

深度学习方法下图像分割的记录和理解
分割分类
-
普通分割
将不同类别物体的像素区域分开。
如前景与后景分割开,狗的区域与猫的区域、背景分割开。 -
语义分割
在普通分割的基础上,分类出每一块区域的语义(即这块区域是什么物体)。
如把画面中的所有物体都指出它们各自的类别。 -
实例分割
在语义分割的基础上,给每个物体编号。
如这个是该画面中的狗A,那个是画面中的狗B。
当下现状
最初,图像块分类是最常用的方法,就是根据图像像素点周围的图像块确定每个像素的类别CNN极大的提高了图像分割的精度。FCN的出现改变了这个现状,也把分割任务提升到新的阶段。现在几乎所有的语义分割都是在这个结构上改来改去的。
主要的套路如下:
- encoder-decoder结构。
- 多尺度的特征融合,空洞卷积,不同级别的上采样。
- 条件随机场(Conditional Random Field,CRF)进行后期处理
FCN
FCN是深度学习用于语义分割的鼻祖了。
FullyConvolutional Networks forSemantic Segmentation 是 UC Berkeley提出来的,也是 2015 年CVPR的best paper 。2014年11月发表在arXiv上。
FCN的主要思想如下图所说:
将原本的分类模型(AlexNet)的最后的全连接层,转化成全卷积,不在输出分类特征,而是一个热图(heatmap)。
下面FCN更详细的信息:
-
FCN-32s
在模型最后conv 7的特征图上,进行步长为32的,上采样,还原到原始图片大小。
-
FCN-16s
在pool 4 层后,加上一个1x1的卷积层,产生一个支路输出特征图A。
对conv 7的输出进行步长为 2的上采样,得到特征图B。
这时候A和B大小一样,进行特征融合,然后进行步长为16的上采样,还原到原始图片大小。
-
FCN-8s
在pool 3 层后,加上一个1x1的卷积层,产生一个支路输出特征图A。
在pool 4 层后,加上一个1x1的卷积层,输出进行步长为 2的上采样,产生一个支路输出特征图B。
对conv 7 的输出进行步长为 4 的上采样,得到特征图C。
这时候A、B、C大小一样,进行特征融合,然后进行步长为8的上采样,还原到原始图片大小。
关于上面所说的上采样:
上采样本质是插值。FCN中上采样的方法是反卷积(Deconvolution)。Caffe和Kera里叫Deconvolution,而tensorflow 里叫 conv_transpose。论文中,作者说反卷积的卷积核是可以学习的,但是代码中并没有学习,lr_mult: 0。和网络前面卷积层不同,deconvolution 中卷积核个数不是随机的,而是根据放大的尺寸生成了与类别相同数量的矩阵。
论文中采用的上采样是双线性内插,通过卷积操作完成的。先上池化,然后卷积。如下图:(蓝色是输入,蓝绿色是输出)
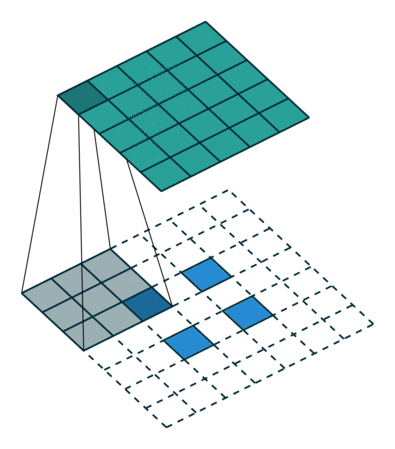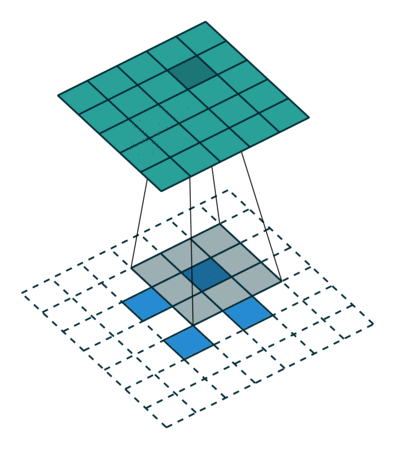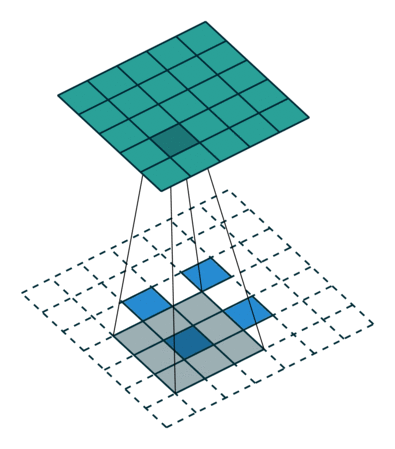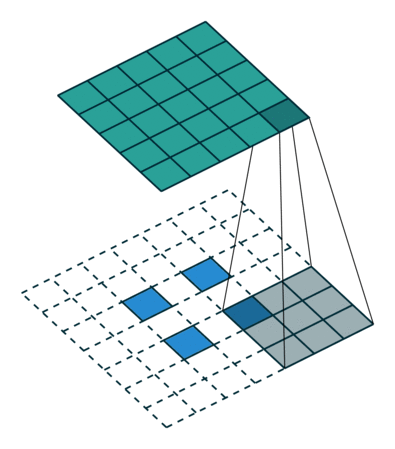
DeconvNet
是韩国的Hyeonwoo Noh 在 ICCV 2015 的文章。2015年5月17日发表在arXiv上的文章。Learning Deconvolution Network for Semantic Segmentation是对FCN的改进。
DeconvNet 的结构是经典encoder-decoder结构。相比于FCN有点混乱的结构,这种对称的结构就显得很优雅。如下图:
前面的encoder部分是VGG-16去掉分类部分的前13个卷积层,末尾是2个全连接层。Decoder部分是对称的反卷积层。
有两点比较独特:
- 在 pooling 处理的过程中会记录最大值位置,unpooling 的时候会把相应的值放回到原来位置。
- 作者强调他们的反卷积网络权重是学习的。
SegNet
SegNet: A Deep Convolutional Encoder-Decoder Architecture for Robust Semantic Pixel-Wise Labelling
这是和DeconvNet 同期的模型,是Vijay Badrinarayanan在2015年5月27日(仅仅相差10天)发表在arXiv上的。
结构和DeconvNet十分相似,给人一种撞衫的感觉。(可见科研的激烈程度,23333)
相同的两点:
-
都是经典encoder-decoder结构,encoder部分都是根据VGG-16来的。
-
pooling 过程都记录了位置信息,upsampling 的时候使用位置信息。如下图:
不同点:
- 仔细看,SegNet在encoder-decoder中间没有deconvNet的两个全连接层。
- SegNet 在卷积层上加了BN结构。
知乎上有网友的评价:
segnet去掉了全连接层从而提升了速度,加了batch normalization加快了收敛抑制了过拟合,加了bayesion可以输出图像的不确定性分割数值,加了test batch dropout提升测试时的性能,加了带权重softmax应对分割样本不均衡现象。可以说,segnet是更实用的框架。
Tensorflow 目前还不支持在池化的时候保留索引,这就很尴尬了。所以上面两个都只有caffe的代码。有人重现了Tensorflow版本的SegNet,不是还是和原始的有些不同。有cpu版本的可用,会比较慢。
Deeplab
DeepLab 是 Google 在这个领域一系列的工作。
-
DeepLabv1:
- 2015-04-09 发表在arXiv上
- ICLR 2015
- DeepLabv1: Semantic image segmentation with deep convolutional nets and fully connected CRFs
具体的细节:
- Deeplab v1是在vgg-16的基础上做了修改。
- 将vgg16的全连接层转为卷积
- 移除原网络最后两个池化层,使用rate=2 的空洞卷积采样
- 是在ImageNet上预训练的vgg16权重上做 finetune

-
DeepLabv2:
- 2017-05-12 发表在arXiv上
- TPAMI2017
- DeepLabv2:DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs
Deeplab v2 的具体细节:
- 用多尺度获得更好的分割效果(用ASPP)
- 提取特征的基础CNN改为ResNet
- 使用不同的学习策略

-
DeepLabv3
- 2017-12-05 发表在arXiv上
- DeepLabv3:Rethinking Atrous Convolution for Semantic Image Segmentation
具体细节:
- 这是一种更加通用的框架
- 级联了多个ResNet中的block单元
- 在ASPP中加入了BN层
- 去掉了CRF
参考链接
https://blog.csdn.net/JNingWei/article/details/73610318
https://github.com/vdumoulin/conv_arithmetic
https://www.zhihu.com/question/50349594
http://app.myzaker.com/news/article.php?pk=59633978d1f1499a4a000016
