【Java】正则表达式
使用正则表达式可以方便的对数据进行匹配,还可以执行更加复杂的字符串验证、拆分、替换功能。
正则表达式
什么是正则表达式
正则表达式,又称规则表达式,通常被用来检索、替换那些符合某个模式(规则)的文本。
正则表达式是对字符串操作的一种逻辑公式,就是用事先定义好的一些特定字符、及这些特定字符的组合,组成一个“规则字符串”,这个“规则字符串”用来表达对字符串的一种过滤逻辑。
给定一个正则表达式和另一个字符串,我们可以达到如下的目的:
- 给定的字符串是否符合正则表达式的过滤逻辑(“匹配”);
- 通过正则表达式,从文本字符串中获取我们想要的特定部分(“过滤”)。
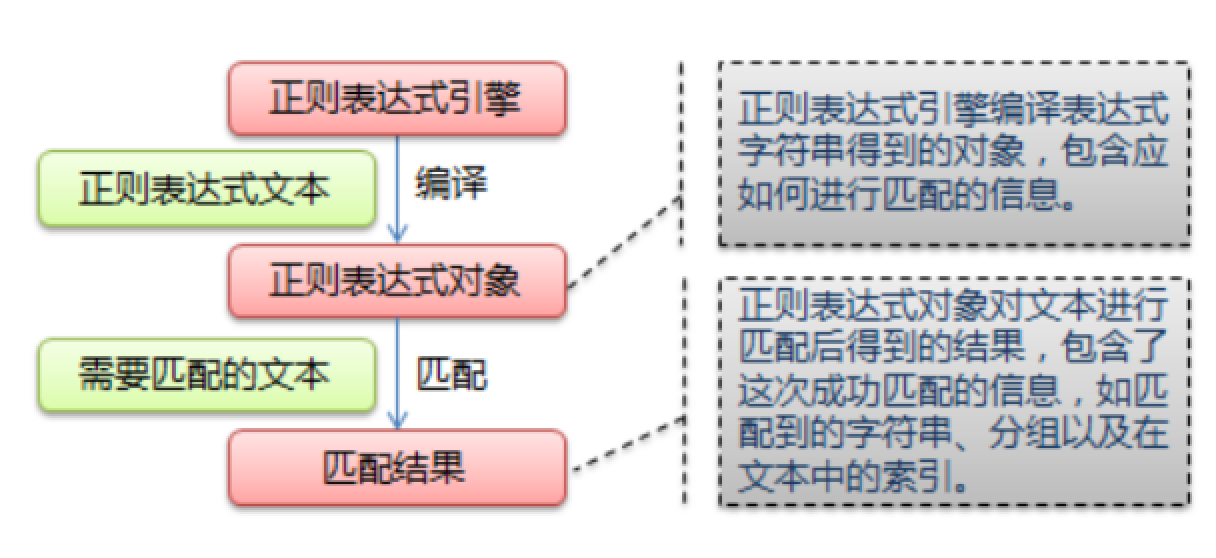
正则表达式匹配规则
这里的正则表达式为Python格式,可以供大家参考。
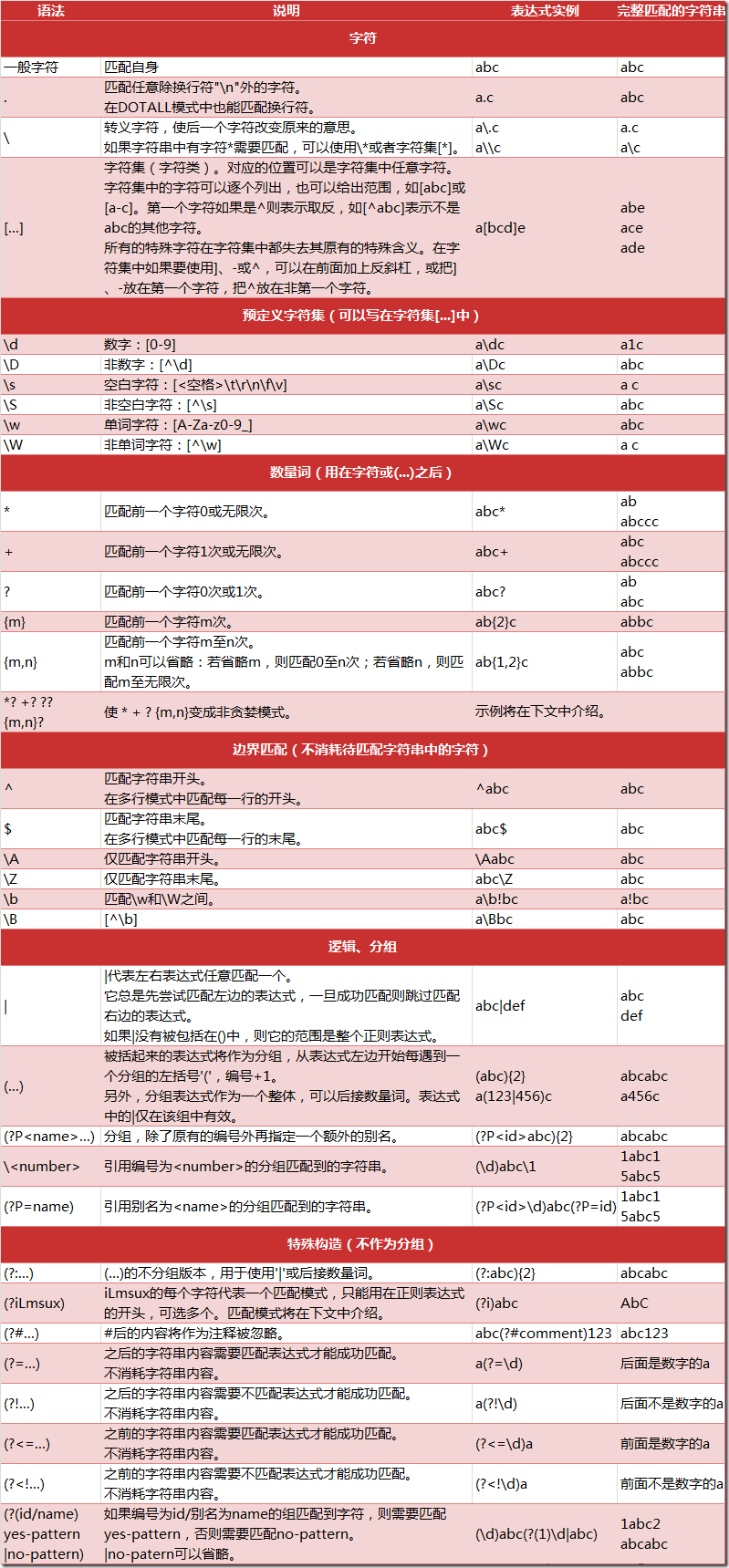
字符
一般字符
匹配自身
正则表达式实例:
abc
完整匹配的字符串:
abc
.
匹配任意换行符"\n"外的字符。
在DOTALL模式中也能匹配换行符。
正则表达式实例:
a.c
完整匹配的字符串:
abc
\
转义字符,使后一个字符改变原来的意思。
如果字符串中有字符*需要匹配,可以使用\*或者字符集[*]。
正则表达式实例:
a\.c
完整匹配的字符串:
a.c
[...]
字符集(字符类)。对应的位置可以是字符集中任意字符。
字符集中的字符可以逐个列出,也可以给出范围,如[abc]或[a-c]。第一个字符如果是^则表示取反,如[^abc]表示不是abc的其他字符。
所有的特殊字符在字符集中都失去其原有的特殊含义。在字符集中如果要使用]、-或^,可以在前面加上反斜杠,或把]、-放在第一个字符,把^放在非第一个字符。
正则表达式实例:
a[bcd]e
完整匹配的字符串:
abe
ace
ade
预定义字符集(可以写在字符集[...]中)
\d
digit
数字:[0-9]
正则表达式实例:
a\dc
完整匹配的字符串:
a1c
a2c
\D
非数字:[^\d]或[^0-9]
正则表达式实例:
a\Dc
完整匹配的字符串:
abc
\s
space
空白字符:[<空格>\t\r\n\f\v]
正则表达式实例:
a\sc
完整匹配的字符串:
a c
\S
非空白字符:[^\s]
正则表达式实例:
a\Sc
完整匹配的字符串:
abc
\w
word
单词字符:[A-Za-z0-9_]
正则表达式实例:
a\wc
完整匹配的字符串:
abc
\W
非单词字符:[^\w]
正则表达式实例:
a\Wc
完整匹配的字符串:
a c
数量词(用在字符或(...)之后)
*
匹配前一个字符0或无限次。
正则表达式实例:
abc*
完整匹配的字符串:
ab
abc
abccc
+
匹配前一个字符1次或无限次。
正则表达式实例:
abc+
完整匹配的字符串:
abc
abccc
?
匹配前一个字符0次或1次。
正则表达式实例:
abc?
完整匹配的字符串:
ab
abc
{m}
匹配前一个字符m次。
正则表达式实例:
ab{2}c
完整匹配的字符串:
abbc
{m,n}
匹配前一个字符m至n次。
m和n可以省略:若省略m ,则匹配0至n次;若省略n:则匹配m至无限次。
正则表达式实例:
ab{1,2}c
完整匹配的字符串:
abc
abbc
*?、+?、??、{m,n}?
一般我们默认都是贪婪匹配去检验字符串格式,即 尽可能多的去匹配字符,遇到换行则停止。而在爬虫中,使用的较多的是惰性匹配。
使*、+、?、{m,n}变成惰性匹配(非贪婪模式)。
示例将在下文中介绍
字符串:玩儿吃鸡游戏,晚上一起上游戏,干嘛呢?打游戏啊!
正则(贪婪):玩儿.*游戏
匹配1:玩儿吃鸡游戏,晚上一起上游戏,干嘛呢?打游戏
正则(惰性):玩儿.*?游戏
匹配2:玩儿吃鸡游戏
边界匹配(不消耗待匹配字符串中的字符)
^
匹配字符串开头。
在多行模式中匹配每一行的开头。
正则表达式实例:
^abc
完整匹配的字符串:
abc
$
匹配字符串末尾。
在多行模式中匹配每一行的末尾。
正则表达式实例:
abc$
完整匹配的字符串:
abc
\A
A,第一个字母是A
仅匹配字符串开头。
正则表达式实例:
\Aabc
完整匹配的字符串:
abc
\Z
Z,最后一个字母是Z
仅匹配字符串末尾。
正则表达式实例:
abc\Z
完整匹配的字符串:
abc
\b
boundary
单词边界就是单词和符号之间的边界
这里的单词可以是中文字符、英文字符、数字;
符号可以是中文符号、英文符号、空格、制表符、换行
匹配\w和\W之间。
正则表达式实例:
a\b!bc
完整匹配的字符串:
a!bc
\B
非单词边界确实是单词与单词、符号与符号之间的边界
[^\b]
正则表达式实例:
a\Bbc
完整匹配的字符串:
abc
逻辑
|
|代表左右表达式任意匹配一个。
它总是先尝试匹配左边的表达式,一旦成功匹配则跳过匹配右边的表达式。
如果|没有被包括在()中,则它的范围是整个正则表达式。
正则表达式实例:
abc|def
完整匹配的字符串:
abc
def
分组
分组的作用
(pattern)匹配 pattern 并捕获该匹配的子表达式。可以使用 $0…$9 属性从结果"匹配"集合中检索捕获的匹配。
若要匹配括号字符 (或者),请使用"\("或者"\)"。
这种$0获取匹配变量还是蛮有用的,如 驼峰转下划线str.replaceAll("[A-Z]", "_$0").toLowerCase();
-
$0:表示全匹配,相当于在正则表达式的最外层加了一个小括号,匹配所有 -
$1:表示第一个括号内容 -
$2:第二个括号 -
$n以此类推 (注意,出现索引超出,$就会变成普通字符)
分组实例
123abc456
(\d+)(\D+)(\d+)
匹配结果:全匹配
替换为 $0 结果,123abc456,相当于((\d+)(\D+)(\d+)),获取了整个组
替换为 $1 结果,整个匹配项,替换成 第一个括号内容了,也就是 123
替换为 $2 结果,整个匹配项,替换成 第2个括号内容了,也就是 abc
替换为 $5 结果,整个匹配项,替换成 普通字符 $5,也就是 $5
代码如下
@Test
void name() {
String str = "123abc456";
System.out.println(str.replaceAll("(\\d+)(\\D+)(\\d+)", "$0_")); // 123abc456_
System.out.println(str.replaceAll("(\\d+)(\\D+)(\\d+)", "$3_$2_$1")); // 456_abc_123
}
驼峰转下划线
String test = "ceShiXia";
String s1 = test.replaceAll ( regex :"[A-Z]", replacement :"_$0");
System.out.println ("s1=:"+s1); // ce_Shi_Xia
String s2 = test.replaceAll ( regex :"([A-Z])", replacement :"_$1");
System.out.println ("s2=:"+s2); // ce_Shi_Xia,与上面最外层加括号是等价的
String s3 = test.replaceAll ( regex :"[A-Z]", replacement :"$0_");
System.out.println ("s3=:"+s3); // ceS_hiX_ia
(...)
被括起来的表达式将作为分组,从表达式左边开始每遇到一个分组的左括号(,编号+1。
另外,分组表达式作为一个整体,可以后接数量词。表达式中的|仅在该组中有效。
正则表达式实例:
abc{2}
a(123|456)c
完整匹配的字符串:
abcabc
a456c
注意:分组不仅可以帮助我们的正则表达式进行逻辑划分,还可以从正则表达式匹配到的字符串中,取出对应分组的内容。即 字符串 -> 匹配字符串 -> 分组字符串,想这样进一步筛选。
示例:
字符串:<div>你好呀</div>
正则:<div>(?P<content>.*?)</div>
匹配字符串:<div>你好呀</div>
分组字符串:这里可以用py举例提取出内容,res.group("content"),结果:你好呀
(?<name>...)和(?P<name>...)
命名捕获组,分组,除了原有的编号外再指定一个额外的别名。
理解:P可以理解为Python,而
(?<name>...)为一般的命名捕获组。
正则表达式实例:
(?P<id>abc){2}
完整匹配的字符串:
abcabc
Java demo
public static void main(String[] args){
String path="userservice-v5";
Pattern pattern=Pattern.compile("(?<name>^.+)-(?<version>v.+$)");
Matcher m=pattern.matcher(path);
while (m.find()){
System.out.println("分组名称:匹配的值");
System.out.println("name:"+m.group("name"));
System.out.println("version:"+m.group("version"));
}
}
运行结果:
分组名称:匹配的值
name:userservice
version:v5
Java中可以使用${name}来获取命名捕获组中捕获的内容
@Test
void name() {
String str1 = "123abc123";
System.out.println(str.replaceAll("(\\d+)(?<id>\\D+)(\\1)", "$3_")); // 123_
System.out.println(str.replaceAll("(\\d+)(?<id>\\D+)(\\d+)", "${id}_")); // abc_
}
引用
\<number>
引用编号为<number>的分组匹配到的字符串。
注意:这里的
\1与$1不同。
\1可以在匹配中使用,代表与前一个捕获组一致,$1不能。$1可以在匹配后使用,代表获取该捕获组中的元素,\1不能。
正则表达式实例:
(\d)abc\1
完整匹配的字符串:
1abc1
5abc5
(?P=name)
引用别名为<name>的分组匹配到的字符串。
正则表达式实例:
(?P<id>\d)abc(?P=id)
完整匹配的字符串:
1abc1
5abc5
特殊构造(不作为分组)
(?:...)
(...)的不分组版本,用于使用|或后接数量词。
正则表达式实例:
(?:abc){2}
完整匹配的字符串:
abcabc
(?iLmsux)
iLmsux的每个字符代表一个匹配模式 ,只能用在正则表达式的开头,可选多个。匹配模式将在下文中介绍。
正则表达式实例:
(?i)abc
完整匹配的字符串:
Abc
(?#...)
#后的内容将作为注释被忽略。
正则表达式实例:
abc(?#comment)123
完整匹配的字符串:
abc123
(?=...)
之后的字符串内容需要匹配表达式才能成功匹配。
不消耗字符串内容。
正则表达式实例:
a(?=\d)
完整匹配的字符串:
后面是数字的a
注意:匹配的还是单个a,只不过有了限定条件,是后面为数字的a
(?!...)
之后的字符串内容需要不匹配表达式才能成功匹配。
不消耗字符串内容。
正则表达式实例:
a(?!\d)
完整匹配的字符串:
后面不是数字的a
(?<=...)
之前的字符串内容需要匹配表达式才能成功匹配。
不消耗字符串内容。
正则表达式实例:
(?<=\d)a
完整匹配的字符串:
前面是数字的a
(?<!...)
之前的字符串内容需要不匹配表达式才能成功匹配。
不消耗字符串内容。
正则表达式实例:
(?<!\d)a
完整匹配的字符串:
前面不是数字的a
(?(id/name)yes-pattern|no-pattern)
如果编号为id/别名为name的组匹配到字符,则需要匹配yes-pattern,否则需要匹配no-pattern。
|no-pattern可以省略。
正则表达式实例:
(\d)abc(?(1)\d|abc)
完整匹配的字符串:
1abc2
abcabc
常用正则表达式
常用的正则规范的定义
正则表达式(Regular Expression, regex, RE):是用来简洁表达一组字符串的表达式。
常用正则规范
| 规范 | 描述 | 备注 |
|---|---|---|
| \ | 表示反斜线(\)字符 | |
| \t | 表示制表符 | table |
| \n | 表示换行 | newline |
| [abc] | 字符a、b或c | |
| [^abc] | 表示除了a、b、c之外的任意字符 | 非 |
| [a-zA-Z0-9] | 表示由字母、数字组成 | |
| \d | 表示数字,等同于[0-9] | Digit |
| \D | 表示非数字,等同于[^0-9] | |
| \x | 表示十六进制数字,匹配十六进制数字,等同于[0-9A-Fa-f] | |
| \X | 表示非十六进制数字,匹配十六进制数字之外的任意字符,等同于[^0-9A-Fa-f] | |
| \l | 表示小写字母,匹配[a-z] | letter |
| \L | 表示非小写字母,匹配[^a-z] | |
| \u | 表示大写字母,匹配[A-Z] | uppercase |
| \U | 表示非大写字母,匹配[^A-Z] | |
| \w | 表示字母、数字、下划线 | Word |
| \W | 表示非字母、数字、下划线 | |
| \s | 表示所有空白字符(换行、空格等) | Space |
| \S | 表示所有非空白字符 | |
| ^ | 行的开头 | 开始锋芒毕露 |
| $ | 行的结尾 | 到最后都是为了钱 |
| . | 匹配除换行符之外的任意字符 |
数量表示(X表示一组规范)
| 规范 | 描述 | 备注 |
|---|---|---|
| X | 必须出现一次 | |
| X? | 可以出现0次或1次 | |
| X* | 可以出现0次、1次或多次 | |
| X+ | 可以出现1次或多次 | |
| X | 必须出现n次 | |
| X | 必须出现n次以上 | |
| X | 必须出现n ~ m次 |
逻辑运算符(X、Y表示一组规范)
| 规范 | 描述 | 备注 |
|---|---|---|
| XY | X规范后跟着Y规范 | |
| X|Y | X规范或Y规范 | |
| (X) | 作为一个捕获组规范 |
捕获组:
在正则中,小括号() 表示捕获组
这个组,也就是在匹配的时候,将某一部分的字符(串)作为组处理,这个组,可以在正则表达式的其它位置或者匹配的结果中使用(使用方式在各种语言中不一定相同,在一般的正则表达式中为$0,$1,如:
^\s+([a-zA-Z]+?)\s.+$
匹配 " abcd 这是什么"
如果没有小括号,那么匹配只有一个结果,也就是整个字符串" abcd 这是什么"
而添加了小括号,匹配就会有两个结果了:
1 " abcd 这是什么"
2 "abcd"
也就是说额外用正则表达式捕获一个字符串
常用类型的正则表达式总结
//格式验证
public class Validate {
//用户名验证
public static Boolean userNameValid(String name) {
//第一个字符为字母,而后匹配长度为2到9的字母、数字或者下划线
return name.matches("^[a-zA-Z][a-zA-Z0-9_]{2,9}$");
}
//密码验证
public static Boolean passWordValid(String pw) {
//匹配长度为6到10的字母或数字
return pw.matches("^[a-zA-Z0-9]{6,10}$");
}
//手机号验证
public static Boolean mobilePhoneValid(String phone) {
/*第一个字符为1,若第二个字符为3,则第三个字符为0到9的一个数字
若第二个字符为4,则第三个字符为5或7
若第二个字符为5,则第三个字符为0到3,5到9的一个数字
若第二个字符为7,则第三个字符为01678中的一个数字
若第二个字符为8,则第三个字符为0到9的一个数字
后面还有8个数字*/
return phone.matches("^1(3[0-9]|4[57]|5[0-35-9]|7[01678]|8[0-9])\\d{8}$");
}
//电话验证
public static Boolean telephoneValid(String tele) {
//3到5位数字 - 7到8为数字 加上( - 1位以上数字)()为可有可无
return tele.matches("\\d{3,5}-\\d{7,8}(-\\d{1,})?");
}
//QQ号验证
public static Boolean qqValid(String qq) {
//第一位字符是1到9,后面的字符为匹配长度是4到14的0到9数字
return qq.matches("[1-9][0-9]{4,14}");
}
//身份证号验证
public static Boolean idValid(String id) {
//15位数字 或者 17位数字加上一个数字或者X或者x
return id.matches("^\\d{15}$|^\\d{17}(\\d|X|x)$");
}
//邮箱验证
public static Boolean emailValid(String email) {
/*一个或多个字母数字或者下划线 + 0个、1个或者多个 小数点或多个字母数字或者下划线
+ 一个@ +一个或多个字母数字下划线 + 0个、1个或者多个 小数点或多个字母数字或者下划线*/
return email.matches("^(\\w)+(\\.\\w+)*@(\\w)+((\\.\\w+)+)$");
}
//网站验证
public static Boolean websiteValid(String ws) {
//(h或者H + 两个 t或者T + p或者P ://)或者(h或者H + 两个 t或者T + p或者P + s或者S://)+有若干个(若干个字母数字-~ 加上 一个.)+若干个字母数字-~/
return ws.matches("^([hH][tT]{2}[pP]://|[hH][tT]{2}[pP][sS]://)(([A-Za-z0-9-~]+)[.])+([A-Za-z0-9-~/])+$");
}
//生日验证
public static Boolean birthDateValid(String bd) {
//四个数字 . 两个数字 . 两个数字
//或者四个数字 - 两个数字 - 两个数字
return bd.matches("(\\d{4}[.]\\d{2}[.]\\d{2})|(\\d{4}[-]\\d{2}[-]\\d{2})");
}
//中文名验证
public static Boolean chineseNameValid(String cn) {
//2到5个汉字
return cn.matches("[\u4E00-\u9FA5]{2,5}");
}
}
PS : 需要提醒的是,使用正则表达式大部分是双反斜杠字符(\\),如 一个点:\\.。
因为在字符串中需要用\来转义一遍字符,再给正则表达式接收再正则转义。如\\.在字符串中\\转义为\,也就是说\\.转变成了\.,再传入正则表达式变为.。
如果在字符串里只写\.的话,第一步就被直接解释为.,之后作为正则表达式被解释时,就变成匹配任意字符了。总结:也就是说,不仅字符串需要转义,正则表达式也需要转义,如 \d,有两道转义,所以需要两个\。
常用正则表达式
整数或者小数:^[0-9]+\.{0,1}[0-9]{0,2}$
只能输入数字:”^[0-9]*$”
只能输入n位的数字:”^\d{n}$”
只能输入至少n位的数字:”^\d{n,}$”
只能输入m~n位的数字:”^\d{m,n}$”
只能输入零和非零开头的数字:”^(0|[1-9][0-9]*)$”。
只能输入有两位小数的正实数:”^[0-9]+(.[0-9]{2})?$”。
只能输入有1~3位小数的正实数:”^[0-9]+(.[0-9]{1,3})?$”。
只能输入非零的正整数:”^\+?[1-9][0-9]*$”。
只能输入非零的负整数:”^\-[1-9][]0-9″*$。
只能输入长度为3的字符:”^.{3}$”。
只能输入由26个英文字母组成的字符串:”^[A-Za-z]+$”。
只能输入由26个大写英文字母组成的字符串:”^[A-Z]+$”。
只能输入由26个小写英文字母组成的字符串:”^[a-z]+$”。
只能输入由数字和26个英文字母组成的字符串:”^[A-Za-z0-9]+$”。
只能输入由数字、26个英文字母或者下划线组成的字符串:”^\w+$”。
验证用户密码:”^[a-zA-Z]\w{5,17}$”
正确格式为:以字母开头,长度在6~18之间,只能包含字符、数字和下划线。验证是否含有^%&’,;=?$\”等字符:”[^%&',;=?$\x22]+”。
只能输入汉字:”^[\u4e00-\u9fa5]{0,}$”
验证Email地址:”^\w+([-+.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)*$”。
验证InternetURL:”^http://([\w-]+\.)+[\w-]+(/[\w-./?%&=]*)?$”。
验证电话号码:”^(\(\d{3,4}-)|\d{3.4}-)?\d{7,8}$”
正确格式为:”XXX-XXXXXXX”、”XXXX-XXXXXXXX”、”XXX-XXXXXXX”、”XXX-XXXXXXXX”、”XXXXXXX”和”XXXXXXXX”。
验证身份证号(15位或18位数字):”^\d{15}|\d{18}$”。
验证一年的12个月:”^(0?[1-9]|1[0-2])$”
正确格式为:”01″~”09″和”1″~”12″。
验证一个月的31天:”^((0?[1-9])|((1|2)[0-9])|30|31)$”
正确格式为;”01″~”09″和”1″~”31″。
匹配中文字符的正则表达式: [\u4e00-\u9fa5]
匹配双字节字符(包括汉字在内):[^\x00-\xff]
应用:计算字符串的长度(一个双字节字符长度计2,ASCII字符计1)String.prototype.len=function(){return this.replace(/[^\x00-\xff]/g,”aa”).length;}
匹配空行的正则表达式:\n[\s| ]*\r
匹配html标签的正则表达式:<(.*)>(.*)<\/(.*)>|<(.*)\/>
匹配首尾空格的正则表达式:(^\s*)|(\s*$)
应用:javascript中没有像vbscript那样的trim函数,我们就可以利用这个表达式来实现,如下:String.prototype.trim = function(){return this.replace(/(^\s*)|(\s*$)/g, “”);}
利用正则表达式分解和转换IP地址:
下面是利用正则表达式匹配IP地址,并将IP地址转换成对应数值的Javascript程序:
function IP2V(ip){re=/(\d+)\.(\d+)\.(\d+)\.(\d+)/g //匹配IP地址的正则表达式
if(re.test(ip)){return RegExp.$1*Math.pow(255,3))+RegExp.$2*Math.pow(255,2))+RegExp.$3*255+RegExp.$4*1}else{throw new Error(“Not a valid IP address!”)}}
不过上面的程序如果不用正则表达式,而直接用split函数来分解可能更简单,程序如下:
var ip=”10.100.20.168″ip=ip.split(“.”)alert(“IP值是:”+(ip[0]*255*255*255+ip[1]*255*255+ip[2]*255+ip[3]*1))
匹配Email地址的正则表达式:\w+([-+.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)*
匹配网址URL的正则表达式:http://([\w-]+\.)+[\w-]+(/[\w- ./?%&=]*)?
利用正则表达式限制网页表单里的文本框输入内容:
用正则表达式限制只能输入中文:onkeyup=”value=value.replace(/[^\u4E00-\u9FA5]/g,”)” onbeforepaste=”clipboardData.setData(‘text’,clipboardData.getData(‘text’).replace(/[^\u4E00-\u9FA5]/g,”))”
用正则表达式限制只能输入全角字符: onkeyup=”value=value.replace(/[^\uFF00-\uFFFF]/g,”)” onbeforepaste=”clipboardData.setData(‘text’,clipboardData.getData(‘text’).replace(/[^\uFF00-\uFFFF]/g,”))”
用正则表达式限制只能输入数字:onkeyup=”value=value.replace(/[^\d]/g,”) “onbeforepaste=”clipboardData.setData(‘text’,clipboardData.getData(‘text’).replace(/[^\d]/g,”))”
用正则表达式限制只能输入数字和英文:onkeyup=”value=value.replace(/[\W]/g,”) “onbeforepaste=”clipboardData.setData(‘text’,clipboardData.getData(‘text’).replace(/[^\d]/g,”))”
匹配中文字符的正则表达式: [\u4e00-\u9fa5]
评注:匹配中文还真是个头疼的事,有了这个表达式就好办了匹配双字节字符(包括汉字在内):[^\x00-\xff]
评注:可以用来计算字符串的长度(一个双字节字符长度计2,ASCII字符计1)匹配空白行的正则表达式:\n\s*\r
评注:可以用来删除空白行匹配HTML标记的正则表达式:<(\S*?)[^>]*>.*?|<.*? />
评注:网上流传的版本太糟糕,上面这个也仅仅能匹配部分,对于复杂的嵌套标记依旧无能为力匹配首尾空白字符的正则表达式:^\s*|\s*$
评注:可以用来删除行首行尾的空白字符(包括空格、制表符、换页符等等),非常有用的表达式匹配Email地址的正则表达式:\w+([-+.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)*
评注:表单验证时很实用匹配网址URL的正则表达式:[a-zA-z]+://[^\s]*
评注:网上流传的版本功能很有限,上面这个基本可以满足需求匹配帐号是否合法(字母开头,允许5-16字节,允许字母数字下划线):^[a-zA-Z][a-zA-Z0-9_]{4,15}$
评注:表单验证时很实用匹配国内电话号码:\d{3}-\d{8}|\d{4}-\d{7}评注:匹配形式如 0511-4405222 或 021-87888822匹配腾讯QQ号:[1-9][0-9]{4,}
评注:腾讯QQ号从10000开始匹配中国邮政编码:[1-9]\d{5}(?!\d)
评注:中国邮政编码为6位数字匹配身份证:\d{15}|\d{18}
评注:中国的身份证为15位或18位匹配ip地址:\d+\.\d+\.\d+\.\d+
评注:提取ip地址时有用匹配特定数字:^[1-9]\d*$
//匹配正整数^-[1-9]\d*$
//匹配负整数^-?[1-9]\d*$
//匹配整数^[1-9]\d*|0$
//匹配非负整数(正整数 + 0)^-[1-9]\d*|0$
//匹配非正整数(负整数 + 0)^[1-9]\d*\.\d*|0\.\d*[1-9]\d*$
//匹配正浮点数^-([1-9]\d*\.\d*|0\.\d*[1-9]\d*)$
//匹配负浮点数^-?([1-9]\d*\.\d*|0\.\d*[1-9]\d*|0?\.0+|0)$
//匹配浮点数^[1-9]\d*\.\d*|0\.\d*[1-9]\d*|0?\.0+|0$
//匹配非负浮点数(正浮点数 + 0)^(-([1-9]\d*\.\d*|0\.\d*[1-9]\d*))|0?\.0+|0$ //匹配非正浮点数(负浮点数 + 0)评注:处理大量数据时有用,具体应用时注意修正匹配特定字符串:^[A-Za-z]+$
//匹配由26个英文字母组成的字符串^[A-Z]+$
//匹配由26个英文字母的大写组成的字符串^[a-z]+$
//匹配由26个英文字母的小写组成的字符串^[A-Za-z0-9]+$
//匹配由数字和26个英文字母组成的字符串^\w+$
//匹配由数字、26个英文字母或者下划线组成的字符串评注:最基本也是最常用的一些表达式整理出来的一些常用的正则表达式 所属分类: JScript
(三)
Email : /^\w+([-+.]\w+)*@\w+([-.]\\w+)*\.\w+([-.]\w+)*$/
isEmail1 : /^\w+([\.\-]\w+)*\@\w+([\.\-]\w+)*\.\w+$/;
isEmail2 : /^.*@[^_]*$/;
Phone : /^((\(\d{3}\))|(\d{3}\-))?(\(0\d{2,3}\)|0\d{2,3}-)?[1-9]\d{6,7}$/
Mobile : /^((\(\d{3}\))|(\d{3}\-))?13\d{9}$/
Url : /^http:\/\/[A-Za-z0-9]+\.[A-Za-z0-9]+[\/=\?%\-&_~`@[\]\’:+!]*([^<>\"\"])*$/
IdCard : /^\d{15}(\d{2}[A-Za-z0-9])?$/
Currency : /^\d+(\.\d+)?$/
Number : /^\d+$/
Code : /^[1-9]\d{5}$/
QQ : /^[1-9]\d{4,8}$/
Integer : /^[-\+]?\d+$/
Double : /^[-\+]?\d+(\.\d+)?$/
English : /^[A-Za-z]+$/
Chinese : /^[\u0391-\uFFE5]+$/
UnSafe : /^(([A-Z]*|[a-z]*|\d*|[-_\~!@#\$%\^&\*\.\(\)\[\]\{\}<>\?\\\/\’\”]*)|.{0,5})$|\s/
PassWord :^[\\w]{6,12}$
ZipCode : ^[\\d]{6}/^(\+\d+ )?(\(\d+\) )?[\d ]+$/;
//这个是国际通用的电话号码判断/^(1[0-2]\d|\d{1,2})$/;
//这个是年龄的判断/^\d+\.\d{2}$/;
//这个是判断输入的是否为货币值
应用:计算字符串的长度(一个双字节字符长度计2,ASCII字符计1)String.prototype.len=function(){return this.replace([^\x00-\xff]/g,”aa”).length;}
应用:javascript中没有像vbscript那样的trim函数,我们就可以利用这个表达式来实现,如下:String.prototype.trim = function(){return this.replace(/(^\s*)|(\s*$)/g, “”);}
匹配空行的正则表达式:\n[\s| ]*\r
匹配HTML标记的正则表达式:/<(.*)>.*<\/\1>|<(.*) \/>/
匹配首尾空格的正则表达式:(^\s*)|(\s*$)
匹配Email地址的正则表达式:\w+([-+.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)*
匹配网址URL的正则表达式:http://([\w-]+\.)+[\w-]+(/[\w- ./?%&=]*)?^\d+$ //
匹配非负整数(正整数 + 0)^[0-9]*[1-9][0-9]*$ //
匹配正整数^((-\d+)|(0+))$ //
匹配非正整数(负整数 + 0)^-[0-9]*[1-9][0-9]*$ //
匹配负整数^-?\d+$ //
匹配整数^\d+(\.\d+)?$ //
匹配非负浮点数(正浮点数 + 0)^(([0-9]+\.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*\.[0-9]+)|([0-9]*[1-9][0-9]*))$ //
匹配正浮点数^((-\d+(\.\d+)?)|(0+(\.0+)?))$ //
匹配非正浮点数(负浮点数 + 0)^(-(([0-9]+\.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*\.[0-9]+)|([0-9]*[1-9][0-9]*)))$ //
匹配负浮点数^(-?\d+)(\.\d+)?$
练习网站:练习正则表达式
Java 正则表达式
正则表达式定义了字符串的模式。
正则表达式可以用来搜索、编辑或处理文本。
正则表达式并不仅限于某一种语言,但是在每种语言中有细微的差别。
正则表达式实例
java.util.regex 包主要包括以下三个类:
-
Pattern 类:
pattern 对象是一个正则表达式的编译表示。Pattern 类没有公共构造方法。要创建一个 Pattern 对象,你必须首先调用其公共静态编译方法,它返回一个 Pattern 对象。该方法接受一个正则表达式作为它的第一个参数。 -
Matcher 类:
Matcher 对象是对输入字符串进行解释和匹配操作的引擎。与Pattern 类一样,Matcher 也没有公共构造方法。你需要调用 Pattern 对象的 matcher 方法来获得一个 Matcher 对象。 -
PatternSyntaxException:
PatternSyntaxException 是一个非强制异常类,它表示一个正则表达式模式中的语法错误。
以下实例中使用了正则表达式 .*runoob.* 用于查找字符串中是否包了 runoob 子串:
import java.util.regex.*;
class RegexExample1{
public static void main(String[] args){
String content = "I am noob " +
"from runoob.com.";
String pattern = ".*runoob.*";
boolean isMatch = Pattern.matches(pattern, content);
System.out.println("字符串中是否包含了 'runoob' 子字符串? " + isMatch);
}
}
运行结果:
字符串中是否包含了 'runoob' 子字符串? true
捕获组
捕获组是把多个字符当一个单独单元进行处理的方法,它通过对括号内的字符分组来创建。
例如,正则表达式 (dog) 创建了单一分组,组里包含"d","o",和"g"。
捕获组是通过从左至右计算其开括号来编号。例如,在表达式((A)(B(C))),有四个这样的组:
- ((A)(B(C)))
- (A)
- (B(C))
- (C)
可以通过调用 matcher 对象的 groupCount 方法来查看表达式有多少个分组。groupCount 方法返回一个 int 值,表示matcher对象当前有多个捕获组。
还有一个特殊的组(group(0)),它总是代表整个表达式。该组不包括在 groupCount 的返回值中。
实例
下面的例子说明如何从一个给定的字符串中找到数字串:
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class RegexMatches {
public static void main( String[] args ) {
// 按指定模式在字符串查找
String line = "This order was placed for QT3000! OK?";
String pattern = "(\\D*)(\\d+)(.*)";
// 创建 Pattern 对象
Pattern r = Pattern.compile(pattern);
// 现在创建 matcher 对象
Matcher m = r.matcher(line);
if (m.find()) {
System.out.println("Found value: " + m.group(0) );
System.out.println("Found value: " + m.group(1) );
System.out.println("Found value: " + m.group(2) );
System.out.println("Found value: " + m.group(3) );
} else {
System.out.println("NO MATCH");
}
}
}
以上实例编译运行结果如下:
Found value: This order was placed for QT3000! OK?
Found value: This order was placed for QT
Found value: 3000
Found value: ! OK?
正则表达式语法
在其他语言中,\\ 表示:我想要在正则表达式中插入一个普通的(字面上的)反斜杠,请不要给它任何特殊的意义。
在 Java 中,\\ 表示:我要插入一个正则表达式的反斜线,所以其后的字符具有特殊的意义。
所以,在其他的语言中(如Perl),一个反斜杠 \ 就足以具有转义的作用,而在 Java 中正则表达式中则需要有两个反斜杠才能被解析为其他语言中的转义作用。也可以简单的理解在 Java 的正则表达式中,两个 \\ 代表其他语言中的一个 \,这也就是为什么表示一位数字的正则表达式是 \\d,而表示一个普通的反斜杠是 \\\\。
\| 将下一字符标记为特殊字符、文本、反向引用或八进制转义符。例如,"n"匹配字符"n"。"\n"匹配换行符。序列"\\\\"匹配"\\","\\("匹配"("。^:匹配输入字符串开始的位置。如果设置了 RegExp 对象的 Multiline 属性,^ 还会与"\n"或"\r"之后的位置匹配。$:匹配输入字符串结尾的位置。如果设置了 RegExp 对象的 Multiline 属性,$ 还会与"\n"或"\r"之前的位置匹配。*:零次或多次匹配前面的字符或子表达式。例如,zo* 匹配"z"和"zoo"。* 等效于 {0,}。+:一次或多次匹配前面的字符或子表达式。例如,"zo+"与"zo"和"zoo"匹配,但与"z"不匹配。+ 等效于 {1,}。?:零次或一次匹配前面的字符或子表达式。例如,"do(es)?"匹配"do"或"does"中的"do"。? 等效于 {0,1}。{n}:n 是非负整数。正好匹配 n 次。例如,"o{2}"与"Bob"中的"o"不匹配,但与"food"中的两个"o"匹配。{n,}:n 是非负整数。至少匹配 n 次。例如,"o{2,}"不匹配"Bob"中的"o",而匹配"foooood"中的所有 o。"o{1,}"等效于"o+"。"o{0,}"等效于"o*"。{n,m}:m 和 n 是非负整数,其中 n <= m。匹配至少 n 次,至多 m 次。例如,"o{1,3}"匹配"fooooood"中的头三个 o。'o{0,1}' 等效于 'o?'。注意:您不能将空格插入逗号和数字之间。?:当此字符紧随任何其他限定符(*、+、?、{n}、{n,}、{n,m})之后时,匹配模式是"非贪心的"。"非贪心的"模式匹配搜索到的、尽可能短的字符串,而默认的"贪心的"模式匹配搜索到的、尽可能长的字符串。例如,在字符串"oooo"中,"o+?"只匹配单个"o",而"o+"匹配所有"o"。.:匹配除"\r\n"之外的任何单个字符。若要匹配包括"\r\n"在内的任意字符,请使用诸如"[\s\S]"之类的模式。(pattern):匹配 pattern 并捕获该匹配的子表达式。可以使用$0…$9属性从结果"匹配"集合中检索捕获的匹配。若要匹配括号字符 ( ),请使用"\("或者"\)"。
这种$0获取匹配变量还是蛮有用的,如 驼峰转下划线str.replaceAll("[A-Z]", "_$0").toLowerCase();(?:pattern):匹配 pattern 但不捕获该匹配的子表达式,即它是一个非捕获匹配,不存储供以后使用的匹配。这对于用"or"字符 (|) 组合模式部件的情况很有用。例如,'industr(?:y|ies) 是比 'industry|industries' 更经济的表达式。(?=pattern):执行正向预测先行搜索的子表达式,该表达式匹配处于匹配 pattern 的字符串的起始点的字符串。它是一个非捕获匹配,即不能捕获供以后使用的匹配。例如,'Windows (?=95|98|NT|2000)' 匹配"Windows 2000"中的"Windows",但不匹配"Windows 3.1"中的"Windows"。预测先行不占用字符,即发生匹配后,下一匹配的搜索紧随上一匹配之后,而不是在组成预测先行的字符后。(?!pattern):执行反向预测先行搜索的子表达式,该表达式匹配不处于匹配 pattern 的字符串的起始点的搜索字符串。它是一个非捕获匹配,即不能捕获供以后使用的匹配。例如,'Windows (?!95|98|NT|2000)' 匹配"Windows 3.1"中的 "Windows",但不匹配"Windows 2000"中的"Windows"。预测先行不占用字符,即发生匹配后,下一匹配的搜索紧随上一匹配之后,而不是在组成预测先行的字符后。x|y:匹配 x 或 y。例如,'z|food' 匹配"z"或"food"。'(z|f)ood' 匹配"zood"或"food"。[xyz]:字符集。匹配包含的任一字符。例如,"[abc]"匹配"plain"中的"a"。[^xyz]:反向字符集。匹配未包含的任何字符。例如,"[^abc]"匹配"plain"中"p","l","i","n"。[a-z]:字符范围。匹配指定范围内的任何字符。例如,"[a-z]"匹配"a"到"z"范围内的任何小写字母。[^a-z]:反向范围字符。匹配不在指定的范围内的任何字符。例如,"[^a-z]"匹配任何不在"a"到"z"范围内的任何字符。\b:匹配一个字边界,即字与空格间的位置。例如,"er\b"匹配"never"中的"er",但不匹配"verb"中的"er"。\B:非字边界匹配。"er\B"匹配"verb"中的"er",但不匹配"never"中的"er"。\cx:匹配 x 指示的控制字符。例如,\cM 匹配 Control-M 或回车符。x 的值必须在 A-Z 或 a-z 之间。如果不是这样,则假定 c 就是"c"字符本身。\d:数字字符匹配。等效于 [0-9]。\D:非数字字符匹配。等效于 [^0-9]。\f:换页符匹配。等效于 \x0c 和 \cL。\n:换行符匹配。等效于 \x0a 和 \cJ。\r:匹配一个回车符。等效于 \x0d 和 \cM。\s:匹配任何空白字符,包括空格、制表符、换页符等。与 [ \f\n\r \v] 等效。\S:匹配任何非空白字符。与 [^ \f\n\r\t\v] 等效。\t:制表符匹配。与 \x09 和 \cI 等效。\v:垂直制表符匹配。与 \x0b 和 \cK 等效。\w:匹配任何字类字符,包括下划线。与"[A-Za-z0-9_]"等效。\W:与任何非单词字符匹配。与"[^A-Za-z0-9_]"等效。\xn:匹配 n,此处的 n 是一个十六进制转义码。十六进制转义码必须正好是两位数长。例如,"\x41"匹配"A"。"\x041"与"\x04"&"1"等效。允许在正则表达式中使用 ASCII 代码。\num:匹配 num,此处的 num 是一个正整数。到捕获匹配的反向引用。例如,"(.)\1"匹配两个连续的相同字符。\n:标识一个八进制转义码或反向引用。如果 \n 前面至少有 n 个捕获子表达式,那么 n 是反向引用。否则,如果 n 是八进制数 (0-7),那么 n 是八进制转义码。\nm:标识一个八进制转义码或反向引用。如果 \nm 前面至少有 nm 个捕获子表达式,那么 nm 是反向引用。如果 \nm 前面至少有 n 个捕获,则 n 是反向引用,后面跟有字符 m。如果两种前面的情况都不存在,则 \nm 匹配八进制值 nm,其中 n 和 m 是八进制数字 (0-7)。\nml:当 n 是八进制数 (0-3),m 和 l 是八进制数 (0-7) 时,匹配八进制转义码 nml。\un:匹配 n,其中 n 是以四位十六进制数表示的 Unicode 字符。例如,\u00A9 匹配版权符号 (©)。
根据 Java Language Specification 的要求,Java 源代码的字符串中的反斜线被解释为 Unicode 转义或其他字符转义。因此必须在字符串字面值中使用两个反斜线,表示正则表达式受到保护,不被 Java 字节码编译器解释。例如,当解释为正则表达式时,字符串字面值
"\b"与单个退格字符匹配,而"\\b"与单词边界匹配。字符串字面值"\(hello\)"是非法的,将导致编译时错误;要与字符串 (hello) 匹配,必须使用字符串字面值"\\(hello\\)"。
Matcher 类的方法
索引方法
索引方法提供了有用的索引值,精确表明输入字符串中在哪能找到匹配:
| 序号 | 方法 | 说明 |
|---|---|---|
| 1 | public int start() | 返回以前匹配的初始索引。 |
| 2 | public int start(int group) | 返回在以前的匹配操作期间,由给定组所捕获的子序列的初始索引 |
| 3 | public int end() | 返回最后匹配字符之后的偏移量。 |
| 4 | public int end(int group) | 返回在以前的匹配操作期间,由给定组所捕获子序列的最后字符之后的偏移量。 |
查找方法
查找方法用来检查输入字符串并返回一个布尔值,表示是否找到该模式:
| 序号 | 方法 | 说明 |
|---|---|---|
| 1 | public boolean lookingAt() | 尝试将从区域开头开始的输入序列与该模式匹配。 |
| 2 | public boolean find() | 尝试查找与该模式匹配的输入序列的下一个子序列。 |
| 3 | public boolean find(int start) | 重置此匹配器,然后尝试查找匹配该模式、从指定索引开始的输入序列的下一个子序列。 |
| 4 | public boolean matches() | 尝试将整个区域与模式匹配。 |
替换方法
替换方法是替换输入字符串里文本的方法:
| 序号 | 方法 | 说明 |
|---|---|---|
| 1 | public Matcher appendReplacement(StringBuffer sb, String replacement) | 实现非终端添加和替换步骤。 |
| 2 | public StringBuffer appendTail(StringBuffer sb) | 实现终端添加和替换步骤。 |
| 3 | public String replaceAll(String replacement) | 替换模式与给定替换字符串相匹配的输入序列的每个子序列。 |
| 4 | public String replaceFirst(String replacement) | 替换模式与给定替换字符串匹配的输入序列的第一个子序列。 |
| 5 | public static String quoteReplacement(String s) | 返回指定字符串的字面替换字符串。这个方法返回一个字符串,就像传递给Matcher类的appendReplacement 方法一个字面字符串一样工作。 |
start 和 end 方法
下面是一个对单词 "cat" 出现在输入字符串中出现次数进行计数的例子:
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class RegexMatches {
private static final String REGEX = "\\bcat\\b";
private static final String INPUT =
"cat cat cat cattie cat";
public static void main( String[] args ){
Pattern p = Pattern.compile(REGEX);
Matcher m = p.matcher(INPUT); // 获取 matcher 对象
int count = 0;
while(m.find()) {
count++;
System.out.println("Match number "+count);
System.out.println("start(): "+m.start());
System.out.println("end(): "+m.end());
}
}
}
以上实例编译运行结果如下:
Match number 1
start(): 0
end(): 3
Match number 2
start(): 4
end(): 7
Match number 3
start(): 8
end(): 11
Match number 4
start(): 19
end(): 22
可以看到这个例子是使用单词边界,以确保字母 "c" "a" "t" 并非仅是一个较长的词的子串。它也提供了一些关于输入字符串中匹配发生位置的有用信息。
Start 方法返回在以前的匹配操作期间,由给定组所捕获的子序列的初始索引,end 方法最后一个匹配字符的索引加 1。
matches 和 lookingAt 方法
matches 和 lookingAt 方法都用来尝试匹配一个输入序列模式。它们的不同是 matches 要求整个序列都匹配,而lookingAt 不要求。
lookingAt 方法虽然不需要整句都匹配,但是需要从第一个字符开始匹配。
这两个方法经常在输入字符串的开始使用。
我们通过下面这个例子,来解释这个功能:
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class RegexMatches {
private static final String REGEX = "foo";
private static final String INPUT = "fooooooooooooooooo";
private static final String INPUT2 = "ooooofoooooooooooo";
private static Pattern pattern;
private static Matcher matcher;
private static Matcher matcher2;
public static void main( String[] args ){
pattern = Pattern.compile(REGEX);
matcher = pattern.matcher(INPUT);
matcher2 = pattern.matcher(INPUT2);
System.out.println("Current REGEX is: "+REGEX);
System.out.println("Current INPUT is: "+INPUT);
System.out.println("Current INPUT2 is: "+INPUT2);
System.out.println("lookingAt(): "+matcher.lookingAt());
System.out.println("matches(): "+matcher.matches());
System.out.println("lookingAt(): "+matcher2.lookingAt());
}
}
以上实例编译运行结果如下:
Current REGEX is: foo
Current INPUT is: fooooooooooooooooo
Current INPUT2 is: ooooofoooooooooooo
lookingAt(): true
matches(): false
lookingAt(): false
replaceFirst 和 replaceAll 方法
replaceFirst 和 replaceAll 方法用来替换匹配正则表达式的文本。不同的是,replaceFirst 替换首次匹配,replaceAll 替换所有匹配。
下面的例子来解释这个功能:
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class RegexMatches {
private static String REGEX = "dog";
private static String INPUT = "The dog says meow. " +
"All dogs say meow.";
private static String REPLACE = "cat";
public static void main(String[] args) {
Pattern p = Pattern.compile(REGEX);
// get a matcher object
Matcher m = p.matcher(INPUT);
INPUT = m.replaceAll(REPLACE);
System.out.println(INPUT);
}
}
以上实例编译运行结果如下:
The cat says meow. All cats say meow.
appendReplacement 和 appendTail 方法
Matcher 类也提供了appendReplacement 和 appendTail 方法用于文本替换:
看下面的例子来解释这个功能:
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class RegexMatches {
private static String REGEX = "a*b";
private static String INPUT = "aabfooaabfooabfoobkkk";
private static String REPLACE = "-";
public static void main(String[] args) {
Pattern p = Pattern.compile(REGEX);
// 获取 matcher 对象
Matcher m = p.matcher(INPUT);
StringBuffer sb = new StringBuffer();
while(m.find()){
m.appendReplacement(sb,REPLACE);
}
m.appendTail(sb);
System.out.println(sb.toString());
}
}
以上实例编译运行结果如下:
-foo-foo-foo-kkk
PatternSyntaxException 类的方法
PatternSyntaxException 是一个非强制异常类,它指示一个正则表达式模式中的语法错误。
PatternSyntaxException 类提供了下面的方法来帮助我们查看发生了什么错误。
| 序号 | 方法 | 说明 |
|---|---|---|
| 1 | public String getDescription() | 获取错误的描述。 |
| 2 | public int getIndex() | 获取错误的索引。 |
| 3 | public String getPattern() | 获取错误的正则表达式模式。 |
| 4 | public String getMessage() | 返回多行字符串,包含语法错误及其索引的描述、错误的正则表达式模式和模式中错误索引的可视化指示。 |
捕获组
捕获组分为:
- 普通捕获组(Expression)
- 命名捕获组(?Expression)
普通捕获组
从正则表达式左侧开始,每出现一个左括号"("记做一个分组,分组编号从 1 开始。0 代表整个表达式。
对于时间字符串:2017-04-25,表达式如下
(\\d{4})-((\\d{2})-(\\d{2}))
有 4 个左括号,所以有 4 个分组:
| 编号 | 捕获组 | 匹配 |
|---|---|---|
| 0 | (\d{4})-((\d{2})-(\d{2})) | 2017-04-25 |
| 1 | (\d{4}) | 2017 |
| 2 | ((\d{2})-(\d{2})) | 04-25 |
| 3 | (\d{2}) | 04 |
| 4 | (\d{2}) | 25 |
代码:
public static final String DATE_STRING = "2017-04-25";
public static final String P_COMM = "(\\d{4})-((\\d{2})-(\\d{2}))";
Pattern pattern = Pattern.compile(P_COMM);
Matcher matcher = pattern.matcher(DATE_STRING);
while (matcher.find()) { //必须要有这句,去不断寻找下一个
System.out.printf("\nmatcher.group(0) value:%s", matcher.group()); // 默认为0
System.out.printf("\nmatcher.group(0) value:%s", matcher.group(0));
System.out.printf("\nmatcher.group(1) value:%s", matcher.group(1));
System.out.printf("\nmatcher.group(2) value:%s", matcher.group(2));
System.out.printf("\nmatcher.group(3) value:%s", matcher.group(3));
System.out.printf("\nmatcher.group(4) value:%s", matcher.group(4));
}
运行结果:
matcher.group(0) value:2017-04-25
matcher.group(0) value:2017-04-25
matcher.group(1) value:2017
matcher.group(2) value:04-25
matcher.group(3) value:04
matcher.group(4) value:25
命名捕获组
每个以左括号开始的捕获组,都紧跟着 ?,而后才是正则表达式。
对于时间字符串:2017-04-25,表达式如下:
(?<year>\\d{4})-(?<md>(?<month>\\d{2})-(?<date>\\d{2}))
有 4 个命名的捕获组,分别是:
| 编号 | 名称 | 捕获组 | 匹配 |
|---|---|---|---|
| 0 | 0 | (?\d{4})-(?(?\d{2})-(?\d{2})) | 2017-04-25 |
| 1 | year | (?\d{4})- | 2017 |
| 2 | md | (?(?\d{2})-(?\d{2})) | 04-25 |
| 3 | month | (?\d{2}) | 04 |
| 4 | date | (?\d{2}) | 25 |
命名的捕获组同样也可以使用编号获取相应值。
public static final String P_NAMED = "(?<year>\\d{4})-(?<md>(?<month>\\d{2})-(?<date>\\d{2}))";
public static final String DATE_STRING = "2017-04-25";
Pattern pattern = Pattern.compile(P_NAMED);
Matcher matcher = pattern.matcher(DATE_STRING);
matcher.find();
System.out.printf("\n===========使用名称获取=============");
System.out.printf("\nmatcher.group(0) value:%s", matcher.group(0));
System.out.printf("\n matcher.group('year') value:%s", matcher.group("year"));
System.out.printf("\nmatcher.group('md') value:%s", matcher.group("md"));
System.out.printf("\nmatcher.group('month') value:%s", matcher.group("month"));
System.out.printf("\nmatcher.group('date') value:%s", matcher.group("date"));
matcher.reset();
System.out.printf("\n===========使用编号获取=============");
matcher.find();
System.out.printf("\nmatcher.group(0) value:%s", matcher.group(0));
System.out.printf("\nmatcher.group(1) value:%s", matcher.group(1));
System.out.printf("\nmatcher.group(2) value:%s", matcher.group(2));
System.out.printf("\nmatcher.group(3) value:%s", matcher.group(3));
System.out.printf("\nmatcher.group(4) value:%s", matcher.group(4));
PS:非捕获组
在左括号后紧跟 ?:,而后再加上正则表达式,构成非捕获组 (?:Expression)。
对于时间字符串:2017-04-25,表达式如下:
(?:\\d{4})-((\\d{2})-(\\d{2}))
这个正则表达式虽然有四个左括号,理论上有 4 个捕获组。但是第一组 (?:\d{4}),其实是被忽略的。当使用 matcher.group(4) 时,系统会报错。
| 编号 | 捕获组 | 匹配 |
|---|---|---|
| 0 | (\d{4})-((\d{2})-(\d{2})) | 2017-04-25 |
| 1 | ((\d{2})-(\d{2})) | 04-25 |
| 2 | (\d{2}) | 04 |
| 3 | (\d{2}) | 25 |
public static final String P_UNCAP = "(?:\\d{4})-((\\d{2})-(\\d{2}))";
public static final String DATE_STRING = "2017-04-25";
Pattern pattern = Pattern.compile(P_UNCAP);
Matcher matcher = pattern.matcher(DATE_STRING);
matcher.find();
System.out.printf("\nmatcher.group(0) value:%s", matcher.group(0));
System.out.printf("\nmatcher.group(1) value:%s", matcher.group(1));
System.out.printf("\nmatcher.group(2) value:%s", matcher.group(2));
System.out.printf("\nmatcher.group(3) value:%s", matcher.group(3));
// Exception in thread "main" java.lang.IndexOutOfBoundsException: No group 4
System.out.printf("\nmatcher.group(4) value:%s", matcher.group(4));
总结
- 普通捕获组使用方便;
- 命名捕获组使用清晰;
- 非捕获组目前在项目中还没有用武之地。
Pattern的所有方法
| Modifier and Type | Method | Description |
|---|---|---|
Predicate<String> |
asMatchPredicate() |
Creates a predicate that tests if this pattern matches a given input string.
|
Predicate<String> |
asPredicate() |
Creates a predicate that tests if this pattern is found in a given input
string.
|
static Pattern |
compile(String regex) |
Compiles the given regular expression into a pattern.
|
static Pattern |
compile(String regex,
int flags) |
Compiles the given regular expression into a pattern with the given
flags.
|
int |
flags() |
Returns this pattern's match flags.
|
Matcher |
matcher(CharSequence input) |
Creates a matcher that will match the given input against this pattern.
|
static boolean |
matches(String regex,
CharSequence input) |
Compiles the given regular expression and attempts to match the given
input against it.
|
String |
pattern() |
Returns the regular expression from which this pattern was compiled.
|
static String |
quote(String s) |
Returns a literal pattern
String for the specified
String. |
String[] |
split(CharSequence input) |
Splits the given input sequence around matches of this pattern.
|
String[] |
split(CharSequence input,
int limit) |
Splits the given input sequence around matches of this pattern.
|
Stream<String> |
splitAsStream(CharSequence input) |
Creates a stream from the given input sequence around matches of this
pattern.
|
String |
toString() |
Returns the string representation of this pattern.
|
Matcher的所有方法
| Modifier and Type | Method | Description |
|---|---|---|
Matcher |
appendReplacement(StringBuffer sb,
String replacement) |
Implements a non-terminal append-and-replace step.
|
Matcher |
appendReplacement(StringBuilder sb,
String replacement) |
Implements a non-terminal append-and-replace step.
|
StringBuffer |
appendTail(StringBuffer sb) |
Implements a terminal append-and-replace step.
|
StringBuilder |
appendTail(StringBuilder sb) |
Implements a terminal append-and-replace step.
|
int |
end() |
Returns the offset after the last character matched.
|
int |
end(int group) |
Returns the offset after the last character of the subsequence
captured by the given group during the previous match operation.
|
int |
end(String name) |
Returns the offset after the last character of the subsequence
captured by the given named-capturing
group during the previous match operation.
|
boolean |
find() |
Attempts to find the next subsequence of the input sequence that matches
the pattern.
|
boolean |
find(int start) |
Resets this matcher and then attempts to find the next subsequence of
the input sequence that matches the pattern, starting at the specified
index.
|
String |
group() |
Returns the input subsequence matched by the previous match.
|
String |
group(int group) |
Returns the input subsequence captured by the given group during the
previous match operation.
|
String |
group(String name) |
Returns the input subsequence captured by the given
named-capturing group during the
previous match operation.
|
int |
groupCount() |
Returns the number of capturing groups in this matcher's pattern.
|
boolean |
hasAnchoringBounds() |
Queries the anchoring of region bounds for this matcher.
|
boolean |
hasTransparentBounds() |
Queries the transparency of region bounds for this matcher.
|
boolean |
hitEnd() |
Returns true if the end of input was hit by the search engine in
the last match operation performed by this matcher.
|
boolean |
lookingAt() |
Attempts to match the input sequence, starting at the beginning of the
region, against the pattern.
|
boolean |
matches() |
Attempts to match the entire region against the pattern.
|
Pattern |
pattern() |
Returns the pattern that is interpreted by this matcher.
|
static String |
quoteReplacement(String s) |
Returns a literal replacement
String for the specified
String. |
Matcher |
region(int start,
int end) |
Sets the limits of this matcher's region.
|
int |
regionEnd() |
Reports the end index (exclusive) of this matcher's region.
|
int |
regionStart() |
Reports the start index of this matcher's region.
|
String |
replaceAll(String replacement) |
Replaces every subsequence of the input sequence that matches the
pattern with the given replacement string.
|
String |
replaceAll(Function<MatchResult,String> replacer) |
Replaces every subsequence of the input sequence that matches the
pattern with the result of applying the given replacer function to the
match result of this matcher corresponding to that subsequence.
|
String |
replaceFirst(String replacement) |
Replaces the first subsequence of the input sequence that matches the
pattern with the given replacement string.
|
String |
replaceFirst(Function<MatchResult,String> replacer) |
Replaces the first subsequence of the input sequence that matches the
pattern with the result of applying the given replacer function to the
match result of this matcher corresponding to that subsequence.
|
boolean |
requireEnd() |
Returns true if more input could change a positive match into a
negative one.
|
Matcher |
reset() |
Resets this matcher.
|
Matcher |
reset(CharSequence input) |
Resets this matcher with a new input sequence.
|
Stream<MatchResult> |
results() |
Returns a stream of match results for each subsequence of the input
sequence that matches the pattern.
|
int |
start() |
Returns the start index of the previous match.
|
int |
start(int group) |
Returns the start index of the subsequence captured by the given group
during the previous match operation.
|
int |
start(String name) |
Returns the start index of the subsequence captured by the given
named-capturing group during the
previous match operation.
|
MatchResult |
toMatchResult() |
Returns the match state of this matcher as a
MatchResult. |
String |
toString() |
Returns the string representation of this matcher.
|
Matcher |
useAnchoringBounds(boolean b) |
Sets the anchoring of region bounds for this matcher.
|
Matcher |
usePattern(Pattern newPattern) |
Changes the
Pattern that this Matcher uses to
find matches with. |
Matcher |
useTransparentBounds(boolean b) |
Sets the transparency of region bounds for this matcher.
|
实例
剑指 Offer 20. 表示数值的字符串
请实现一个函数用来判断字符串是否表示数值(包括整数和小数)。例如,字符串"+100"、"5e2"、"-123"、"3.1416"、"-1E-16"、"0123"都表示数值,但"12e"、"1a3.14"、"1.2.3"、"+-5"及"12e+5.4"都不是。
答案
该题的正则表达式可以描述为
^[+|-]?((\\d+\\.?)|(\\d*\\.?\\d+))([E|e][+|-]?\\d+)?$
则可以直接用正则表达式搞定
class Solution {
public boolean isNumber(String s) {
String regex = "^[+|-]?((\\d+\\.?)|(\\d*\\.?\\d+))([E|e][+|-]?\\d+)?$";
return s.trim().matches(regex);
}
}
笔者将不定期更新【考研或就业】的专业相关知识以及自身理解,希望大家能【关注】我。
如果觉得对您有用,请点击左下角的【点赞】按钮,给我一些鼓励,谢谢!
如果有更好的理解或建议,请在【评论】中写出,我会及时修改,谢谢啦!
本文来自博客园,作者:Nemo&
转载请注明原文链接:https://www.cnblogs.com/blknemo/p/10034890.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号