Linux安装ELK--Logstash
一、什么是Logstash
Logstash是一个开源的、接受来自多种数据源(input)、过滤你想要的数据(filter)、存储到其他设备的日志管理程序。Logstash包含三个基本插件input\filter\output,一个基本的logstash服务必须包含input和output.
Logstash如何工作:
Logstash数据处理有三个阶段,input–>filter–>output.input生产数据,filter根据定义的规则修改数据,output将数据输出到你定义的存储位置。
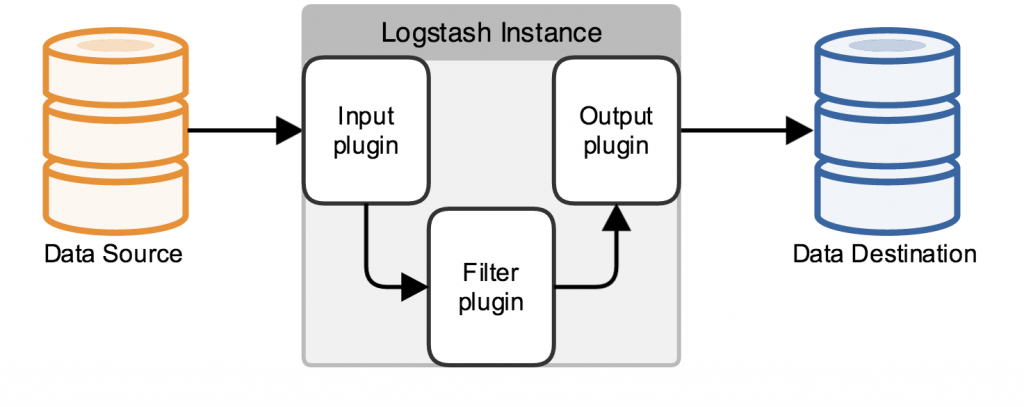
Inputs:
数据生产商,包含以下几个常用输出:
-
file: 从文件系统中读取文件,类似使用tail -0F
-
syslog: syslog服务,监听在514端口使用RFC3164格式
-
redis: 从redis服务读取,使用redis管道和列表。
-
beats: 一种代理,自己负责收集好数据然后转发给Logstash,常用的如filebeat.
Filters:
filters相当一个加工管道,它会一条一条过滤数据根据你定义的规则,常用的filters如下:
-
grok: 解析无规则的文字并转化为有结构的格式。
-
mutate: 丰富的基础类型处理,包括类型转换、字符串处理、字段处理等。
-
drop: 丢弃一部分events不进行处理,例如: debug events
-
clone: 负责一个event,这个过程中可以添加或删除字段。
-
geoip: 添加地理信息(为前台kibana图形化展示使用)
Outputs:
-
elasticserache elasticserache接收并保存数据,并将数据给kibana前端展示。
-
output 标准输出,直接打印在屏幕上。
二、Logstash的安装配置
Logstash运行仅仅依赖java运行环境(jre),JDK版本1.8以上即可。直接从ELK官网下载Logstash:https://www.elastic.co/cn/products
1 # tar -zxvf logstash-6.1.0.tar.gz 2 # cd logstash-6.1.0
现在我们来运行一下一个简单的例子:
1 # bin/logstash -e 'input { stdin { } } output { stdout {} }'
我们现在可以在命令行下输入一些字符,然后我们将看到logstash的输出内容:
1 hello world 2 2017-11-21T01:22:14.405+0000 0.0.0.0 hello world
Ok,还挺有意思的吧… 以上例子我们在运行logstash中,定义了一个叫”stdin”的input还有一个”stdout”的output,无论我们输入什么字符,Logstash都会按照某种格式来返回我们输入的字符。这里注意我们在命令行中使用了-e参数,该参数允许Logstash直接通过命令行接受设置。这点尤其快速的帮助我们反复的测试配置是否正确而不用写配置文件。
让我们再试个更有意思的例子。首先我们在命令行下使用CTRL-C命令退出之前运行的Logstash。现在我们重新运行Logstash使用下面的命令:
1 # bin/logstash -e 'input { stdin { } } output { stdout { codec => rubydebug } }'
我们再输入一些字符,这次我们输入”hello world ”:
1 hello world2 { 3 "message" => "hello world", 4 "@timestamp" => "2017-11-20T23:48:05.335Z", 5 "@version" => "1", 6 "host" => "node1" 7 }
以上示例通过重新设置了叫”stdout”的output(添加了”codec”参数),我们就可以改变Logstash的输出表现。类似的我们可以通过在你的配置文件中添加或者修改inputs、outputs、filters,就可以使随意的格式化日志数据成为可能,从而订制更合理的存储格式为查询提供便利。
前面已经说过Logstash必须有一个输入和一个输出,上面的例子表示从终端上输入并输出到终端。
数据在线程之间以事件的形式流传。不要叫行,因为Logstash可以处理多行事件。
input {
# 输入域,可以使用上面提到的几种输入方式。stdin{} 表示标准输入,file{} 表示从文件读取。
input的各种插件: https://www.elastic.co/guide/en/logstash/current/input-plugins.html
}
output {
#Logstash的功能就是对数据进行加工,上述例子就是Logstash的格式化输出,当然这是最简单的。
output的各种插件:https://www.elastic.co/guide/en/logstash/current/output-plugins.html
}
Logstash配置文件和命令:
Logstash的默认配置已经够我们使用了,从5.0后使用logstash.yml文件,可以将一些命令行参数直接写到YAML文件即可。
-
–configtest 或 -t 用于测试Logstash的配置语法是否正确,非常好的一个参数。
-
–log 或 -l Logstash默认输出日志到标准输出,指定Logstash的日志存放位置
-
–pipeline-workers 或 -w 指定运行filter和output的pipeline线程数量,使用默认就好。
-
-f 指定规则文件,可以将自己的文件放在同一个路径下,使用-f 即可运行。
一个简单的Logstash从文件中读取配置
1 vim file.conf #file.conf可以放在任意位置 2 input { 3 stdin { 4 } 5 } 6 output { 7 stdout { 8 codec=>rubydebug 9 } 10 } 11 ~ 12 bin/logstash -f /root/conf/file.conf #启动即可
三、一些常用的插件
1、grok插件
Grok是Logstash最重要的插件,你可以在grok里自定义好命名规则,然后在grok参数或者其他正则表达式中引用它。
官方给出了120个左右默认的模式:https://github.com/logstash-plugins/logstash-patterns-core/tree/master/patterns
1 USERNAME [a-zA-Z0-9._-]+ 2 USER %{USERNAME}
第一行,用普通的正则表达式来定义一个grok表达式;第二行,通过打印赋值格式,用前面定义好的grok表达式来定义里一个grok表达式。
正则表达式引格式:
1 %{SYNTAX:SEMANTIC}
-
SYNTAX:表示你的规则是如何被匹配的,比如3.14将会被NUMBER模式匹配,55.1.1.2将会被IP模式匹配。
-
SEMANTIC:表示被匹配到的唯一标识符,比如3.14被匹配到了后,SEMANTIC就当是3.14。
匹配到的数据默认是strings类型,当然你也可以装换你匹配到的数据,类似这样:
1 %{NUMBER:num:int}
当前只支持装换为int和float。
例如:
1 filter { 2 grok { 3 match => { 4 "message" => "%{WORD} %{NUMBER:request_time:float} %{WORD}" 5 } 6 } 7 }
1 jasi 12.12 asioa 2 { 3 "@timestamp" => 2017-02-08T05:55:18.460Z, 4 "request_time" => 12.12, 5 "@version" => "1", 6 "host" => "0.0.0.0", 7 "message" => "jasi 12.12 asioa" 8 }
这个我们就匹配到我们想要的值了,并将名字命名为:request_time
在实际生产中为了方便我们不可能在配置文件中一行一行的写表达式,建议把所有的grok表达式统一写到一个地方,使用patterns_dir选项来引用。
1 grok { 2 patterns_dir => "/root/conf/nginx" #这是你定义的grok表达式文件 3 match => { "message" => "%{CDN_FORMAT}" } 4 add_tag => ["CDN"] 5 }
事实上,我们收集的日志也有很多不需要的地方,我们可以删除一部分field信息,保留我们想要的那一部分。
1 grok { 2 match => { 3 "message" => "%{WORD} %{NUMBER:request_time:float} %{WORD}" 4 } 5 remove_field => [ "request_time" ] 6 overwrite => [ "message" ] 7 } 8 as 12 as 9 { 10 "@timestamp" => 2017-02-08T06:39:07.921Z, 11 "@version" => "1", 12 "host" => "0.0.0.0", 13 "message" => "as 12 as" 14 }
已经没有request_time这个field啦~
更多关于grok的用户看官方文档:https://www.elastic.co/guide/en/logstash/current/plugins-filters-grok.html
最重要的一点:我强烈建议每个人都要使用 Grok Debugger 来调试自己的 grok 表达式。
2、kv插件
在很多的情况下,日志类容本身就是类似于key-value的格式,kv插件就是自动处理类似于key=value样式的数据。
kv {
source => "request" #数据来源,默认是message
field_split => "&" # 用于分割键值对
value_split => "=" # 识别键值对的关系,如 k1:v1 k2:v2 ":"即为键值对关系连接符
}

3、geoip插件
geoip主要是查询IP地址归属地,用来判断访问网站的来源地。
1 geoip { 2 source => "clientip" 3 fields => [ "ip","city_name","country_name","location" ] #fields包含信息太多,可以自定义 4 }

Logstash还有许多比较常用的插件,如json\multiline等,可以到官方文档查看。
转自:https://www.busyboy.cn/?p=988

 浙公网安备 33010602011771号
浙公网安备 33010602011771号