【算法】分支界限三步走
前面我们介绍了一下回溯法的使用。
现在我们来给大家介绍一下它的好朋友——分支界限法。
如果说回溯法是使用深度优先遍历算法,那么分支界限法就是使用广度优先遍历算法。
深度优先遍历可以只使用一个属性来存放当前状态,但是广度优先遍历就不可以了,所以广度优先遍历的节点必须用来存储当前状态,一个节点代表一个当前状态,而一条边就代表了一次操作,A状态经过一条边(操作)变为B状态。
我在写这篇文章的时候搜遍了网上各种各样的分支界限法来解决01背包问题,看各个代码都要一两百行,都是优化之后的最优化版分支界限法,这样是不利于新手进行理解的,所以我在此写了一个最初级的分支界限法解决01背包问题,可以看到要不了50行就能解决01背包问题。
分支界限法
对于分支界限法,网上有很多种解释,这里我依照自己的(死宅)观点做了以下两种通俗易懂的解释:
-
正经版解释:所谓“分支”就是采用广度优先的策略,依次搜索E-结点的所有分支,也就是所有相邻结点,抛弃不满足约束条件的结点,其余结点加入活结点表。然后从表中选择一个结点作为下一个E-结点,继续搜索。
-
动漫版解释:看过火影忍者的都知道,主角拥有影分身的能力,如果主角使用影分身从一个点出发,前往不同的分支,主角的运动速度相同的情况下,同一时刻时分支的深度也应该相同,有的分身走到死路,有的分身达到界限无法进行下去,当分身无法进行下去时,那么就解除该分身,直接放弃掉这个分身,当然,肯定也会有分身成功到达目的地找到最优解,这与我们今天要讲的分支界限法极其相似。
PS:雏田党大获全胜!
- 总结版解释:从众多分支的路径中,同时地毯式搜索找到符合结果的路径或路径集。
概念
分支界限算法:是类似于广度优先的搜索过程,也就是地毯式搜索,主要是在搜索过程中寻找问题的解,当发现已不满足求解条件时,就舍弃该分身,不管了。
它是一种选优搜索法,按选优条件向前广度优先搜索,以达到目标。但当探索到某一步时,发现原先选择并不优或达不到目标,就放弃该分身,不进行下一步退回,这种走不通就放弃分身的技术称为分支界限法。
所谓“分支”就是采用广度优先的策略,依次搜索E-结点的所有分支,也就是所有相邻结点,抛弃不满足约束条件的结点,其余结点加入活结点表。然后从表中选择一个结点作为下一个E-结点,继续搜索。
选择下一个E-结点的方式不同,则会有几种不同的分支搜索方式。不用感到恐慌,其实这几种不同的搜索方式很好实现,只需要换一下不同的数据结构容器即可。
-
FIFO搜索(使用队列实现):按照先进先出原则选取下一个节点为扩展节点。 活结点表是先进先出队列。
-
LIFO搜索(使用栈实现):活结点表是堆栈。
-
优先队列式搜索(使用优先队列实现):按照优先队列中规定的优先级选取优先级最高的节点成为当前扩展节点。 活结点表是优先权队列,LC分支限界法将选取具有最高优先级的活结点出队列,成为新的E-结点。
Java中的优先队列PriorityQueue对元素采用的是堆排序,头是按指定排序方式的最小元素。堆排序只能保证根是最大(最小),整个堆并不是有序的。
优先队列PriorityQueue是Queue接口的实现,可以对其中元素进行排序,可以放基本的包装类型或自定义的类,对于基本类型的包装类,优先队列中元素的默认排列顺序是升序,但是对于自定义类来说,需要自定义比较类
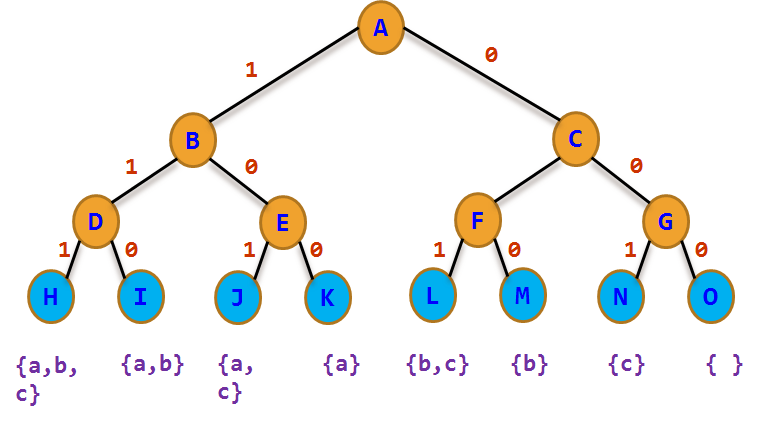
上图为01背包问题的解空间树,如果当前点不符合要求就放弃,直接剪枝。
在许多能使用回溯法的问题时,都可以使用分支界限法,算是给读者一个新的思路去解决问题。
基本思想
在包含问题的所有解的解空间树中,按照广度优先搜索的策略,从根结点出发广度地毯式探索解空间树。对于不同的分支搜索方式要使用不同的数据结构来实现。
当探索到某一结点时,要先判断该结点是否包含问题的解:
- 如果包含,就将该结点的延伸结点加入队列,以便之后遍历;
- 如果该结点不包含问题的解,则直接剪枝放弃该结点的延伸结点。(其实分子界限法就是对隐式图的广度优先搜索算法)
结束条件:
- 若用分子界限法求问题的所有解时,根结点的所有可行的子树都要已被搜索遍才结束。
- 若使用分子界限法求任一个解时,只要搜索到问题的一个解就可以结束。
适用场景
分支界限法一般使用在问题可以树形化表示时的场景。
这样说明的话可能有点抽象,那么我们来换个方法说明。
当你发现,你的问题需要用到多重循环,具体几重循环你又没办法确定,那么就可以使用我们的分支界限算法来将循环一层一层的进行遍历。
就像这样:
void LevelOrder(BiTree T) {
InitQueue(Q); //初始化辅助队列
BiTNode *p;
EnQueue(Q, T); //将根结点入队
while(!IsEmpty(Q)) { //队列不空循环
DeQueue(Q, p); //队头元素出队,出队指针才是用来遍历的遍历指针
visit(p); //访问当前p所指向结点
if(p->lchild != NULL) { //左子树不空,则左子树入队列
EnQueue(Q, p->lchild);
}
if(p->rchild != NULL) { //右子树不空,则右子树入队列
EnQueue(Q, p->rchild);
}
}
}
这样层次遍历的话,无论多少重循环我们都可以满足。
分支界限三步走
由于上述网上的步骤太抽象了,所以在这里我自己总结了分子界限三步走:
- 编写检测函数:检测函数用来检测此路径是否满足题目条件,是否能通过。
这步不做硬性要求。。不一定需要
- 建立状态结点:分支界限法中需要广度优先遍历整个分支树,所以其结点都需要记录下当前的状态,否则到需要进行遍历时我们不能得知此结点的状态,无法进行操作。
与此相对的就是回溯法,回溯法由于是一条路走到底,所以并不需要使用结点记录下当前的状态。
类比:做作业
回溯法:先做完数学作业再做英语作业,我们的思路是完整的,是一步一步顺着来的,不会被遗忘。
分支界限法:做一会数学作业,再做一会英语作业,这样我们为了保证之前做的思路不会遗忘,我们要使用结点记录下当前的状态。
- 明确所有分支(选择):这个构思路径最好用树形图表示。
例如:走迷宫有上下左右四个方向,也就是说我们站在一个点处有四种选择,我们可以画成无限向下延伸的四叉树。
直到向下延伸到叶子节点,那里便是出口;
从根节点到叶子节点沿途所经过的节点就是我们满足题目条件的选择。
- 寻找界限条件:每一个分支都需要进行判断,判断是否到达了界限,如果到达界限那么我们就无需再进行下去了,直接剪枝放弃该分支。
比如说,01背包中的界限条件就是,在将物品放置进背包前,要进行判断放入背包是否会造成超重,如果不超重,那就可以放入背包。
编写检测函数(非必须)
第一步,写出检测函数,来检测这个路径是否满足条件,是否能通过。
这个函数依据题目要求来编写,当然,如果要求不止一个,可能需要编写多个检测函数。
建立状态结点
分支界限法中需要广度优先遍历整个分支树,所以其结点都需要记录下当前的状态,否则到需要进行遍历时我们不能得知此结点的状态,无法进行操作。
与此相对的就是回溯法,回溯法由于是一条路走到底,所以并不需要使用结点记录下当前的状态。
类比:做作业
回溯法:先做完数学作业再做英语作业,我们的思路是完整的,是一步一步顺着来的,不会被遗忘。
分支界限法:做一会数学作业,再做一会英语作业,这样我们为了保证之前做的思路不会遗忘,我们要使用结点记录下当前的状态。
在01背包问题中,我们需要记录的状态是此时背包内物品的重量与价值。所以我们的状态结点为:
/**
* 结点类,一个结点对象对应着一个当前的背包状态
*/
class Node {
public int weight; // 结点所相应的重量
public int value; // 结点所对应的价值
public Node() {
}
public Node(int weight, int value) {
this.weight = weight;
this.value = value;
}
}
明确所有分支
这个构思路径最好用树形图表示。
例如:走迷宫有上下左右四个方向,也就是说我们站在一个点处有四种选择,我们可以画成无限向下延伸的四叉树。
直到向下延伸到叶子节点,那里便是出口;
从根节点到叶子节点沿途所经过的节点就是我们满足题目条件的选择。
第三步,要知道这个结点有几个选择,即 几叉树。
在01背包问题中,每个物品都有2个选择,0不放入背包,1放入背包,两条路,二叉树。
- 不放入背包
- 放入背包
寻找界限条件
每一个分支都需要进行判断,判断是否到达了界限,如果到达界限那么我们就无需再进行下去了,直接剪枝放弃该分支。
比如说,01背包中的界限条件就是,在将物品放置进背包前,要进行判断放入背包是否会造成超重,如果不超重,那就可以放入背包。
前面我们确定了一个结点有两条分支,一个是不装入背包,一个是装入背包。我们现在需要为每个分支寻找它们的界限条件。
不装入背包当然没有什么界限条件,而装入背包则需要判断,如果放入背包是否会造成超重,如果不超重,那就可以放入背包。
代码如下:
// 不放此p号物品的状态
queue.add(new Node(nowBagNode.weight, nowBagNode.value));
// 放置此p号物品的状态
if (nowBagNode.weight + weights[p] < maxWeight) {
nowBagNode.weight += weights[p];
nowBagNode.value += values[p];
p++;
queue.add(new Node(nowBagNode.weight, nowBagNode.value));
maxValue = nowBagNode.value > maxValue? nowBagNode.value : maxValue;
}
完整的代码我放在下面的实例中了。
实例
01背包问题
假定有N=4件商品,分别用A、B、C、D表示。每件商品的重量分别为3kg、2kg、5kg和4kg,对应的价值分别为66元、40元、95元和40元。现有一个背包,可以容纳的总重量位9kg,问:如何挑选商品,使得背包里商品的总价值最大?
22、20、19、10
答案:
暴力破解法:

由于暴力破解法不是我们本章的重点,所以代码再此掠过,只留下示意图
我在写这篇文章的时候搜遍了网上各种各样的分支界限法来解决01背包问题,看各个代码都要一两百行,都是优化之后的最优化版分支界限法,这样是不利于新手进行理解的,所以我在此写了一个最初级的分支界限法解决01背包问题,可以看到要不了50行就能解决01背包问题。
/**
* 结点类,一个结点对象对应着一个当前的背包状态
*/
class Node {
public int weight; // 结点所相应的重量
public int value; // 结点所对应的价值
public Node() {
}
public Node(int weight, int value) {
this.weight = weight;
this.value = value;
}
}
public class Bag01 {
public int maxWeight = 9; // 背包的最大容量
public int maxValue = 0; // 背包内的最大价值总和
/**
* 分支界限法
* @param weights 所有物品的重量数组
* @param values 所有物品的价值数组
*/
public void f(int[] weights, int[] values) {
Queue<Node> queue = new ArrayDeque<>();
Node node = new Node();
// 放入一个初始结点,结点状态均为0
queue.add(node);
int p = 0; // 物品指针位置
while (!queue.isEmpty()) {
// 取出当前结点的背包状态
Node nowBagNode = queue.remove();
// 如果物品没有放完
if (p < weights.length) {
// 不放此p号物品的状态
queue.add(new Node(nowBagNode.weight, nowBagNode.value));
// 放置此p号物品的状态,如果放入超重了,那就不能放
if (nowBagNode.weight + weights[p] < maxWeight) {
nowBagNode.weight += weights[p];
nowBagNode.value += values[p];
p++;
queue.add(new Node(nowBagNode.weight, nowBagNode.value));
maxValue = nowBagNode.value > maxValue? nowBagNode.value : maxValue;
}
}
}
System.out.println(maxValue);
}
public static void main(String[] args) {
int[] weights = {2, 3, 5, 4};
int[] values = {66, 40, 95, 40};
Bag01 bag01 = new Bag01();
bag01.f(weights, values);
}
}
程序运行结果:
161
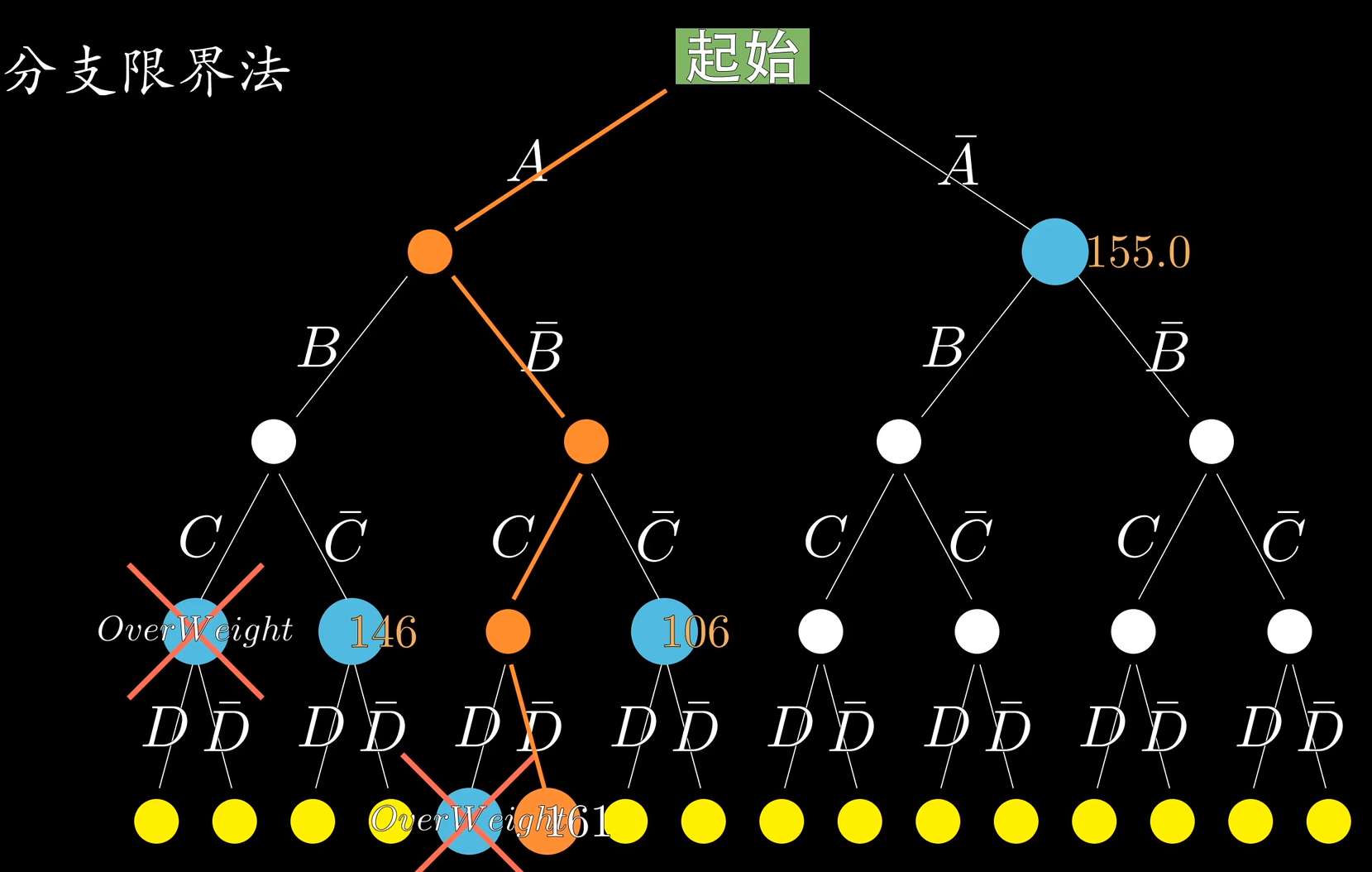
如果你想换一种搜索方式,那么你可以把上面的队列换成堆栈或者优先队列试试。
优化
我还想看一下他们的代码,写一个优化版本。
上界估算优化
这里我们的上界估算是结合贪心算法的优先队列(剪枝)
这里我们还是拿01背包问题来举例子。
需要注意的是,这里的优先队列是一个人为的概念,你也可以指定属于自己的优先级排列方式,只要言之有理,能让速度加快即可。
结合贪心算法,这里我们假设能够只拿物品的一部分把背包塞满,每次从队列中取出上限值最大的一个结点(即 从该结点出发到叶子节点在理想情况下可能得到的最大价值)
注意是“可能得到的最大价值”,真实情况下由于每件商品只能整体选择或者不选,因此价值总和总是小于等于该最大上限值,而且随着道路的不断前进,该最优值总是不断减小,越来越接近真实值,当走完全程考虑完所有商品时,该最优值就变成了真实值。
也就是说,价值上限=节点现有价值+背包剩余容量*剩余物品的最大单位重量价值
现在我们计算出它们的性价比,我们每次都选取单位重量下价值最大的那个物品,并且假定我们可以只选取物品的一部分。
| 商品 | 重量 | 价值 | 性价比 |
|---|---|---|---|
| A | 3 | 66 | 22 |
| B | 2 | 40 | 20 |
| C | 5 | 95 | 19 |
| D | 4 | 40 | 10 |
性价比:A>B>C>D
最大上限值的计算,就拿A结点来举例好了:
第一步:如实计算已选道路:在此道路中A是必选的
- 选A,总重量3,总价值0+66=66
第二步:贪婪算法计算未知道路。
我们依次选取出性价比最高的物品:
- 选A+B,总重量5,总价值66+40=106
- 选A+B+部分C,总重量9,106+4*19=182
所以A结点的上限为182。
遍历方法:
我们每次都从优先队列中取出上限值最大的一个结点,依次加入该结点的子节点进行遍历,直到弹出的上限值(即 最大最优价值)为某一叶子节点(即 结果),此叶子节点即为获得背包最大价值的最优组合方式,因为它比其他道路最优的情况还要好,那么它一定大于其他道路的真实价值。
物品类:
public class Knapsack implements Comparable<Knapsack> {
/*物品重量*/
private int weight;
/*物品价值*/
private int value;
/*单位重量价值*/
private int unitValue;
public Knapsack(int weight, int value){
this.weight = weight;
this.value = value;
this.unitValue = (weight == 0) ? 0 : value/weight;
}
public int getWeight(){
return weight;
}
public void setWeight(int weight){
this.weight = weight;
}
public int getValue(){
return value;
}
public void setValue(int value){
this.value = value;
}
public int getUnitValue(){
return unitValue;
}
@Override
public int compareTo(Knapsack snapsack) {
int value = snapsack.unitValue;
if (unitValue > value)
return 1;
if (unitValue < value)
return -1;
return 0;
}
}
当前状态结点:
/*当前操作的节点,放入物品或不放入物品*/
class Node {
/*当前放入物品的重量*/
private int currWeight;
/*当前放入物品的价值*/
private int currValue;
/*不放入当前物品可能得到的价值上限*/
private int upperLimit;
/*当前操作物品的索引*/
private int index;
public Node(int currWeight, int currValue, int index) {
this.currWeight = currWeight;
this.currValue = currValue;
this.index = index;
}
}
实现:
public class ZeroAndOnePackage {
/*物品数组*/
private Knapsack[] knapsacks;
/*背包承重量*/
private int totalWeight;
/*物品数*/
private int num;
/*可以获得的最大价值*/
private int bestValue;
public ZeroAndOnePackage(Knapsack[] knapsacks, int totalWeight) {
super();
this.knapsacks = knapsacks;
this.totalWeight = totalWeight;
this.num = knapsacks.length;
/*物品依据单位重量价值进行排序*/
Arrays.sort(knapsacks, Collections.reverseOrder());
}
public int getBestValue() {
return bestValue;
}
/*价值上限=节点现有价值+背包剩余容量*剩余物品的最大单位重量价值
*当物品由单位重量的价值从大到小排列时,计算出的价值上限大于所有物
*品的总重量,否则小于物品的总重量当放入背包的物品越来越来越多时,
*价值上限也越来越接近物品的真实总价值
*/
private int getPutValue(Node node) {
/*获取背包剩余容量*/
int surplusWeight = totalWeight - node.currWeight;
int value = node.currValue;
int i = node.index;
while (i < this.num && knapsacks[i].getWeight() <= surplusWeight) {
surplusWeight -= knapsacks[i].getWeight();
value += knapsacks[i].getValue();
i++;
}
/*当物品超重无法放入背包中时,可以通过背包剩余容量*下个物品单位重量的价值计算出物品的价值上限*/
if (i < this.num) {
value += knapsacks[i].getUnitValue() * surplusWeight;
}
return value;
}
public void findMaxValue() {
LinkedList<Node> nodeList = new LinkedList<Node>();
/*起始节点当前重量和当前价值均为0*/
nodeList.add(new Node(0, 0, 0));
while (!nodeList.isEmpty()) {
/*取出放入队列中的第一个节点*/
Node node = nodeList.pop();
// 如果当前结点的上限大于等于最大价值并且结点索引小于物品总数,那就可以进行操作
// 否则,没啥操作的必要,上限都没当前最大价值大,何必操作呢
if (node.upperLimit >= bestValue && node.index < num) {
/*左节点:该节点代表物品放入背包中,上个节点的价值+本次物品的价值为当前价值*/
int leftWeight = node.currWeight + knapsacks[node.index].getWeight();
int leftValue = node.currValue + knapsacks[node.index].getValue();
Node left = new Node(leftWeight, leftValue, node.index + 1);
/*放入当前物品后可以获得的价值上限*/
left.upperLimit = getPutValue(left);
/*当物品放入背包中左节点的判断条件为保证不超过背包的总承重*/
if (left.currWeight <= totalWeight && left.upperLimit > bestValue) {
/*将左节点添加到队列中*/
nodeList.add(left);
if (left.currValue > bestValue) {
/*物品放入背包不超重,且当前价值更大,则当前价值为最大价值*/
bestValue = left.currValue;
}
}
/*右节点:该节点表示物品不放入背包中,上个节点的价值为当前价值*/
Node right = new Node(node.currWeight, node.currValue,node.index + 1);
/*不放入当前物品后可以获得的价值上限*/
right.upperLimit = getPutValue(right);
if (right.upperLimit >= bestValue) {
/*将右节点添加到队列中*/
nodeList.add(right);
}
}
}
}
public static void main(String[] args) {
Knapsack[] knapsack = new Knapsack[] {
new Knapsack(2, 13),new Knapsack(1, 10), new Knapsack(3, 24), new Knapsack(2, 15),
new Knapsack(4, 28), new Knapsack(5, 33), new Knapsack(3, 20),new Knapsack(1, 8)};
int totalWeight = 12;
ZeroAndOnePackage zeroAndOnePackage = new ZeroAndOnePackage(knapsack, totalWeight);
zeroAndOnePackage.findMaxValue();
System.out.println("最大价值为:"+zeroAndOnePackage.getBestValue());
}
}
优化理论
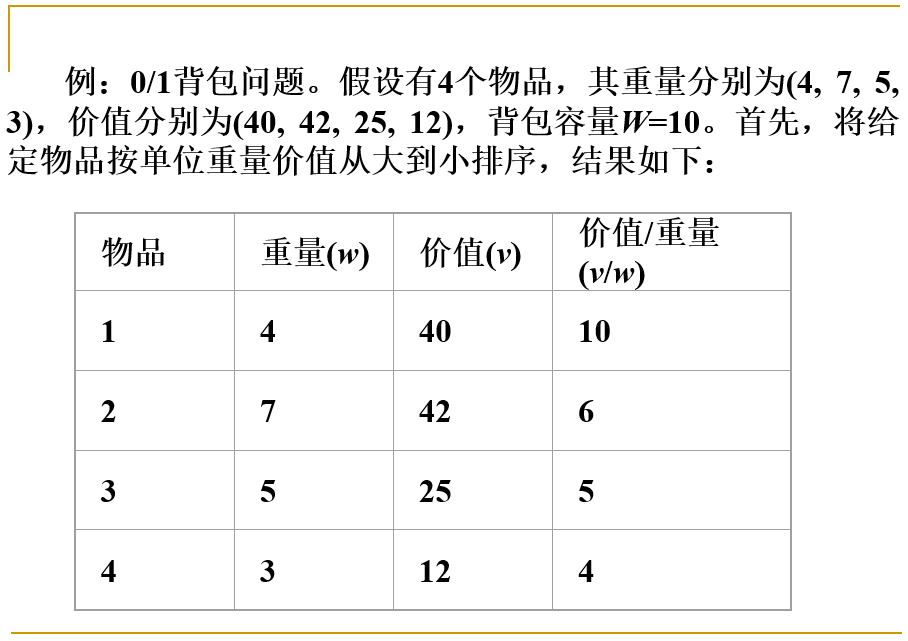
1. 问题描述
设有n个物体和一个背包,物体i的重量为wi价值为pi ,背包的载荷为M, 若将物体i(1<= i <=n)装入背包,则有价值为pi . 目标是找到一个方案, 使得能放入背包的物体总价值最高.
设N=3, W=(16,15,15), P=(45,25,25), C=30(背包容量)
2. 队列式分支限界法
可以通过画分支限界法状态空间树的搜索图来理解具体思想和流程
每一层按顺序对应一个物品放入背包(1)还是不放入背包(0)
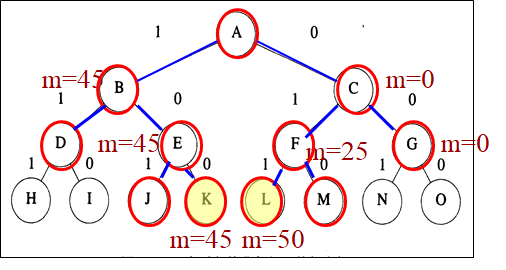
步骤:
-
用一个队列存储活结点表,初始为空
-
A为当前扩展结点,其儿子结点B和C均为可行结点,将其按从左到右顺序加入活结点队列,并舍弃A。
-
按FIFO原则,下一扩展结点为B,其儿子结点D不可行,舍弃;E可行,加入。舍弃B
-
C为当前扩展结点,儿子结点F、G均为可行结点,加入活结点表,舍弃C
-
扩展结点E的儿子结点J不可行而舍弃;K为可行的叶结点,是问题的一个可行解,价值为45
-
当前活结点队列的队首为F, 儿子结点L、M为可行叶结点,价值为50、25
-
G为最后一个扩展结点,儿子结点N、O均为可行叶结点,其价值为25和0
-
活结点队列为空,算法结束,其最优值为50
注意:活结点就是不可再进行扩展的节点,也就是两个儿子还没有全部生成的节点
3. 优先队列式分支限界法
3.1 以活结点价值为优先级准则

步骤:
-
用一个极大堆表示活结点表的优先队列,其优先级定义为活结点所获得的价值。初始为空。
-
由A开始搜索解空间树,其儿子结点B、C为可行结点,加入堆中,舍弃A。
-
B获得价值45,C为0. B为堆中价值最大元素,并成为下一扩展结点。
-
B的儿子结点D是不可行结点,舍弃。E是可行结点,加入到堆中。舍弃B。
-
E的价值为45,是堆中最大元素,为当前扩展结点。
-
E的儿子J是不可行叶结点,舍弃。K是可行叶结点,为问题的一个可行解价值为45。
-
继续扩展堆中唯一活结点C,直至存储活结点的堆为空,算法结束。
-
算法搜索得到最优值为50,最优解为从根结点A到叶结点L的路径(0,1,1)。
3.2 以限界函数为优先级准则
应用贪心法求得近似解为(1, 0, 0, 0),获得的价值为40,这可以作为0/1背包问题的下界。
如何求得0/1背包问题的一个合理的上界呢?考虑最好情况,背包中装入的全部是第1个物品且可以将背包装满,则可以得到一个非常简单的上界的计算方法:
b=W×(v1/w1)=10×10=100。于是,得到了目标函数的界[40, 100]。
所以我们定义限界函数为:
再来画状态空间树的搜索图:
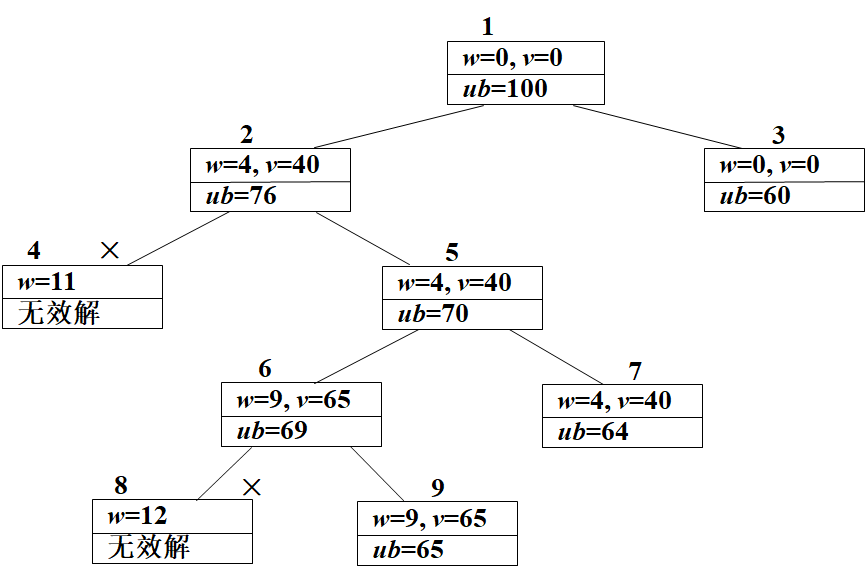
步骤:
-
在根结点1,没有将任何物品装入背包,因此,背包的重量和获得的价值均为0,根据限界函数计算结点1的目标函数值为10×10=100;
-
在结点2,将物品1装入背包,因此,背包的重量为4,获得的价值为40,目标函数值为40 + (10-4)×6=76,将结点2加入待处理结点表PT中;在结点3,没有将物品1装入背包,因此,背包的重量和获得的价值仍为0,目标函数值为10×6=60,将结点3加入表PT中;
-
在表PT中选取目标函数值取得极大的结点2优先进行搜索;
-
在结点4,将物品2装入背包,因此,背包的重量为11,不满足约束条件,将结点4丢弃;在结点5,没有将物品2装入背包,因此,背包的重量和获得的价值与结点2相同,目标函数值为40 + (10-4)×5=70,将结点5加入表PT中;
-
在表PT中选取目标函数值取得极大的结点5优先进行搜索;
-
在结点6,将物品3装入背包,因此,背包的重量为9,获得的价值为65,目标函数值为65 + (10-9)×4=69,将结点6加入表PT中;在结点7,没有将物品3装入背包,因此,背包的重量和获得的价值与结点5相同,目标函数值为40 + (10-4)×4=64,将结点6加入表PT中;
-
在表PT中选取目标函数值取得极大的结点6优先进行搜索;
-
在结点8,将物品4装入背包,因此,背包的重量为12,不满足约束条件,将结点8丢弃;在结点9,没有将物品4装入背包,因此,背包的重量和获得的价值与结点6相同,目标函数值为65;
-
由于结点9是叶子结点,同时结点9的目标函数值是表PT中的极大值,所以,结点9对应的解即是问题的最优解,搜索结束。
总结:
-
剪枝函数给出每个可行结点相应的子树可能获得的最大价值的上界。
-
如这个上界不会比当前最优值更大,则可以剪去相应的子树。
-
也可将上界函数确定的每个结点的上界值作为优先级,以该优先级的非增序抽取当前扩展结点。由此可快速获得最优解。
题外话
分支界限法一直是我比较喜欢的算法思想,我们的人生不就是这样一棵二叉树吗?从出生开始最终走向终点,不同的道路决定不同的终点,在每个分岔口不妨试着用分支界限法的思想帮助我们做出判断,快速走向最美好的人生。对于每次选择,我们不妨先算一算它的最优和最差结果,对于最优结果,我们可以想一想它值不值得我们付出精力去做,对于最差结果,我们想一想能不能承担的了,或许不需要结果,在计算的过程中突然就有了答案。。。
笔者将不定期更新【考研或就业】的专业相关知识以及自身理解,希望大家能【关注】我。
如果觉得对您有用,请点击左下角的【点赞】按钮,给我一些鼓励,谢谢!
如果有更好的理解或建议,请在【评论】中写出,我会及时修改,谢谢啦!
本文来自博客园,作者:Nemo&
转载请注明原文链接:https://www.cnblogs.com/blknemo/p/14375477.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号