【Java】Java8新特性
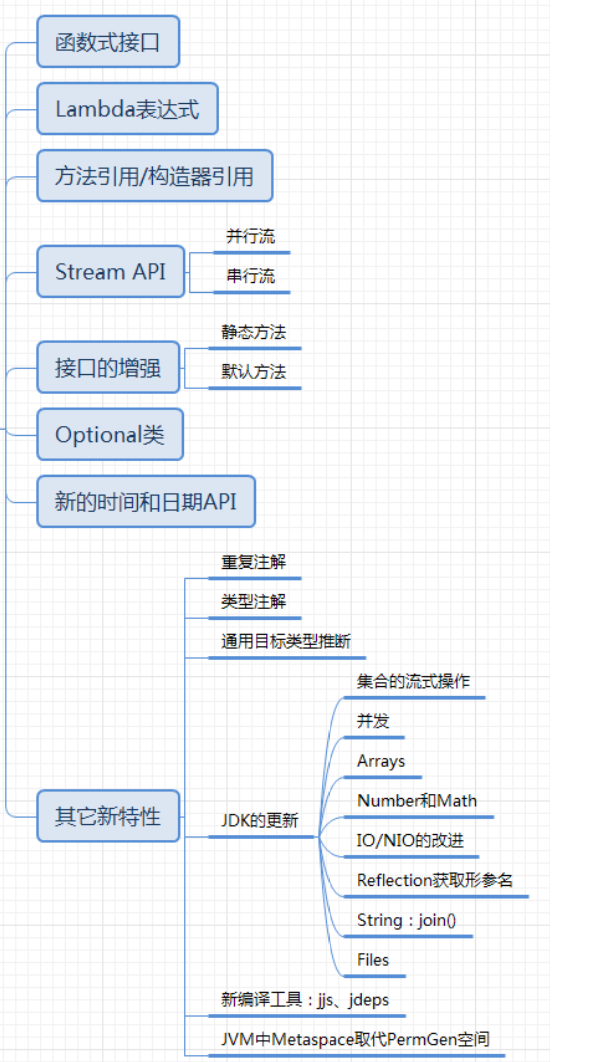
Java 8新特性汇总
Java 8的改进
速度更快
代码更少(增加了新的语法:Lambda表达式)
引入强大的Stream APl
便于并行
最大化减少空指针异常:Optional
Nashorn引擎,允许在JVM上运行JS应用
并行流就是把一个内容分成多个数据块,并用不同的线程分别处理每个数据块的流。相比较串行的流,并行的流可以很大程度上提高程序的执行效率。
Java 8中将并行进行了优化,我们可以很容易的对数据进行并行操作。Stream API可以声明性地通过 parallel()与 sequential()在并行流与顺序流之间进行切换
一、Lambda表达式
大家可以想象一下这样一个场景,我们临时想用一个学生对象,只用那么一次,之后就不会再用了,大家难道要为这一次使用特意去声明一个具体的对象吗?
这样,就有了我们的匿名对象这样一个概念。
而匿名函数(Lambda表达式)也是如此,在一个场景,我们临时只想用这个函数一次,肯定不想去特意声明一个函数呀!
匿名对象:new Student();
匿名函数:(x,y) -> {}
1. Lambda表达式概述
Lambda是一个匿名函数,可以把Lambda表达式理解为是一段可以传递的代码(将代码像数据一样进行传递)。使用它可以写出更简洁、更灵活的代码。作为一种更紧凑的代码风格,使Java的语言表达能力得到了提升。
其实Lambda表达式就是实现函数式接口的方法的一种表达式方式,用来表示一个函数式接口的对象实例。
以前创建(new)一个接口的对象时,我们使用的是匿名内部类的方式,实现接口中的抽象方法,并创建。
现在使用Lambda表达式可以直接使用此表达式来实现接口中的抽象方法,来表示一个函数式接口的对象实例,并创建。
new Interface() {public int f() {...}} 等价于 () -> {...}
为什么要使用Lambda表达式
下面我们来看这样一个例子:
@Test
public void test1() {
Comparator<Integer> com = new Comparator<Integer>() {
@Override
public int compare(Integer o1, Integer o2) {
return Integer.compare(o1, o2); //就这一句有用
}
};
TreeSet<Integer> ts = new TreeSet<>(com);
}
大家发现没有,整段有用得到代码实际上就这一句话:return Integer.compare(o1, o2);
使用Lambda表达式以后:
//Lambda表达式
@Test
public void test2() {
Comparator<Integer> com = (x, y) -> Integer.compare(x, y);
TreeSet<Integer> ts = new TreeSet<>(com);
}
业务功能实现方式举例
首先,先创建一个Employee的类,里面包含属性name, age, salary,添加set、get方法,toString方法,以及无参和有参构造函数;
List<Employee> employees = Arrays.asList(
new Employee("张三", 18, 9999 .99),
new Employee("李四", 38, 5555.99),
new Employee("王五", 50, 6666.66),
new Employee("赵六", 16, 3333.33),
new Employee("田七", 8, 7777.77)
);
需求一
需求:获取当前公司员工年龄大于35的员工信息;
//需求:获取当前公司中员工年龄大于35的员工信息
@Test
public void test3( ) {
List<Employee> list = filterEmployees employees);
for (Employee employee : list) {
System.out.println(employee);
}
}
public List<Employee> filterEmployees(List<Employee> list){
List<Employee> emps = new ArrayList<>();
for (Employee emp : list) {
if(emp.getAge() >= 35) {
emps.add(emp);
}
}
return emps;
}
运行结果:
Employee [name=李四, age=38, salary=5555.99]
Employee [name=王五, age=50, salary=6666.66]
需求二
需求:获取当前公司中员工工资大于5000的员工信息
//需求:获取当前公司中员工工资大于5000的员工信息
public List<Employee> filterEmployees2(List<Employee> list){
List<Employee> emps = new ArrayList<>();
for (Employee emp : list) {
if(emp. getSalary() >= 5000) { // 冗余的代码
emps.add(emp);
}
}
return emps;
}
会发现以前的操作方法十分繁复冗余,那么可以通过哪些方式可以来优化代码呢?
优化方法一:策略设计模式
采用设计模式。
设计接口:
public interface MyPredicate<T> { // 添加泛型
public boolean test(T t);
}
需求一
然后在类中实现该接口:
public class FilterEmployeeByAge implements MyPredicate<Employee> {
@Override
public boolean test(Employee t) {
return t.getAge() >= 35;
}
}
优化后的写法:
//代化方式一:
@Test
public void test4(){
List<Employee> list = filterEmployee(employees, new FilterEmployeeByAge());
for (Employee employee : list) {
System.out.println(employee);
}
}
//代化方式一:
public List<Employee> filtermployee(List<Employee> list, MyPredicate<Employee> mp) {
List<Employee> emps = new ArrayList<>();
for (Employee employee : list) {
if(mp.test(employee) {
emps.add(employee);
}
}
return emps ;
}
运行结果:
Employee [name=李四, age=38, salary=5555.99]
Employee [name=王五, age=50, salary=6666.66]
需求二
public class FilterEmployeeBySalary implements MyPredicate<Employee> {
@Override
public boolean test(Employee t) {
return t.getSalary() >= 5000;
}
}
//代化方式一:
@Test
public void test4() {
List<Employee> list = filterEmployee(employees, new FilterEmployeeByAge());
for (Employee employee : list) {
System.out.println(employee);
}
System.out.println("-------------------------");
List<Employee> list2 = filterEmployee(employees, new FilterEmploveeBySalary());
for (Employee employee : list2) {
System.out.println(employee);
}
}
运行结果
Employee [name=李四, age=38, salary=5555.99]
Employee [name=王五, age=50, salary=6666.66]
------------------------------
Employee [name=张三, age=18, salary=9999.99]
Employee [name=李四, age=38, salary=5555.99]
Emplayee [name=王五, age=50, salary=6666.66]
Employee [name=田七, age=8, salary=7777.77]
缺点:每次实现一个策略,必须新建一个类;
优化方式二:匿名内部类
public List<Employee> filterEmployee(List<Employee> list, MyPredicate<Employee> mp) {
List<Employee> emps = new ArrayList<>();
for (Employee employee : list) {
if(mp.test(employee)){
emps.add(employee);
}
}
return emps ;
}
//代化方式二:匿名内部类
@Test
public void test5() {
List<Employee> list = filterEmployee(employees, new MyPredicate<Employee>() {
@Override
public boolean test(Employee t) {
return t.getSalary() <= 5000;
}
});
for (Employee employee : list) {
System.out.println(employee);
}
}
运行结果
Employee [name=赵六, age=16, salary=3333.33]
优化方式三:Lambda表达式(策略设计模式)
public List<Employee> filterEmployee(List<Employee> list, MyPredicate<Employee> mp) {
List<Employee> emps = new ArrayList<>();
for (Employee employee : list) {
if (mp.test(employee)) {
emps.add(employee);
}
}
return emps ;
}
//代化方式三: Lambda 表达式
@Test
public void test6() {
List<Employee> list = filterEmployee(employees, (e) -> e.getSalary() <= 5000);
list.forEach(System.out::println);
}
运行结果
Employee [name=赵六, age=16, salary=3333.33]
优化方式四:Stream API
//优化方式四:
@Test
public void test7() {
employees.stream( )
.filter((e) -> e.getSalary())= 5000)
.limit(2) //输出前2个
.forEach(System.out::println);
System.out.println("-------------------------");
//只打印出名字
employees.stream()
.map(Employee::getName)
.forEach(System.out::println);
}
运行结果
Employee [name=张三, age=18, salary=9999.99]
Employee [name=李四, age=38, salary=5555.99]
-------------------------
张三
李四
王五
赵六
田七
2. 使用Lambda表达式前后对比
示例一:调用Runable接口
@Test
public void test1(){
//未使用Lambda表达式的写法
Runnable r1 = new Runnable() {
@Override
public void run() {
System.out.println("hello Lambda!");
}
};
r1.run();
System.out.println("========================");
//Lambda表达式写法
Runnable r2 = () -> System.out.println("hi Lambda!");
r2.run();
}
示例二:使用Comparator接口
@Test
public void test2(){
//未使用Lambda表达式的写法
Comparator<Integer> com1 = new Comparator<Integer>() {
@Override
public int compare(Integer o1, Integer o2) {
return Integer.compare(o1,o2);
}
};
int compare1 = com1.compare(12, 32);
System.out.println(compare1);//-1
System.out.println("===================");
//Lambda表达式的写法
Comparator<Integer> com2 = (o1,o2) -> Integer.compare(o1,o2);
int compare2 = com2.compare(54, 21);
System.out.println(compare2);//1
System.out.println("===================");
//方法引用
Comparator<Integer> cpm3 = Integer::compareTo;
int compare3 = cpm3.compare(12, 12);
System.out.println(compare3);//0
}
3. 怎样使用Lambda表达式
3.1 Lambda表达式基本语法
1.举例: (o1,o2) -> Integer.compare(o1,o2);
2.格式:
-> :lambda操作符 或 箭头操作符
-> 左边:lambda形参列表 (其实就是接口中的抽象方法的形参列表)
-> 右边:lambda体 (其实就是重写的抽象方法的方法体)
3.2Lambda表达式使用(包含六种情况)
左右遇一括号省,左侧推断类型省。
3.2.1 语法格式一:无参,有返回值
Runnable r1 = () -> {System.out.println(“hello Lambda!”)}
3.2.2语法格式二:Lambda需要一个参数,但没有返回值
Consumer<String> con = (String str) -> {System.out.println(str)}
3.2.3 语法格式三:数据类型可省略,因为可由编译器推断得出,称为类型推断
Consumer<String> con = (str) -> {System.out.println(str)}
其实,类型推断我们很早就用过了,看看下面这个例子:
String[] strs = {"a", "b", "c"}; // 这个abc我们没写类型,但是它还是推断出来了
int[] ints;
ints = {1, 2, 3}; // 这样会报错噢,因为我们根据该语句推断不出来abc的类型
List<String> list = new ArrayList<>(); // 类型推断
3.2.4 语法格式四:Lambda若只需要一个参数时,小括号可以省略
Consumer<String> con = str -> {System.out.println(str)}
3.2.5 语法格式五:Lambda需要两个以上的参数,多条执行语句,并且可以有返回值
Comparator<Integer>com = (o1,o1) -> {
Syste.out.println("Lambda表达式使用");
return Integer.compare(o1,o2);
}
3.2.6 语法格式六:当Lambda体只有一条语句时,return和大括号若有,都可以省略
Comparator<Integer>com = (o1,o1) -> Integer.compare(o1,o2);
代码示例:
public class LambdaTest2 {
//语法格式一:无参,无返回值
@Test
public void test1() {
//未使用Lambda表达式
Runnable r1 = new Runnable() {
@Override
public void run() {
System.out.println("Hello Lambda");
}
};
r1.run();
System.out.println("====================");
//使用Lambda表达式
Runnable r2 = () -> {
System.out.println("Hi Lambda");
};
r2.run();
}
//语法格式二:Lambda 需要一个参数,但是没有返回值。
@Test
public void test2() {
//未使用Lambda表达式
Consumer<String> con = new Consumer<String>() {
@Override
public void accept(String s) {
System.out.println(s);
}
};
con.accept("你好啊Lambda!");
System.out.println("====================");
//使用Lambda表达式
Consumer<String> con1 = (String s) -> {
System.out.println(s);
};
con1.accept("我是Lambda");
}
//语法格式三:数据类型可以省略,因为可由编译器推断得出,称为“类型推断”
@Test
public void test3() {
//未使用Lambda表达式
Consumer<String> con = new Consumer<String>() {
@Override
public void accept(String s) {
System.out.println(s);
}
};
con.accept("你好啊Lambda!");
System.out.println("====================");
//使用Lambda表达式
Consumer<String> con1 = (s) -> {
System.out.println(s);
};
con1.accept("我是Lambda");
}
@Test
public void test(){
ArrayList<String> list = new ArrayList<>();//类型推断,用左边推断右边
int[] arr = {1,2,3,4};//类型推断,用左边推断右边
}
//语法格式四:Lambda 若只需要一个参数时,参数的小括号可以省略
@Test
public void test4() {
//未使用Lambda表达式
Consumer<String> con = new Consumer<String>() {
@Override
public void accept(String s) {
System.out.println(s);
}
};
con.accept("你好啊Lambda!");
System.out.println("====================");
//使用Lambda表达式
Consumer<String> con1 = s -> {
System.out.println(s);
};
con1.accept("我是Lambda");
}
//语法格式五:Lambda 需要两个或以上的参数,多条执行语句,并且可以有返回值
@Test
public void test5() {
//未使用Lambda表达式
Comparator<Integer> com1 = new Comparator<Integer>() {
@Override
public int compare(Integer o1, Integer o2) {
System.out.println(o1);
System.out.println(o2);
return Integer.compare(o1, o2);
}
};
System.out.println(com1.compare(23, 45));
System.out.println("====================");
//使用Lambda表达式
Comparator<Integer> com2 = (o1, o2) -> {
System.out.println(o1);
System.out.println(o2);
return o1.compareTo(o2);
};
System.out.println(com2.compare(23, 12));
}
//语法格式六:当 Lambda 体只有一条语句时,return 与大括号若有,都可以省略
@Test
public void test6() {
//未使用Lambda表达式
Comparator<Integer> com1 = new Comparator<Integer>() {
@Override
public int compare(Integer o1, Integer o2) {
return Integer.compare(o1, o2);
}
};
System.out.println(com1.compare(23, 45));
System.out.println("====================");
//使用Lambda表达式
Comparator<Integer> com2 = (o1, o2) -> o1.compareTo(o2);
System.out.println(com2.compare(23, 12));
}
@Test
public void test7(){
//未使用Lambda表达式
Consumer<String> con1 = new Consumer<String>() {
@Override
public void accept(String s) {
System.out.println(s);
}
};
con1.accept("hi!");
System.out.println("====================");
//使用Lambda表达式
Consumer<String> con2 = s -> System.out.println(s);
con2.accept("hello");
}
}
3.3 Lambda表达式使用总结
-> 左边:lambda形参列表的参数类型可以省略(类型推断);如果lambda形参列表只有一个参数,其一对()也可以省略
-> 右边:lambda体应该使用一对{}包裹;如果lambda体只有一条执行语句(可能是return语句),省略这一对{}和return关键字
4. Lambda表达式总结
Lambda表达式的本质:作为函数式接口的实例
如果一个接口中,只声明了一个抽象方法,则此接口就称为函数式接口。我们可以在一个接口上使用 @FunctionalInterface 注解,这样做可以检查它是否是一个函数式接口。
因此以前用匿名实现类表示的现在都可以用Lambda表达式来写。
二、函数式接口
1. 函数式接口概述
只包含一个抽象方法的接口,称为函数式接口。
类比:相当于数学里面的f(x)。
可以通过Lambda表达式来创建该接口的对象。(若Lambda表达式抛出一个受检异常(即:非运行时异常),那么该异常需要在目标接口的抽象方法上进行声明)。
可以在一个接口上使用@FunctionalInterface注解,这样做可以检查它是否是一个函数式接口。同时 javadoc也会包含一条声明,说明这个接口是一个函数式接口。
Lambda表达式的本质:作为函数式接口的实例
在 java.util.function 包下定义了Java 8的丰富的函数式接口
自定义函数式接口
@FunctionalInterface
public interface MyInterface {
void method1();
}
2. 适用场景
当某种方法中,前面一部分是通用的代码,后面一部分代码灵活多变,就可以使用函数式接口作为参数,来将后面一部分代码提取出来,延迟定义。
- 可以实现回调函数,如 当对象状态改变,则调用Consumer回调函数
callback.accept(i);;
实例:在安卓中监听器监听某控件的改变,调用回调函数完成业务逻辑,就是这样实现的。
public test(Consumer<Integer> callback) {
// ...监听到某控件状态改变
// 下面声明了回调函数,留给用户进行回调使用
callback.accept(i);
}
- 可以提取出公共的代码片段,只修改不同的那部分代码。
public test(Consumer<Integer> callback) {
// ...通用代码片段
callback.accept(i);
}
3. Java内置函数式接口
Runnable接口可以当做是一种特殊的『函数式』接口,输入输出均为空,只是执行方法过程,包含方法void run()
3.1四大核心函数式接口

| 函数式接口 | 参数类型 | 返回类型 | 用途 |
|---|---|---|---|
Consumer<T>消费型接口 |
T | void | 对类型为T的对象应用操作,包含方法:void accept(T t) |
Supplier<T>供给型接口 |
无 | T | 返回类型为T的对象,包含方法:T get() |
Function<T, R>函数型接口 |
T | R | 对类型为T的对象应用操作,并返回结果。结果是R类型的对象。包含方法:R apply(T t) |
Predicate<T>断定型接口 |
T | boolean | 确定类型为T的对象是否满足某约束,并返回boolean值。包含方法:boolean test(T t) |
理解:
消费型:有参数、没有返回值。类似于生物中的消费者。把传过去的参数消费完了,没有返回的值了,有去无回;
供给型:无参数、有返回值。类似于生物中的生产者。不需要传过去参数,就能供给返回值,默默付出。
函数型:有参数、有返回值。类似于数学中的自变量与因变量,一一映射。
断言型:有参数、有布尔返回值。断定参数是否满足条件,明察秋毫。
应用举例
public class LambdaTest3 {
// 消费型接口 Consumer<T> void accept(T t)
@Test
public void test1() {
//未使用Lambda表达式
Learn("java", new Consumer<String>() {
@Override
public void accept(String s) {
System.out.println("学习什么? " + s);
}
});
System.out.println("====================");
//使用Lambda表达
Learn("html", s -> System.out.println("学习什么? " + s));
}
// 变量s相当于数学里面的自变量x,接口Consumer相当于函数f(x)
private void Learn(String s, Consumer<String> stringConsumer) {
stringConsumer.accept(s);
}
// 供给型接口 Supplier<T> T get()
@Test
public void test2() {
//未使用Lambdabiaodas
Supplier<String> sp = new Supplier<String>() {
@Override
public String get() {
return new String("我能提供东西");
}
};
System.out.println(sp.get());
System.out.println("====================");
//使用Lambda表达
Supplier<String> sp1 = () -> new String("我能通过lambda提供东西");
System.out.println(sp1.get());
}
//函数型接口 Function<T,R> R apply(T t)
@Test
public void test3() {
//使用Lambda表达式
Employee employee = new Employee(1001, "Tom", 45, 10000);
Function<Employee, String> func1 =e->e.getName();
System.out.println(func1.apply(employee));
System.out.println("====================");
//使用方法引用
Function<Employee,String>func2 = Employee::getName;
System.out.println(func2.apply(employee));
}
//断定型接口 Predicate<T> boolean test(T t)
@Test
public void test4() {
//使用匿名内部类
Function<Double, Long> func = new Function<Double, Long>() {
@Override
public Long apply(Double aDouble) {
return Math.round(aDouble);
}
};
System.out.println(func.apply(10.5));
System.out.println("====================");
//使用Lambda表达式
Function<Double, Long> func1 = d -> Math.round(d);
System.out.println(func1.apply(12.3));
System.out.println("====================");
//使用方法引用
Function<Double,Long>func2 = Math::round;
System.out.println(func2.apply(12.6));
}
}
3.2 其他函数式接口

| 函数式接口 | 参数类型 | 返回类型 | 用途 |
|---|---|---|---|
BiFunction<T, U, R> |
T, U | R | 对类型为T, U的对象应用操作,返回R类型的结果。包含方法:R apply(T t, U u) |
UnaryOperator<T>(Function子接口) |
T | T | 对类型为T的对象进行一元运算,并返回T类型的结果。包含方法为:T apply(T t) |
BinaryOperator<T>(BiFunction子接口) |
T, T | T | 对类型为T的对象进行二元运算,并返回T类型的结果。包含方法为:T apply(T t1, T t2) |
BiConsumer<T, U> |
T, U | void | 对类型为T, U参数应用操作。包含方法为:void accept(T t, U u) |
BiPredicate<T, U> |
T, U | boolean | 包含方法为:boolean test(T t, U u) |
ToIntFunction<T> |
T | int | 计算int值的函数 |
ToLongFunction<T> |
T | long | 计算long值的函数 |
ToDoubleFunction<T> |
T | double | 计算double值的函数 |
IntFunction<T> |
int | R | 参数为int类型的函数 |
LongFunction<T> |
long | R | 参数为long类型的函数 |
DoubleFunction<T> |
Double | R | 参数为double类型的函数 |
4. 使用总结
4.1 何时使用lambda表达式?
当需要对一个函数式接口实例化的时候,可以使用lambda表达式。
4.2 何时使用给定的函数式接口?
如果我们开发中需要定义一个函数式接口,首先看看在已有的jdk提供的函数式接口是否提供了能满足需求的函数式接口。如果有,则直接调用即可,不需要自己再自定义了。
三、方法的引用
1. 方法引用概述
方法引用可以看做是Lambda表达式深层次的表达。换句话说,方法引用就是Lambda表达式,也就是函数式接口的一个实例,通过方法的名字来指向一个方法。
str -> System.out.println(str);等价于System.out::println
2. 使用情景
当要传递给Lambda体的操作,已经有实现的方法了,就可以使用方法引用!
相当于使用已经实现好的函数的操作方法,注意噢,仅仅是使用操作的方法(过程,功能),即 数学中的f()连里面的x都不需要,仅仅是操作方法。
所以方法引用不需要传递参数。
3. 使用格式
类(或对象) :: 方法名
:::作用域操作符。指明了方法的作用域(即 类,对象)。
类比:在C++中代表作用域操作符。如 类作用域操作符指明了成员函数所属的类。
4. 使用情况
情况1 对象 :: 非静态方法
情况2 类 :: 静态方法
情况3 类 :: 非静态方法
5. 使用要求
要求接口中的抽象方法的形参列表和返回值类型与方法引用的方法的形参列表和返回值类型相同!(针对于情况1和情况2)
当函数式接口方法的第一个参数是需要引用方法的调用者,并且第二个参数是需要引用方法的参数(或无参数)时:ClassName::methodName(针对于情况3)
6. 使用建议
如果给函数式接口提供实例,恰好满足方法引用的使用情境,就可以考虑使用方法引用给函数式接口提供实例。如果不熟悉方法引用,那么还可以使用lambda表达式。
7. 使用举例
public class MethodRefTest {
// 情况一:对象 :: 实例方法
//Consumer中的void accept(T t)
//PrintStream中的void println(T t)
@Test
public void test1() {
//使用Lambda表达
Consumer<String> con1 = str -> System.out.println(str);
con1.accept("中国");
System.out.println("====================");
//使用方法引用
PrintStream ps = System.out;
Consumer con2 = ps::println;
con2.accept("China");
}
//Supplier中的T get()
//Employee中的String getName()
@Test
public void test2() {
//使用Lambda表达
Employee emp = new Employee(1001, "Bruce", 34, 600);
Supplier<String> sup1 = () -> emp.getName();
System.out.println(sup1.get());
System.out.println("====================");
//使用方法引用
Supplier sup2 = emp::getName;
System.out.println(sup2.get());
}
// 情况二:类 :: 静态方法
//Comparator中的int compare(T t1,T t2)
//Integer中的int compare(T t1,T t2)
@Test
public void test3() {
//使用Lambda表达
Comparator<Integer> com1 = (t1, t2) -> Integer.compare(t1, t2);
System.out.println(com1.compare(32, 45));
System.out.println("====================");
//使用方法引用
Comparator<Integer> com2 = Integer::compareTo;
System.out.println(com2.compare(43, 34));
}
//Function中的R apply(T t)
//Math中的Long round(Double d)
@Test
public void test4() {
//使用匿名内部类
Function<Double, Long> func = new Function<Double, Long>() {
@Override
public Long apply(Double aDouble) {
return Math.round(aDouble);
}
};
System.out.println(func.apply(10.5));
System.out.println("====================");
//使用Lambda表达式
Function<Double, Long> func1 = d -> Math.round(d);
System.out.println(func1.apply(12.3));
System.out.println("====================");
//使用方法引用
Function<Double, Long> func2 = Math::round;
System.out.println(func2.apply(12.6));
}
// 情况三:类 :: 实例方法
// Comparator中的int comapre(T t1,T t2)
// String中的int t1.compareTo(t2)
@Test
public void test5() {
//使用Lambda表达式
Comparator<String> com1 = (s1, s2) -> s1.compareTo(s2);
System.out.println(com1.compare("abd", "aba"));
System.out.println("====================");
//使用方法引用
Comparator<String> com2 = String::compareTo;
System.out.println(com2.compare("abd", "abc"));
}
//BiPredicate中的boolean test(T t1, T t2);
//String中的boolean t1.equals(t2)
@Test
public void test6() {
//使用Lambda表达式
BiPredicate<String, String> pre1 = (s1, s2) -> s1.equals(s2);
System.out.println(pre1.test("abc", "abc"));
System.out.println("====================");
//使用方法引用
BiPredicate<String, String> pre2 = String::equals;
System.out.println(pre2.test("abc", "abd"));
}
// Function中的R apply(T t)
// Employee中的String getName();
@Test
public void test7() {
//使用Lambda表达式
Employee employee = new Employee(1001, "Tom", 45, 10000);
Function<Employee, String> func1 =e->e.getName();
System.out.println(func1.apply(employee));
System.out.println("====================");
//使用方法引用
Function<Employee,String>func2 = Employee::getName;
System.out.println(func2.apply(employee));
}
}
四、构造器和数组的引用
1.使用格式
方法引用:类名 :: new
数组引用:数组类型[] :: new
2. 使用要求
2.1 构造器引用
和方法引用类似,函数式接口的抽象方法的形参列表和构造器的形参列表一致。抽象方法的返回值类型即为构造器所属的类的类型
2.2 数组引用
可以把数组看做是一个特殊的类,则写法与构造器引用一致。
3. 使用举例
3.1 构造器引用
//构造器引用
//Supplier中的T get()
@Test
public void test1() {
//使用匿名内部类
Supplier<Employee> sup = new Supplier<Employee>() {
@Override
public Employee get() {
return new Employee();
}
};
System.out.println(sup.get());
//使用Lambda表达式
System.out.println("====================");
Supplier<Employee> sup1 = () -> new Employee(1001, "Tom", 43, 13333);
System.out.println(sup1.get());
//使用方法引用
Supplier<Employee> sup2 = Employee::new;
System.out.println(sup2.get());
}
//Function中的R apply(T t)
@Test
public void test2() {
//使用Lambda表达式
Function<Integer, Employee> func1 = id -> new Employee(id);
Employee employee = func1.apply(1001);
System.out.println(employee);
System.out.println("====================");
//使用方法引用
Function<Integer, Employee> func2 = Employee::new;
Employee employee1 = func2.apply(1002);
System.out.println(employee1);
}
//BiFunction中的R apply(T t,U u)
@Test
public void test3() {
//使用Lambda表达式
BiFunction<Integer, String, Employee> func1 = (id, name) -> new Employee(id, name);
System.out.println(func1.apply(1001, "Tom"));
System.out.println("====================");
//使用方法引用
BiFunction<Integer, String, Employee> func2 = Employee::new;
System.out.println(func2.apply(1002, "Jarry"));
}
3.2 数组引用
//数组引用
//Function中的R apply(T t)
@Test
public void test4() {
Function<Integer, String[]> func1 = length -> new String[length];
String[] arr1 = func1.apply(5);
System.out.println(Arrays.toString(arr1));
System.out.println("====================");
//使用方法引用
Function<Integer,String[]>func2=String[]::new;
String[] arr2 = func2.apply(10);
System.out.println(Arrays.toString(arr2));
}
五、StreamAPI
1. Stream API概述
Stream关注的是对数据的运算,与CPU打交道;集合关注的是数据的存储,与内存打交道;
Java8提供了一套api,使用这套api可以对内存中的数据进行过滤、排序、映射、归约等操作。类似于sql对数据库中表的相关操作。
Stream是数据渠道,用于操作数据源(集合、数组等)所生成的元素序列。“集合讲的是数据, Stream讲的是计算!”
使用注意点:
①Stream 自己不会存储元素。
②Stream 不会改变源对象。相反,他们会返回一个持有结果的新Stream。
③Stream 操作是延迟执行的。这意味着他们会等到需要结果的时候才执行。
2. Stream使用流程
① Stream的实例化
② 一系列的中间操作(过滤、映射、...)
③ 终止操作

使用流程中的注意点:
一个中间操作链,对数据源的数据进行处理
一旦执行终止操作,就执行中间操作链,并产生结果。之后,不会再被使用
3. 使用方法
3.1 步骤一 创建Stream
3.1.1 创建方式一:通过集合
Java 8的Collection接口被扩展,提供了两个获取流的方法:
default Stream<E> stream() : 返回一个顺序流
default Stream<E> parallelStream() : 返回一个并行流
3.1.2 创建方式二:通过数组
Java 8中的Arrays的静态方法stream()可以获取数组流
调用Arrays类的 static<T> Stream<T> stream(T[] array): 返回一个流
重载形式,能够处理对应基本类型的数组:
public static IntStream stream(int[] array)public static LongStream stream(long[] array)public static DoubleStream stream(double[] array)
3.1.3创建方式三:通过Stream的of()方法
可以调用Stream类静态方法of(),通过显示值创建一个流。可以用于接收任意数量的参数,也可以是一个数组。
public static <T>Stream<T> of(T...values):返回一个流
3.1.4 创建方式四:创建无限流
迭代: public static<T> Stream<T> iterate(final T seed, final UnaryOperator<T> f)
生成: public static<T> Stream<T> generate(Supplier<T> s)
代码示例:
public class StreamAPITest1 {
//创建 Stream方式一:通过集合
@Test
public void test1() {
List<Employee> employees = EmployeeData.getEmployees();
//efault Stream<E> stream() : 返回一个顺序流
Stream<Employee> stream = employees.stream();
//default Stream<E> parallelStream() : 返回一个并行流
Stream<Employee> employeeStream = employees.parallelStream();
}
//创建 Stream方式二:通过数组
@Test
public void test2() {
int[] arrs = {1, 2, 3, 6, 2};
//调用Arrays类的static <T> Stream<T> stream(T[] array): 返回一个流
IntStream stream = Arrays.stream(arrs);
Employee e1 = new Employee(1001, "Tom");
Employee e2 = new Employee(1002, "Jerry");
Employee[] employees = {e1, e2};
Stream<Employee> stream1 = Arrays.stream(employees);
}
//创建 Stream方式三:通过Stream的of()
@Test
public void test3() {
Stream<Integer> integerStream = Stream.of(12, 34, 45, 65, 76);
}
//创建 Stream方式四:创建无限流
@Test
public void test4() {
//迭代
//public static<T> Stream<T> iterate(final T seed, final UnaryOperator<T> f)
//遍历前10个偶数
Stream.iterate(0, t -> t + 2).limit(10).forEach(System.out::println);
//生成
//public static<T> Stream<T> generate(Supplier<T> s)
Stream.generate(Math::random).limit(10).forEach(System.out::println);
}
}
3.2 步骤二 中间操作
多个中间操作可以连接起来形成一个流水线,除非流水线上触发终止操作,否则中间操作不会执行任何的处理!而在终止操作时一次性全部处理,称为“惰性求值”。
3.2.1筛选与切片

filter(Predicate p):接收Lambda,从流中排除某些元素distinct():筛选,通过流所生成元素的hashCode()和equals()去除重复元素limit(long maxSize):截断流,使其元素不超过给定数量skip(long n):跳过元素,返回一个扔掉了前n个元素的流。若流中元素不足n个,则返回一个空流。与limit(n)互补
代码示例:
//1-筛选与切片,注意执行终止操作后,Stream流就被关闭了,使用时需要再次创建Stream流
@Test
public void test1(){
List<Employee> employees = EmployeeData.getEmployees();
//filter(Predicate p)——接收 Lambda , 从流中排除某些元素。
Stream<Employee> employeeStream = employees.stream();
//练习:查询员工表中薪资大于7000的员工信息
employeeStream.filter(e -> e.getSalary() > 7000).forEach(System.out::println);
//limit(n)——截断流,使其元素不超过给定数量。
employeeStream.limit(3).forEach(System.out::println);
System.out.println();
//skip(n) —— 跳过元素,返回一个扔掉了前 n 个元素的流。若流中元素不足 n 个,则返回一个空流。与 limit(n) 互补
employeeStream.skip(3).forEach(System.out::println);
//distinct()——筛选,通过流所生成元素的 hashCode() 和 equals() 去除重复元素
employees.add(new Employee(1010,"刘庆东",56,8000));
employees.add(new Employee(1010,"刘庆东",56,8000));
employees.add(new Employee(1010,"刘庆东",56,8000));
employees.add(new Employee(1010,"刘庆东",56,8000));
employeeStream.distinct().forEach(System.out::println);
}
3.2.2 映射
映射相当于x与f(x)之间的关系,f(x)将每一个x都进行了函数操作,一一映射。

map(Function f):接收一个函数作为参数,该函数会被应用到每个元素上,并将其映射成一个新的元素。mapToDouble(ToDoubleFunction f):接收一个函数作为参数,该函数会被应用到每个元素上,产生一个新的DoubleStream。mapToInt(ToIntFunction f):接收一个函数作为参数,该函数会被应用到每个元素上,产生一个新的IntStream。mapToLong(ToLongFunction f):接收一个函数作为参数,该函数会被应用到每个元素上,产生一个新的LongStream。flatMap(Function f):接收一个函数作为参数,将流中的每个值都换成另一个流,然后把所有流连接成一个流。
代码示例:
//2-映射
@Test
public void test2(){
List<String> list = Arrays.asList("aa", "bb", "cc", "dd");
//map(Function f)——接收一个函数作为参数,将元素转换成其他形式或提取信息,该函数会被应用到每个元素上,并将其映射成一个新的元素。
list.stream().map(str -> str.toUpperCase()).forEach(System.out::println);
//练习1:获取员工姓名长度大于3的员工的姓名。
List<Employee> employees = EmployeeData.getEmployees();
Stream<String> nameStream = employees.stream().map(Employee::getName);
nameStream.filter(name -> name.length() >3).forEach(System.out::println);
System.out.println();
//练习2:使用map()中间操作实现flatMap()中间操作方法
Stream<Stream<Character>> streamStream = list.stream().map(StreamAPITest2::fromStringToStream);
streamStream.forEach(s ->{
s.forEach(System.out::println);
});
System.out.println();
//flatMap(Function f)——接收一个函数作为参数,将流中的每个值都换成另一个流,然后把所有流连接成一个流。
Stream<Character> characterStream = list.stream().flatMap(StreamAPITest2::fromStringToStream);
characterStream.forEach(System.out::println);
}
//将字符串中的多个字符构成的集合转换为对应的Stream的实例
public static Stream<Character>fromStringToStream(String str){
ArrayList<Character> list = new ArrayList<>();
for (Character c :
str.toCharArray()) {
list.add(c);
}
return list.stream();
}
//map()和flatMap()方法类似于List中的add()和addAll()方法
@Test
public void test(){
ArrayList<Object> list1 = new ArrayList<>();
list1.add(1);
list1.add(2);
list1.add(3);
list1.add(4);
ArrayList<Object> list2 = new ArrayList<>();
list2.add(5);
list2.add(6);
list2.add(7);
list2.add(8);
list1.add(list2);
System.out.println(list1);//[1, 2, 3, 4, [5, 6, 7, 8]]
list1.addAll(list2);
System.out.println(list1);//[1, 2, 3, 4, [5, 6, 7, 8], 5, 6, 7, 8]
}
3.2.3 排序
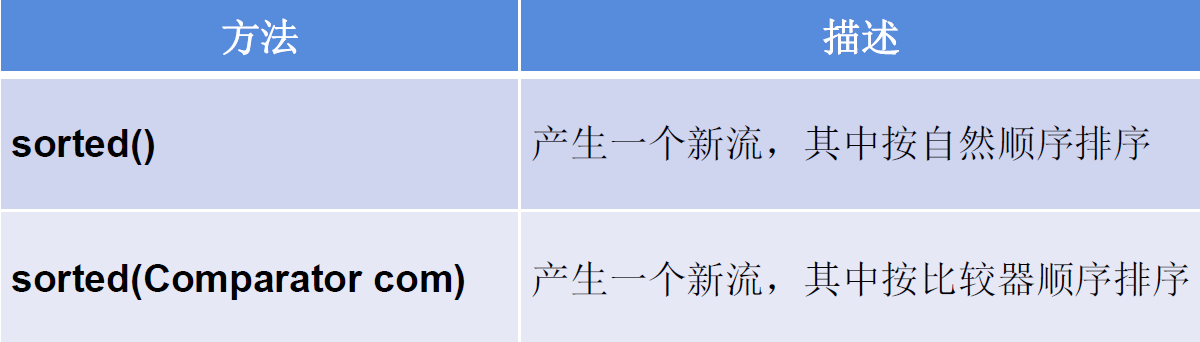
sorted():产生一个新流,其中按自然顺序排序sorted(Comparator com):产生一个新流,其中按比较器顺序排序
代码示例:
//3-排序
@Test
public void test3(){
//sorted()——自然排序
List<Integer> list = Arrays.asList(12, 34, 54, 65, 32);
list.stream().sorted().forEach(System.out::println);
//抛异常,原因:Employee没有实现Comparable接口
List<Employee> employees = EmployeeData.getEmployees();
employees.stream().sorted().forEach(System.out::println);
//sorted(Comparator com)——定制排序
List<Employee> employees1 = EmployeeData.getEmployees();
employees1.stream().sorted((e1,e2)->{
int ageValue = Integer.compare(e1.getAge(), e2.getAge());
if (ageValue != 0){
return ageValue;
}else {
return -Double.compare(e1.getSalary(),e2.getSalary());
}
}).forEach(System.out::println);
}
3.3 步骤三 终止操作
终端操作会从流的流水线生成结果。其结果可以是任何不是流的值,例如:List、 Integer,甚至是void
流进行了终止操作后,不能再次使用。
3.3.1 匹配与查找
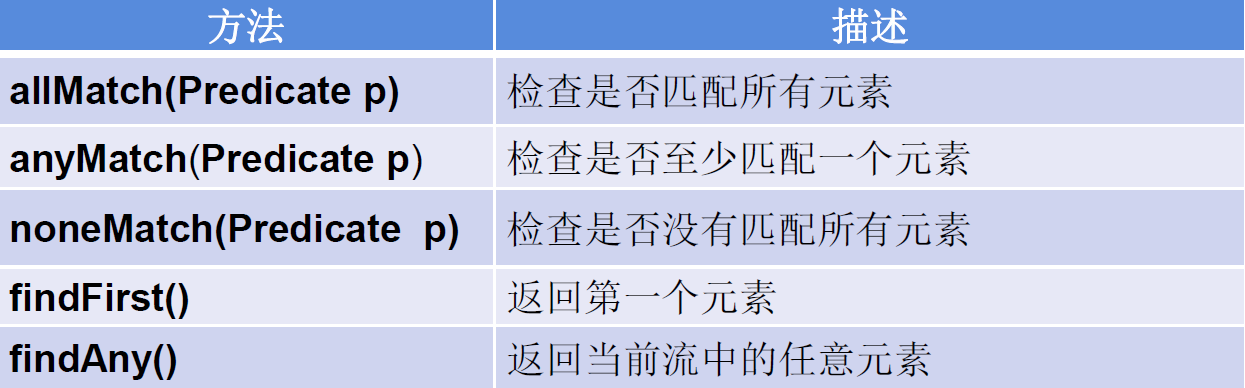

-
allMatch(Predicate p):检查是否匹配所有元素 -
anyMatch(Predicate p):检查是否至少匹配一个元素 -
noneMatch(Predicate p):检查是否没有匹配所有元素 -
findFirst():返回第一个元素 -
findAny():返回当前流中的任意元素 -
count():返回流中元素总数 -
max(Comparator c):返回流中最大值 -
min(Comparator c):返回流中最小值 -
forEach(Consumer c):内部迭代(使用Collection接口需要用户去做迭代,称为外部迭代。相反,Stream API使用内部迭代——它帮你把迭代做了)
代码示例:
//1-匹配与查找
@Test
public void test1(){
List<Employee> employees = EmployeeData.getEmployees();
//allMatch(Predicate p)——检查是否匹配所有元素。
//练习:是否所有的员工的年龄都大于18
boolean allMatch = employees.stream().allMatch(e -> e.getAge() > 18);
System.out.println(allMatch);
//anyMatch(Predicate p)——检查是否至少匹配一个元素。
//练习:是否存在员工的工资大于 5000
boolean anyMatch = employees.stream().anyMatch(e -> e.getSalary() > 5000);
System.out.println(anyMatch);
//noneMatch(Predicate p)——检查是否没有匹配的元素。
//练习:是否存在员工姓“雷”
boolean noneMatch = employees.stream().noneMatch(e -> e.getName().startsWith("雷"));
System.out.println(noneMatch);
//findFirst——返回第一个元素
Optional<Employee> first = employees.stream().findFirst();
System.out.println(first);
//findAny——返回当前流中的任意元素
Optional<Employee> employee = employees.parallelStream().findAny();
System.out.println(employee);
}
@Test
public void test2(){
List<Employee> employees = EmployeeData.getEmployees();
// count——返回流中元素的总个数
long count = employees.stream().filter(e -> e.getSalary()>5000).count();
System.out.println(count);
//max(Comparator c)——返回流中最大值
//练习:返回最高的工资
Stream<Double> salaryStream = employees.stream().map(e -> e.getSalary());
Optional<Double> maxSalary = salaryStream.max(Double::compareTo);
System.out.println(maxSalary);
//min(Comparator c)——返回流中最小值
//练习:返回最低工资的员工
Optional<Double> minSalary = employees.stream().map(e -> e.getSalary()).min(Double::compareTo);
System.out.println(minSalary);
//forEach(Consumer c)——内部迭代
employees.stream().forEach(System.out::println);
System.out.println();
//使用集合的遍历操作
employees.forEach(System.out::println);
}
3.3.2 归约

reduce(T iden, BinaryOperator b):可以将流中元素反复结合起来,得到一个值。返回Treduce(BinaryOperator b):可以将流中元素反复结合起来,得到一个值。返回Optional<T>
备注:map和reduce的连接通常称为 map-reduce模式,因Google用它来进行网络搜索而出名
代码示例:
//2-归约
@Test
public void test3(){
//reduce(T identity, BinaryOperator)——可以将起始值identity与流中元素反复结合起来,得到一个值。返回 T
//练习1:计算1-10的自然数的和
List<Integer> list = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10);
Integer sum = list.stream().reduce(0, Integer::sum);
System.out.println(sum);
//reduce(BinaryOperator) ——可以将流中元素反复结合起来,得到一个值。返回 Optional<T>
//因为没有起始值,所以有可能为空,所以使用Optional
//练习2:计算公司所有员工工资的总和
List<Employee> employees = EmployeeData.getEmployees();
Optional<Double> sumSalary = employees.stream().map(e -> e.getSalary()).reduce(Double::sum);
System.out.println(sumSalary);
}
3.3.3 收集

collect(Collector c):将流转换为其他形式。接受一个Collector接口的实现,用于给Stream中元素做汇总的方法。
Collector接口中方法的实现决定了如何对流执行收集的操作(如收集到List、Set、Map)
Collectors实用类提供了很多静态方法,可以方便地创建常见收集器实例具体方法与实例如下表:


| 方法 | 返回类型 | 作用 | 示例 |
|---|---|---|---|
toList |
List<T> |
把流中元素收集到List | List<Employee> emps = list.stream().collect(Collectors.toList()) |
toSet |
Set<T> |
把流中元素收集到Set | Set<Employee> emps = list.stream().collect(Collectors.toSet()) |
toMap |
Map<T, V> |
把流中元素收集到Map,如果有重复键可以使用mergeFunc((oldValue, newValue) -> newValue)进行替换 |
Map<Employee> emps = list.stream().collect(Collectors.toMap(key, value, mergeFunc)) |
toCollection |
Collection<T> |
把流中元素收集到创建的集合 | List<Employee> emps = list.stream().collect(Collectors.toCollection(ArrayList::new)) |
counting |
Long |
计算流中元素的个数 | long count = list.stream().collect(Collectors.counting()) |
summingInt |
Integer |
对流中元素的整数属性求和 | int total = list.stream().collect(Collectors.summingInt(Employee::getSalary)) |
averagingInt |
Double |
计算流中元素Integer属性的平均值 | double avg = list.stream().collect(averagingInt(Employee::Salary)) |
summarizingInt |
IntSummaryStatistics |
搜集流中的Integer属性的统计值。如:平均值 | int summaryStatisticsiss = list.stream().collect(Collectors.summarizingInt(Employee::getSalary)) |
joining |
String |
连接流中的每个字符串 | String str = list.stream().map(Employee::getName).collect(Collectors.joining()) |
maxBy |
Optional<T> |
根据比较器选择最大值 | Optional<Emp> max = list.stream().collect(Collectors.maxBy(comparingInt(Employee::getSalary))) |
minBy |
Optional<T> |
根据比较器选择最小值 | Optional<Emp> min = list.stream().collect(Collectors.minBy(comparingInt(Employee::getSalary))) |
reducing |
归约产生的类型 | 从一个作为累加器的初始值开始,利用BinaryOperator与流中元素逐个结合,从而归约成单个值 | int total = list.stream().collect(Collectors.reducing(0, Employee::getSalary, Integer::sum)) |
collectingAndThen |
转换函数返回的类型 | 包裹另一个收集器,对其结果转换函数 | int how = list.stream().collect(Collectors.collectingAndThen(Collectors.toList(), List::size)) |
groupingBy |
Map<K, List<T>> |
根据某属性值对流进行分组,属性为K,结果为V | Map<Emp.Status, List<Emp>> map = list.stream().collect(Collectors.groupingBy(Employee::getStatus)) |
partitioningBy |
Map<Boolean, List<T>> |
根据true或false进行分区 | Map<Boolean, List<Emp>> map = list.stream().collect(Collectors.partitioningBy(Employee::getManage)) |
代码示例:
//3-收集
@Test
public void test4(){
//collect(Collector c)——将流转换为其他形式。接收一个 Collector接口的实现,用于给Stream中元素做汇总的方法
//练习1:查找工资大于6000的员工,结果返回为一个List或Set
List<Employee> employees = EmployeeData.getEmployees();
List<Employee> employeeList = employees.stream().filter(e -> e.getSalary() > 6000).collect(Collectors.toList());
employeeList.forEach(System.out::println);
System.out.println();
Set<Employee> employeeSet = employees.stream().filter(e -> e.getSalary() > 6000).collect(Collectors.toSet());
employeeSet.forEach(System.out::println);
}
分组技巧:
employeeList.stream().collect(Collectors.groupingBy(e -> {
if (e.getSalary() < 6000) {
return "LT6000";
}
else if (e.getSalary() == 6000) {
return "EQ6000";
}
else if (e.getSalary() > 6000) {
return "GT6000";
}
return "NOTHING";
}))
踩坑
注意一下:这里的toMap有个坑,toMap方法基于merge方法,如果值为空,会报错空指针
解决方法一:添加过滤,把value为空的元素去掉,加一个 filter
Map<String, String> deptMap = departments.stream().filter(e -> e != null && StringUtil.notEmpty(e.getNo()))
.collect(Collectors.toMap(Department::getUuid, Department::getName, (k1, k2) -> k2));
解决方法二:若value为空,设置默认值""
public class Test {
public static void main(String[] args) {
List<Student> students = new ArrayList<>();
students.add(new Student("张三", 18));
students.add(new Student("李四", 21));
students.add(new Student("王五", null));
// 如果age为null,则直接赋值默认值0
Map<String, Integer> studentMap = students.stream().collect(Collectors.toMap(Student::getName, s -> Optional.ofNullable(s.getAge()).orElse(0)));
System.out.println(studentMap);
}
}
解决方法三:调用hashMap putAll方法, 注意key相同时,value会覆盖。
public class Test {
public static void main(String[] args) {
List<Student> students = new ArrayList<>();
students.add(new Student("张三", 18));
students.add(new Student("李四", 21));
students.add(new Student("王五", null));
Map<String, Integer> studentMap = students.stream().collect(HashMap::new, (map, student) -> map.put(student.getName(), student.getAge()), HashMap::putAll);
System.out.println(studentMap);
}
}
使用技巧
1. int[]数组 → List<Integer>
int[] array = {1, 2, 5, 5, 5, 5, 6, 6, 7, 2, 9, 2};
List<Integer> list1 = Arrays.stream(array).boxed().collect(Collectors.toList());
2. List<Integer> → int[]数组
int[] intArr1 = list.stream().mapToInt(Integer::valueOf).toArray();
组装复杂父子树形结构(List 集合形式) 实例
前言
在最近的开发中,一星期内遇到了两个类似的需求:返回组装好的部门树、返回组装好的地区信息树,最终都需要返回 List 集合对象给前端。
于是在经过需求分析和探索实践后,我对于这种基于 Stream 和 List 结构的父、子树形结构的操作有了新的认识,现在拿出来和大家作分享交流。
一般来说完成这样的需求大多数人会想到递归,但递归的方式弊端过于明显:方法多次自调用效率很低、数据量大容易导致堆栈溢出、随着树深度的增加其时间复杂度会呈指数级增加等。
核心思路如下:
- 一次数据库查询全部数据(几万条),其它全是内存操作、性能高;
- 同时熟练使用 stream 流操作、Lambda 表达式、Java 地址引用,完成组装;
- 使用缓存注解(底层Redis分布式缓存实现),过期后自动更新缓存,再次调用接口则先命中缓存,没有的话再查数据库
- 使用RocketMQ来做异步通知更新,即当数据有更改时,可以异步将数据先更新,再写入缓存,使业务更合理,考虑更全面
一、以部门结构为例
这里的实体是放在 MySQL 里的,使用简单的封装好的查询语句,这个很简单,剩下的就是内存操作了。
1.1实体
租户表:租户就是一个组织或者公司,所以每个租户都有自己的部门。下面的表结构我只列了一些核心的字段,其它不重要。
@Data
public class PmTenant {
/**
* 主键Id
*/
@TableId(type = IdType.ASSIGN_ID)
private Long id;
/**
* 租户名称
*/
private String tenantName;
/**
* 租户唯一编码,对外暴露
*/
private String tenantCode;
/**
* 租户Id
*/
private String tenantId;
/**
* 租户状态,0可用,1禁用
*/
private Integer status;
}
部门表:公司里都会有许多的部门,一个部门里还有部门。从最顶层公司到你所在的的部门,可能会有多达六、七层。以下同样只展示核心字段:
@Data
public class PmDept {
/**
* 主键id
*/
@TableId(type = IdType.ASSIGN_ID)
private Integer id;
/**
* 父部门Id
*/
private Integer parentDeptId;
/**
* 部门id,全局唯一,所有系统用
*/
private Integer deptId;
/**
* 部门名称
*/
private String deptName;
/**
* 部门所处的排序
*/
private Integer orderNum;
/**
* 部门所处的层级
*/
private Integer depth;
/**
* 部门状态,0可用,1删除
*/
private Integer status;
/**
* 租户id
*/
private String tenantId;
/**
* 租户编码
*/
private String tenantCode;
}
1.2返回VO
这个返回的VO是给前端的,里面的子节点集合属性 childrenNodeList ,是一个关键字段,所有该方式返回树结构的 VO 都需要有该字段来”封装自己“。
@Data
public class DeptTreeNodeVO implements Serializable {
/**
* 子节点 list 集合,封装自己
*/
private List<DeptTreeNodeVO> childrenNodeList;
/**
* 部门Id
*/
protected Integer deptId;
/**
* 父部门Id
*/
protected Integer parentDeptId;
/**
* 部门名称
*/
protected String deptName;
}
1.3具体实现
下面直接上代码,注释已经说的比较清楚了:
@Resource
private PmTenantService pmTenantService;
@Resource
private PmDeptMapper pmDeptMapper;
@Override
@Cache(expiryTime = 300)
public List<DeptTreeNodeVO> assembleTree(){
//租户信息列表,这里是两个租户
List<PmTenant> tenantList = this.pmTenantService.list();
//step1:最外层根据租户去组装,有两个租户那么 Stream 就会遍历组装两次;换句话说,如果只有一个租户,就不需要最外层的 Stream
List<DeptTreeNodeVO> resultList = tenantList.stream().map(tenant -> {
//注:这里 map 只是简单转换了返回的对象属性(返回需要的类型),本质还是该租户下的所有部门数据
List<DeptTreeNodeVO> deptTreeNodeVOList = this.selectAllDeptByTenantCode(tenant.getTenantCode())
.stream().map(val -> val.convertExt(DeptTreeNodeVO.class)).collect(Collectors.toList());
//step2:利用父节点分组,即按照该租户下的所有部门的父Id进行分组,把所有的子节点List集合都找出来并一层层分好组
Map<Integer, List<DeptTreeNodeVO>> listMap = deptTreeNodeVOList.parallelStream()
.collect(Collectors.groupingBy(DeptTreeNodeVO::getParentDeptId));
//step3:关键一步,关联上子部门,将子部门的List集合经过遍历一层层地放置好,最终会得到完整的部门父子关系List集合
deptTreeNodeVOList.forEach(val -> val.setChildrenNodeList(listMap.get(val.getDeptId())));
//step4:过滤出顶级部门,即所有的子部门数据都归属于一个顶级父Id
List<DeptTreeNodeVO> allChildrenList = deptTreeNodeVOList.stream()
.filter(val -> val.getParentDeptId().equals(NumberUtils.INTEGER_ZERO)).collect(Collectors.toList());
//组装最外层关于租户需要的数据,实质已经不是处理部门数据了
DeptTreeNodeVO node = new DeptTreeNodeVO();
node.setChildrenNodeList(allChildrenList);
node.setDeptName(tenant.getTenantName());
return node;
}).collect(Collectors.toList());
return Optional.of(resultList).orElse(null);
}
/**
* 获取某个租户下的所有部门信息
*
* @return
*/
public List<PmDept> selectAllDeptByTenantCode(String tenantCode) {
return pmDeptMapper.selectList(new LambdaQueryWrapper<PmDept>()
.eq(PmDept::getTenantCode, tenantCode)
.eq(PmDept::getStatus, PmDeptStatus.DISABLE.getStatus()));
}
1.4效果展示
我这里测试的例子是只有三层,数据也没有完全展开,当然五六层也是没问题的。
只要总的部门数据量在一两万条以内(啥情况部门数量会有几万个?部门表一般是独立于其它表的)速度都是比较快的,服务器性能(主要内存给力)好的话,基本整个请求/响应(抛开网络I/O消耗)可以在一秒内完成。
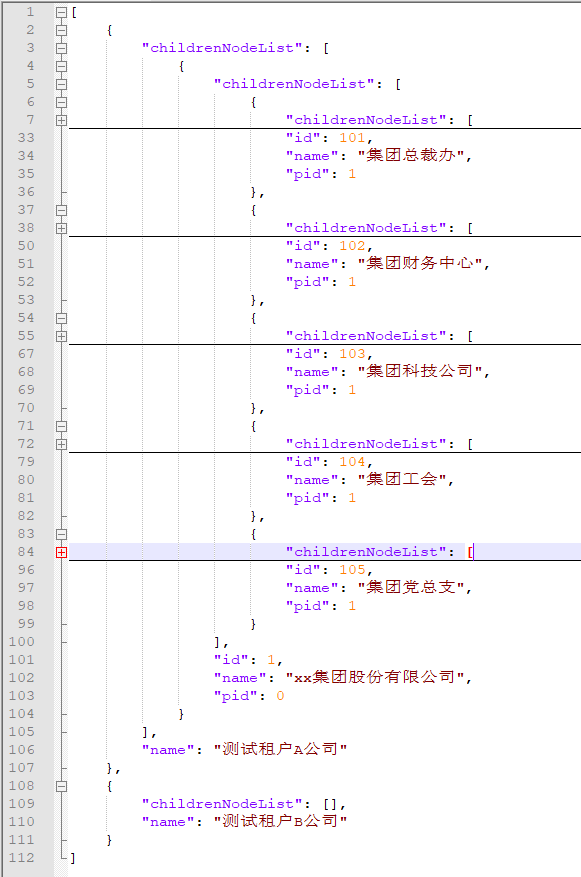
部门树结构效果图---
二、以省市县结构为例
这里的实体是放在 MongoDB 里的,不熟悉 MongoDB 也不要紧,这里只需要使用一次查全量的语句。
2.1实体
全国行政区表:全国的行政区包括省/直辖市/自治区、地级市、区/县级市/县这三级,再往下的街道/镇、以及下面的村/小组就不包含了。同样也是只留关键属性:
@Data
public class Region {
/**
* 区域id
*/
@Id
public Long id;
/**
* 父Id
*/
public Long parentId;
/**
* 地区名称
*/
public String name;
/**
* 地区全称
*/
public String district;
/**
* 所属省
*/
public String province;
/**
* 所属地级市
*/
public String city;
/**
* 所属省Id
*/
public Long provinceId;
/**
* 所属地级市Id
*/
public Long cityId;
/**
* 所处层级
*/
public Integer depth;
}
2.2返回VO
同样,这个里面的子节点集合属性 childrenRegionList,是一个关键字段,所有该方式返回树结构的 VO 都需要有该字段来”封装自己“。
@Data
public class RegionCascadeVO extends RegionVO {
/**
* 子节点 list 集合
*/
private List<RegionCascadeVO> childrenRegionList;
/**
* 区域id
*/
public Long id;
/**
* 地区名称
*/
public String name;
/**
* 所处层级
*/
public Integer depth;
/**
* 省
*/
public String province;
/**
* 城市
*/
public String city;
/**
* 地区全称
*/
public String district;
/**
* 父Id
*/
public Long parentId;
/**
* 所属省Id
*/
public Long provinceId;
/**
* 所属地级市Id
*/
public Long cityId;
}
2.3具体实现
下面同样直接上代码,注释比较详细:
@Resource
private RegionRepository regionRepository;
@Override
@Cache(expiryTime = 300)
public List<RegionCascadeVO> quickAllTree() {
//第一步,从数据库中查出所有数据,按照排序条件进行排序,本质上还是这个所有数据的 List 集合
List<RegionCascadeVO> regionCascadeVOList = this.regionRepository.findAll().stream()
//注:这里使用 map 映射了需要返回的VO,即相同的属性字段就会转换
.map(val -> val.convertExt(RegionCascadeVO.class))
//业务需要的排序规则,使用工具来处理
.sorted((s1, s2) -> RegionSortUtil.citySort(s1.getName(), s2.getName()))
.sorted((s1, s2) -> RegionSortUtil.countySort(s1.getName(), s2.getName()))
.collect(Collectors.toList());
//第二步,根据父Id 字段进行分组,即所有数据都会按照第一层至最后一层都按照父子关系进行分组;注意,是对所有数据分组
Map<Long, List<RegionCascadeVO>> listMap = regionCascadeVOList.parallelStream().collect(Collectors.groupingBy(RegionCascadeVO::getParentId));
//第三步,也是最关键的一步,将父Id下面的所有子数据List集合,经过遍历后都一层层地放置好,最终会得到一个包含父子关系的完整List
regionCascadeVOList.forEach(val -> val.setChildrenRegionList(listMap.get(val.getId())));
//第四步,过滤出符合顶层父Id的所有数据,即所有数据都归属于一个顶层父Id
return regionCascadeVOList.stream().filter(val -> RegionConstant.CHINA_ID.equals(val.getParentId())).collect(Collectors.toList());
}
2.4效果展示
我这里测试环境的例子是只有省/直辖市/自治区、地级市、区/县级市/县这三级,数据也没有完全展开,当然到下面的镇/街道,乃至村/小组也是没问题的。
这里总的测试数据量是几千条,如果加上镇/街道应该得有几万条,速度也还是是比较快的,服务器性能(主要内存给力)好的话,基本整个请求/响应(抛开网络I/O消耗)可以在一秒内完成。
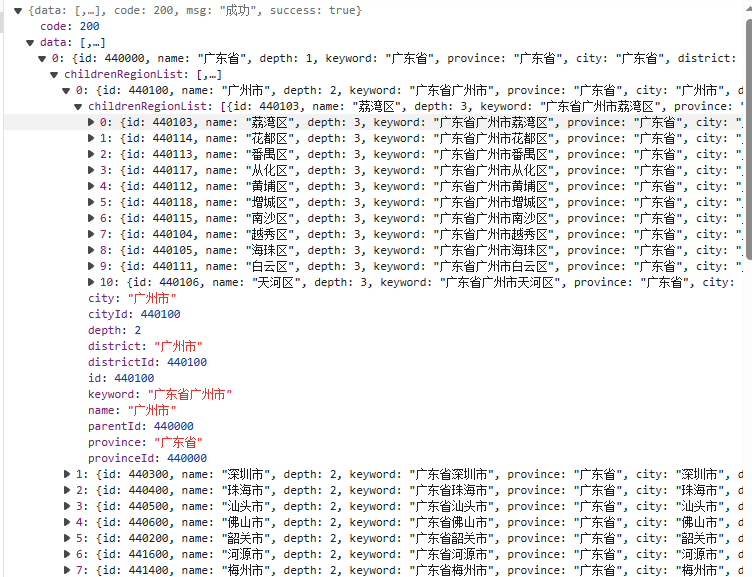
中国行政区域信息层次结构效果时间消耗,这里响应只有两百多毫秒,如下图的接口的性能展示:

接口性能展示原因只有一个:数据库只查一次,把查到的全部数据放内存里,剩下的就是 Stream 的内存操作,都是地址的引用,性能是比较高的。
三、文章小结
使用 Stream 流组装复杂父子树形结构(List 集合形式)的分享到这里就结束了,编码没有捷径,都是项目实践里出真知,一点点摸索攒经验。
六、Optional类的使用
1. Optional类的概述
为了解决java中的空指针问题而生!
Optional<T> 类(java.util.Optional) 是一个容器类,它可以保存类型T的值,代表这个值存在;或者仅仅保存null,表示这个值不存在。
原来用 null 表示一个值不存在,现在 Optional 可以更好的表达这个概念。并且可以避免空指针异常。
2. Optional类提供的方法
Optional类提供了很多方法,可以不用再显式的进行空值检验。
of:把指定的值封装为Optional对象,如果指定的值为null,则抛出NullPointerExceptionempty:创建一个空的Optional对象ofNullable:把指定的值封装为Optional对象,如果指定的值为null,则创建一个空的Optional对象get:如果创建的Optional中有值存在,则返回此值,否则抛出NoSuchElementExceptionorElse:如果创建的Optional中有值存在,则返回此值,否则返回一个默认值orElseGet:如果创建的Optional中有值存在,则返回此值,否则返回一个由Supplier接口生成的值orElseThrow:如果创建的Optional中有值存在,则返回此值,否则抛出一个由指定的Supplier接口生成的异常filter:如果创建的Optional中的值满足filter中的条件,则返回包含该值的Optional对象,否则返回一个空的Optional对象map:如果创建的Optional中的值存在,对该值执行提供的Function函数调用(Function类型为T),返回一个Optional类型的值,否则就返回一个空的Optional对象flagMap:如果创建的Optional中的值存在,就对该值执行提供的Function函数调用(Function类型为Optional<T>),返回一个Optional类型的值,否则就返回一个空的Optional对象isPresent:如果创建的Optional中的值存在,返回true,否则返回falseifPresent:如果创建的Optional中的值存在,则执行该方法的调用,否则什么也不做
2.1 创建Optional类对象的方法
Optional.of(T t):创建一个 Optional 实例,t必须非空;
Optional.empty():创建一个空的 Optional 实例
Optional.ofNullable(T t):t可以为null
2.2 判断Optional容器是否包含对象
boolean isPresent():判断是否包含对象
void ifPresent(Consumer<? super T> consumer):如果有值,就执行Consumer接口的实现代码,并且该值会作为参数传给它。
2.3 获取Optional容器的对象
T get():如果调用对象包含值,返回该值,否则抛异常
T orElse(T other):如果有值则将其返回,否则返回指定的other对象
else:其他的
T orElseGet(Supplier<? extends T> other):如果有值则将其返回,否则返回由Supplier接口实现提供的对象。
T orElseThrow(Supplier<? extends X> exceptionSupplier):如果有值则将其返回,否则抛出由Supplier接口实现提供的异常。
2.4 搭配使用
of() 和 get() 方法搭配使用,明确对象非空
ofNullable() 和 orElse() 搭配使用,不确定对象非空
3. 应用举例
public class OptionalTest {
@Test
public void test1() {
//empty():创建的Optional对象内部的value = null
Optional<Object> op1 = Optional.empty();
if (!op1.isPresent()){//Optional封装的数据是否包含数据
System.out.println("数据为空");
}
System.out.println(op1);
System.out.println(op1.isPresent());
//如果Optional封装的数据value为空,则get()报错。否则,value不为空时,返回value.
System.out.println(op1.get());
}
@Test
public void test2(){
String str = "hello";
// str = null;
//of(T t):封装数据t生成Optional对象。要求t非空,否则报错。
Optional<String> op1 = Optional.of(str);
//get()通常与of()方法搭配使用。用于获取内部的封装的数据value
String str1 = op1.get();
System.out.println(str1);
}
@Test
public void test3(){
String str ="Beijing";
str = null;
//ofNullable(T t) :封装数据t赋给Optional内部的value。不要求t非空
Optional<String> op1 = Optional.ofNullable(str);
System.out.println(op1);
//orElse(T t1):如果Optional内部的value非空,则返回此value值。如果
//value为空,则返回t1.
String str2 = op1.orElse("shanghai");
System.out.println(str2);
}
}
使用Optional类避免产生空指针异常
public class GirlBoyOptionalTest {
//使用原始方法进行非空检验
public String getGrilName1(Boy boy){
if (boy != null){
Girl girl = boy.getGirl();
if (girl != null){
return girl.getName();
}
}
return null;
}
//使用Optional类的getGirlName()进行非空检验
public String getGirlName2(Boy boy){
Optional<Boy> boyOptional = Optional.ofNullable(boy);
//此时的boy1一定非空,boy为空是返回“迪丽热巴”
Boy boy1 = boyOptional.orElse(new Boy(new Girl("迪丽热巴")));
Girl girl = boy1.getGirl();
//girl1一定非空,girl为空时返回“古力娜扎”
Optional<Girl> girlOptional = Optional.ofNullable(girl);
Girl girl1 = girlOptional.orElse(new Girl("古力娜扎"));
return girl1.getName();
}
//测试手动写的控制检测
@Test
public void test1(){
Boy boy = null;
System.out.println(getGrilName1(boy));
boy = new Boy();
System.out.println(getGrilName1(boy));
boy = new Boy(new Girl("杨幂"));
System.out.println(getGrilName1(boy));
}
//测试用Optional类写的控制检测
@Test
public void test2(){
Boy boy = null;
System.out.println(getGirlName2(boy));
boy = new Boy();
System.out.println(getGirlName2(boy));
boy = new Boy(new Girl("杨幂"));
System.out.println(getGirlName2(boy));
}
}
应用场景:
1.默认值
传统方式
public static String getName(User u) {
if (u == null)
return "Unknown";
return u.name;
}
杜绝使用这种方式(不简洁)
public static String getName(User u) {
Optional<User> user = Optional.ofNullable(u);
if (!user.isPresent())
return "Unknown";
return user.get().name;
}
正确方式(链式调用):
public static String getName(User u) {
return Optional.ofNullable(u)
.map(user->user.name)
.orElse("Unknown");
//.orElseGet(() -> "john");
}
2.多重非空条件判断
传统方式
public static String getChampionName(Competition comp) throws IllegalArgumentException {
if (comp != null) {
CompResult result = comp.getResult();
if (result != null) {
User champion = result.getChampion();
if (champion != null) {
return champion.getName();
}
}
}
throw new IllegalArgumentException("The value of param comp isn't available.");
}
链式调用(map 遍历属性)
public static String getChampionName(Competition comp) throws IllegalArgumentException {
return Optional.ofNullable(comp)
.map(c->c.getResult())
.map(r->r.getChampion())
.map(u->u.getName())
.orElseThrow(()->new IllegalArgumentException("The value of param comp isn't available."));
}
3.不为空才操作(单边判断)
string.ifPresent(System.out::println);
4.指定条件过滤
public boolean priceIsInRange2(Modem modem2) {
return Optional.ofNullable(modem2)
.map(Modem::getPrice)
.filter(p -> p >= 10)
.isPresent();
}
5.filter 与 findFirst 结合
Optional<String> found = Stream.of(getEmpty(), getHello(), getBye())
.filter(Optional::isPresent)
.map(Optional::get)
.findFirst();
七、对反射的支持增强
提高了创建对象、对象赋值和反射创建对象的时间
代码示例:
public class testReflection {
// 循环次数10亿次
private static final int loopCnt = 1000 * 1000 * 1000;
public static void main(String[] args) throws InvocationTargetException, NoSuchMethodException, InstantiationException, IllegalAccessException {
// 输出jdk版本
System.out.println("java version is" + System.getProperty("java.version"));
createNewObject();
optionObject();
reflectCreateObject();
}
// person对象
static class Person {
private Integer age = 20;
public Integer getAge() {
return age;
}
public void setAge(Integer age) {
this.age = age;
}
}
// 每次创建新对象
public static void createNewObject() {
long startTime = System.currentTimeMillis();
for (int i = 0; i < loopCnt; i++) {
Person person = new Person();
person.setAge(30);
}
long endTime = System.currentTimeMillis();
System.out.println("循环十亿次创建对象所需的时间:" + (endTime - startTime));
}
// 为同一个对象赋值
public static void optionObject() {
long startTime = System.currentTimeMillis();
Person p = new Person();
for (int i = 0; i < loopCnt; i++) {
p.setAge(10);
}
long endTime = System.currentTimeMillis();
System.out.println("循环十亿次为同一对象赋值所需的时间:" + (endTime - startTime));
}
// 通过反射创建对象
public static void reflectCreateObject() throws IllegalAccessException, InstantiationException, NoSuchMethodException, InvocationTargetException {
long startTime = System.currentTimeMillis();
Class<Person> personClass = Person.class;
Person person = personClass.newInstance();
Method setAge = personClass.getMethod("setAge", Integer.class);
for (int i = 0; i < loopCnt; i++) {
setAge.invoke(person, 90);
}
long endTime = System.currentTimeMillis();
System.out.println("循环十亿次反射创建对象所需的时间:" + (endTime - startTime));
}
}
编译级别为JDK8时
java version is 1.8.0_201
循环十亿次创建对象所需的时间:9
循环十亿次为同一对象赋值所需的时间:59
循环十亿次反射创建对象所需的时间:2622
编译级别为JDK7时
java version is 1.7
循环十亿次创建对象所需的时间:6737
循环十亿次为同一对象赋值所需的时间:3394
循环十亿次反射创建对象所需的时间:293603
笔者将不定期更新【考研或就业】的专业相关知识以及自身理解,希望大家能【关注】我。
如果觉得对您有用,请点击左下角的【点赞】按钮,给我一些鼓励,谢谢!
如果有更好的理解或建议,请在【评论】中写出,我会及时修改,谢谢啦!
本文来自博客园,作者:Nemo&
转载请注明原文链接:https://www.cnblogs.com/blknemo/p/13847627.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号