【数据结构】数组及其常用算法
矩阵在计算机图形学、工程计算中占有举足轻重的地位。在数据结构中考虑的是如何用最小的内存空间来存储同样的一组数据。所以,我们不研究矩阵及其运算等,而把精力放在如何将矩阵更有效地存储在内存中,并能方便地提取矩阵中的元素。
- 数组的存储结构
一个数组的所有元素在内存中占用一段连续的存储空间。
- 以行优先方式存储
- 以列优先方式存储
数组A[M, N],起始地址为base,则元素A[i, j]的地址为?
\(总数组矩形面积=M行\*N列\)
- 行优先存储:\(base+i\*N+j\),相当于计算从0到i-1的完整行矩形面积(长i宽N),加上不完整的一行1*j。
- 列优先存储:\(base+j\*M+i\),相当于计算从0到j-1的完整列矩形面积(长j宽M),加上不完整的一列1*i。
数组 A[0..5,0..6]的每个元素占五个字节,将其按列优先次序存储在起始地址为 1000 的内存单元中,则元素 A[5,5]的地址是( A )。
A. 1175 B. 1180 C. 1205 D. 1210
- 需要注意的是,当求出数组A[0,0]到特定元素A[5,5]的那部分时,不要着急着写出地址。
因为我们所求出来的所占空间,是A[0,0]的首地址从1开始数(或者说 从A[0,0]的首地址开始到A[5,5]的尾地址(即A[6,1]的首地址))计算时的元素个数6*6=36(即 从A[0,0]到A[5,5],包含A[5,5]有36个元素,但是题目的起始地址一般为0。
所以应该A[0,0]的首地址从0开始数(或者说 从A[0,0]的首地址开始到A[5,5]的首地址)计算的话,则是36-1=35(即 从A[0,0]到A[5,5],不包含A[5,5]有35个元素)。
例如,首地址从0开始数,即意味着当首地址为5时,只存了一个元素的空间,但是地址却是第二个元素的(首)地址。
1 抽象数据类型数组的说明
2 数组的物理结构
3 特殊矩阵的压缩存储: 对称矩阵与三对角矩阵的压缩存储
4 稀疏矩阵的压缩存储:三元组顺序表与十字链表
5 稀疏矩阵的运算(转置算法)
6 广义表的概念:概念、物理结构、递归算法
- 计算数组中给顶元素的地址
- 数组的存储方式(按行或按列优先存放)
- 计算给定元素的前面的元素个数s
- 每个元素的存储空间k
- 该元素地址=起始元素地址+s*k
特殊矩阵
特殊矩阵压缩存储后仍然具有随机存储特性。(只用计算公式即可,无需查找时间)
二维数组→线性
注意:(因为一维数组下标是从0开始的,个数要-1,相当于减掉了自身,所以只用计算前面的元素个数,)(如果一位数组从1开始,就不用-1了,那么就不是前面了,就要加上本身aij,计算自身和前面的元素个数)(如果从1开始,那么下面的公式就要+1)
对称矩阵
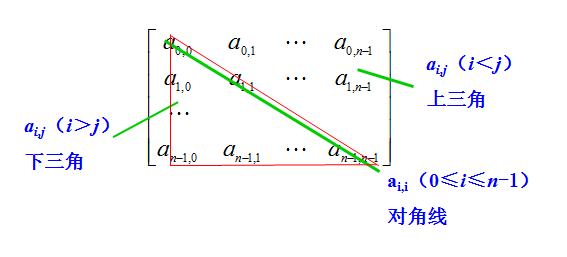
对称矩阵:矩阵中的元素满足\(a_{i,j}\)=\(a_{j,i}\),另外矩阵必须是方阵。
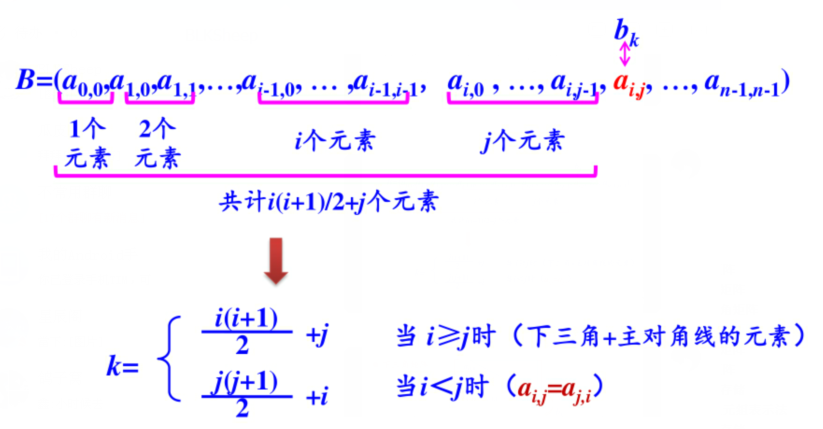
- 问题:假设有一个n*n的对称矩阵,第一个元素是\(a_{0,0}\),请用一种存储效率较高的存储方式将其存储在一位数组中。
- 解答:将对称矩阵A[0...n-1,0...n-1],存放在一维数据B[n(n+1)/2]中,即 元素\(a_{i,j}\)存放在\(b_k\)中。(只存放主对角线和下三角区的元素)
注意:(因为一维数组下标是从0开始的,个数要-1,相当于减掉了自身,所以只用计算前面的元素个数,)(如果一位数组从1开始,就不用-1了,那么就不是前面了,就要加上本身aij,计算自身和前面的元素个数)
- 在数组B中(下标从0开始),位于\(a_{i,j}\)(i≥j)前面的元素个数为:
- 第0行:1个元素
- 第1行:2个元素
- ...
- 第i-1行:i个元素
注意:0到i-1是等差序列(都是完整的)
- 第i行(不完整):j个元素
- 共计i(i+1)/2+j个元素
- 元素下标k与(i,j)之间的对应关系如下:\[k=\begin{cases} {{i(i+1)}\over{2}}+j & \text{i≥j,下三角区及对角线}\\ {{j(j+1)}\over{2}}+i & \text{i<j,上三角区}\\ \end{cases}\]
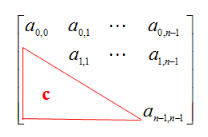
上三角矩阵
其中下三角元素均为常数C或0的n阶矩阵称为上三角矩阵。
- 问题:假设有一个n*n的上三角矩阵,第一个元素是\(a_{0,0}\),请用一种存储效率较高的存储方式将其存储在一位数组中。
- 解答:将对称矩阵A[0...n-1,0...n-1],存放在一位数据B[n(n+1)/2]中,即 元素\(a_{i,j}\)存放在b_k中。(只存放主对角线和下三角区的元素)
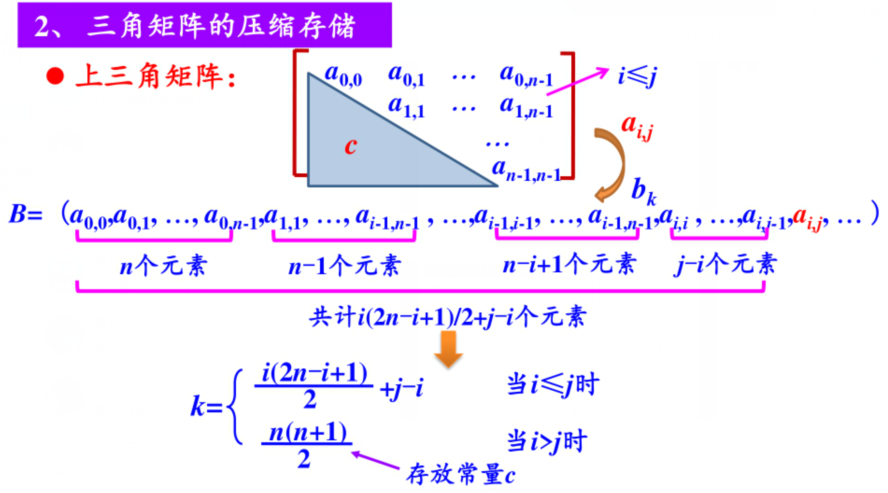
- 在数组B中(下标从0开始),位于\(a_{i,j}\)(i≥j)前面的元素个数为:
- 第0行:n个元素
- 第1行:n-1个元素
- ...
- 第i-1行:n-(i-1)=n-i+1个元素
注意:0到i-1是等差序列(都是完整的)
- 第i行(不完整):(n-i)-(n-j)=j-i个元素
注意:n-i为第i行总元素,n-j为j及j后面的元素个数,相减则为j前面的元素个数
- 共计i(2n-i+1)/2+j-i个元素
- 元素下标k与(i,j)之间的对应关系如下:\[k=\begin{cases} {{i(2n-i+1)}\over{2}}+j-i & \text{i≤j,上三角区及对角线}\\ {{n(n+1)}\over{2}} & \text{i>j,下三角区(存放常量C)(放在最后一个位置)}\\ \end{cases}\]
下三角矩阵
其中上三角元素均为常数C或0的n阶矩阵称为下三角矩阵。
- 问题:假设有一个n*n的下三角矩阵,第一个元素是\(a_{0,0}\),请用一种存储效率较高的存储方式将其存储在一位数组中。
- 解答:将对称矩阵A[0...n-1,0...n-1],存放在一位数据B[n(n+1)/2]中,即 元素\(a_{i,j}\)存放在\(b_k\)中。(只存放主对角线和下三角区的元素)
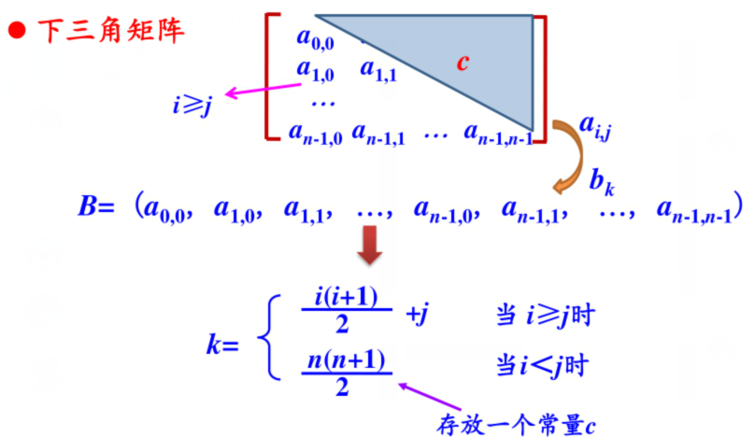

- 在数组B中(下标从0开始),位于\(a_{i,j}\)(i≥j)前面的元素个数为:
- 第0行:1个元素
- 第1行:2个元素
- ...
- 第i-1行(0到i-1是等差序列):i个元素
- 第i行(不完整):j个元素
- 共计i(2n-i+1)/2+j-i个元素
- 元素下标k与(i,j)之间的对应关系如下:\[k=\begin{cases} {{i(i+1)}\over{2}}+j & \text{i≥j,下三角区及对角线}\\ {{n(n+1)}\over{2}} & \text{i<j,上三角区(存放常量C)(放在最后一个位置)}\\ \end{cases}\]
对角矩阵
对角矩阵:也称带状矩阵,它的所有非零元素都集中在以主对角线为中心的两侧的带状区域内(对角线的个数为奇数)。换句话说,除了主对角线和主对角线两边的对角线外,其他元素的值均为0。
-
问题:对于一个按照行优先存储的三对角矩阵,求出第i行带状区域内第一个元素X在一维数组中的下标

-
当b=1时,称为三对角矩阵,其压缩地址计算公式如下:****$$k=2i+j$$
稀疏矩阵
稀疏矩阵:如果\(A_{m*n}\)中非零元素的个数远远小于总元素的个数,则这个矩阵可以被称为是稀疏矩阵。
稀疏矩阵压缩存储后并不具有随机存储特性。(使用顺序或者链式存储,需要查找时间)
- 稀疏矩阵的压缩存储方法是只存储非0元素。
顺序存储
三元组表示法
- 稀疏矩阵中的每一个非0元素需由一个三元组(i,j,value)唯一确定。(约定非零元素通常以行序为主序顺序排列)
其中,i表示行,j表示列,value表示元素值。
typedef struct {
float val;
int i;
int j;
}Trimat; //三元组结构体
Trimat trimat[maxSize+1];
伪地址表示法
- 伪地址是指该元素在矩阵中(包括0元素在内)按照行优先顺序的相对位置,用(value,location)的形式进行存储。
其中,value表示矩阵的具体数值,loaction表示其伪地址值。
- 伪地址/列数=行号,伪地址%列数=列号
链式存储
邻接表表示法
- 邻接表表示法:创建一个一维数组,数组的下标与矩阵的行号相对应,而数组中的每个元素是一个指针。指针指向一个存储了相应行元素信息的线性表,其中的信息包括元素值,元素列号以及下一个元素的指针。
十字链表表示法
-
每行的所有结点链起来构成一个带行头结点的循环单链表。以hi作为第i行的头结点。
-
每列的所有结点链起来构成一个带列头结点的循环单链表。以hi作为第i列的头结点。
-
行列头结点可以共享。
-
行列头结点个数=MAX(m,n)
-
增加一个总头结点,并把所有行、列头结点链起来构成一个循环单链表。
-
十字链表表示法:每个十字链表都有一个头结点,头结点共有五个域,分别是矩阵的行数、列数、非0元素的个数、矩阵元素的行数组以及矩阵元素的列数组。两个数组都存储了指向矩阵中非零元素的指针。
-
在十字链表中,为每个非0元素申请一个元素结点,结点包括五个域,分别是行号、列号、元素值、指向同一行下个元素的指针以及指向同一列下个元素的指针。
矩阵转置
矩阵转置:把原本第i行第j列的元素存储在新矩阵中第j行第i列的位置。
广义表
广义表(Lists,又称列表)是线性表的推广。线性表定义为n≥0个元素a0,a1,...,an的有限序列。线性表的元素仅限于原子项,院子是作为结构上不可分割的成分,它可以是一个数或一个结构,若放松对表元素的这种限制,容许它们具有自身结构,这样就产生了广义表的概念。
- 可共享:一个广义表的子表可以是其他已经被定义的广义表的引用,可以为其他广义表所共享。
- 可递归:一个广义表可以是递归定义的,自己可以作为自己的子表。
- 广义表的长度:为表中最上层元素的个数
- 广义表的深度:为表中括号的最大层数,求深度时可以将子表全部展开。
- 广义表的表头(Head)和表尾(Tail):当广义表非空时,第一个元素为广义表的表头,其余元素组成的表是广义表的表尾。
操作
根据表头、表尾的定义可知:任何一个非空广义表的表头是表中第一个元素,它可以是原子,也可以是子表,而其表尾必定是子表。
也就是说,广义表的head操作,取出的元素是什么,那么结果就是什么。但是tail操作取出的元素外必须加一个表——“()”
- 取表头:原子或子表,即 第一个元素(可能是原子或列表)
- 取表尾:(子表集),即 其余元素组成的表(一定是列表)
- 当只有一个元素时,表头当然存在,但是表尾为“()”空(因为没有其余的元素)
举一个简单的列子:已知广义表LS=((a,b,c),(d,e,f)),如果需要取出这个e这个元素,那么使用tail和head如何将这个取出来。
利用上面说的,tail取出来的始终是一个表,即使只有一个简单的一个元素,tail取出来的也是一个表,而head取出来的可以是一个元素也可以是一个表。
解:
tail(LS) = ((d,e,f))
head(tail(LS)) = (d,e,f)
tail(head(tail(LS))) = (e,f) //无论如何都会加上这个()括号
head(tail(head(tail(LS)))) = e //head可以去除单个元素
头尾链表存储结构


扩展线性表存储结构
常用算法
差分数组(前缀和)
定义
差分,又名差分函数或差分运算,差分的结果反映了离散量之间的一种变化,是研究离散数学的一种工具,常用函数差近似导数。
差分其实就是数据之间的差,什么数据的差呢?就是上面所给的原始数组的相邻元素之间的差值,我们令 d[i]=a[i+1]-a[i],一遍for循环即可将差分数组求出来。
性质
-
计算数列各项的值:观察d[2]=f[1]+f[2]=d[1]+d[2]-d[1]=d[2]可知,数列第i项的值是可以用差分数组的前i项的和计算的,即d[i]=f[i]的前缀和。
-
计算数列每一项的前缀和:第i项的前缀和即为数列前i项的和,那么推导可知
即可用差分数组求出数列前缀和;
用途:
1. 快速处理区间加减操作:
假如现在对数列中区间[L,R]上的数加上x,
我们通过性质(1)知道,第一个受影响的差分数组中的元素为f[L],即令f[L]+=x,那么后面数列元素在计算过程中都会加上x(即 前缀和);
最后一个受影响的差分数组中的元素为f[R],所以令f[R+1]-=x,即可保证不会影响到R以后数列元素的计算。
这样我们不必对区间内每一个数进行处理,只需处理两个差分后的数即可;
2. 询问区间和问题:
由性质(2)我们可以计算出数列各项的前缀和数组sum各项的值;那么显然,区间[L,R]的和即为ans=sum[R]-sum[L-1];
差分数组怎么求
其实差分数组是一个辅助数组,从侧面来表示给定某一数组的变化,一般用来对数组进行区间修改的操作。
下面给你一个栗子,给出一个差分数组:

还是上面那个表里的栗子,我们需要进行以下操作:
1、将区间【1,4】的数值全部加上3
2、将区间【3,5】的数值全部减去5
很简单对吧,你可以进行枚举。但是如果给你的数据量是1e5,操作量1e5,限时1000ms你暴力枚举能莽的过去吗?T到你怀疑人生直接。这时我们就需要使用到差分数组了。
其实当你将原始数组中元素同时加上或者减掉某个数,那么他们的差分数组其实是不会变化的。
利用这个思想,咱们将区间缩小,缩小的例子中的区间 【1,4】吧这是你会发现只有 d[1]和d[5]发生了变化,而d[2],d[3],d[4]却保持着原样,

在进行下一个操作,

这时我们就会发现这样一个规律,当对一个区间进行增减某个值的时候,他的差分数组对应的区间左端点的值会同步变化,而他的右端点的后一个值则会相反地变化,其实这个很好理解
其实也就这么一点代码就ok了
while (m--) { //操作次数
cin >> left >> right >> change; //左右端点及其变化的值
d[left]+=change;
d[right+1]-=change;
}
差分数组能干啥
既然我们要对区间进行修改,那么差分数组的作用一定就是求多次进行区间修改后的数组喽
注意:只能是区间元素同时增加或减少相同的数的情况才能用
因为我们的差分数组是由原始数组的相邻两项作差求出来的,即 d[i]=a[i]-a[i-1];那么我们能不能反过来,求得一下修改过后的a[i]呢?
直接反过来即得 a[i]=a[i-1]+d[i]
事实证明这是正确的,具体证法就不再推广,有空再补上吧;
更新数组a的方式则是下面的那一点点代码,这样我们就求出来了更新后的数组 a,是不是比线段树快多了呢?
for(int i=1;i<=n;i++)
a[i]=a[i-1]+b[i];
差分数组怎么用
翻来覆去还是那句,区间修改,当然了,有时候要结合树状数组来使用。直接看题目吧!
适用场景
一般使用在区间元素同时增加或减少相同的数的情况,常常与前缀和一起使用。
理解:****差分数组的性质导致我们修改第i个元素的时候,会对所有下标大于等于i的元素都进行相同的修改,即 从i开始后面的所有元素都进行相同的修改。
所以我们想要让区间[n,m]内的元素 + 1,我们就可以先让d[n] + 1(即 从n开始后面的所有元素+1),再让d[m + 1] - 1(即 从m开始消除之前n进行修改的影响,即 只修改了区间n~m之间的元素).
例子:如果现在要修改区间a[0]~a[4],只需要把
d[0]+1(所有的a都有d[0]的元素),然后把d[5]-1(a[5]及以后的数字都有d[5]的元素),这样就可以实现区间修改,求前缀和即可。
例子
先举个例子:
现在有数组a[7]
int a[7];
a[0]=1;a[1]=2;a[2]=3;a[3]=4;a[4]=5;a[5]=6;a[6]=7;a[7]=8;
如果要把a[0]-a[4]都加一,最朴素的方法就是
a[0]++;a[1]++;a[2]++;a[3]++;a[4]++;
时间复杂度为O(n),打字打着都很费力。
但是如果先有一个神奇的差分数组d[7],就可以省力得多了!
现在开一个d[7]:
int d[7];
d[0]=a[0];
for(int i=1;i<=7;i++){
d[i]=a[i]-a[i-1];
}
差分数组就完成啦!
差分数组是干什么用的?
你会发现,
a[0]=d[0];
a[1]=d[1]+d[0];
a[2]=d[2]+d[1]+d[0];
以此类推
这样就可以单点查询(差分数组的前缀和即原数组)
如果现在要修改区间a[0]~a[4],只需要把d[0]+1(所有的a都有d[0]的元素),然后把d[5]-1(a[5]及以后的数字都有d[5]的元素),这样就可以实现区间修改,求前缀和即可。
面试题 16.10. 生存人数
给定 N 个人的出生年份和死亡年份,第 i 个人的出生年份为 birth[i],死亡年份为 death[i],实现一个方法以计算生存人数最多的年份。
你可以假设所有人都出生于 1900 年至 2000 年(含 1900 和 2000 )之间。如果一个人在某一年的任意时期处于生存状态,那么他应该被纳入那一年的统计中。例如,生于 1908 年、死于 1909 年的人应当被列入 1908 年和 1909 年的计数。
如果有多个年份生存人数相同且均为最大值,输出其中最小的年份。
示例:
输入:
birth = {1900, 1901, 1950}
death = {1948, 1951, 2000}
输出: 1901
答案
看到题我们的第一反应就是覆盖区间,我们需要把出生到死亡这段时间区间内的存活人数+1,然后找出最大的那个存活人数即可。
可是这样做就很麻烦了,时间复杂度为\(O(m*n)\)。
这种区间整体修改的情况,我们可以使用差分数组来解决。
把出生到死亡这段时间区间内的存活人数+1:把差分数组的出生日期+1,死亡日期后面一个日期-1,即可完成该功能。
live[birth[i] - 1900]++;和live[death[i] - 1900 + 1]--;
差分数组实现。时间复杂度O(n)
需求是将一个数组,某一段数值都加1(复杂度为n),遍历n遍(复杂度即变为n*n)。正好适用于差分数组的特点,只需遍历一遍,即可得到差分数组,然后再遍历一边
- 遍历一遍,求出差分数组
- 再遍历一遍,推到出原数组;同时判断比较出生存人数最多的年份
问题可以看成问数轴1900到2000得范围内哪个点被覆盖得次数最多,覆盖是指题目给出得区间[出生日期,死亡日期]
这样直观得想法就是给出一个区间[x,y],就把区间[x,y]里面每个数字都加上1,最后扫描一遍[1900,2000]看看哪个点得值最大.
使用差分数组,可以把一个区间得每一个数加1得操作,变成2个端点得操作,时间复杂度是O(1)。最终得复杂度是O(n)。
class Solution {
public int maxAliveYear(int[] birth, int[] death) {
// 新奇做法:前缀和
int[] live = new int[102]; // 因为2000年死的人算是2001年未生存,2000年算是活着
for (int i = 0; i < birth.length; i++) {
live[birth[i] - 1900]++;
// 例如,生于 1908 年、死于 1909 年的人应当被列入 1908 年和 1909 年的计数。
live[death[i] - 1900 + 1]--;
}
int sum = 0, max = 0, index = 0;
for (int i = 0; i < live.length; i++) {
sum += live[i];
if (sum > max) {
max = sum;
index = i;
}
}
return index + 1900;
}
}
边界法
使用一些指针变量充当数组边界,方便数组进行多样化的遍历。如 up、down、left、right等。
面试题 01.07. 旋转矩阵
给你一幅由 N × N 矩阵表示的图像,其中每个像素的大小为 4 字节。请你设计一种算法,将图像旋转 90 度。
不占用额外内存空间能否做到?
示例 1:
给定 matrix =
[
[1,2,3],
[4,5,6],
[7,8,9]
],
原地旋转输入矩阵,使其变为:
[
[7,4,1],
[8,5,2],
[9,6,3]
]
示例 2:
给定 matrix =
[
[ 5, 1, 9,11],
[ 2, 4, 8,10],
[13, 3, 6, 7],
[15,14,12,16]
],
原地旋转输入矩阵,使其变为:
[
[15,13, 2, 5],
[14, 3, 4, 1],
[12, 6, 8, 9],
[16, 7,10,11]
]
答案
这题其实画一个 4 * 4 的数组旋转非顶点元素试一遍就知道怎么做了。。
class Solution {
// 行、列
// 0、[] -> []、n - 1
// 1、[] -> []、n - 2
// i、[] -> []、n - i - 1
public void rotate(int[][] matrix) {
int n = matrix.length;
for (int x = 0; x < n / 2; x++) {
for (int y = x; y < n - x - 1; y++) {
// for (int y = x; y < (n + 1) / 2; y++) {
int temp = matrix[x][y];
matrix[x][y] = matrix[n - y - 1][x];
matrix[n - y - 1][x] = matrix[n - x - 1][n - y - 1];
matrix[n - x - 1][n - y - 1] = matrix[y][n - x - 1];
matrix[y][n - x - 1] = temp;
}
}
}
}
树状数组
定义
树状数组或二叉索引树(英语:Binary Indexed Tree),又以其发明者命名为Fenwick树,最早由Peter M. Fenwick于1994年以A New Data Structure for Cumulative Frequency Tables为题发表在SOFTWARE PRACTICE AND EXPERIENCE。其初衷是解决数据压缩里的累积频率(Cumulative Frequency)的计算问题,现多用于高效计算数列的前缀和, 区间和。
原码,反码,补码的产生过程,就是为了解决,计算机做减法和引入符号位(正号和负号)的问题。
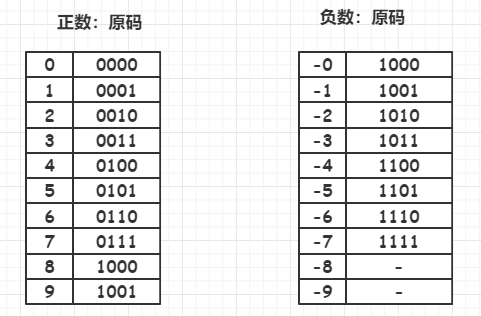
原码
是最简单的机器数表示法。用最高位表示符号位,‘1’表示负号,‘0’表示正号。其他位存放该数的二进制的绝对值。
若以带符号位的四位二进值数为例
- 1010 : 最高位为1,表示这是一个负数,其他三位为010
- 即 \((0*2^{2}) + (1*2^{1})+(0*2^{0})=2\)(‘^’表示幂运算符)
- 所以1010表示十进制数(-2)。
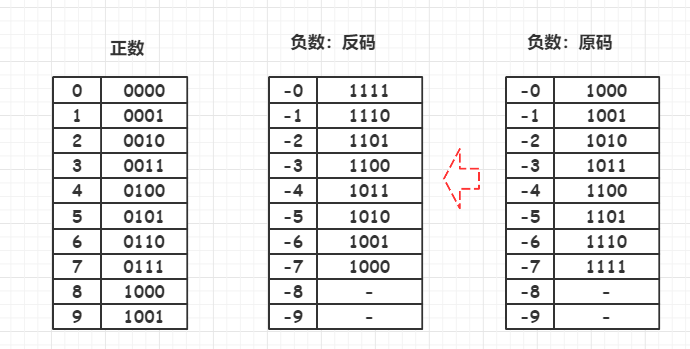
反码
正数的反码还是等于原码,负数的反码就是他的原码除符号位外,按位取反
若以带符号位的四位二进制数为例:
- 3是正数,反码与原码相同,则可以表示为0011
- -3的原码是1011,符号位保持不变,低三位(011)按位取反得(100)
- 所以-3的反码为1100
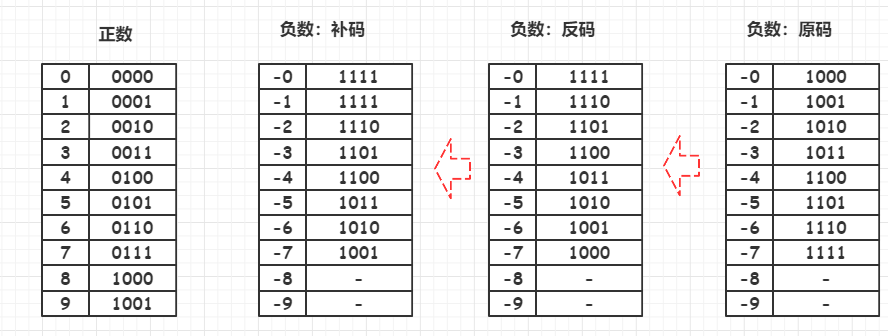
补码
正数的补码等于他的原码,负数的补码等于反码+1。(这只是一种算补码的方式,多数书对于补码就是这句话
负数的补码等于他的原码自低位向高位,尾数的第一个‘1’及其右边的‘0’保持不变,左边的各位按位取反,符号位不变。
树状数组
\(C[1] = A[1]\)
\(C[2] = A[1] + A[2]\)
\(C[3] = A[3]\)
\(C[4] = A[1] + A[2] + A[3] + A[4]\)
\(C[5] = A[5]\)
\(C[6] = A[5] + A[6]\)
\(C[7] = A[7]\)
\(C[8] = A[1] + A[2] + A[3] + A[4] + A[5] + A[6] + A[7] + A[8]\)
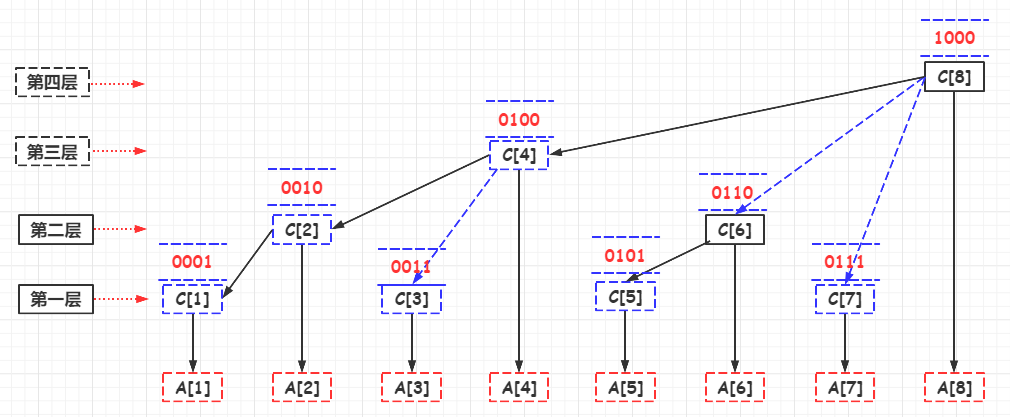
\(C[i]=A[i−2^k+1]+A[i−2^k+2]+...+A[i]\)
其中k为i的二进制中最低位到最高位连续0的长度,
1.举例 ,6,二进制为0110, 这时候k为1,从右往左数0,遇到第一个1的时候停下来:
\(C[6]=A[6−2^1+1]+A[6]\) => \(C[6]=A[5]+A[6]\)
可能有疑问指出,为什么不是
\(C[6]=A[6−2^1+1]+A[6−2^1+2]+...+A[6]\) => \(C[6]=A[5]+A[6]+...+A[i]\)
因为6的二进制为0110,其低位只有10,也就是两个元素,即C[6]C[6]只管理两个节点,对应图上可以看出是A[6]与A[5]
2.举例,4 二进制为0100,这时候k为2,从右往左数,遇到第一个1的时候停下来:
\(C[4]=A[i−2^2+1]+A[i−2^2+2]+...+A[i]\) => \(C[4]=A[1]+A[2]+A[3]+A[4]\)
找前7项的和
\(SUM=C[7]+C[7-2^{k1}]+C[(7-2^{k1})-2^{k2}]\)
=> \(SUM=C[7]+C[7-2^0]+C[(7-2^0)-2^1]\)
=> \(SUM=C[7]+C[6]+C[4]\)
k1 为7的二进制中从最低位到高位连续零的长度
k2 为6的二进制中从最低位到高位连续零的长度
k3 为4的二进制中从最低位到高位连续零的长度
公式:
\(SUM=C[i]+C[i-2^{k1}]+C[(i-2^{k1})-2^{k2}]+...\)
lowbit(x) = x & (-x)
- 当x为0时结果为0
- x为奇数时,结果为1
- x为偶数时,结果为x中2的最大次方的因子,即\(2^k\)
离散化
针对数值的大小做一个排名的「映射」,把原始数据映射到 [1, len] 这个区间,这样「树状数组」底层的数组空间会更紧凑,更易于维护。
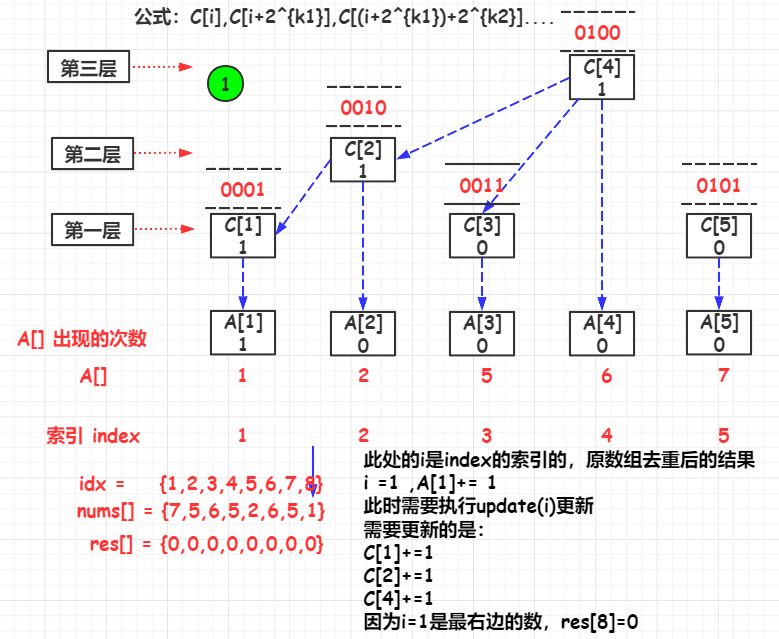
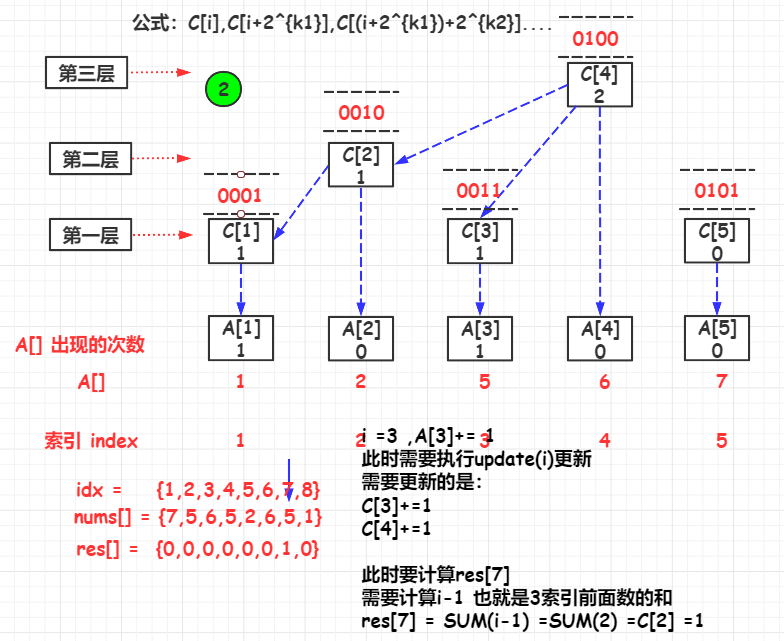
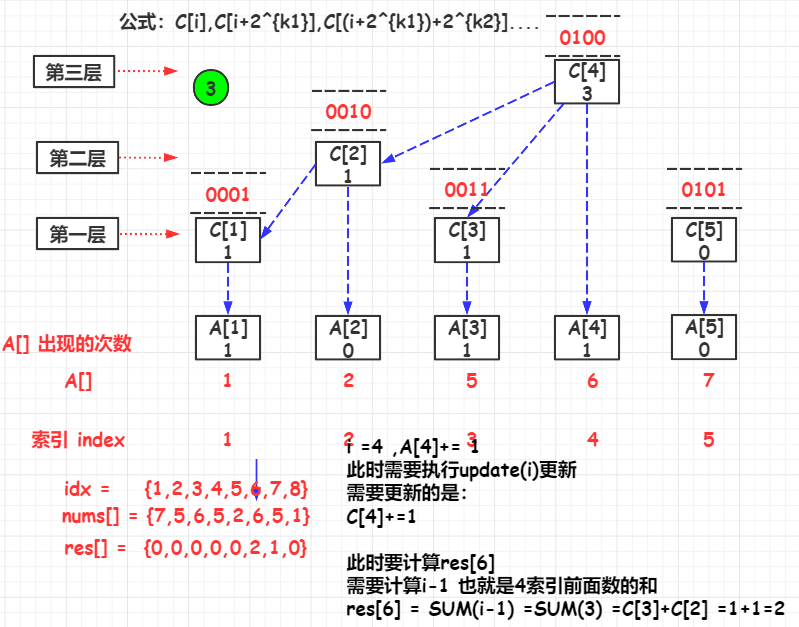
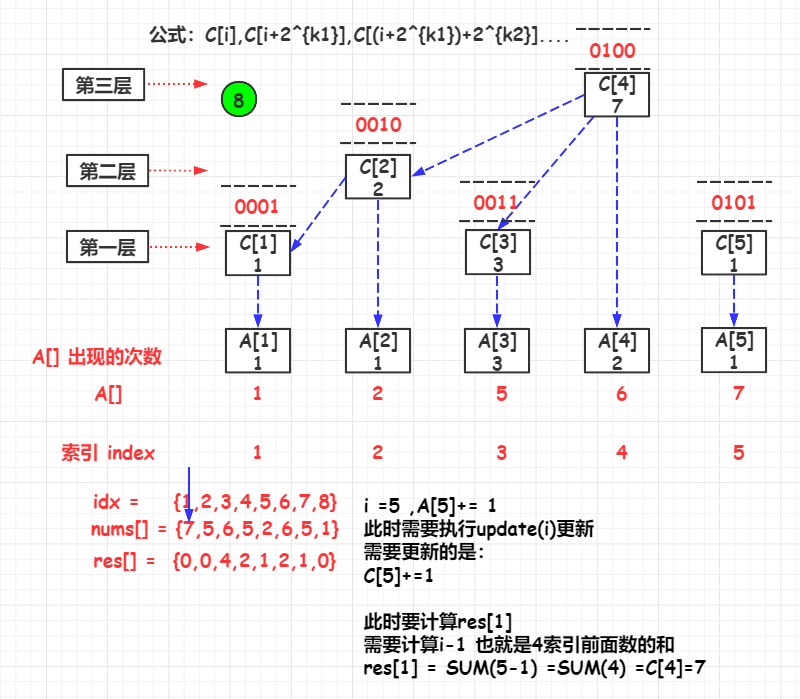
update(i)
如果要更新A[i]的值时,与A[i]直接关联的C[]有:
\(C[i],C[i+2^{k1}],C[(i+2^{k1})+2^{k2}]....\)
其中,i是初始索引,k1是i的lowbit,k2是\(i-2^{k1}\)的lowbit
举例:A[1],与其直接关联的C[]有:
\(C[i],C[i+2^{k1}],C[(i+2^{k1})+2^{k2}]....\) => \(C[1],C[1+2^1],C[(i+2^1)+2^2]....\) => \(C[1],C[2],C[4]\)
其代码实现是实现lowbit的增加,i += lowbit(i) 但是i的值不能超过n
query(i)
其代码实现是实现lowbitlowbit的减少,i -= lowbit(i),但是i的值不能小于1
举例,参考的yangbingjie的题解的例子
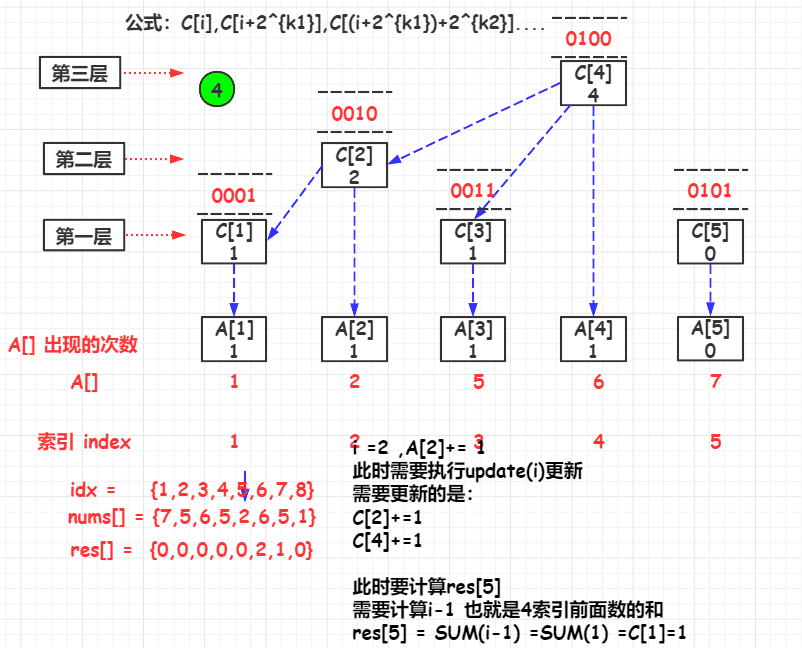
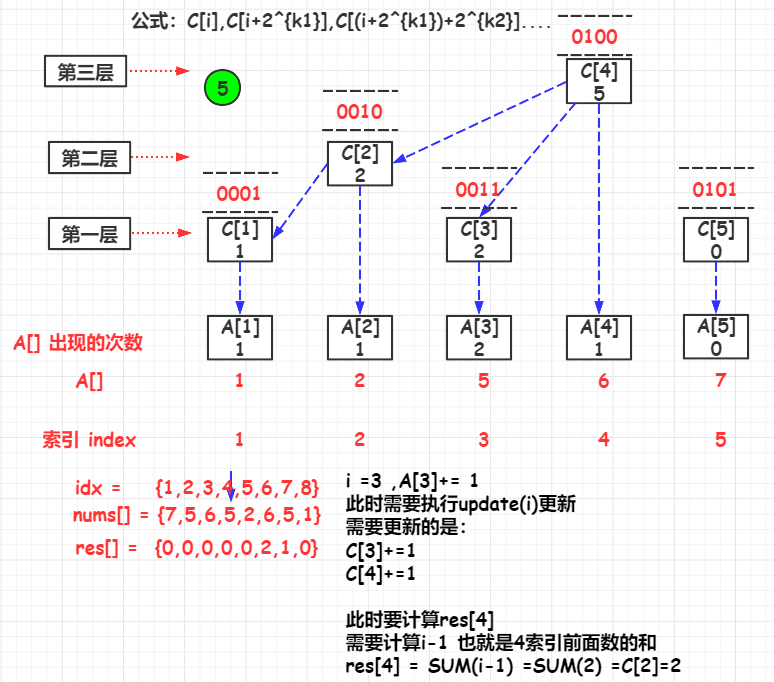
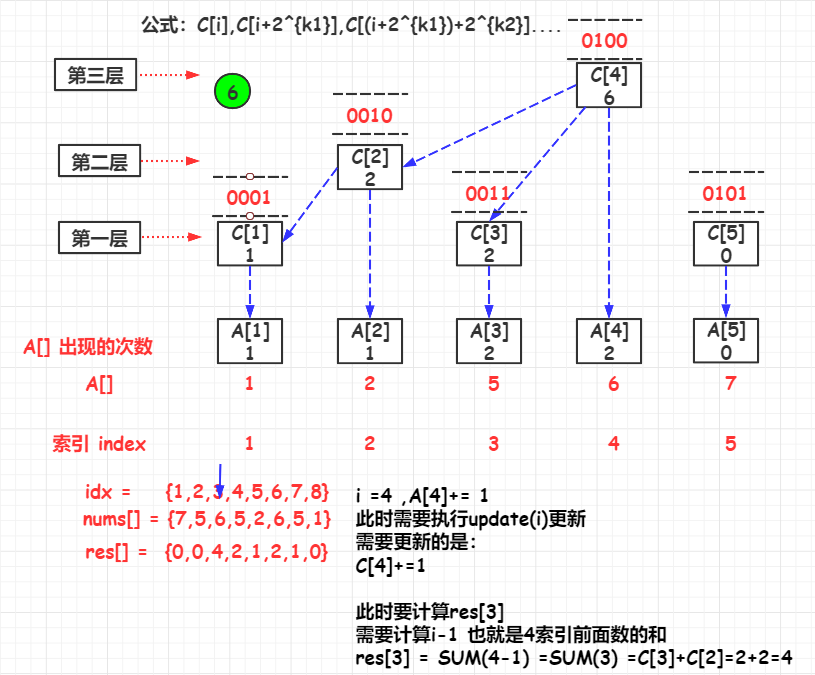
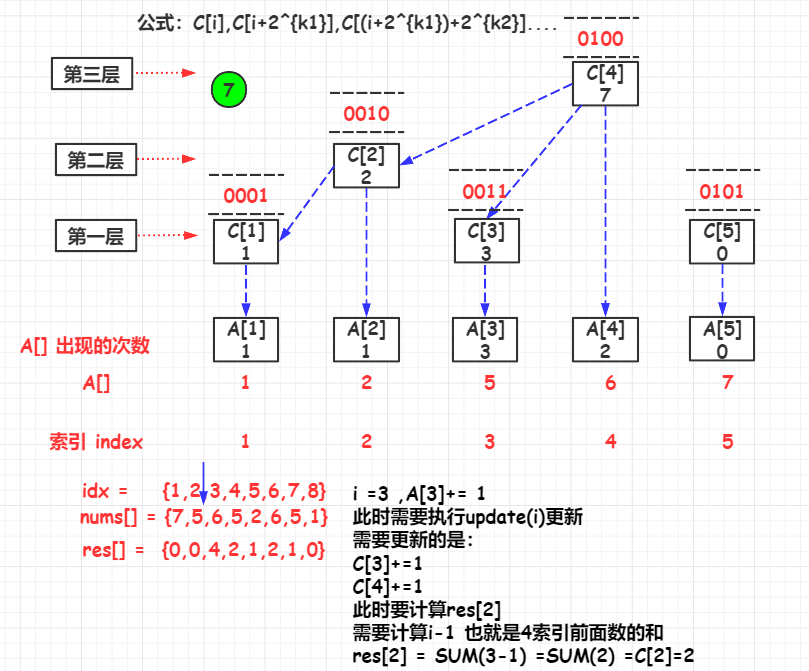
FenwickTree
class FenwickTree {
int n;
int[] C;
//初始化
public FenwickTree(int n) {
this.n = n;
this.C = new int[n];
}
// 单点更新:将 i 位置与其直接关联的 C 都更新一遍
public void update(int i) {
while (i < n) {
C[i]++;
i += lowbit(i);
}
}
//传进来的值-1过,查询之前有多少个数
//区间查询:查询小于等于 i 的元素个数
public int query(int i) {
int sum = 0;
while (i >= 1) {
sum += C[i];
i -= lowbit(i);
}
return sum;
}
//算lowbit
public int lowbit(int x) {
return x & (-x);
}
}
主体代码
思路
- 预处理nums数组,使用TreeSet的结构去重排序
- 做一个Map<k,v>其中k是nums中的数字,v是改元素的排名,从小到大排列
- 初始化FenwickTree,多放一个位置,使下标从1开始
- 从右到左遍历,获取到该元素的排名后(离散化后索引),
public List<Integer> countSmaller(int[] nums) {
List<Integer> res = new ArrayList<>();
int len = nums.length;
if (len == 0) return res;
//1.预处理nums
Set<Integer> treeSet = new TreeSet<>();
for (int num : nums) treeSet.add(num);
//2.匹配映射关系的map
Map<Integer, Integer> map = new HashMap<>();
int rank = 1;//相当于A数组的下标索引
for (int num : treeSet) {
map.put(num, rank++);
}
//3.初始化FenwickTree
FenwickTree fenwickTree = new FenwickTree(treeSet.size() + 1);
for (int i = nums.length - 1; i >= 0; i--) {
rank = map.get(nums[i]);
//更新当前的元素的C[rank]
fenwickTree.update(rank);
//当前排名前的元素的个数
res.add(fenwickTree.query(rank - 1));
}
Collections.reverse(res);
return res;
}
}
| 题号 | 链接 | 备注 |
|---|---|---|
| 130/684 | 一文掌握并查集算法 | |
| 一文掌握Morris遍历算法 | ||
| 315 | 一文掌握树状数组 |
笔者将不定期更新【考研或就业】的专业相关知识以及自身理解,希望大家能【关注】我。
如果觉得对您有用,请点击左下角的【点赞】按钮,给我一些鼓励,谢谢!
如果有更好的理解或建议,请在【评论】中写出,我会及时修改,谢谢啦!
本文来自博客园,作者:Nemo&
转载请注明原文链接:https://www.cnblogs.com/blknemo/p/11596566.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号