破解字体加密
前言
字体加密在源代码中是乱码的,但在浏览器显示是正常的。
本博文仅供学习研究。
加密
字体加密的大概流程:
1、在后端返回数据到前端时,将一个unicode编码与被加密字符映射并生成字体文件;
2、此时后端返回的数据是与被加密字符映射的unicode,此unicode与加密字符并无关系,根据编码表转换是转换成其他字符;
3、前端接收到数据,根据字体文件的映射解析数据,显示到界面。
此流程为本人猜想,并未实践过。
解密
以 58 为例,
待解密字符:驋驋龤;
解密思路:按照浏览器解析行为
1、找到字体文件
2、根据待解密字符的unicode编码找到此unicode编码的真正映射字符
-
手动解密
1、找到待解密字符的字体文件,可以通过css样式找到;
58字体文件为base64:

2、将base64 转码并存储为 .ttf 文件:
在此(https://www.motobit.com/util/base64-decoder-encoder.asp)网站可解码base64并存储为二进制数据的 .bin 文件,将下载的二进制数据的 .bin 文件后缀更改为 .ttf,
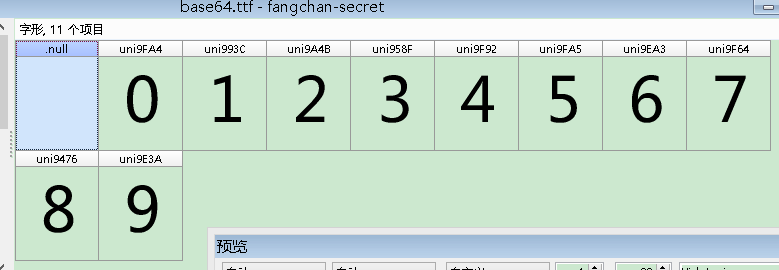
3、通过 FontCreator 软件打开字体文件,可看到字符与unicode的映射关系:
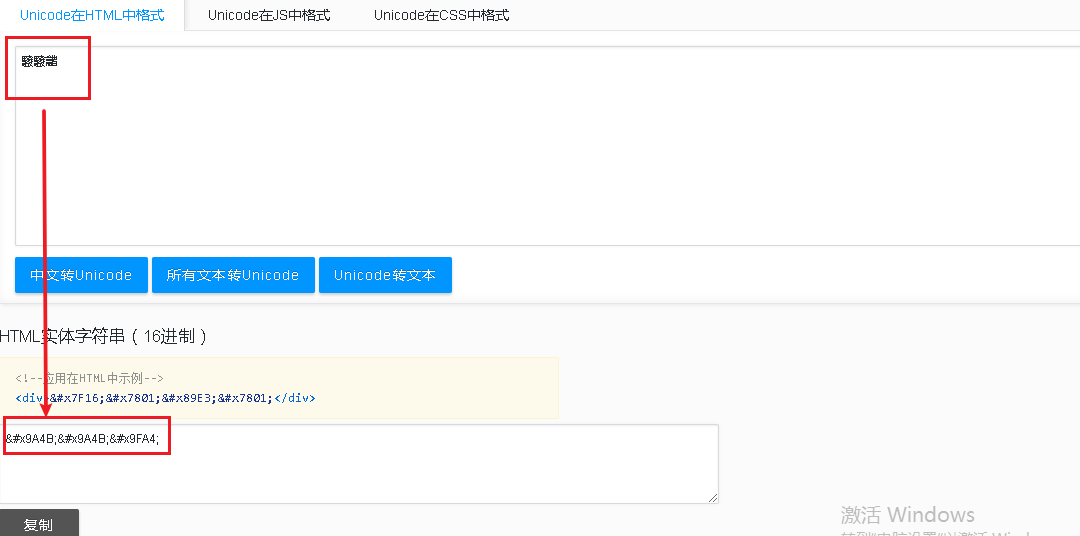
4、将待解密字符转换为unicode编码:驋驋龤:驋驋龤
可通过此网站(https://www.css-js.com/tools/unicode.html)在线转换,得到结果:
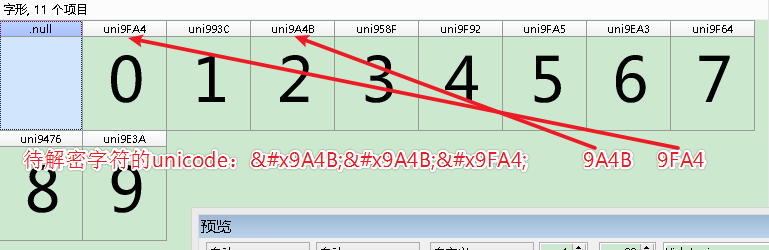
5、根据待解密字符的unicode编码(驋驋龤)在FontCreator 软件中查找对应的字符,得知 驋驋龤 解密后为 220。
-
代码解密
python为例:
1 from fontTools.ttLib import TTFont 2 import base64 3 4 5 6 # 模块依赖: 7 # base64 :解码base64 8 # TTFont :解析字体文件 9 10 11 # 存储的ttf文件路径及名称 12 filePath = 'decode.ttf' 13 14 # 字体文件的base64 15 base64str = 'AAEAAAALAIAAAwAwR1NVQiCLJXoAAAE4AAAAVE9TLzL4XQjtAAABjAAAAFZjbWFwq8J/ZQAAAhAAAAIuZ2x5ZuWIN0cAAARYAAADdGhlYWQYrcvJAAAA4AAAADZoaGVhCtADIwAAALwAAAAkaG10eC7qAAAAAAHkAAAALGxvY2ED7gSyAAAEQAAAABhtYXhwARgANgAAARgAAAAgbmFtZTd6VP8AAAfMAAACanBvc3QFRAYqAAAKOAAAAEUAAQAABmb+ZgAABLEAAAAABGgAAQAAAAAAAAAAAAAAAAAAAAsAAQAAAAEAAOGGAfhfDzz1AAsIAAAAAADak0BcAAAAANqTQFwAAP/mBGgGLgAAAAgAAgAAAAAAAAABAAAACwAqAAMAAAAAAAIAAAAKAAoAAAD/AAAAAAAAAAEAAAAKADAAPgACREZMVAAObGF0bgAaAAQAAAAAAAAAAQAAAAQAAAAAAAAAAQAAAAFsaWdhAAgAAAABAAAAAQAEAAQAAAABAAgAAQAGAAAAAQAAAAEERAGQAAUAAAUTBZkAAAEeBRMFmQAAA9cAZAIQAAACAAUDAAAAAAAAAAAAAAAAAAAAAAAAAAAAAFBmRWQAQJR2n6UGZv5mALgGZgGaAAAAAQAAAAAAAAAAAAAEsQAABLEAAASxAAAEsQAABLEAAASxAAAEsQAABLEAAASxAAAEsQAAAAAABQAAAAMAAAAsAAAABAAAAaYAAQAAAAAAoAADAAEAAAAsAAMACgAAAaYABAB0AAAAFAAQAAMABJR2lY+ZPJpLnjqeo59kn5Kfpf//AACUdpWPmTyaS546nqOfZJ+Sn6T//wAAAAAAAAAAAAAAAAAAAAAAAAABABQAFAAUABQAFAAUABQAFAAUAAAACQAEAAIAAwAKAAcACAAFAAEABgAAAQYAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAADAAAAAAAiAAAAAAAAAAKAACUdgAAlHYAAAAJAACVjwAAlY8AAAAEAACZPAAAmTwAAAACAACaSwAAmksAAAADAACeOgAAnjoAAAAKAACeowAAnqMAAAAHAACfZAAAn2QAAAAIAACfkgAAn5IAAAAFAACfpAAAn6QAAAABAACfpQAAn6UAAAAGAAAAAAAAACgAPgBmAJoAvgDoASQBOAF+AboAAgAA/+YEWQYnAAoAEgAAExAAISAREAAjIgATECEgERAhIFsBEAECAez+6/rs/v3IATkBNP7S/sEC6AGaAaX85v54/mEBigGB/ZcCcwKJAAABAAAAAAQ1Bi4ACQAAKQE1IREFNSURIQQ1/IgBW/6cAicBWqkEmGe0oPp7AAEAAAAABCYGJwAXAAApATUBPgE1NCYjIgc1NjMyFhUUAgcBFSEEGPxSAcK6fpSMz7y389Hym9j+nwLGqgHButl0hI2wx43iv5D+69b+pwQAAQAA/+YEGQYnACEAABMWMzI2NRAhIzUzIBE0ISIHNTYzMhYVEAUVHgEVFAAjIiePn8igu/5bgXsBdf7jo5CYy8bw/sqow/7T+tyHAQN7nYQBJqIBFP9uuVjPpf7QVwQSyZbR/wBSAAACAAAAAARoBg0ACgASAAABIxEjESE1ATMRMyERNDcjBgcBBGjGvv0uAq3jxv58BAQOLf4zAZL+bgGSfwP8/CACiUVaJlH9TwABAAD/5gQhBg0AGAAANxYzMjYQJiMiBxEhFSERNjMyBBUUACEiJ7GcqaDEx71bmgL6/bxXLPUBEv7a/v3Zbu5mswEppA4DE63+SgX42uH+6kAAAAACAAD/5gRbBicAFgAiAAABJiMiAgMzNjMyEhUUACMiABEQACEyFwEUFjMyNjU0JiMiBgP6eYTJ9AIFbvHJ8P7r1+z+8wFhASClXv1Qo4eAoJeLhKQFRj7+ov7R1f762eP+3AFxAVMBmgHjLfwBmdq8lKCytAAAAAABAAAAAARNBg0ABgAACQEjASE1IQRN/aLLAkD8+gPvBcn6NwVgrQAAAwAA/+YESgYnABUAHwApAAABJDU0JDMyFhUQBRUEERQEIyIkNRAlATQmIyIGFRQXNgEEFRQWMzI2NTQBtv7rAQTKufD+3wFT/un6zf7+AUwBnIJvaJLz+P78/uGoh4OkAy+B9avXyqD+/osEev7aweXitAEohwF7aHh9YcJlZ/7qdNhwkI9r4QAAAAACAAD/5gRGBicAFwAjAAA3FjMyEhEGJwYjIgA1NAAzMgAREAAhIicTFBYzMjY1NCYjIga5gJTQ5QICZvHD/wABGN/nAQT+sP7Xo3FxoI16pqWHfaTSSgFIAS4CAsIBDNbkASX+lf6l/lP+MjUEHJy3p3en274AAAAAABAAxgABAAAAAAABAA8AAAABAAAAAAACAAcADwABAAAAAAADAA8AFgABAAAAAAAEAA8AJQABAAAAAAAFAAsANAABAAAAAAAGAA8APwABAAAAAAAKACsATgABAAAAAAALABMAeQADAAEECQABAB4AjAADAAEECQACAA4AqgADAAEECQADAB4AuAADAAEECQAEAB4A1gADAAEECQAFABYA9AADAAEECQAGAB4BCgADAAEECQAKAFYBKAADAAEECQALACYBfmZhbmdjaGFuLXNlY3JldFJlZ3VsYXJmYW5nY2hhbi1zZWNyZXRmYW5nY2hhbi1zZWNyZXRWZXJzaW9uIDEuMGZhbmdjaGFuLXNlY3JldEdlbmVyYXRlZCBieSBzdmcydHRmIGZyb20gRm9udGVsbG8gcHJvamVjdC5odHRwOi8vZm9udGVsbG8uY29tAGYAYQBuAGcAYwBoAGEAbgAtAHMAZQBjAHIAZQB0AFIAZQBnAHUAbABhAHIAZgBhAG4AZwBjAGgAYQBuAC0AcwBlAGMAcgBlAHQAZgBhAG4AZwBjAGgAYQBuAC0AcwBlAGMAcgBlAHQAVgBlAHIAcwBpAG8AbgAgADEALgAwAGYAYQBuAGcAYwBoAGEAbgAtAHMAZQBjAHIAZQB0AEcAZQBuAGUAcgBhAHQAZQBkACAAYgB5ACAAcwB2AGcAMgB0AHQAZgAgAGYAcgBvAG0AIABGAG8AbgB0AGUAbABsAG8AIABwAHIAbwBqAGUAYwB0AC4AaAB0AHQAcAA6AC8ALwBmAG8AbgB0AGUAbABsAG8ALgBjAG8AbQAAAAIAAAAAAAAAFAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAACwECAQMBBAEFAQYBBwEIAQkBCgELAQwAAAAAAAAAAAAAAAAAAAAA' 16 17 # 待解密字符 18 encodestr = u'驋驋龤' 19 20 21 # 存储文件(以二进制方式) 22 # filePath :存储的文件路径及名称 23 # data :需要存储的数据 24 def writeTTFFile(filePath, data): 25 #print(encodestr.encode("unicode_escape").decode()) 26 #print(int(encodestr.encode("unicode_escape")[2:], 16)) 27 with open(filePath, 'wb') as f: 28 f.write(data) 29 30 # 解析字体并解密待解密字符 31 # filePath :字体文件的路径及名称 32 # str :待解密字符 33 # return :返回解密后的字符 34 def TTFDecode(filePath, encodestr): 35 font = TTFont(filePath) 36 strRes = font.getBestCmap() 37 print(strRes) 38 glypDict = font.getReverseGlyphMap() 39 print(glypDict) 40 ret = '' 41 for ch in encodestr: #遍历待解密字符,挨个解密 42 strResKey = int(ch.encode("unicode_escape")[2:], 16) #将单个字符转换为unicode并截取16进制部分,并转换为10进制数字 43 glypDictKey = strRes[strResKey] #通过转换出的10进制数字在 'strRes' 里查找对应的glyph资源 44 ret = ret + str(glypDict[glypDictKey] - 1) #在 'strRes' 查找出的值在 'glypDict' 里查找出对应的字符并拼接,得到解密后的字符, 这里减1 是58加密时的规则,其他网站的加密可能不是这样 45 return ret 46 47 writeTTFFile(filePath, base64.b64decode(base64str)) 48 decodestr = TTFDecode(filePath, encodestr) 49 print(decodestr)
代码重点在 34、35行,这两行解析了字体文件的映射关系;
print(strRes) 输出为:{38006: 'glyph00009', 38287: 'glyph00004', 39228: 'glyph00002', 39499: 'glyph00003', 40506: 'glyph00010', 40611: 'glyph00007', 40804: 'glyph00008', 40850: 'glyph00005', 40868: 'glyph00001', 40869: 'glyph00006'}
print(glypDict):{'glyph00000': 0, 'glyph00001': 1, 'glyph00002': 2, 'glyph00003': 3, 'glyph00004': 4, 'glyph00005': 5, 'glyph00006': 6, 'glyph00007': 7, 'glyph00008': 8, 'glyph00009': 9, 'glyph00010': 10}
例如:待解密字符:驋 的unicode编码的10进制为 39499 ,那么在 strRes 中查找对应的值为 glyph00003 ,glyph00003 在 glypDict 中查找对应的值为 3,再减 1就是2,得到解密后的字符就是 2。
减 1 操作是58网站的加密规则,可通过对比观察得到。
可以将 ttf 文件转为 ttx 文件,ttx 文件直观展示了映射关系,通过代码:TTFont('encode.ttf').saveXML('decode.ttx'),转换;
font.getBestCmap():这段代码就是解析得到

font.getReverseGlyphMap():这段代码就是解析得到:
-
其他演示
待解密字符: 𘢘𘢗𘢓𘢕;
字体文件:http://qidian.gtimg.com/qd_anti_spider/PUNzUOms.woff
1 def decode(): 2 encodestr = '𘢘𘢗𘢓𘢕' 3 glypDict = { 4 'zero': '0', 5 'one': '1', 6 'two': '2', 7 'three': '3', 8 'four': '4', 9 'five': '5', 10 'six': '6', 11 'seven': '7', 12 'eight': '8', 13 'nine': '9', 14 'period': '.' 15 16 } 17 strRes = TTFont(BytesIO(requests.get('http://qidian.gtimg.com/qd_anti_spider/PUNzUOms.woff').content)).getBestCmap() 18 print(strRes) 19 ret = '' 20 for ch in encodestr: 21 ret = ret + glypDict[strRes[int(ch.encode('unicode_escape')[2:], 16)]] 22 return ret 23 print(decode())
与58不同,字体文件是 .woff,但原理一样,在解密时,应手动解密一遍,配合 FontCreator 软件,或转成 xml格式,仔细观察。

