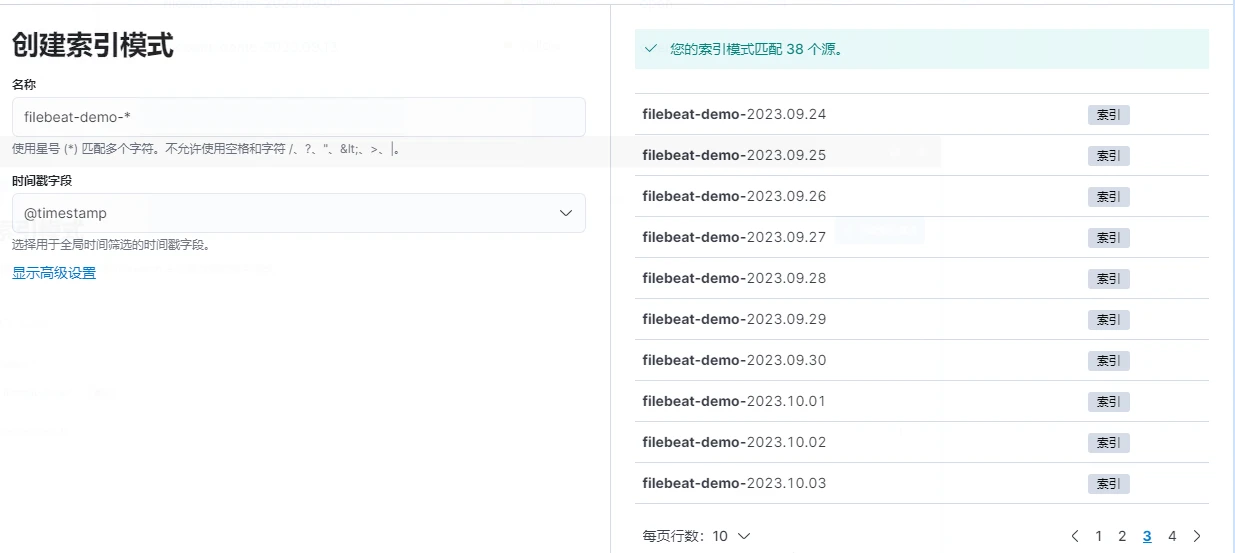
3.创建索引模式
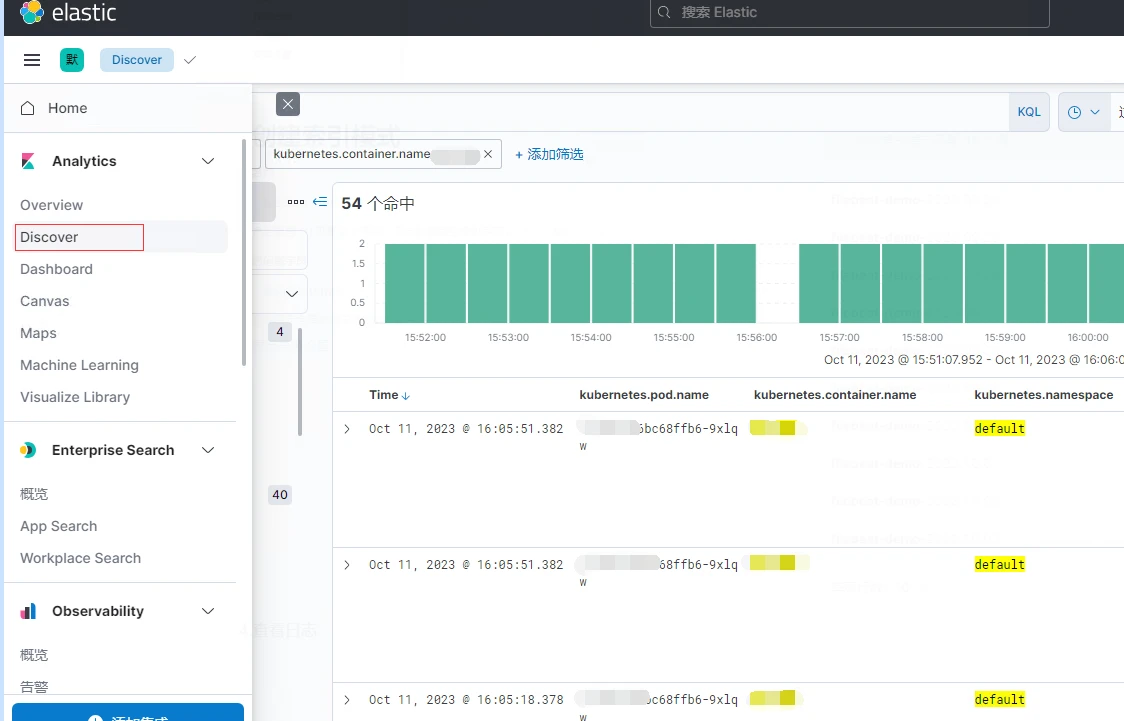
4.查看日志
点击侧边栏,选择discover,就能看到Filebeat收集到的容器日志,可以按照自己的需求进行日志筛选


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· Docker 太简单,K8s 太复杂?w7panel 让容器管理更轻松!