web scrapying with python
网络抓取是一个相对不同的主题,需要使用数据库,Web服务器,HTTP,HTML,Internet安全,图像处理,数据科学和其他工具
Alice拥有一个Web服务器。Bob使用台式计算机,试图连接到Alice的服务器。当一台机器想要与另一台机器通信时,会发生以下交换:
Bob的计算机沿着1和0位的流发送,由线上的高压和低压指示。这些位形成一些信息,包含标题和正文。标头包含其本地路由器MAC地址的直接目的地,最终目的地为Alice的IP地址。正文包含了他对Alice的服务器应用程序的请求。
Bob的本地路由器接收所有这些1和0并将它们解释为来自Bob自己的MAC地址的数据包,并发往Alice的IP地址。他的路由器在数据包上标记自己的IP地址作为“从”IP地址,并通过Internet发送出去。
Bob的数据包遍历了几个中间服务器,这些服务器将数据包指向正确的物理/有线路径,并发送到Alice的服务器上。
Alice的服务器在她的IP地址接收数据包。
Alice的服务器读取数据包端口目的地(几乎总是端口80用于Web应用程序,这可以被认为是类似于分组数据的“公寓号”,其中IP地址是“街道地址”),在标题中,将它传递给适当的应用程序 - Web服务器应用程序。
Web服务器应用程序从服务器处理器接收数据流。这些数据表示如下:
这是一个GET请求
请求以下文件:index.html
Web服务器找到正确的HTML文件,将其捆绑到一个新的数据包中发送给Bob,并将其发送到其本地路由器,以便通过相同的进程传输回Bob的机器。
#这将创建一个新的Selenium WebDriver,使用PhantomJS库,它告诉WebDriver加载页面然后暂停执行三秒钟,然后查看页#面以检索(希望加载的)内容。
from urllib.request import urlopen
from bs4 import BeautifulSoup
import re
import datetime
import random
pages = set()
random.seed(datetime.datetime.now())
#Retrieves a list of all Internal links found on a page
def getInternalLinks(bsObj, includeUrl):
internalLinks = []
#Finds all links that begin with a "/"
for link in bsObj.findAll("a", href=re.compile("^(/|.*"+includeUrl+")")):
if link.attrs['href'] is not None:
if link.attrs['href'] not in internalLinks:
internalLinks.append(link.attrs['href'])
return internalLinks
#Retrieves a list of all external links found on a page
def getExternalLinks(bsObj, excludeUrl):
externalLinks = []
#Finds all links that start with "http" or "www" that do
#not contain the current URL
for link in bsObj.findAll("a",href=re.compile("^(http|www)((?!"+excludeUrl+").)*$")):
if link.attrs['href'] is not None:
if link.attrs['href'] not in externalLinks:
externalLinks.append(link.attrs['href'])
return externalLinks
def splitAddress(address):
addressParts = address.replace("http://", "").split("/")
return addressParts
def getRandomExternalLink(startingPage):
html = urlopen(startingPage)
bsObj = BeautifulSoup(html)
externalLinks = getExternalLinks(bsObj, splitAddress(startingPage)[0])
if len(externalLinks) == 0:
internalLinks = getInternalLinks(startingPage)
return getRandomExternalLink(internalLinks[random.randint(0,len(internalLinks)-1)])
else:
return externalLinks[random.randint(0, len(externalLinks)-1)]
def followExternalOnly(startingSite):
externalLink = getRandomExternalLink(startingSite)
print("Random external link is: "+externalLink)
followExternalOnly(externalLink)
allExtLinks = set()
allIntLinks = set()
def getAllExternalLinks(siteUrl):
html = urlopen(siteUrl)
bsObj = BeautifulSoup(html)
followExternalOnly("http://oreilly.com")
重定向允许在不同的域名下查看相同的网页。重定向有两种类型:服务器端重定向,其中URL改变之前的页面加载,对于服务器端重定向,通常不必担心,urllib库会自动处理重定向
客户端重定向,有时会出现“您将在10秒内被定向...”类型的消息,其中页面在重定向到新页面之前加载。(JavaScript或HTML执行的客户端重定向)
GET 是您通过浏览器中的地址栏访问网站时使用的内容。得到
是您拨打电话时使用的方法
到http://freegeoip.net/json/50.78.253.58。您可以认为GET说:“嘿,网络服务器,请告诉我这些信息。”
POST 是您在填写表单或提交信息时使用的,可能是服务器上的后端脚本。每次登录网站时,您都会使用您的用户名和(希望)加密密码发出 POST 请求。如果您使用API 发出 POST 请求,则说“请将此信息存储在数据库中”。
PUT 在与网站交互时不太常用,但在API中不时使用。Put 请求用于更新对象或信息。例如,API可能需要 POST 请求来创建新用户,但如果要更新该用户的电子邮件地址,则可能需要 PUT 请求。
DELETE 很简单; 它用于删除对象。例如,如果我向http://myapi.com/user/23 发送 DELETE 请求,它将删除ID为23的用户。公共API中通常不会遇到 DELETE 方法,这些方法主要是为了传播信息而创建的。允许随机用户从他们的数据库中删除该信息。但是,就像 PUT 方法一样,这是一个很好的了解
认证(Authentication)
API身份验证的所有方法通常都围绕着某种token的使用
除了在请求本身的URL中传递token之外,还可以通过请求头中的cookie将token传递给服务器
#urlretrieve从URL下载文件
from urllib.request import urlretrieve
from urllib.request import urlopen
from bs4 import BeautifulSoup
html = urlopen("http://www.pythonscraping.com")
bsObj = BeautifulSoup(html)
imageLocation = bsObj.find("a", {"id": "logo"}).find("img")["src"]
urlretrieve (imageLocation, "logo.jpg")
from collections import OrderedDict
from urllib.request import urlopen
from bs4 import BeautifulSoup
import re,string,operator
def cleanInput(input):
input= re.sub('\n+'," ",input).lower()
input = re.sub('\[[0-9]*\]',"",input)
input=re.sub(' +'," ",input)
#input = input.encode('ascii','ignore')
cleanInput=[]
input = input.split(' ')
for item in input:
item = item.strip(string.punctuation)
if len(item)>1 or (item.lower()=='a' or item.lower()=='i'):
cleanInput.append(item)
return cleanInput
def ngrams(input,n):
input =cleanInput(input)
output={}
for i in range(len(input)-n+1):
ngramTmep=" ".join(input[i:i+n])
if ngramTmep not in output:
output[ngramTmep]=0
output[ngramTmep]+=1
return output
content=str(
urlopen("http://pythonscraping.com/files/inaugurationSpeech.txt").read(),
'utf-8')
ngrams=ngrams(content,2)
#对dict排序,根据values(1),keys(0)
sortedNGrams = sorted(ngrams.items(),key=operator.itemgetter(1),reverse=True)
print(sortedNGrams)
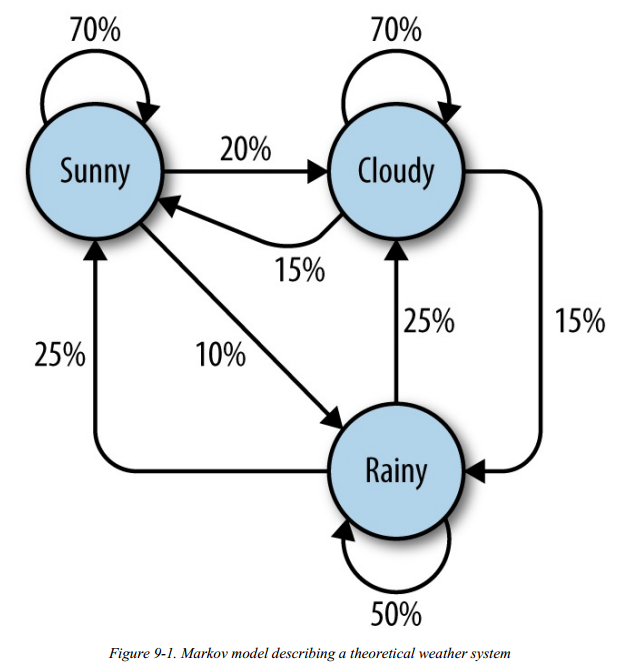
马尔科夫
马尔科夫链,是数学中具有马尔可夫性质的离散时间随机过程。该过程中,在给定当前知识或信息的情况下,过去(即当前以前的历史状态)对于预测将来(即当前以后的未来状态)是无关的。
一个马尔科夫过程就是指过程中的每个状态的转移只依赖于之前的 n个状态,这个过程被称为1个 n阶的模型,其中 n是影响转移状态的数目。最简单的马尔科夫过程就是一阶过程,每一个状态的转移只依赖于其之前的那一个状态。
我们为了找到随时间变化的模式,就试图去建立一个可以产生模式的过程模型。我们使用了具体的时间步骤、状态、并且做了马尔科夫假设。有了这些假设,这个能产生模式系统就是一个马尔科夫过程。一个马尔科夫过程包括一个初始向量和一个状态转移矩阵。关于这个假设需要注意的一点是状态转移概率不随时间变化
通过表单和登录进行爬虫
前面章节都是用get方法直接抓取URL
POST方法,该方法将信息推送到Web服务器进行存储和分析。
HTML表单也可以帮助他们格式化POST请求。当然,通过一些编码,我们可以自己创建这些请求并使用刮刀提交它们
http://pythonscraping.com/pages/files/form.html
<form method="post" action="processing.php">
First name: <input type="text" name="firstname"><br>
Last name: <input type="text" name="lastname"><br>
<input type="submit" value="Submit">
</form>
这里有几点需要注意:首先,两个输入字段的名称是firstname和lastname。这个很重要。这些字段的名称确定将POST到的变量参数的名称
表单提交时的服务器。如果你想模仿通过表单提交数据到服务器,你需要确保你的变量名匹配。
需要注意的第二件事是表单的动作是在processing.php (绝对路径是http://pythonscraping.com/files/processing.php)。对表单的任何POST请求都应该在此页面上进行,而不是在表单本身所在的页面上进行。请记住:HTML表单的目的只是为了帮助网站访问者格式化正确的请求以发送到执行实际操作的页面。除非您正在进行研究以格式化请求本身,否则您无需为可以在其上找到表单的页面烦恼。
import requests
params = {'firstname': 'Ryan', 'lastname': 'Mitchell'}
r = requests.post("http://pythonscraping.com/pages/processing.php", data=params)#模仿表单提交数据到服务器
print(r.text)#Hello there, Ryan Mitchell!
无论任何形式字段看起来多么复杂,您只需要担心两件事:元素的名称及其值。通过查看源代码并查找name属性,可以轻松确定元素的名称。当然,最简单查看表单提交的数据的方法是通过开发者工具里头的Network,查看相应文件的Form data
处理登录和Cookie
如果您正在处理一个经常在没有警告的情况下修改Cookie的更复杂的网站,或者您甚至不想开始使用cookie,该怎么办?在这种情况下,请求会话功能(session)完美地工作.会话对象(通过调用requests.Session()检索)会跟踪会话信息,例如cookie,标头,甚至是有关您可能在HTTP上运行的协议的信息,例如HTTPAdapters。
import requests
session = requests.Session()
params={'username':'arr','password':'password'}
s= session.post('http://pythonscraping.com/pages/cookies/welcome.php',params)
print('Cookie is set to:')
print(s.cookies.get_dict())
print('Going to profile page...')
s= session.get('http://pythonscraping.com/pages/cookies/profile.php')
print(s.text)
HTTP基本访问身份验证
在cookie出现之前,一种流行的处理登录方式是使用HTTP 基本访问身份验证。您仍然会不时地看到它,特别是在高安全性或公司网站上,以及一些API
Requests包中包含一个专门用于处理HTTP身份验证的auth模块:
import requests
from requests.auth import AuthBase
from requests.auth import HTTPBasicAuth
auth = HTTPBasicAuth('ryan','password')
r= requests.post(url='http://pythonscraping.com/pages/auth/login.php', auth=
auth)
print(r)
JavaScript 抓取
客户端脚本语言是在浏览器本身而不是在Web服务器上运行的语言。客户端语言的成功取决于您的浏览器正确解释和执行语言的能力
在大多数情况下,您经常只会在线遇到两种客户端语言:ActionScript(Flash应用程序使用)和JavaScript。
<script>
var fibonacci = function(){
var a =1;
var b = 1;
return function(){
var temp=b;
b = a+b;
a =temp;
return b;
}
}
var fibInstance = fibonacci();
console.log(fibInstance()+" is in the Fibonacci sequence");
console.log(fibInstance()+" is in the Fibonacci sequence");
console.log(fibInstance()+" is in the Fibonacci sequence");
</script>
如果在网站上找到JQuery,则在抓取时必须小心。JQuery擅长动态创建仅在执行JavaScript后才出现的HTML内容。如果使用传统方法抓取页面内容,则只会检索JavaScript创建内容之前出现的预加载页面
如果某个网站使用Google Analytics或类似的网络分析系统,并且您不希望该网站知道它正在被抓取或抓取,请务必丢弃用于分析的所有Cookie或完全丢弃Cookie。
Ajax(Asynchronous JavaScript and XML)和动态HTML
AJAX 不是新的编程语言,而是一种使用现有标准的新方法。
AJAX 最大的优点是在不重新加载整个页面的情况下,可以与服务器交换数据并更新部分网页内容。
AJAX 不需要任何浏览器插件,但需要用户允许JavaScript在浏览器上执行。
Selenium
Selenium 是一款功能强大的网络抓取工具,最初是为网站测试而开发的。如今,当需要对浏览器中出现的网站进行准确描绘时,也会使用它。Selenium的工作原理是自动化浏览器加载网站,检索所需数据,甚至截取屏幕截图或断言某些操作发生在网站上。
Selenium不包含自己的Web浏览器; 它需要与第三方浏览器集成才能运行。例如,如果您使用Firefox运行Selenium,您会在屏幕上看到Firefox实例打开,导航到网站,并执行您在代码中指定的操作。虽然这可能是值得关注的,但我更喜欢我的脚本在后台安静地运行,因此我使用一个名为 PhantomJS 的工具代替实际的浏览器。
PhantomJS就是所谓的无头浏览器。它将网站加载到内存中并在页面上执行JavaScript,但是没有向用户提供网站的任何图形呈现。通过结合Selenium
PhantomJS,你可以运行一个非常强大的网络抓取,轻松处理你需要的cookie,JavaScript,标题和其他一切
http://pythonscraping.com/pages/javascript/ajaxDemo.html两秒后Ajax异步加载
from selenium import webdriver
import time
driver = webdriver.PhantomJS(executable_path='<PhantomJS Path Here>')
driver.get('http://pythonscraping.com/pages/javascript/ajaxDemo.html')
time.sleep(3)
print(driver.find_element_by_id('content').text)
driver.close()
#或者
http://pythonscraping.com/pages/javascript/ajaxDemo.html两秒后Ajax异步加载
from selenium import webdriver
import time
driver = webdriver.PhantomJS(executable_path='<PhantomJS Path Here>')
driver.get('http://pythonscraping.com/pages/javascript/ajaxDemo.html')
time.sleep(3)
pageSource = driver.page_source
bs = BeautifulSoup(pageSource, 'html.parser')
print(bs.find(id='content').get_text())
driver.close()
以上解决方法是低效的。页面加载时间不一致,具体取决于任何特定毫秒的服务器负载,并且连接速度会发生自然变化。虽然此页面加载应该只需要两秒钟,但您需要整整三秒钟才能确保它完全加载。更有效的解决方案将反复检查满载页面上是否存在特定元素,并仅在该元素存在时返回
Selenium库是在WebDriver对象上调用的API.WebDriver有点像浏览器,因为它可以加载网页,但它也可以像BeautifulSou对象一样用于查找页面元素,与页面上的元素交互(发送文本,单击等),以及执行其他操作进行网络抓取。
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.PhantomJS(executable_path='<PhantomJS Path Here>')
driver.get('http://pythonscraping.com/pages/javascript/ajaxDemo.html')
try:
element = WebDriverWait(driver,10).until(EC.presence_of_element_located((By.ID, 'loadedButton')))
finally:
print(driver.find_element_by_id('content').text)
driver.close()
触发DOM状态由expected_condition定义(请注意,导入在此处转换为EC,这是用于简洁的常用约定)。Selenium库中的预期条件可能很多,包括:
弹出警告框
元素(例如文本框)被置于选定状态
页面标题发生更改,或者文本现在显示在页面上或特定元素中。
元素现在对DOM可见,或者元素从DOM中消失。
大多数这些预期条件要求你首先指定要监视的元素。
图像处理和文本识别
将图像翻译成文本称为光学字符识别(OCR)
pillow,Tesseract
这两个库在处理和处理来自网络的图像上进行OCR时,可以形成强大的互补二重奏。Pillow执行第一次传递,清洁和过滤图像,Tesseract尝试将这些图像中找到的形状与其已知文本库进行匹配
#CAPTCHA,图像验证
from urllib.request import urlretrieve
from urllib.request import urlopen
from bs4 import BeautifulSoup
import subprocess
import requests
from PIL import Image
from PIL import ImageOps
def cleanImage(imagePath):
image = Image.open(imagePath)
image = image.point(lambda x:0 if x<143 else 255)
borderImage = ImageOps.expand(image,border=20,fill='white')
borderImage.save(imagePath)
html = urlopen("http://www.pythonscraping.com/humans-only")
bs = BeautifulSoup(html,'html.parser')
imageLocation = bs.find('img',{'title':'Image CAPTCHA'})['src']
formBuildId = bs.find('input', {'name':'form_build_id'})['value']
captchaSid = bs.find('input', {'name':'captcha_sid'})['value']
captchaToken = bs.find('input', {'name':'captcha_token'})['value']
catchaUrl = 'http://pythonscraping.com'+imageLocation
urlretrieve(catchaUrl,'captcha.jpg')
cleanImage('captcha.jpg')
p = subprocess.Popen(['tesseract','captcha.jpg','captcha'],stdout=subprocess.PIPE,stderr=subprocess.PIPE)
p.wait()
f = open('captcha.txt','r')
captchaResponse = f.read().replace(' ','').replace('\n','')
print('Captcha solution attempt: '+captchaResponse)
if len(captchaResponse)==5:
params = {'captcha_token': captchaToken, 'captcha_sid': captchaSid,
'form_id': 'comment_node_page_form', 'form_build_id': formBuildId,
'captcha_response': captchaResponse, 'name': 'Ryan Mitchell',
'subject': 'I come to seek the Grail',
'comment_body[und][0][value]':
'...and I am definitely not a bot'}
r = requests.post('http://www.pythonscraping.com/comment/reply/10',
data=params)
responseObj = BeautifulSoup(r.text, 'html.parser')
if responseObj.find('div', {'class': 'messages'}) is not None:
print(responseObj.find('div', {'class': 'messages'}).get_text())
else:
print('There was a problem reading the CAPTCHA correctly!')
Avoiding Scraping Traps
看起来像人而不是机器人
1.adjust your headers
HTTP headers是每次向Web服务器发出请求时由您发送的属性或首选项列表;主要包含以下字段
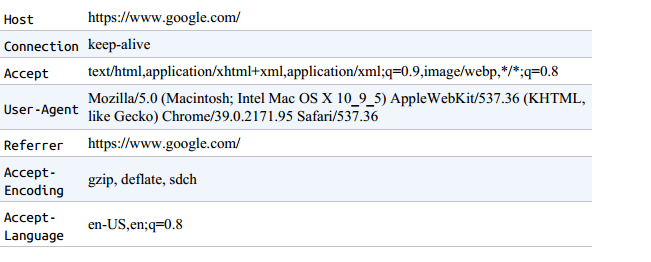
import requests
from bs4 import BeautifulSoup
session = requests.Session()
headers = {'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_5)'
'AppleWebKit 537.36 (KHTML, like Gecko) Chrome',
'Accept':'text/html,application/xhtml+xml,application/xml;'
'q=0.9,image/webp,*/*;q=0.8'}
url = 'https://www.whatismybrowser.com/'\
'developers/what-http-headers-is-my-browser-sending'
req = session.get(url, headers=headers)
bs = BeautifulSoup(req.text, 'html.parser')
print(bs.find('table', {'class':'table-striped'}).get_text)
浏览网页的移动设备通常会看到网站的简化版本,缺少横幅广告,Flash和其他分散注意力。如果您尝试将用户代理更改为以下内容,您可能会发现网站更容易抓取
User-Agent:Mozilla/5.0 (iPhone; CPU iPhone OS 7_1_2 like Mac OS X)
AppleWebKit/537.51.2 (KHTML, like Gecko) Version/7.0 Mobile/11D257
Safari/9537.53
#通过get_cookies()查看任意网站的cookie
from selenium import webdriver
driver = webdriver.PhantomJS(executable_path='<Path to Phantom JS>')
driver.get('http://pythonscraping.com')
driver.implicitly_wait(1)
print(driver.get_cookies())
#Python 设置Cooikes
from selenium import webdriver
driver = webdriver.PhantomJS(executable_path='<Path to Phantom JS>')
driver.get("http://pythonscraping.com")
driver.implicitly_wait(1)
print(driver.get_cookies())
savedCookies = driver.get_cookies()
driver2 = webdriver.PhantomJS(executable_path='<Path to Phantom JS>')
driver2.get("http://pythonscraping.com")
driver2.delete_all_cookies()
for cookie in savedCookies:
driver2.add_cookie(cookie)
driver2.get("http://pythonscraping.com")
driver.implicitly_wait(1)
print(driver2.get_cookies())
有时需要检查表单所在的页面,看看是否遗漏了服务器可能期望的任何内容。如果您看到几个隐藏字段,通常是随机生成的大型字符串变量,则Web服务器可能会在表单提交时检查它们是否存在。此外,可能还有其他检查以确保表单变量仅被使用一次,最近生成(这消除了将它们简单地存储在脚本中并一遍又一遍地使用它们的可能性)或两者兼而有之
#hidden fields
from selenium import webdriver
from selenium.webdriver.remote.webelement import WebElement
driver = webdriver.PhantomJS(executable_path='E:\\lessUseSoft\\phantomjs-2.1.1-windows\\bin\\phantomjs.exe')
driver.get("http://pythonscraping.com/pages/itsatrap.html")
links = driver.find_elements_by_tag_name("a")
for link in links:
if not link.is_displayed():
print("The link "+link.get_attribute("href")+" is a trap")
fields = driver.find_elements_by_tag_name("input")
for field in fields:
if not field.is_displayed():
print("Do not change value of "+field.get_attribute("name"))
本章中有很多信息,实际上在本书中,有关如何构建一个看起来不像robot而更像人类的抓取的信息。如果您不断被网站阻止而您不知道原因,可以使用以下方法来解决问题:
首先,如果您从Web服务器接收的页面是空白的,缺少信息,或者不是您期望的(或者在您自己的浏览器中看到过),则可能是由于在网站上执行JavaScript以创建页面。回顾第10章。
如果您要向网站提交表单或发出POST请求,请检查页面以确保网站期望您提交的所有内容都以正确的格式提交。使用Chrome的网络检查器等工具查看发送到网站的实际POST命令,以确保您拥有所有内容。
如果您尝试登录网站并且无法使登录“坚持”,或者网站遇到其他奇怪的“状态”行为,请检查您的cookie。确保在每次页面加载之间正确保留cookie,并确保每次请求都将cookie发送到站点。
如果您从客户端收到HTTP错误,尤其是403 Forbidden错误,则可能表明该网站已将您的IP地址识别为机器人并且不愿意接受任何其他请求。您需要等到IP地址从列表中删除,或者获取新的IP地址(参见第14章)。为了确保你不会再次受阻,请尝试以下操作:
确保您的抓取没有太快地穿过现场。快速抓取是一种不好的做法,会给网络管理员的服务器带来沉重的负担,使您陷入法律麻烦,并且是抓取robot被列入黑名单的头号原因。为您的robot添加延迟并让它们在一夜之间运行。记住:急于编写程序或收集数据是项目管理不善的标志; 提前计划以避免像这样的混乱。
显而易见的一个:改变你的标题!如果您不确定某些合理的标头值是什么,请复制您自己的浏览器标头。
确保您没有点击或访问人类通常无法访问的任何内容(有关更多信息,请参阅 “避免使用蜜罐” )。
如果您发现自己经历了许多难以获取访问权限,请考虑与网站管理员联系,让他们知道您在做什么。尝试通过电子邮件发送网站管理员@ <域名>或admin @ <域名>,以获取使用您的抓取工具的权限。管理员也是人!
利用网络抓取进行网页测试
单元测试特征:
每个单元测试都测试组件功能的一个方面。例如,如果从银行帐户中提取负数,则可能会确保抛出相应的错误消息。
通常,单元测试根据他们正在测试的组件在同一个类中组合在一起。您可能会对从银行帐户中提取的负美元价值进行测试,然后对透支银行帐户的行为进行单元测试。
每个单元测试可以完全独立运行,单元测试所需的任何设置或拆卸必须由单元测试本身处理。同样,单元测试不得干扰其他测试的成功或失败,并且必须能够以任何顺序成功运行。
每个单元测试通常至少包含一个断言。例如,单元测试可能断言2 + 2的答案是4.偶尔,单元测试可能只包含故障状态。例如,如果未抛出异常,它可能会失败,但如果一切顺利,则默认传递。
单元测试与大部分代码分开。虽然他们一定需要导入和使用他们正在测试的代码,但它们通常保存在单独的类和目录中
unittest module 是基于Java的JUnit包改写的内置Python模块
import unittest
class TestAddition(unittest.TestCase):
def setUp(self):
print('Setting up the test')
def tearDown(self):
print('Tearing down the test')
def test_twoPlusTwo(self):
total = 2+2
self.assertEqual(4,total)
if __name__=='__main__':
unittest.main()
虽然setUp和tearDown在这里没有提供任何有用的功能,但是为了说明的目的,它们被包括在内.这两个函数是运行在每次单独测试前后,tearDownClass和setUpClass在类中的所有测试之前和之后进行
利用Selenium进行测试
driver = webdriver.PhantomJS()
driver.get("http://en.wikipedia.org/wiki/Monty_Python")
assert "Monty Python" in driver.title
driver.close()
Python单元测试和Selenium单元测试的语法几乎没有共同之处。Selenium不要求将其单元测试作为类中的函数包含在内; 它的“断言”陈述不需要括号; 并且测试以静默方式传递,仅在失败时产生某种消息
正如您可以在浏览器中对网站的各种元素进行许多操作一样,Selenium可以对任何给定元素执行许多操作。其中包括
myElement.click()
myElement.click_and_hold()
myElement.release()
myElement.double_click()
myElement.send_keys_to_element('content to enter')
...
#selenium,链式action
from selenium import webdriver
from selenium.webdriver.remote.webelement import WebElement
from selenium.webdriver.common.keys import Keys
from selenium.webdriver import ActionChainsdriver = webdriver.PhantomJS(executable_path='<Path to Phantom JS>')
driver.get("http://pythonscraping.com/pages/files/form.html")
firstnameField = driver.find_element_by_name("firstname")
lastnameField = driver.find_element_by_name("lastname")
submitButton = driver.find_element_by_id("submit")
### METHOD 1 ###
firstnameField.send_keys("Ryan")
lastnameField.send_keys("Mitchell")
submitButton.click()
################
### METHOD 2 ###
actions = ActionChains(driver).click(firstnameField).send_keys("Ryan")
.click(lastnameField).send_keys("Mitchell")
.send_keys(Keys.RETURN)
actions.perform()
################
print(driver.find_element_by_tag_name("body").text)
driver.close()
点击按钮并输入文字是一回事,但Selenium真正发挥作用的是处理相对新颖的网络互动形式的能力。Selenium可以轻松地操作拖放界面。使用其拖放功能需要您指定“源”元素(要拖动的元素)以及用于拖动它的偏移量,或者用于将其拖动到的目标元素
#拖动(可用于验证)
from selenium import webdriver
from selenium.webdriver.remote.webelement import WebElement
from selenium.webdriver import ActionChains
driver = webdriver.PhantomJS(executable_path='<Path to Phantom JS>')
driver.get('http://pythonscraping.com/pages/javascript/draggableDemo.html')
print(driver.find_element_by_id("message").text)
element = driver.find_element_by_id("draggable")target = driver.find_element_by_id("div2")
actions = ActionChains(driver)
actions.drag_and_drop(element, target).perform()
print(driver.find_element_by_id("message").text)
截图
driver.implicitly_wait(5)
driver.get('http://www.pythonscraping.com/')
driver.get_screenshot_as_file('D:/project/testCode/python/tmp/pythonscraping.png')
from selenium import webdriver
from selenium.webdriver.remote.webelement import WebElement
from selenium.webdriver import ActionChains
import unittest
class TestAddition(unittest.TestCase):
driver = None
def setUp(self):
global driver
driver = webdriver.PhantomJS(executable_path='<Path to Phantom JS>')
url = 'http://pythonscraping.com/pages/javascript/draggableDemo.html'
driver.get(url)
def tearDown(self):
print('Tearing down the test')
def test_drag(self):
global driver
element = driver.find_element_by_id("draggable")
target = driver.find_element_by_id("div2")
actions = ActionChains(driver)
actions.drag_and_drop(element, target).perform()
self.assertEqual("You are definitely
not a bot!", driver.find_element_by_id(
"message").text)
if __name__ == '__main__':
unittest.main()
网站上的任何内容都可以通过Python的unittest和Selenium的组合进行测试
远程抓取
避免IP地址被屏蔽
IP地址阻止仍然是服务器管理员阻止可疑Web抓取访问服务器的极为常用的方法。如果IP地址被阻止了,唯一的方法是换另一IP地址进行抓取,这可以通过将web抓取程序移动到新服务器或使用Tor等服务通过不同的服务器路由流量来实现。
Tor(The Onion Router)是第二代洋葱路由(onion routing)的一种实现,用户通过Tor可以在因特网上进行匿名交流。Tor专门防范流量过滤、嗅探分析,让用户免受其害
http://icanhazip.com/查看ip
import socks
import socket
from urllib.request import urlopen
socks.set_default_proxy(socks.SOCKS5, "localhost", 9150)
socket.socket = socks.socksocket
print(urlopen('http://icanhazip.com').read())
#运行此脚本,它应显示不属于你自己的IP地址
版权保护仅适用于创作作品。它不包括统计数据或事实.幸运的是,网络抓取所追求的大部分都是统计数据和事实。虽然从网络上收集诗歌并在你自己的网站上显示诗歌的网络抓取可能违反了版权法,但是一个网络抓取收集有关诗歌发布频率的信息不是。原始形式的诗歌是一种创造性的作品。按月在网站上发布的诗歌的平均字数是事实数据,而不是创造性作品。
代理服务器:一台机器转发请求但使用代理服务器的IP地址的服务器
遇到任何网络抓取项目时,你应该总是问自己:
我想回答的问题是什么,或者我想解决的问题是什么?哪些数据可以帮助我实现这一目标,它在哪里?
网站如何显示这些数据?我可以确切地确定网站代码的哪个部分包含此信息吗?
如何隔离数据并检索它?
需要进行哪些处理或分析才能使其更有用?
如何使这个过程更好,更快,更强大?
请记住:互联网是一个巨大的API,用户界面稍差。
Selenium文档
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
driver = webdriver.Chrome(executable_path='D:\\小软件\\chromedriver.exe')
driver.get("http://www.python.org")
assert "Python" in driver.title
elem = driver.find_element_by_name("q")
elem.clear()
elem.send_keys("pycon")#下发参数,字符串
elem.send_keys(Keys.RETURN)#对该元素按回车
assert "No results found." not in driver.page_source #对响应后的页面进行一断定,看是否有搜索到内容
driver.close()#close 是关闭当前页面,quit是退出整个浏览器
Selenium WebDriver内置支持处理弹出对话框。在您触发将打开弹出窗口的操作后,您可以使用以下命令访问警报:
alert = driver.switch_to_alert()
这将返回当前打开的警报对象。使用此对象,您现在可以接受,关闭,读取其内容,甚至可以键入提示
历史文件
driver.forward()
driver.back()
Cookies
# Go to the correct domain
driver.get("http://www.example.com")
# Now set the cookie. This one's valid for the entire domain
cookie = {‘name’ : ‘foo’, ‘value’ : ‘bar’}
driver.add_cookie(cookie)
# And now output all the available cookies for the current URL
driver.get_cookies()
获得元素
Selenium提供了很多获得元素的方法
如:
find_element_by_id
find_element_by_name
find_element_by_xpath
self.driver.find_element_by_xpath( '//*[text()="%s"]' % "查询")等价于splinter里头的self,driver.find_by_text('查询')
self.driver.find_element_by_xpath('//option[normalize-space(text())="%s"]' %'查询')等价于splinter里头的self,driver.find_option_by_text('查询')
Locating by XPath
XPath 是一门用于定位XML文档节点的语言,由于HTML可以是XML(XHTML)的实现,因此Selenium用户可以利用这种强大的语言来定位其Web应用程序中的元素。
使用XPath的主要原因之一是当您没有适合您要查找的元素的id或name属性时。您可以使用XPath以绝对术语(不建议)或相对于具有id或name属性的元素来定位元素。XPath定位器还可用于通过id和name以外的属性指定元素。
假设有一HTML
<html>
<body>
<form id="loginForm">
<input name="username" type="text" />
<input name="password" type="password" />
<input name="continue" type="submit" value="Login" />
<input name="continue" type="button" value="Clear" />
</form>
</body>
<html>
可以用以下方法获得响应元素
login_form = driver.find_element_by_xpath("/html/body/form[1]")
login_form = driver.find_element_by_xpath("//form[1]")
login_form = driver.find_element_by_xpath("//form[@id='loginForm']")
username = driver.find_element_by_xpath("//form[input/@name='username']")
username = driver.find_element_by_xpath("//form[@id='loginForm']/input[1]")
username = driver.find_element_by_xpath("//input[@name='username']")
clear_button = driver.find_element_by_xpath("//input[@name='continue'][@type='button']")
clear_button = driver.find_element_by_xpath("//form[@id='loginForm']/input[4]")
<html>
<body>
<h1>Welcome</h1>
<p>Site content goes here.</p>
</body>
<html>
continue_link = driver.find_element_by_link_text('Continue')
continue_link = driver.find_element_by_partial_link_text('Conti')
<html>
<body>
<h1>Welcome</h1>
<p>Site content goes here.</p>
</body>
<html>
heading1 = driver.find_element_by_tag_name('h1')
Waits
若现有的wait接口无法满足需求,你可以自己创建。
class element_has_css_class(object):
"""An expectation for checking that an element has a particular css class.
locator - used to find the element
returns the WebElement once it has the particular css class
"""
def __init__(self, locator, css_class):
self.locator = locator
self.css_class = css_class
def __call__(self, driver):
element = driver.find_element(*self.locator) # Finding the referenced element
if self.css_class in element.get_attribute("class"):
return element
else:
return False
# Wait until an element with id='myNewInput' has class 'myCSSClass'
wait = WebDriverWait(driver, 10)
element = wait.until(element_has_css_class((By.ID, 'myNewInput'), "myCSSClass"))
driver.refresh()刷新
driver.forward()前进
driver.back()后退
driver.get_cookie('cookieKey')根据cookieKey,获取cookie信息
driver.get_cookies()获取所有cookie信息
driver.add_cookie({'name':'temp','value':'123123'})#添加cookie
driver.delete_all_cookies()
driver.delete_cookie('Uicode')
driver.get_window_size()获取当前浏览器的大小
driver.set_window_size(‘width’,'height')
获取当前窗口针对于Windows的位置的坐标x,y
driver.get_window_position()
设置当前窗口针对Windows的位置,x,y
driver.set_window_position(20,20)
最大化当前窗口,不需要传参
driver.maximize_window()
返回当前操作的浏览器句柄
driver.current_window_handle
返回所有打开server的浏览器句柄
driver.window_handles
获取当前页面的二进制图片数据,需要自己去写入文件
driver.get_screenshot_as_png()
as_png的上层封装,只需要传入图片名称自动写成图片
driver.get_screenshot_as_file('fileName.png')
执行JavaScript语句
driver.execute_script('JavaScript Commond')
当开启多个时,关闭当前页面
driver.close()
退出并关闭所有页面驱动
driver.quit()
返回页面源码
driver.page_source
返回tag标题
driver.title
返回当前Url
driver.current_url
获取浏览器名称 如:chrome
driver.name
根据标签属性名称,获取属性value
element.get_attribute('style')
向输入框输入字符串 如果input的type为file类型 可以输入文件绝对路径上传文件
element.send_keys()
清除文本内容
element.clear()
鼠标左键点击操作
element.click()
通过属性名称获取属性
element.get_property('id')
返回元素是否可见 True or False
element.is_displayed()
返回元素是否被选中 True or False
element.is_selected()
返回标签元素的名字
element.tag_name
获取当前标签的宽和高
element.size
获取元素的文本内容
element.text
模仿回车按钮 提交数据
element.submit()
获取当前元素的坐标
element.location
截取图片
element.screenshot()
NoSuchElementException:没有找到元素
NoSuchFrameException:没有找到iframe
NoSuchWindowException:没找到窗口句柄handle
NoSuchAttributeException:属性错误
NoAlertPresentException:没找到alert弹出框
ElmentNotVisibleException:元素不可见
ElementNotSelectableException:元素没有被选中
TimeoutException:查找元素超时
Splinter:
用途:查找HTML元素,运行Js代码,与Web交互(主要是鼠标操作),Cookies,查找元素是否出现,截屏
提供了状态码,用于验证操作是否成功,如:browser.status_code.is_success()
driver->Element
driver api ,element api
CookieManager
ElementList
#简单实例
from splinter.browser import Browser
with Browser(driver_name='chrome',executable_path='D:\\小软件\\chromedriver.exe') as browser:
url = 'https://www.baidu.com'
browser.visit(url)
browser.fill('wd', 'splinter - python acceptance testing for web applications')
# Find and click the 'search' button
button = browser.find_by_id('su')
# Interact with elements
button.click()
if browser.is_text_present('splinter.readthedocs.io'):
print("Yes, the official website was found!")
else:
print("No, it wasn't found... We need to improve our SEO techniques")
browser.fill('username', 'janedoe')#填充值
而在Selenium中,其语法为:
elem = browser.find_element.by_name('username')
elem.send_keys('janedoe')
Visit any website using the browser.visit method.
browser.visit('http://google.com')
browser.reload()
browser.html
b = Browser(user_agent="Mozilla/5.0 (iPhone; U; CPU like Mac OS X; en)")

 浙公网安备 33010602011771号
浙公网安备 33010602011771号