中文文本处理——去除非中文字符、去除停用词、统计词频
去除非中文字符
1 path1 = 'path1.txt' #打开需要处理的txt文件 2 path2 = 'path2.txt' #储存处理后的数据 3 f = open(path1, 'r', encoding= 'utf-8', errors= 'ignore') #将文本格式编码为utf-8,防止编码错误 4 fw = open(path2,'w', encoding='utf-8',errors= 'ignore') 5 for line in f: #逐行处理 6 constr = '' #记录每行处理后的数据 7 for uchar in line: 8 if uchar >= u'\u4e00' and uchar <= u'\u9fa5': #是中文字符 9 if uchar != ' ': #去除空格 10 constr += uchar 11 fw.write(constr+'\n') #写入处理后的数据,每行以空格隔开
在打开文本文件时,如果删掉这两个条件
encoding= 'utf-8', errors= 'ignore'
可能会出现以下报错。

解决办法:
首先,保存(或者另存为)文件时,将编码一项选择utf-8格式。然后打开文件时,写入时代码写为
f = open(path1, 'r', encoding= 'utf-8', errors= 'ignore')
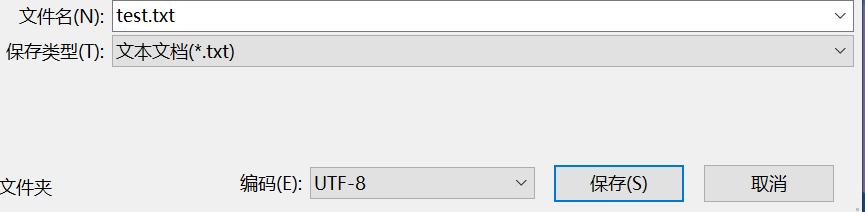
这样就可以正常打开文件了。
去除停用词、统计词频
首先下载一个停用词的文本文件。可以在GitHub上下载。
1.首先使用jieba分词对已去掉非中文的数据进行分词。
2.然后根据停用词表,对分词后的文本去除停用词。
3.统计词频,输出频率最高的前三十个
1 import jieba 2 import jieba as jieba 3 4 path2 = "path2.txt" #打开已去除掉非中文的文本文件 5 path3 = "D:/stopwords_u.txt" #停用词txt 6 txt = open(path2, encoding="utf-8").read() #加载待处理数据文件 7 stopwords = [line.strip() for line in open(path2, encoding="utf-8").readlines()] #加载停用词 8 words = jieba.lcut(txt) #分词 9 counts = {} #计数{word,frequency} 10 for word in words: 11 if word not in stopwords: #不在停用词表中 12 if len(word) == 1: #长度为1的话,不储存 13 continue 14 else: #不是停用词且词长度不为1 15 counts[word] = counts.get(word, 0) + 1 16 17 items = list(counts.items()) 18 items.sort(key=lambda x: x[1], reverse=True) 19 for i in range(30): #输出词频统计前30项 20 word, count = items[i] 21 print("{:<10}{:>7}".format(word, count))

 浙公网安备 33010602011771号
浙公网安备 33010602011771号