
Hadoop伪分布式HDFS环境搭建和使用
1.环境要求
Java版本不低于Hadoop要求,并配置环境变量
2.安装
1)在网站hadoop.apache.org下载稳定版本的Hadoop包
2)解压压缩包
检查Hadoop是否可用
hadoop/bin/hadoop version

3)修改配置文件
Hadoop配置以.xml文件形式存在
修改文件hadoop/etc/hadoop/core-site.xml:
<configuration> <property> <name>hadoop.tmp.dir</name> <value>/home/users/hadoop/hadoop/tmp</value> </property> <property> <name>fs.default.name</name> <value>hdfs://localhost:9000</value> </property> </configuration>
修改文件hadoop/etc/hadoop/hdfs-site.xml:
<configuration> <property> <name>dfs.datanode.data.dir</name> <value>/home/users/hadoop/hadoop/data</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>/home/users/hadoop/hadoop/name</value> </property> <property> <name>dfs.http.address</name> <value>0.0.0.0:8100</value> </property> <property> <name>dfs.replication</name> <value>1</value> </property> </configuration>
4)namenode格式化
hadoop/bin/hdfs namenode -format

格式化成功如上图所示。
5)开启Namenode和Datanode
hadoop/sbin/start-dfs.sh
执行成功后,输入如下命令查看开启状态
jps

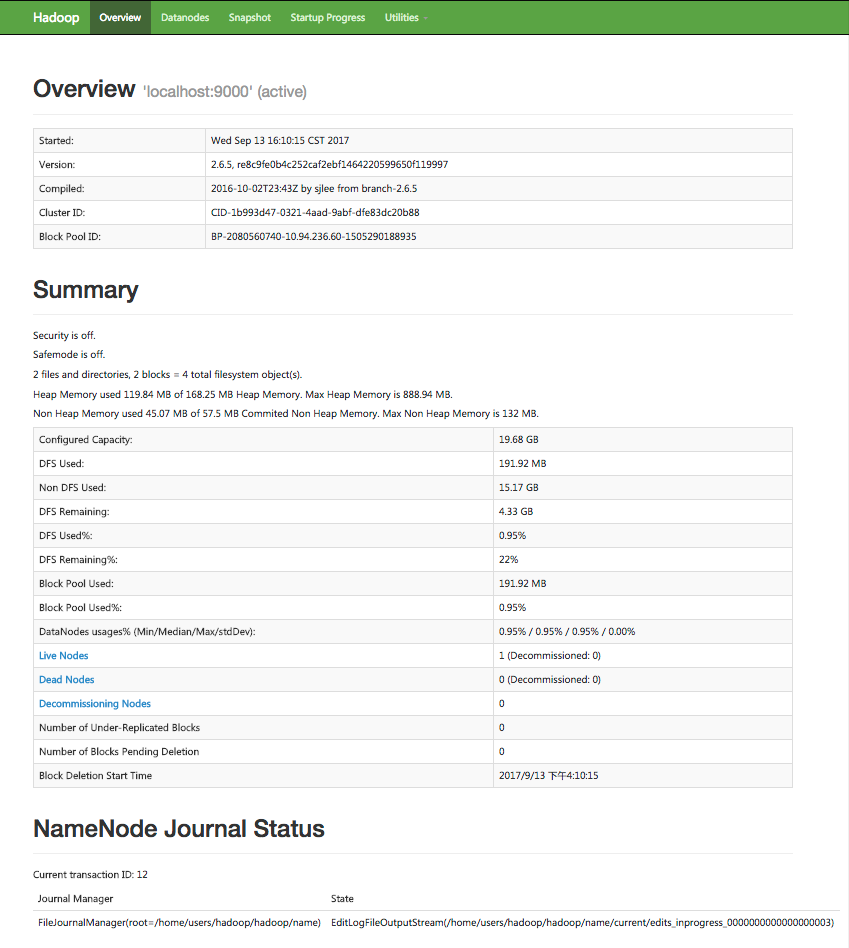
6)web页面查看hdfs服务状况
http://hostname:8100 //8100对应hdfs-site.xml配置文件中的dfs.http.address端口号
7)安装过程中遇到的问题
<1>namenode格式化的时候遇到JAVA_HOME环境变量问题
解决办法:hadoop/etc/hadoop/hadoop-env.xml文件中有变量的设置,但是不能满足要求,还要修改一下hadoop/libexec/hadoop-config.sh文件中大概160行,新增:
export JAVA_HOME=/home/tools/tools/java/jdk1.6.0_20
<2>datanode无法启动
出现该问题的原因:在第一次格式化dfs后,启动并使用了hadoop,后来又重新执行了格式化命令(hdfs namenode -format),这时namenode的clusterID会重新生成,而datanode的clusterID 保持不变。
解决办法:将hadoop/name/current下的VERSION中的clusterID复制到hadoop/data/current下的VERSION中,覆盖掉原来的clusterID,让两个保持一致然后重启,启动后执行jps,查看进程
3.HDFS的使用
HDFS的命令执行格式:hadoop fs -cmd,其中cmd是类shell的命令
hadoop fs -ls / //查看hdfs根目录的文件树
hadoop fs -mkdir /test //创建test文件夹
hadoop fs -cp 文件 文件 //拷贝文件
注:以上命令可以通过添加环境变量来简化


