

Mac配置Hadoop最详细过程
Mac配置Hadoop最详细过程
原文链接: http://www.cnblogs.com/blog5277/p/8565575.html
原文作者: 博客园-曲高终和寡
https://www.cnblogs.com/landed/p/6831758.html
一.准备工作:
1. JDK1.7版本及以上(貌似Hadoop只支持1.6以上的版本,不确定,保险起见用1.7,我自己用的是1.8)
2. 2.7.3版本的Hadoop https://archive.apache.org/dist/hadoop/common/hadoop-2.7.3/ 下载那个二百多M的那个
二.配置SSH免密登录
1.打开Mac的远程连接
系统偏好设置-->共享-->远程登录

2.如果你读过,并且跟着配置过
[从零开始搭网站二]服务器环境配置:Mac电脑连接CentOS不用每次都输入密码
,可以跳过这一步,否则的话:
打开终端(terminal),输入并一直回车,问你yes/no记得输yes
ssh-keyagent -t
完成以后跳转到 ~/.ssh 目录下
cd ~/.ssh
查看目录下的文件
ls
确保你目录下有这两个密钥文件

3.输入以下代码,即可免密登录
cat ~/.ssh/id_rsa.pub > ~/.ssh/authorized_keys
4.验证,输入以下代码
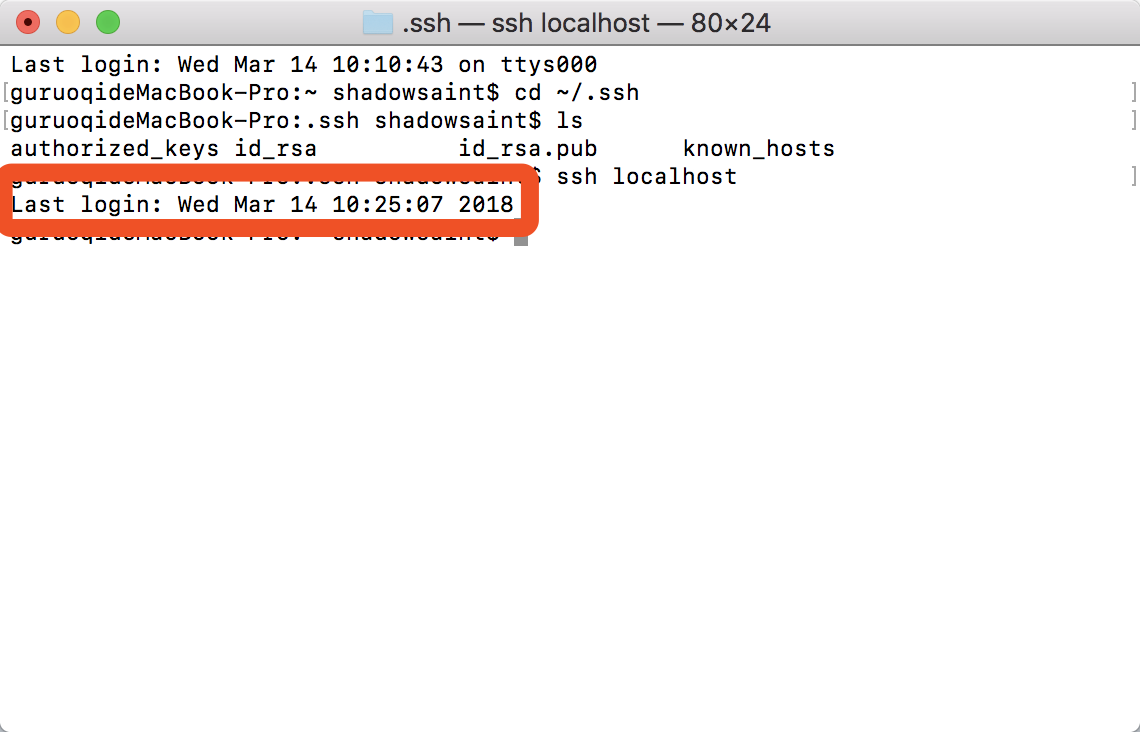
ssh localhost
如果如下图所示,直接提示 last login + 时间 就是没输密码直接登录了
三:解压缩并配置Hadoop
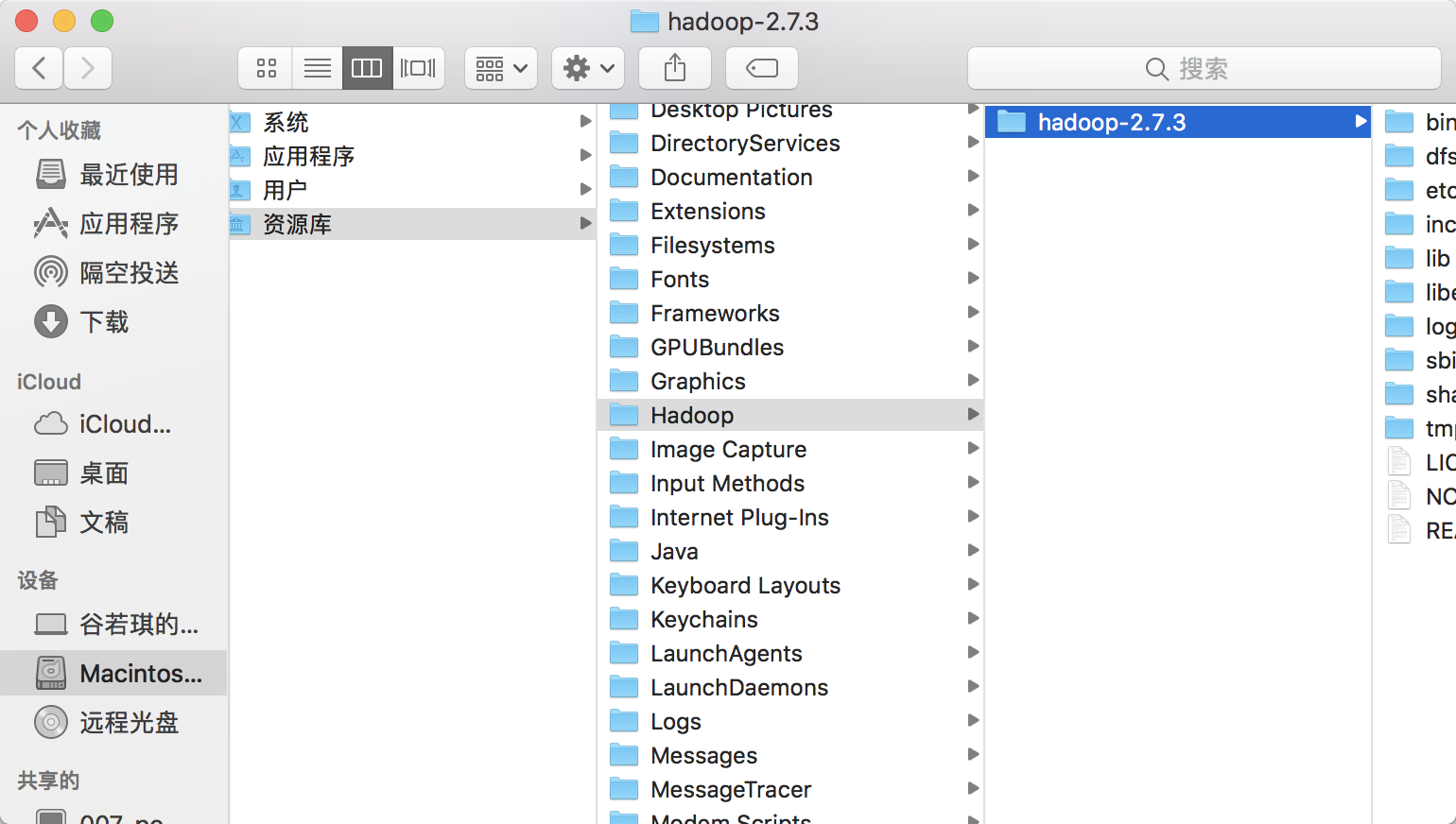
1.在你喜欢的位置建个文件夹并命名,我是所有安装的东西都放在 /Library/下 ,然后把第一步下载的Hadoop 2.7.3.tar.gz粘贴进来,双击提取到当前目录,如下图所示
2.打开终端,配置Hadoop的环境变量,输入以下代码,如果没有 /etc/profile 的话会新建,有的话会直接编辑(因为这个涉及系统环境变量编辑,可能会让你输入你的Mac的密码)
sudo vim /etc/profile
按 i 进入编辑模式
粘贴进如下代码:
export HADOOP_HOME=/Library/Hadoop/hadoop-2.7.3
export PATH=$PATH:$HADOOP_HOME/bin
这个时候打开你Hadoop的安装路径,定位到 /Library/Hadoop/hadoop-2.7.3 这个目录上,同时按下 option+command+c 复制文件路径 , 这样粘贴出来以后应该是这个样子:
/Library/Hadoop/hadoop-2.7.3
如果你的安装版本和路径和我不同,那么就把你复制的这个,替换掉上文环境变量里面的HADOOP_HOME里面的路径
替换完了以后按i退出编辑模式,按:wq!强制退出并保存,zai再输入下面的代码使改动立刻生效
source /etc/profile
3.找到你的Java的安装路径,定位到 Java/JavaVirtualMachines/jdk1.8.0_111.jdk/Contents/Home 这个目录上,同时按下 option+command+c 复制文件路径 , 这样粘贴出来以后应该是这个样子:
/Library/Java/JavaVirtualMachines/jdk1.8.0_144.jdk/Contents/Home
定位的文件夹如下图所示:

4.回到你Hadoop的安装路径下,开始编辑配置文件,这一步,以及下面所有的配置,全部都在 /Library/Hadoop/hadoop-2.7.3/etc/hadoop 这个路径下
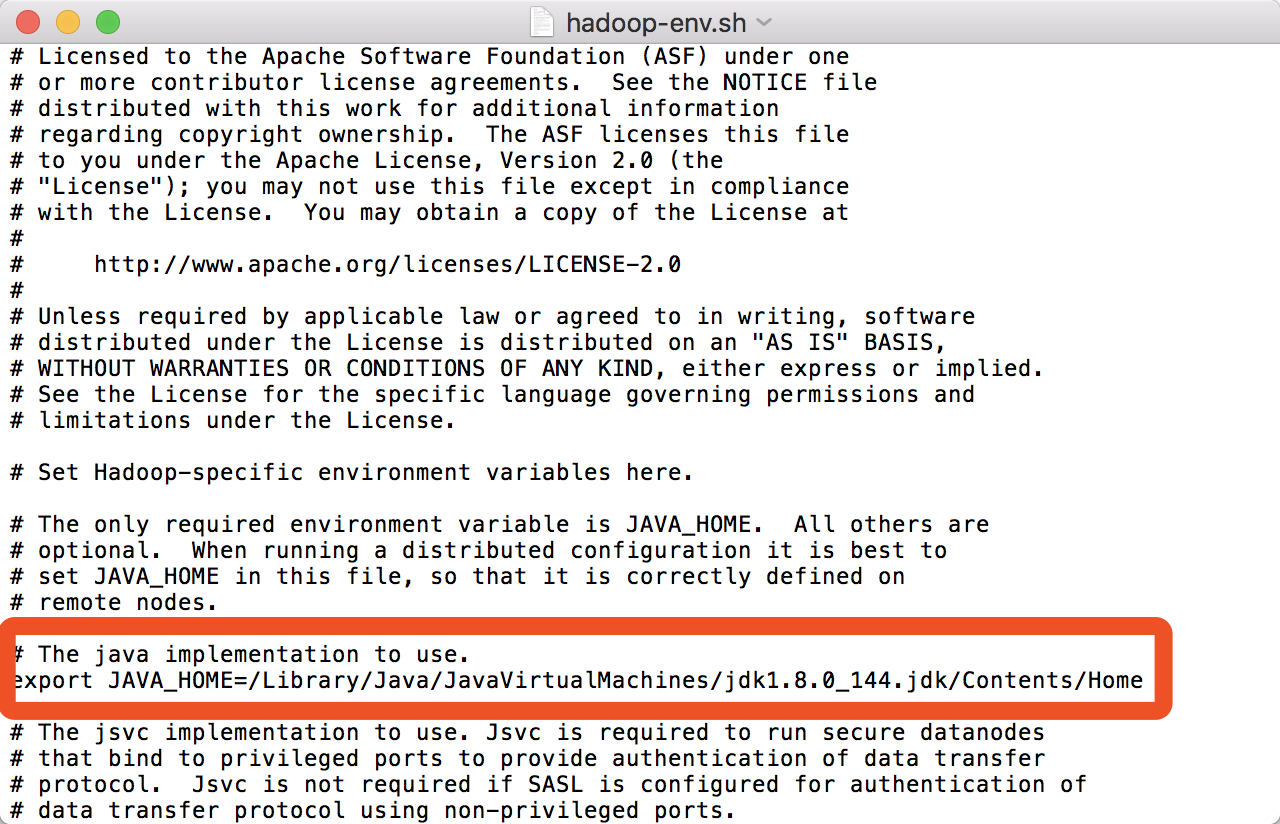
5.编辑 hadoop-env.sh 文件(右键-->打开方式-->文本编辑.app , 下同,不再赘述) , 把原本的JAVA_HOME换成你刚刚复制的Java路径:
export JAVA_HOME=/Library/Java/JavaVirtualMachines/jdk1.8.0_144.jdk/Contents/Home
如图所示:
6.编辑 core-site.xml 文件 , 将 configuration 标签替换为(注意,安装Hadoop版本不一样,或者安装路径不一样的,记得替换掉加红加粗部分):
<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://127.0.0.1:9000</value> </property> <property> <name>io.file.buffer.size</name> <value>131072</value> </property> <property> <name>hadoop.tmp.dir</name> <value>file:/Library/Hadoop/hadoop-2.7.3/tmp</value> <description>Abasefor other temporary directories.</description> </property> <property> <name>hadoop.proxyuser.spark.hosts</name> <value>*</value> </property> <property> <name>hadoop.proxyuser.spark.groups</name> <value>*</value> </property> </configuration>
7.编辑 hdfs-site.xml 文件 , 将 configuration 标签替换为(注意红色部分):
<configuration> <property> <name>dfs.namenode.secondary.http-address</name> <value>127.0.0.1:9001</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:/Library/Hadoop/hadoop-2.7.3/dfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:/Library/Hadoop/hadoop-2.7.3/dfs/data</value> </property> <property> <name>dfs.replication</name> <value>3</value> </property> <property> <name>dfs.webhdfs.enabled</name> <value>true</value> </property> </configuration>
8.复制并粘贴 mapred-site.xml.template 将 mapred-site.xml的副本.template 重命名为: mapred-site.xml , 然后编辑这个文件 , 将 configuration 标签替换为:
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>mapreduce.jobhistory.address</name> <value>127.0.0.1:10020</value> </property> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>127.0.0.1:19888</value> </property> </configuration>
9.编辑 yarn-site.xml 文件 , 将 configuration 标签替换为:
<configuration> <!-- Site specific YARN configuration properties --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name> <value>org.apache.hadoop.mapred.ShuffleHandler</value> </property> <property> <name>yarn.resourcemanager.address</name> <value>127.0.0.1:8032</value> </property> <property> <name>yarn.resourcemanager.scheduler.address</name> <value>127.0.0.1:8030</value> </property> <property> <name>yarn.resourcemanager.resource-tracker.address</name> <value>127.0.0.1:8035</value> </property> <property> <name>yarn.resourcemanager.admin.address</name> <value>127.0.0.1:8033</value> </property> <property> <name>yarn.resourcemanager.webapp.address</name> <value>127.0.0.1:8088</value> </property> </configuration>
10.编辑 slaves 文件,将里面的内容替换为(貌似默认就是这个,我改动了好多次了不记得了,确保是这个吧)
localhost
注意:
如果 hadoop 配置集群,可以将配置文件 etc/hadoop 下内容同步到其他机器上,并修改 slaves 文件
scp -r hadoop root@另一台机器名:/Library/hadoop/etc
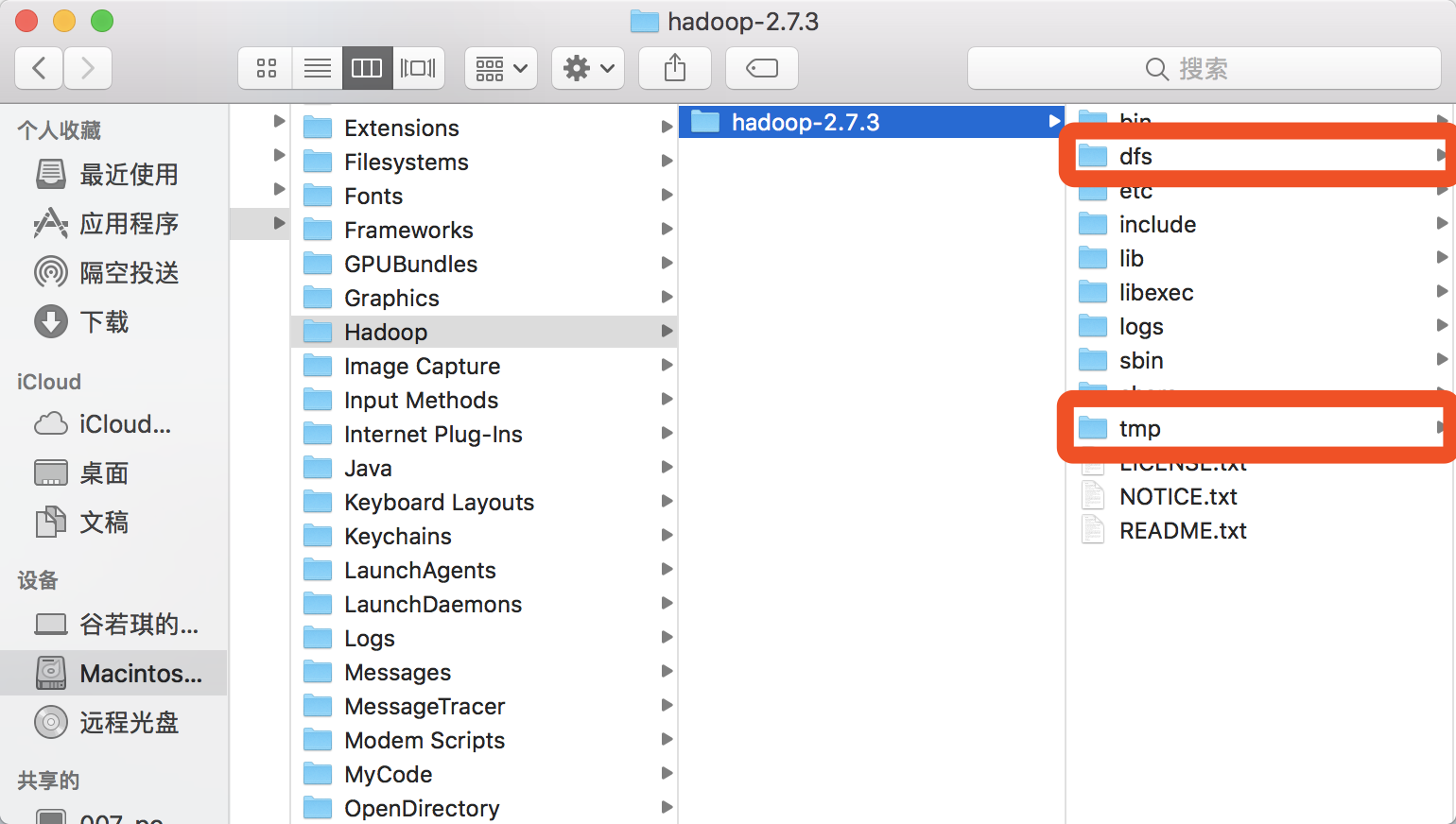
11.回到 /Library/Hadoop/hadoop-2.7.3 目录下,在该目录里面建立两个文件夹 tmp dfs ,如下图所示:
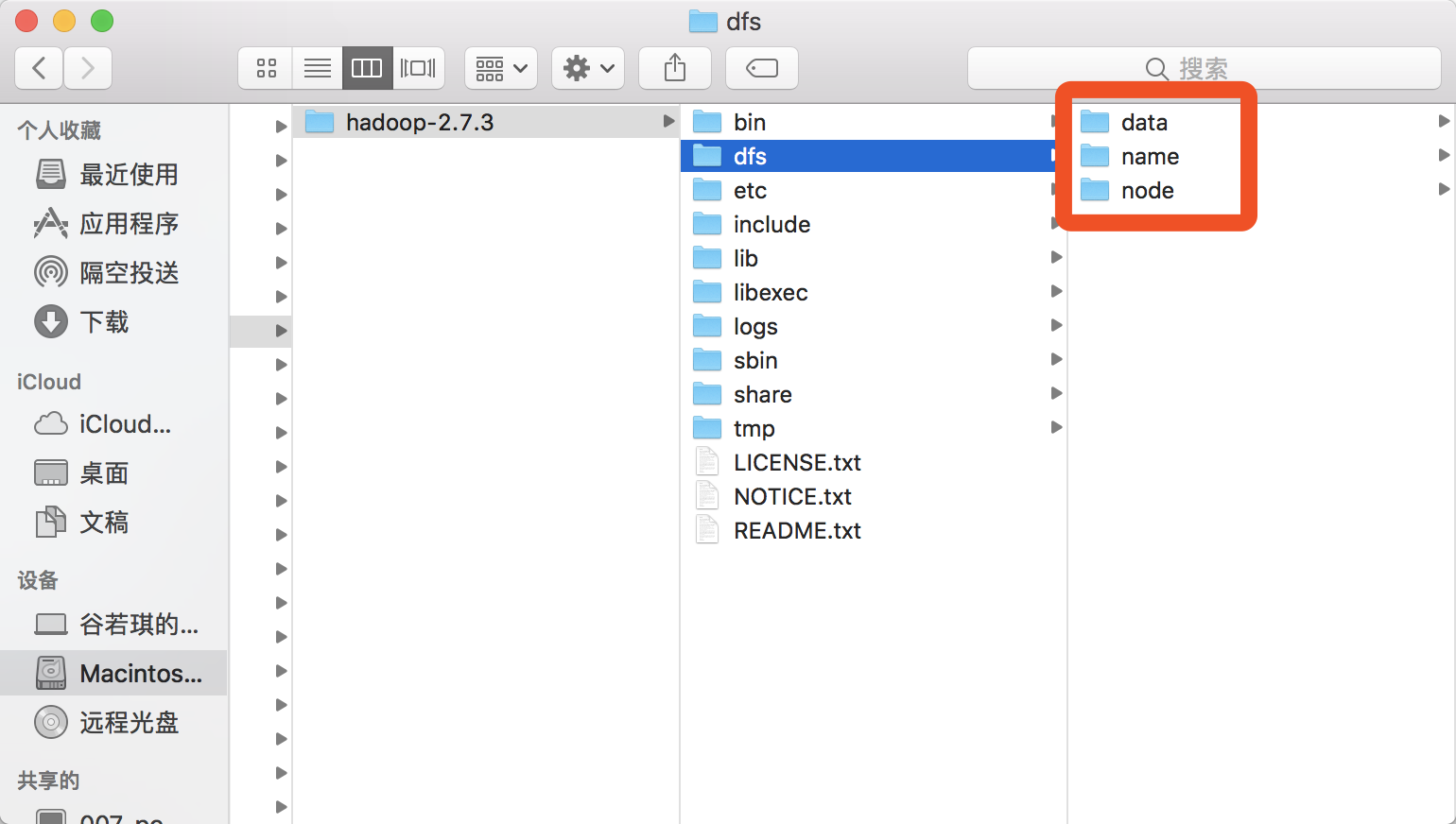
12.在dfs文件夹里面,建立三个文件夹 name node data , 如下图所示:
13.打开终端,定位到 /Library/Hadoop/hadoop-2.7.3/bin 这一级目录:
cd /Library/Hadoop/hadoop-2.7.3/bin
14.这一步是为了格式化一个新的hdfs系统,分配namenode,在终端里面输入:
./hadoop namenode –format
注意:
如果这一步不成功的话,比如出现以下提示(我特么在这里困了好久):
hadoop nodename nor servname provided, or not known
或者出现杂七杂八其他的错误提示,(不同的错误请根据提示,看你是namenode配置那里,即slaves里面配置的,还有各个配置文件里面的127.0.0.1这里的配置出错呢,还是别的什么地方出错,这里坑很多,加油...)
再或者你需要从新格式化一个新的hdfs系统,分配新的namenode的话,
请务必删除掉第10步创建的tmp和dfs文件夹,再从新创建,
因为hadoop 格式化只可进行一次,多次格式化会造成 namenode 结点和 datanode 结点配置文件中 ID 不统一,造成启动 hadoop 后 Namenode 等结点缺失,无法访问 hdfs 数据的问题
14,截止第13步,其实Hadoop配置已经完成了,接下来是启动,在终端定位到 /Library/Hadoop/hadoop-2.7.3/sbin 这个路径下:
cd /Library/Hadoop/hadoop-2.7.3/sbin
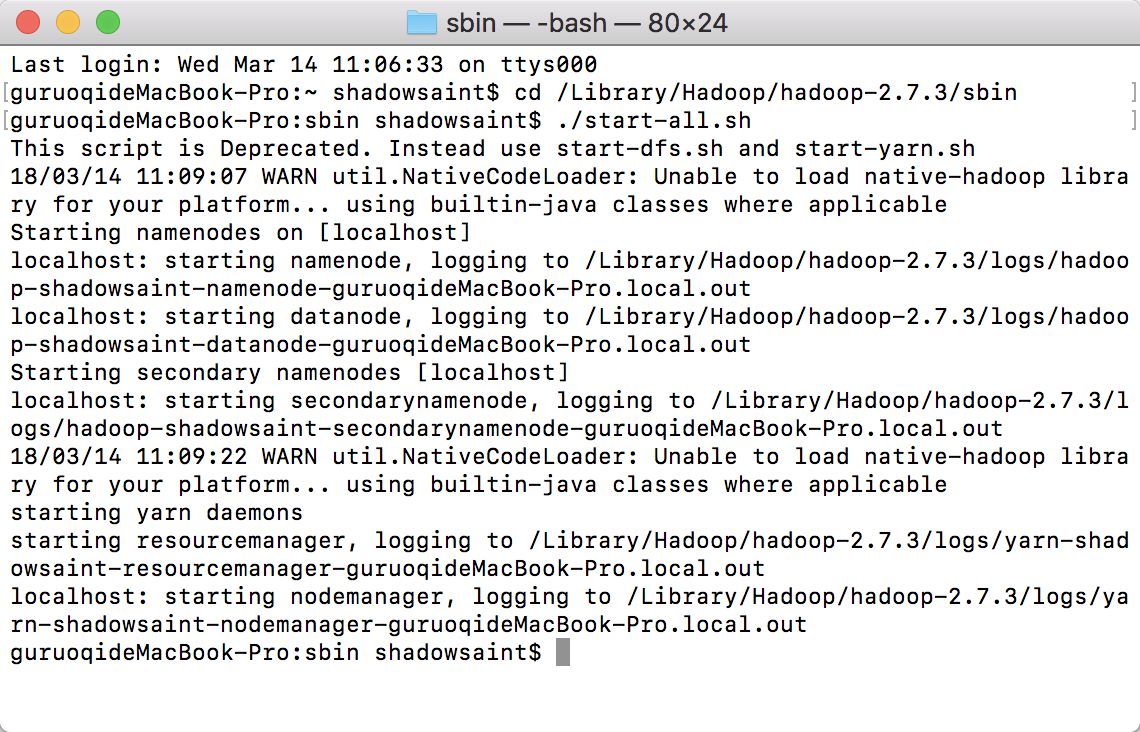
输入以下代码启动:
./start-all.sh
看到如下图所示的东西即为启动成功:
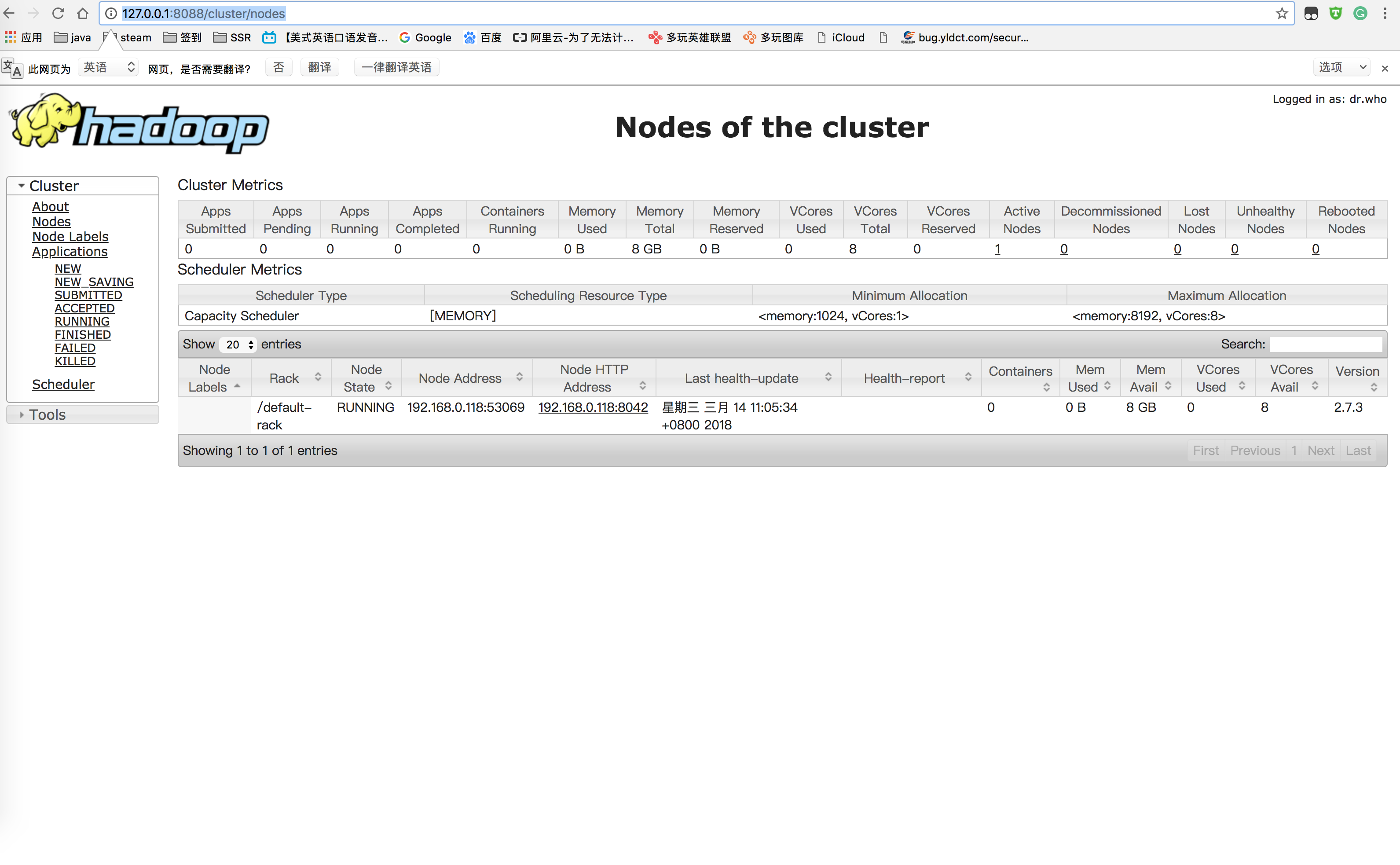
在浏览器输入:
http://127.0.0.1:8088/cluster/nodes
即可看到活动的node节点,如下图所示:
好啦,全部完成了,想要关闭Hadoop的话,就还是在sbin的目录下,输入:
./stop-all.sh

 浙公网安备 33010602011771号
浙公网安备 33010602011771号