


Windows下在eclipse中使用和操作hadoop开发,连接hadoop集群,调用API
一、前言
本案例在虚拟机下安装好linux的hadoop-2.6.5集群完全分布式(HA的),并配置好运行。Windows下安装了201803版的Eclipse、java-1.8
二、Windows下Eclipse配置hadoop插件
解压在虚拟机linux下安装的hadoop-2.6.5.tar.gz文件在D:\usr\hadoop-2.6.5\hadoop-2.6.5
1、下载eclipse插件:hadoop-eclipse-plugin-2.6.0.jar
在网上找资源,很多,感觉是随便一个版本都行,还是我运气好,下其中一个就能用,很多帖子这里也没说清楚。
2、把下载的jar包拷贝到eclipse安装目录下的plugins目录下,重新启动eclipse该插件会生效。判断插件生效的方法如图:
在Eclipse软件下Windows>>Perfrences下看到有Hadoop Map/Reduce

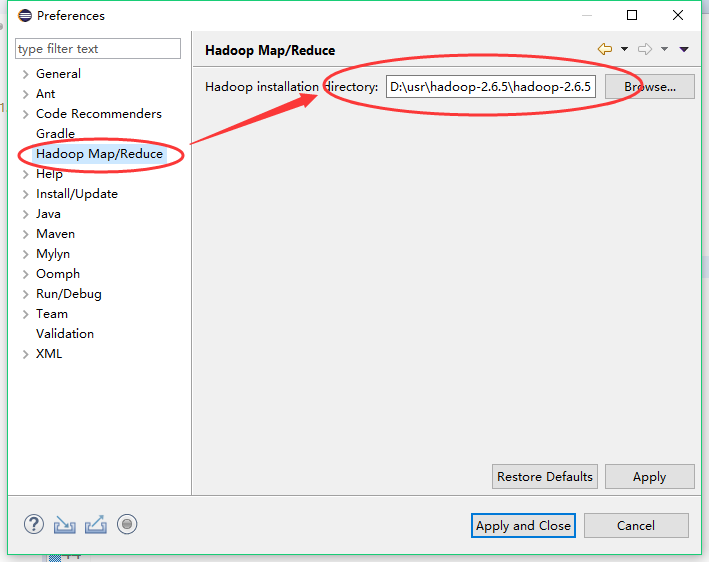
3、配置eclipse的hadoop开发模式
点击Windows>>Perfrences>>Hadoop Map/Reduce选择解压过的hadoop目录,如图选择解压的目录
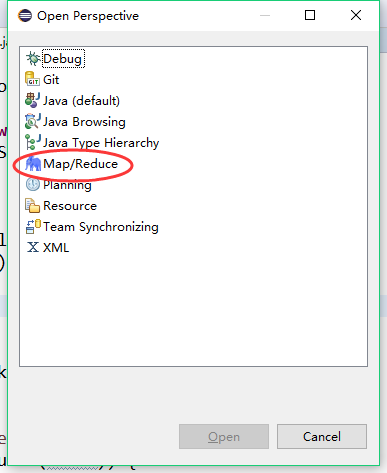
选择eclipse软件下Windows>> Perspective>>Open Perspective>>Other>>Map/Reduce,如图
选择eclipse软件下Windows>>Show View>>Other>>Map/Reduce Location,就不放图了,这图上传太麻烦了!!!!
4、添加这3个文件winutils.exe,libwinutils.lib,hadoop.dll
(1)在https://github.com/SweetInk/hadoop-common-2.7.1-bin中下载winutils.exe,libwinutils.lib 拷贝到D:\usr\hadoop-2.6.5\hadoop-2.6.5\bin目录
(2)在https://github.com/SweetInk/hadoop-common-2.7.1-bin中下载hadoop.dll,并拷贝到c:\windows\system32目录中,这里要重启电脑才生效!可以配置完后面再重启,现在重启更好了!!!
5、配置Windows下hadoop的环境变量
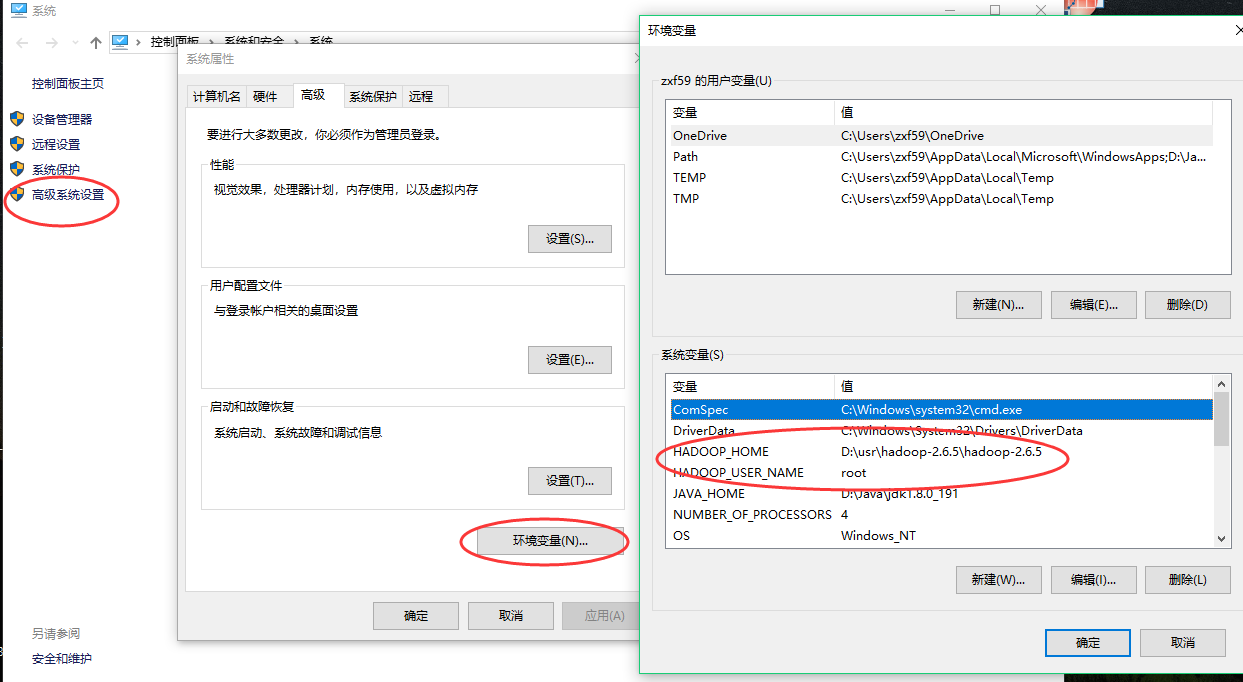
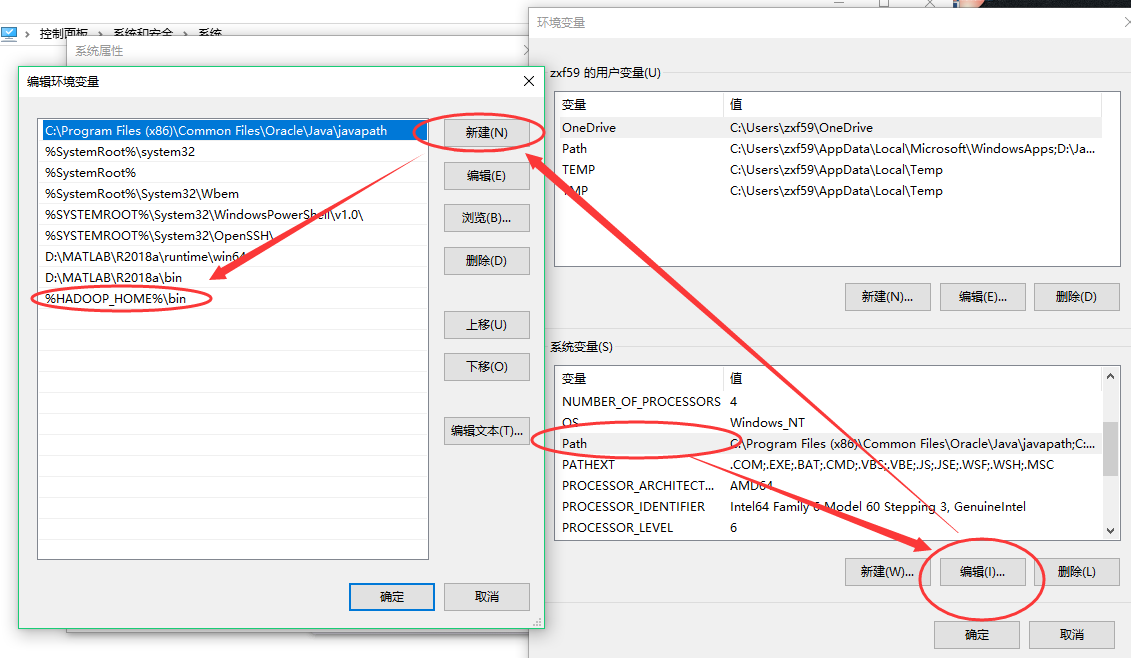
三、添加Map/Reduce Location用户端
1、新建一个Hadoop Location

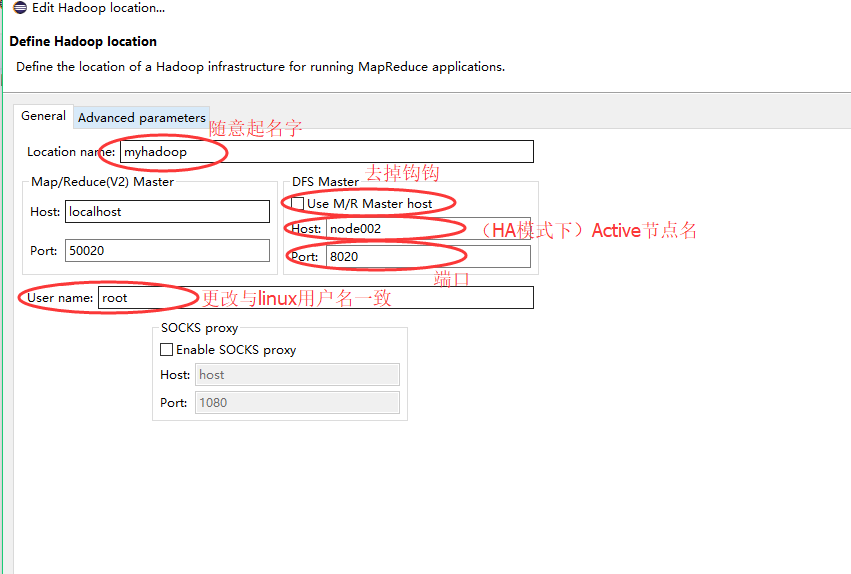
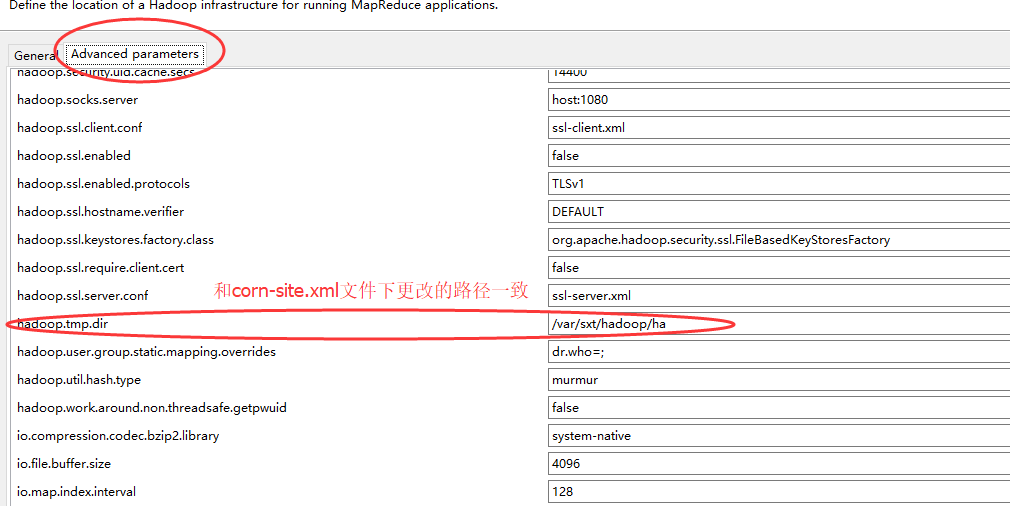
至此,算是配置连接成功了!
测试:
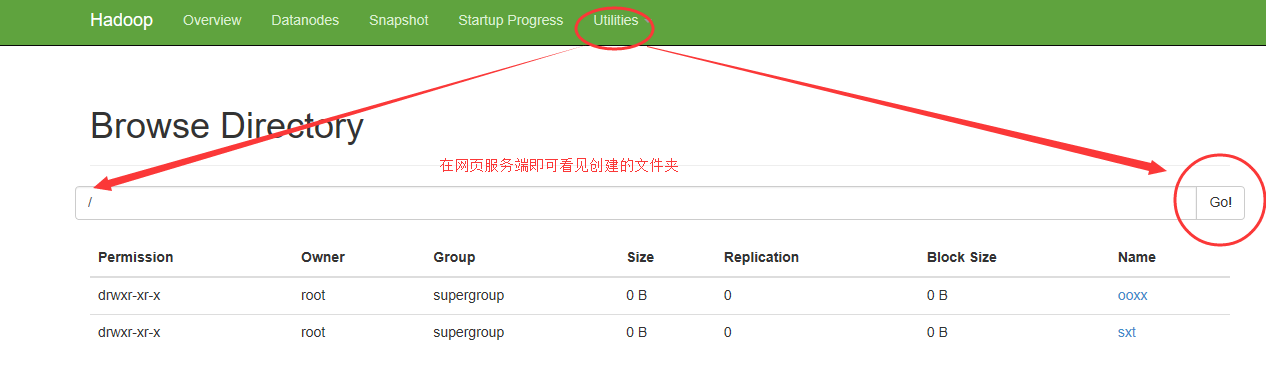
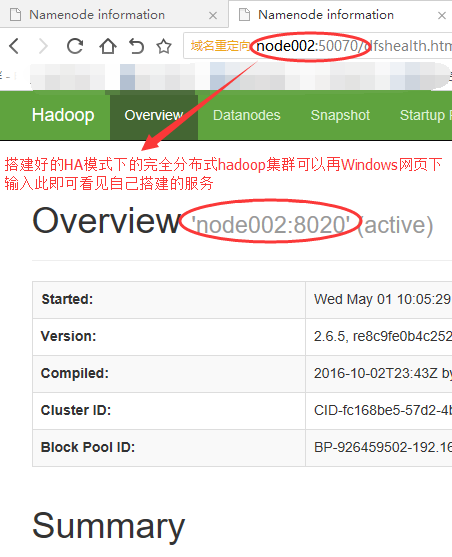
如果看见网页上显示,即打通了Windows下eclipse与虚拟机linux下的hadoop!
以下为创建客户端与hdfs交互的测试代码,带了注释应该容易看懂!
package com.sxt.hadoop.hdfs; import java.io.BufferedInputStream; import java.io.BufferedOutputStream; import java.io.File; import java.io.FileInputStream; import java.io.FileOutputStream; import java.io.InputStream; import java.io.OutputStream; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.BlockLocation; import org.apache.hadoop.fs.FSDataInputStream; import org.apache.hadoop.fs.FSDataOutputStream; import org.apache.hadoop.fs.FileStatus; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IOUtils; import org.junit.After; import org.junit.Before; import org.junit.Test; public class TestHDFS { Configuration conf; FileSystem fs; //hdfs准备了一个类可以创建一个客户端 @Before //创建一个客户端,用于与hdfs集群交互 public void conn() throws Exception { conf = new Configuration(true); //读取了两个配置文件core-site.xml、hdfs-site.xml,生成一个对象 fs = FileSystem.get(conf); //得到客户端对象,filesystem是父类,要根据core文件返回不同的子类对象 } @After public void close() throws Exception { //关闭客户端 fs.close(); } @Test public void mkdir() throws Exception { //在hdfs中创建文件夹 Path ifile = new Path("/ooxx"); if (fs.equals(ifile)) { fs .delete(ifile, true); } fs.mkdirs(ifile); } @Test public void upload() throws Exception { //把Windows下本地磁盘的文件上传到hdfs中 Path f = new Path("/ooxx/hell.txt"); FSDataOutputStream output = fs.create(f); InputStream input = new BufferedInputStream(new FileInputStream(new File("D:\\LICENSE.txt"))); IOUtils.copyBytes(input, output, conf, true); } @Test //在hdfs中下载文件写入到Windows本地磁盘中去 public void download() throws Exception { Path f = new Path("/ooxx/hell.txt"); FSDataInputStream input = fs.open(f); //用客户端fs的open函数打开f文件使用hdfs的输入流读取 //使用Windows下的io流加缓存buffer流写入本地磁盘 OutputStream output = new BufferedOutputStream(new FileOutputStream(new File("D:\\LICENSE1.txt"))); IOUtils.copyBytes(input, output, conf, true); } @Test public void blks() throws Exception { //得到一个文件的存储信息 Path f = new Path("/user/root/test.txt"); FileStatus ifile = fs.getFileStatus(f); //得到包含文件各种信息的对象 //得到这个文件从0-getlen大小的范围内组成的所有块的信息数组 BlockLocation[] blks = fs.getFileBlockLocations(ifile, 0, ifile.getLen()); for (BlockLocation b : blks) { System.out.println(b); //打印数组的每一行信息 } //怎么读取文件? FSDataInputStream in = fs.open(f); System.out.print((char)in.readByte());//读取输入流的第一个字节,为ASIC码,强转为字符 System.out.print((char)in.readByte()); System.out.print((char)in.readByte()); System.out.println("\n\n"); in.seek(1048576); //让程序从偏移量为1048576的位置开始读,这里即是第二个块开始的地方 for (int i = 0; i < 25; i++) { System.out.print((char)in.readByte()); } } }
