

Python从零开始写爬虫-4 解析HTML获取小说正文
Python从零开始写爬虫-4 解析HTML获取小说正文
在上一节中, 我们已经学会如何获取小说的目录, 这一节我们将学习如何通过正则表达式(在第二节学习过)来获取小说正文.
首先, 先随便选择一个章节, 作为例子, 我们就以 "吞噬星空第一章:罗峰"为例子, 来进行我们的学习.
首先依然式先获取该网页的源代码
import requests
r = requests.get('http://www.biquger.com/biquge/12928/4282781')
r.encoding = 'utf-8'
print(r.text)

通过分析源代码, 我们可以发现小说的正文被<div class"content" id="booktext">...</div>包括. 那我们就可以通过正则表达式提取该部分内容即可.
使用正则表达式提取正文
按照我们之前所学的, 使用下列正则表达式搜索:
res = re.search(r'<div class="content" id="booktext">((.)*?)</div>', r.text)
print(res)

可以发现, 没有搜索结果. 查看正则表达式说明文档, 发现 .是不匹配换行符, 而我们的小说正文不可能只有一行, 所以无法匹配. 我们的正文应该是所有字符加换行符, 应该使用: (.|\n), 使用[.\n]是不可以的, 原因我也不知道.
res = re.search(r'<div class="content" id="booktext">((.|\n)*?)</div>', r.text)
text = res.group(1)
print(text)

我也经成功提取到了正文, 但是发现里面很多html的标记语言, 例如: :, <br />等.下面我们将对提取到正文进行进一步的处理, 使其符合我们的阅读习惯.
处理正文
在html标记语言中, 表示空格, <br />表示换行符. 我们按照该要求替换正文中的内容.
text = text.replace(' ', ' ')
text = text.replace('<br />', '\n')

看起来好多, 但是有一个问题, 段与段之间的空行好像有点多啊, 通过print(repr(text))我们可以发现, 段与段之间存在四个换行符\n, 正常情况, 段与段之间只有一个换行符, 我们需要将四个换行符替换成一个换行符.
text = text.replace('\n\n\n\n', '\n')
print(text)
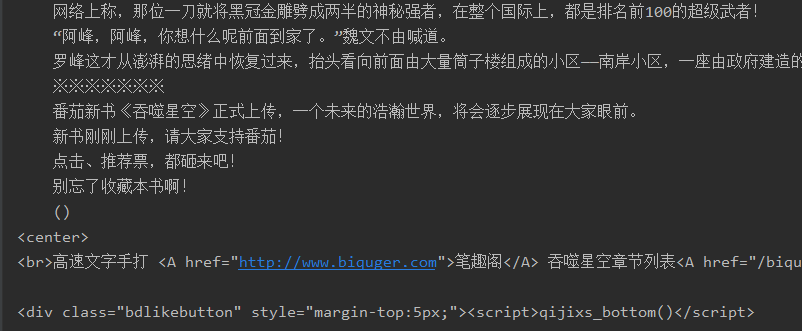
发现空行处理好了, 但是在末尾还有一些我们不希望存在的文字出现, 他们被包裹在<center>(.|\n)</script> 之间.我们需要把他替换掉, str的replace是不支持正则表达式替换的, 我们需要使用re中sub.
text = re.sub(r'<center>(.|\n)*?</script>', '', text)
print(text)

可以发现,现在的正文已经符合我们的阅读习惯了.
整理
将上面的内容整理成函数, 今天的学习就结束了
def parse(url):
r = requests.get(url)
r.encoding = 'utf-8'
res = re.search(r'<div class="content" id="booktext">((.|\n)*?)</div>', r.text)
text = res.group(1)
text = text.replace(' ', ' ')
text = text.replace('<br />', '\n')
text = text.replace('\n\n\n\n', '\n')
text = re.sub(r'<creturn textenter>(.|\n)*?</script>', '', text)
return text
总结
我们已经获得该章节的正文了, 在该学习中, 我们先通过requests获得小说正文网页的源代码, 然后通过re.search来获得小说的正文, 最后通过不断的处理, 最终获得我们希望的样子.但是注意: 每个以网站的格式都不一样, 甚至每一篇小说的格式都一样, 应根据情况处理正文.

