elasticsearch Ik分词器
Ik 分词器:比较适合中文的一个分词器
分词器:把一段文字划分成一个个关键字,我们在搜索的时候会把自己的搜索信息进行分词,会把数据库中或者索引库中的数据进行分词,然后进行匹配操作。elasticsearch默认分词器是把每个字分成一个词,这显然不行,所以想使用中文,建议用IK分词器
IK:有两种算法:ik_smart(最少切分),ik_max_word(最细粒度划分)
下面看看IK的使用
1、下载安装
下载地址:https://github.com/medcl/elasticsearch-analysis-ik
2、安装
解压到elasticsearch文件中的plugins内(随便新建一个文件夹解压到里面,把压缩包删除),
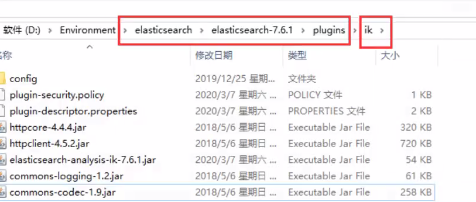
3、重启ES,观察(plugin已加载analysis-ik)

4、kibana测试


对于ik_max_word(最细粒度划分)(他会穷尽词库的可能划分),这肯定得有依据,那就是ik中的字典
那么问题来了:如果你想按照自己组的词查询怎么办?
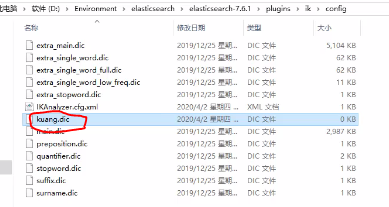
这就得用字典了,自己写一个字典然后配置到ik的配置文件内
1、新建之后,笔记本打开,输入自己的词
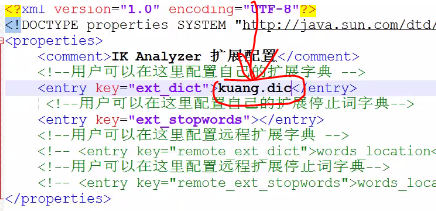
2、配置(配置文件在config内,就一个.xml文件,很好找)
3、重启es
再去测试,自己感悟 哈哈哈
如有不足 多多指教,谢谢!
文章参考:Java 狂神说

