【算法】递归三步走
递归
递归实现的原理:对于递归的问题,我们一般都是从上往下递归的,直到递归到最底,再一层一层着把值返回。
一个递归函数的调用过程类似于多个函数的嵌套的调用,只不过调用函数和被调用函数是同一个函数。为了保证递归函数的正确执行,系统需设立一个工作栈。具体地说,递归调用的内部执行过程如下:
- 运动开始时,首先为递归调用建立一个工作栈,其结构包括值参、局部变量和返回地址;
- 每次执行递归调用之前,把递归函数的值参、局部变量的当前值以及调用后的返回地址压栈;
- 每次递归调用结束后,将栈顶元素出栈,使相应的值参和局部变量恢复为调用前的值,然后转向返回地址指定的位置继续执行。
在我们了解了递归的基本思想及其数学模型之后,我们如何才能写出一个漂亮的递归程序呢?我认为主要是把握好如下三个方面:
- 明确递归函数的作用;
- 明确递归终止条件与对应的解决办法;
- 找出函数的等价关系式,提取重复的逻辑缩小问题规模。
适用场景
- 对于一开始就可以写一个递归出口,以免空指针报错的,比如一开始就写
if (root == null),我们可以考虑一下使用递归,找找递推关系式。 - 对于一步一步推出来的,递推出来的,即 上一个答案与下一个有关的,都可以考虑一下递归
- 回溯法,要退回去的,也可以考虑递归
回溯法一般使用在问题可以树形化表示时的场景。
这样说明的话可能有点抽象,那么我们来换个方法说明。
当你发现,你的问题需要用到多重循环,具体几重循环你又没办法确定,那么就可以使用我们的回溯算法来将循环一层一层的进行嵌套。
就像这样:
void f(int count) {
if (count == max) {
return;
}
for (...) {
f(count+1);
}
}
这样套起来的话,无论多少重循环我们都可以满足。
递归三步走
1. 明确函数功能
1.明确函数功能:要清楚你写这个函数是想要做什么?它的输入是什么?它的输出是什么?它的参数是什么?它的全局变量是什么?
递归的时候要按照题目的要求来设置函数功能,再根据函数功能来设置函数的参数。
其实我们按照题目要求来设置函数功能,最后总是莫名其妙就把问题给解决了,可能很多人都觉得这也太奇妙了吧。
理解:其实递归的理论基础其实就是制定查找规则,按照这个规则找答案,一定能找到答案。例如,这个题:面试题 04.06. 后继者,做出来之后觉得莫名其妙就找到答案了。
问题:可是如果完全按照题目要求来设置函数功能的话,那根据先序遍历和中序遍历来确定后序遍历函数的方法参数真的能返回一个数组吗?
技巧:
- 全局变量和方法参数:(当前节点状态)这个方法的参数最好由递归时的当前阶段的状态决定!最好这个方法的参数能够记录我们当前阶段的状态!
比如说,如果我们这个方法需要实现阶乘,那么我们的方法参数需要记录当前阶乘的数字(即 当前阶段的状态)
- 返回数据:返回数据应该是我们遇到递归出口之后,需要告诉给前一步递归的信息数据!
比如,计算阶乘我们就需要在遇到递归出口之后,告诉我们前一步递归我们现在的结果数据,方便整合。
注意:递归函数的返回值最好设置为单个元素,比如说一个节点或者一个数值,告诉前一步递归我们现在的结果数据即可。
如果返回值是数组的话,我们将无法从中提取到任何有效信息来进行操作;
如果结果需要数组的话,我们可以将数组作为公共变量返回值为void,我们在方法体里面操作数组即可。
2. 寻找递归出口
2.寻找递归出口:我们需要思考,什么时候我们该结束递归了。递归一定要有结束条件,不然会永远递归下去,禁止套娃;
递归出口:一般为某深度,或叶子节点,或非叶子节点(包括根节点)、所有节点等。决定递归出去时要执行的操作。
特别注意:每次提交数组的集合(即
List<List<>>)的时候,都要记得创建一个新的数组来存放结果数组元素(即new List<>(list)),不然后面操作的都是加入集合后的那个数组。
这里需要注意的是,由于我们的节点状态可能需要多个参数来表示,所以我们的递归出口可能也并不唯一,我们有可能需要为每个状态参数来安排一个递归出口,确保我们的递归能够确实有效的出去。
例如:
我们需要注意这里的递归出口:
- 当我们操作一棵树root的时候,我们的递归出口可能是
if (root == null),- 而我们在操作两颗树t1,t2的时候,我们的递归出口应该包括这两棵树所有为null的情况,如
if (t1 == null && t2 == null)和if (t1 == null || t2 == null)这样才能概况完所有为null的出口情况。
并且值得注意的是,我们的递归出口并不一定都是在最开头的位置,我们一般在最开头设置递归出口是希望递归能以最快的速度出去;
但是有时候我们在对当前节点进行一些相关处理操作之后我们就希望判断一下能不能递归出口,所以递归出口有可能是在代码中间的,大家需要灵活应用。
在这一步,我们需要思考题目需要的解在哪里?是在某一具体的深度、还是在叶子结点、还是在非叶子结点(包括根节点)、还是在每个节点、还是在从跟结点到叶子结点的路径?
-
在某一具体的深度:
if (depth >= n)
很常见,大部分就是 -
在每个节点:
if (true)
面试题 08.04. 幂集
3. 找出递推关系
3.找出递推关系:开始实现递归,一步一步递推出最终结果。
一般是前后数据有所关联,递推。
三步走实例
1. 明确函数功能
第一步,明确这个函数的功能是什么,它要完成什么样的一件事。
而这个功能,是完全由你自己来定义的。也就是说,我们先不管函数里面的代码是什么、怎么写,而首先要明白,你这个函数是要用来干什么的。
明确函数功能其实就是明确题目的目的、递归的目的。比如说一棵树,你就可以对它左子树操作、右子树操作,然后再写对根节点的操作,这样就能完成对整个树的递归。
例如:求解任意一个数的阶乘
要做出这个题,
第一步,要明确即将要写出的这个函数的功能为:算n的阶乘。
//算n的阶乘(假设n不为0)
int f(int n) {
}
2. 寻找递归出口(初始条件)
递归就是在函数实现的内部代码中,调用这个函数本身。所以,我们必须要找出递归的结束条件,不然的话,会一直调用自己,一直套娃,直到内存充满。
- 必须有一个明确的结束条件。因为递归就是有“递”有“归”,所以必须又有一个明确的点,到了这个点,就不用“递下去”,而是开始“归来”。
第二步,我们需要找出当参数为何值时,递归结束,之后直接把结果返回。
(一般为初始条件,然后从初始条件一步一步扩充到最终结果)注意:这个时候我们必须能根据这个参数的值,能够直接知道函数的结果是什么。
让我们继续完善上面那个阶乘函数。
第二步,寻找递归出口:我们需要思考,什么时候我们该结束递归了。
当n=1时,我们能够直接知道f(1)=1,此时我们的结果已知,可以结束递归了;
那么递归出口就是n=1时函数返回1。
如下:
//算n的阶乘(假设n不为0)
int f(int n) {
if(n == 1) {
return 1;
}
}
当然,当n=2时,我们也是知道f(2)等于多少的,n=2也可以作为递归出口。递归出口可能并不唯一的。
这里需要注意的是,由于我们的节点状态可能需要多个参数来表示,所以我们的递归出口可能也并不唯一,我们有可能需要为每个状态参数来安排一个递归出口,确保我们的递归能够确实有效的出去。
我们需要注意这里的递归出口:
- 当我们操作一棵树root的时候,我们的递归出口可能是
if (root == null), - 而我们在操作两颗树t1,t2的时候,我们的递归出口应该包括这两棵树所有为null的情况,如
if (t1 == null && t2 == null)和if (t1 == null || t2 == null)这样才能概况完所有为null的出口情况。
3. 找出递推关系
第三步,我们要从初始条件一步一步递推到最终结果。
类比:数学归纳法,多米诺骨牌
- 初始条件:f(1) = 1
- 递推关系式:f(n) = f(n-1)*n
递归:
- 递:f(n) = n * f(n-1),将f(n)→f(n-1)了。这样,问题就由n缩小为了n-1,并且为了原函数f(n)不变,我们需要让f(n-1)乘以n。就这样慢慢从f(n),f(n-1)“递”到f(1)。
- 归:这样就可以从n=1,一步一步“归”到n=2,n=3...
// 算n的阶乘(假设n不为0)
int f(int n) {
if(n = 1) {
return n;
}
// 把f(n)的递推关系写进去
return f(n-1) * n;
}
到这里,递归三步走就完成了,那么这个递归函数的功能我们也就实现了。
可能初学的读者会感觉很奇妙,这就能算出阶乘了?
那么,我们来一步一步推一下。
f(1)=1
f(2)=f(1)*2=2
f(3)=f(2)*3=2*3=6
...
你看看是不是解决了,n都能递推出来!
这里的递推关系也可以为boolean,比如判断二叉平衡树
public boolean isBalanced(TreeNode root) {
if (root == null) {
return true;
}
return Math.abs(h(root.left) - h(root.right)) <= 1 && isBalanced(root.left) && isBalanced(root.right);
}
当满足所有条件时,才返回true;否则,返回false。
这是一种技巧,大家可以留意一下。
优化思路
这里的递归优化思路和回溯算法中的优化思路基本一致,两者可以互通,大家可以把我的两篇文章都看看作对比。
重复计算
其实递归当中有很多子问题被重复计算。
对于斐波那契数列,f(n) = f(n-1)+f(n-2)。
递归调用的状态图如下:
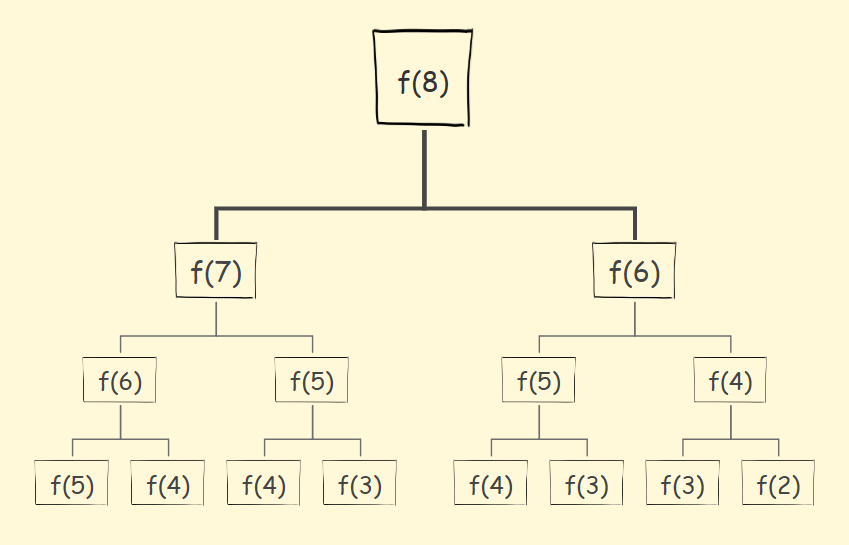
其中,递归计算时f(6)、f(5)...都被重复了很多次,这是极大的浪费,当n越大,因重复计算浪费的就越多,所以我们必须要进行优化。
-
优化思路:
- 建立一个数组,将子问题的计算结果保存起来。
- 判断之前是否计算过:
- 计算过,取出来用
- 没有计算过,再递归计算
-
实例:
- 把n作为数组下标,f(n)作为值。
例如arr[n] = f(n)。 - f(n)还没有计算过的时候,我们让arr[n]等于一个特殊值。
例如arr[n] = -1。 - 当我们要判断的时候,
- 如果 arr[n] = -1,则证明f(n)没有计算过;
- 否则,f(n)就已经计算过了,且f(n) = arr[n]。
直接把值取出来用就行了。
- 把n作为数组下标,f(n)作为值。
代码如下:
// 我们实现假定 arr 数组已经初始化好的了。
int f(int n) {
if(n <= 1) {
return n;
}
//先判断有没计算过
if(arr[n] != -1) {
//计算过,直接返回
return arr[n];
}else {
// 没有计算过,递归计算,并且把结果保存到 arr数组里
arr[n] = f(n-1) + f(n-1);
reutrn arr[n];
}
}
剪枝
剪枝:就是在算法优化中,通过某种判断,避免一些不必要的遍历过程。
形象的说,就是剪去了搜索树中的某些“枝条”,故称剪枝。
应用剪枝优化的核心问题是设计剪枝判断方法,即 确定哪些枝条应当舍弃,哪些枝条应当保留的方法。
类比:这个剪枝其实就像人生,一个人因很多种选择,而到达不同的结局,然而有些选择我们一开始就可以判断是bad end了,那么我们在一开始就不会选择那样的道路,而不是到达结局才发现是bad end,撞了南墙才知道疼。
未剪枝——不撞南墙不死心,到最后结局才能判断是否是自己想要的结果
剪枝——及时止损
剪枝可分为:
- 可行性剪枝
- 最优性剪枝
可行性剪枝
可行性剪枝:该方法判断继续搜索能否得出答案,如果不能直接回溯。
最优性剪枝
最优性剪枝:又称为上下界剪枝,是一种重要的搜索剪枝策略。
它记录当前得到的最优值,如果当前结点已经无法产生比当前最优解更优的解时,可以提前回溯。
回溯算法可以设置标志位flag代表找到了,找到了就直接返回,避免继续回溯浪费时间;或者说找到了方法就返回true。。等方法都行。
可以看我写的回溯算法中的例题《剑指 Offer 12. 矩阵中的路径》
自底向上(递归向上)
上面说了那么多,都是自顶向下(把问题逐步变小)的递归(递归向下)。
(但是我比较习惯按自顶向下做,按自底向上思考递归,因为比较符合数学归纳法,顺着推)
除了自顶向下,其实自底向上也是可以完成任务的!
例如,上面的斐波那契数列
自顶向下:把问题逐渐减小
int Fibonacci(int n) {
if(n == 0)
return 0;
if(n == 1)
return 1;
return Fibonacci(n-1) + Fibonacci(n-2);
}
自底向上:用底部的小问题答案,组装成最后的大问题答案
int Fibonacci(int n) {
int array[n] = {0};
array[1] = 1;
for(int i = 2; i < n; i++)
array[i] = array[i-1] + array[i-2];
}
尾递归
递归 中的 尾递归,其实就好比 动态规划 中的 滚动数组
理解:****尾递归的本质,其实是将递归方法中的需要的“所有状态”通过方法的参数传入下一次调用中。
递归与尾递归
关于递归操作,相信大家都已经不陌生。简单地说,一个函数直接或间接地调用自身,是为直接或间接递归。例如,我们可以使用递归来计算一个单向链表的长度:
public class Node {
public Node(int value, Node next) {
this.Value = value;
this.Next = next;
}
public int Value { get; private set; }
public Node Next { get; private set; }
}
编写一个递归的GetLength方法:
public static int getLengthRecursively(Node head) {
if (head == null) return 0;
return getLengthRecursively(head.Next) + 1;
}
在调用时,getLengthRecursively()方法会不断调用自身,直至满足递归出口。对递归有些了解的朋友一定猜得到,如果单项链表十分长,那么上面这个方法就可能会遇到栈溢出,也就是抛出StackOverflowException。这是由于每个线程在执行代码时,都会分配一定尺寸的栈空间(Windows系统中为1M),每次方法调用时都会在栈里储存一定信息(如参数、局部变量、返回地址等等),这些信息再少也会占用一定空间,成千上万个此类空间累积起来,自然就超过线程的栈空间了。
不过这个问题并非无解,我们只需把递归改成如下形式即可(在这篇文章里我们不考虑非递归的解法):
public static int getLengthTailRecursively(Node head, int acc) {
if (head == null) return acc;
return getLengthTailRecursively(head.Next, acc + 1);
}
getLengthTailRecursively()方法多了一个acc参数,acc的为accumulator(累加器)的缩写,它的功能是在递归调用时“积累”之前调用的结果,并将其传入下一次递归调用中。
这就是getLengthTailRecursively()方法与getLengthRecursively()方法相比在递归方式上最大的区别:getLengthRecursive()方法在递归调用后还需要进行一次“+1”,而getLengthTailRecursively()的递归调用属于方法的最后一个操作。
这就是所谓的“尾递归”。与普通递归相比,由于尾递归的调用处于方法的最后,因此方法之前所积累下的各种状态对于递归调用结果已经没有任何意义,因此完全可以把本次方法中留在堆栈中的数据完全清除,把空间让给最后的递归调用。这样的优化便使得递归不会在调用堆栈上产生堆积,意味着即使是“无限”递归也不会让堆栈溢出。这便是尾递归的优势。
有些朋友可能已经想到了,尾递归的本质,其实是将递归方法中的需要的“所有状态”通过方法的参数传入下一次调用中。对于getLengthTailRecursively方法,我们在调用时需要给出acc参数的初始值:
getLengthTailRecursively(head, 0)
为了进一步熟悉尾递归的使用方式,我们再用著名的“菲波纳锲”数列作为一个例子。传统的递归方式如下:
public static int fibonacciRecursively(int n) {
if (n < 2) return n;
return fibonacciRecursively(n - 1) + fibonacciRecursively(n - 2);
}
而改造成尾递归,我们则需要提供两个累加器:
// 运算位 + 运算位 -> 结果位
// acc1 + acc2 -> (acc1 + acc2)
// acc2 + (acc1 + acc2) -> 结果位
public static int fibonacciTailRecursively(int n, int acc1, int acc2) {
if (n == 0) return acc1;
return fibonacciTailRecursively(n - 1, acc2, acc1 + acc2);
}
于是在调用时,需要提供两个累加器的初始值:
fibonacciTailRecursively(10, 0, 1)
1、递归
前言:今天上网看帖子的时候,看到关于尾递归的应用(http://bbs.csdn.net/topics/390215312),大脑中感觉这个词好像在哪里见过,但是又想不起来具体是怎么回事。如是乎,在网上搜了一下,顿时豁然开朗,知道尾递归是怎么回事了。下面就递归与尾递归进行总结,以方便日后在工作中使用。
关于递归的概念,我们都不陌生。简单的来说递归就是一个函数直接或间接地调用自身,是为直接或间接递归。一般来说,递归需要有边界条件、递归前进段和递归返回段。当边界条件不满足时,递归前进;当边界条件满足时,递归返回。
用递归需要注意以下两点:
- 递归就是在过程或函数里调用自身。
- 在使用递归策略时,必须有一个明确的递归结束条件,称为递归出口。
递归一般用于解决三类问题:
- 数据的定义是按递归定义的。(Fibonacci函数,n的阶乘)
- 问题解法按递归实现。(回溯)
- 数据的结构形式是按递归定义的。(二叉树的遍历,图的搜索)
递归的缺点:
递归解题相对常用的算法如普通循环等,运行效率较低。因此,应该尽量避免使用递归,除非没有更好的算法或者某种特定情况,递归更为适合的时候。在递归调用的过程当中系统为每一层的返回点、局部量等开辟了栈来存储,因此递归次数过多容易造成栈溢出。
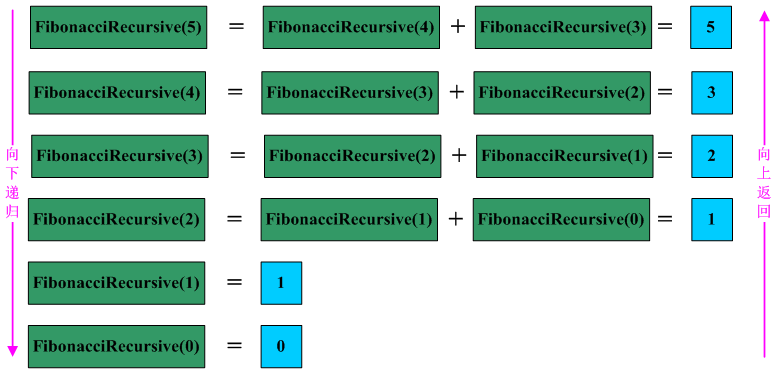
用线性递归实现Fibonacci函数,程序如下所示:
int FibonacciRecursive(int n) {
if (n < 2)
return n;
return (FibonacciRecursive(n-1)+FibonacciRecursive(n-2));
}
递归写的代码非常容易懂,完全是根据函数的条件进行选择计算机步骤。例如现在要计算n=5时的值,递归调用过程如下图所示:
2、尾递归
顾名思义,尾递归就是从最后开始计算, 每递归一次就算出相应的结果, 也就是说, 函数调用出现在调用者函数的尾部, 因为是尾部, 所以根本没有必要去保存任何局部变量. 直接让被调用的函数返回时越过调用者, 返回到调用者的调用者去。尾递归就是把当前的运算结果(或路径)放在参数里传给下层函数,深层函数所面对的不是越来越简单的问题,而是越来越复杂的问题,因为参数里带有前面若干步的运算路径。
尾递归是极其重要的,不用尾递归,函数的堆栈耗用难以估量,需要保存很多中间函数的堆栈。比如f(n, sum) = f(n-1) + value(n) + sum; 会保存n个函数调用堆栈,而使用尾递归f(n, sum) = f(n-1, sum+value(n)); 这样则只保留后一个函数堆栈即可,之前的可优化删去。
采用尾递归实现Fibonacci函数,程序如下所示:
int FibonacciTailRecursive(int n,int ret1,int ret2) {
if(n==0)
return ret1;
return FibonacciTailRecursive(n-1,ret2,ret1+ret2);
}
int FibonacciTailRecursive(int n,int ret1,int ret2) {
if(n==0)
return ret1;
// 这种感觉就是动态规划的优化——滚动数组,运算位前进,只不过是借用递归来实现不确定的循环层数
int a = ret2;
int b = ret1 + ret2;
return FibonacciTailRecursive(n-1,a,b);
}
例如现在要计算n=5时的值,尾递归调用过程如下图所示:

从图可以看出,为递归不需要向上返回了,但是需要引入而外的两个空间来保持当前的结果。
为了更好的理解尾递归的应用,写个程序进行练习。采用直接递归和尾递归的方法求解单链表的长度,C语言实现程序如下所示:
#include <stdio.h>
#include <stdlib.h>
typedef struct node {
int data;
struct node* next;
}node,*linklist;
void InitLinklist(linklist* head) {
if(*head != NULL)
free(*head);
*head = (node*)malloc(sizeof(node));
(*head)->next = NULL;
}
void InsertNode(linklist* head,int d) {
node* newNode = (node*)malloc(sizeof(node));
newNode->data = d;
newNode->next = (*head)->next;
(*head)->next = newNode;
}
//直接递归求链表的长度
int GetLengthRecursive(linklist head) {
if(head->next == NULL)
return 0;
return (GetLengthRecursive(head->next) + 1);
}
//采用尾递归求链表的长度,借助变量acc保存当前链表的长度,不断的累加
int GetLengthTailRecursive(linklist head,int *acc) {
if(head->next == NULL)
return *acc;
*acc = *acc+1;
return GetLengthTailRecursive(head->next,acc);
}
void PrintLinklist(linklist head) {
node* pnode = head->next;
while(pnode) {
printf("%d->",pnode->data);
pnode = pnode->next;
}
printf("->NULL\n");
}
int main() {
linklist head = NULL;
int len = 0;
InitLinklist(&head);
InsertNode(&head,10);
InsertNode(&head,21);
InsertNode(&head,14);
InsertNode(&head,19);
InsertNode(&head,132);
InsertNode(&head,192);
PrintLinklist(head);
printf("The length of linklist is: %d\n",GetLengthRecursive(head));
GetLengthTailRecursive(head,&len);
printf("The length of linklist is: %d\n",len);
system("pause");
}
程序测试结果如下图所示:

实例
斐波那契数列
斐波那契数列的是这样一个数列:1、1、2、3、5、8、13、21、34....,即第一项 f(1) = 1,第二项 f(2) = 1.....,第 n 项目为 f(n) = f(n-1) + f(n-2)。求第 n 项的值是多少。
-
明确函数功能:f(n)为求第n项的值
// 1.f(n)为求第n项的值 int f(int n) { } -
寻找递归出口:f(1)=1,f(2)=1
// 1.f(n)为求第n项的值 int f(int n) { // 2.递归出口 if(n <= 2) { return 1; } } -
找出递推关系:f(n) = f(n-1) + f(n-2)
// 1.f(n)为求第n项的值 int f(int n) { // 2.递归出口 if(n <= 2) { return 1; } // 3.递推关系 return f(n-1) + f(n-2); }
小青蛙跳台阶
一只青蛙一次可以跳上1级台阶,也可以跳上2级。求该青蛙跳上一个n级的台阶总共有多少种跳法。
-
明确函数功能:f(n)为青蛙跳上一个n级的台阶总共有多少种跳法
int f(int n) { } -
寻找递归出口:f(0)=0,f(1)=1
int f(int n) { // 递归出口 if(n <= 1) { return n; } } -
找出递推关系:f(n) = f(n-1)+f(n-2)
int f(int n) { // 递归出口 if(n <= 2) { return 1; } // 递推关系 return f(n-1) + f(n-2); }
剑指 Offer 24. 反转链表
定义一个函数,输入一个链表的头节点,反转该链表并输出反转后链表的头节点。
示例:
输入: 1->2->3->4->5->NULL
输出: 5->4->3->2->1->NULL
答案
初始
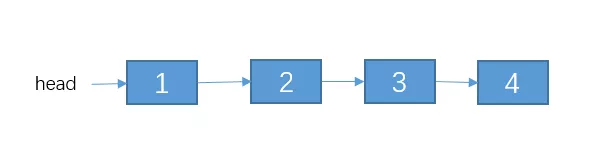
反转head.next
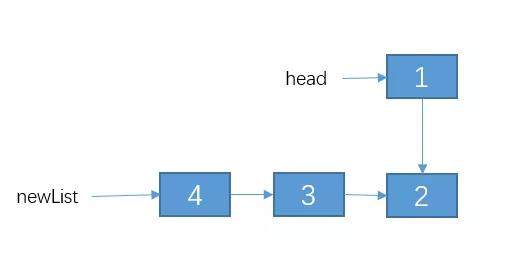
接下来只需要把节点 2 的 next 指向 1,然后把 1 的 next 指向 null,不就行了?,即通过改变 newList 链表之后的结果如下:
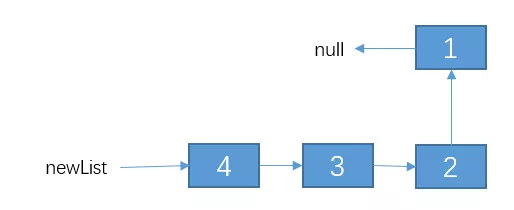
// 试试递归
class Solution {
public ListNode reverseList(ListNode head) {
if (head == null || head.next == null) {
return head;
}
ListNode newHead = reverseList(head.next); // 反转head.next,也就是说,现在的head.next变为尾结点了
ListNode tail = head.next; // 尾结点
tail.next = head; // 尾结点加上还没有反转的头节点
head.next = null; // 头节点的下一个置为null,作为新的尾结点
return newHead;
}
}
约瑟夫环问题 剑指 Offer 62. 圆圈中最后剩下的数字
0,1,···,n-1这n个数字排成一个圆圈,从数字0开始,每次从这个圆圈里删除第m个数字(删除后从下一个数字开始计数)。求出这个圆圈里剩下的最后一个数字。
例如,0、1、2、3、4这5个数字组成一个圆圈,从数字0开始每次删除第3个数字,则删除的前4个数字依次是2、0、4、1,因此最后剩下的数字是3。
示例 1:
输入: n = 5, m = 3
输出: 3
示例 2:
输入: n = 10, m = 17
输出: 2
答案
class Solution {
public int lastRemaining(int n, int m) {
// 约瑟夫环问题
if (n == 1) {
return 0;
}
// 1. 我们首先删除第 (m % n) 个元素
// 2. 删除之后从下一个元素开始计数,即 第 (m % n) 个元素变成了我们的首元素。
// (这是一个循环链表噢,所以剩下的链表为 以第(m % n)个元素开头的长度为n - 1的链表)
// 3. 我们只需要递归返回获取我们这长度为 n - 1 的链表以 m 为跨度删除,会剩下第几个元素
// 4. 假设这个元素为第 x 个元素,那么我们链表长度为 n 时,剩下的元素应该是从第一次删除的第(m % n)个元素为开头算起往后的第 x 个元素。
// 举个例子:我们链表长度为 n - 1 时删除,会剩下第 1 个元素
// 那么我们链表长度为 n 时第一次删除,会删除第(m % n)个元素,
// 然后再剩下的以第(m % n)个元素开头的,长度为 n - 1的链表中删除,最终会剩下开头的第 1 个元素,只不过这个第 1 个元素现在的序号是从 (m % n) 开始往后算的(当长度为 n 时,不包括第(m % n)个元素,它已经被删除了)
// 注意:应该从第一次删除的第(m % n)个元素为开头算起(长度为n - 1的链表不包含这个元素)往后的第 1 个元素。
int x = lastRemaining(n - 1, m);
return (m % n + x) % n;
// return (m + x) % n; // 等价于上面的式子
}
}
// class Solution {
// public int lastRemaining(int n, int m) {
// // 约瑟夫环问题
// // 我们循环遍历数组,将要删除的数字置为n,每次遍历都要跳过n去执行m次,一共要删除n-1轮,留下一个
// int cur = 0;
// for (int i = n; i > 1; i++) {
// int times = m;
// while (times != 0) {
// if (cur == n) {
// cur = (cur + 1) % i; // 前进
// continue;
// }
// cur = (cur + 1) % i; // 前进
// times--;
// }
// cur = n; // 做到这里发现不对劲了,因为它不是遍历数组,我们的改变无法持久化存储!!!!
// }
// }
// }
剑指 Offer 16. 数值的整数次方
实现 pow(x, n) ,即计算 x 的 n 次幂函数(即,xn)。不得使用库函数,同时不需要考虑大数问题。
示例 1:
输入:x = 2.00000, n = 10
输出:1024.00000
示例 2:
输入:x = 2.10000, n = 3
输出:9.26100
示例 3:
输入:x = 2.00000, n = -2
输出:0.25000
解释:2-2 = 1/22 = 1/4 = 0.25
超时答案
class Solution {
public double myPow(double x, int n) {
return n >= 0 ? f(x, n) : 1.0 / f(x,n);
}
public double f(double x, int n) {
if (n == 0) {
return 1;
}
if (n > 0) {
return x * f(x, n - 1);
}
if (n < 0) {
return x * f(x, n + 1);
}
return 1;
}
}
快速幂
「快速幂算法」的本质是分治算法。举个例子,如果我们要计算 \(x^{64}\) ,我们可以按照:
的顺序,从 x 开始,每次直接把上一次的结果进行平方,计算 6 次就可以得到 \(x^{64}\) 的值,而不需要对 x 乘 63 次 x。
再举一个例子,如果我们要计算 \(x^{77}\),我们可以按照:
的顺序,在 \(x \to x^2\),\(x^2 \to x^4\),\(x^{19} \to x^{38}\) 这些步骤中,我们直接把上一次的结果进行平方,而在 \(x^4 \to x^9\),\(x^9 \to x^{19}\),\(x^{38} \to x^{77}\) 这些步骤中,我们把上一次的结果进行平方后,还要额外乘一个 x。
直接从左到右进行推导看上去很困难,因为在每一步中,我们不知道在将上一次的结果平方之后,还需不需要额外乘 x。但如果我们从右往左看,分治的思想就十分明显了:
- 当我们要计算 \(x^n\) 时,我们可以先递归地计算出 \(y = x^{\lfloor n/2 \rfloor}\),其中 \(\lfloor a \rfloor\) 表示对 a 进行下取整;
- 根据递归计算的结果,如果 n 为偶数,那么 \(x^n = y^2\);如果 n 为奇数,那么 \(x^n = y^2 \times x\);
- 递归的边界为 \(n = 0\),任意数的 0 次方均为 1。
由于每次递归都会使得指数减少一半,因此递归的层数为 \(O(\log n)\),算法可以在很快的时间内得到结果。
// 很遗憾,上面的递归遇到n为2147483647的时候爆栈了,只能换种方法了。。
// 试试快速幂
class Solution {
public double myPow(double x, int n) {
if(n == 0){
return 1;
}else if(n < 0){ // 如果是负数,那就把它变成正数来求解
return 1 / (x * myPow(x, - n - 1));
}else if(n % 2 == 1){ // 正数,幂为奇数我们可以把它变成偶数
return x * myPow(x, n - 1);
}else{ // 正数,幂为偶数我们可以使用快速幂
// 快速幂:x → x2 → x4 → x8 → x16 → x32 → x64
return myPow(x * x, n / 2);
}
}
}
复杂度分析
-
时间复杂度:\(O(\log n)\),即为递归的层数。
-
空间复杂度:\(O(\log n)\),即为递归的层数。这是由于递归的函数调用会使用栈空间。
笔者将不定期更新【考研或就业】的专业相关知识以及自身理解,希望大家能【关注】我。
如果觉得对您有用,请点击左下角的【点赞】按钮,给我一些鼓励,谢谢!
如果有更好的理解或建议,请在【评论】中写出,我会及时修改,谢谢啦!
本文来自博客园,作者:Nemo&
转载请注明原文链接:https://www.cnblogs.com/blknemo/p/12197931.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号