【设计模式】解释器模式
解释器模式(Interpreter Pattern)提供了评估语言的语法或表达式的方式,它属于行为型模式。这种模式实现了一个表达式接口,该接口解释一个特定的上下文。这种模式被用在 SQL 解析、符号处理引擎等。
基本介绍
-
意图:给定一个语言,定义它的文法表示,并定义一个解释器,这个解释器使用该标识来解释语言中的句子。
-
主要解决:对于一些固定文法构建一个解释句子的解释器。
-
何时使用:如果一种特定类型的问题发生的频率足够高,那么可能就值得将该问题的各个实例表述为一个简单语言中的句子。这样就可以构建一个解释器,该解释器通过解释这些句子来解决该问题。
-
如何解决:构建语法树,定义终结符与非终结符。
-
关键代码:构建环境类,包含解释器之外的一些全局信息,一般是 HashMap。
-
应用实例:编译器、运算表达式计算。
-
优点:
- 1、可扩展性比较好,灵活。
- 2、增加了新的解释表达式的方式。
- 3、易于实现简单文法。
-
缺点:
- 1、可利用场景比较少。
- 2、对于复杂的文法比较难维护。
- 3、解释器模式会引起类膨胀。
- 4、解释器模式采用递归调用方法。
-
使用场景:
- 1、可以将一个需要解释执行的语言中的句子表示为一个抽象语法树。
- 2、一些重复出现的问题可以用一种简单的语言来进行表达。
- 3、一个简单语法需要解释的场景。
注意事项:可利用场景比较少,JAVA 中如果碰到可以用 expression4J 代替。
概括
基本介绍
- 在编译原理中,一个算术表达式通过词法分析器形成词法单元,而后这些词法单元再通过语法分析器构建语法分析树,最终形成一颗抽象的语法分析树。这里的词法分析器和语法分析器都可以看做是解释器
- 解释器模式(Interpreter Pattern):是指给定一个语言(表达式),定义它的文法的一种表示,并定义一个解释器, 使用该解释器来解释语言中的句子(表达式)
- 应用场景
- 应用可以将一个需要解释执行的语言中的句子表示为一个抽象语法树
- 一些重复出现的问题可以用一种简单的语言来表达
- 一个简单语法需要解释的场景
- 这样的例子还有,比如编译器、运算表达式计算、正则表达式、机器人等
解释器模式的原理类图
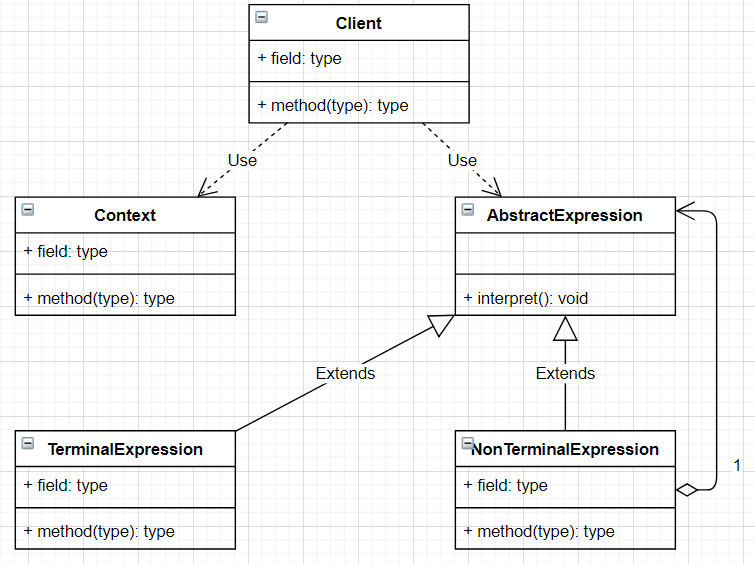
对原理类图的说明-即(解释器模式的角色及职责)
- ontext:是环境角色,含有解释器之外的全局信息.
- bstractExpression:抽象表达式,声明一个抽象的解释操作,这个方法为抽象语法树中所有的节点所共享
- erminalExpression:为终结符表达式, 实现与文法中的终结符相关的解释操作
- onTermialExpression:为非终结符表达式,为文法中的非终结符实现解释操作.
说明:输入 Context he TerminalExpression 信息通过 Client 输入即可
我的理解
对于一些固定文法构建一个解释句子的解释器。
比如说 我们高中时候上数学课,“符号看象限,奇变偶不变。”这句话,其实对于一般人来说,听不懂,这什么意思啊。我们听得懂是因为老师在我们的脑子里安装了一个固定解释句子文法的解释器。所以老师只用说这十个字,我们就能明白到底需要做什么。这就是解释器的作用。
俺有一个《泡 MM 真经》,上面有各种泡 MM 的攻略,比如说去吃西餐的步骤、去看电影的方法等等,跟 MM 约会时,只要做一个 Interpreter,照着上面的脚本执行就可以了。
解释器模式:给定一个语言后,解释器模式可以定义出其文法的一种表示,并同时提供一个解释器。客户端可以使用这个解释器来解释这个语言中的句子。解释器模式将描述怎样在有了一个简单的文法后,使用模式设计解释这些语句。在解释器模式里面提到的语言是指任何解释器对象能够解释的任何组合。在解释器模式中需要定义一个代表文法的命令类的等级结构,也就是一系列的组合规则。每一个命令对象都有一个解释方法,代表对命令对象的解释。命令对象的等级结构中的对象的任何排列组合都是一个语言。
应用实例
四则运算问题
通过解释器模式来实现四则运算,如计算 a+b-c 的值,具体要求
- 先输入表达式的形式,比如 a+b+c-d+e, 要求表达式的字母不能重复
- 在分别输入 a ,b, c, d, e 的值
- 最后求出结果:如图

使用传统方式
- 编写一个方法,接收表达式的形式,然后根据用户输入的数值进行解析,得到结果
- 问题分析:如果加入新的运算符,比如 * / ( 等等,不利于扩展,另外让一个方法来解析会造成程序结构混乱, 不够清晰.
- 解决方案:可以考虑使用解释器模式, 即: 表达式 -> 解释器(可以有多种) -> 结果
使用解释器模式
- 应用实例要求
通过解释器模式来实现四则运算, 如计算 a+b-c 的值 - 思路分析和图解(类图)
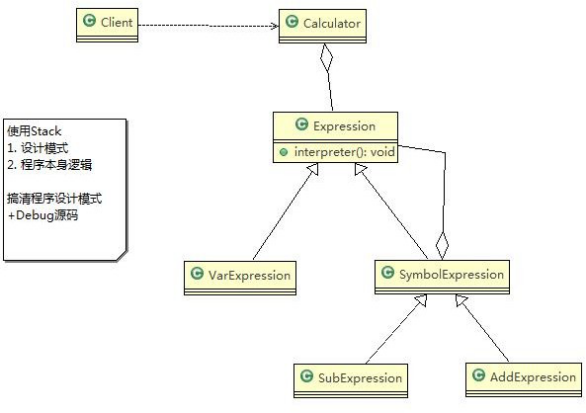
代码实现
Expression
package com.nemo.interpreter;
import java.util.HashMap;
/**
*抽象类表达式,通过 HashMap 键值对, 可以获取到变量的值
*
*@author Administrator
*
*/
public abstract class Expression {
// a + b - c
// 解释公式和数值, key 就是公式(表达式) 参数[a,b,c], value 就是就是具体值
// HashMap {a=10, b=20}
public abstract int interpreter(HashMap<String, Integer> var);
}
VarExpression
package com.nemo.interpreter;
import java.util.HashMap;
/**
*变量的解释器
*@author Administrator
*
*/
public class VarExpression extends Expression {
private String key; // key=a,key=b,key=c
public VarExpression(String key) {
this.key = key;
}
// var 就是{a=10, b=20}
// interpreter 根据 变量名称,返回对应值
@Override
public int interpreter(HashMap<String, Integer> var) {
return var.get(this.key);
}
}
SymbolExpression
package com.nemo.interpreter;
import java.util.HashMap;
/**
*抽象运算符号解析器 这里,每个运算符号,都只和自己左右两个数字有关系,
*但左右两个数字有可能也是一个解析的结果,无论何种类型,都是 Expression 类的实现类
*
*@author Administrator
*
*/
public class SymbolExpression extends Expression {
protected Expression left;
protected Expression right;
public SymbolExpression(Expression left, Expression right) {
this.left = left;
this.right = right;
}
//因为 SymbolExpression 是让其子类来实现,因此 interpreter 是一个默认实现
@Override
public int interpreter(HashMap<String, Integer> var) {
return 0;
}
}
AddExpression
package com.nemo.interpreter;
import java.util.HashMap;
/**
*加法解释器
*@author Administrator
*
*/
public class AddExpression extends SymbolExpression {
public AddExpression(Expression left, Expression right) {
super(left, right);
}
//处理相加
//var 仍然是 {a=10,b=20}..
//一会我们 debug 源码,就 ok
public int interpreter(HashMap<String, Integer> var) {
//super.left.interpreter(var) : 返回 left 表达式对应的值 a = 10
//super.right.interpreter(var): 返回 right 表达式对应值 b = 20
return super.left.interpreter(var) + super.right.interpreter(var);
}
}
SubExpression
package com.nemo.interpreter;
import java.util.HashMap;
public class SubExpression extends SymbolExpression {
public SubExpression(Expression left, Expression right) {
super(left, right);
}
//求出 left 和 right 表达式相减后的结果
public int interpreter(HashMap<String, Integer> var) {
return super.left.interpreter(var) - super.right.interpreter(var);
}
}
Calculator
package com.nemo.interpreter;
import java.util.HashMap;
import java.util.Stack;
public class Calculator {
// 定义表达式
private Expression expression;
// 构造函数传参,并解析
public Calculator(String expStr) { // expStr = a+b
// 安排运算先后顺序
Stack<Expression> stack = new Stack<>();
// 表达式拆分成字符数组
char[] charArray = expStr.toCharArray();// [a, +, b]
Expression left = null;
Expression right = null;
//遍历我们的字符数组, 即遍历 [a, +, b]
//针对不同的情况,做处理
for (int i = 0; i < charArray.length; i++) {
switch (charArray[i]) {
case '+': //
left = stack.pop();// 从 stack 取 出 left => "a"
right = new VarExpression(String.valueOf(charArray[++i]));// 取出右表达式 "b"
stack.push(new AddExpression(left, right));// 然后根据得到 left 和 right 构建 AddExpresson 加入 stack
break;
case '-': //
left = stack.pop();
right = new VarExpression(String.valueOf(charArray[++i]));
stack.push(new SubExpression(left, right));
break;
default:
//如果是一个 Var 就创建要给 VarExpression 对象,并 push 到 stack
stack.push(new VarExpression(String.valueOf(charArray[i])));
break;
}
}
//当遍历完整个 charArray 数组后,stack 就得到最后 Expression
this.expression = stack.pop();
}
public int run(HashMap<String, Integer> var) {
//最后将表达式 a+b 和 var = {a=10,b=20}
//然后传递给 expression 的 interpreter 进行解释执行
return this.expression.interpreter(var);
}
}
ClientTest
package com.nemo.interpreter;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.HashMap;
public class ClientTest {
public static void main(String[] args) throws IOException {
String expStr = getExpStr(); // a+b
HashMap<String, Integer> var = getValue(expStr);// var {a=10, b=20}
Calculator calculator = new Calculator(expStr);
System.out.println("运算结果:" + expStr + "=" + calculator.run(var));
}
// 获得表达式
public static String getExpStr() throws IOException {
System.out.print("请输入表达式:");
return (new BufferedReader(new InputStreamReader(System.in))).readLine();
}
// 获得值映射
public static HashMap<String, Integer> getValue(String expStr) throws IOException {
HashMap<String, Integer> map = new HashMap<>();
for (char ch : expStr.toCharArray()) {
if (ch != '+' && ch != '-') {
if (!map.containsKey(String.valueOf(ch))) {
System.out.print("请输入" + String.valueOf(ch) + "的值:");
String in = (new BufferedReader(new InputStreamReader(System.in))).readLine();
map.put(String.valueOf(ch), Integer.valueOf(in));
}
}
}
return map;
}
}
解释器模式在 Spring 框架应用的源码剖析
- Spring 框架中 SpelExpressionParser 就使用到解释器模式
- 代码分析+Debug 源码
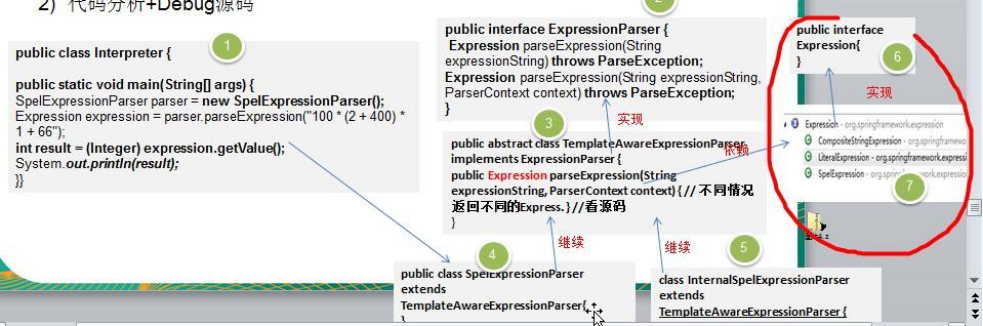
- 说明

解释器模式的注意事项和细节
- 当有一个语言需要解释执行,可将该语言中的句子表示为一个抽象语法树,就可以考虑使用解释器模式,让程序具有良好的扩展性
- 应用场景:编译器、运算表达式计算、正则表达式、机器人等
- 使用解释器可能带来的问题:解释器模式会引起类膨胀、解释器模式采用递归调用方法,将会导致调试非常复杂、效率可能降低.
笔者将不定期更新【考研或就业】的专业相关知识以及自身理解,希望大家能【关注】我。
如果觉得对您有用,请点击左下角的【点赞】按钮,给我一些鼓励,谢谢!
如果有更好的理解或建议,请在【评论】中写出,我会及时修改,谢谢啦!
本文来自博客园,作者:Nemo&
转载请注明原文链接:https://www.cnblogs.com/blknemo/p/13259813.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号