【算法】动态规划四步走
动态规划
动态规划:自底向上、由小及大
回溯法:自顶向下、由大及小例如:得到一个数字12345,动态规划会将 原问题12345 分割为 子类问题1234 + 当前问题5,思考新增的那个数字会对最优解造成怎样的影响,找初始值、找递推关系式、找最优解;
而回溯法则会从12345开始思考,一步一步向下遍历,遍历1、遍历2……遍历5。
动态规划(dynamic programming):它是把研究的问题分成若干个阶段,且在每一个阶段都要“动态地”做出决策,从而使整个阶段都要取得最优效果。
理解:其实,无非就是利用历史记录,来避免我们的重复计算。
而这些历史记录,我们得需要一些变量来保存历史记录的状态,一般是用一维数组或者多维数组来保存。
其实我挺好奇为什么用动态规划这个名字的,所以我花时间找了一下,如果大家想要知道这个名字的由来,可以去看看:动态规划
- 总结版解释:从时间阶段的迭代中,找到当前时间阶段的最优解
理解:若当前元素为第i个,那么 前i个状态下的最优解 = 前i-1个状态下的最优解 + 当前抉择
适用场景
虽然动态规划主要用于求解以时间划分阶段的动态过程的优化问题,但是一些与时间无关的静态规划(如线性规划、非线性规划),只要人为地引进时间因素,把它视为多阶段决策过程,也可以用动态规划方法方便地求解。
- 连续多阶段决策且递推。
注意:得是连续的,因为数组是连续的顺序表,你得把数组填满,才能获得答案!
得是递推的,如今的状态是根据以前的状态递推出来的。这里与回溯法不同的是,回溯法以前的状态不一定是最佳状态,回溯法只是将所有可能性都遍历完了;而动态规划以前的状态必须是最佳状态,每一次递推都是从以前的最佳状态开始递推,比较有大局观。
- 第 n 种情况,n 为阶段,为 n 时的结果。
比如说剪绳子问题,它会跟你说给你一根长度为 n 的绳子,那么我们可以考虑一下 n - 1 或者 n - 2 是不是能推出 n。。
- 最优值:最大、最多等值,一定是最优值,而不是最优集合、最优解
题目只问最优值,并没有问最优解,因此绝大多数情况下可以考虑使用「动态规划」的方法。
理解:由于动态规划是一个填表的过程,所以表格中只会有某个数值,也就是说,我们只能去找到最优值,而不是最优解或最优集。
最优值:集合内元素和的最大值(如 99)
最优解:集合内元素和为最大的集合(如 [90, 9])
-
前后数据有关
-
原问题可分解为子类问题
关键词:为 n 时的结果,阶段,递推,最优值
动态规划四步走
动态规划的思路与分治法极为相似,都是由原问题 = 子类问题 + 当前问题这个公式推导而来,我们的阶段问题记录表就是我们的子类问题,而我们的当前问题就是利用子类问题推导出来解决的。
如 1..n = 1..n-1 + n
技巧:使用下面的方式,表示不可达,以免做加减运算的时候会越界
int MIN_VALUE = Integer.MIN_VALUE / 2;int MAX_VALUE = Integer.MAX_VALUE / 2;
1. 明确数组含义(明确分解策略)
1.明确数组的含义:建立数组,明确数组元素的含义。分解策略必须能够使我们对当前节点状态有一定的认知,能够成功划分子类问题进行递推。
原问题 = 子类问题 + 当前问题,我们需要明确一个分解策略来将数组阶段进行记录;(前缀分解 或 范围分解)- 数组需要记录不同阶段(节点)的状态,每一个数组元素及其下标都应该对应着一个阶段(节点)的状态;
这种不同阶段的状态编码一般都具有前缀性质,即 考虑了之前编号的数据,即 当前的状态值考虑了(或者说综合了)之前的相关的状态值
数组dp[]:原问题 = 子类问题 + 当前问题
- 一维或二维:划分子类问题。
- 一维
dp[i]:前缀分解,分解范围\([0, i]\); - 二维
dp[leftIndex][rightIndex]:范围分解,分解范围\([leftIndex, rightIndex]\)
- 一维
- 多维:记录节点状态
- 数组元素值:记录最优值、结果值、可行性(boolean)
这里需要注意,动态规划的状态不是当前第 i 个,而是
前 i 个累计的状态。
理解:动态规划与回溯法异曲同工,类似于回溯递归到第 i 层,此时的结果是累计了前 i 次操作得出来的,一步一步走到第 n 层,即可得到我们最终所需的最优解。
注意:阶段一定要和数组一样是连续的,我们只有填满数组,才能获得答案;
比如说,01背包的背包重量容量状态,我们其实有效的也就那么几个值,容量一个一个增加物品也放不进去,但是我们还是得连续的一个一个向上增加,因为我们这数组是一个连续的表,并不能让我们从中空出几个,并且,空出几个也不利于我们的递推填表,我们需要填满整个表,才能得出我们的答案!
这里要注意的是,我们的动态规划是不同于递归的,递归不需要记录当前阶段的状态就能知道该走哪一步,慢慢走下去,而我们的动态规划是迭代方法,需要不停记录当前阶段的状态(数组保存的状态一般都具有前缀性,即 数组保存的一般是包含了前几个状态在内的最优值),否则可能就找不着东南西北了。
理解:若当前元素为第i个,那么 前i个状态下的最优解 = 前i-1个状态下的最优解 + 当前抉择
为什么数组保存的状态一般都具有前缀性呢?其实也很好理解,因为我们的计算机只能顺着一个一个进行读取,最终会将数据分为已读取的和未读取的两部分,我们只知道已读取的这左边的前缀的状态是什么,未读取的状态我们是不知道的
而我们的数组就是记录状态的好东西!!!
- 一维数组可以记录两个状态,一是下标状态,二是下标对应的数值状态;
- 二维数组可以记录三个状态,一是一维下标状态,二是二维下标状态,三是下标对应的数值状态;
这里你可以想想01背包问题,二维数组的一维下标记录了当前选择的物品编号(前i个物品分配情况的阶段,这种编码一般都具有前缀性质,即 考虑了之前编号的数据),二维下标记录了当前背包总容量(容量递增的阶段),下标对应的数值状态记录了背包总价值。它们三个合起来,我们就能知道不同阶段的不同状态信息,我们就可以递推出所有信息!!!!!
理解:其实,数组就是一般的阶段状态记录,我们要选取合适维度的数组来记录我们所拥有的信息,每一个数组元素及其下标都应该对应着一个阶段的状态。
递归、回溯法的状态是记录当前位置的状态,并非当前位置的最优状态,因为没有办法知道当前位置是否为最优,我们只能知道我们当前路线的当前位置的状态,而不知道其他路线的当前位置的状态,并且没有办法保存当前位置的最优状态,毕竟是递归,数据就不断地刷新了。
可以理解成486,只有回溯能力,不能保证回溯的当前位置状态最优。
而动态规划记录的是当前位置的最优状态,动态规划可以知道其他路线的位置最优状态。
它比较有大局观,每次都统筹规划,从最优的状态选择中不断前进!
也就是说,与递归、回溯法不同,回溯法只能知道当前的状态是怎样的,并不能保证当前的状态是最优的,它的优势在于遍历所有可能性;
而动态规划则是每一步都通过规划,保证当前状态最优,它的优势在于统筹规划,每次都是最优的。
根据数组,制作阶段问题表
1.制作阶段记录表:根据数组建表,之后会填入初始值,最后利用递推关系式写程序推出其他空表项。
注意:这个是为我们通过初始值和递推关系式写出程序提供可视化条件以及思路,把抽象的东西可视化了,时时刻刻都知道自己要干嘛。
当然,如果脑子里有思路可以忽略。。启发:这个想法其实是由编译原理中的 “编译程序绝大多数时间花在管理表格上” 这句话来的。
因为在编译中,编译的每个阶段所需要的信息多数从表格中读取,产生的中间结果都记录在相应的表格中,可以说整个编译过程就是造表、查表的过程。
也就是说,我们的动态规划算法也可以理解成造表、查表的一个过程。
2. 寻找最小问题
2.寻找最小问题(寻找数组初始值):寻找数组元素初始值的出口,这个出口最好写在最前面,我们的结果就是用数组初始值结合下面的递推关系式得出来的;
注意:这个初始值要特别的给出一个出口,因为它们不是被递推出来的。
以免后面设置的初始值越界,比如 数组dp[1]容量为1,结果初始值设置了dp[2]的值,就越界了。技巧:我们也可以通过递推关系式下标索引的越界,来反向推理得到我们应该初始化的范围,如 对于递推关系式包含下标
i - 1和i - 2,我们为了避免越界,我们就应该为下标为 0、1 的元素进行初始化,避免其越界。
例如:
// 初始值出口
if (n <= 2) {
return n;
}
有时候问题过于复杂,导致初始值能找到,但是可能由于状态过多,考虑不周、找不全。
这种情况下,我们可以从下面的递推关系式的条件入手
-
如递推关系式为
dp[i][0][j] = Math.max(dp[i - 1][0][j], dp[i - 1][1][j - 1] + prices[i]);,我们可以看到一维下标包含i - 1,三维下标包含j - 1,所以我们的数组初始值需要将dp[0][x][x]和dp[x][x][0]包含其中给解决掉,不然当i和j为0时,遍历就会超出数组边界。 -
如子类问题为
dp[leftIndex + 1][rightIndex - 1],我们可以看到此子类问题的规则:rightIndex - 1 >= 0,rightIndex >= 1,所以需要将下标为0的数组填表,需要将窗口长度为1的数组初始化填表leftIndex + 1 <= rightIndex - 1,rightIndex - leftIndex >= 2,所以需要将rightIndex - leftIndex值为0和1的,窗口长度为1和2的数组初始化填表
3. 划分子类问题(找出递推关系式)
3.划分子类问题(找出递推关系式):明确递推范围(即 dp[i]与它后几位有关?),找出数组元素递推关系式。
注意:可以从
dp[i] = ?这一数学公式开始推想,寻找我们的递推范围,比如说青蛙跳台阶一次可以跳 1 格或 2 格,所以我们的递推范围为 2,即dp[i]与dp[i-1]和dp[i-2]有关。并且需要注意,我们的初始值已经填入进去了,我们得从没有填数据的位置开始填表。
子类问题的数量
原问题 = 子类问题 + 当前问题
原问题可能不止与一个子类问题有关,因为问题的划分方式多种多样,子类问题与当前问题也多种多样,遇到这种情况可以考虑所有之内问题与当前问题,多次填表,之后再将多次填表的结果组合成原问题的结果。
原问题:[10,9,2,5,3,7,101,18]以18为尾的子序列长度
子类问题:[10,9,2,5,3,7,101]以101为尾的子序列长度、[10,9,2,5,3,7]、[10,9,2,5,3]、...、[10]
当前问题:18,每次与子类问题的尾进行大小比较,推出原问题
子类问题需要多次填表,需要额外的一层循环。
子类问题的规则(推出最小问题)
并且根据子类问题的规则,我们可以倒推出我们的最小问题(初始问题):
如子类问题为dp[leftIndex + 1][rightIndex - 1],我们可以看到此子类问题的规则:
- 下标不能越界:
rightIndex - 1 >= 0,rightIndex >= 1,所以需要将下标为0的数组填表,需要将窗口长度为1的数组初始化填表 - 左边界不能超过右边界:
leftIndex + 1 <= rightIndex - 1,rightIndex - leftIndex >= 2,所以需要将rightIndex - leftIndex值为0和1的,窗口长度为1和2的数组初始化填表
子类问题的大小层级(推出填表顺序)
填表顺序与子类问题的大小层级有关,我们的填表顺序需要保证子类问题慢慢增大(由小及大),利用小子类问题的结果推出大子类问题的结果,直到推出原问题结果。
也就是说,我们最好能按照子类问题的大小层级进行填表,而不是按照我们的表格遍历顺序
- 最小问题层
- 小子类问题层
- 中子类问题层
- 大子类问题层
- 原问题
实例:
-
前缀分解
dp[index]:一般是顺序填表,一行一行地填表。原问题:[1, 2, 3, 4, 5]、子类问题:[1, 2, 3, 4]、当前问题:5
子类问题的大小:[1]、[1, 2]、[1, 2, 3]、[1, 2, 3, 4]、[1, 2, 3, 4, 5]从最小问题一步步递推到原问题;
所以我们的填表顺序:dp[0]->dp[1]->dp[2]->dp[3]->dp[4] -
范围分解
dp[leftIndex][rightIndex]:范围分解比较有代表意义的就是 5. 最长回文子串,填表顺序比较奇特。原问题:babab、子类问题:aba、当前问题:b b
子类问题的大小:b、aba、babab
所以我们的填表顺序:dp[2][2]->dp[1][3]->dp[0][4],可以看到我们第一层级窗口大小为1,第二层级窗口大小为3,第三层级窗口大小为5
所以我们的最终填表顺序:窗口大小1、3、5,这样会比上面一种跳跃式填表更具有逻辑性,并且程序会更加好写。
4. 解决当前问题(找出递推关系式)
4.解决当前问题:根据子类问题明确递推范围,并从中找出与当前问题相关的解决方式(递推关系式)。
如 上一步我们找到了
dp[i]与dp[i-1]和dp[i-2]有关,这一步我们就需要解决,dp[i]与dp[i-1]和dp[i-2]之间的递推关系式。
递推关系式的筛选直接决定了整个算法的递推效率,例如下面的题《322. 零钱兑换》,两种递推方法,带来的算法效率大有不同。
我们要根据当前的历史记录表,找到能够直接递推出当前元素的某个递推关系式,注意是 直接,越直接,我们的递推效率越高。
就拿零钱兑换这题举例,我的思路是按总金额的增减进行递推;而答案是直接按硬币的增减进行递推,所以答案的递推效率会更高。
四步走举例
明确数组的含义
第一步:定义数组元素的含义。
上面说了,我们会用一个数组,来保存历史记录,假设用一维数组 dp[] 吧。这个时候有一个非常非常重要的点,就是规定你这个数组元素的含义,即 你的 dp[i] 是代表什么意思?
那么下面我来举个例子吧!
问题描述:一只青蛙一次可以跳上1级台阶,也可以跳上2级。求该青蛙跳上一个n级的台阶总共有多少种跳法。
首先,拿到这个题,我们需要判断用什么方法,要跳上n级的台阶,我们可能需要用到前几级台阶的数据,即 历史记录,所以我们可以用动态规划。
我们需要存储的信息:
- 当前台阶数
- 跳到当前台阶有多少种跳法
所以我们使用一维数组:
- 当前台阶数:数组下标
- 跳到当前台阶有多少种跳法:数组元素值
然后依据上面我说的第一步,建立数组 dp[] ,那么顺理成章我们的 dp[i] 应该规定含义为:跳上一个i级的台阶总共有dp[i]种解法。
那么,求解dp[n]就是我们的任务。
制作阶段记录表
- 根据数组,制表,确定一维表、二维表;
- 填入初始值;
- 根据递推关系式,写程序推出剩余的空表项。
注意:这里一维表比较简单可能体现不出它的作用,到二维表它就能很方便的将数据可视化了。
此题,由于明确了数组的含义,我们可以确定是一张一维表。
历史记录表:
| 数组dp | 1 | 2 | 3 | … | n |
|---|---|---|---|---|---|
| 值 |
寻找数组初始值
第二步:找出初始值。
利用我们学过数学归纳法,我们可以知道如果要进行递推,我们需要一个初始值来推出结果值,也就是我们常说的第一张多米诺骨牌。
本题的初始值很容易我们就找出来了,
- 当 n = 1 时,即 只有一级台阶,那么我们的青蛙只用跳一级就可以了,只有一种跳法,dp[1] = 1;
- 当 n = 2 时,即 有两级台阶,我们的青蛙有两种选择,一级一级的跳 和 一次跳两级,dp[2] = 2;
- 当 n = 3 时,即 有三级台阶,我们的青蛙跳一级 + dp[2],或 跳两级 + dp[1],这时候我们就反应过来了,需要进行下一步找出 n 的递推关系式。
历史记录表:
| 数组dp | 1 | 2 | 3 | … | n |
|---|---|---|---|---|---|
| 值 | 1 | 2 |
找出递推关系式
第三步:找出数组元素之间的关系式。
动态规划有一点类似于数学归纳法的,当我们要计算 dp[n] 时,是可以利用 dp[1]……dp[n-2]、dp[n-1] ,来推出 dp[n] 的,也就是可以利用历史数据来推出新的元素值,所以我们要找出数组元素之间的关系式,例如, dp[i] = dp[i-1] + dp[i-2] ,这个就是它们的递推关系式了。而这一步,也是最难的一步,后面我会讲几种类型的题来说。
当 n = i 时,即 有 i 级台阶,我们的青蛙最后究竟怎么样到达的这第 i 级台阶呢?
因为青蛙的弹跳力有限,只能一次跳一级或者两级,所以我们有两种方式可以到达最后的这第 i 级:
- 从 i-1 处跳一级
- 从 i-2 处跳两级
所以,我们只需要把青蛙跳上 i-1 级台阶 和 i-2 级台阶的跳法加起来,我们就可以得到到达第 i 级的跳法(i≥3),即
这样我们知道了初始值dp[1]、dp[2],可以从dp[3]开始递推出4、5、6、...、n。
历史记录表:
| 数组dp | 1 | 2 | 3 | … | n |
|---|---|---|---|---|---|
| 值 | 1 | 2 | 3 | … |
用程序循环得出后面的空表项。
你看有了初始值,以及数组元素之间的关系式,那么我们就可以像数学归纳法那样递推得到dp[n]的值了,而dp[n]的含义是由你来定义的,你想求什么,就定义它是什么,这样,这道题也就解出来了。
答案:
// 青蛙跳台阶
int f(int n) {
// 特别给初始值的出口
if(n <= 2)
return n;
// 创建数组保存历史数据
int[] dp = new int[n+1];
// 给出初始值
dp[1] = 1;
dp[2] = 2;
// 通过递推关系式来计算出 dp[n]
for(int i = 3; i <= n; i++) {
dp[i] = dp[i-1] + dp[i-2];
}
// 把最终结果返回
return dp[n];
}
状态数组定义技巧
其实,我们的动态规划算法,根据状态数组的定义不同,我们也会有不同的解法,当然,这些解法都是可以得到正确答案的,大家可以按照自己的思维去决定怎么定义状态数组。
下面总结了几种常用的状态数组定义技巧。
理解:下面的所有方法都可以概括为一句话——数组保存的状态一般都具有前缀性,此数组的该状态存储的是前几个中的最优值。
以 [i] 结尾(dp[i]表示以元素nums[i]结尾的最优解)
适用场景:要求元素连续、窗口
如 连续子数组的最大和
为何定义最大和 \(dp[i]\) 中必须包含元素 \(nums[i]\) :保证 \(dp[i]\) 递推到 \(dp[i+1]\) 的正确性;如果不包含 \(nums[i]\) ,递推时则不满足题目的 连续子数组 要求。
原理:其实就是限定末尾下标为 i 的那个元素必须包含。
示例操作:dp[i] = Math.max(dp[i - 1] + nums[i], nums[i])
以 [0, i] 为范围区间(dp[i]表示区间 [0, i] 里的最优解)
适用场景:范围、区间、不连续、一维
原理:不限定下标为 i 的那个元素必须包含,只代表范围。
示例操作:dp[i] = Math.max(dp[i - 1], dp[i - 2] + nums[i]);
以 [i][j] 表示完整的当前状态(dp[i][j]表示第 i 次选与不选的状态 j 情况下的最优解)
适用场景:j取值0、1表示两种状态(加入或不加入),背包问题(前i个物品,容量为j,利用i来消除排列组合的重复性(优化中会提到))
二维,比较通用
原理:完整的表明当前状态,方便递推。
示例操作:dp[i][0] = Math.max(dp[i - 1][0], dp[i - 1][1])和dp[i][1] = dp[i - 1][0] + nums[i]
上面的这些方法,下面都会讲的!
线性
具有线性阶段划分的动态规划算法称为线性动态规划(简称线性DP)。若状态包含多个维度,则每个维度都是线性划分的阶段,也属于线性DP。
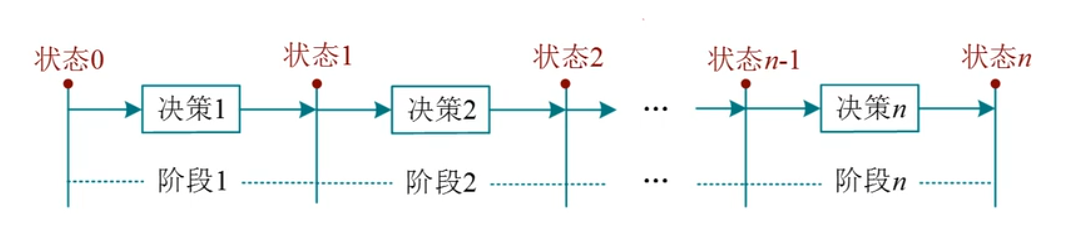
前缀性
- 原问题:区间0..i的最优值
- 子类问题:区间0..i-1的最优值
- 当前问题:i的值
- 最小问题:区间0..0的初始最优值
区间
区间DP属于线性DP的一种,以区间长度作为DP的阶段,以区间的左右端点作为状态的维度。一个状态通常由被它包含且比它更小的区间状态转移而来。
阶段(长度)、状态(左右端点)、决策三者按照由外到内的顺序构成三层循环。
- 原问题:区间i..j的最优值
- 子类问题:区间i..k、k..j的最优值(k=i+1,i+2...j-1)
- 当前问题:结合子类问题
- 最小问题:区间i..i的初始最优值
注意:所有子类问题都需要由小及大求解,区间由小及大的方式为区间长度。
最少租金
题目描述(P1359/T1624):长江游艇俱乐部在长江上设置了n个游艇出租站,游客可以在这些出租站租用游艇,在下游的任何一个游艇出租站归还游艇。游艇出租站i到游艇出租站j之间的租金为r(i,j)。现在要求出从游艇出租站1到游艇出租站n所需的最少的租金。
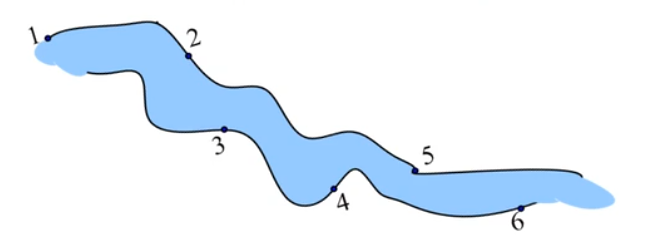
答案
当要租用游艇从一个站到另外一个站时,中间可能经过很多站点,不同的停靠站策略就有不同的租金。
- 原问题:第i个站点到第j个站点的最优值,i, i+1, i+2, ..., j
- 子类问题:假设在第k个站点停靠,可划分为i..k、k..j的最优值(k有多种划分取值,需多次迭代填表)
- 当前问题:i..j的最优值 = min(i..k的最优值 + k..j的最优值)
- 最小问题:直达站点,无需停靠的dp[i][j] = r[i][j]
void rent(){
for (int d = 3; d <= n; d++) { // 区间长度d
for (int i = 1; i <= n - d + 1; i++) { // 状态起点i,终点j
int j = i + d - 1;
for (int k = i + 1; k < j; k++) { // 枚举决策点k
if (dp[i][j] > dp[i][k] + dp[k][j])
dp[i][j] = dp[i][k] + dp[k][j];
}
}
}
}
树形
在树形结构上实现的动态规划称为树形DP。动态规划是多阶段决策问题,而树形结构有明显的层次性,正好对应动态规划的多个阶段。
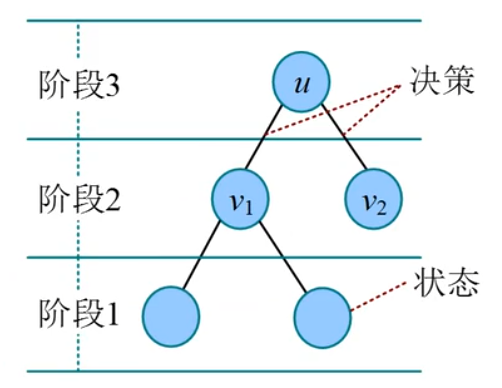
树形DP一般自底向上,将子树从小到大作为DP的“阶段”,将节点编号作为DP状态的第1维,代表以该节点为根的子树。
树形DP一般采用深度优先遍历,递归求解每棵子树(分治法,每次递归返回每棵子树的最优值),回溯时从子节点向上进行状态转移。在当前节点的所有子树都求解完毕后,才可以求解当前节点。
(也可以广度优先遍历,使用拓扑排序,依次从叶子节点(入度为0)开始向上遍历。
- 原问题:根节点为i的树的最优值
- 子类问题:i的子树的最优值(分治法,使用dfs递归返回每棵子树的最优值)
- 当前问题:结合所有子类问题(在当前问题处结合所有子类问题,
dp[i] += dfs(v)) - 最小问题:根节点为叶子节点的初始最优值
注意:所有子类问题都需要由小及大求解,树形由小及大的方式为子树大小,从叶子节点向上,到小子树,到中子树,到大子树。
记忆化搜索,当搜索到之后存入数组,如果数组中有值,则直接返回。
周年派对
题目描述(POJ2342/HDU1520):Ural 大学将举行80周年校庆晚会。大学职员的主管关系像一棵以校长为根的树。为了让每-一个 人都玩的嗨皮,校长不希望职员和他的直接上司都在场。人事处已经评估了每个职员的欢乐度,你的任务是列出一个邀请职员名单,使参会职员的欢乐度总和最大。
输入:职员的编号从1到N。输入的第一行包含数字 N (1≤N≤6000)。后面的N行中的每一行都包含相应职员的欢乐度。欢乐度是一个从-128到127整数。之后的N-1行是描述主管关系树。每一行都具有以下格式: L K,表示第K名职员是第L名职员的直接主管。输入以包含0 0 的行结尾。
输出:输出参会职员欢乐度的最大和值。
输入样例:
7
1 1 1 1 1 1 1
1 3
2 3
6 4
7 4
4 5
3 5
0 0
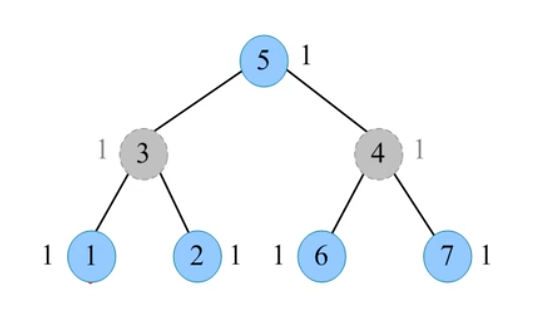
输出样例:
5
答案
明确数组含义:
-
dp[u][0]表示不选择节点u时,在以节点u为根的子树中参加职员的欢乐度最大和。
-
dp[u][1]表示选择节点u时,在以节点u为根的子树中参加职员的欢乐度最大和。
-
原问题:当前节点u为根的树的最大欢乐度(选或不选),
max(dp[root][0], dp[root][1]),root为树根 -
子类问题:u的子节点为根的子树的最大欢乐度
-
当前问题:当前节点u选或不选
- 若不选择当前节点u,则它的所有子节点v都可选或不选,取最大值即可。
dp[u][0]+=max(dp[v][0], dp[v][1]); - 若选择当前节点u,则它的所有子节点v均不可选。
dp[u][1] += dp[v][0];
- 若不选择当前节点u,则它的所有子节点v都可选或不选,取最大值即可。
-
最小问题:叶子节点
dp[u][0] = 0, dp[u][1] = val[u];
dfs:分治法
// E[u]为邻接表
void dfs(int u){
dp[u][0]=0;
dp[u][1]=val[u];
for(int i=0;i<E[u].size();i++){
int v=E[u][i];
dfs(v); // 分治法,填写子节点的dp
dp[u][0]+=max(dp[v][1],dp[v][0]);
dp[u][1]+=dp[v][0];
}
}
dfs换一种理解:
// E[u]为邻接表
int[] dfs(int u){
dp[u][0]=0;
dp[u][1]=val[u];
for(int i=0;i<E[u].size();i++){
// 划分子类问题
int v=E[u][i];
dp[v] = dfs(v); // 分治法,填写子节点的dp
// 解决当前问题
dp[u][0]+=max(dp[v][1],dp[v][0]);
dp[u][1]+=dp[v][0];
}
}
bfs:
void bfs() {
for (int i = 0; i < val.length; i++) {
dp[i][0] = 0;
dp[i][1] = val[i];
}
for (int i = 0; i < indegree.length; i++) {
if (indegree[i] == 0) {
queue.offer(i);
}
}
// 拓扑排序,从叶子节点开始
while (!queue.isEmpty()) {
int cur = queue.poll();
// 遍历该节点的邻接表
for (int v : edges.get(cur)) {
// 当前节点的邻接节点均为其父节点
dp[v][0] += max(dp[cur][0], dp[cur][1]);
dp[v][1] += dp[cur][0];
indegree[v]--;
if (indegree[v] == 0) {
queue.offer(v);
}
}
}
}
337. 打家劫舍 III
小偷又发现了一个新的可行窃的地区。这个地区只有一个入口,我们称之为 root 。
除了 root 之外,每栋房子有且只有一个“父“房子与之相连。一番侦察之后,聪明的小偷意识到“这个地方的所有房屋的排列类似于一棵二叉树”。 如果 两个直接相连的房子在同一天晚上被打劫 ,房屋将自动报警。
给定二叉树的 root 。返回 在不触动警报的情况下 ,小偷能够盗取的最高金额 。
示例 1:
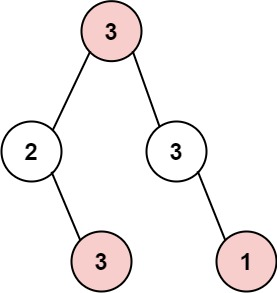
输入: root = [3,2,3,null,3,null,1]
输出: 7
解释: 小偷一晚能够盗取的最高金额 3 + 3 + 1 = 7
示例 2:
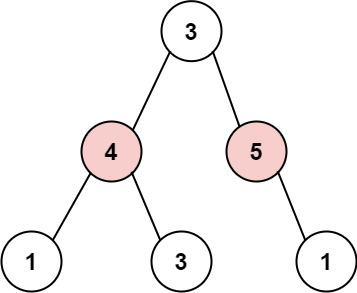
输入: root = [3,4,5,1,3,null,1]
输出: 9
解释: 小偷一晚能够盗取的最高金额 4 + 5 = 9
答案
方法一:动态规划
思路与算法
简化一下这个问题:一棵二叉树,树上的每个点都有对应的权值,每个点有两种状态(选中和不选中),问在不能同时选中有父子关系的点的情况下,能选中的点的最大权值和是多少。
我们可以用 f(o) 表示选择 o 节点的情况下,o 节点的子树上被选择的节点的最大权值和;g(o) 表示不选择 o 节点的情况下,o 节点的子树上被选择的节点的最大权值和;l 和 r 代表 o 的左右孩子。
- 当 o 被选中时,o 的左右孩子都不能被选中,故 o 被选中情况下子树上被选中点的最大权值和为 l 和 r 不被选中的最大权值和相加,即 f(o) = g(l) + g(r)。
- 当 o 不被选中时,o 的左右孩子可以被选中,也可以不被选中。对于 o 的某个具体的孩子 x,它对 o 的贡献是 x 被选中和不被选中情况下权值和的较大值。故 \(g(o) = \max \{ f(l) , g(l)\}+\max\{ f(r) , g(r) \}\)。
至此,我们可以用哈希表来存 f 和 g 的函数值,用深度优先搜索的办法后序遍历这棵二叉树,我们就可以得到每一个节点的 f 和 g。根节点的 f 和 g 的最大值就是我们要找的答案。
我们不难给出这样的实现:
class Solution {
Map<TreeNode, Integer> f = new HashMap<TreeNode, Integer>();
Map<TreeNode, Integer> g = new HashMap<TreeNode, Integer>();
public int rob(TreeNode root) {
dfs(root);
return Math.max(f.getOrDefault(root, 0), g.getOrDefault(root, 0));
}
public void dfs(TreeNode node) {
if (node == null) {
return;
}
dfs(node.left);
dfs(node.right);
f.put(node, node.val + g.getOrDefault(node.left, 0) + g.getOrDefault(node.right, 0));
g.put(node, Math.max(f.getOrDefault(node.left, 0), g.getOrDefault(node.left, 0)) + Math.max(f.getOrDefault(node.right, 0), g.getOrDefault(node.right, 0)));
}
}
假设二叉树的节点个数为 n。
我们可以看出,以上的算法对二叉树做了一次后序遍历,时间复杂度是 \(O(n)\);由于递归会使用到栈空间,空间代价是 \(O(n)\),哈希表的空间代价也是 \(O(n)\),故空间复杂度也是 \(O(n)\)。
我们可以做一个小小的优化,我们发现无论是 f(o) 还是 g(o),他们最终的值只和 f(l)、g(l)、f(r)、g(r) 有关,所以对于每个节点,我们只关心它的孩子节点们的 f 和 g 是多少。我们可以设计一个结构,表示某个节点的 f 和 g 值,在每次递归返回的时候,都把这个点对应的 f 和 g 返回给上一级调用,这样可以省去哈希表的空间。
代码如下。
class Solution {
public int rob(TreeNode root) {
int[] rootStatus = dfs(root);
return Math.max(rootStatus[0], rootStatus[1]);
}
public int[] dfs(TreeNode node) {
if (node == null) {
return new int[]{0, 0};
}
int[] l = dfs(node.left);
int[] r = dfs(node.right);
int selected = node.val + l[1] + r[1];
int notSelected = Math.max(l[0], l[1]) + Math.max(r[0], r[1]);
return new int[]{selected, notSelected};
}
}
复杂度分析
-
时间复杂度:\(O(n)\)。上文中已分析。
-
空间复杂度:\(O(n)\)。虽然优化过的版本省去了哈希表的空间,但是栈空间的使用代价依旧是 \(O(n)\),故空间复杂度不变。
数位
数位DP是与数位相关的一类计数类DP,一般用于统计[l, r]区间满足特定条件的元素个数。数位指个位、十位、百位、千位等,数位DP就是在数位上进行动态规划。数位DP在实质上是一种有策略的穷举方式,在子问题求解完毕后将其结果记忆化就可以了。
如何枚举?
枚举[0,386]区间的所有数时,首先从百位开始枚举,百位可能是0、1、2、3。枚举时不超过386即可。(树形图)
- 百位0:十位可以是09,个位也可以是09,枚举没有限制,因为百位是0时,后面的位数无论是多少,都不可能超过386,相当于枚举000~099。
- 百位1:十位可以是09,个位也可以是09,枚举没有限制,枚举100~199。
- 百位2:十位可以是09,个位也可以是09,枚举没有限制,枚举200~299。
- 百位3:十位只可以是08,否则超过386,此时是有上界限制的。当十位是07时,个位可以是09,因为379还是不会超过386。但当十位是8时,个位只可以是06,此时有上界限制,相当于枚举300379、380386。
数位DP需要注意的几个问题:
(1)记忆化。无限制时,可以记忆化;有限制时,不可以记忆化,需要继续根据限制枚举。
枚举[0,386]区间的所有数,当百位是02时,十位和个位枚举没有限制,都是一样的,采用记忆化递归,只需计算一次并将结果存储起来,下次判断若已赋值,则直接返回该值即可。百位是3时,十位限制在08;十位是07时,个位无限制;十位是8时,个位限制在06。
(2)上界限制。当高位枚举刚好达到上界时,紧接着的下一位枚举就有上界限制了。可以设置一个变量limit标记是否有上界限制。
(3)高位枚举0。为什么高位需要枚举0?这是因为百位枚举0相当于此时枚举的这个数最多是两位数,若十位继续枚举0,则枚举的是一位数。枚举小于或等于386的数,一位数、两位数当然也比它小,所以高位要枚举0。
(4)前导0。有时会有前导0的问题,可以设置一个lead变量表示有前导0。例如统计数字里面0出现的次数。若有前导0,例如008,数字8不包含0,则不应该统计8前
面的两个0。若没有前导0,例如108,则应该统计8前面的1个0。
定时炸弹
题目描述(HDU3555): 反恐怖分子在尘土中发现了一枚定时炸弹,但这次恐怖分子改进了定时炸弹。定时炸弹的数字序列从1到n。若当前的数字序列包括子序列“49”, 则爆炸的力量会增加一个点。现在反恐人员知道了数字n,他们想知道最后的力量点。
输入:输入的第1行包含一个整数T(1≤T≤10000),表示测试用例的数量。对每个测试用例,都有一个整数n (\(1≤n≤2^{63}-1\))作为描述。。
输出:对每个测试用例,都输出一个整数,表示最终的力量点。
输入样例:
3
1
50
500
输出样例:
0
1
15
答案
状态表示:dp[pos][sta]表示当前第pos位在sta状态下满足条件的个数,sta表示前一位是否是4,布尔变量。
状态转移方程:
if (sta && i == 9) ans += limit ? n % z[pos - 1] + 1 : z[pos - 1];
z[pos]表示\(1O^{pos}\),若无限制,则“49”后面有多少位,就累加z[pos-1]的个数。若有限制,则求出“49”后面的数字再加1。
例如,[1, 500]区间,枚举时“49”后面还有1位数,无限制,则累加10个包含“49”的数,分别为490~499。
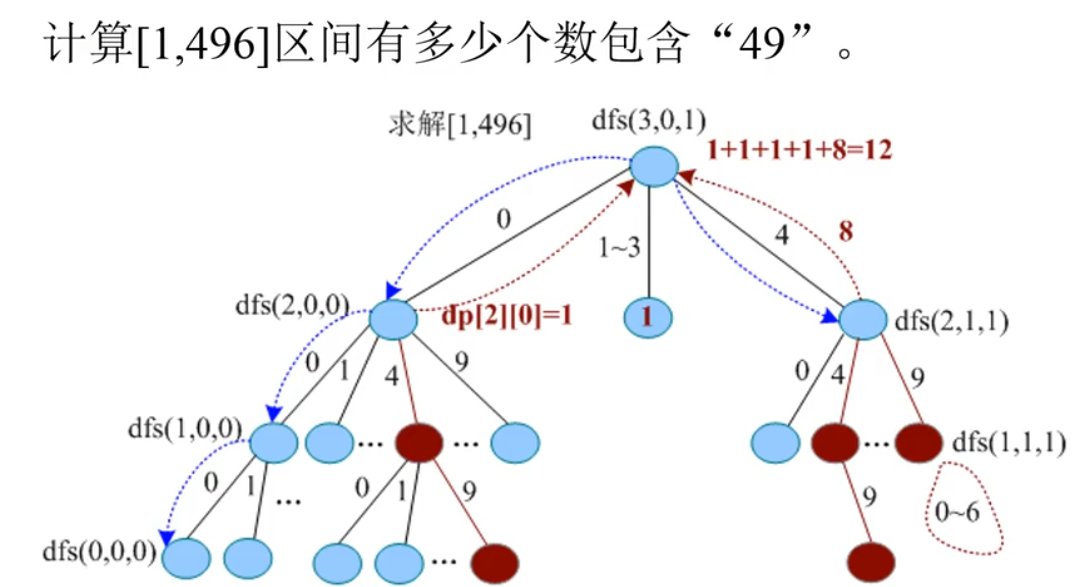
例如,[1, 496]区间,枚举时“49”后面的数字是6,有限制,则累加6+1个(包括0)包含“49”的数,即490~496。
z[pos]表示\(10^{pos}\),若无限制,则“49”后面有多少位,累加z[pos-1]的个数。若有限制,则求出“49”后面的数字再加1。
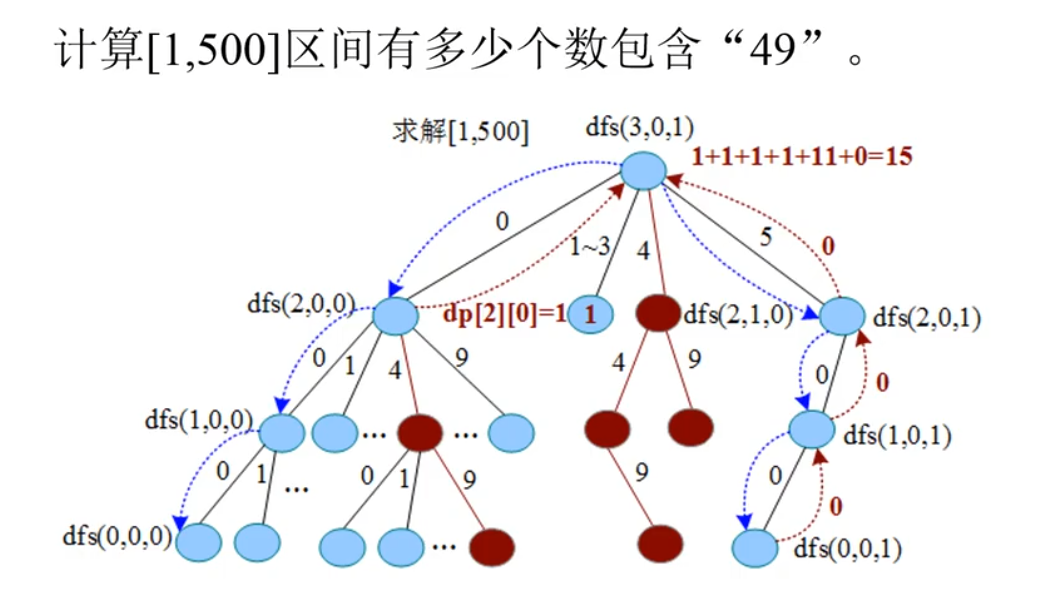
计算[1 ,500]区间有多少个数包含“49”。
(1)数字分解: dig[1]=0, dig[2]=0, dig[3]=5。
(2)从高位开始,当前位是3,前面1位不是4,有限制。len=dig[3]=5,枚举i=0..5。
- i=0:以0开头的两位数,无限制,枚举i=0..9, 只有1个数包含“49” ,即049, dp[2][0]=1。
- i=l:以1开头的两位数,无限制且dp[2][0]已赋值,返回。
- i=2:以2开头的两位数,无限制且dp[2][0]已赋值,返回。
- i=3:以3开头的两位数,无限制且dp[2][0]已赋值,返回。
- i=4:以4开头的两位数,无限制,枚举i=0..9。 i=4时,向下找到一个解49,即449; i=9时,累加10个解,即490~499。dp[2][1]=11。
- i=5:以5开头的两位数,有限制,len=dig[2]=0,执行i=0,递归求解。pos=0时,返回0。
(3)累加结果,返回[1,500]区间包含“49”的数15个。
// z[]为提前记录的10的倍数数组,方便取出某一位数字,避免重复计算
z[0] = 1;
for (int i = 1; i < pos; i++) {
z[i] = z[i - 1] * 10;
}
//dp[pos][sta]表示当前第pos位,sta状态下满足条件的个数,sta表示前一位是否是4,只有0和1两种状态
LL dfs(int pos, bool sta, bool limit) { // 求包含49的个数
if (!pos) return 0;
if (!limit && dp[pos][sta] != -1) return dp[pos][sta];//如果无限制且已赋值,直接返回
// 枚举长度
int len = limit ? dig[pos] : 9; //if(limit) Len=dig[pos]; else len=9;
LL ans = 0;
for (int i = 0; i <= len; i++){
if (sta && i == 9) // 如果前一位为4,当前位为9
// 如果限制,区间总数n 与 后几位取余,如 当前位为4,496 % 100 = 96 + 1(包括0,0..96有97个数)
// 如果无限制,则0..99,100个数
ans += limit ? n % z[pos - 1] + 1 : z[pos - 1];
else
ans += dfs(pos - 1, i == 4, limit && i == len);
if (!limit) dp[pos][sta] = ans; // 无限制才记忆化,有限制无需记忆
return ans;
}
LL solve(LL x) {//求解[1..x]之间满足条件的个数
int pos=0;
while(x) {//数位分解
dig[++pos] = x % 10;
x /= 10;
}
return dfs(pos, 0, 1);
}
2376. 统计特殊整数
如果一个正整数每一个数位都是 互不相同 的,我们称它是 特殊整数 。
给你一个 正 整数 n ,请你返回区间 [1, n] 之间特殊整数的数目。
示例 1:
输入:n = 20
输出:19
解释:1 到 20 之间所有整数除了 11 以外都是特殊整数。所以总共有 19 个特殊整数。
示例 2:
输入:n = 5
输出:5
解释:1 到 5 所有整数都是特殊整数。
示例 3:
输入:n = 135
输出:110
解释:从 1 到 135 总共有 110 个整数是特殊整数。
不特殊的部分数字为:22 ,114 和 131 。
答案
https://leetcode.cn/problems/count-special-integers/solution/shu-wei-dp-mo-ban-by-endlesscheng-xtgx/
力扣上的数位 DP 题目
- 数字 1 的个数(题解)
面试题 17.06. 2出现的次数(题解) - 不含连续1的非负整数(题解)
- 最大为 N 的数字组合(周赛精讲 中讲了)
- 至少有 1 位重复的数字
- 范围内的数字计数
- 找到所有好字符串(有难度,需要结合一个知名字符串算法)
将 n 转换成字符串 s,定义 \(f(i,\textit{mask}, \textit{isLimit},\textit{isNum})\) 表示构造从左往右第 i 位及其之后数位的合法方案数,其余参数的含义为:
- \(\textit{mask}\) 表示前面选过的数字集合,换句话说,第 i 位要选的数字不能在 \textit{mask}mask 中。
- \(\textit{isLimit}\) 表示当前是否受到了 n 的约束。若为真,则第 i 位填入的数字至多为 s[i],否则可以是 9。如果在受到约束的情况下填了 s[i],那么后续填入的数字仍会受到 n 的约束。
- \(\textit{isNum}\) 表示 i 前面的数位是否填了数字。若为假,则当前位可以跳过(不填数字),或者要填入的数字至少为 1;若为真,则必须填数字,且要填入的数字可以从 0 开始。
后面两个参数可适用于其它数位 DP 题目。
枚举要填入的数字,具体实现逻辑见代码。
下面代码中 Java/C++/Go 只需要记忆化 \((i,\textit{mask})\) 这个状态,因为:
- 对于一个固定的 \((i,\textit{mask})\),这个状态受到 \(\textit{isLimit}\) 或 \(\textit{isNum}\) 的约束在整个递归过程中至多会出现一次,没必要记忆化。
- 另外,如果只记忆化 \((i,\textit{mask})\),\(\textit{dp}\) 数组的含义就变成在不受到约束时的合法方案数,所以要在
!isLimit && isNum成立时才去记忆化。
class Solution {
char s[];
int dp[][];
public int countSpecialNumbers(int n) {
s = Integer.toString(n).toCharArray();
var m = s.length;
dp = new int[m][1 << 10];
for (var i = 0; i < m; i++) Arrays.fill(dp[i], -1);
return f(0, 0, true, false);
}
int f(int i, int mask, boolean isLimit, boolean isNum) {
if (i == s.length) return isNum ? 1 : 0;
if (!isLimit && isNum && dp[i][mask] >= 0) return dp[i][mask];
var res = 0;
if (!isNum) res = f(i + 1, mask, false, false); // 可以跳过当前数位
for (int d = isNum ? 0 : 1, up = isLimit ? s[i] - '0' : 9; d <= up; ++d) // 枚举要填入的数字 d
if ((mask >> d & 1) == 0) // d 不在 mask 中
res += f(i + 1, mask | (1 << d), isLimit && d == up, true);
if (!isLimit && isNum) dp[i][mask] = res;
return res;
}
}
状态压缩
什么是状态压缩 DP
一般来说,动态规划使用一个一维数组或者二维数组来保存状态。
比如 42.接雨水 中,我们使用一维数组 dp[i] 表示下标 i左边最高柱子的高度。dp[i] 包含了两个信息:
- 下标 i 左边的柱子
- 最高的高度值
比如 10.正则表达式匹配 中,我们使用二维数组 dp[i][j] 表示 字符串 s 的前 i 项和 t 的前 j 项是否匹配。dp[i][j] 包含了三个信息:
- s 的前 i 项
- t 的前 j 项
- 是否匹配
对于本题来讲,通过分析,我们也可以表示类似的状态,dp[i][j] 表示当第 i 行的座位分布为 j 时,前 i 行可容纳的最大学生人数。但如果我们还想知道第 i 行有多少个座位呢?这无疑多了一个维度,这时我们不能用类似 dp[i][j][k] 来表示了,因为计算机中没有类似三维的数据结构。
这时候状态中所包含的信息过多,该怎么办呢?我们可以利用二进制以及位运算来实现对于本来应该很大的数组的操作,这就是状态压缩,而使用状态压缩来保存状态的 DP 就叫做状态压缩 DP。
1. 用位编码表示状态
可以使用位编码记录每一行的状态
// n行m列,所以有1 << m种状态
int status = 1 << m;
// 将已知的位置图按行开始位运算划分,每一行都是一个二进制数字
int[] newSeats = new int[n];
for (int i = 0; i < n; i++) {
int sum = 0;
for (int j = 0; j < m; j++) {
// 相当于十进制求和,先*10,后相加
sum <<= 1; // 先前进,有效前进就只前进m-1次
if (seats[i][j] == '#') {
sum += 1;
}
}
newSeats[i] = sum;
}
// dp[i][j]:第i行状态为j的情况下的最大值
int[][] dp = new int[n][status];
2. 判断此状态是否有效
比如判断是否当前状态有1相邻。
(j & (j << 1)) != 0 || (j & (j >> 1)) != 0
3. 判断 此行(第i行) 状态j 与 上一行(第i-1行) 状态k 的关系
我们需要将此行i的状态j 与 上一行i-1的所有状态k,相互比较,迭代填表。
// 上一行的状态分别与当前行状态映射,多次填表
for (int k = 0; k < status; k++) {
// 检验上一行与当前行的状态在一起是否合法
if ((j & (k << 1)) != 0 || (j & (k >> 1)) != 0) {
continue;
}
dp[i][j] = Math.max(dp[i - 1][k], dp[i][j]);
}
1349. 参加考试的最大学生数
class Solution {
public int maxStudents(char[][] seats) {
// n行m列
int n = seats.length, m = seats[0].length;
int status = 1 << m;
int[] newSeats = new int[n];
for (int i = 0; i < n; i++) {
int sum = 0;
for (int j = 0; j < m; j++) {
// 相当于十进制求和,先*10,后相加
sum <<= 1; // 先前进,有效前进就只前进m-1次
if (seats[i][j] == '#') {
sum += 1;
}
}
newSeats[i] = sum;
}
// dp[i][j]:第i行状态为j的情况下的最大值
int[][] dp = new int[n][status];
int res = 0;
for(int j = 0; j < status; j++) {
// 二进制的状态j中1代表坐人了,0代表空位
// 检验当前行的状态是否合法
if ((j & (j << 1)) != 0 || (j & (j >> 1)) != 0 || (newSeats[0] & j) != 0) {
continue;
}
dp[0][j] += count(j);
}
for(int i = 1; i < n; i++) {
for(int j = 0; j < status; j++) {
// 二进制的状态j中1代表坐人了,0代表空位
// 检验当前行的状态是否合法
if ((j & (j << 1)) != 0 || (j & (j >> 1)) != 0 || (newSeats[i] & j) != 0) {
continue;
}
// 上一行的状态分别与当前行状态映射,多次填表
for (int k = 0; k < status; k++) {
// 检验上一行与当前行的状态在一起是否合法
if ((j & (k << 1)) != 0 || (j & (k >> 1)) != 0) {
continue;
}
dp[i][j] = Math.max(dp[i - 1][k], dp[i][j]);
}
dp[i][j] += count(j);
res = Math.max(res, dp[i][j]);
}
}
return res;
}
public int count(int x){
int res = 0;
while (x != 0){
x = x & (x - 1);
res++;
}
return res;
}
}
多种状态数组定义应用实例
其实,我们的动态规划算法,根据状态数组的定义不同,我们也会有不同的解法,当然,这些解法都是可以得到正确答案的,大家可以按照自己的思维去决定怎么定义状态数组。
面试题 17.16. 按摩师
一个有名的按摩师会收到源源不断的预约请求,每个预约都可以选择接或不接。在每次预约服务之间要有休息时间,因此她不能接受相邻的预约。给定一个预约请求序列,替按摩师找到最优的预约集合(总预约时间最长),返回总的分钟数。
注意:本题相对原题稍作改动
示例 1:
输入: [1,2,3,1]
输出: 4
解释: 选择 1 号预约和 3 号预约,总时长 = 1 + 3 = 4。
示例 2:
输入: [2,7,9,3,1]
输出: 12
解释: 选择 1 号预约、 3 号预约和 5 号预约,总时长 = 2 + 9 + 1 = 12。
示例 3:
输入: [2,1,4,5,3,1,1,3]
输出: 12
解释: 选择 1 号预约、 3 号预约、 5 号预约和 8 号预约,总时长 = 2 + 4 + 3 + 3 = 12。
dp[i]表示以元素nums[i]结尾的最优的预约时长
其实也就是限定下标为 i 的那天接受预约。(下面还有不限定的情况,需要分类讨论,大家可以看看)
当 nums[i] 为结尾,必定选中的情况下,总预约时长可分为两种情况,求最大值
- 在选中 nums[i] 之前,休息一天:nums[i] + dp[i - 2]
- 在选中 nums[i] 之前,休息两天:nums[i] + dp[i - 3]
class Solution {
public int massage(int[] nums) {
// 感觉动态规划
// 头两个可以单独选出来
if (nums.length == 0) {
return 0;
} else if (nums.length == 1) {
return nums[0];
} else if (nums.length == 2) {
return Math.max(nums[0], nums[1]);
} else if (nums.length == 3) {
return Math.max(nums[0] + nums[2], nums[1]);
}
int[] dp = new int[nums.length];
dp[0] = nums[0];
dp[1] = nums[1];
dp[2] = Math.max(nums[0] + nums[2], nums[1]);
for (int i = 3; i < nums.length; i++) {
dp[i] = Math.max(dp[i - 2], dp[i - 3]) + nums[i];
// dp[i] = Math.max(dp[i], dp[i - 1]);
}
return Math.max(dp[nums.length - 1], dp[nums.length - 2]);
}
}
dp[i]表示区间 [0,i] 里接受预约请求的最大时长
https://leetcode.cn/problems/the-masseuse-lcci/solution/dong-tai-gui-hua-by-liweiwei1419-8/
方法二:设计一维状态变量
第 1 步:定义状态
dp[i]:区间 [0,i] 里接受预约请求的最大时长。
第 2 步:状态转移方程
这个时候因为不限定下标为 i 这一天是否接受预约,因此需要分类讨论:
- 接受预约,那么昨天就一定休息,由于状态
dp[i - 1]的定义涵盖了下标为i - 1这一天接收预约的情况,状态只能从下标为i - 2的状态转移而来:dp[i - 2] + nums[i]; - 不接受预约,那么昨天可以休息,也可以不休息,状态从下标为
i - 1的状态转移而来:dp[i - 1];
二者取最大值,因此状态转移方程为 dp[i] = max(dp[i - 1], dp[i - 2] + nums[i])。
第 3 步:思考初始化
看状态转移方程,下标最小到 i - 2,因此初始化的时候要把 dp[0] 和 dp[1] 算出来,从 dp[2] 开始计算。
dp[0]:只有 1 天的时候,必须接受预约,因此 dp[0] = nums[0];dp[1]:头 2 天的时候,由于不能同时接受预约,因此最优值是这两天接受预约时长的最大值dp[1] = max(nums[0], nums[1]);
第 4 步:思考输出
由于定义的状态有前缀性质,并且对于下标为 i 的这一天也考虑了接受预约与不接受预约的情况,因此输出就是最后一天的状态值。
第 5 步:思考空间优化
看状态转移方程。当前状态只与前两个状态相关,我们只关心最后一天的状态值,因此依然可以使用「滚动变量」的技巧,这个时候滚动起来的就是 3 个变量了。这样的代码依然是丢失了可读性,也存在一定编码错误的风险,请见题解后的「参考代码 5」。
参考代码 2:
public class Solution {
public int massage(int[] nums) {
int len = nums.length;
if (len == 0) {
return 0;
} else if (len == 1) {
return nums[0];
} else if (len == 2) {
return Math.max(nums[0], nums[1]);
}
// dp[i]:区间 [0, i] 里接受预约请求的最大时长
int[] dp = new int[len];
dp[0] = nums[0];
dp[1] = Math.max(nums[0], nums[1]);
for (int i = 2; i < len; i++) {
// 今天在选与不选中,选择一个最优的
dp[i] = Math.max(dp[i - 1], dp[i - 2] + nums[i]);
}
return dp[len - 1];
}
}
复杂度分析:
- 时间复杂度:\(O(N)\),N 是数组的长度;
- 空间复杂度:\(O(N)\),状态数组的大小为 N,可以优化到 3,请见题解后的「参考代码 5」。
我们看到解决这个问题的复杂程度与如何定义状态是相关的,定义状态的角度没有固定的模式,但有一个方向是可以考虑的,那就是从「状态转移方程」容易得到的角度去考虑如何设计状态。
「状态」和「状态转移方程」得到以后,这个问题其实就得到了解决,剩下的一些细节的问题在编码的时候只要稍微留意一点就行了。
二维数组dp[i][j]
方法一:设计二维状态变量
第 1 步:设计状态
「状态」这个词可以理解为「记录了求解问题到了哪一个阶段」。
由于当前这一天有按摩师有两种选择:
(1)接预约;
(2)不接预约。
但根据题意,今天是否接预约,是受到昨天影响的。为了消除这种影响,我们在状态数组要设置这个维度。
dp[i][0]表示:区间[0..i]里接受预约请求,并且下标为i的这一天不接受预约的最大时长;dp[i][1]表示:区间[0..i]里接受预约请求,并且下标为i的这一天接受预约的最大时长。
说明:这个定义是有前缀性质的,即 当前的状态值考虑了(或者说综合了)之前的相关的状态值,第 2 维保存了当前最优值的决策,这种通过增加维度,消除后效性的操作在「动态规划」问题里是非常常见的。
无后效性的理解:
1、后面的决策不会影响到前面的决策;
2、之前的状态怎么来的并不重要。个人理解:其实就是前后状态彼此独立互不干扰,即 每个状态都能完整的表示当前状态,不受前后状态的干扰。
一般的情况是,只要有约束,就可以增加一个维度消除这种约束带来的影响,再具体一点说,就是把「状态」定义得清楚、准确,「状态转移方程」就容易得到了。
「力扣」的几道股票问题基本都是这个思路,而且设置状态的思想和这道题是完全一致的。
第 2 步:状态转移方程
「状态转移方程」可以理解为「不同阶段之间的联系」。
今天只和昨天的状态相关,依然是分类讨论:
- 今天不接受预约:或者是昨天不接受预约,或者是昨天接受了预约,取二者最大值,即:
dp[i][0] = max(dp[i - 1][0], dp[i - 1][1]); - 今天接受预约:只需要从昨天不接受预约转移而来,加上今天的时长,即:
dp[i][1] = dp[i - 1][0] + nums[i]。
第 3 步:考虑初始化
从第 2 天开始,每天的状态值只与前一天有关,因此第 1 天就只好老老实实算了。好在不难判断:dp[0][0] = 0 与 dp[0][1] = nums[0];
这里有一种技巧,可以把状态数组多设置一行,这样可以减少对第 1 天的初始化,这样的代码把第 1 天的情况考虑了进去,但编码的时候要注意状态数组下标的设置, 请见题解最后的「参考代码 3」。
第 4 步:考虑输出
由于状态值的定义是前缀性质的,因此最后一天的状态值就考虑了之前所有的天数的情况。按摩师最后一天可以接受预约,也可以不接受预约,取二者最大值。
第 5 步:考虑是否可以优化空间
由于今天只参考昨天的值,可以使用「滚动数组」完成,优化空间以后的代码丢失了一定可读性,也会给编码增加一点点难度,请见题解后的「参考代码 4」。
参考代码 1:
public class Solution {
public int massage(int[] nums) {
int len = nums.length;
if (len == 0) {
return 0;
}
if (len == 1) {
return nums[0];
}
// dp[i][0]:区间 [0, i] 里接受预约请求,并且下标为 i 的这一天不接受预约的最大时长
// dp[i][1]:区间 [0, i] 里接受预约请求,并且下标为 i 的这一天接受预约的最大时长
int[][] dp = new int[len][2];
dp[0][0] = 0;
dp[0][1] = nums[0];
for (int i = 1; i < len; i++) {
dp[i][0] = Math.max(dp[i - 1][0], dp[i - 1][1]);
dp[i][1] = dp[i - 1][0] + nums[i];
}
return Math.max(dp[len - 1][0], dp[len - 1][1]);
}
}
复杂度分析:
- 时间复杂度:\(O(N)\),N 是数组的长度;
- 空间复杂度:\(O(N)\),状态数组的大小为 2N,可以优化到常数级别,请见题解后的「参考代码 4」。
以上是中规中矩的写法。在这里根据问题本身的特点,状态可以不用设置那么具体,就将题目问的设计成状态(题目:每个预约都可以选择接或不接),状态转移方程依然好写。
总结
「动态规划」其实不是什么特别难懂的东西(只是说思想),只是这一类问题刚接触的时候有点不太适应,并且这类问题容易被包装得很过分,而且没有明显的套路,题型多样,所以学习「动态规划」会有一些些吃力,这没有办法,见多了就好。如果是准备面试,不需要掌握特别复杂的「动态规划」问题(当然前提是你没有在简历上说你是算法竞赛高手)。
「动态规划」告诉了我们另一种求解问题的思路。我们学习编程,习惯了自顶向下求解问题(递归),在自顶向下求解问题的过程中,发现了重复子问题,我们再加上缓存。而「动态规划」告诉我们,其实有一类问题我们可以从一个最简单的情况开始考虑,通过逐步递推,每一步都记住当前问题的答案,得到最终问题的答案,即「动态规划」告诉了我们「自底向上」思考问题的思路。
也就是说「动态规划」告诉我们的新的思路是:不是直接针对问题求解,由于我们找到了这个问题最开始的样子,因此后面在求解的过程中,每一步都可以参考之前的结果(在处理最优化问题的时候,叫「最优子结构」),由于之前的结果有重复计算(「重复子问题」),因此必须记录下来。
这种感觉不同于「记忆化递归」,「记忆化递归」是直接面对问题求解,遇到一个问题解决了以后,就记下来,随时可能面对新问题。而「动态规划」由于我们发现了这个问题「最初」的样子,因此每一步参考的以前的结果都是知道的,就像我们去考试,所有的考题我们都见过,并且已经计算出了答案一样,我们只需要参考以前做题的答案,就能得到这一题的答案,这是「状态转移」。应用「最优子结构」是同一回事,即:综合以前计算的结果,直接得到当前的最优值。
「动态规划」的内涵和外延很丰富,不是几句话和几个问题能够理解清楚的,需要我们做一些经典的问题去慢慢理解它,和掌握「动态规划」问题思考的方向。
参考代码 4:根据方法三:状态数组多设置一行,以避免对极端用例进行讨论。
Java
public class Solution {
public int massage(int[] nums) {
int len = nums.length;
// dp 数组多设置一行,相应地定义就要改变,遍历的一些细节也要相应改变
// dp[i][0]:区间 [0, i) 里接受预约请求,并且下标为 i 的这一天不接受预约的最大时长
// dp[i][1]:区间 [0, i) 里接受预约请求,并且下标为 i 的这一天接受预约的最大时长
int[][] dp = new int[len + 1][2];
// 注意:外层循环从 1 到 =len,相对 dp 数组而言,引用到 nums 数组的时候就要 -1
for (int i = 1; i <= len; i++) {
dp[i][0] = Math.max(dp[i - 1][0], dp[i - 1][1]);
dp[i][1] = dp[i - 1][0] + nums[i - 1];
}
return Math.max(dp[len][0], dp[len][1]);
}
}
复杂度分析:
- 时间复杂度:\(O(N)\),N 是数组的长度;
- 空间复杂度:\(O(N)\),状态数组的大小为 \(2(N + 1)\),记为 \(O(N)\)。
参考代码 5:根据方法三,使用「滚动数组」技巧,将空间优化到常数级别
在编码的时候,需要注意,只要访问到 dp 数组的时候,需要对下标 % 2,等价的写法是 & 1。
Java
public class Solution {
public int massage(int[] nums) {
int len = nums.length;
if (len == 0) {
return 0;
}
if (len == 1) {
return nums[0];
}
// dp[i & 1][0]:区间 [0, i] 里接受预约请求,并且下标为 i 的这一天不接受预约的最大时长
// dp[i & 1][1]:区间 [0, i] 里接受预约请求,并且下标为 i 的这一天接受预约的最大时长
int[][] dp = new int[2][2];
dp[0][0] = 0;
dp[0][1] = nums[0];
for (int i = 1; i < len; i++) {
dp[i & 1][0] = Math.max(dp[(i - 1) & 1][0], dp[(i - 1) & 1][1]);
dp[i & 1][1] = dp[(i - 1) & 1][0] + nums[i];
}
return Math.max(dp[(len - 1) & 1][0], dp[(len - 1) & 1][1]);
}
}
复杂度分析:
- 时间复杂度:\(O(N)\),N 是数组的长度;
- 空间复杂度:\(O(1)\),状态数组的大小为 4,常数空间。
参考代码 6:根据方法二,使用 3 个变量滚动完成计算,将空间优化到常数级别。
在实现上可以在取下标的时候对 3 取模。
Java
class Solution {
public int massage(int[] nums) {
int len = nums.length;
if (len == 0) {
return 0;
}
if (len == 1) {
return nums[0];
}
// dp[i % 3]:区间 [0,i] 里接受预约请求的最大时长
int[] dp = new int[3];
dp[0] = nums[0];
dp[1] = Math.max(nums[0], nums[1]);
for (int i = 2; i < len; i++) {
// 今天在选与不选中,选择一个最优的
dp[i % 3] = Math.max(dp[(i - 1) % 3], dp[(i - 2) % 3] + nums[i]);
}
return dp[(len - 1) % 3];
}
}
复杂度分析:
- 时间复杂度:\(O(N)\),N 是数组的长度;
- 空间复杂度:\(O(1)\),状态数组的大小为 3,常数空间。
优化思路
滚动数组
数组是最常用的数据结构之一,现在我们对数组的下标进行特殊处理,使每一次操作仅保留若干有用信息,新的元素不断循环刷新,看上去数组的空间被滚动地利用,此模型我们称其为滚动数组。其主要达到压缩存储的作用,一般常用在DP类题目中。因为DP题目是一个自下而上的扩展过程,我们常常用到是连续的解,而每次用到的只是解集中的最后几个解,所以以滚动数组形式能大大减少内存开支。
类比:滚动数组可以想象成我们的显示屏,对于有很多的数字来说,每次只显示对我们有用的、有限的数字,用完(显示完)就向后移动一位,显示的数量不变。这样可以节省很多空间。
滚动数组是常见的一种空间优化方式。
应用是递推算法,动态规划(其实现方式是递推)。
举个栗子:
斐波那契数列是递推的一个最好的例子,它的递推公式是:
也就是说,我们只需要知道n-1和n-2项就能知道第n项,第n项跟前面的所有项都没关系。
所以我们完全可以只开一个长度为3的数组来完成这个过程。
普通解法
public int fib(int n) {
if (n <= 1) {
return 1;
}
int[] d = new int[n];
d[0] = 1;
d[1] = 1;
for (int i = 2; i < n; i++){
d[i] = d[i - 1] + d[i - 2];
}
return d[n-1];
}
上述方法使用n个空间(近似认为)
但是注意,上面这个循环d[i]只需要解集中的前2个解d[i-1]和d[i-2],为了节约空间我们可以使用滚动数组的方法
滚动数组模优化
滚动数组模优化做法:这种数组的滚动可以通过模运算实现,需要多大的数组滚动,模就为几。
public int fib(int n) {
if (n <= 1) {
return 1;
}
int d[] = new int[3];
d[0] = 1;
d[1] = 1;
for (int i = 2; i < n; i++) {
d[i % 3] = d[(i - 1) % 3] + d[(i - 2) % 3];
}
// 最后 i 进行运算的值一定是等于 n-1 的,那时候即是我们要求的结果。
return d[(n - 1) % 3];
}
滚动数组运算位优化
我们可以将滚动数组进一步优化,将数组分为运算位和结果位,那么我们就可以使用递推关系式,将运算位中的值进行运算得出结果位,再把结果位中运算的值传递给运算位,继续运算。不停的递推。
递推关系式:y = f(x) = x1 + x2 + ...
- 运算位x:负责将递推关系式中的算式进行运算得出结果位,运算位中的每一个元素都要参与运算。
- 结果位y:负责将结果位中的值传递给运算位,再继续进行运算,不停地递推。
理解:
- 可以理解为数据不动,数组窗口右移
①、②、③、4、5
1、②、③、④、5- 或者窗口不动,数据左移(相对移动)
①、②、③、4、5
②、③、④、5、6
也可以进一步简化成这样,
public int fib(int n) {
if (n <= 1) {
return 1;
}
int d[] = new int[3];
d[0] = 1;
d[1] = 1;
for (int i = 2; i < n; i++) {
// 我们将 d[2] 视为结果位
// 那么 d[0] 和 d[1] 即为运算位
d[2] = d[1] + d[0];
// 计算出 d[2] 后,我们如果要进行下一步计算,则需要使用到此时 d[1] 和 d[2] 的值,来计算出下一个(d[3])
// 所以我们将此时的 d[1] 和 d[2] 的值向前移动到运算位
// 也可以理解为,我们要将运算位的元素更换为 d[1] 和 d[2] 的值
d[0] = d[1];
d[1] = d[2];
}
// 在返回时,我们只需要返回结果位的值即可
return d[2];
}
同理,以0/1背包为例,因为其转移只涉及到了dp[i−1]和dp[i]这两维度的状态,所以可以用滚动数组转移。
滚动数组实际是一种节约空间的办法,时间上没什么优势,比如:
一个DP,平常如果需要1000×1000的空间,其实根据DP的特点,能以2×1000的空间解决问题,并且通过滚动,获得和1000×1000一样的效果。
多次迭代填表
有时候,我们的递推关系式并不明确,并不能直接得出某单元格的值,阶段记录表并不能一次性填好值,得多次迭代填表,需要额外使用一层循环,去考虑不同的情况,不断刷新叠加某一层单元格的值。
可以看到下面的dp只有一维数组,但是额外使用了一层循环,去叠加单元格的值。
for (int c = 0; c < 4; ++c) { // 按照编号升序选择4种硬币
int coin = coins[c];
for (int i = coin; i <= n; ++i) { // 每选择一种就迭代填表
f[i] = (f[i] + f[i - coin]) % MOD;
}
}
结果去重(顺序性)(组合而非排列)
面对一些如同背包九讲这样的问题,我们可能会需要对选择的结果集进行去重,比如说 选择物品1和5 与 选择物品5和1,其实是一个相同的结果,我们应该对其进行去重处理。
而我们去重的方式很简单,那就是制定选择规则,赋予我们的选择顺序性。
我们一般采用升序顺序性,我们按照升序顺序来选择我们的元素,比如说 选择元素1和5,我们就只有这一种选择,没有5和1这种选择,因为我们是按照升序来选择的。
一般这种问题涉及到如何消除排列组合的影响,也就是说,当成一个集合使用。
其实如果我们想要使用这种方法不重复、消除排列组合的影响的话,我们可以使其中的选择元素以某种方式顺序排列,这样就能消除重复的影响了。
动态规划问题一般都带有前缀性,像0/1背包问题,它就是一种双前缀性问题,因为不止它的背包容量具有前缀性,它的物品选择也具有前缀性。
它的目的就是为了消除排列组合问题的顺序性,也就是说,我们构造了物品选择编号的一种前缀性,我们就可以决定物品从小到大选择的一种顺序性来避免他们的排列组合重复。
因为我们的动态规划具有当前性,我们只能操作当前的选择当前的节点,所以这会给我们带来一种排列组合的问题,比如说 1和5还有5和1,这是两种选择了。
如果我们希望把他当成一种选择的话,我们就需要消除这种排列组合带来的问题,我们最好的做法就是将当前性与顺序性相结合,我们的选择按某种递增或递减的顺序来决定,这样就可以消除重复的选择。
这种顺序性,我们可以使用以下两种方法来进行实现。
- 第一种方法很简单,就是使用多重循环,也就是说我们增加一种循环来保证我们的选择的一个顺序性,我们使用外层循环来保证我们选择的编号顺序由小到大 (这种方法也就是我所说的多次迭代填表)。
- 第二种方法也很简单,就是使用二维状态数组,也就是说,我们额外使用一个数组下标来表示我们的选择的编号顺序由小到大。
下面我们拿背包问题来举例子:
有 n 个物品和容量为 V 的背包,第 i 件物品的体积为 c[i],价值为 w[i]。现在的目标是确定要将哪些物体放入背包,以保证在体积 不超过背包容量 的前提下,背包内的 总价值最高?
顺序迭代填表(顺序性)
顺序多次迭代填表,顾名思义,我们的表格不是一次性就填好,而是经过多次迭代修改,慢慢地填好。(简单易懂又好用!)
使用多重循环,也就是说我们增加一种循环来保证我们的选择的一个顺序性,我们使用外层循环来保证我们选择的编号顺序由小到大(这种方法也就是我所说的多次迭代填表)。
其实,原理就是最外层循环固定当前问题,然后匹配不同的子类问题去解决不同的原问题。保证当前问题不会因为排序而重复处理(组合),[1,2]和[2,1]是一种结果。
我们传统方法是,最外层循环固定原问题,然后划分不同的子类问题和不同的当前问题。
原问题 = 子类问题 + 当前问题
- 固定原问题,划分子类问题和当前问题(排列)
- 固定当前问题,匹配不同的子类问题去解决不同的原问题(组合)
先选择1进行填表,再选择5进行迭代填表。。。。
for (int c = 0; c < 4; ++c) { // 按照编号升序选择4种硬币
int coin = coins[c];
for (int i = coin; i <= n; ++i) { // 每选择一种就迭代填表
f[i] = (f[i] + f[i - coin]) % MOD;
}
}
或者
for (int c = 0; c < 4; ++c) { // 按照编号升序选择4种硬币
int coin = coins[c];
for (int i = 0; i <= n; ++i) { // 每选择一种就迭代填表
if (i >= coin) {
f[i] = (f[i] + f[i - coin]) % MOD;
}
}
}
顺序二维数组(顺序性)
使用顺序二维状态数组,也就是说,我们额外使用一个数组下标来表示我们的选择的编号顺序由小到大,这样我们就可以使用顺序性来消除重复性。
状态定义:dp[i][j] 为前 i 个物品(物品顺序性)中,容量恰好为 j 时的最大价值。
for (int i = 1; i < coins.length; i++) {
for (int j = 0; j < dp[i].length; j++) {
// 当前硬币的价值大于总价值时,无法将当前硬币放进去
if (coins[i] > j) {
dp[i][j] = dp[i - 1][j] % 1000000007;
} else {
dp[i][j] = (dp[i - 1][j] + dp[i][j - coins[i]]) % 1000000007;
}
}
}
排列与组合
解题思路:
在LeetCode上有两道题目非常类似,分别是
如果我们把每次可走步数/零钱面额限制为 [1,2],把楼梯高度/总金额限制为 3, 那么这两道题目就可以抽象成 "给定 [1,2],求组合成3的组合数和排列数"。
接下来引出本文的核心两段代码,虽然是 Cpp 写的,但是都是最基本的语法,对于可能看不懂的地方,我加了注释。
C++
class Solution1 {
public:
int change(int amount, vector<int>& coins) {
int dp[amount+1];
memset(dp, 0, sizeof(dp)); //初始化数组为0
dp[0] = 1;
for (int j = 1; j <= amount; j++){ //枚举金额
for (int coin : coins){ //枚举硬币
if (j < coin) continue; // coin不能大于amount
dp[j] += dp[j-coin];
}
}
return dp[amount];
}
};
class Solution2 {
public:
int change(int amount, vector<int>& coins) {
int dp[amount+1];
memset(dp, 0, sizeof(dp)); //初始化数组为0
dp[0] = 1;
for (int coin : coins){ //枚举硬币
for (int j = 1; j <= amount; j++){ //枚举金额
if (j < coin) continue; // coin不能大于amount
dp[j] += dp[j-coin];
}
}
return dp[amount];
}
};
如果不仔细看,你会觉得这两个 Solution 似乎是一模一样的代码,但细心一点你会发现他们在嵌套循环上存在了差异。这个差异使得一个求解结果是 排列数,一个求解结果是 组合数。
因此在不看后面的分析之前,你能分辨出哪个 Solution 是得到排列,哪个 Solution 是得到组合吗?
在揭晓答案之前,让我们先分别用DP的方法解决爬楼梯和 零钱兑换II 的问题。每个解题步骤都按照 DP 三部曲,a.定义子问题,b. 定义状态数组,c. 定义状态转移方程。
70. 爬楼梯
问题描述如下:
假设你正在爬楼梯。需要 n 阶你才能到达楼顶。
每次你可以爬 1 或 2 个台阶。你有多少种不同的方法可以爬到楼顶呢?
这道题目子问题是,problem(i) = sub(i-1) + sub(i-2), 即求解第i阶楼梯等于求解第 i-1 阶楼梯和第 i-2 阶楼梯之和。
状态数组是 DP[i], 状态转移方程是 DP[i] = DP[i-1] = DP[i-2]
那么代码也就可以写出来了。
C++
class Solution {
public:
int climbStairs(int n) {
int DP[n+1];
memset(DP, 0, sizeof(DP));
DP[0] = 1;
DP[1] = 1;
for (int i = 2; i <= n; i++){
DP[i] = DP[i-1] + DP[i-2] ;
}
return DP[n];
}
};
由于每次我们只关注 DP[i-1] 和 DP[i-2] ,所以代码中能把数组替换成 2 个变量,降低空间复杂度,可以认为是 将一维数组降维成点。
如果我们把问题泛化,不再是固定的 1,2,而是任意给定台阶数,例如 1,2,5 呢?
我们只需要修改我们的 DP 方程 DP[i] = DP[i-1] + DP[i-2] + DP[i-5], 也就是DP[i] = DP[i] + DP[i-j] ,j =1,2,5
在原来的基础上,我们的代码可以做这样子修改
C++
class Solution {
public:
int climbStairs(int n) {
int DP[n+1];
memset(DP, 0, sizeof(DP));
DP[0] = 1;
int steps[2] = {1,2};
for (int i = 1; i <= n; i++){
for (int j = 0; j < 2; j++){
int step = steps[j];
if ( i < step ) continue;// 台阶少于跨越的步数
DP[i] = DP[i] + DP[i-step];
}
}
return DP[n];
}
};
后续修改 steps 数组,就实现了原来问题的泛化。
那么这个代码是不是看起来很眼熟呢?我们能不能交换内外的循环呢?也就是下面的代码
C++
for (int j = 0; j < 2; j++){
int step = steps[j];
for (int i = 1; i <= n; i++){
if ( i < step ) continue;// 台阶少于跨越的步数
DP[i] = DP[i] + DP[i-step];
}
}
大家可以尝试思考下这个问题,嵌套循环是否能够调换,调换之后的 DP 方程的含义有没有改变?
零钱兑换II
问题描述如下:
给定不同面额的硬币和一个总金额。写出函数来计算可以凑成总金额的硬币组合数。假设每一种面额的硬币有无限个。
定义子问题: problem(i) = sum( problem(i-j) ), j =1,2,5。含义为凑成总金额i的硬币组合数等于凑成总金额硬币 i-1, i-2, i-5,...的子问题之和。
我们发现这个子问题定义居然和我们之前泛化的爬楼梯问题居然是一样的,那后面的状态数组和状态转移方程也是一样的,所以当前问题的代码可以在之前的泛化爬楼梯问题中进行修改而得。
C++
class Solution {
public:
int change(int amount, vector<int>& coins) {
int dp[amount+1];
memset(dp, 0, sizeof(dp)); //初始化数组为0
dp[0] = 1;
for (int j = 1; j <= amount; j++){ //枚举金额
for (int i = 0; i < coins.size(): i++){
int coin = coins[i]; //枚举硬币
if (j < coin) continue; // coin不能大于amount
dp[j] += dp[j-coin];
}
}
return dp[amount];
}
};
这就是我们之前的 Solution1 代码。
但是当你运行之后,却发现这个代码并不正确,得到的结果比预期的大。究其原因,该代码计算的结果是 排列数,而不是 组合数,也就是代码会把 1,2 和 2,1 当做两种情况。但更加根本的原因是我们子问题定义出现了错误。
正确的 子问题 定义应该是,problem(k,i) = problem(k-1, i) + problem(k, i-k)
即 前 k 个硬币凑齐金额 i 的组合数 等于 前 k-1 个硬币凑齐金额 i 的组合数 加上 在原来 i-k 的基础上使用硬币的组合数。说的更加直白一点,那就是用前 k 的硬币凑齐金额 i ,要分为两种情况开率,一种是没有用前 k-1 个硬币就凑齐了,一种是前面已经凑到了 i-k ,现在就差第 k 个硬币了。
状态数组就是 DP[k][i], 即前 k 个硬币凑齐金额 i 的组合数。
这里不再是一维数组,而是二维数组。第一个维度用于记录当前组合有没有用到硬币k,第二个维度记录现在凑的金额是多少?如果没有第一个维度信息,当我们凑到金额i的时候,我们不知道之前有没有用到硬币k。
因为这是个组合问题,我们不关心硬币使用的顺序,而是关心硬币有没有被用到。是否使用第k个硬币受到之前情况的影响。
状态转移方程如下
bash
if 金额数大于硬币
DP[k][i] = DP[k-1][i] + DP[k][i-k]
else
DP[k][i] = DP[k-1][i]
因此正确代码如下:
C++
class Solution {
public:
int change(int amount, vector<int>& coins) {
int K = coins.size() + 1;
int I = amount + 1;
int DP[K][I];
//初始化数组
for (int k = 0; k < K; k++){
for (int i = 0; i < I; i++){
DP[k][i] = 0;
}
}
//初始化基本状态
for (int k = 0; k < coins.size() + 1; k++){
DP[k][0] = 1;
}
for (int k = 1; k <= coins.size() ; k++){
for (int i = 1; i <= amount; i++){
if ( i >= coins[k-1]) {
DP[k][i] = DP[k][i-coins[k-1]] + DP[k-1][i];
} else{
DP[k][i] = DP[k-1][k];
}
}
}
return DP[coins.size()][amount];
}
};
我们初始化的数组大小为coins.size()+1* (amount+1), 这是因为第一列是硬币为0的基本情况。
此时,交换这里面的循环不会影响最终的结果。也就是
C++
for (int i = 1; i <= amount; i++){
for (int k = 1; k <= coins.size() ; k++){
if ( i >= coins[k-1]) {
DP[k][i] = DP[k][i-coins[k-1]] + DP[k-1][i];
} else{
DP[k][i] = DP[k-1][k];
}
}
}
之前爬楼梯问题中,我们将一维数组降维成点。这里问题能不能也试着降低一个维度,只用一个数组进行表示呢?
这个时候,我们就需要重新定义我们的子问题了。
此时的子问题是,对于硬币从 0 到 k,我们必须使用第k个硬币的时候,当前金额的组合数。
因 此状态数组 DP[i] 表示的是对于第k个硬币能凑的组合数
状态转移方程如下
DP[[i] = DP[i] + DP[i-k]
于是得到我们开头的第二个Solution。
C++
class Solution {
public:
int change(int amount, vector<int>& coins) {
int dp[amount+1];
memset(dp, 0, sizeof(dp)); //初始化数组为0
dp[0] = 1;
for (int coin : coins){ //枚举硬币
for (int i = 1; i <= amount; i++){ //枚举金额
if (i < coin) continue; // coin不能大于amount
dp[i] += dp[i-coin];
}
}
return dp[amount];
}
};
好了,继续之前的问题,这里的内外循环能换吗?
显然不能,因为我们这里定义的子问题是,必须选择第k个硬币时,凑成金额i的方案。如果交换了,我们的子问题就变了,那就是对于金额 i, 我们选择硬币的方案。
同样的,我们回答之前爬楼梯的留下的问题,原循环结构对应的子问题是,对于楼梯数 i, 我们的爬楼梯方案。第二种循环结构则是,固定爬楼梯的顺序,我们爬楼梯的方案。也就是第一种循环下,对于楼梯 3,你可以先 2 再 1,或者先 1 再 2,但是对于第二种循环,只能先 1 再 2,有顺序性,只能记录组合数。
多种结果去重应用实例
面试题 08.11. 硬币
硬币。给定数量不限的硬币,币值为25分、10分、5分和1分,编写代码计算n分有几种表示法。(结果可能会很大,你需要将结果模上1000000007)
示例1:
输入: n = 5
输出:2
解释: 有两种方式可以凑成总金额:
5=5
5=1+1+1+1+1
示例2:
输入: n = 10
输出:4
解释: 有四种方式可以凑成总金额:
10=10
10=5+5
10=5+1+1+1+1+1
10=1+1+1+1+1+1+1+1+1+1
未去重错误答案
class Solution {
public int waysToChange(int n) {
// 动态规划
if (n <= 1) {
return 1;
}
int[] dp = new int[n + 1];
dp[0] = 1;
for (int i = 1; i < dp.length; i++) {
if (i >= 1) {
dp[i] = (dp[i] + dp[i - 1]) % 1000000007;
}
if (i >= 5) {
dp[i] = (dp[i] + dp[i - 5]) % 1000000007;
}
if (i >= 10) {
dp[i] = (dp[i] + dp[i - 10]) % 1000000007;
}
if (i >= 25) {
dp[i] = (dp[i] + dp[i - 25]) % 1000000007;
}
}
return dp[n];
}
}
代码好像没问题,但是我们求6的硬币情况数时,我们观察一下流程:
前面5种情况数:dp[1,5] = [1,1,1,1,2];
coin = 1:
dp[6] += (dp[6 - coin] => dp[5] => 2);
即拿到coin(1)的情况有两种 :
coin(1,1,1,1,1) + coin(1);
coin(5) + coin(1);
coin = 5:
dp[6] += (dp[6 - coin] => dp[1] => 1);
即拿到coin(5)的情况有一种:
coin(1) + coin(5);
但是事实却是 6 的情况只有两种,(1,1,1,1,1,1)和(1,5)。这里是把(1,5)和(5,1)前后顺序不同的情况重复算了 1 次。因此我们应该去考虑硬币顺序带来的影响。
顺序迭代填表
上面的错误方法我们可以知道,我们应该去消除硬币顺序带来的排列组合的影响。
我们规定硬币编号升序,采用循环顺序多次迭代填表。
class Solution {
public int waysToChange(int n) {
// 动态规划
if (n <= 1) {
return 1;
}
int[] dp = new int[n + 1];
dp[0] = 1;
// 使用顺序性来消除排列组合带来的重复性,使我们的结果集选择唯一(按硬币选择从小到大排列)
// 先放 1 进行填表的情况
for (int i = 1; i < dp.length; i++) {
if (i >= 1) {
dp[i] = (dp[i] + dp[i - 1]) % 1000000007;
}
}
// 再放 5 进行填表
for (int i = 1; i < dp.length; i++) {
if (i >= 5) {
dp[i] = (dp[i] + dp[i - 5]) % 1000000007;
}
}
// 再放 10 进行填表
for (int i = 1; i < dp.length; i++) {
if (i >= 10) {
dp[i] = (dp[i] + dp[i - 10]) % 1000000007;
}
}
// 最后放 25 进行填表
for (int i = 1; i < dp.length; i++) {
if (i >= 25) {
dp[i] = (dp[i] + dp[i - 25]) % 1000000007;
}
}
return dp[n];
}
}
整合:
class Solution {
public int waysToChange(int n) {
int[] dp = new int[n + 1];
int[] coins = new int[]{1,5,10,25};
//刚好可以用一个硬币凑成的情况,是一种情况
// while i == coin :
//dp[i] = dp[i - coin] => dp[0]
dp[0] = 1;
/**
* dp方程:dp[i] += dp[i - coin];
*/
for(int coin : coins) {
for(int i = coin; i <= n; i++) {
dp[i] = (dp[i] + dp[i - coin]) % 1000000007;
}
}
return dp[n];
}
}
顺序二维数组
我们使用顺序二维数组,
状态定义:dp[i][v] 为前 i 个硬币中,金额恰好为 v 时的表示法个数。
我们使用这个 i,前 i 个物品,来让我们的结果集升序顺序排列。
前 i 个物品的区间范围,可分为两种情况:
- 第 i 个物品不能放入:
dp[i][j] = dp[i - 1][j] - 第 i 个物品能放入:
dp[i][j] = (dp[i - 1][j] + dp[i][j - coins[i]])
二维数组多次迭代填表:
class Solution {
public int waysToChange(int n) {
int[] coins = {1,5,10,25};
int[][] dp = new int[4][n + 1];
// 初始化
for (int i = 0; i < n + 1; i++) {
dp[0][i] = 1;
}
// 多次迭代填表
for (int i = 1; i < 4; i++) {
for (int j = 0; j < n + 1; j++) {
// dp[i][j]=dp[i-1][j]%1000000007;
// if(j>=coins[i]) dp[i][j]=(dp[i-1][j]+dp[i][j-coins[i]])%1000000007;
// 不放入硬币 i 的情况
dp[i][j] = (dp[i][j] + dp[i-1][j]) % 1000000007;
int coin = coins[i];
// 放入硬币 i 的情况
if (j >= coin) {
dp[i][j] = (dp[i][j] + dp[i][j - coin]) % 1000000007;
}
}
}
return dp[3][n];
}
}
我的:
class Solution {
public int waysToChange(int n) {
// 需要去重,dp为二维数组,一维为前i个币,二维为价值
int[] coins = new int[] {1, 5, 10, 25};
int[][] dp = new int[4][n + 1];
// 初始化数组,初始值
Arrays.fill(dp[0], 1);
for (int i = 1; i < coins.length; i++) {
for (int j = 0; j < dp[i].length; j++) {
// 当前硬币的价值大于总价值时,无法将当前硬币放进去
if (coins[i] > j) {
dp[i][j] = dp[i - 1][j] % 1000000007;
} else {
dp[i][j] = (dp[i - 1][j] + dp[i][j - coins[i]]) % 1000000007;
}
}
}
return dp[3][n];
}
}
实例
剑指 Offer 10- II. 青蛙跳台阶问题
一只青蛙一次可以跳上1级台阶,也可以跳上2级台阶。求该青蛙跳上一个 n 级的台阶总共有多少种跳法。
答案需要取模 1e9+7(1000000007),如计算初始结果为:1000000008,请返回 1。
示例 1:
输入:n = 2
输出:2
示例 2:
输入:n = 7
输出:21
示例 3:
输入:n = 0
输出:1
我的
class Solution {
public int numWays(int n) {
if (n <= 1) {
return 1;
}
int[] dp = new int[n + 1];
dp[0] = 1;
dp[1] = 1;
dp[2] = 2;
for (int i = 3; i < dp.length; i++) {
dp[i] = (dp[i - 1] + dp[i - 2]) % 1000000007;
}
return dp[n];
}
}
超级青蛙跳台阶
一个台阶总共有 n 级,超级青蛙有能力一次跳到 n 阶台阶,也可以一次跳 n-1 阶台阶,也可以跳 n-2 阶台阶……也可以跳 1 阶台阶。
问超级青蛙跳到 n 层台阶有多少种跳法?(n<=50)
例如:
输入台阶数:3
输出种类数:4
解释:4 种跳法分别是(1,1,1),(1,2),(2,1),(3)
答案:
这里我是运用了“数学”来得出式子的,为了告诉大家不要拘泥于程序,数学也是一个很有用的工具。
用 Fib(n) 表示超级青蛙🐸跳上 n 阶台阶的跳法数。
如果按照定义,Fib(0)肯定需要为 0,否则没有意义。我们设定 Fib(0) = 1;n = 0 是特殊情况,通过下面的分析会知道,令 Fib(0) = 1 很有好处。
PS:Fib(0)等于几都不影响我们解题,但是会影响我们下面的分析理解。
-
当 n = 1 时, 只有一种跳法,即 1 阶跳:\(Fib(1) = 1\);
-
当 n = 2 时, 有两种跳的方式,一阶跳和二阶跳:\(Fib(2) = 2\);
到这里为止,和普通跳台阶是一样的。 -
当 n = 3 时,有三种跳的方式,第一次跳出一阶后,对应 Fib(3-1) 种跳法; 第一次跳出二阶后,对应 Fib(3-2)种跳法;第一次跳出三阶后,只有这一种跳法。
- 当 n = 4 时,有四种方式:第一次跳出一阶,对应 Fib(4-1)种跳法;第一次跳出二阶,对应Fib(4-2)种跳法;第一次跳出三阶,对应 Fib(4-3)种跳法;第一次跳出四阶,只有一种跳法。
- 当 n = n 时,共有 n 种跳的方式:
第一次跳出一阶后,后面还有 Fib(n-1)中跳法;
...
...
...
第一次跳出 n 阶后,后面还有 Fib(n-n)中跳法。
通过上述分析,我们就得到了数列通项公式:
因此,有 $$Fib(n-1)=Fib(0)+Fib(1)+Fib(2)+...+Fib(n-2)$$
两式相减得:$$Fib(n)-Fib(n-1) = Fib(n-1)$$ $$Fib(n) = 2Fib(n-1), n >= 3$$
这就是我们需要的递推公式:$$Fib(n) = 2Fib(n-1), n >= 3$$
public class SY1 {
//自底向上的动态规划 超级青蛙 N 阶跳
static long solution(int number) {
//题目保证 number 最大为 50
long[] Counter=new long[51];
Counter[0] = 1;
Counter[1] = 1;
Counter[2] = 2;
int calculatedIndex = 2;
if(number <= calculatedIndex)
return Counter[number];
if(number > 50) //防止下标越界
number = 50;
for(int i = calculatedIndex + 1; i <= number; i++)
Counter[i] = 2 * Counter[i - 1];
calculatedIndex = number;
return Counter[number];
}
public static void main(String[] args) {
Scanner cin = new Scanner(System.in);
System.out.print(solution(cin.nextInt()));
}
}
程序运行结果:

NC311 圆环回原点
圆环上有 10 个点,编号 0~9 。从 0 出发,每次可以顺时针或逆时针走一格,请问一共走且仅走 n 步回到原点的方法有多少种。
数据范围:\(1 \le n \le 10^4\),由于答案可能会非常大,所以请对答案对 \(10^9+7\) 取模
示例1
输入:3
返回值:0
说明:无论如何也不可能走 3 步回到原点
示例2
输入:2
返回值:2
说明:可能的方案有 0->1->0, 0->9->0
答案
走n步到0的方案数=走n-1步到1的方案数+走n-1步到9的方案数。
这里需要注意,Java中的%代表取余运算,而非取模运算,对正数来说取模和取余是相同的结果,但是对负数来说,取模会得到正数,取余会得到负数。
-1 % 10 == -1
所以我们需要对负数加上模,变成正数,才能正常取模。
public class Solution {
public int circle (int n) {
// write code here
int mod = 1000000007;
// dp[i][j]:走i步到数字j的方案数
int[][] dp = new int[n + 1][10];
dp[0][0] = 1;
for (int i = 1; i <= n; i++) {
for (int j = 0; j < 10; j++) {
// 对负数的取模运算:(j - 1 + 10) % 10
// 子类问题为i - 1,所以我们的最小问题初始化得初始化i = 0,不然会越界
dp[i][j] = (dp[i - 1][(j + 1) % 10] + dp[i - 1][(j - 1 + 10) % 10]) % mod;
}
}
return dp[n][0];
}
}
62. 不同路径
一个机器人位于一个 m x n 网格的左上角(起始点在下图中标记为“Start”)。机器人试图达到网格的右下角(在下图中标记为“Finish”)。
- 机器人每次只能向下或者向右移动一步。
问总共有多少条不同的路径?

例如,上图是一个 3 x 7 的网格。有多少可能的路径?
这里为了让大家能明白历史记录表的作用,我举了一道二维表的题。
明确数组的含义
由题可知,我们的目的是从左上角到右下角一共有多少种路径。
那我们就定义 dp[i][j]的含义为:当机器人从左上角走到 (i, j) 这个位置时,一共有 dp[i][j] 种路径。
那么 dp[m-1][n-1] 就是我们要找的答案了。
制作阶段记录表
由于明确了数组的含义,我们可以知道这其实是一张二维表。
| 0 | 1 | 2 | … | m | |
|---|---|---|---|---|---|
| 0 | |||||
| 1 | |||||
| 2 | |||||
| … | |||||
| n |
寻找数组初始值
这时,看题目的要求限制:机器人每次只能向下或者向右移动一步。
所以我们从左上角开始,向下的那一列(即 第一列) 和 向右的那一行(即 第一行)上面所有的节点,都只有一条路径到那。
因此,初始值如下:
- dp[0][0…n-1] = 1; // 第一行,机器人只能一直往右走
- dp[0…m-1][0] = 1; // 第一列,机器人只能一直往下走
历史记录表:
| 0 | 1 | 2 | … | m | |
|---|---|---|---|---|---|
| 0 | 1 | 1 | 1 | … | 1 |
| 1 | 1 | ||||
| 2 | 1 | ||||
| … | … | ||||
| n | 1 |
找出递推关系式
这是动态规划四步走中最难的一步,我们从 dp[i][j] = ? 这一数学公式开始推想。
由于机器人只能向下走或者向右走,所以有两种方式到达(i, j):
- 一种是从 (i-1, j) 这个位置走一步到达
- 一种是从 (i, j-1) 这个位置走一步到达
所以我们可以知道,到达 (i, j) 的所有路径为这两种方式的和,可以得出递推关系式:
dp[i][j] = dp[i-1, j] + dp[i, j-1]
历史记录表:
| 0 | 1 | 2 | … | m | |
|---|---|---|---|---|---|
| 0 | 1 | 1 | 1 | … | 1 |
| 1 | 1 | 2 | 3 | ||
| 2 | 1 | 3 | 6 | ||
| … | … | ||||
| n | 1 |
我们可以利用此递推关系式,写出程序填完整个表项。
在下面代码中,我选择的是逐行填入表格。
答案:
public static int uniquePaths(int m, int n) {
if (m <= 0 || n <= 0) {
return 0;
}
int[][] dp = new int[m][n]; // 地图
// 初始化
for(int i = 0; i < m; i++) {
dp[i][0] = 1;
}
for(int i = 0; i < n; i++) {
dp[0][i] = 1;
}
// 递推 dp[m-1][n-1]
for (int i = 1; i < m; i++) { // 逐行填写空表格
for (int j = 1; j < n; j++) {
dp[i][j] = dp[i-1][j] + dp[i][j-1];
}
}
return dp[m-1][n-1];
}
01背包
问题描述
有n个物品,它们有各自的体积和价值,现有给定容量的背包,如何让背包里装入的物品具有最大的价值总和?
为方便讲解和理解,下面讲述的例子均先用具体的数字代入,即:eg:number=4,capacity=8
| i(物品编号) | 1 | 2 | 3 | 4 |
|---|---|---|---|---|
| w(体积) | 2 | 3 | 4 | 5 |
| v(价值) | 3 | 4 | 5 | 6 |
答案:
做到这里,大家应该对动态规划很熟悉了,那么我们就加快速度。
1. 明确数组含义
一眼望去,我们这里的状态需要三个变量来存储:
- 当前商品编号
- 当前背包容量
- 当前背包总价值
所以我们采用二维数组的方法来存取。
2. 制作阶段记录表
状态:v[i][j] 代表当前背包容量 j,前 i 个物品最佳组合对应的价值
- 当前商品编号,前 i 个物品,前 i 个阶段:一维下标 i,代表物品阶段,随着物品越来越多,可选择的越来越多
- 当前背包容量:二维下标 j,代表背包容量阶段,随着背包慢慢变大,能装的越来越多
- 当前背包总价值:数值状态 v[i][j]
3. 寻找数组初始值
V(0,j) = V(i,0) = 0;
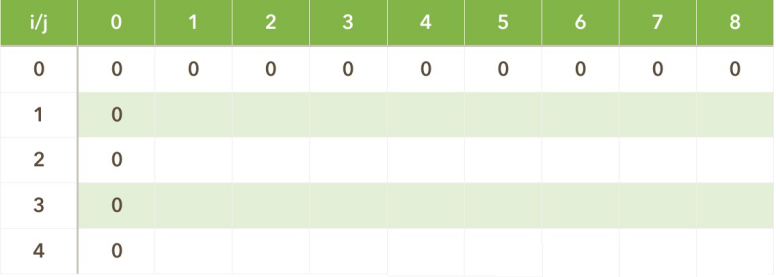
4. 找出递推关系式
寻找递推关系式,面对当前商品有两种可能性:
- 包的容量比该商品体积小,装不下,此时的价值与前 i-1 个的价值是一样的,即V(i, j)=V(i - 1, j);
- 还有足够的容量可以装该商品,但装了也不一定达到当前最优价值,所以在装与不装之间选择最优的一个,即V(i, j)= max{V(i - 1, j), V(i - 1, j - w(i)) + v(i)}。
其中V(i-1, j)表示不装,V(i-1, j - w(i)) + v(i) 表示装了第i个商品,背包容量减少 w(i),但价值增加了 v(i);
由此可以得出递推关系式:
- j < w(i) V(i, j)=V(i - 1, j)
- j >= w(i) V(i, j)=max
可以这么理解,如果要到达V(i,j)这一个状态有几种方式?
肯定是两种,第一种是第i件商品没有装进去,第二种是第i件商品装进去了。
没有装进去很好理解,就是V(i - 1, j);
装进去了怎么理解呢?如果装进去第 i 件商品,那么装入之前是什么状态,肯定是V(i - 1, j - w(i))。由于最优性原理(上文讲到),V(i - 1, j - w(i))就是前面决策造成的一种状态,后面的决策就要构成最优策略。两种情况进行比较,得出最优。
然后一行一行的填表:
如,i=1,j=1,w(1)=2,v(1)=3,有j<w(1),故V(1,1)=V(1-1,1)=0;
又如i=1,j=2,w(1)=2,v(1)=3,有j=w(1),故V(1,2)=max{ V(1-1,2),V(1-1,2-w(1))+v(1) }=max{0,0+3}=3;
如此下去,填到最后一个,i=4,j=8,w(4)=5,v(4)=6,有j>w(4),故V(4,8)=max{ V(4-1,8),V(4-1,8-w(4))+v(4) }=max{9,4+6}=10……
所以填完表如下图:

表格填完可知,最优解即是V(number, capacity) = V(4, 8) = 10。
Java
public class LeetCode {
public static void main(String[] args) {
int[] w = { 2 , 3 , 4 , 5 }; //商品的体积2、3、4、5
int[] v = { 3 , 4 , 5 , 6 }; //商品的价值3、4、5、6
Solution solution = new Solution();
System.out.println(solution.bag(8, w, v));
}
}
class Solution {
public int bag(int weight, int[] w, int[] v) {
// 3个参数,二维数组
// bag[i][j] i表示前i个物品最佳组合,j表示当前背包容量
// bag[i][j] 当前背包容量 j,前 i 个物品最佳组合对应的价值
int[][] bag = new int[w.length][weight + 1];
// 设置初始值入口
// 背包容量为0时,价值为0
for (int i = 0; i < bag.length; i++) {
bag[i][0] = 0;
}
// 物品编号为0时,随着背包容量变大就慢慢能装进去了
for (int i = 0; i < bag[0].length; i++) {
if (i < w[0]) {
bag[0][i] = 0;
} else {
bag[0][i] = v[0];
}
}
// 递推公式 bag[i][j]
// 放入第i个物品:bag[i][j] = max(bag[i - 1][j], bag[i][j - w[i]] + v[i])
for (int i = 1; i < bag.length; i++) {
for (int j = 1; j < bag[i].length; j++) {
if (j >= w[i]) {
// 还有足够的容量可以装该商品,但装了也不一定达到当前最优价值,所以在装与不装之间选择最优的一个,即V(i,j)=max{V(i-1,j),V(i-1,j-w(i))+v(i)}。
// 没有装进去很好理解,就是V(i-1,j);装进去了怎么理解呢?如果装进去第i件商品,那么装入之前是什么状态,肯定是V(i-1,j-w(i))。
bag[i][j] = Math.max(bag[i - 1][j], bag[i - 1][j - w[i]] + v[i]);
} else {
// 包的容量比该商品体积小,装不下,此时的价值与前i-1个的价值是一样的,即V(i,j)=V(i-1,j);
bag[i][j] = bag[i - 1][j];
}
}
}
for (int i = 0; i < bag.length; i++) {
for (int j = 0; j < bag[i].length; j++) {
System.out.print(bag[i][j] + " ");
}
System.out.println();
}
return bag[bag.length - 1][bag[0].length - 1];
}
}
答案
为了和之前的动态规划图可以进行对比,尽管只有4个商品,但是我们创建的数组元素由5个。
#include<iostream>
using namespace std;
#include <algorithm>
int main()
{
int w[5] = { 0 , 2 , 3 , 4 , 5 }; //商品的体积2、3、4、5
int v[5] = { 0 , 3 , 4 , 5 , 6 }; //商品的价值3、4、5、6
int bagV = 8; //背包大小
int dp[5][9] = { { 0 } }; //动态规划表
for (int i = 1; i <= 4; i++) {
for (int j = 1; j <= bagV; j++) {
if (j < w[i])
dp[i][j] = dp[i - 1][j];
else
dp[i][j] = max(dp[i - 1][j], dp[i - 1][j - w[i]] + v[i]);
}
}
//动态规划表的输出
for (int i = 0; i < 5; i++) {
for (int j = 0; j < 9; j++) {
cout << dp[i][j] << ' ';
}
cout << endl;
}
return 0;
}
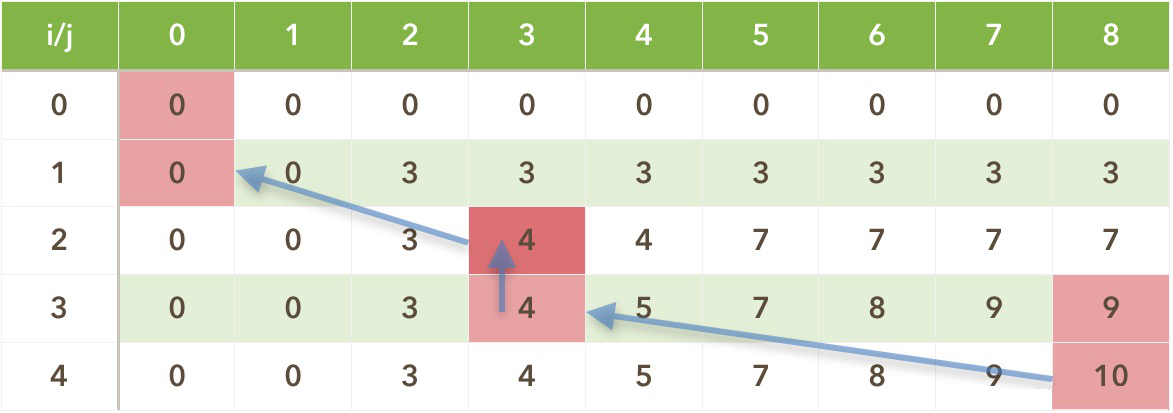
背包问题最优解回溯
通过上面的方法可以求出背包问题的最优解,但还不知道这个最优解由哪些商品组成,故要根据最优解回溯找出解的组成,根据填表的原理可以有如下的寻解方式:
- V(i,j)=V(i-1,j)时,说明没有选择第i 个商品,则回到V(i-1,j);
- V(i,j)=V(i-1,j-w(i))+v(i)时,说明装了第i个商品,该商品是最优解组成的一部分,随后我们得回到装该商品之前,即回到V(i-1,j-w(i));
- 一直遍历到i=0结束为止,所有解的组成都会找到。
就拿上面的例子来说吧:
- 最优解为V(4,8)=10,而V(4,8)!=V(3,8)却有V(4,8)=V(3,8-w(4))+v(4)=V(3,3)+6=4+6=10,所以第4件商品被选中,并且回到V(3,8-w(4))=V(3,3);
- 有V(3,3)=V(2,3)=4,所以第3件商品没被选择,回到V(2,3);
- 而V(2,3)!=V(1,3)却有V(2,3)=V(1,3-w(2))+v(2)=V(1,0)+4=0+4=4,所以第2件商品被选中,并且回到V(1,3-w(2))=V(1,0);
- 有V(1,0)=V(0,0)=0,所以第1件商品没被选择。
代码实现
背包问题最终版详细代码实现如下:
#include<iostream>
using namespace std;
#include <algorithm>
int w[5] = { 0 , 2 , 3 , 4 , 5 }; //商品的体积2、3、4、5
int v[5] = { 0 , 3 , 4 , 5 , 6 }; //商品的价值3、4、5、6
int bagV = 8; //背包大小
int dp[5][9] = { { 0 } }; //动态规划表
int item[5]; //最优解情况
void findMax() { //动态规划
for (int i = 1; i <= 4; i++) {
for (int j = 1; j <= bagV; j++) {
if (j < w[i])
dp[i][j] = dp[i - 1][j];
else
dp[i][j] = max(dp[i - 1][j], dp[i - 1][j - w[i]] + v[i]);
}
}
}
void findWhat(int i, int j) { //最优解情况
if (i >= 0) {
if (dp[i][j] == dp[i - 1][j]) {
item[i] = 0;
findWhat(i - 1, j);
}
else if (j - w[i] >= 0 && dp[i][j] == dp[i - 1][j - w[i]] + v[i]) {
item[i] = 1;
findWhat(i - 1, j - w[i]);
}
}
}
void print() {
for (int i = 0; i < 5; i++) { //动态规划表输出
for (int j = 0; j < 9; j++) {
cout << dp[i][j] << ' ';
}
cout << endl;
}
cout << endl;
for (int i = 0; i < 5; i++) //最优解输出
cout << item[i] << ' ';
cout << endl;
}
int main()
{
findMax();
findWhat(4, 8);
print();
return 0;
}
当然,01背包不止动态规划这一种解决方法,还有分支界限法等,分支界限法可以查看分支界限三步走
注意,这里不能使用滚动数组,因为我们的代码bag[i][j] = Math.max(bag[i - 1][j], bag[i - 1][j - w[i]] + v[i]);有较大的跳跃性。
KMP算法
没想到吧!!动态规划算法还能应用到KMP算法之中!
巧了,我也没想到,不过拜读了大佬的作品之后,我悟了。
那么,我们试试看用自己的方法做一下!
有限状态机
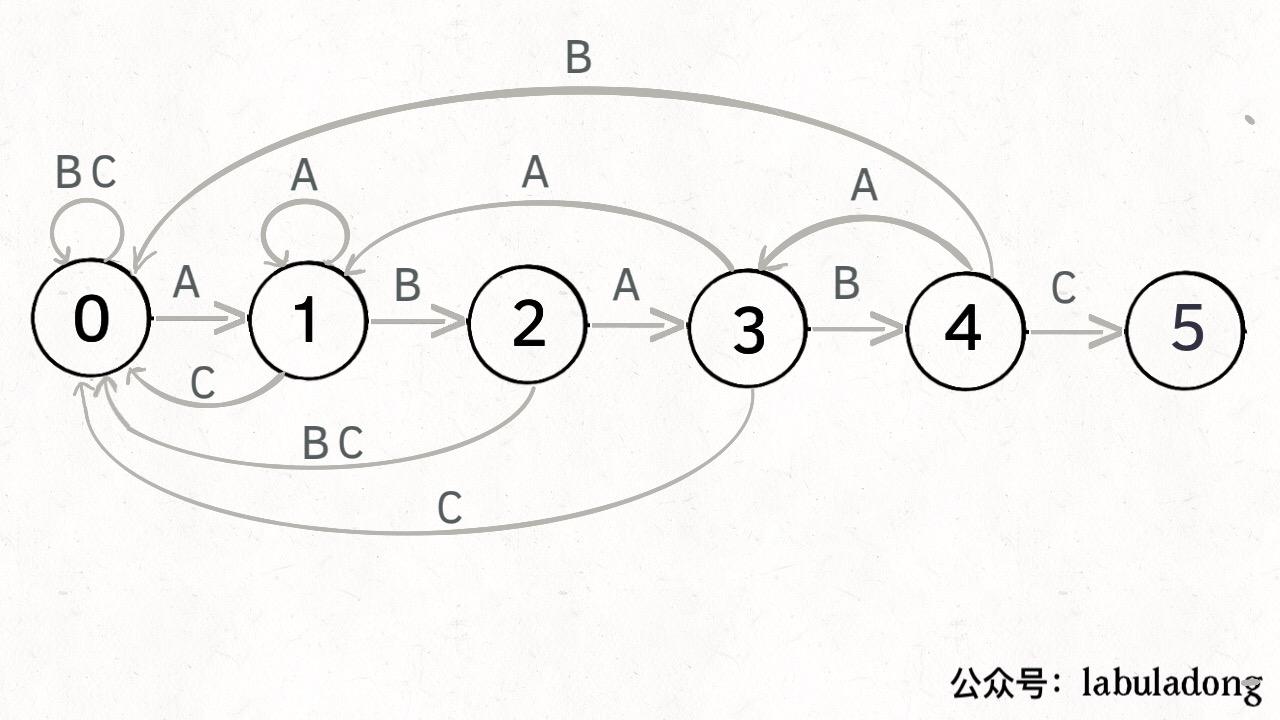
1. 明确数组的含义
我们的状态需要三个变量来存储,所以我们采用二维数组dp[i][j] = k;:
- 当前状态编号i,即 圆圈
- 当前状态遇到的字符j,即 箭头
- 当前状态遇到某一字符后跳转到什么状态编号k,即 箭头所指向的状态编号
2. 制作阶段记录表
i取决于状态个数,即 模式串pat的字符个数+1
这里以"ABABC"举例
| 当前状态编号i\当前状态遇到的字符j | A | B | C | ... | Z |
|---|---|---|---|---|---|
| 0 | k = ? | ||||
| 1 | |||||
| 2 | |||||
| 3 | |||||
| 4 | |||||
| 5 |
3. 寻找数组初始值
只有遇到匹配的字符我们的状态 0 才能前进为状态 1,遇到其它字符的话还是停留在状态 0。
| 当前状态编号i\当前状态遇到的字符j | A | B | C | ... | Z |
|---|---|---|---|---|---|
| 0 | k = 1 | 0 | 0 | ... | 0 |
| 1 | |||||
| 2 | |||||
| 3 | |||||
| 4 | |||||
| 5 |
4. 找出递推关系式
这一步是最难的,我们怎么递推呢?
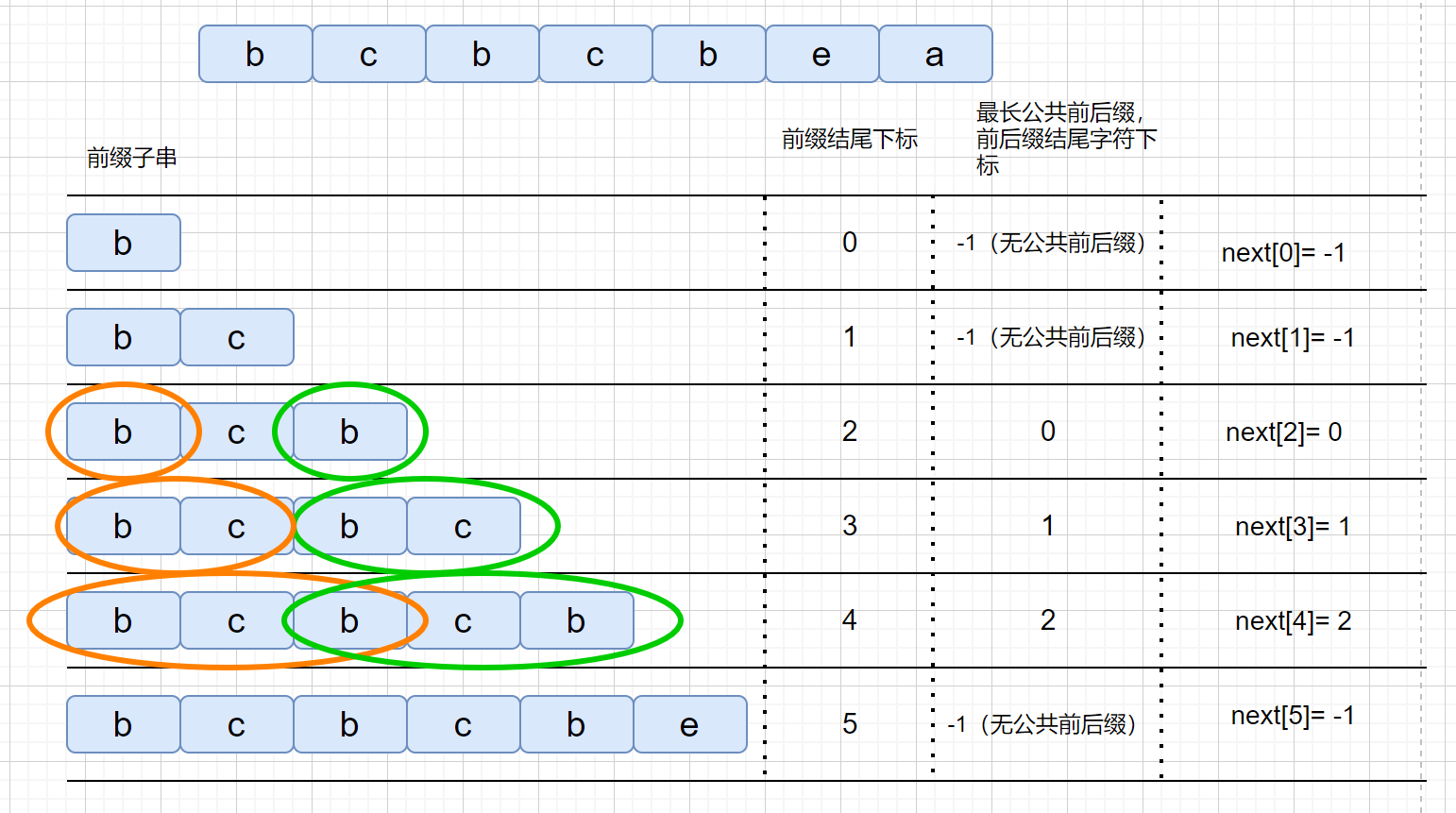
KMP算法的精髓就是,前缀覆盖后缀,完全重合以省去遍历过程。
我们可以把状态的操作分为前进和后退两个部分
- 前进:只有遇到匹配的字符才能前进,即
c == pat.charAt(j)时我们才能dp[j][c] = j + 1; - 后退:如果遇到的字符不匹配,那我们就得倒退回最长公共前后缀的前缀的末尾字符下标 影子状态X,即
dp[j][c] = dp[X][c];
所谓影子状态,就是和当前状态具有相同前缀的状态。就是用来方便回溯的,作为当前状态j的一种“特殊的”前驱结点,即 X -> j
这个倒退过程,其实就是后缀覆盖前缀的过程。
箭头A (状态X) 箭头B (状态X+1):dp[X][B]就代表有AB前缀的状态
(状态X) 箭头B:这种组合是一体的,谁也离不开谁。
那么我们的 X 从哪里来呢?
- X 的初始值设置为 0;
- 更新 X 的操作:状态X 更新为状态X 面对状态 j 对应的字符pat.charAt(j)时状态变化的情况,即 更新为下一个状态的影子状态
X = dp[X][pat.charAt(j)];
详情可以看看下面代码的注释,在这里就不过多解释了。
public class KMP {
private int[][] dp;
private String pat;
public KMP(String pat) {
this.pat = pat;
int M = pat.length();
// dp[状态][字符] = 下个状态
dp = new int[M][256];
// base case
dp[0][pat.charAt(0)] = 1;
// 影子状态 X 初始为 0,所谓影子状态,就是和当前状态具有相同的前缀。感觉就是用来方便回溯的
// 你也可以就把它理解为一种满足相同前缀的“不一样”的前驱结指针
int X = 0;
// 当前状态 j 从 1 开始
for (int j = 1; j < M; j++) {
for (int c = 0; c < 256; c++) {
if (pat.charAt(j) == c)
dp[j][c] = j + 1; // 前进
else
dp[j][c] = dp[X][c]; // 后退,状态j 遇到c,不相等,不知道怎么处理,按拥有相同前缀的影子X遇到c时候处理
}
// 更新影子状态,这里更新影子状态是为了下一个状态做铺垫,即 更新为下一个状态的影子
// 其实,也就是相当于当前状态的前驱指针后移,即 pre++
X = dp[X][pat.charAt(j)]; // 影子状态 影子X遇到当前状态j的字符,返回与当前状态具有相同前缀的状态!!!如影随形
// 最长前后缀的前缀下标,方便j找不到相等情况时,后缀覆盖前缀
// 为了防止大家迷糊这里我标明一下进入下一个状态
// j++;
}
}
public int search(String txt) {
int M = pat.length();
int N = txt.length();
// pat 的初始态为 0
int j = 0;
for (int i = 0; i < N; i++) {
// 计算 pat 的下一个状态
j = dp[j][txt.charAt(i)];
// 到达终止态,返回结果
if (j == M) return i - M + 1;
}
// 没到达终止态,匹配失败
return -1;
}
}
剑指 Offer 63. 股票的最大利润
假设把某股票的价格按照时间先后顺序存储在数组中,请问买卖该股票一次可能获得的最大利润是多少?
示例 1:
输入: [7,1,5,3,6,4]
输出: 5
解释: 在第 2 天(股票价格 = 1)的时候买入,在第 5 天(股票价格 = 6)的时候卖出,最大利润 = 6-1 = 5 。
注意利润不能是 7-1 = 6, 因为卖出价格需要大于买入价格。
示例 2:
输入: [7,6,4,3,1]
输出: 0
解释: 在这种情况下, 没有交易完成, 所以最大利润为 0。
动态规划答案
class Solution {
public int maxProfit(int[] prices) {
// 连续多阶段决策
// 动态规划
int len = prices.length;
// 特殊判断
if (len < 2) {
return 0;
}
int[][] dp = new int[len][2];
// dp[i][0] 下标为 i 这天结束的时候,不持股,手上拥有的现金数
// dp[i][1] 下标为 i 这天结束的时候,持股,手上拥有的现金数
// 初始化:不持股显然为 0,持股就需要减去第 1 天(下标为 0)的股价
dp[0][0] = 0;
dp[0][1] = -prices[0];
// 从第 2 天开始遍历
for (int i = 1; i < len; i++) {
// 不持股
dp[i][0] = Math.max(dp[i - 1][0], dp[i - 1][1] + prices[i]);
// 持股
dp[i][1] = Math.max(dp[i - 1][1], -prices[i]);
}
return dp[len - 1][0];
}
}
一次遍历答案
// 试试一次遍历
class Solution {
public int maxProfit(int[] prices) {
// 我们需要一个变量min来存储以往的最低价格,用 当天价格 - min,就能获得当天的利润,取最大即可
int min = Integer.MAX_VALUE; // 历史最低价
int res = 0; // 最大利润
for (int i = 0; i < prices.length; i++) {
min = Math.min(min, prices[i]); // 取最小历史价格
res = Math.max(res, prices[i] - min); // 取最大利润
}
return res;
}
}
121. 买卖股票的最佳时机
给定一个数组 prices ,它的第 i 个元素 prices[i] 表示一支给定股票第 i 天的价格。
你只能选择 某一天 买入这只股票,并选择在 未来的某一个不同的日子 卖出该股票。设计一个算法来计算你所能获取的最大利润。
返回你可以从这笔交易中获取的最大利润。如果你不能获取任何利润,返回 0 。
示例 1:
输入:[7,1,5,3,6,4]
输出:5
解释:在第 2 天(股票价格 = 1)的时候买入,在第 5 天(股票价格 = 6)的时候卖出,最大利润 = 6-1 = 5 。
注意利润不能是 7-1 = 6, 因为卖出价格需要大于买入价格;同时,你不能在买入前卖出股票。
示例 2:
输入:prices = [7,6,4,3,1]
输出:0
解释:在这种情况下, 没有交易完成, 所以最大利润为 0。
答案
一次遍历
算法
假设给定的数组为:[7, 1, 5, 3, 6, 4]
如果我们在图表上绘制给定数组中的数字,我们将会得到:
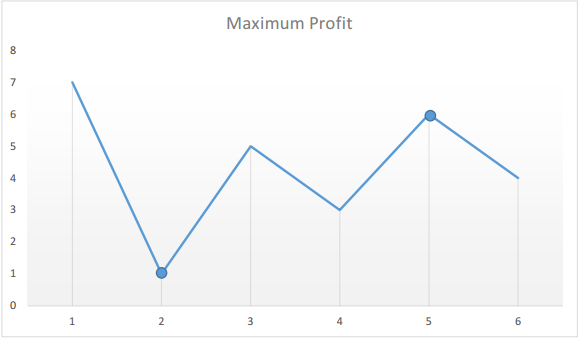
我们来假设自己来购买股票。随着时间的推移,每天我们都可以选择出售股票与否。那么,假设在第 i 天,如果我们要在今天卖股票,那么我们能赚多少钱呢?
显然,如果我们真的在买卖股票,我们肯定会想:如果我是在历史最低点买的股票就好了!太好了,在题目中,我们只要用一个变量记录一个历史最低价格 minprice,我们就可以假设自己的股票是在那天买的。那么我们在第 i 天卖出股票能得到的利润就是 prices[i] - minprice。
因此,我们只需要遍历价格数组一遍,记录历史最低点,然后在每一天考虑这么一个问题:如果我是在历史最低点买进的,那么我今天卖出能赚多少钱?当考虑完所有天数之时,我们就得到了最好的答案。
public class Solution {
public int maxProfit(int prices[]) {
int minprice = Integer.MAX_VALUE;
int maxprofit = 0;
for (int i = 0; i < prices.length; i++) {
if (prices[i] < minprice) {
minprice = prices[i];
} else if (prices[i] - minprice > maxprofit) {
maxprofit = prices[i] - minprice;
}
}
return maxprofit;
}
}
复杂度分析
- 时间复杂度:O(n),只需要遍历一次。
- 空间复杂度:O(1),只使用了常数个变量。
我的
class Solution {
public int maxProfit(int[] prices) {
int min = Integer.MAX_VALUE, res = 0;
for (int price : prices) {
min = Math.min(price, min);
res = Math.max(res, price - min);
}
return res;
}
}
122. 买卖股票的最佳时机 II
给定一个数组,它的第 i 个元素是一支给定股票第 i 天的价格。
设计一个算法来计算你所能获取的最大利润。你可以尽可能地完成更多的交易(多次买卖一支股票)。
注意:你不能同时参与多笔交易(你必须在再次购买前出售掉之前的股票)。
示例 1:
输入: [7,1,5,3,6,4]
输出: 7
解释: 在第 2 天(股票价格 = 1)的时候买入,在第 3 天(股票价格 = 5)的时候卖出, 这笔交易所能获得利润 = 5-1 = 4 。
随后,在第 4 天(股票价格 = 3)的时候买入,在第 5 天(股票价格 = 6)的时候卖出, 这笔交易所能获得利润 = 6-3 = 3 。
示例 2:
输入: [1,2,3,4,5]
输出: 4
解释: 在第 1 天(股票价格 = 1)的时候买入,在第 5 天 (股票价格 = 5)的时候卖出, 这笔交易所能获得利润 = 5-1 = 4 。
注意你不能在第 1 天和第 2 天接连购买股票,之后再将它们卖出。
因为这样属于同时参与了多笔交易,你必须在再次购买前出售掉之前的股票。
示例 3:
输入: [7,6,4,3,1]
输出: 0
解释: 在这种情况下, 没有交易完成, 所以最大利润为 0。
答案
与Ⅰ不同,这题不限制买卖次数,Ⅰ只能买卖一次。
需要设置一个二维矩阵表示状态。
第 1 步:定义状态
状态 dp[i][j] 定义如下:
dp[i][j] 表示到下标为 i 的这一天,持股状态为 j 时,我们手上拥有的最大现金数。
注意:限定持股状态为 j 是为了方便推导状态转移方程,这样的做法满足 无后效性。
其中:
- 第一维 i 表示下标为 i 的那一天( 具有前缀性质,即 考虑了之前天数的交易 );
- 第二维 j 表示下标为 i 的那一天是持有股票,还是持有现金。这里 0 表示持有现金(cash),1 表示持有股票(stock)。
第 2 步:思考状态转移方程
状态从持有现金(cash)开始,到最后一天我们关心的状态依然是持有现金(cash);
每一天状态可以转移,也可以不动。状态转移用下图表示:

(状态转移方程写在代码中)
说明:
- 由于不限制交易次数,除了最后一天,每一天的状态可能不变化,也可能转移;
- 写代码的时候,可以不用对最后一天单独处理,输出最后一天,状态为 0 的时候的值即可。
第 3 步:确定初始值
起始的时候:
- 如果什么都不做,dp[0][0] = 0;
- 如果持有股票,当前拥有的现金数是当天股价的相反数,即 dp[0][1] = -prices[i];
第 4 步:确定输出值
终止的时候,上面也分析了,输出 dp[len - 1][0],因为一定有 dp[len - 1][0] > dp[len - 1][1]。
class Solution {
public int maxProfit(int[] prices) {
int n = prices.length;
int[][] dp = new int[n][2];
dp[0][0] = 0;
dp[0][1] = -prices[0];
for (int i = 1; i < n; ++i) {
dp[i][0] = Math.max(dp[i - 1][0], dp[i - 1][1] + prices[i]);
dp[i][1] = Math.max(dp[i - 1][1], dp[i - 1][0] - prices[i]);
}
return dp[n - 1][0];
}
}
其他方法:
// 上面的代码可以是可以,但是太臃肿了,我们改进一下
class Solution {
// 其实整个题意就是,给你一个折线图,求所有上升折线的总上升量
public int maxProfit(int[] prices) {
// 利润
int sum = 0;
for (int i = 0; i + 1 < prices.length; i++) {
int up = prices[i + 1] - prices[i]; // 上升量
if (up > 0) { // 如果上升量大于0,那就加上
sum += up;
}
}
return sum;
}
}
123. 买卖股票的最佳时机 III
给定一个数组,它的第 i 个元素是一支给定的股票在第 i 天的价格。
设计一个算法来计算你所能获取的最大利润。你最多可以完成 两笔 交易。
注意:你不能同时参与多笔交易(你必须在再次购买前出售掉之前的股票)。
示例 1:
输入:prices = [3,3,5,0,0,3,1,4]
输出:6
解释:在第 4 天(股票价格 = 0)的时候买入,在第 6 天(股票价格 = 3)的时候卖出,这笔交易所能获得利润 = 3-0 = 3 。
随后,在第 7 天(股票价格 = 1)的时候买入,在第 8 天 (股票价格 = 4)的时候卖出,这笔交易所能获得利润 = 4-1 = 3 。
示例 2:
输入:prices = [1,2,3,4,5]
输出:4
解释:在第 1 天(股票价格 = 1)的时候买入,在第 5 天 (股票价格 = 5)的时候卖出, 这笔交易所能获得利润 = 5-1 = 4 。
注意你不能在第 1 天和第 2 天接连购买股票,之后再将它们卖出。
因为这样属于同时参与了多笔交易,你必须在再次购买前出售掉之前的股票。
示例 3:
输入:prices = [7,6,4,3,1]
输出:0
解释:在这个情况下, 没有交易完成, 所以最大利润为 0。
示例 4:
输入:prices = [1]
输出:0
答案
一天结束时,可能有持股、可能未持股、可能卖出过1次、可能卖出过2次、也可能未卖出过
所以定义状态转移数组dp[天数][当前是否持股][卖出的次数]
具体一天结束时的6种状态:
- 未持股,未卖出过股票:说明从未进行过买卖,利润为0
dp[i][0][0]=0 - 未持股,卖出过1次股票:可能是今天卖出,也可能是之前卖的(昨天也未持股且卖出过)
dp[i][0][1]=max(dp[i-1][1][0]+prices[i],dp[i-1][0][1]) - 未持股,卖出过2次股票:可能是今天卖出,也可能是之前卖的(昨天也未持股且卖出过)
dp[i][0][2]=max(dp[i-1][1][1]+prices[i],dp[i-1][0][2]) - 持股,未卖出过股票:可能是今天买的,也可能是之前买的(昨天也持股)
dp[i][1][0]=max(dp[i-1][0][0]-prices[i],dp[i-1][1][0]) - 持股,卖出过1次股票:可能是今天买的,也可能是之前买的(昨天也持股)
dp[i][1][1]=max(dp[i-1][0][1]-prices[i],dp[i-1][1][1]) - 持股,卖出过2次股票:最多交易2次,这种情况不存在
dp[i][1][2]=float('-inf')
根据这些状态即可轻松写出代码
技巧:因为最小值再减去1就是最大值(越界了)
Integer.MIN_VALUE-1=Integer.MAX_VALUE,所以采用int MIN_VALUE = Integer.MIN_VALUE / 2;
class Solution {
public int maxProfit(int[] prices) {
if (prices == null || prices.length <= 1) return 0;
// 0. 利润
// 1. 前i天
// 2. 是否持股
// 3. 交易次数
int[][][] dp = new int[prices.length][2][3];
// 因为最小值再减去1就是最大值Integer.MIN_VALUE-1=Integer.MAX_VALUE
int MIN_VALUE = Integer.MIN_VALUE / 2;
// 初始化
dp[0][0][0] = 0;//第一天休息
dp[0][1][0] = -prices[0];//买股票
dp[0][0][1] = dp[0][1][1] = MIN_VALUE;//不可能
dp[0][0][2] = dp[0][1][2] = MIN_VALUE;//不可能
for (int i = 1; i < prices.length; i++) {
dp[i][0][0] = 0;
dp[i][0][1] = Math.max(dp[i - 1][1][0] + prices[i], dp[i - 1][0][1]);
dp[i][0][2] = Math.max(dp[i - 1][1][1] + prices[i], dp[i - 1][0][2]);
dp[i][1][0] = Math.max(dp[i - 1][0][0] - prices[i], dp[i - 1][1][0]);
dp[i][1][1] = Math.max(dp[i - 1][0][1] - prices[i], dp[i - 1][1][1]);
dp[i][1][2] = MIN_VALUE;
}
return Math.max(0, Math.max(dp[prices.length - 1][0][1], dp[prices.length - 1][0][2]));
}
}
188. 买卖股票的最佳时机 IV
给定一个整数数组 prices ,它的第 i 个元素 prices[i] 是一支给定的股票在第 i 天的价格。
设计一个算法来计算你所能获取的最大利润。你最多可以完成 k 笔交易。
注意:你不能同时参与多笔交易(你必须在再次购买前出售掉之前的股票)。
示例 1:
输入:k = 2, prices = [2,4,1]
输出:2
解释:在第 1 天 (股票价格 = 2) 的时候买入,在第 2 天 (股票价格 = 4) 的时候卖出,这笔交易所能获得利润 = 4-2 = 2 。
示例 2:
输入:k = 2, prices = [3,2,6,5,0,3]
输出:7
解释:在第 2 天 (股票价格 = 2) 的时候买入,在第 3 天 (股票价格 = 6) 的时候卖出, 这笔交易所能获得利润 = 6-2 = 4 。
随后,在第 5 天 (股票价格 = 0) 的时候买入,在第 6 天 (股票价格 = 3) 的时候卖出, 这笔交易所能获得利润 = 3-0 = 3 。
我的
在Ⅲ的基础上进行扩充,可以看到我们的状态数组变成三维了,初始化范围变得不太容易确定了。
我们可以通过递推关系式,数组下标的越界,来确定我们的初始化范围
class Solution {
public int maxProfit(int k, int[] prices) {
if (prices == null || prices.length <= 1) return 0;
// 0. 利润
// 1. 前i天
// 2. 是否持股
// 3. 交易次数
int[][][] dp = new int[prices.length][2][k + 1];
// 因为最小值再减去1就是最大值Integer.MIN_VALUE-1=Integer.MAX_VALUE
int MIN_VALUE = Integer.MIN_VALUE / 2;
int max = MIN_VALUE;
int result = 0;
// 初始化,初始化范围由下面的递推关系式反推得到的
// Arrays.fill(dp[0][0], MIN_VALUE);
// Arrays.fill(dp[0][1], MIN_VALUE);
for (int i = 0; i < dp[0][0].length; i++) {
dp[0][0][i] = MIN_VALUE;
dp[0][1][i] = MIN_VALUE;
}
dp[0][0][0] = 0;//第一天休息
dp[0][1][0] = -prices[0];//买股票
for (int i = 0; i < dp.length; i++) {
max = Math.max(max, -prices[i]);
dp[i][0][0] = 0;
dp[i][1][0] = max;
}
// 下面的递推关系式中包含 i - 1、j - 1,会对 i、j 取 0 值的时候产生影响(越界),需要在初始化数组的时候直接初始化
for (int i = 1; i < prices.length; i++) {
for (int j = 1; j < k + 1; j++) {
dp[i][0][j] = Math.max(dp[i - 1][0][j], dp[i - 1][1][j - 1] + prices[i]);
dp[i][1][j] = Math.max(dp[i - 1][1][j], dp[i - 1][0][j] - prices[i]);
result = Math.max(result, dp[i][0][j]);
}
}
return result;
}
}
剑指 Offer 46. 把数字翻译成字符串
给定一个数字,我们按照如下规则把它翻译为字符串:0 翻译成 “a” ,1 翻译成 “b”,……,11 翻译成 “l”,……,25 翻译成 “z”。一个数字可能有多个翻译。请编程实现一个函数,用来计算一个数字有多少种不同的翻译方法。
示例 1:
输入: 12258
输出: 5
解释: 12258有5种不同的翻译,分别是"bccfi", "bwfi", "bczi", "mcfi"和"mzi"
动态规划答案
我们可以看出它的递推范围为2,即 我们的1位字符和2位字符都有可能被翻译。
所以我们要找的递推关系式为:dp[n] = dp[n - 1] + dp[n - 2](这个n - 2不一定能成立。。)
class Solution {
public int translateNum(int num) {
// 回溯法思想:循环层数不确定
// 一个得算
// 1个两个得算
// 2个两个得算
// 3个两个。。。。
// 动态规划思想:数字位数n的阶段,数字位数n-1、n-2的阶段,能不能推出来
String str = String.valueOf(num);
// 状态:前n位数,翻译方法数
int[] dp = new int[str.length() + 1];
// 初始化,一位数
dp[0] = 1;
dp[1] = 1;
for (int i = 2; i < dp.length; i++) {
// (i - 1) + 1 = i
dp[i] += dp[i - 1];
// 如果后两位在10~25之间,那就可以翻译
// (i - 2) + 2 = i
String temp = str.substring(i - 2, i);
if (temp.compareTo("10") >= 0 && temp.compareTo("25") <= 0) {
dp[i] += dp[i - 2];
}
}
return dp[dp.length - 1];
}
}
回溯法
有关回溯法,也可以看看我写的回溯三步走。
回溯法分析,存在两个分支:
- 取一个数字
- 取两个数字
// 上面可以运行,但是我想试试递归回溯
// 个人感觉这题跟青蛙跳台阶一个风格
class Solution {
public int res = 0;
public int translateNum(int num) {
// 回溯法思想:循环层数不确定
// 一个得算
// 1个两个得算
// 2个两个得算
// 3个两个。。。。
backtrack(String.valueOf(num), 0);
return res;
}
public void backtrack(String str, int index) {
// 这里的递归出口要注意:我们是到顶了再前进一格,这样回退的话就可以取到最后一个元素的边界,这样就好进一步取2位子串
if (index > str.length()) {
res++;
return;
}
backtrack(str, index + 1);
if (index >= 2) {
String temp = str.substring(index - 2, index);
if (temp.compareTo("10") >= 0 && temp.compareTo("25") <= 0) {
backtrack(str, index + 2);
}
}
}
}
剑指 Offer 60. n个骰子的点数
把n个骰子扔在地上,所有骰子朝上一面的点数之和为s。输入n,打印出s的所有可能的值出现的概率。
你需要用一个浮点数数组返回答案,其中第 i 个元素代表这 n 个骰子所能掷出的点数集合中第 i 小的那个的概率。
示例 1:
输入: 1
输出: [0.16667,0.16667,0.16667,0.16667,0.16667,0.16667]
示例 2:
输入: 2
输出: [0.02778,0.05556,0.08333,0.11111,0.13889,0.16667,0.13889,0.11111,0.08333,0.05556,0.02778]
答案
// 11 -> 12 21 -> 22 13 31 -> 14 41 23 32 -> 15 51 24 42 33 -> 16 61 52 25 43 34 -> 17 71 62 26 53 35 440
class Solution {
public double[] dicesProbability(int n) {
// 动态规划
// 状态:前i个骰子,总点数,概率
double[][] dp = new double[n + 1][6 * n + 1];
Arrays.fill(dp[1], 1, 7, 1.0 / 6);
// dp[n - 1][i] = dp[n - 2][i - 1] * 1.0 / 6;
for (int i = 2; i <= n; i++) {
for (int j = i; j <= 6 * i; j++) {
for (int k = 1; k <= 6 && k < j; k++) {
// 当第i个骰子的点数为k时,多次迭代填表
// 如 总点数为5时,k从1到4,可以组合成14, 23, 32, 41
// 前i,点数j = 前i-1,点数j-k
dp[i][j] += dp[i - 1][j - k] * 1.0 / 6;
}
}
}
return Arrays.copyOfRange(dp[n], n, dp[n].length);
}
}
答案优化(滚动数组)
// 大佬写的滚动数组:由于 dp[i] 仅由 dp[i-1] 递推得出,为降低空间复杂度,只建立两个一维数组 dp , tmp 交替前进即可。
class Solution {
public double[] dicesProbability(int n) {
// 动态规划
// 状态:前i个骰子,总点数,概率
double[] pre = new double[6]; // 前数组指针,代表dp[i - 1]
Arrays.fill(pre, 1.0 / 6.0);
for (int i = 2; i <= n; i++) {
// double[] cur = new double[6 * n - n + 1]; // 现数组指针,代表dp[i]
double[] cur = new double[5 * i + 1]; // 与上面等价[6 * n - n + 1]
for (int j = 0; j < pre.length; j++) {
for (int k = 0; k < 6; k++) {
cur[j + k] += pre[j] / 6.0;
}
}
pre = cur; // 前进
}
return pre;
}
}
剑指 Offer 14- I. 剪绳子
给你一根长度为 n 的绳子,请把绳子剪成整数长度的 m 段(m、n都是整数,n>1并且m>1),每段绳子的长度记为 k[0],k[1]...k[m-1] 。请问 k[0]k[1]...*k[m-1] 可能的最大乘积是多少?例如,当绳子的长度是8时,我们把它剪成长度分别为2、3、3的三段,此时得到的最大乘积是18。
示例 1:
输入: 2
输出: 1
解释: 2 = 1 + 1, 1 × 1 = 1
示例 2:
输入: 10
输出: 36
解释: 10 = 3 + 3 + 4, 3 × 3 × 4 = 36
答案
动态规划,自底向上,我们从绳长为2开始看起,慢慢把绳长+1,看看是否可以借助前一个结果来达成目的
- 绳长2,结果1
- 绳长3,结果2
- 绳长4,结果4
- 绳长5,结果6
- 绳长6,结果9:可以按1、2、3、4、5剪一刀,剩下的绳长可以考虑用之前的数据,按3剪一刀,与余下的相乘,取最大。
// 动态规划
class Solution {
public int cuttingRope(int n) {
// 状态参数:绳子长度、最大乘积
int[] dp = new int[n + 1];
int max = 0;
// 初始化,数组默认初始值为0
dp[2] = 1;
// 填表
for (int i = 3; i < n + 1; i++) { // 填表
for (int cut = 2; cut < i; cut++) { // 以cut为长度剪一刀
// 获取 剪一刀后直接相乘的乘积 和 剪一刀后与原先最大乘积的乘积 两者的最大值
max = Math.max(cut * (i - cut), cut * dp[i - cut]);
// 这个 最大值 和 当前dp[i] 进行比较,取最大值,看看哪一种cut能取到最大
dp[i] = Math.max(dp[i], max);
}
}
return dp[n];
}
}
数学答案
// 经过多次实验,感觉按3剪比较大
class Solution {
public int cuttingRope(int n) {
if(n <= 3) return n - 1;
int a = n / 3, b = n % 3;
// 余0时
if(b == 0) return (int)Math.pow(3, a);
// 余1时
if(b == 1) return (int)Math.pow(3, a - 1) * 4;
// 余2时
return (int)Math.pow(3, a) * 2;
}
}
剑指 Offer 42. 连续子数组的最大和
输入一个整型数组,数组中的一个或连续多个整数组成一个子数组。求所有子数组的和的最大值。
要求时间复杂度为O(n)。
示例1:
输入: nums = [-2,1,-3,4,-1,2,1,-5,4]
输出: 6
解释: 连续子数组 [4,-1,2,1] 的和最大,为 6。
答案
动态规划解析:
- 状态定义: 设动态规划列表 dp ,dp[i] 代表以元素 nums[i] 为结尾的连续子数组最大和。(即 前缀性质)
为何定义最大和 dp[i] 中必须包含元素 nums[i] :保证 dp[i] 递推到 dp[i+1] 的正确性;如果不包含 nums[i] ,递推时则不满足题目的 连续子数组 要求。
-
转移方程: 若 \(dp[i-1] \leq 0\) ,说明 dp[i - 1] 对 dp[i] 产生负贡献,即 dp[i-1] + nums[i] 还不如 nums[i] 本身大。
- 当 \(dp[i - 1] > 0\) 时:执行 dp[i] = dp[i-1] + nums[i];
- 当 \(dp[i - 1] \leq 0\) 时:执行 dp[i] = nums[i];
-
初始状态: dp[0] = nums[0],即以 nums[0] 结尾的连续子数组最大和为 nums[0]。
-
返回值: 返回 dp 列表中的最大值,代表全局最大值。
原问题:[1, 2, 3, 4]的最大和
子类问题:[1, 2, 3]的最大和
当前问题:4
class Solution {
public int maxSubArray(int[] nums) {
// 试试双指针滑动数组,发现没啥用,不能根据现在的情况判断如何前进后退
// 只能想想别的办法了,一看这是多阶段决策问题,动态规划!
// 两个参数,1.现在的索引号,2.当前最大和
int[] dp = new int[nums.length];
dp[0] = nums[0];
int max = nums[0];
for (int i = 1; i < nums.length; i++) {
// 如果纠结于现在索引号取和不取的最大和,会导致不取的时候子数组不连续,所以该数组状态不行
// dp[i] = Math.max(dp[i - 1], dp[i - 1] + nums[i]);
// 所以我们定义必取现在的索引号,那么会造成一个新的问题,我们的动态规划最大值不一定是最后一个了,所以我们需要存储最大值
dp[i] = Math.max(dp[i - 1] + nums[i], nums[i]);
max = Math.max(dp[i], max);
}
return max;
}
}
剑指 Offer 48. 最长不含重复字符的子字符串
请从字符串中找出一个最长的不包含重复字符的子字符串,计算该最长子字符串的长度。
示例 1:
输入: "abcabcbb"
输出: 3
解释: 因为无重复字符的最长子串是 "abc",所以其长度为 3。
示例 2:
输入: "bbbbb"
输出: 1
解释: 因为无重复字符的最长子串是 "b",所以其长度为 1。
示例 3:
输入: "pwwkew"
输出: 3
解释: 因为无重复字符的最长子串是 "wke",所以其长度为 3。
请注意,你的答案必须是 子串 的长度,"pwke" 是一个子序列,不是子串。
动态规划
这题本来是用滑动窗口做的,但是这里,动态规划也可以做
动态规划 + 哈希表
动态规划解析:
状态定义: 设动态规划列表 dp ,dp[j] 代表以字符 s[j] 为结尾的 “最长不重复子字符串” 的长度。
转移方程: 固定右边界 j ,设字符 s[j] 左边距离最近的相同字符为 s[i] ,即 s[i] = s[j]。
- 当 i < 0,即 s[j] 左边无相同字符,则 dp[j] = dp[j-1] + 1;
- 当 dp[j - 1] < j - i ,说明字符 s[i] 在子字符串 dp[j-1] 区间之外 ,则 dp[j] = dp[j - 1] + 1;
- 当 dp[j − 1] ≥ j − i ,说明字符 s[i] 在子字符串 dp[j-1] 区间之中 ,则 dp[j] 的左边界由 s[i] 决定,即 dp[j] = j - i;
当 i < 0 时,由于 dp[j − 1] ≤ j 恒成立,因而 dp[j - 1] < j - i 恒成立,因此分支 1. 和 2. 可被合并。
返回值:max(dp) ,即全局的 “最长不重复子字符串” 的长度。
哈希表统计: 遍历字符串 s 时,使用哈希表(记为 map)统计 各字符最后一次出现的索引位置 。
左边界 i 获取方式: 遍历到 s[j] 时,可通过访问哈希表 map[s[j]] 获取最近的相同字符的索引 i 。
原问题:abca
子类问题:abc,长度3
当前问题:a
class Solution {
public int lengthOfLongestSubstring(String s) {
if (s.length() <= 1) {
return s.length();
}
char[] chars = s.toCharArray();
// 存放元素和其对应下标
Map<Character, Integer> map = new HashMap<>();
// dp[i]代表以 i 为结尾的子字符串的符合条件的最长长度
int[] dp = new int[chars.length];
// 最小问题
dp[0] = 1;
map.put(chars[0], 0);
int res = 0;
for (int i = 1; i < dp.length; i++) {
// dp[i] = dp[i - 1] + 1;
Integer index = map.getOrDefault(chars[i], -1);
if (index == -1 || index < i - 1 - dp[i - 1] + 1) {
dp[i] = dp[i - 1] + 1;
} else { // 元素在上一子字符串之内
dp[i] = i - index;
}
map.put(chars[i], i);
res = Math.max(res, dp[i]);
}
return res;
}
}
复杂度分析:
- 时间复杂度 O(N):其中 N 为字符串长度,动态规划需遍历计算 dpdp 列表。
- 空间复杂度 O(1):字符的 ASCII 码范围为 0 ~ 127 ,哈希表 dicdic 最多使用 O(128) = O(1) 大小的额外空间。
铺满骨牌
有 2*n 的一个长方形方格,用一个 1*2 的骨牌铺满方格 编写一个程序,试对给出的任意一个n(n>0), 输出铺法总数。
答案
【算法分析】
(1)当n=1时,
只能是一种铺法,铺法总数有示为x1=1。
(2)当n=2时:
骨牌可以两个并列竖排,也可以并列横排,再无其他方法,如下左图所示,因此,铺法总数表示为x2=2;
推出一般规律:对一般的n,要求xn可以这样来考虑,
若第一个骨牌是竖排列放置,
剩下有n-1个骨牌需要排列,这时排列方法数为xn-1;
若第一个骨牌是横排列,
整个方格至少有2个骨牌是横排列(1*2骨牌),因此剩下n-2个骨牌需要排列,这是骨牌排列方法数为xn-2。
从第一骨牌排列方法考虑,只有这两种可能,所以有:
f(n)=f(n-1)+f(n-2) (n>2)
f(1)=1
f(2)=2
【代码】
int main() {
int a[101];
a[1]=1, a[2]=2;
Scanner cin = new Scanner(System.in);
int n = cin.nextInt();
for(int i = 3; i <= n; i++) {
a[i] = a[i-1] + a[i-2];
}
return a[n];
}
322. 零钱兑换
给你一个整数数组 coins ,表示不同面额的硬币;以及一个整数 amount ,表示总金额。
计算并返回可以凑成总金额所需的 最少的硬币个数 。如果没有任何一种硬币组合能组成总金额,返回 -1 。
你可以认为每种硬币的数量是无限的。
示例 1:
输入:coins = [1, 2, 5], amount = 11
输出:3
解释:11 = 5 + 5 + 1
示例 2:
输入:coins = [2], amount = 3
输出:-1
示例 3:
输入:coins = [1], amount = 0
输出:0
我的
以总价值的增减进行递推
class Solution {
public int coinChange(int[] coins, int amount) {
int max = amount + 1;
int[] dp = new int[amount + 1];
Arrays.fill(dp, max);
// 初始化
dp[0] = 0;
for (int coin : coins) {
if (coin <= amount) {
dp[coin] = 1;
}
}
for (int i = 1; i <= amount; i++) {
// 按总金额的增减进行递推
for (int j = 0; j <= i / 2; j++) {
dp[i] = Math.min(dp[j] + dp[i - j], dp[i]);
}
}
return dp[amount] == max ? -1 : dp[amount];
}
}
答案
我们采用自下而上的方式进行思考。仍定义 F(i) 为组成金额 i 所需最少的硬币数量,假设在计算 F(i) 之前,我们已经计算出 F(0)−F(i−1) 的答案。 则 F(i) 对应的转移方程应为
其中 \(c_j\) 代表的是第 j 枚硬币的面值,即我们枚举最后一枚硬币面额是 \(c_j\),那么需要从 \(i-c_j\) 这个金额的状态 \(F(i-c_j)\) 转移过来,再算上枚举的这枚硬币数量 1 的贡献,由于要硬币数量最少,所以 F(i) 为前面能转移过来的状态的最小值加上枚举的硬币数量 1。
例子1:假设
coins = [1, 2, 5], amount = 11
则,当 i==0 时无法用硬币组成,为 0 。当 i<0 时,忽略 F(i)
| F(i) | 最小硬币数量 | 备注 |
|---|---|---|
| F(0) | 0 | 金额为0不能由硬币组成 |
| F(1) | 1 | F(1)=min(F(1-1),F(1-2),F(1-5))+1=1 |
| F(2) | 1 | F(2)=min(F(2-1),F(2-2),F(2-5))+1=1 |
| F(3) | 2 | F(3)=min(F(3-1),F(3-2),F(3-5))+1=2 |
| F(4) | 2 | F(4)=min(F(4-1),F(4-2),F(4-5))+1=2 |
| ... | ... | ... |
| F(11) | 3 | F(11)=min(F(11-1),F(11-2),F(11-5))+1=3 |
我们可以看到问题的答案是通过子问题的最优解得到的。
例子2:假设
coins = [1, 2, 3], amount = 6

在上图中,可以看到:
与我思路的不同之处:答案是按硬币的增减进行递推,而我是按总金额的增减进行递推,所以我的方法所需的时间会更长。
public class Solution {
public int coinChange(int[] coins, int amount) {
int max = amount + 1;
// dp数组的含义为 总金额为i的情况下,所需最少硬币个数
int[] dp = new int[amount + 1];
Arrays.fill(dp, max);
// 初始化
dp[0] = 0;
for (int i = 1; i <= amount; i++) {
// 按单个硬币的增减进行递推
for (int j = 0; j < coins.length; j++) {
if (i >= coins[j]) {
dp[i] = Math.min(dp[i], dp[i - coins[j]] + 1);
}
}
}
return dp[amount] > amount ? -1 : dp[amount];
}
}
复杂度分析
- 时间复杂度:\(O(Sn)\),其中 S 是金额,n 是面额数。我们一共需要计算 O(S) 个状态,S 为题目所给的总金额。对于每个状态,每次需要枚举 n 个面额来转移状态,所以一共需要 O(Sn) 的时间复杂度。
- 空间复杂度:\(O(S)\)。数组 dp 需要开长度为总金额 S 的空间。
518. 零钱兑换 II(组合问题)
给你一个整数数组 coins 表示不同面额的硬币,另给一个整数 amount 表示总金额。
请你计算并返回可以凑成总金额的硬币组合数。如果任何硬币组合都无法凑出总金额,返回 0 。
假设每一种面额的硬币有无限个。
题目数据保证结果符合 32 位带符号整数。
示例 1:
输入:amount = 5, coins = [1, 2, 5]
输出:4
解释:有四种方式可以凑成总金额:
5=5
5=2+2+1
5=2+1+1+1
5=1+1+1+1+1
示例 2:
输入:amount = 3, coins = [2]
输出:0
解释:只用面额 2 的硬币不能凑成总金额 3 。
示例 3:
输入:amount = 10, coins = [10]
输出:1
动态规划
这道题中,给定总金额 amount 和数组 coins,要求计算金额之和等于 amount 的硬币组合数。其中,coins 的每个元素可以选取多次,且不考虑选取元素的顺序,因此这道题需要计算的是选取硬币的组合数。
可以通过动态规划的方法计算可能的组合数。用 dp[x] 表示金额之和等于 x 的硬币组合数,目标是求 dp[amount]。
动态规划的边界是 dp[0]=1。只有当不选取任何硬币时,金额之和才为 0,因此只有 1 种硬币组合。
对于面额为 coin 的硬币,当 coin≤i≤amount 时,如果存在一种硬币组合的金额之和等于 i−coin,则在该硬币组合中增加一个面额为 coin 的硬币,即可得到一种金额之和等于 i 的硬币组合。因此需要遍历 coins,对于其中的每一种面额的硬币,更新数组 dp 中的每个大于或等于该面额的元素的值。
由此可以得到动态规划的做法:
- 初始化 dp[0]=1;
- 遍历 coins,对于其中的每个元素 coin,进行如下操作:
- 遍历 i 从 coin 到 amount,将 dp[i−coin] 的值加到 dp[i]。
- 最终得到 dp[amount] 的值即为答案。
上述做法不会重复计算不同的排列。因为外层循环是遍历数组 coins 的值,内层循环是遍历不同的金额之和,在计算 dp[i] 的值时,可以确保金额之和等于 i 的硬币面额的顺序,由于顺序确定,因此不会重复计算不同的排列。
例如,coins=[1,2],对于 dp[3] 的计算,一定是先遍历硬币面额 1 后遍历硬币面额 2,只会出现以下 2 种组合:
硬币面额 2 不可能出现在硬币面额 1 之前,即不会重复计算 3=2+1 的情况。
class Solution {
public int change(int amount, int[] coins) {
int[] dp = new int[amount + 1];
dp[0] = 1;
// 固定当前问题
for (int coin : coins) {
for (int i = coin; i <= amount; i++) {
dp[i] += dp[i - coin];
}
}
return dp[amount];
}
}
复杂度分析
-
时间复杂度:\(O(\textit{amount} \times n)\),其中 amount 是总金额,n 是数组 coins 的长度。需要使用数组 coins 中的每个元素遍历并更新数组 dp 中的每个元素的值。
-
空间复杂度:\(O(\textit{amount})\),其中 amount 是总金额。需要创建长度为 amount+1 的数组 dp。
300. 最长递增子序列
给你一个整数数组 nums ,找到其中最长严格递增子序列的长度。
子序列 是由数组派生而来的序列,删除(或不删除)数组中的元素而不改变其余元素的顺序。例如,[3,6,2,7] 是数组 [0,3,1,6,2,2,7] 的子序列。
示例 1:
输入:nums = [10,9,2,5,3,7,101,18]
输出:4
解释:最长递增子序列是 [2,3,7,101],因此长度为 4 。
示例 2:
输入:nums = [0,1,0,3,2,3]
输出:4
示例 3:
输入:nums = [7,7,7,7,7,7,7]
输出:1
我的
如果不选用确定的尾元素,那我们对当前节点的状态将会一无所知,无法进行递推。
原问题:[10,9,2,5,3,7,101,18]以18为尾的子序列长度
子类问题:[10,9,2,5,3,7,101]以101为尾的子序列长度、[10,9,2,5,3,7]、[10,9,2,5,3]、...、[10]
当前问题:18,每次与子类问题的尾进行大小比较,推出原问题
子类问题需要多次填表,需要额外的一层循环
class Solution {
public int lengthOfLIS(int[] nums) {
int res = 1;
int[] dp = new int[nums.length];
// 这里没有先进行初始化是因为递推公式没有任何限制,可以直接递推
// Arrays.fill(dp, 1);
for (int i = 0; i < dp.length; i++) {
dp[i] = 1;
// 多次填表,多次划分子类问题
for (int j = 0; j < i; j++) {
if (nums[i] > nums[j]) {
dp[i] = Math.max(dp[j] + 1, dp[i]);
}
res = Math.max(res, dp[i]);
}
}
return res;
}
}
复杂度分析
-
时间复杂度:\(O(n^2)\),其中 n 为数组 nums 的长度。动态规划的状态数为 n,计算状态 dp[i] 时,需要 \(O(n)\) 的时间遍历 dp[0…i−1] 的所有状态,所以总时间复杂度为 \(O(n^2)\)。
-
空间复杂度:\(O(n)\),需要额外使用长度为 n 的 dp 数组。
贪心 + 二分查找
思路与算法
考虑一个简单的贪心,如果我们要使上升子序列尽可能的长,则我们需要让序列上升得尽可能慢,因此我们希望每次在上升子序列最后加上的那个数尽可能的小。
基于上面的贪心思路,我们维护一个数组 d[i],表示长度为 i 的最长上升子序列的末尾元素的最小值,用 len 记录目前最长上升子序列的长度,起始时 len 为 1,\(d[1] = \textit{nums}[0]\)。
同时我们可以注意到 d[i] 是关于 i 单调递增的。因为如果 \(d[j] \geq d[i]\) 且 j < i,我们考虑从长度为 i 的最长上升子序列的末尾删除 i−j 个元素,那么这个序列长度变为 j ,且第 j 个元素 x(末尾元素)必然小于 d[i]d[i],也就小于 d[j]。那么我们就找到了一个长度为 j 的最长上升子序列,并且末尾元素比 d[j] 小,从而产生了矛盾。因此数组 d 的单调性得证。
我们依次遍历数组 nums 中的每个元素,并更新数组 d 和 len 的值。如果 \(\textit{nums}[i] > d[\textit{len}]\) 则更新 \(len = len + 1\),否则在 \(d[1 \ldots len]\)中找满足 \(d[i - 1] < \textit{nums}[j] < d[i]\) 的下标 i,并更新 \(d[i] = \textit{nums}[j]\)。
根据 d 数组的单调性,我们可以使用二分查找寻找下标 i,优化时间复杂度。
最后整个算法流程为:
设当前已求出的最长上升子序列的长度为 len(初始时为 1),从前往后遍历数组 nums,在遍历到 nums[i] 时:
如果 \(\textit{nums}[i] > d[\textit{len}]\) ,则直接加入到 d 数组末尾,并更新 \(\textit{len} = \textit{len} + 1\);
否则,在 d 数组中二分查找,找到第一个比 nums[i] 小的数 d[k] ,并更新 \(d[k + 1] = \textit{nums}[i]\)。
以输入序列 [0, 8, 4, 12, 2] 为例:
-
第一步插入 0,d = [0];
-
第二步插入 8,d = [0, 8];
-
第三步插入 4,d = [0, 4];
-
第四步插入 12,d = [0, 4, 12];
-
第五步插入 2,d = [0, 2, 12]。
-
最终得到最大递增子序列长度为 3。
class Solution {
public int lengthOfLIS(int[] nums) {
int len = 1, n = nums.length;
if (n == 0) {
return 0;
}
int[] d = new int[n + 1];
d[len] = nums[0];
for (int i = 1; i < n; ++i) {
if (nums[i] > d[len]) {
d[++len] = nums[i];
} else {
int l = 1, r = len, pos = 0; // 如果找不到说明所有的数都比 nums[i] 大,此时要更新 d[1],所以这里将 pos 设为 0
while (l <= r) {
int mid = (l + r) >> 1;
if (d[mid] < nums[i]) {
pos = mid;
l = mid + 1;
} else {
r = mid - 1;
}
}
d[pos + 1] = nums[i];
}
}
return len;
}
}
复杂度分析
-
时间复杂度:\(O(n\log n)\)。数组 nums 的长度为 n,我们依次用数组中的元素去更新 d 数组,而更新 d 数组时需要进行 \(O(\log n)\) 的二分搜索,所以总时间复杂度为 \(O(n\log n)\)。
-
空间复杂度:\(O(n)\),需要额外使用长度为 n 的 d 数组。
线性动态规划
115. 不同的子序列
给定一个字符串 s 和一个字符串 t ,计算在 s 的子序列中 t 出现的个数。
字符串的一个 子序列 是指,通过删除一些(也可以不删除)字符且不干扰剩余字符相对位置所组成的新字符串。(例如,"ACE" 是 "ABCDE" 的一个子序列,而 "AEC" 不是)
题目数据保证答案符合 32 位带符号整数范围。
示例 1:
输入:s = "rabbbit", t = "rabbit"
输出:3
解释:
如下图所示, 有 3 种可以从 s 中得到 "rabbit" 的方案。
rabbbit
rabbbit
rabbbit
示例 2:
输入:s = "babgbag", t = "bag"
输出:5
解释:
如下图所示, 有 5 种可以从 s 中得到 "bag" 的方案。
babgbag
babgbag
babgbag
babgbag
babgbag
双重线性动态规划
可以看到这题不光有一个原问题babgbag,还有一个原问题bag。这两个原问题都需要划分子类问题,才能够进行求解。所以说是双重线性动态规划。
动态规划
dp[i][j] 代表 T 的前 i 字符串可以由 S 的前 j 字符串组成最多个数.
所以动态方程:
-
当 S[j] == T[i] , dp[i][j] = dp[i-1][j-1] + dp[i][j-1];
-
当 S[j] != T[i] , dp[i][j] = dp[i][j-1]
举个例子,如示例的
-
对于第一行, T 为空,因为空集是所有字符串子集, 所以我们第一行都是 1
-
对于第一列, S 为空,这样组成 T 个数当然为 0 了
至于下面如何进行,大家可以通过动态方程,自行模拟一下!
代码:
class Solution {
public int numDistinct(String s, String t) {
int[][] dp = new int[t.length() + 1][s.length() + 1];
for (int j = 0; j < s.length() + 1; j++) dp[0][j] = 1;
for (int i = 1; i < t.length() + 1; i++) {
for (int j = 1; j < s.length() + 1; j++) {
if (t.charAt(i - 1) == s.charAt(j - 1)) dp[i][j] = dp[i - 1][j - 1] + dp[i][j - 1];
else dp[i][j] = dp[i][j - 1];
}
}
return dp[t.length()][s.length()];
}
}
1143. 最长公共子序列
给定两个字符串 text1 和 text2,返回这两个字符串的最长 公共子序列 的长度。如果不存在 公共子序列 ,返回 0 。
一个字符串的 子序列 是指这样一个新的字符串:它是由原字符串在不改变字符的相对顺序的情况下删除某些字符(也可以不删除任何字符)后组成的新字符串。
例如,"ace" 是 "abcde" 的子序列,但 "aec" 不是 "abcde" 的子序列。
两个字符串的 公共子序列 是这两个字符串所共同拥有的子序列。
示例 1:
输入:text1 = "abcde", text2 = "ace"
输出:3
解释:最长公共子序列是 "ace" ,它的长度为 3 。
示例 2:
输入:text1 = "abc", text2 = "abc"
输出:3
解释:最长公共子序列是 "abc" ,它的长度为 3 。
示例 3:
输入:text1 = "abc", text2 = "def"
输出:0
解释:两个字符串没有公共子序列,返回 0 。
答案
已知text1、text2,两个线性问题
- 原问题:dp[i][j],text1 = "abcde", text2 = "ace"
- 子类问题:dp[i - 1][j - 1],text1 = "abcd", text2 = "ac";
dp[i - 1][j],text1 = "abcd", text2 = "ace";
dp[i][j - 1],text1 = "abcde", text2 = "ac",均为子类问题 - 当前问题:当前字符i - 1和j - 1是否相等,e和e
class Solution {
public int longestCommonSubsequence(String text1, String text2) {
int M = text1.length();
int N = text2.length();
int[][] dp = new int[M + 1][N + 1];
for (int i = 1; i <= M; ++i) {
for (int j = 1; j <= N; ++j) {
// dp[i][j] = dp[i - 1][j - 1]、dp[i][j - 1]、dp[i - 1][j]
if (text1.charAt(i - 1) == text2.charAt(j - 1)) {
dp[i][j] = dp[i - 1][j - 1] + 1;
} else {
dp[i][j] = Math.max(dp[i - 1][j], dp[i][j - 1]);
}
}
}
return dp[M][N];
}
}
数组为boolean实例
boolean代表着某种结果的可行性。
- dp数组中一定有某一维下标代表结果数
- 而dp[]的实际元素值代表这种结果数的可行性
5. 最长回文子串
给你一个字符串 s,找到 s 中最长的回文子串。
示例 1:
输入:s = "babad"
输出:"bab"
解释:"aba" 同样是符合题意的答案。
示例 2:
输入:s = "cbbd"
输出:"bb"
动态规划
思路与算法
对于一个子串而言,如果它是回文串,并且长度大于 2,那么将它首尾的两个字母去除之后,它仍然是个回文串。例如对于字符串 “ababa”,如果我们已经知道 “bab” 是回文串,那么 “ababa” 一定是回文串,这是因为它的首尾两个字母都是 “a”。
根据这样的思路,我们就可以用动态规划的方法解决本题。我们用 P(i,j) 表示字符串 s 的第 i 到 j 个字母组成的串(下文表示成 s[i:j])是否为回文串:
回文串:
这里的「其它情况」包含两种可能性:
-
s[i, j] 本身不是一个回文串;
-
i > j,此时 s[i, j] 本身不合法。
那么我们就可以写出动态规划的状态转移方程:
也就是说,只有 s[i+1:j−1] 是回文串,并且 s 的第 i 和 j 个字母相同时,s[i:j] 才会是回文串。
上文的所有讨论是建立在子串长度大于 2 的前提之上的,我们还需要考虑动态规划中的边界条件,即子串的长度为 1 或 2。对于长度为 1 的子串,它显然是个回文串;对于长度为 2 的子串,只要它的两个字母相同,它就是一个回文串。因此我们就可以写出动态规划的边界条件:
动态规划的边界条件:
根据这个思路,我们就可以完成动态规划了,最终的答案即为所有 \(P(i, j) = \text{true}\) 中 j−i+1(即子串长度)的最大值。注意:在状态转移方程中,我们是从长度较短的字符串向长度较长的字符串进行转移的,因此一定要注意动态规划的循环顺序。
原问题:abcdcba
子类问题:bcdcb
当前问题:左a和右a
public class Solution {
public String longestPalindrome(String s) {
int len = s.length();
char[] chars = s.toCharArray();
int resLeft = 0, resRight = 0;
// dp[i][j] 表示 s[i..j] 是否是回文串
boolean[][] dp = new boolean[len][len];
// 初始化:所有长度为 1 的子串都是回文串
for (int i = 0; i < len; i++) {
dp[i][i] = true;
}
// 原问题dp[left][right]、子类问题dp[left + 1][right - 1]
// 当前问题dp[left][right] = dp[left + 1][right - 1] && chars[left] == chars[right]
// 递推开始
// 先枚举子串长度
for (int L = 2; L <= len; L++) {
int left = 0, right = left + L - 1;
while (right < len) {
if (right - left + 1 > 3) {
dp[left][right] = dp[left + 1][right - 1] && chars[left] == chars[right];
} else {
dp[left][right] = chars[left] == chars[right];
}
// 只要 dp[left][right] == true 成立,就表示子串 s[left..right] 是回文,此时记录左右边界
if (dp[left][right] && right - left > resRight - resLeft) {
resRight = right;
resLeft = left;
}
left++;
right++;
}
}
return s.substring(resLeft, resRight + 1);
}
}
我的
原问题:babab、子类问题:aba、当前问题:b b
- 子类问题的大小:b、aba、babab
- 所以我们的填表顺序:
dp[2][2]->dp[1][3]->dp[0][4],可以看到我们第一层级窗口大小为1,第二层级窗口大小为3,第三层级窗口大小为5 - 所以我们的最终填表顺序:窗口大小1、3、5,这样会比上面一种跳跃式填表更具有逻辑性,并且程序会更加好写。
并且根据子类问题的规则,我们可以倒推出我们的最小问题(初始问题):
如子类问题为dp[leftIndex + 1][rightIndex - 1],我们可以看到此子类问题的规则:
- 下标不能越界:
rightIndex - 1 >= 0,rightIndex >= 1,所以需要将下标为0的数组填表,需要将窗口长度为1的数组初始化填表 - 左边界不能超过右边界:
leftIndex + 1 <= rightIndex - 1,rightIndex - leftIndex >= 2,所以需要将rightIndex - leftIndex值为0和1的,窗口长度为1和2的数组初始化填表
原问题:dp[left][right]
子类问题:dp[left + 1][right - 1]
- 规则rightIndex - 1 >= 0、leftIndex + 1 <= rightIndex - 1
- rightIndex >= 1、rightIndex - leftIndex >= 2
也就是说,窗口长度为1和2的都可能需要初始化
class Solution {
public String longestPalindrome(String s) {
int resLeft = 0, resRight = 0;
boolean[][] dp = new boolean[s.length()][s.length()];
// 子类问题:dp[left + 1][right - 1]
// 规则rightIndex - 1 >= 0、leftIndex + 1 <= rightIndex - 1
// rightIndex >= 1、rightIndex - leftIndex >= 2
// 也就是说,窗口长度为1和2的都可能需要初始化
for (int i = 0; i < dp.length; i++) {
// 窗口长度为1
dp[i][i] = true;
// 窗口长度为2
if (i + 1 < dp.length) {
dp[i][i + 1] = s.charAt(i) == s.charAt(i + 1);
if (dp[i][i + 1]) {
resLeft = i;
resRight = i + 1;
}
}
}
// 填表,从窗口大小为3开始填
for (int l = 3; l <= dp.length; l++) {
int leftIndex = 0, rightIndex = leftIndex + l - 1;
while (rightIndex < dp.length) {
dp[leftIndex][rightIndex] = dp[leftIndex + 1][rightIndex - 1] && s.charAt(leftIndex) == s.charAt(rightIndex);
if (dp[leftIndex][rightIndex] && rightIndex - leftIndex > resRight - resLeft) {
resRight = rightIndex;
resLeft = leftIndex;
}
leftIndex++;
rightIndex++;
}
}
return s.substring(resLeft, resRight + 1);
}
}
139. 单词拆分
给你一个字符串 s 和一个字符串列表 wordDict 作为字典。请你判断是否可以利用字典中出现的单词拼接出 s 。
注意:不要求字典中出现的单词全部都使用,并且字典中的单词可以重复使用。
示例 1:
输入: s = "leetcode", wordDict = ["leet", "code"]
输出: true
解释: 返回 true 因为 "leetcode" 可以由 "leet" 和 "code" 拼接成。
示例 2:
输入: s = "applepenapple", wordDict = ["apple", "pen"]
输出: true
解释: 返回 true 因为 "applepenapple" 可以由 "apple" "pen" "apple" 拼接成。
注意,你可以重复使用字典中的单词。
示例 3:
输入: s = "catsandog", wordDict = ["cats", "dog", "sand", "and", "cat"]
输出: false
我的分析方法
分析:当然,这题也可以使用字典树来做!
原问题:leetcode是否可被拼接出(原问题=子类问题+当前问题)
子类问题:子类问题不止于后面的一个元素有关,需要重新遍历前面所有的问题。
| 子类问题 | 当前问题 |
|---|---|
| l | eetcode |
| le | etcode |
| lee | tcode |
| leet | code |
| ... | ... |
| leetcod是否可被拼接出 | e是否在字典内 |
最小问题:空字符串
class Solution {
public boolean wordBreak(String s, List<String> wordDict) {
Set<String> set = new HashSet<>(wordDict);
boolean[] dp = new boolean[s.length() + 1];
dp[0] = true;
for (int i = 1; i < dp.length; i++) {
for (int j = 0; j < i; j++) {
// 原问题:dp[i]
// 子类问题:dp[j]
// 当前问题:子字符串(j, i)
if (dp[j] && set.contains(s.substring(j, i))) {
dp[i] = true;
break;
}
}
}
return dp[dp.length - 1];
}
}
416. 分割等和子集
给你一个 只包含正整数 的 非空 数组 nums 。请你判断是否可以将这个数组分割成两个子集,使得两个子集的元素和相等。
示例 1:
输入:nums = [1,5,11,5]
输出:true
解释:数组可以分割成 [1, 5, 5] 和 [11] 。
示例 2:
输入:nums = [1,2,3,5]
输出:false
解释:数组不能分割成两个元素和相等的子集。
我的回溯(最优解)
很遗憾回溯法超时了,但是如果题目问的是这两个子集分别是什么(华为笔试),那回溯法就是很好的一个方法。
class Solution {
public boolean canPartition(int[] nums) {
int sum = 0;
for (int num : nums) {
sum += num;
}
if (sum % 2 == 1) {
return false;
}
sum = sum / 2;
// 从集合中找出和为sum的子数组
boolean[][] dp = new boolean[nums.length][sum + 1];
for (int i = 0; i < nums.length; i++) {
dp[i][0] = true;
dp[i][nums[i]] = true;
if (nums[i] == sum) {
return true;
}
}
// dp[i][j] = dp[i - 1][j]
// dp[i][j] = dp[i - 1][j - nums[i]]
for (int i = 1; i < dp.length; i++) {
for (int j = 0; j < dp[0].length; j++) {
dp[i][j] = dp[i - 1][j];
if (j - nums[i] >= 0) {
dp[i][j] |= dp[i - 1][j - nums[i]];
}
}
}
return dp[dp.length][dp[0].length];
}
}
动态规划(最优值)
分析:
- 一个大数组划分为两个子数组,且和相同,所以 大数组的和 / 2 = 小数组的和
- 如果为奇数,则false
现在我们已知小数组的和,我们希望在大数组中挑选出子集元素,子集元素的和组合成小数组的和。
我们来举个例子吧:
- 原问题:[1,5,11,5]的子集合的和能否组成目标值(boolean)
(我们需要记录下此集合的每一个子集合的和为多少(true) - 子类问题:[1,5,11],能组成的和值 1、5、6、11、12、16
- 当前问题:5,将子类问题的所有和值加上5,能构成新一轮的和值
所以我们的dp数组,需要记录
- 子类问题子集:0~i
- 子集的和:0~j
- 是否可行:dp
需要二维dp数组,boolean dp[i][j]代表0~i数组中子集的和为j是否可行
class Solution {
public boolean canPartition(int[] nums) {
int sum = 0;
for (int num : nums) {
sum += num;
}
if (sum % 2 == 1) {
return false;
}
sum = sum / 2;
// 从集合中找出和为sum的子数组
boolean[][] dp = new boolean[nums.length][sum + 1];
for (int i = 0; i < nums.length; i++) {
dp[i][0] = true;
if (nums[i] > sum) {
return false;
}
dp[i][nums[i]] = true;
if (nums[i] == sum) {
return true;
}
}
// dp[i][j] = dp[i - 1][j]
// dp[i][j] = dp[i - 1][j - nums[i]]
for (int i = 1; i < dp.length; i++) {
for (int j = 0; j < dp[0].length; j++) {
dp[i][j] = dp[i - 1][j];
if (j - nums[i] >= 0) {
dp[i][j] |= dp[i - 1][j - nums[i]];
}
}
}
return dp[dp.length - 1][dp[0].length - 1];
}
}
其他
55. 跳跃游戏
给定一个非负整数数组 nums ,你最初位于数组的 第一个下标 。
数组中的每个元素代表你在该位置可以跳跃的最大长度。
判断你是否能够到达最后一个下标。
示例 1:
输入:nums = [2,3,1,1,4]
输出:true
解释:可以先跳 1 步,从下标 0 到达下标 1, 然后再从下标 1 跳 3 步到达最后一个下标。
示例 2:
输入:nums = [3,2,1,0,4]
输出:false
解释:无论怎样,总会到达下标为 3 的位置。但该下标的最大跳跃长度是 0 , 所以永远不可能到达最后一个下标。
我的动态规划
dp数组来记录下当前第i个元素是否可达,迭代多次填表。
class Solution {
public boolean canJump(int[] nums) {
// dp[i],从0跳到位置i时的最少跳跃次数
boolean[] dp = new boolean[nums.length];
// 因为下面会 + 1,超出了边界,所以除以2
dp[0] = true;
for (int i = 0; i < dp.length; i++) {
// 前进j步
for (int j = 1; j <= nums[i] && i + j < dp.length; j++) {
dp[i + j] = dp[i];
}
}
return dp[dp.length - 1];
}
}
我的
本来使用了dp数组来记录下当前第i个元素能达到的最远距离(i + nums[i])。
原问题:dp[i]可达的最远距离
子类问题:dp[0..i-1]可达的最远距离
当前问题:
- dp[0..i-1]是否能够抵达 i,如果不能抵达,那就不可达;
- 如果可以抵达那就取最大值:dp[i] = Max(dp[0..i-1]) >= i ? Max(i + nums[i], Max(dp[0..i-1])) : return false(不可达)
后来发现,只用通过一个元素记录最远距离即可。
public class Solution {
public boolean canJump(int[] nums) {
int n = nums.length;
int rightmost = 0;
for (int i = 0; i < n; ++i) {
// 如果最远距离比当前i要小了,说明此元素不可达
if (rightmost < i) {
return false;
}
rightmost = Math.max(rightmost, i + nums[i]);
}
return true;
}
}
45. 跳跃游戏 II
给你一个非负整数数组 nums ,你最初位于数组的第一个位置。
数组中的每个元素代表你在该位置可以跳跃的最大长度。
你的目标是使用最少的跳跃次数到达数组的最后一个位置。
假设你总是可以到达数组的最后一个位置。
示例 1:
输入: nums = [2,3,1,1,4]
输出: 2
解释: 跳到最后一个位置的最小跳跃数是 2。
从下标为 0 跳到下标为 1 的位置,跳 1 步,然后跳 3 步到达数组的最后一个位置。
示例 2:
输入: nums = [2,3,0,1,4]
输出: 2
动态规划
用动态规划多次填表,dp[i],从0跳到位置i时的最少跳跃次数。
从前往后遍历,多次填表。
- 原问题:[2,3,1,1,4]
- 子类问题:[2,3,1,1]、[2,3,1]、[2,3]、[2]
- 当前问题:[4]、[1,4]、[1,1,4]、[3,1,1,4]
由于子类问题和当前问题不唯一,所以需要两个for循环。
class Solution {
public int jump(int[] nums) {
// dp[i],从0跳到位置i时的最少跳跃次数
int[] dp = new int[nums.length];
// 因为下面会 + 1,超出了边界,所以除以2
Arrays.fill(dp, Integer.MAX_VALUE / 2);
dp[0] = 0;
for (int i = 0; i < dp.length; i++) {
for (int j = 1; j <= nums[i] && i + j < dp.length; j++) {
dp[i + j] = Math.min(dp[i + j], dp[i] + 1);
}
}
return dp[dp.length - 1];
}
}
正向查找可到达的最大位置
方法一虽然直观,但是时间复杂度比较高,有没有办法降低时间复杂度呢?
如果我们「贪心」地进行正向查找,每次找到可到达的最远位置,就可以在线性时间内得到最少的跳跃次数。
例如,对于数组 [2,3,1,2,4,2,3],初始位置是下标 0,从下标 0 出发,最远可到达下标 2。下标 0 可到达的位置中,下标 1 的值是 3,从下标 1 出发可以达到更远的位置,因此第一步到达下标 1。
从下标 1 出发,最远可到达下标 4。下标 1 可到达的位置中,下标 4 的值是 4 ,从下标 4 出发可以达到更远的位置,因此第二步到达下标 4。
在具体的实现中,我们维护当前能够到达的最大下标位置,记为边界。我们从左到右遍历数组,到达边界时,更新边界并将跳跃次数增加 1。
在遍历数组时,我们不访问最后一个元素,这是因为在访问最后一个元素之前,我们的边界一定大于等于最后一个位置,否则就无法跳到最后一个位置了。如果访问最后一个元素,在边界正好为最后一个位置的情况下,我们会增加一次「不必要的跳跃次数」,因此我们不必访问最后一个元素。
class Solution {
public int jump(int[] nums) {
int length = nums.length;
int end = 0; // 结束位置
int maxPosition = 0; // 最大位置
int steps = 0;
for (int i = 0; i < length - 1; i++) {
maxPosition = Math.max(maxPosition, i + nums[i]);
if (i == end) {
end = maxPosition;
steps++;
}
if (end >= length) {
return steps;
}
}
return steps;
}
}
复杂度分析
- 时间复杂度:\(O(n)\),其中 n 是数组长度。
- 空间复杂度:\(O(1)\)。
多数组动态规划
多数组动态规划,其实也可以视作多维的动态规划数组,只不过这维度保存的状态可能填表顺序不一样,就拿[接雨水]这题来说,我们需要两个动态规划数组,一个存放左边的最大值,从左往右填表,一个存放右边的最大值,从右往左填表。
152. 乘积最大子数组
给你一个整数数组 nums ,请你找出数组中乘积最大的非空连续子数组(该子数组中至少包含一个数字),并返回该子数组所对应的乘积。
测试用例的答案是一个 32-位 整数。
子数组 是数组的连续子序列。
示例 1:
输入: nums = [2,3,-2,4]
输出: 6
解释: 子数组 [2,3] 有最大乘积 6。
示例 2:
输入: nums = [-2,0,-1]
输出: 0
解释: 结果不能为 2, 因为 [-2,-1] 不是子数组。
多数组动态规划
因为有负数存在,最小值也可以变成最大值,所以需要小心了,需要两个动态规划数组来分别存放当前最大值和当前最小值。
class Solution {
public int maxProduct(int[] nums) {
int res = nums[0];
int[] maxDp = new int[nums.length];
maxDp[0] = nums[0];
// 有负数存在,最小值也可以变成最大值,所以需要小心了
int[] minDp = new int[nums.length];
minDp[0] = nums[0];
for (int i = 1; i < maxDp.length; i++) {
maxDp[i] = Math.max(minDp[i - 1] * nums[i], Math.max(maxDp[i - 1] * nums[i], nums[i]));
minDp[i] = Math.min(maxDp[i - 1] * nums[i], Math.min(minDp[i - 1] * nums[i], nums[i]));
res = Math.max(res, maxDp[i]);
}
return res;
}
}
42. 接雨水
给定 n 个非负整数表示每个宽度为 1 的柱子的高度图,计算按此排列的柱子,下雨之后能接多少雨水。
示例 1:

输入:height = [0,1,0,2,1,0,1,3,2,1,2,1]
输出:6
解释:上面是由数组 [0,1,0,2,1,0,1,3,2,1,2,1] 表示的高度图,在这种情况下,可以接 6 个单位的雨水(蓝色部分表示雨水)。
示例 2:
输入:height = [4,2,0,3,2,5]
输出:9
多数组动态规划
虽然这题我用双指针做的,但是也不妨碍有动态规划的方法。
对于下标 i,下雨后水能到达的最大高度等于下标 i 两边的最大高度的最小值,下标 i 处能接的雨水量等于下标 i 处的水能到达的最大高度减去 height[i]。
朴素的做法是对于数组 height 中的每个元素,分别向左和向右扫描并记录左边和右边的最大高度,然后计算每个下标位置能接的雨水量。假设数组 height 的长度为 n,该做法需要对每个下标位置使用 \(O(n)\) 的时间向两边扫描并得到最大高度,因此总时间复杂度是 \(O(n^2)\)。
上述做法的时间复杂度较高是因为需要对每个下标位置都向两边扫描。如果已经知道每个位置两边的最大高度,则可以在 \(O(n)\) 的时间内得到能接的雨水总量。使用动态规划的方法,可以在 \(O(n)\) 的时间内预处理得到每个位置两边的最大高度。
创建两个长度为 n 的数组 leftMax 和 rightMax。对于 \(0≤i<n\),leftMax[i] 表示下标 i 及其左边的位置中,height 的最大高度,rightMax[i] 表示下标 i 及其右边的位置中,height 的最大高度。
显然,\(leftMax[0]=height[0]\),\([n-1]rightMax[n−1]=height[n−1]\)。两个数组的其余元素的计算如下:
- 当 \(1≤i≤n−1\) 时,\(leftMax[i]=max(leftMax[i−1],height[i])\);
- 当 \(0≤i≤n−2\) 时,\(rightMax[i]=max(rightMax[i+1],height[i])\)。
因此可以正向遍历数组 height 得到数组 leftMax 的每个元素值,反向遍历数组 height 得到数组 \textit{rightMax}ightMax 的每个元素值。
在得到数组 \(leftMax\) 和 \(rightMax\) 的每个元素值之后,对于 \(0≤i<n\),下标 i 处能接的雨水量等于 \(min(leftMax[i],rightMax[i])−height[i]\)。遍历每个下标位置即可得到能接的雨水总量。
多数组:左当前最大值、右当前最大值
class Solution {
public int trap(int[] height) {
int n = height.length;
if (n == 0) {
return 0;
}
int[] leftMax = new int[n];
leftMax[0] = height[0];
for (int i = 1; i < n; ++i) {
leftMax[i] = Math.max(leftMax[i - 1], height[i]);
}
int[] rightMax = new int[n];
rightMax[n - 1] = height[n - 1];
for (int i = n - 2; i >= 0; --i) {
rightMax[i] = Math.max(rightMax[i + 1], height[i]);
}
int ans = 0;
for (int i = 0; i < n; ++i) {
ans += Math.min(leftMax[i], rightMax[i]) - height[i];
}
return ans;
}
}
799. 香槟塔
我们把玻璃杯摆成金字塔的形状,其中 第一层 有 1 个玻璃杯, 第二层 有 2 个,依次类推到第 100 层,每个玻璃杯 (250ml) 将盛有香槟。
从顶层的第一个玻璃杯开始倾倒一些香槟,当顶层的杯子满了,任何溢出的香槟都会立刻等流量的流向左右两侧的玻璃杯。当左右两边的杯子也满了,就会等流量的流向它们左右两边的杯子,依次类推。(当最底层的玻璃杯满了,香槟会流到地板上)
例如,在倾倒一杯香槟后,最顶层的玻璃杯满了。倾倒了两杯香槟后,第二层的两个玻璃杯各自盛放一半的香槟。在倒三杯香槟后,第二层的香槟满了 - 此时总共有三个满的玻璃杯。在倒第四杯后,第三层中间的玻璃杯盛放了一半的香槟,他两边的玻璃杯各自盛放了四分之一的香槟,如下图所示。
现在当倾倒了非负整数杯香槟后,返回第 i 行 j 个玻璃杯所盛放的香槟占玻璃杯容积的比例( i 和 j 都从0开始)。
示例 1:
输入: poured(倾倒香槟总杯数) = 1, query_glass(杯子的位置数) = 1, query_row(行数) = 1
输出: 0.00000
解释: 我们在顶层(下标是(0,0))倒了一杯香槟后,没有溢出,因此所有在顶层以下的玻璃杯都是空的。
示例 2:
输入: poured(倾倒香槟总杯数) = 2, query_glass(杯子的位置数) = 1, query_row(行数) = 1
输出: 0.50000
解释: 我们在顶层(下标是(0,0)倒了两杯香槟后,有一杯量的香槟将从顶层溢出,位于(1,0)的玻璃杯和(1,1)的玻璃杯平分了这一杯香槟,所以每个玻璃杯有一半的香槟。
示例 3:
输入: poured = 100000009, query_row = 33, query_glass = 17
输出: 1.00000
我的
原问题:dp[i][j] 第i行第j列有多少水流进
子类问题:dp[i - 1][j - 1]和dp[i - 1][j]有多少水流进去
当前问题:杯子装满之后会进行分流,有一半的水会流到当前杯子
class Solution {
public double champagneTower(int poured, int query_row, int query_glass) {
double[][] dp = new double[query_row + 1][query_glass + 1];
// dp[i][j] 第i行第j列有多少水流进
// dp[i][j] = dp[i - 1][j - 1] dp[i - 1][j]
dp[0][0] = poured;
for (int i = 1; i < dp.length; i++) {
for (int j = 0; j < dp[i].length; j++) {
if (j - 1 >= 0) {
dp[i][j] += Math.max((dp[i - 1][j - 1] - 1), 0) / 2;
}
dp[i][j] += Math.max((dp[i - 1][j] - 1), 0) / 2;
}
}
return Math.min(1, dp[query_row][query_glass]);
}
}
221. 最大正方形
在一个由 '0' 和 '1' 组成的二维矩阵内,找到只包含 '1' 的最大正方形,并返回其面积。
示例 1:
输入:matrix = [["1","0","1","0","0"],["1","0","1","1","1"],["1","1","1","1","1"],["1","0","0","1","0"]]
输出:4
示例 2:
输入:matrix = [["0","1"],["1","0"]]
输出:1
示例 3:
输入:matrix = [["0"]]
输出:0
方法一:暴力法
由于正方形的面积等于边长的平方,因此要找到最大正方形的面积,首先需要找到最大正方形的边长,然后计算最大边长的平方即可。
暴力法是最简单直观的做法,具体做法如下:
-
遍历矩阵中的每个元素,每次遇到 1,则将该元素作为正方形的左上角;
-
确定正方形的左上角后,根据左上角所在的行和列计算可能的最大正方形的边长(正方形的范围不能超出矩阵的行数和列数),在该边长范围内寻找只包含 1 的最大正方形;
-
每次在下方新增一行以及在右方新增一列,判断新增的行和列是否满足所有元素都是 1。
class Solution {
public int maximalSquare(char[][] matrix) {
int maxSide = 0;
if (matrix == null || matrix.length == 0 || matrix[0].length == 0) {
return maxSide;
}
int rows = matrix.length, columns = matrix[0].length;
for (int i = 0; i < rows; i++) {
for (int j = 0; j < columns; j++) {
if (matrix[i][j] == '1') {
// 遇到一个 1 作为正方形的左上角
maxSide = Math.max(maxSide, 1);
// 计算可能的最大正方形边长
int currentMaxSide = Math.min(rows - i, columns - j);
for (int k = 1; k < currentMaxSide; k++) {
// 判断新增的一行一列是否均为 1
boolean flag = true;
if (matrix[i + k][j + k] == '0') {
break;
}
for (int m = 0; m < k; m++) {
if (matrix[i + k][j + m] == '0' || matrix[i + m][j + k] == '0') {
flag = false;
break;
}
}
if (flag) {
maxSide = Math.max(maxSide, k + 1);
} else {
break;
}
}
}
}
}
int maxSquare = maxSide * maxSide;
return maxSquare;
}
}
复杂度分析
- 时间复杂度:\(O(mn \min(m,n)^2)\),其中 m 和 n 是矩阵的行数和列数。
- 需要遍历整个矩阵寻找每个 1,遍历矩阵的时间复杂度是 \(O(mn)\)。
- 对于每个可能的正方形,其边长不超过 m 和 n 中的最小值,需要遍历该正方形中的每个元素判断是不是只包含 1,遍历正方形时间复杂度是 \(O(\min(m,n)^2)\)。
- 总时间复杂度是 \(O(mn \min(m,n)^2)\)。
- 空间复杂度:\(O(1)\)。额外使用的空间复杂度为常数。
方法二:动态规划
方法一虽然直观,但是时间复杂度太高,有没有办法降低时间复杂度呢?
可以使用动态规划降低时间复杂度。我们用 dp(i,j) 表示以 (i, j) 为右下角,且只包含 1 的正方形的边长最大值。如果我们能计算出所有 dp(i,j) 的值,那么其中的最大值即为矩阵中只包含 1 的正方形的边长最大值,其平方即为最大正方形的面积。
那么如何计算 dp 中的每个元素值呢?对于每个位置 (i, j),检查在矩阵中该位置的值:
-
如果该位置的值是 0,则 dp(i,j)=0,因为当前位置不可能在由 1 组成的正方形中;
-
如果该位置的值是 1,则 dp(i,j) 的值由其上方、左方和左上方的三个相邻位置的 dp 值决定。具体而言,当前位置的元素值等于三个相邻位置的元素中的最小值加 1,状态转移方程如下:
如果读者对这个状态转移方程感到不解,可以参考 1277. 统计全为 1 的正方形子矩阵的官方题解,其中给出了详细的证明。
此外,还需要考虑边界条件。如果 i 和 j 中至少有一个为 0,则以位置 (i, j) 为右下角的最大正方形的边长只能是 1,因此 dp(i,j)=1。
以下用一个例子具体说明。原始矩阵如下。
0 1 1 1 0
1 1 1 1 0
0 1 1 1 1
0 1 1 1 1
0 0 1 1 1
对应的 dp 值如下。
0 1 1 1 0
1 1 2 2 0
0 1 2 3 1
0 1 2 3 2
0 0 1 2 3
下图也给出了计算 dp 值的过程。
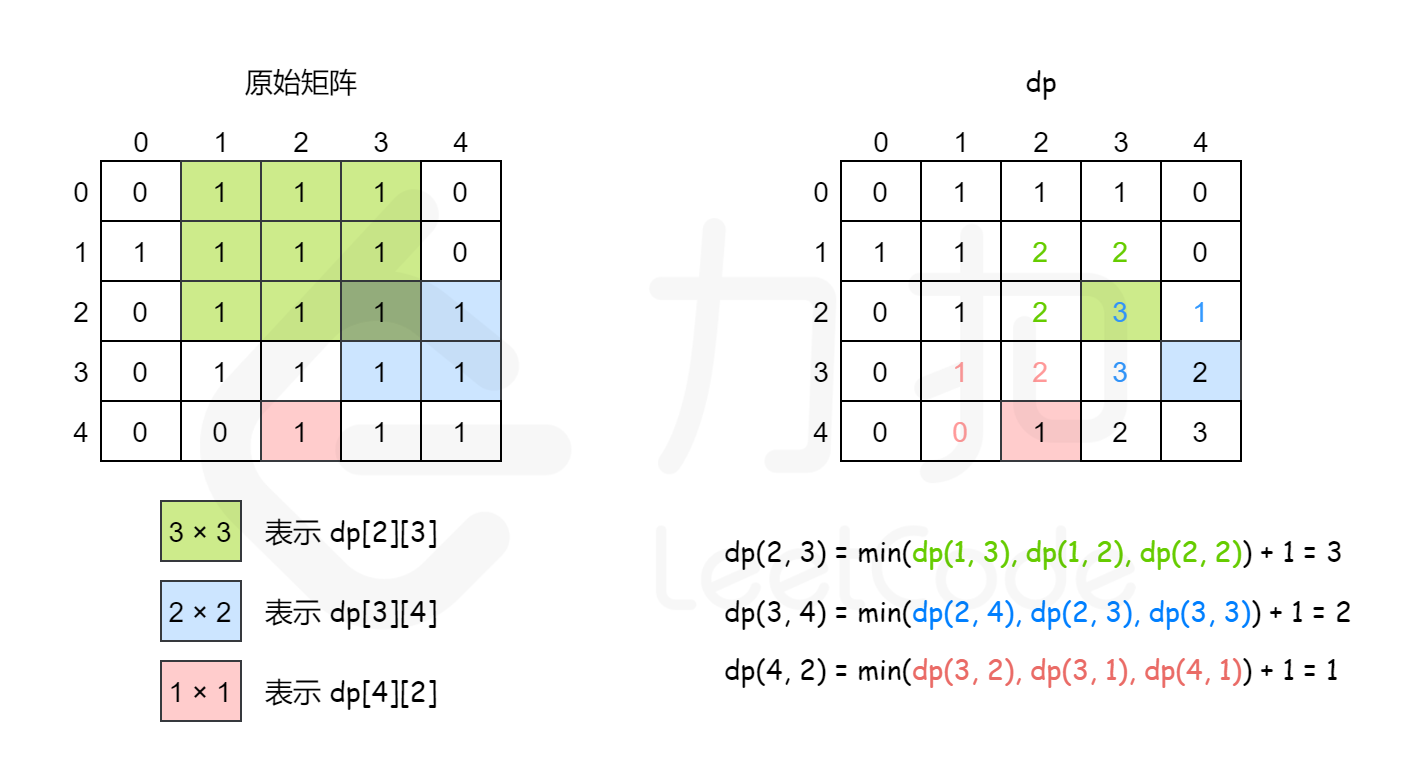
class Solution {
public int maximalSquare(char[][] matrix) {
int maxSide = 0;
if (matrix == null || matrix.length == 0 || matrix[0].length == 0) {
return maxSide;
}
int rows = matrix.length, columns = matrix[0].length;
int[][] dp = new int[rows][columns];
for (int i = 0; i < rows; i++) {
for (int j = 0; j < columns; j++) {
if (matrix[i][j] == '1') {
if (i == 0 || j == 0) {
dp[i][j] = 1;
} else {
dp[i][j] = Math.min(Math.min(dp[i - 1][j], dp[i][j - 1]), dp[i - 1][j - 1]) + 1;
}
maxSide = Math.max(maxSide, dp[i][j]);
}
}
}
int maxSquare = maxSide * maxSide;
return maxSquare;
}
}
复杂度分析
-
时间复杂度:\(O(mn)\),其中 m 和 n 是矩阵的行数和列数。需要遍历原始矩阵中的每个元素计算 dp 的值。
-
空间复杂度:\(O(mn)\),其中 m 和 n 是矩阵的行数和列数。创建了一个和原始矩阵大小相同的矩阵 dp。由于状态转移方程中的 dp(i,j) 由其上方、左方和左上方的三个相邻位置的 dp 值决定,因此可以使用两个一维数组进行状态转移,空间复杂度优化至 \(O(n)\)。
我的
初始化数组的时候记得也要记录最大边!!
class Solution {
public int maximalSquare(char[][] matrix) {
int maxSide = 0;
if (matrix == null || matrix.length == 0 || matrix[0].length == 0) {
return maxSide;
}
int rows = matrix.length, columns = matrix[0].length;
int[][] dp = new int[rows][columns];
// 初始化
for (int i = 0; i < columns; i++) {
dp[0][i] = matrix[0][i] - '0';
maxSide = Math.max(maxSide, dp[0][i]);
}
for (int i = 0; i < rows; i++) {
dp[i][0] = matrix[i][0] - '0';
maxSide = Math.max(maxSide, dp[i][0]);
}
for (int i = 1; i < rows; i++) {
for (int j = 1; j < columns; j++) {
if (matrix[i][j] == '1') {
dp[i][j] = Math.min(Math.min(dp[i - 1][j], dp[i][j - 1]), dp[i - 1][j - 1]) + 1;
maxSide = Math.max(maxSide, dp[i][j]);
}
}
}
int maxSquare = maxSide * maxSide;
return maxSquare;
}
}
当代码敲完的那一刻,是不是就感觉这个二维表也太好看了吧。。。把抽象的东西可视化了,时时刻刻都知道自己要干嘛。
笔者将不定期更新【考研或就业】的专业相关知识以及自身理解,希望大家能【关注】我。
如果觉得对您有用,请点击左下角的【点赞】按钮,给我一些鼓励,谢谢!
如果有更好的理解或建议,请在【评论】中写出,我会及时修改,谢谢啦!
本文来自博客园,作者:Nemo&
转载请注明原文链接:https://www.cnblogs.com/blknemo/p/12201940.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号