
深度学习入门 基于Python的理论与实现
深度学习入门 基于Python的理论与实现
感知机
由美国学者Frank Rosenblatt在1957年提出,是作为神经网络(深度学习)的起源的算法。
感知机接收多个输入信号,输出一个信号
信号只有0和1两种取值
感知机将输入信号乘以相应的权重后求和,若大于阈值则输出1,否则输出0
若用代表输入信号,代表输出信号,表示权重,表示阈值则感知机的数学表达式为
感知机的实现
若将上式中的阈值换成, 得到带偏置的感知机
感知机的局限性
单层感知机只能表示(或者说分离)线性空间,想表达非线性空间需要用到组合感知机(叠加层)
多层感知机
叠加了多层的感知机称为多层感知机
多层感知机可以表示计算机
神经网络
神经网络由三部分组成
- 输入层
- 中间层(隐藏层)
- 输出层
激活函数
激活函数是连接感知机和神经网络的桥梁
激活函数包括阶跃函数、sigmoid函数等
神经网络通常使用sigmoid函数作为激活函数
sigmoid函数
阶跃函数的实现(支持Numpy数组)
def step_function(x):
y = x > 0 # 将数组中元素与阈值比较,生成布尔型数组
return y.astype(np.int) # 将布尔型数组转换成0/1数组
sigmoid函数与阶跃函数的比较
- 阶跃函数的输出在阈值两侧急剧变化;sigmoid函数具有平滑性
- 阶跃函数的输出只有0/1;sigmoid函数的输出具有连续性
为了发挥叠加层带来的优势,神经网络的激活函数必须使用非线性函数
RELU(Rectified Linear Unit)函数
数学表达式
代码实现
def relu(x):
return np.maximum(0, x)
多维数组的运算
多维数组
数字排成N维状的集合
二维数组也称为矩阵(matrix),数组的横向排列称为行(row), 纵向排列称为列(column)
矩阵乘法
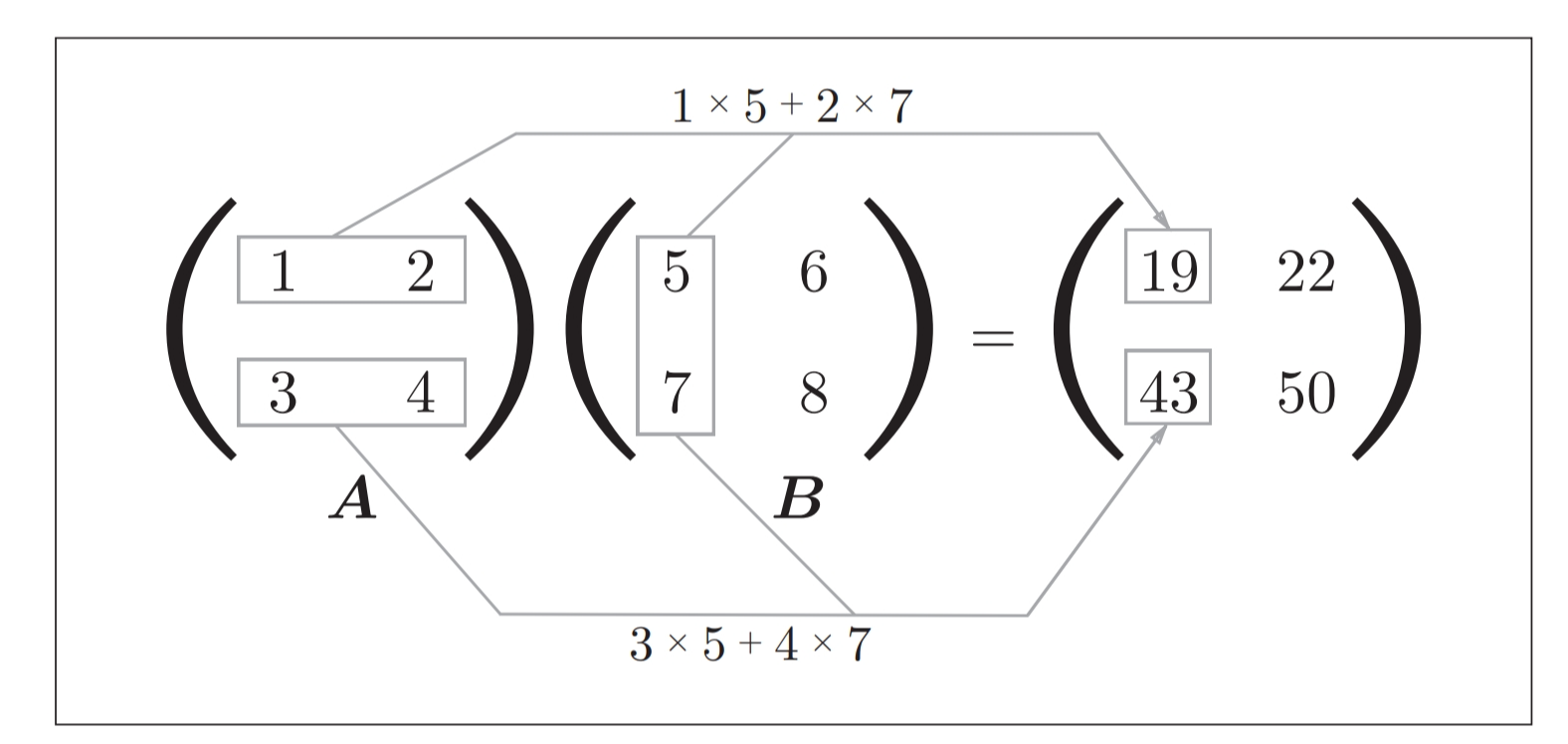
m行n列的矩阵A可以和n行p列的矩阵B相乘,结果是m行p列的矩阵
神经网络的内积
通过矩阵的乘积可以一次性完成运算
输出层的设计
一般而言,回归问题用恒等函数,分类问题用softmax函数
机器学习的问题大致可以分为分类问题和回归问题。分类问题是数据属于哪一个类别的问题。比如,区分图像中的人是男性还是女性 的问题就是分类问题。而回归问题是根据某个输入预测一个(连续的)数值的问题。比如,根据一个人的图像预测这个人的体重的问题就是回归问题(类似“57.4kg”这样的预测)
恒等函数
恒等函数会将输入按原样输出
softmax函数
数学表达式
其中为输入信号
实现
def softmax(a):
C = np.max(a)
exp_a = np.exp(a - C) # 防止溢出
sum_exp_a = np.sum(exp_a)
y = exp_a / sum_exp_a
return y
特征
- softmax函数的输出总是0.0到1.0之间的实数
- 输出的总和是1
ℹ️神经网络在进行分类时,输出层的softmax函数可以省略。[1]
输出层的神经元数量
输出层的神经元数量需要根据待解决的问题来定
对于分类问题,输出层的神经元数量一般设定为类别的数量
手写数字识别
神经网络的推理也被称为神经网络的前向传播(forward propagation)
MNIST数据集
由0到9的数字图像构成,训练图像6万张,测试图像1万张
图像数据是28像素28像素的灰度通道(1通道),各个通道的取值在0到255之间。每个图像数据都相应地标有标签
加载数据
import sys, os
sys.path.append(os.pardir) # 为了导入父目录中的文件
from dataset.mnist import load_mnist # 下载数据集或读取本地pickle文件
(x_train, t_train), (x_test, t_test) = load_mnist(flatten=True,
normalize=False) # 以(训练图像 ,训练标签 ),(测试图像,测试标签 )形式返回数据
Python有pickle这个便利的功能。这个功能可以将程序运行中的对象保存为文件。如果加载保存过的pickle文件,可以立刻复原之前程序运行中的对象。用于读入MNIST数据集的load_mnist()函数内部也使用了 pickle功能(在第2次及以后读入时)。利用 pickle功能, 可以高效地完成MNIST数据的准备工作
显示图像
图像的显示使用PIL(Python Image Library)
import sys, os
sys.path.append(os.pardir)
import numpy as np
from dataset.mnist import load_mnist
from PIL import Image
def img_show(img):
pil_img = Image.fromarray(np.uint8(img)) # 将Numpy数组转换为PIL用的数据对象
pil_img.show()
(x_train, t_train), (x_test, t_test) = load_mnist(flatten=True,
normalize=False)
img = x_train[0]
label = t_train[0]
print(label) # 5
print(img.shape) # (784,)
img = img.reshape(28, 28) # 把图像的形状变成原来的尺寸
print(img.shape) # (28, 28)
img_show(img)
神经网络的推理
获取数据
def get_data():
(x_train, t_train), (x_test, t_test) = \
load_mnist(noramlize=True, flatten=True, one_hot_label=False) # 预处理:将数据正规化、展开成一维、不使用one hot标签
return x_test, t_test
生成网络
def init_network():
with open("sample_weight.pkl", 'rb') as f:
network = pickle.load(f)
return network
分类
def predict(network, x):
W1, W2, W3 = network['W1'], network['W2'], network['W3']
b1, b2, b3 = network['b1'], network['b2'], network['b3']
a1 = np.dot(x, W1) + b1
z1 = sigmoid(a1)
a2 = np.dot(z1, W2) + b2
z2 = sigmoid(a2)
a3 = np.dot(z2, W3) + b3
y = softmax(a3)
return y
用这3个函数来实现神经网络的推理,并评估识别精度(accuracy, acc)
x, t = get_data()
network = init_network()
accuracy_cnt = 0
for i in range(len(x)):
y = predict(network, x[i])
p = np.argmax(y) # 获取概率最高的元素的索引
if p == t[i]:
accuracy_cnt += 1
print("Accuracy:" + str(float(accuracy_cnt) / len(x)))
批处理
打包输入的数据称为批(batch)
批处理可以缩短图像的处理时间[2]
代码实现
x, t = get_data()
network = init_network()
batch_size = 100 # 批数量
accuracy_cnt = 0
for i in range(0, len(x), batch_size):
x_batch = x[i:i+batch_size] # 从输入数据中抽出批数据
y_batch = predict(network, x_batch)
p = np.argmax(y_batch, axis=1)
accuracy_cnt += np.sum(p == t[i:i+batch_size])
print("Accuracy:" + str(float(accuracy_cnt) / len(x)))
神经网络的学习
从数据中学习
有两种方法
- 先从图像中提取特征量,再用机器学习技术学习这些特征量的模式
- 由神经网络从收集到的数据中直接找出规律性
深 度 学 习 有 时 也 称 为 端 到 端 机 器 学 习(end-to-end machine learning)。这里所说的端到端是指从一端到另一端的意思,也就是 从原始数据(输入)中获得目标结果(输出)的意思。
测试数据和训练数据
在机器学习中一般分为训练数据和测试数据两部分,训练数据也可以称为监督数据
泛化能力是指处理未被观察过的数据(不包含在训练数据中的数据)的能力。获得泛化能力是机器学习的最终目标。
只对某个数据集过度拟合的状态称为过拟合(over fitting)。
损失函数
神经网络学习时以某个指标为线索寻找最优权重参数。神经网络学习时所用的指标称为损失函数(loss function)。
损失函数可以使用任意函数,但一般用均方误差和交叉熵误差等。
均方误差(mean squared error)
数学表达式
表示神经网络的输出,表示监督数据,表示数据的维数
将正确解的标签表示为1,其他标签表示为0的表示方法称为one-hot表示
实现
def mean_squared_error(y, t):
return 0.5 * np.sum((y - t) ** 2)
交叉熵误差(cross entropy error)
数学表达式
是神经网络的输出,是正确解标签的one-hot表示
实现
# one-hot形式
def cross_entropy_error(y, t):
delta = 1e - 7 # 防止np.log(0)
return -np.sum(t * np.log(y + delta))
# 标签形式
def cross_entropy_error(y, t):
if y.ndim == 1:
t = t.reshape(1, t.size)
y = y.reshape(1, y.size)
batch_size = y.shape[0]
return -np.sum(np.log(y[np.arange(batch_size), t] + 1e-7)) / batch_size # np.arange(batch_size)会生成一个从0到batch_size-1的数组。
mini-batch学习
从学习数据中选出一小批(mini-batch),然后对每个mini-batch进行学习的方式
batch_mask = np.random.choice(train_size, batch_size) # 从指定范围内抽取指定数量的数据
数值微分
利用微小的差分求导的方法称为数值微分(numerical differentiation)
基于数学式的推导求导数的过程,则用“解析性”(analytic)一词,称为“解析性求解”或者“解析性求导”。
解析性求导得到的导数是不含误差的“真的导数”
偏导数
有多个变量的函数的导数称为偏导数
偏导数需要将多个变量中的某一个变量定为目标变量,并将其他变量固定为 某个值。
梯度
像这样的由全部变量的偏导数汇总而成的向量称为梯度(gradient)
梯度指示的方向是各点的函数值减小最多的方向
实现
def numerical_gradient(f, x):
h = 1e-4 # 0.0001
grad = np.zeros_like(x) # 生成和x形状相同的数组
for idx in range(x.size):
tmp_val = x[idx]
# f(x+h)的计算
x[idx] = tmp_val + h
fxh1 = f(x)
# f(x-h)的计算
x[idx] = tmp_val - h
fxh2 = f(x)
grad[idx] = (fxh1 - fxh2) / (2*h)
x[idx] = tmp_val # 还原值
return grad
梯度下降法
梯度下降法是一种用于求解损失函数最小化问题的优化算法
其基本思想是沿着目标函数的梯度方向,以固定的学习率,不断迭代更新模型参数,使损失函数的值不断减小
数学表达式
式中的为学习率(learning rate)
像学习率这样的参数称为超参数。这是一种和神经网络的参数(权重 和偏置)性质不同的参数。相对于神经网络的权重参数是通过训练 数据和学习算法自动获得的,学习率这样的超参数则是人工设定的。 一般来说,超参数需要尝试多个值,以便找到一种可以使学习顺利 进行的设定。
实现
def gradient_descent(f, init_x, lr=0.01, step_num=100):
x = init_x
for i in range(step_num):
grad = numerical_gradient(f, x)
x -= lr * grad
return x
神经网络的梯度
这里所说的梯度是指损失函数关于权重参数的梯度。
若损失函数用L表示,权重为W,梯度可以用表示
学习算法的实现
学习步骤
- mini-batch
- 计算梯度
- 更新参数(SGD, 随机梯度下降法)
- 重复
两层神经网络的学习
import sys, os
sys.path.append(os.pardir)
from common.functions import *
from common.gradient import numerical_gradient
class TwoLayerNet:
def __init__(self, input_size, hidden_size, output_size,
weight_init_std=0.01):
# 初始化权重
self.params = {}
self.params['W1'] = weight_init_std * \
np.random.randn(input_size, hidden_size)
self.params['b1'] = np.zeros(hidden_size)
self.params['W2'] = weight_init_std * \
np.random.randn(hidden_size, output_size)
self.params['b2'] = np.zeros(output_size)
def predict(self, x):
W1, W2 = self.params['W1'], self.params['W2']
b1, b2 = self.params['b1'], self.params['b2']
a1 = np.dot(x, W1) + b1
z1 = sigmoid(a1)
a2 = np.dot(z1, W2) + b2
y = softmax(a2)
return y
# x:输入数据, t:监督数据
def loss(self, x, t):
y = self.predict(x)
return cross_entropy_error(y, t)
def accuracy(self, x, t):
y = self.predict(x)
y = np.argmax(y, axis=1)
t = np.argmax(t, axis=1)
accuracy = np.sum(y == t) / float(x.shape[0])
return accuracy
# x:输入数据, t:监督数据
def numerical_gradient(self, x, t):
loss_W = lambda W: self.loss(x, t)
grads = {}
grads['W1'] = numerical_gradient(loss_W, self.params['W1'])
grads['b1'] = numerical_gradient(loss_W, self.params['b1'])
grads['W2'] = numerical_gradient(loss_W, self.params['W2'])
grads['b2'] = numerical_gradient(loss_W, self.params['b2'])
return grads
epoch是一个单位。一个 epoch表示学习中所有训练数据均被使用过 一次时的更新次数。比如,对于 10000笔训练数据,用大小为 100 笔数据的mini-batch进行学习时,重复随机梯度下降法 100次,所 有的训练数据就都被“看过”了A。此时,100次就是一个 epoch。
误差反向传播法
通过计算损失函数对每个参数的梯度,反向更新参数的值
误差反向传播法基于求导的链式法则,只需要每个节点局部计算,因此比数值微分法效率高
误差反向传播法的实现
加法层
class AddLayer:
def __init__(self):
pass
def forward(self, x, y):
out = x + y
return out
def backward(self, dout):
dx = dout * 1
dy = dout * 1
return dx, dy
乘法层
class MulLayer:
def __init__(self):
self.x = None
self.y = None
def forward(self, x, y):
self.x = x
self.y = y
out = x * y
return out
def backward(self, dout):
dx = dout * self.y # 翻转x和y
dy = dout * self.x
return dx, dy
激活函数层
RELU函数
class Relu:
def __init__(self):
self.mask = None
def forward(self, x):
self.mask = (x <= 0)
out = x.copy()
out[self.mask] = 0
return out
def backward(self, dout):
dout[self.mask] = 0
dx = dout
return dx
sigmoid函数
class Sigmoid:
def __init__(self):
self.out = None
def forward(self, x):
out = 1 / (1 + np.exp(-x))
self.out = out
return out
def backward(self, dout):
dx = dout * (1.0 - self.out) * self.out
return dx
Affine层
# 批版本的Affine
class Affine:
def __init__(self, W, b):
self.W = W
self.b = b
self.x = None
self.dW = None
self.db = None
def forward(self, x):
self.x = x
out = np.dot(x, self.W) + self.b
return out
def backward(self, dout):
dx = np.dot(dout, self.W.T)
self.dW = np.dot(self.x.T, dout)
self.db = np.sum(dout, axis=0)
return dx
Softmax-with-Loss 层
class SoftmaxWithLoss:
def __init__(self):
self.loss = None # 损失
self.y = None # softmax的输出
self.t = None # 监督数据(one-hot vector)
def forward(self, x, t):
self.t = t
self.y = softmax(x)
self.loss = cross_entropy_error(self.y, self.t)
return self.loss
def backward(self, dout=1):
batch_size = self.t.shape[0]
dx = (self.y - self.t) / batch_size
return dx
误差反向传播法的梯度确认
确认数值微分求出的梯度结果和误差反向传播法求出的结果是否一致(严格地讲,是非常相近)的操作称为梯度确认(gradient check)。
与学习相关的技巧
参数的更新方法
-
随机梯度下降(SGD)
以固定学习率学习梯度更新参数
class SGD: def __init__(self, lr=0.01): self.lr = lr def update(self, params, grads): for key in params.keys(): params[key] -= self.lr * grads[key] -
Momentum(动量)
借鉴物理中动量的概念,减小与最小值无关的参数更新
class Momentum: def __init__(self, lr=0.01, momentum=0.9): self.lr = lr self.momentum = momentum self.v = None def update(self, params, grads): if self.v is None: self.v = {} for key, val in params.items(): self.v[key] = np.zeros_like(val) for key in params.keys(): self.v[key] = self.momentum*self.v[key] - self.lr*grads[key] params[key] += self.v[key] -
AdaGrad
为每个元素调整学习率[3]
class AdaGrad: def __init__(self, lr=0.01): self.lr = lr self.h = None def update(self, params, grads): if self.h is None: self.h = {} for key, val in params.items(): self.h[key] = np.zeros_like(val) for key in params.keys(): self.h[key] += grads[key] * grads[key] params[key] -= self.lr * grads[key] / (np.sqrt(self.h[key]) + 1e-7) -
Adam
结合了Momentum和AdaGrad两种方法
权重的初始值
-
随机生成
初始值满足高斯分布
-
Xavier初始值
如果前一层节点数为n,初始值使用标准差为的分布
用作激活函数的函数最好具有关于原点对称的性质。
-
He初始值
仅当激活函数为RELU函数时,使用标准差为的高斯分布
Batch Normalization
调整各层的激活值分布使其拥有适当的广度
正则化
能抑制过拟合
过拟合
发生过拟合的原因
- 模型拥有大量参数,表现能力强
- 训练数据少
权值衰减
很多过拟合是因为权重参数取值过大发生的
权值衰减通过对大的权值进行惩罚,来抑制过拟合
L2范数
为损失函数加上, 为权重梯度加上
Dropout
在学习过程中,随机删除神经元
可以通过一个网络实现集成学习的效果
class Dropout:
def __init__(self, dropout_ratio=0.5):
self.dropout_ratio = dropout_ratio
self.mask = None
def forward(self, x, train_flg=True):
if train_flg:
self.mask = np.random.rand(*x.shape) > self.dropout_ratio
return x * self.mask
else:
return x * (1.0 - self.dropout_ratio)
def backward(self, dout):
return dout * self.mask
超参数的验证
调整超参数时,必须使用专用的验证数据,并在最后使用测试数据
常用方法是从数据集中分割一部分作为验证数据
(x_train, t_train), (x_test, t_test) = load_mnist()
# 打乱训练数据
x_train, t_train = shuffle_dataset(x_train, t_train)
# 分割验证数据
validation_rate = 0.20
validation_num = int(x_train.shape[0] * validation_rate)
x_val = x_train[:validation_num]
t_val = t_train[:validation_num]
x_train = x_train[validation_num:]
t_train = t_train[validation_num:]
超参数的最优化
-
设定超参数的范围。
-
从设定的超参数范围中随机采样。
-
使用步骤 1 中采样到的超参数的值进行学习,通过验证数据评估识别精度(但是要将 epoch 设置得很小)。
-
重复步骤 1 和步骤 2(100 次等),根据它们的识别精度的结果,缩小超参数的范围。
(x_train, t_train), (x_test, t_test) = load_mnist(normalize=True)
# 为了实现高速化,减少训练数据
x_train = x_train[:500]
t_train = t_train[:500]
# 分割验证数据
validation_rate = 0.20
validation_num = int(x_train.shape[0] * validation_rate)
x_train, t_train = shuffle_dataset(x_train, t_train)
x_val = x_train[:validation_num]
t_val = t_train[:validation_num]
x_train = x_train[validation_num:]
t_train = t_train[validation_num:]
def __train(lr, weight_decay, epocs=50):
network = MultiLayerNet(input_size=784, hidden_size_list=[100, 100, 100, 100, 100, 100],
output_size=10, weight_decay_lambda=weight_decay)
trainer = Trainer(network, x_train, t_train, x_val, t_val,
epochs=epocs, mini_batch_size=100,
optimizer='sgd', optimizer_param={'lr': lr}, verbose=False)
trainer.train()
return trainer.test_acc_list, trainer.train_acc_list
# 超参数的随机搜索======================================
optimization_trial = 100
results_val = {}
results_train = {}
for _ in range(optimization_trial):
# 指定搜索的超参数的范围===============
weight_decay = 10 ** np.random.uniform(-8, -4)
lr = 10 ** np.random.uniform(-6, -2)
# ================================================
val_acc_list, train_acc_list = __train(lr, weight_decay)
print("val acc:" + str(val_acc_list[-1]) + " | lr:" + str(lr) + ", weight decay:" + str(weight_decay))
key = "lr:" + str(lr) + ", weight decay:" + str(weight_decay)
results_val[key] = val_acc_list
results_train[key] = train_acc_list
更精密的方法有贝叶斯最优化等
卷积神经网络
整体结构
卷积神经网络在普通神经网络的基础上多了卷积层和池化层
卷积层
卷积层对输入数据进行卷积运算[4], 即以一定的间隔滑动滤波器进行乘积累加运算,不同滤波器会产生不同的结果,反映了滤波器对像素点附近特征的探索与提取
填充
卷积运算会缩小数据,为了避免数据缩小导致无法继续进行卷积运算,需要对输入数据进行填充
步幅
应用滤波器的位置间隔称为步幅(stride)
增大步幅后,输出大小会变小。而增大填充后,输出大小会变大。
假设输入大小为(H, W),滤波器大小为(FH, FW),输出大小为 (OH, OW),填充为P,步幅为S。
池化层
池化层是缩小长、宽空间的运算
常用的池化有Max池化等[5]
特征
- 没有要学习的参数
- 通道数不发生改变
- 对微小的位置变化具有健壮性
卷积层和池化层的实现
四维数组
(批数, 通道数, 高度,长度)
im2col[6]
im2col是一个函数,它会将输入数据展开以适合权重
使用im2col的实现会比普通实现更加消耗内存,但可以有效地利用线性代数库加速运算
卷积层的实现
class Convolution:
def __init__(self, W, b, stride=1, pad=0):
self.W = W
self.b = b
self.stride = stride
self.pad = pad
def forward(self, x):
FN, C, FH, FW = self.W.shape
N, C, H, W = x.shape
out_h = int(1 + (H + 2*self.pad - FH) / self.stride)
out_w = int(1 + (W + 2*self.pad - FW) / self.stride)
col = im2col(x, FH, FW, self.stride, self.pad)
col_W = self.W.reshape(FN, -1).T
# 滤波器的展开
out = np.dot(col, col_W) + self.b
out = out.reshape(N, out_h, out_w, -1).transpose(0, 3, 1, 2)
return out
池化层的实现
池化的情况下,在通道方向上是独立的,这一点和卷积层不同。
池化的应用区域按通道单独展开
class Pooling:
def __init__(self, pool_h, pool_w, stride=1, pad=0):
self.pool_h = pool_h
self.pool_w = pool_w
self.stride = stride
self.pad = pad
def forward(self, x):
N, C, H, W = x.shape
out_h = int(1 + (H - self.pool_h) / self.stride)
out_w = int(1 + (W - self.pool_w) / self.stride)
# 展开(1)
col = im2col(x, self.pool_h, self.pool_w, self.stride, self.pad)
col = col.reshape(-1, self.pool_h*self.pool_w)
# 最大值(2)
out = np.max(col, axis=1)
# 转换(3)
out = out.reshape(N, out_h, out_w, C).transpose(0, 3, 1, 2)
return out
CNN的可视化
权重的可视化
卷积层的滤波器会提取边缘或斑块等原始信息
基于分层结构的信息提取
如果堆叠了多层卷积层,则随着层次加深,提取的信息也愈加复杂、抽象
随着层次加深,神经元从简单的形状向“高级”信息变化
具有代表性的CNN
LeNet
LeNet 有几个不同点。第一个不同点在于激活函数。LeNet 中使用 sigmoid 函数,而现在的 CNN 中主要使用 ReLU 函数。此外,原始的 LeNet 中使用子采样(subsampling)缩小中间数据的大小,而现在的 CNN 中 Max 池化是主流。
AlexNet
AlexNet 叠有多个卷积层和池化层,最后经由全连接层输出结果。虽然结构上 AlexNet 和 LeNet 没有大的不同,但有以下几点差异。
-
激活函数使用 ReLU。
-
使用进行局部正规化的 LRN(Local Response Normalization)层。
-
使用 Dropout(6.4.3 节)
深度学习
加深网络
加深层的好处
- 减少参数数量
- 减少学习数据,使学习更加高效
深度学习的高速化
基于GPU的高速化
GPU更擅长大量的并行计算(矩阵计算)
分布式学习
将深度学习的学习过程扩展开,缩短一次学习所需时间
运算精度的位数缩减
由于神经网络的健壮性,可以缩减数值精度,使用16位的半精度浮点数进行计算
深度学习的应用
- 物体检测
- 图像分割
- 图像标题生成
深度学习的未来
- 图像风格变换
- 图像生成
- 自动驾驶
- Deep Q-Network(强化学习)
一般而言,神经网络只把输出值最大的神经元所对应的类别作为识别结果。并且,即便使用softmax函数,输出值最大的神经元的位置也不会变。在实际的问题中,由于指数函数的运算需要一定的计算机运算量,因此输出层的softmax函数一般会被省略。 ↩︎
这是因为大多数处理 数值计算的库都进行了能够高效处理大型数组运算的最优化。并且, 在神经网络的运算中,当数据传送成为瓶颈时,批处理可以减轻数据总线的负荷(严格地讲,相对于数据读入,可以将更多的时间用在计算上)。也就是说,批处理一次性计算大型数组要比分开逐步计算 各个小型数组速度更快。 ↩︎
AdaGrad会记录过去所有梯度的平方和。因此,学习越深入,更新的幅度就越小。实际上,如果无止境地学习,更新量就会变为0,完全不再更新。为了改善这个问题,可以使用RMSProp方法。RMSProp方法并不是将过去所有的梯度一视同仁地相加,而是逐渐地遗忘过去的梯度,在做加法运算时将新梯度的信息更多地反映出来。这种操作从专业上讲,称为“指数移动平均”,呈指数函数式地减小过去的梯度的尺度。 ↩︎
卷积运算指的是一个函数在另一个函数上的加权叠加 ↩︎
除了Max池化之外,还有Average池化等。相对于Max池化是从 目标区域中取出最大值,Average池化则是计算目标区域的平均值。 在图像识别领域,主要使用Max池化。 ↩︎
im2col这个名称是“image to column”的缩写,翻译过来就是“从图像到矩阵”的意思。 ↩︎


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)