【SQL】SELECT语句

SELECT语句的组成:
| 子句 | 描述 | 备注 |
|---|---|---|
SELECT |
显示指定列的内容 | 不可缺少,可以为列名指定别名,列名也可以是表达式 |
FROM |
指明数据来源 | 不可缺少,可以为表名指定别名 |
INTO |
将查询结果存储到新表中 | 可缺少,新表中各列的参数与原表相同,用于快速建表 |
WHERE |
指定条件 | 若缺少此项,则表示全部记录 |
GROUP BY |
将查询结果分组显示 | 可缺少,分组依据通常是一个列名 |
ORDER BY |
将查询结果排序 | 可缺少,可以指定排列方式为升序(默认)和降序 |
LIMIT |
用来限制结果数量 | 可缺少 |
SELECT语句的完整语法:SFWGHOL(说服我干活噢了)
SELECT【ALL/DISTINCT】目标列表达式 【AS 别名】, ··· --ALL不去掉重复 DISTINCT去掉重复
FROM 表名或视图名 或者(SELECT语句)AS 表名(属性)
[JOIN] 表名 [ON] 连接条件
[WHERE] 条件表达式
[GROUP BY] 列名 【HAVING 条件表达式】
[ORDER BY] 列名 【ASC|DESC】 --ASC = ASCENDING(默认为递增)DESC = DESCENDING(递减)
[LIMIT子句]
其中SELECT和FROM是必须的,其他关键字是可选的。
技巧:SELECT查询出来是一张视图,视图可以放在FROM中嵌套查询。
注意:这几个关键字的执行顺序与SQL语句的书写顺序并不是一致的。
执行顺序:
FROM:需要从那个数据表检索数据ON:筛选条件。配合join使用,用于多表查询。根据on的条件筛选出满足条件的行,生成虚拟表 v2。
在数据库实现里,优化器会把 ON 条件下推到执行计划,用索引、哈希、归并等方式避免真正产生笛卡尔积。
【SQL】执行计划
JOIN:连接方式。用于多表查询WHERE:过滤表中数据的条件GROUP BY:如何将上面过滤出的数据分组HAVING:对上面已经分组的数据进行过滤的条件SELECT:挑选结果集中的哪个列 或 列的计算结果ORDER BY:按照什么样的顺序来查看返回的数据
注意:
ORDER BY的执行顺序在SELECT之后,所以是可以使用SELECT语句中的AS别名的
limit:虽然 LIMIT 在逻辑执行顺序里排在最后一步,但数据库的物理执行计划会把它当成“提前终止”条件,边算边停,绝不会先把 1 万行全部物化出来再丢掉 9999 行。
https://learn.microsoft.com/en-us/previous-versions/sql/sql-server-2008/ms189499(v=sql.100)
https://blog.csdn.net/JokerLJG/article/details/126509214
缩进格式
如下,一个字段一行:
SELECT customers.customer_id id,
customers.customer_name name,
orders.order_id,
orders.order_date
FROM customers
LEFT JOIN orders ON
orders.customer_id = customers.customer_id --join的表字段放前面(方便查看)
AND XXXX = XXX
WHERE
customer_state = 'NY'
AND order_status = 'Completed'
OR order_status = 'Shipped'
OR customer_id IN (
SELECT customer_id
FROM orders
WHERE order_status = 'Completed'
)
竖屏显示
技巧:可以在SELECT语句后面加上\G代表group分组,竖屏显示每一列数据,更清晰。
SELECT * FROM table\G;
***********1. row*************
id: 1
name: 2
size: 3
去重选项
去重选项:是指是否对结果中完全相同的记录(所有字段数据都相同)进行去重:
ALL:不去重(默认)DISTINCT:去重
- 语法:
SELECT 去重选项 字段列表 FROM 表名;
CREATE TABLE student(name VARCHAR(15),gender VARCHAR(15));
INSERT INTO student(name,gender) VALUES("lihua","male");
INSERT INTO student(name,gender) VALUES("lihua","male");
SELECT * FROM student;
SELECT DISTINCT * FROM student;
注意:去重针对的是查询出来的记录,而不是存储在表中的记录。如果说仅仅查询的是某些字段,那么去重针对的是这些字段。
字段别名
字段别名:是指给列名另取一个名字。
- 字段别名只会在当次查询结果中生效。
- 字段别名一般都是简写字段名、辅助了解字段意义(比如我们定义的名字是name,我们希望返回给用户的结果显示成姓名)
- 语法:
SELECT 字段 AS 字段别名 FROM 表名;
注意:字段别名一般是不需要单引号或者双引号的,直接写就可以了。除非字段别名为空的空格。
CREATE TABLE student(name VARCHAR(15),gender VARCHAR(15));
INSERT INTO student(name,gender) VALUES("lihua","male");
INSERT INTO student(name,gender) VALUES("lihua","male");
SELECT * FROM student;
SELECT name AS "姓名",gender AS "性别" FROM student;
数据源
事实上,查询的来源可以不是“表名”,只需是一个二维表视图即可。那么数据来源可以是一个SELECT结果。
数据源可以为单表数据源 或者 多表数据源
- 单表:
SELECT 字段列表 FROM 表名; - 多表:
SELECT 字段列表 FROM 表名1,表名2,…;
注意:多表查询时是将每个表中的X条记录与另一个表Y条记录组成结果,组成的结果的记录条数为X*Y (笛卡尔积)
- 语法:
SELECT 字段列表 FROM (SELECT语句) AS 表别名;
这是将一个查询结果作为一个查询的目标二维表视图,需要将查询结果定义成一个表别名才能作为数据源
SELECT name FROM (SELECT * FROM student) AS d;
WHERE子句
WHERE子句:用于(从磁盘中)筛选符合条件的结果。
WHERE几种语法:
基于值:
=
=:WHERE 字段 = 值;
查找出对应字段等于对应值的记录。
(相似的,<是小于对应值,<=是小于等于对应值,>是大于对应值,>=是大于等于对应值,!=是不等于)例如:
WHERE NAME = 'lihua'
LIKE
LIKE:WHERE 字段 LIKE 值;
功能与 = 相似,用来匹配字符串,但可以使用模糊匹配来查找结果。- 通配符
%用法:替代一个或多个字符 - 通配符
_用法:仅替代一个字符 - 通配符
[charlist]用法:字符列中的任何单一字符 - 通配符
[^charlist]用法:不在字符列中的任何单一字符例如:
WHERE NAME LIKE 'li%' - 转义:
like '%\_%' escape '\',这样可以匹配出包含下划线_的字符串
- 通配符
技巧:当字段存入的值为(CSV)逗号分隔的字符串(
1,2,3,11)时,可以使用WHERE ',' || SCENE || ',' LIKE '%,1,%',(1,2,3,11)->(,1,2,3,11,),这样就不会把11当作1查出来了。
特别技巧:直接使用单字符(n进制,如 62进制=10个数字+26个大写字母+26个小写字母,[0-9A-Za-z]),避免多字符造成的查询影响。
https://www.saoniuhuo.com/question/detail-2754805.html
IS
IS:WHERE 字段 IS 值;
判断对应字段是否为空。(IS [NOT] NULL)
基于值的范围:
IN
-
IN:WHERE 字段 IN 范围;
查找出对应字段的值在所指定范围的记录。例如:
WHERE AGE IN (18,19,20),这是一个很有用的语句,可以查询、修改、删除多条符合条件的记录。 -
NOT IN:WHERE 字段 IN 范围;
查找出对应字段的值不在所指定范围的记录。例如:
WHERE AGE NOT IN (18,19,20)
IN操作符的语法如下:
SELECT column_name(s)
FROM table_name
WHERE column_name IN (value1, value2, ...);
其中,column_name是要匹配的列名,table_name是要查询的表名,value1、value2等是要匹配的值。
IN操作符可以应用于多种情况,以下是一些常见的用法:
单列匹配
单列匹配:可以使用IN操作符匹配一个列中的多个值。例如,我们有一个表格students,其中有一个列名为grade,我们想要查询所有年级为10、11和12的学生,可以使用以下查询:
SELECT *
FROM students
WHERE grade IN (10, 11, 12);
这将返回所有年级为10、11和12的学生的记录。
多列匹配
多列匹配:IN操作符也可以用于匹配多个列的值。例如,我们有一个表格students,其中有两列分别为grade和gender,我们想要查询所有年级为10和11的女生,可以使用以下查询:
SELECT *
FROM students
WHERE (grade, gender) IN ((10, female), (11, female));
这将返回所有年级为10和11的女生的记录。
子查询
子查询:IN操作符也可以与子查询一起使用。子查询是一个嵌套在主查询中的查询语句。例如,我们有一个表格students和一个表格courses,我们想要查询所有选修了数学课程的学生,可以使用以下查询:
SELECT *
FROM students
WHERE student_id IN (
SELECT student_id FROM courses WHERE course_name = 'Math'
);
这将返回所有选修了数学课程的学生的记录。
使用多个列进行匹配:
SELECT *
FROM 表名
WHERE (列名1, 列名2) IN (
SELECT 列名1, 列名2 FROM 表名 WHERE 条件
)
BETWEEN X AND Y
BETWEEN X AND Y:WHERE 字段 BETWEEN X AND Y;
查找出对应字段的值在闭区间[X, Y]范围的记录。例如:
WHERE AGE BETWEEN 18 and 20。
条件复合:
-
OR:WHERE 条件1 OR 条件2…;
查找出符合条件1或符合条件2的记录。 -
AND:WHERE 条件1 AND 条件2…;
查找出符合条件1并且符合条件2的记录。 -
NOT:WHERE NOT 条件1;
查找出不符合条件的所有记录。 -
&&的功能与AND相同;
||与OR功能类似;
!与NOT功能类似。
注意:WHERE是从磁盘中获取数据的时候就进行筛选的,所以某些在内存是才有的东西WHERE无法使用。字段别名什么的是本来不是“磁盘中的数据”(是在内存这中运行时才定义的),所以WHERE无法使用,一般都依靠HAVING来筛选。
理解:WHERE是第一道筛选(在磁盘中),然后从磁盘中加载到内存中,HAVING是第二道筛选(在内存中)。
SELECT name AS n ,gender FROM student WHERE name ="lihua";
-- SELECT name AS n ,gender FROM student WHERE n ="lihua"; 报错
SELECT name AS n ,gender FROM student HAVING n ="lihua";
优化你的like语句
日常开发中,如果用到模糊关键字查询,很容易想到like,但是like很可能让你的索引失效。
反例:
select userId,name from user where userId like '%123';
正例:
select userId,name from user where userId like '123%';
理由:
- 把
%放前面,并不走索引 - 把
%放关键字后面,还是会走索引的
用于筛选的常用函数
筛选Date类型的时间,CREATE_TIME为Date类型
to_char(CREATE_TIME, 'yyyy-MM-dd') = '2024-06-17'
CREATE_TIME >= to_date('2024-06-17', 'yyyy-MM-dd')
GROUP BY子句
GROUP BY子句:可以将查询结果依据指定字段来将结果分组,指定字段的值均相同,则分为一组。(主要配合统计函数来进行分组统计)
理解:****将一个表分为多个组(子表),再对每个组(子表)使用统计函数,得出结果。例子:按姓名分组,即 相同姓名的分为一组,
COUNT(name)计算出每个组的名字字段数据数。
“Group By”从字面意义上理解就是根据“By”指定的规则对数据进行分组,所谓的分组就是将一个“数据集”划分成若干个“小区域”,然后针对若干个“小区域”进行数据处理。
- 语法:
SELECT 字段列表(统计函数) FROM 表名 GROUP BY 字段...;
注意:字段可以有多个,有多个字段时则是多个字段均相同才会分到一组。
SELECT name,gender,count(name) AS "组员" FROM student AS "学生" GROUP BY name; --按名字分组,查询出每个分组的名字数
SELECT name,gender,count(name) AS "组员" FROM student AS "学生" GROUP BY name,gender; --按名字和性别分组,查询出每个分组的名字数
注意:上面的
COUNT(name)就是我们的统计函数,统计函数是必要的,否则我们的分组将毫无意义,不使用统计函数分组的作用还是有的,只不过变为了去重。
实际上,GROUP BY的作用主要是统计(使用情景很多,比如说统计某人的总分数,学生中女性的数量。。),所以一般会配合一些统计函数来使用:
COUNT(X):统计每组的记录数,X是*时,代表记录数;为字段名时,代表统计字段数据数(除去NULL)MAX(X):统计最大值,X是字段名MIN(X):统计最小值,X是字段名AVG(X):统计平均值,X是字段名SUM(X):统计总和,X是字段名
注意:
GROUP BY子句后面还可以跟上ASC或DESC,代表分组后是否根据字段排序。
实例
按名字分组,我们可以发现有三个叫王五的。
SELECT s_name,class,count(s_name) AS 组员 FROM student AS 学生 GROUP BY s_name

按名字和班级分组,我们可以发现C班有一个王五,E班也有一个,F班也有一个。
SELECT s_name,class,count(s_name) AS 组员 FROM student AS 学生 GROUP BY s_name, class

HAVING子句
HAVING子句:功能与WHERE类似,不过HAVING的条件判断发生在数据在内存中时,所以可以使用在内存中才发生的数据,如“分组”,“字段别名”等。(操作符之类的可以参考WHERE的,增加的只是一些“内存”中的筛选条件)
- 语法:
SELECT 字段列表 FROM 表名 HAVING 条件;【操作符之类的可以参考WHERE的,增加的只是一些“内存”中的筛选条件】
SELECT name AS n ,gender FROM student HAVING n ="lihua";
SELECT name,gender,COUNT(*) AS "组员" FROM student AS d GROUP BY name,gender HAVING COUNT(*) >2 ;--这里只显示记录数>2的分组
查找重复记录
SELECT s_name,class,count(s_name) AS 组员 FROM student AS 学生 GROUP BY s_name
HAVING COUNT(1) > 1
ORDER BY子句
ORDER BY子句:可以使查询结果按照某个字段来排序。
- ASC:代表排序是递增的(默认)
- DESC:代表是递减的
注意:也可以指定某个字段的排序方法。
比如第一个字段递增,第二个递减。只需要在每个字段后面加ASC或DESC即可(虽然默认不加是递增,但还是加上更清晰明确)。
- 语法:
SELECT 字段列表 FROM 表名 ORDER BY 字段 [ASC|DESC];
注意:字段可以有多个,从左到右,后面的排序基于前面的,(比如:先按NAME排序,再按GENDER排序,后面的GENDER排序是当前面NAME相同时再进行二次排序)
SELECT * FROM student ORDER BY name;
SELECT * FROM student ORDER BY name,gender;
SELECT * FROM student ORDER BY name ASC,gender DESC;
如果您的 MySQL 数据库中的字符串只包含数字并且您想按数字顺序对它们进行排序,可以使用 MySQL 内置的 CAST() 函数将字符串转换为数字,然后对数字进行排序。
例如:
假设您有一个名为 mytable 的表,其中包含一个名为 mycolumn 的列,该列包含字符串数字,您可以使用以下查询对它们进行排序:
SELECT mycolumn FROM mytable ORDER BY CAST(mycolumn AS UNSIGNED) ASC;
这将按升序顺序返回 mytable 中的所有行,并将 mycolumn 中的字符串数字转换为无符号整数进行排序。
如果您想按降序顺序对它们进行排序,可以将 ASC 替换为 DESC。
请注意,如果 mycolumn 中包含非数字字符,则 CAST() 函数将返回 0。
因此,如果您的列中包含其他字符,则可能需要使用其他方法来排序。
自定义排序
在 SQL 中,可以使用 ORDER BY 子句结合 CASE 表达式来按照某个字段是否拥有特定前缀进行排序,从而实现拥有特定前缀的记录置顶的效果。
基本思路:使用 CASE 表达式对字段进行判断,如果字段包含指定前缀,则返回一个较小的值(如 0),否则返回一个较大的值(如 1)。然后在 ORDER BY 子句中按照这个返回值进行升序排序,这样包含指定前缀的记录就会出现在前面。
实例:假设我们有一个名为 products 的表,其中有一个 product_name 字段,我们想要将包含前缀 “hot_” 的记录置顶。
SELECT *
FROM products
ORDER BY
CASE
WHEN product_name LIKE 'hot_%' THEN 0
ELSE 1
END,
create_time DESC;
CASE 表达式检查 product_name 是否以 “hot_” 开头。如果是,返回 0;否则返回 1。
在 ORDER BY 子句中,首先按照 CASE 表达式返回的值进行排序,这样返回 0 的记录(即包含 “hot_” 前缀的记录)会排在返回 1 的记录前面。
然后在包含前缀的记录和不包含前缀的记录各自内部,还可以按照其他字段(这里是 create_time)进行排序,以确保它们的顺序是确定的。
这种方法可以根据需要灵活地调整排序的优先级和顺序。你可以根据实际情况修改 CASE 表达式中的判断条件和返回值,以实现不同字段前缀的置顶效果。
LIMIT子句
LIMIT子句:是用来限制结果数量的。
与WHERE、HAVING等配合使用时,可以限制匹配出的结果。
但凡是涉及数量的时候都可以使用LIMIT(这里只是强调LIMIT的作用,不要过度理解)
理解:由于数据的存储使用的B+树(可以类比链表),数据是一条一条找出来的,所以limit就能很好的限制数据的查找数量,提升速度。
- 语法:
SELECT 字段列表 FROM 表名 LIMIT [OFFSET,] COUNT; OFFSET:是偏移量(常数),OFFSET默认从0开始,可以说是每条记录的索引号COUNT:是数量(常数)
SELECT * FROM student LIMIT 2;
SELECT * FROM student LIMIT 3,2;
SELECT * FROM student WHERE name ="lihua" limit 2; --取前2个记录行
SELECT * FROM student WHERE name ="lihua" limit 3,2; --从第3条开始,取2条
一般我们实际的数据库都会很大,所以都取最后几条新的记录看看:
SELECT * FROM student ORDER BY id DESC LIMTI 10;
加上
limit 1后,只要找到了对应的一条记录,就不会继续向下扫描了,效率将会大大提高。
当然,如果name是唯一索引的话,是不必要加上limit 1了,因为limit的存在主要就是为了防止全表扫描,从而提高性能,如果一个语句本身可以预知不用全表扫描,有没有limit ,性能的差别并不大。
查找数据是否存在
根据某一条件从数据库表中查询 『有』与『没有』,只有两种状态,那为什么在写SQL的时候,还要SELECT count(*) 呢?
无论是刚入道的程序员新星,还是精湛沙场多年的程序员老白,都是一如既往的count
#### SQL写法:
SELECT count(*) FROM table WHERE a = 1 AND b = 2
#### Java写法:
int nums = xxDao.countXxxxByXxx(params);
if ( nums > 0 ) {
//当存在时,执行这里的代码
} else {
//当不存在时,执行这里的代码
}
推荐写法如下:
#### SQL写法:
SELECT 1 FROM table WHERE a = 1 AND b = 2 LIMIT 1
SELECT 1 FROM table WHERE a = 1 AND b = 2 AND ROWNUM = 1
#### Java写法:
Integer exist = xxDao.existXxxxByXxx(params);
if ( exist != NULL ) {
//当存在时,执行这里的代码
} else {
//当不存在时,执行这里的代码
}
SQL不再使用count,而是改用LIMIT 1,让数据库查询时遇到一条就返回,不要再继续查找还有多少条了
业务代码中直接判断是否非空即可。
根据查询条件查出来的条数越多,性能提升的越明显,在某些情况下,还可以减少联合索引的创建。
如果知道查询结果只有一条或者只要最大/最小一条记录,建议用limit 1
假设现在有employee员工表,要找出一个名字叫jay的人。
CREATE TABLE `employee` (
`id` int(11) NOT NULL,
`name` varchar(255) DEFAULT NULL,
`age` int(11) DEFAULT NULL,
`date` datetime DEFAULT NULL,
`sex` int(1) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
反例:
-- 100万条数据耗时0.56s
select id,name from employee where name='jay'
正例:
-- 耗时0.00s
select id,name from employee where name='jay' limit 1;
理由:
- 加上limit 1后,只要找到了对应的一条记录,就不会继续向下扫描了,效率将会大大提高。
- 当然,如果name是唯一索引的话,是不必要加上
limit 1了,因为limit的存在主要就是为了防止全表扫描,从而提高性能,如果一个语句本身可以预知不用全表扫描,有没有limit,性能的差别并不大。
配合EXISTS运算符使用:
EXISTS运算符用于指定子查询以测试行的存在。 以下是EXISTS运算符的语法:
[NOT] EXISTS (subquery)
如果子查询包含任何行,则EXISTS运算符返回true。 否则它返回false。
EXISTS运算符在找到行后立即终止查询处理,因此,可以利用EXISTS运算符的此功能来提高查询性能。
SELECT
employee_id, first_name, last_name
FROM
employees
WHERE
EXISTS (
SELECT
1
FROM
dependents
WHERE
dependents.employee_id = employees.employee_id
);
游标查询(优化limit分页)
我们日常做分页需求时,一般会用 limit 实现,但是当偏移量特别大的时候,查询效率就变得低下。
反例:
select id,name,age from employee limit 10000,10
正例:
//方案一 :返回上次查询的最大记录(偏移量)
select id,name from employee where id>10000 limit 10.
//方案二:order by + 索引
select id,name from employee order by id limit 10000,10
//方案三:在业务允许的情况下限制页数:
理由:
- 当偏移量最大的时候,查询效率就会越低,因为Mysql并非是跳过偏移量直接去取后面的数据,而是先把偏移量+要取的条数,然后再把前面偏移量这一段的数据抛弃掉再返回的。
- 如果使用优化方案一,返回上次最大查询记录(偏移量),这样可以跳过偏移量,效率提升不少。
- 方案二使用order by+索引,也是可以提高查询效率的。
- 方案三的话,建议跟业务讨论,有没有必要查这么后的分页啦。因为绝大多数用户都不会往后翻太多页。
传统分页的问题
在传统分页中,数据通常是 基于页码或偏移量 进行加载的。如果数据在分页过程发生了变化,比如插入新数据、删除老数据,用户看到的分页数据可能会出现不一致,导致用户错过或重复某些数据。
举个例子,对于即时通讯项目,用户可能会持续收到新的消息。如果按照传统分页基于偏移量加载,第一页已经加载了第 1 - 5 行的数据,本来要查询的第二页数据是第 6 - 10 行(对应的 SQL 语句为 limit 5, 5),数据库记录如下:
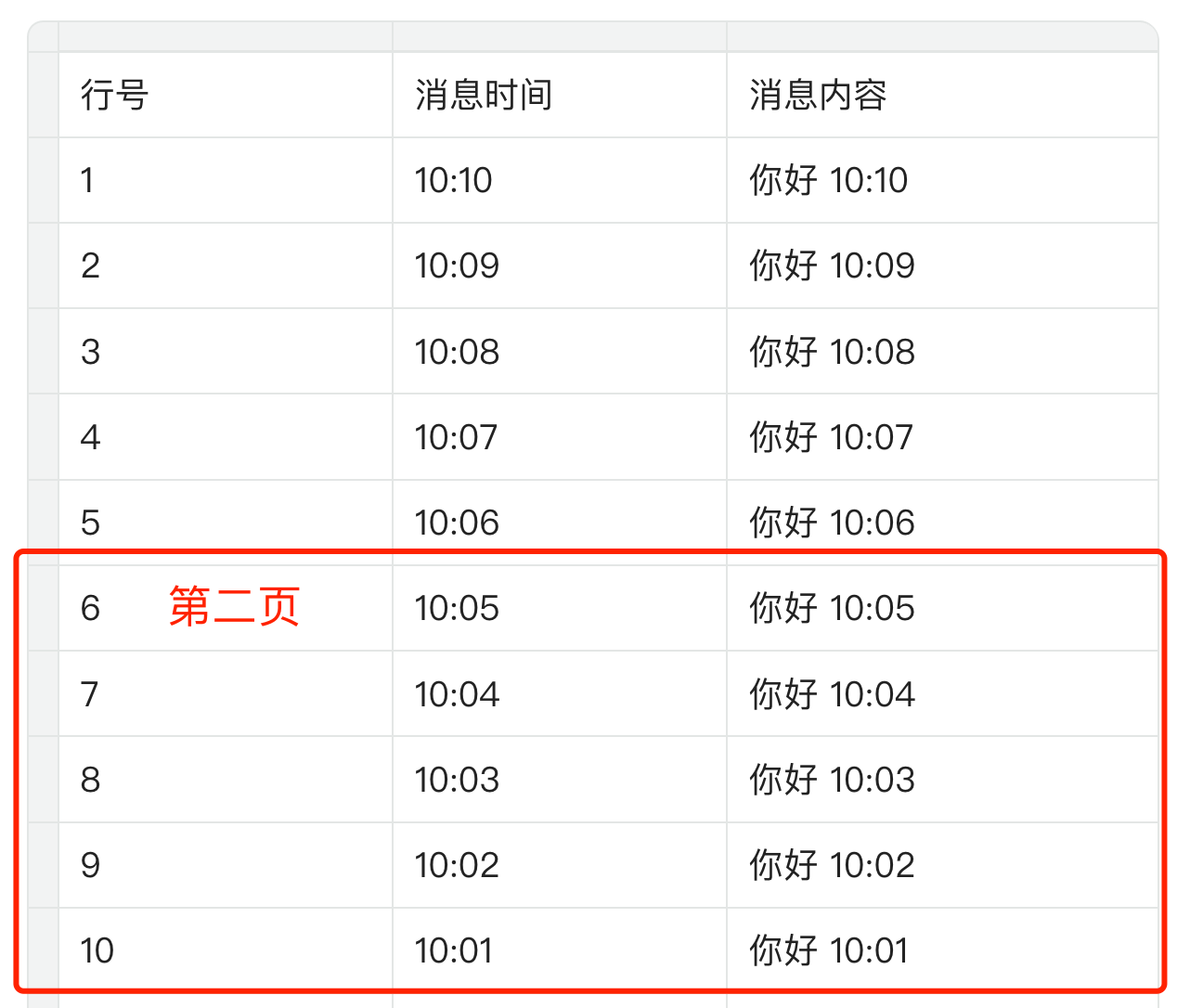
结果在查询第二页前,突然用户又收到了 5 条新消息,数据库记录就变成了下面这样。原本的第一页,变成了当前的第二页!
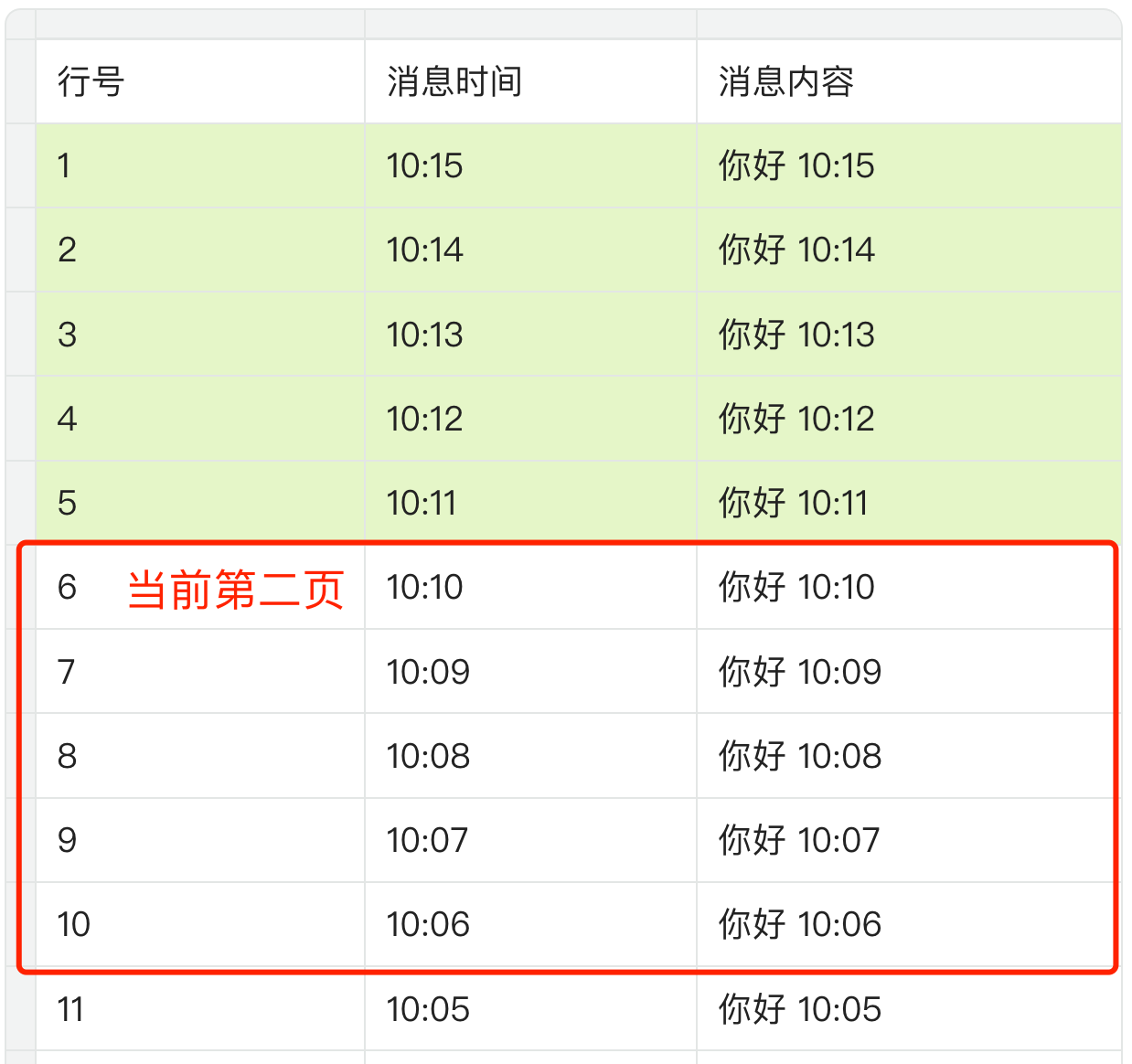
这样就导致查询出的第二页数据,正好是之前已经查询出的第一页的数据,造成了消息重复加载。所以不建议采用这种方法。
游标查询
游标查询:按ID升序,每次只处理一批数据,这一批数据只有100条记录,每次处理完成之后,保存这100条数据中的最大ID和时间,给处理下一批数据的时候用。
id的初始状态可以设置为0,然后慢慢根据查出来的数据id递增
注意:这个id得记住持久化,不然重启服务就没了
SELECT
*
FROM
user
WHERE
id > #{lastId}
-- AND create_time >= #{lastCreateTime}
ORDER BY
id DESC
-- , create_time DESC
LIMIT 100;
注意:雪花算法生成的ID是有序的,如 MybatisPlus的
IdWorker.getIdStr()
笔者将不定期更新【考研或就业】的专业相关知识以及自身理解,希望大家能【关注】我。
如果觉得对您有用,请点击左下角的【点赞】按钮,给我一些鼓励,谢谢!
如果有更好的理解或建议,请在【评论】中写出,我会及时修改,谢谢啦!
本文来自博客园,作者:Nemo&
转载请注明原文链接:https://www.cnblogs.com/blknemo/p/10030855.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号