【URL Scheme】URL的结构以及与URI的区别
URI和URL的区别
URI = Universal Resource Identifier
URL = Universal Resource Locator
在学习中,我们难免会遇到 URI 和 URL,有时候都傻傻分不清,为啥这边是 URI 那边又是 URL,这两者到底有什么区别呢?
我们从名字上看
- 统一资源标识符(Uniform Resource Identifier, URI):是一个用于标识某一互联网资源名称的字符串。
- 统一资源定位符(Uniform Resource Locator, URL):是一个用于标识和定位某一互联网资源名称的字符串。
可能大家就比较困惑了,这俩好像是一样的啊?那我们就类比一下我们现实生活中的情况:
我们要找一个人——张三,我们可以通过他的唯一的标识来找,比如说身份证,那么这个身份证就唯一的标识了一个人,这个身份证就是一个 URI;
而要找到张三,我们不一定要用身份证去找,我们还可以根据地址去找,如 在清华大学18号宿舍楼的404房间第一个床铺的张三,我们也可以唯一确定一个张三,
动物住址协议://地球/中国/北京市/清华大学/18号宿舍楼/404号寝/张三.人。而这个地址就是我们用于标识和定位的 URL。
我们从上面可以很明显的看出,URI 通过任何方法标识一个人即可,而 URL 虽然也可以标识一个人,但是它主要是通过定位地址的方法标识一个人,所以 URL 其实是 URI 的一个子集,即 URL 是靠标识定位地址的一个 URI。
Url 的构成(URL Scheme)
URL Scheme 是一种统一资源定位符(URL)的标识符,用于指定该 URL 所使用的协议和访问资源的方式。
用于在浏览器地址栏输入网址、超链接、应用程序间跳转等场景,指导应用程序使用相应的协议去访问资源。
如
weixin://可以跳转到微信app
URL(Uniform Resource Locator, 统一资源定位符),用于定位网络上的资源,每一个信息资源都有统一的且在网上唯一的地址。
Url一般有以下部分组成
scheme:[subscheme]://[username:password@]host:port/path?query#fragment
-
Scheme:URL方案,如 通信协议,一般为http、https等;(协议一般会有一个与它匹配的URL方案) -
Host: 服务器的域名主机名或ip地址; -
Port:端口号,此项为可选项,默认为80; -
Path:目录,由“/”隔开的字符串,表示的是主机上的目录或文件地址; -
Query:查询,此项为可选项,可以给动态网页传递参数;多个参数用“
&”隔开,每个参数的名和值用“=”隔开;- 数组:
中括号http://ip:port/test_transMap?id=1&name=2¶ms[]=value1¶ms[]=value2
逗号http://ip:port/test_transMap?id=1&name=2¶ms[key1]=value1,value2 - 键值对:
http://ip:port/test_transMap?id=1&name=2¶ms[key1]=value1¶ms[key2]=value2
- 数组:
-
Fragment: 信息片段,字符串,用于指定网络资源中的某片断;多个参数用“
&”隔开,锚点不会随着请求发送给服务器,而Query参数会。 -
subscheme:可选,子协议,常用于区分不同数据库驱动协议例子:
jdbc:mysql://localhost:3306/nemo?user=root&password=123456jdbc:oracle:thin:@localhost:1521:nemojdbc:sqlserver://localhost:1433:DatabaseName=nemo
-
username:password:可选,用于登录主机的用户名和密码。
例子:正如命令
ssh user@127.0.0.1
http://user:123@baidu.com/loginftp://user:123@127.0.0.1telnet://user:123@127.0.0.1ssh://user:123@127.0.0.1
其实,把 URL 说成是网址其实是很不严谨的说法,因为 URL 有很严格的结构,表示也很灵活、有弹性。
在 RFC 3986: Uniform Resource Identifier (URI): Generic Syntax 的 Syntax Components 把 URL 描述为如下图:
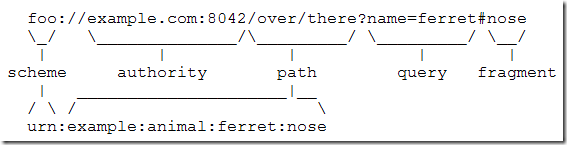
如图所示,把 URL 分成几个部分,这样便可以了解URL的构成。 在 URI scheme - Wikipedia 页面中对 URL 的描述更为详细,如下图:

特别需要注意的是,我们的文件路径其实也是URL的一种,它属于是本地文件传输协议(File Protocol)
File协议主要用于访问本地计算机中的文件,就如同在Windows资源管理器中打开文件一样。
要使用File协议,基本的格式如下:file://文件绝对路径。(文件的绝对路径一般是以斜杠/开头,所以我们一般是file:///)
比如要打开F盘flash文件夹中的1.swf文件,那么可以在资源管理器或IE地址栏中键入:file:///f:/flash/1.swf并回车。
大家可以做个实验,在资源管理器中键入斜杠/开头的文件路径,会在浏览器中打开文件路径,并且在地址栏中是以此协议格式开头file://。
mailto 资源为电子邮件地址,通过 SMTP 访问。 格式 mailto:
fragment
主要资源是由 URI 进行标识,URI 中的 fragment 用来标识次级资源。我理解看来,fragment 主要是用来标识 URI 所标识资源里的某个资源。
在 URI 的末尾通过 hash mark(#)作为 fragment 的开头,其中 # 不属于 fragment 的值。
https://domain/index#L18
这个 URI 中 L18 就是 fragment 的值。这有哪些特殊的地方呢?
#有别于?,?后面的查询字符串会被网络请求带上服务器,而 fragment 不会被发送给服务器;- fragment 的改变不会触发浏览器刷新页面,但是会生成浏览历史;
- fragment 会被浏览器根据文件媒体类型(MIME type)进行对应的处理;
- Google 的搜索引擎会忽略
#及其后面的字符串。
针对以上几点特性,分别介绍下 URI fragment 的应用。
特性 1 & 2 单页面路由
针对 1、2 这两个特性,目前主要的应用就是单页面路由。具体原理简单描述如下:JavaScript 提供了 location.hash 来操作当前 URI 的 fragment,同时提供了 Hashchange 事件监听 fragment 的变化。利用这两个 API 再结合上述特性 1、2 就可以实现一个简单前端路由。具体流程如下图:
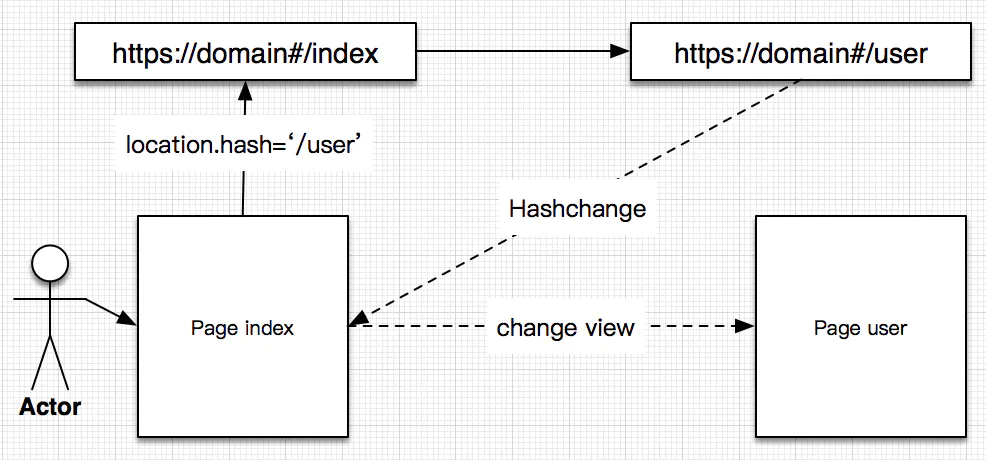
修改 location.hash 值,触发 hashchange 事件,JS 处理对应的逻辑,改变页面 UI 实现页面的跳转,并在浏览器中产生历史记录。
特性 3 HTML 锚点
在 HTML 中比较常见的一个应用 —— 页面内定位。在页面中通过设置标签的 id 属性来定义锚点,从而实现锚点定位。实际上锚点定位的实现正是依赖了 fragment 的特性 3。如这个 URI https://domain/index.html#L18,假设返回的文件类型是 text/html,则浏览器会读取 URI's fragment,然后在页面中寻找 L18 这个锚点,并将页面滚动到该锚点的位置。
因此我们当点击 <a href="#top">top</a>时,实际上处理过程是 URI 的 hash 发生变化,然后浏览器读取新的 fragment,并寻找 DOM 中是否存在对应的锚点,将该锚点显示到页面中。在 MIME Type 为 HTML 或 XML 时,如https://domain/index.html#这个 URI 中是空的 fragment,则浏览器默认显示页面的最顶端。
特性 4
特性4 其实是针对 hash 模式前端路由来说的一个缺点。因为 fragment 会被 Google 搜索引擎忽略掉,因此对于用 hash 模式前端路由的应用的 SEO 来说是很不友好的。不过 Google 给了一个方案,就是在 # 紧跟一个 ! ,这样Google 搜索引擎就会将这个 URI 进行转换,如 https://domain/index.html#!L18转换后就成为了 https://domain/index.html?_escaped_fragment_=L18。这样搜索引擎就会携带上 URI's fragment 直接去访问这个 URI,开发者可以利用这个 trick 优化网站的 SEO。
小结
- fragment 对于 HTML 文档来说就是页面内的定位标识符,可以实现 HTML 页面内的定位。当然浏览器针对不同类型的资源会有区分的处理 fragment;
- 利用 fragment 实现前端页面无刷新修改 Brower's URI;
- 根据搜索引擎规则,可以优化无刷新修改页面的 SEO;
笔者将不定期更新【考研或就业】的专业相关知识以及自身理解,希望大家能【关注】我。
如果觉得对您有用,请点击左下角的【点赞】按钮,给我一些鼓励,谢谢!
如果有更好的理解或建议,请在【评论】中写出,我会及时修改,谢谢啦!
本文来自博客园,作者:Nemo&
转载请注明原文链接:https://www.cnblogs.com/blknemo/p/13198506.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号