IP协议的发展历程
1. IP协议
1.1为什么需要IP协议
- 好像ip地址就像每个人的家门号一样家喻户晓,被大家默认用来作为寻址的门牌号,起初,设计IP地址也是为了寻找某台主机,但是作为世界上家喻户晓的IPv4,大家不应该感到疑惑,MAC地址(又被称为物理地址)为什么不可以去表示一个主机?毕竟Mac地址可是唯一的一个地址,用他来寻址为什么不可以,如果能明白为什么不用MAC地址去寻找网络中的主机,而是通过IP地址去寻找,就会清楚的明白IP地址的定位。
我们先来看看Mac地址的地址格式

理清Mac地址的具体模样,就可以思考一下IP的存在了.我们应该站在设计者的角度去衡量如果用Mac地址去寻找网络中的主机是否可靠,给出以下场景:
A小区:有几千家用户
B小区:有几百家用户
C小区:用几万家用户
如果我做为一名邮寄员,我需要传输一份邮件,这个邮件上记录着只有Mac地址(现在被用来当作地址)的标识,我需要投递给一家快递站,让快递站告诉我应该寄给哪个小区,于是快递站的服务人员手忙加乱地翻开了记事本,查一查这个地址的所在地,但是翻了翻记事本,发现有着成万的数据记录在上面,于是服务人员开摆了,说你找去吧,就这样,你碌碌无为的工作到夜晚,感到身心俱疲.
当然,计算机处理着即使成万的数据也是非常快的,但现实中,网络中的用户并不是以万的单位出现的,而这个快递站也就是我们所谓的交换机,交换机工作在数据链路层,这也就是自底向上的一种建立服务的设计思想,如果有数十亿的项存在我们的交换机,意味着每个交换机如同一个笨重的仓库放在我们的面前,他也就失去了快递站的职能,所以用Mac地址去寻找网络中的主机是十分不明智的,所以便会有了IP地址,那IP地址就解决办法了吗?
2. IP地址的分类
2.1 有分类的IP地址
首先熟悉IPv4地址的分类:A,B,C,D,E类地址,
划分地址的方法是什么?
根据网络号和主机号不同进行划分
在这里先给出A,B,C三类地址的划分范围,就能够明白很多
| 类别 | IP地址范围 | 最大主机数 |
|---|---|---|
| A | 0.0.0.0 ~ 127.255.255.255 | 1677724 |
| B | 128.0.0.0 ~ 191.255.255.255 | 65534 |
| C | 192.0.0.0 ~ 223.255.255.255 | 254 |
A类:8位网络号,24位主机号
B类:16位网络和,16位主机号
C类:24位网络和,8位主机号
A类地址网络号的高第1位为0,B类地址网络号的高前两位为10,C类地址的网络号前高三位为110,至于为什么这么定义,其实很好想,如果明白指令集如何划分,其实地址的划分也类似于此,就比如如果B类地址的前两位如果是01就无法和A类地址的前1位0区分,更准确来说,B类地址直接被涵括在了A类地址里,其实这种划分地址的思想,在划分我们的子网长度时也有用到
接下来就是明白主机的数是如何确定下来的了:
先来看C类地址,也就是拥有最短位数主机位,很容易的辨别出来28 表示8位可表示的数据个数,等于256,减去2就是254.
一定有人明白其中的两个地址就是网络地址和广播地址,事实如此,在A类,B类也是如此,可是网络地址和广播地址用来干什么的,每一类都专门分一个出去?好大的面子
我们先来了解一下网络地址和广播地址,主机号全为0则为网络地址,主机号全为1则为广播地址
就没人疑惑网络号和主机号是干嘛的吗?
- 网络号是用来标识网络,那主机号就是用来标识网络中的某个主机的,那主机号全为0的地址则表示不用来区分某个特定的主机,可以用来表示这个网络的网络地址,类似来表示这个网络这片区域。
- 广播地址顾名思义就是进行广播通知的地址,用来告知这一片区域的所有主机(我们的路由器一般不会直接发送广播地址,那设计广播地址的意义是什么?)
- 网络中并不仅仅存在1对1的网络通信,同时也存在一对多的通信,例如:像现在的路由器和我们的移动设备之间,常常能看到大部分人的私有ip地址都是192.168.1开头的。经过我们细心的发现这其实是DHCP服务器分配给我们的一个ip地址,而我们的移动设备如何去获取DHCP服务器的IP地址则是进行的广播通信,这时候就需要通过UDP广播通信,可见广播的真实价值不可估量,当然,广播通信同样存在着很多问题。
2.12 D类地址和E类地址
D,E类地址仅做了解即可,他们并没有网络和主机的区分,目前用来做多播地址使用

来了解一下什么是多播?
多播<广播,在同一片区域内,多播的通信对象一般来说是小于广播的,毕竟广播的通信对象一般是确定好了,有多少个主机就有多少个通信对象,而多播则是用来发给组内特定的主机.例如:现在要通知小区的某一栋楼的所有用户,而不是通知一个小区的所有用户,当然多播也不仅限于一个区域,也就是一个子网下通信,由于路由器一般不进行广播通信,所以也有着相应的多播路由器去做多播工作.
2.2 无分类的IP地址
接下来我们先用哈夫曼树去看一下有分类的IP地址:
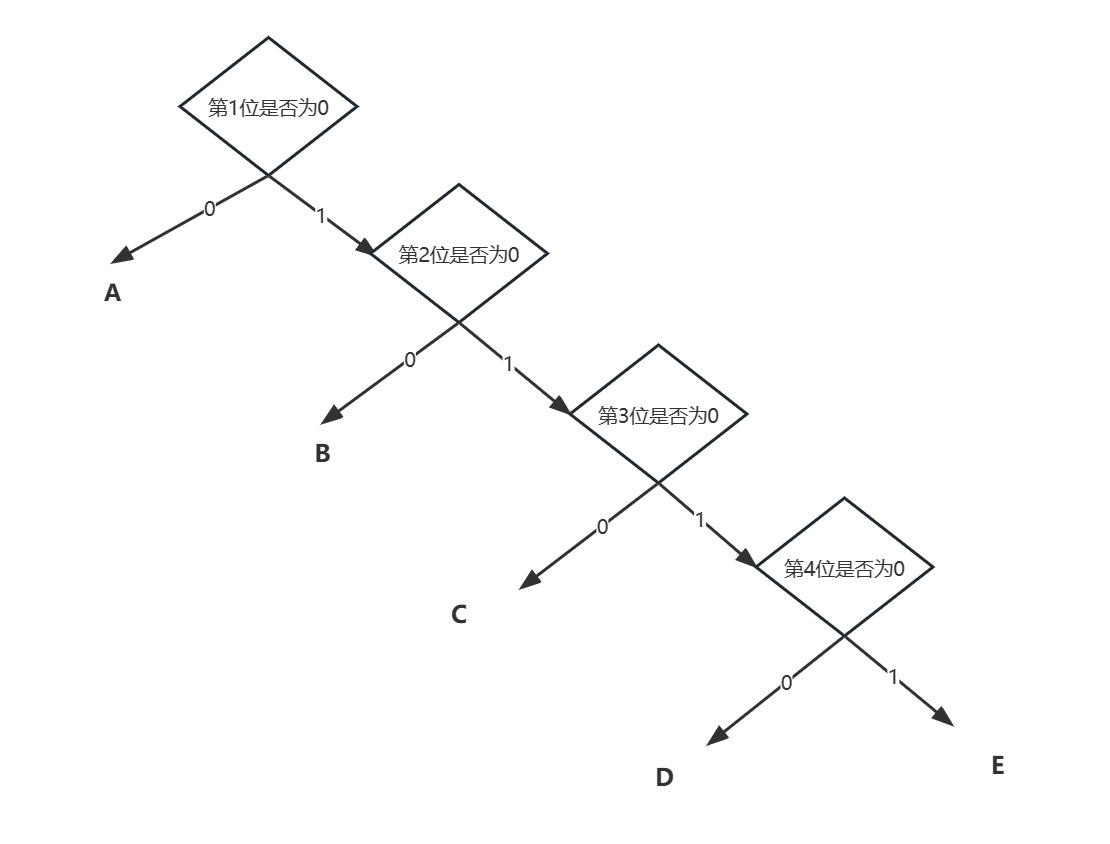
显而易见的就是地址浪费,毕竟固定下来的东西,如果不能做到高效率的利用,就存在浪费,从A,B,C三类地址的可分配主机数便可看出,这并不均衡,实际的网络主机号通常都是按需分配,同时,分类的IP地址会导致路由表的增长.因此无分类的地址便为了解决而提出(现在网络通信一般都不采用A,B,C分类的IP地址进行通信,而是通过无分类地址和路由聚合来进行通信)
既然不定长的划分网络号和主机号,那该如何表示呢?
表现形式:a.b.c.d/x,其实在子网的划分,很多人觉得都很常见,/x表示前x位标识网络号,x取值范围是0~32
例如:12.13.5.2/24,则前24位表示网络号,后8位表示主机号
3.子网的划分
3.1为什么要划分子网
如果目标IP和源IP属于同一个子网,那么就将数据包交付给交换机
如果目标IP和源IP不属于同一个子网,那么就将数据包交付给路由器
可见,子网的划分跟路由器有很大的关系,毕竟就如同小区一般,每个小区也就类似一个子网,可以更好的管理,同时,创立子网,也就尽量隔离了广播域
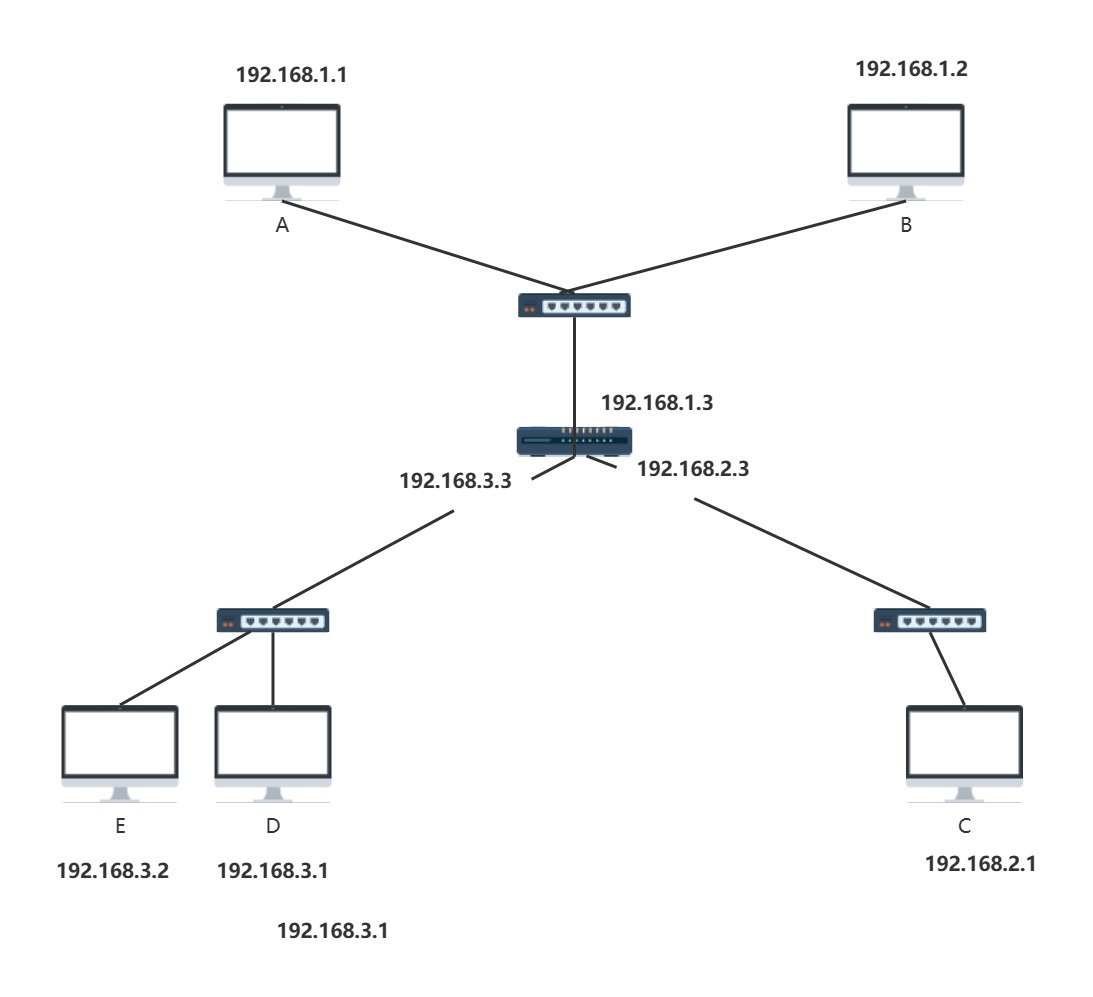
这里我们先不用管MAC地址,先来简单的观看一下子网的划分
A,B一家,E,D一家,C一家
到这里,估计会有人提出质疑,分配的也太规整了,为什么交换下的两台主机就一定是一个子网的?
其实,这很好解释,IP地址不是你自己分配的,而是DHCP服务器替你分配好的,加上现在路由器其实已经集成了交换机,你移动设备的IP地址基本是你伸手饭来得到的,自然是一个子网下的.
3.2子网如何划分
- 子网划分借用了主机号的部分
做了子网划分后的地址:

为此我们来试着去划分子网,拿192.168.1.X来举例,前3个字段为网络号,后1个字段为主机号,接下来我们从主机号中抽出两位用来划分子网的数量
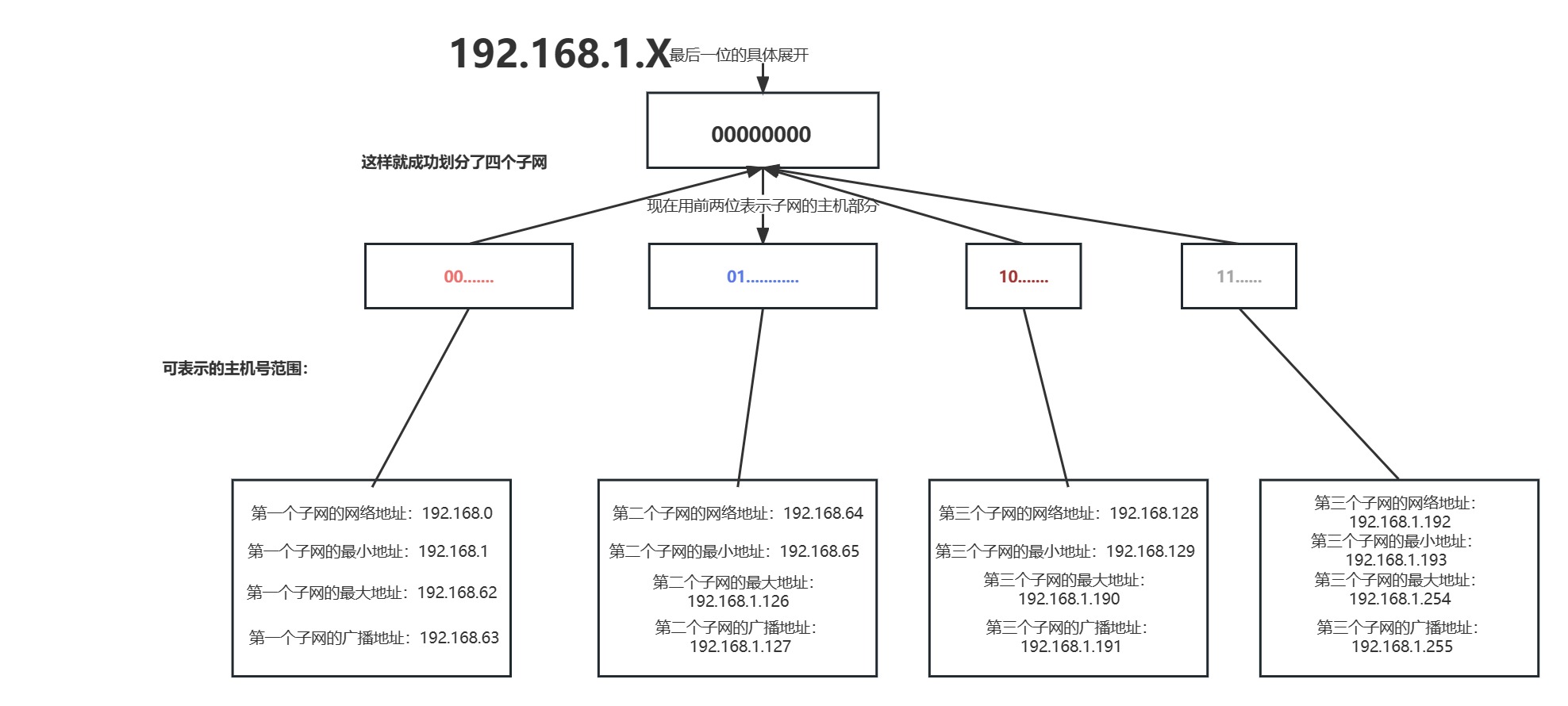
于是被划分成了四个子网:
子网1:192.168.1.0/26,其中X的取值范围是0-63。
子网2:192.168.1.64/26,其中X的取值范围是64-127。
子网3:192.168.1.128/26,其中X的取值范围是128-191。
子网4:192.168.1.192/26,其中X的取值范围是192-255。
就这样每个小区的每家每户都有了一个对应的具体地址,被划分成了四个地址,于是我们依然要面对一个问题,如何判断是同一个小区,也就是判断是否为同一个子网,这将会影响包的走向
于是引出了一个概念:子网掩码
3.3子网掩码
- 上述划分子网的方式是定长的划分子网,这种自定义划分子网也就意味着需要我们知道子网掩码是多少
在这里给出答案,上面四个子网的子网掩码是192.168.1.192

子网掩码这个名字很有意思,先跟子网号挂钩,掩码就好像遮住了这个子网段,但是通过这个掩码好像就知道是不是这个子网的,不得不说,这种巧妙的设计十分精彩,毕竟谁能想到仅仅是与IP地址与子网掩码运算就能判断在不在这一个子网下
接下来,我们看一下四个子网与子网掩码发生与运算为什么能判断是否在同一个子网下
由于192后6位都是0,与运算的结果依旧是0,只有着前2位子网号进行着与运算,所以我们只看前两位
1.子网1:子网1的子网号00&&子网掩码11得到答案是00,等于子网1的网络地址(因为主机号和后6位0全与结果为0)2.子网2:子网2的滋味号01&&子网掩码11得到答案是01,等于子网2的网络地址
3.子网3:子网2的滋味号10&&子网掩码11得到答案是01,等于子网2的网络地址
4.子网4:子网2的滋味号11&&子网掩码11得到答案是01,等于子网2的网络地址
这样便能够迅速确定是否是同一个子网
3.4不定长的子网划分
- 前面我们已经了解过定长的子网划分已经理解了他的子网掩码,接下来我们理解不定长的子网划分,就如同IP地址一样,我们是划分了网络号和主机号,子网同样也是将子网号长度不固定的去分配,试想一下,每个子网下的主机数是否就一定一样吗?
- 上面的情况或许过于理想,就如同IP地址的定长分配一样,也会造成浪费,毕竟每个子网下的主机可是不确定的,所以才需要不定长的子网划分
-
接下来我们思考一下如果一个子网下所需要的主机(用户数量多),是不是意味着子网号尽可能小,主机号尽可能多,这样的分配貌似才是公平的
-
接下来我们依然讨论192.168.1.X这个可恶的地址,还是如上图一样,只不过子网部分的地址并不是固定的,上述的子网,每个子网拥有62台主机号,那假设子网1需要100台,子网2需要60台,子网3需要30台,子网4需要10台,(这里用最后一个字节来不定长划分子网,但是不定长划分子网是为了避免浪费,而不是提升总量,所以最后一位能容纳的主机数依然是(0~255),所以这里分配的主机数并没有超过247(255-2*4),如果超过,需要在前面的主机号依然去借位)接下来,我们来看看如何划分:

具体的用哈夫曼树去表示子网号:
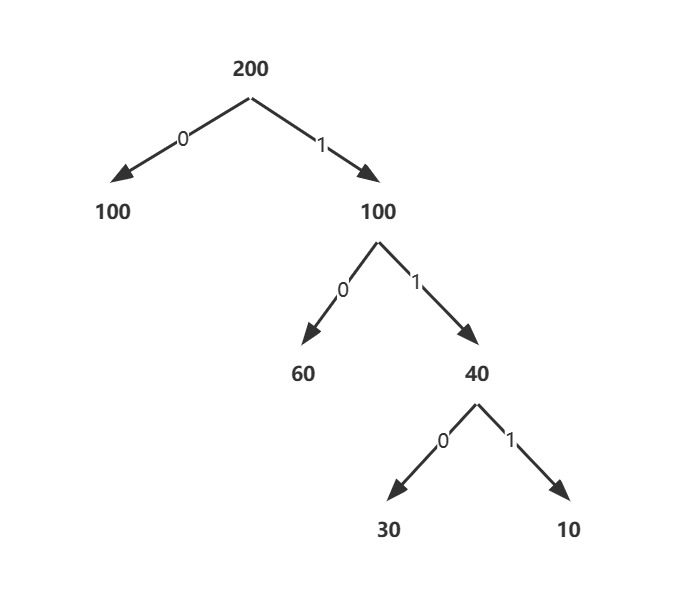
- 如同分类IP一样的分类方式,就可以避免不同子网内因为主机号的缘故出现相同的前缀而被涵括在里面,有可能导致冲突(也如同指令编码一样)
现在我们再来看每个子网的具体网络号和广播号:
子网1:192.168.1.0/25,其中有126个地址(128-2)
子网2:192.168.1.128/26,其中有62个地址
子网3:192.168.1.192/27,其中有30个地址
子网4:192.168.1.224/28,其中有14个地址
这便完成了按需分配,在子网1中就能容纳更多的主机,现代计算机分配子网的方式大部分都采用不定长的子网划分.也称可变长度子网掩码(VLSM)。
在不定长子网划分中,网络管理员可以根据实际需求为每个子网选择适当的子网掩码.
既然如此,我们就来看看这四个子网下的子网掩码:
子网掩码1:255.255.255.128
子网掩码2:255.255.255.192
子网掩码3:255.255.255.224
子网掩码4:255.255.255.240
- 其实可以根据经验规律发现子网掩码一定要有连续的1和0,不能出现类似101,10001,1101这种,所以通常都是单个的1,11,111,1111后面紧跟0,这样才能保住我们与运算出来的网络地址是否有用.
至于这4个子网掩码为什么不同,而上述定长的子网划分的子网掩码又为什么相同,其实很好解释.
上述的子网被均分成了64个IP地址给每个子网,这意味着每个子网的主机数是固定的,想一想子网掩码是与子网有关,而不去关心主机号的,自然而然上述的子网掩码需要高2位为双11,也就是192,而这四个不定长划分的子网掩码,显而易见的可以看出128就是1个1,192就是两个1,224就是三个1,240就是四个1,毕竟如果不是一个子网下的,他们的子网号就不相同,那么和连续的1进行与运算的时候出来的网络地址就不会相同(这也就是利用了和1进行任何与运算要取决与和1进行与运算的值).
3.5什么是缺省性子网掩码
缺省子网掩码顾名思义也就是缺少子网的掩码,比如我们的A,B,C三类地址,就是固定分类的三类地址,在不划分子网的情况下:
A:255.0.0.0
B:255.255.0.0
C:255.255.255.0
4.IP与以太网包的收发操作
4.1什么是包
TCP模块在执行连接,收发,断开操作阶段时,其实是离不开IP模块进行封装成IP数据包交付给通信对象的,包也可以理解为我们的数据对象,其中包含着头部和数据两部分.
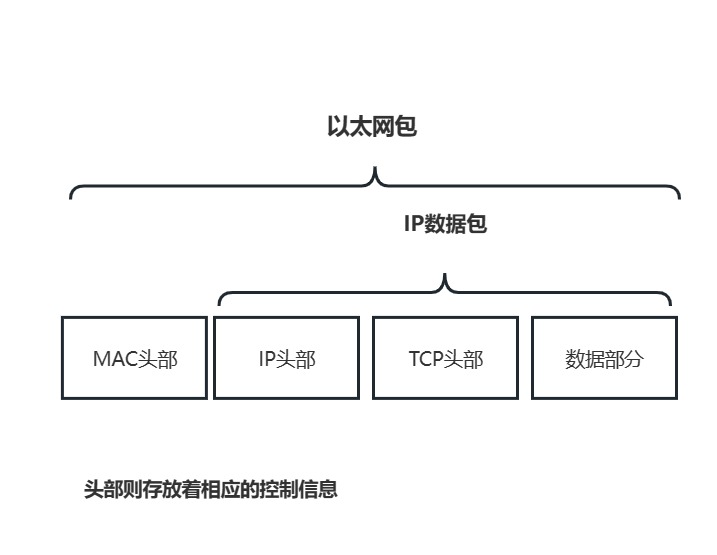
4.2IP模块执行的职能
正如TCP头部在TCP模块被完成创建,IP头部和MAC头部同样也被IP模块创建.
IP头部,包含IP地址,MAC头部,包含MAC地址
- 封装好的网络包会由协议栈交付给网络硬件,通过驱动程序发送到相应的网卡,这时候网卡接收到的网络包是一堆0和1组成的数字信息,网卡会将这些数字信息转换成相应的电信号或者光信号,通过网线或者光纤发送出去,然后这些信号就会被传输到我们的网络节点,也就是交换机,路由器,最后到达目的地,由目的地在返回接受一个包
4.21IP头部
既然IP头部放着IP协议相关的控制信息,他在被IP模块创建时,我们就需要去了解一些
IPv4:
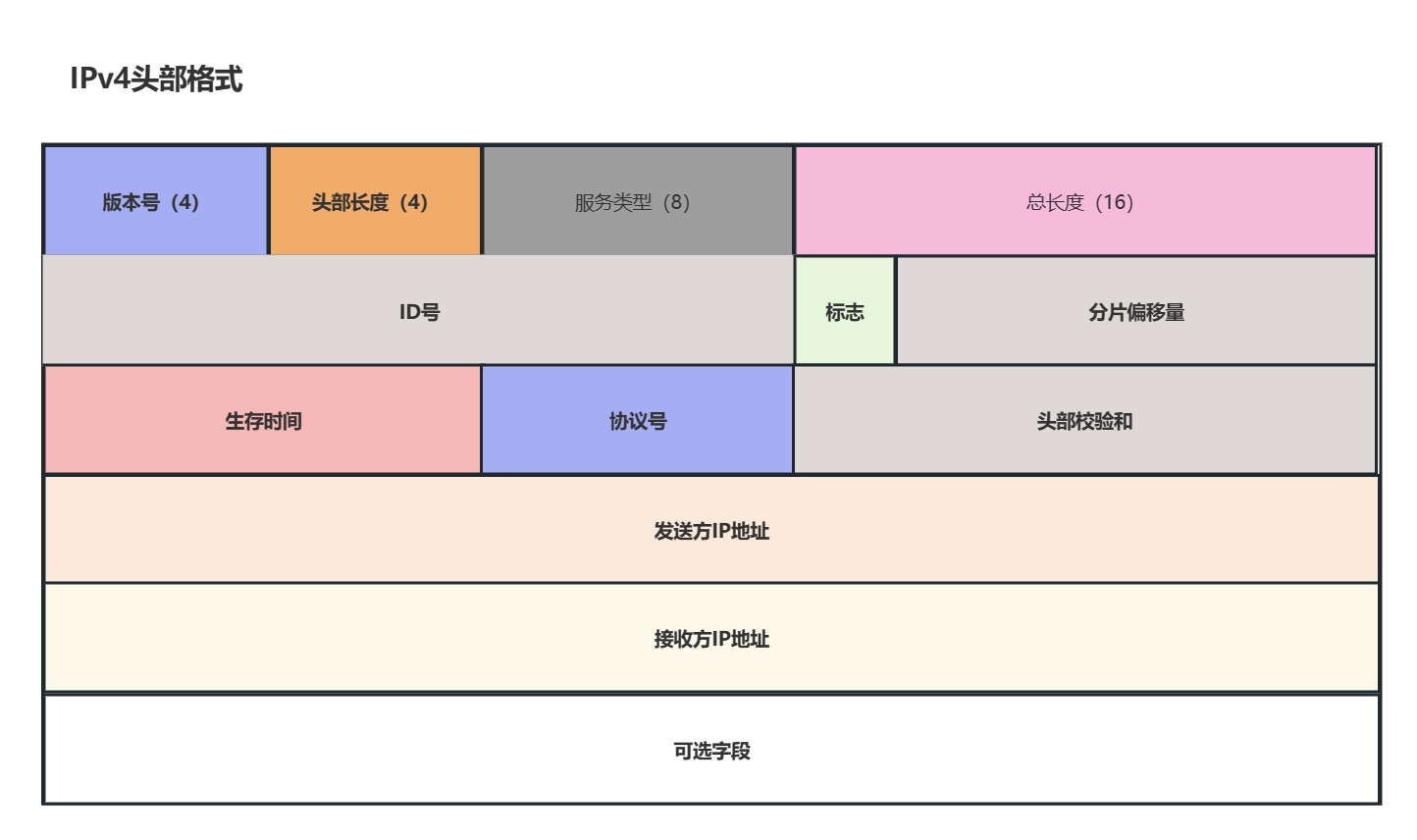
-
我们先来了解一下标志位(3比特):其中2个比特有效,分别表示是否允许分片,以及当前包是否允许分片包
-
至于常见的协议号也在这里列举了:
TCP : 06 UDP : 11 ICMP : 01 -
另外,这里不得不提起头部校验和,随着时代的发展,现在的路由器甚至已经不利用这个字段做什么了,也就是现在其实已经不使用了,比如以太网交换机通过循环冗余校验(CRC),TCP利用校验和字段来验证数据的完整性,某些应用层协议也会去校验数据的完整性,虽然某些教科书上还会写着头部校验和这个字段依然在被使用,但这种说法并不准确.
4.22MAC头部字段
在前面,我们举例过MAC地址的地址格式48比特,当然,那可能是发送方也有可能是接收方的MAC地址,因此MAC头部字段则封装着目的MAC地址和源MAC地址,此外还封装着额外一个字段叫以太网类型(16比特)
- 拿以太网类型字段举例说明
0800:IP协议
0806:ARP协议
86DD:IP6协议
0000-05DC: IEEE 802.3
4.3包在网络中的传输
4.31集线器
- 我们先来想一想两台主机之间的通信和许多台之间的通信有什么区别?
网络的拓扑结构不同,这是最直观的区别.简单的拓扑结构是否意味着简单的通信,复杂的拓扑结构是否意味着更可靠的通信
我们先来看看两台之间的网络架构

- 再来看看许多主机的网络架构
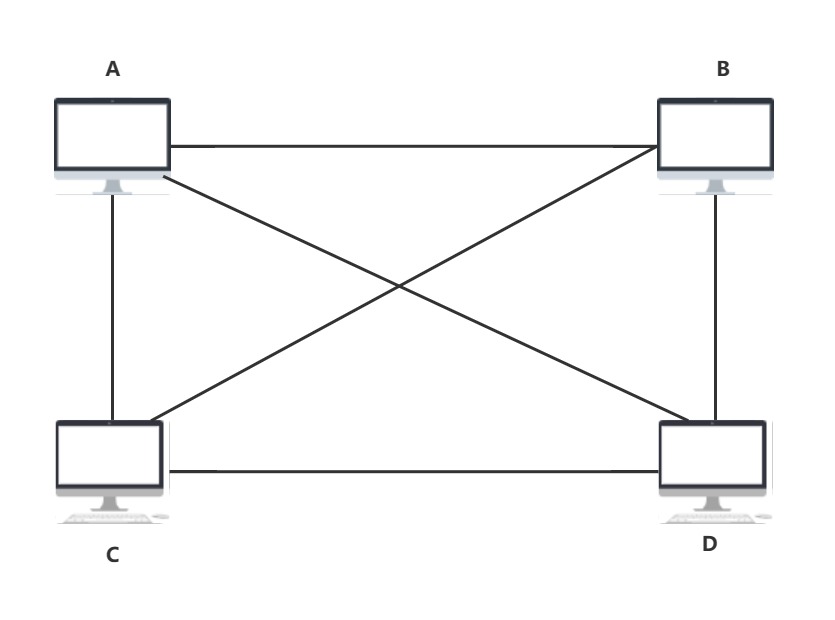
- 可以看到如果仅是网线的拓扑连接,这个连线的数量几乎是指数级别,得出数学公式:连接数 = (n * (n - 1)) / 2.
很多人都能听过交换机,路由器,集线器,但是他们的发明帮助了优化网络拓扑结构,提高网络的可靠性,比如,我在A,B,C,D四台主机中添加集线器
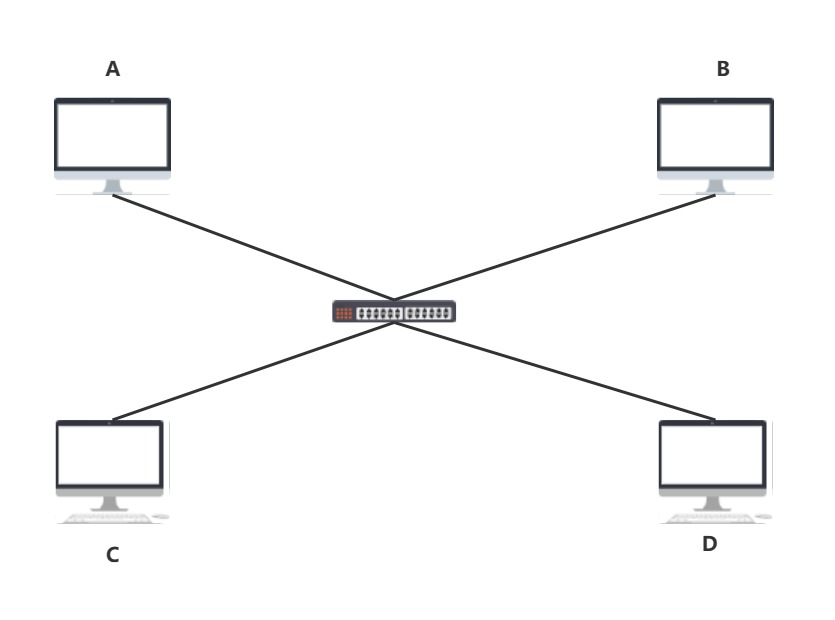
虽然加入了集线器,减少了网线的连接,但是同样存在问题
集线器(中继式集线器):不具备智能路由功能或数据处理能力,它只是简单地将数据包广播给所有连接的设备,这意味着会发生碰撞.这也就意味着在网线上传播信号是半双工传播.所以就会出现以下这种情况:
A->C,就会导致广播为B,C,D,从网络的利用率上来看甚至还不如多连几根线呢
于是就有了进阶版的集线器,交换机(也叫交换式集线器)
4.32交换机
让集线器具备选择的功能,也就引入了MAC地址
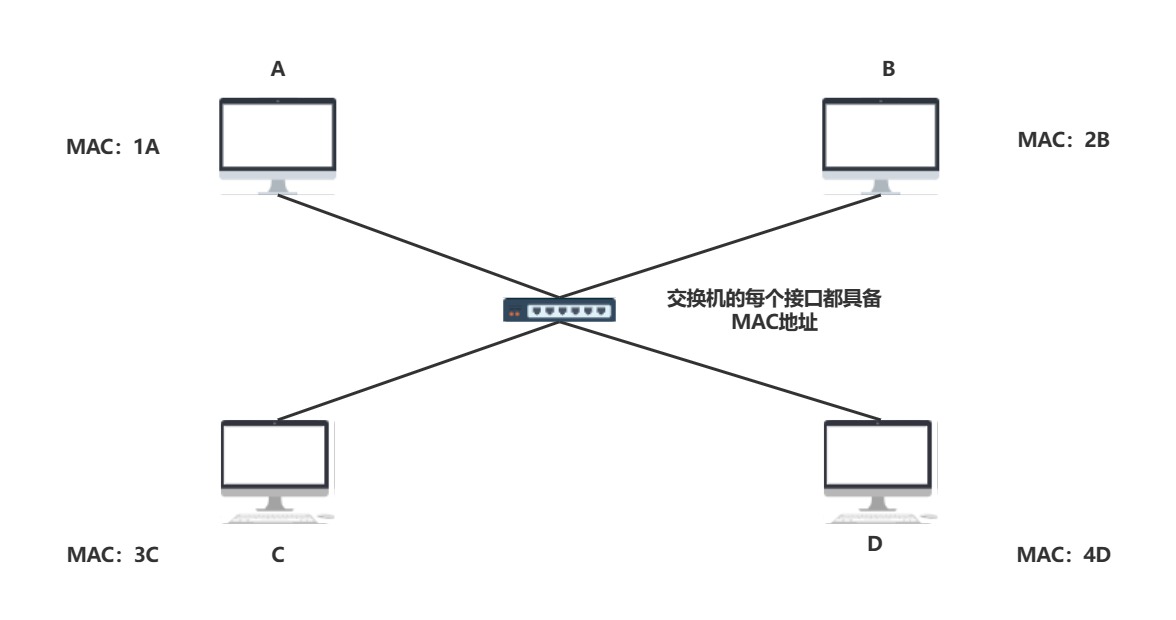
- 这样,每次在A想发送给C数据包的时候就可以在MAC头部添加目的地址和源地址,通过交换机就可以查表找到,而不需要进行广播通知
思考一下,主机A该如何得知目的主机的MAC地址?
答案:广播
我们的MAC地址依然存在广播地址(FF-FF-FF-FF),这时候我们就可以通过交换机发送广播地址发送给每台和交换机相连的主机
继续思考一下,主机C该如何通过广播地址知道是主机A发送给他的,因此他才可以做出回应
答案:IP地址
我们的主机C接收到广播帧后,会根据包中的目的IP地址和自己进行比对,如果比对成功,则返回目的MAC地址为自己MAC地址的响应帧
这个思考过程其实就是ARP(地址解析协议)的大致思想
- 不过如果次次通过广播依旧无法凸显交换机的优势,因此MAC表是交换机用来查找和缓存的存储数据,在没有任何数据通过交换机时,此时,交换机的MAC表内无任何地址,当交换机的MAC交换表被丰富后:
| MAC地址 | 端口 |
|---|---|
| 1A | 1 |
| 2B | 2 |
| 3C | 3 |
| 4D | 4 |
试着思考一下主机A脱离了网络,或者说主机E进入了网络,和端口1,相连,这时候主机C发送数据包给主机A会发生什么?
交换机会删除端口1的MAC地址信息,重新建立,因此交换机存在MAC地址表的维护,只要一段时间没有使用,就可以删除了,这个删除的时间一般是几分钟.
接下来貌似一个成熟的网络结构就形成了,试着再思考一下,从交换机端口收到的数据包还会从交换机收到数据包的端口返回吗?
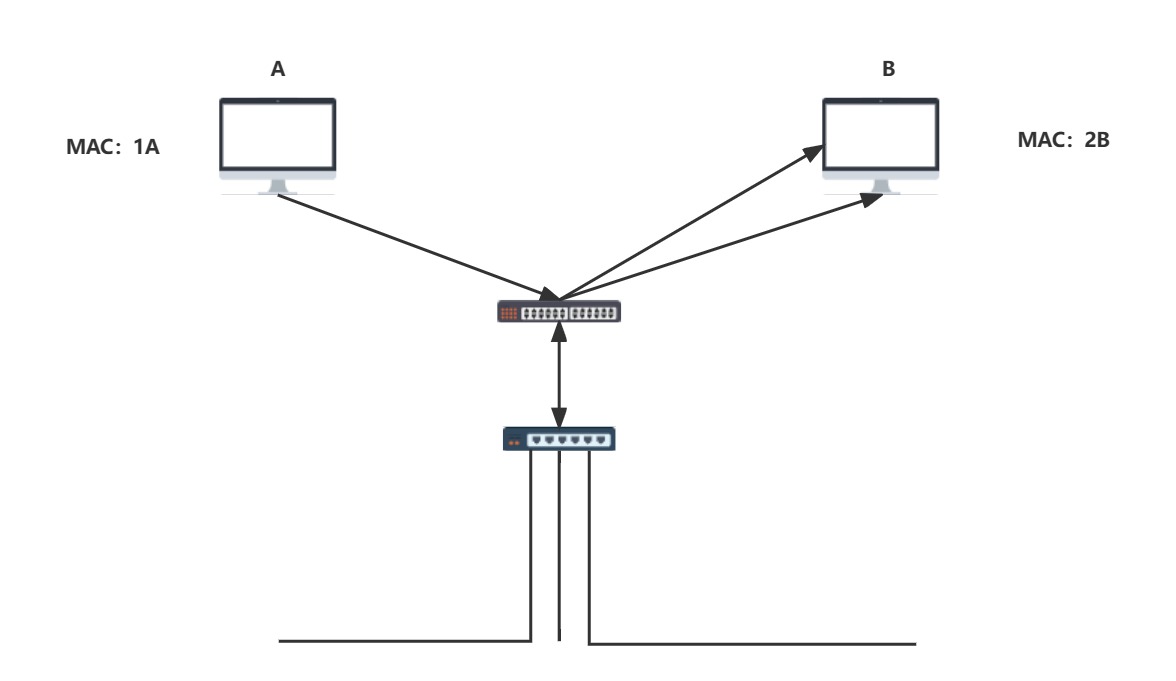
主机A(假设主机A想发送给B)发送给集线器,集线器广播通知了所有网络设备,交换机得知了主机A要寻找主机B,于是转发给集线器,集线器又会将数据包传达给B(也会传给A,没有画出来).这就会导致无法正常通信,因此当交换机发现一个包要返回原端口时,就会之间丢弃此包(集线器工作在物理层,并不具备MAC地址),如果接收方MAC地址是一个广播地址,那么交换机处发送源端口以外的全部端口进行发送
- 因此,在现代以太网通信中,集线器已经被交换机取代,交换机继可以做到广播转发,又可以做到选择性转发帧
- 但是,仅仅凭借着交换机就能够完成网络的拓扑结构和可靠性吗?
上面的交换机貌似仅仅连接了四台网络设备,倘若每一个物理端口都连接一个网络设备,都进行最大数量的连接,那由一个交换机组成的一个网络也仅仅几十或者几百个而已,因此将交换机和交换机互连的方式诞生了
- 交换机与交换机互连会发生什么?
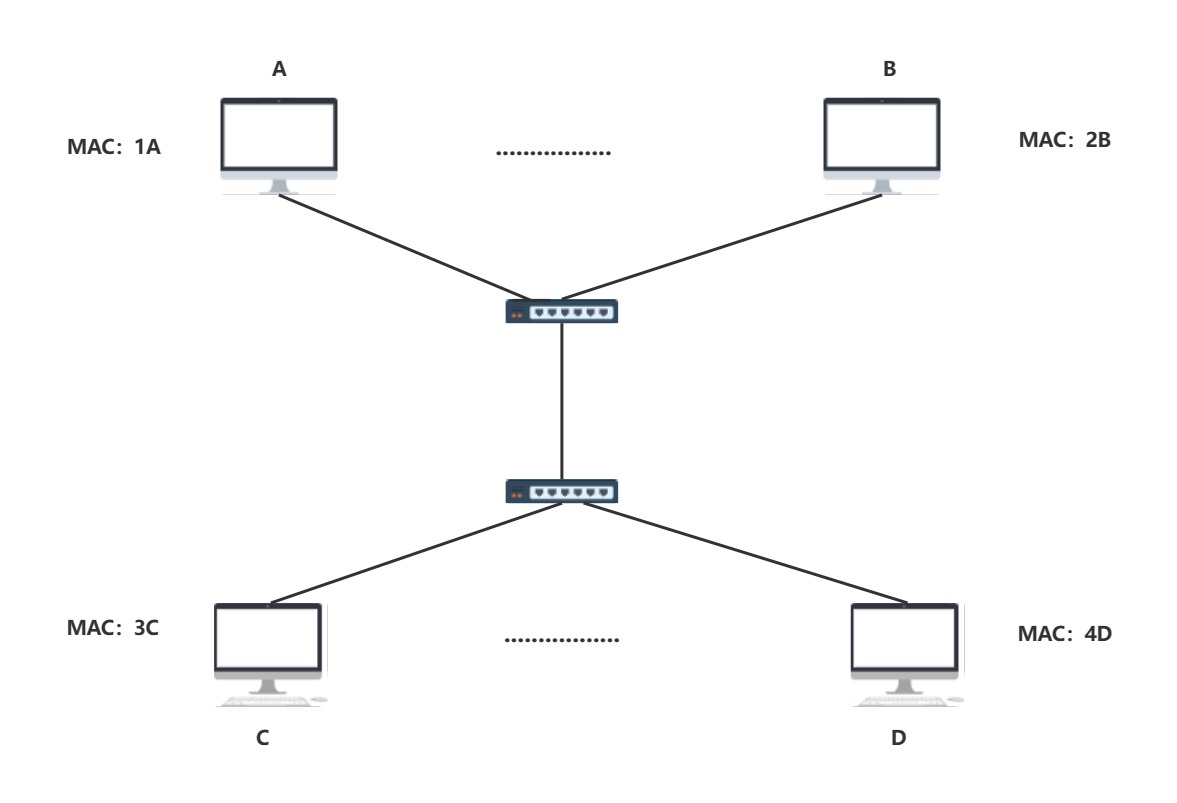
(中间省略点,是因为懒不信画了,有很多台主机假如几十)
那么两台交换机的MAC地址表会记录什么(这里展示与A,B相连的交换机)
| MAC地址 | 端口 |
|---|---|
| 1A | 1 |
| 2B | 2 |
| ....... | ....... |
| 3C | 7 |
| 4D | 7 |
| ........ | 7 |
其实可以观察出另一个交换机下的所有主机在MAC地址表里都是以7(我假设的端口,和另一个交换机相连)端口为映射关系,而表格里的多数主机都被省略了,倘若这个网络的主机数较多,意味着MAC地址与端口的映射关系也会变多,这也仅仅是两个网络下,如果引入更多的网络,将会大大增加交换机地址的映射关系,因此,网络的划分仅靠交换机好像并不能得以实现.
4.34路由器
我们已经明白靠交换机互连的方式已经不能满足真正的网络通信,如果能把和交换机互连的那个端口用一条记录去表示交换机下的所有主机,在通过交换机去寻找就好了!
- 是的,这就是路由器,也就是通过路由器,IP地址才发挥了他的真正才能
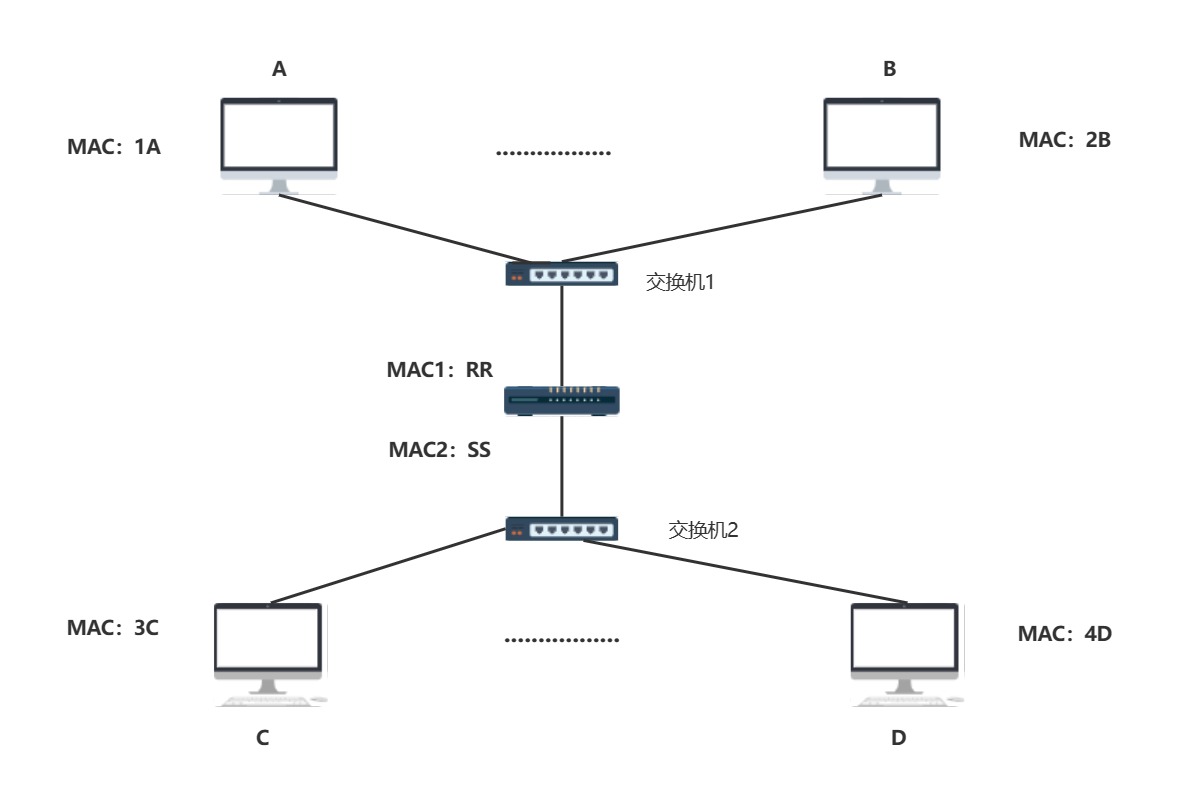
- 路由器也如同交换机一样,每个端口都具备一个MAC地址,与交换机不同的是路由器的每个端口还具备IP地址,不然子网的划分就不具备意义了
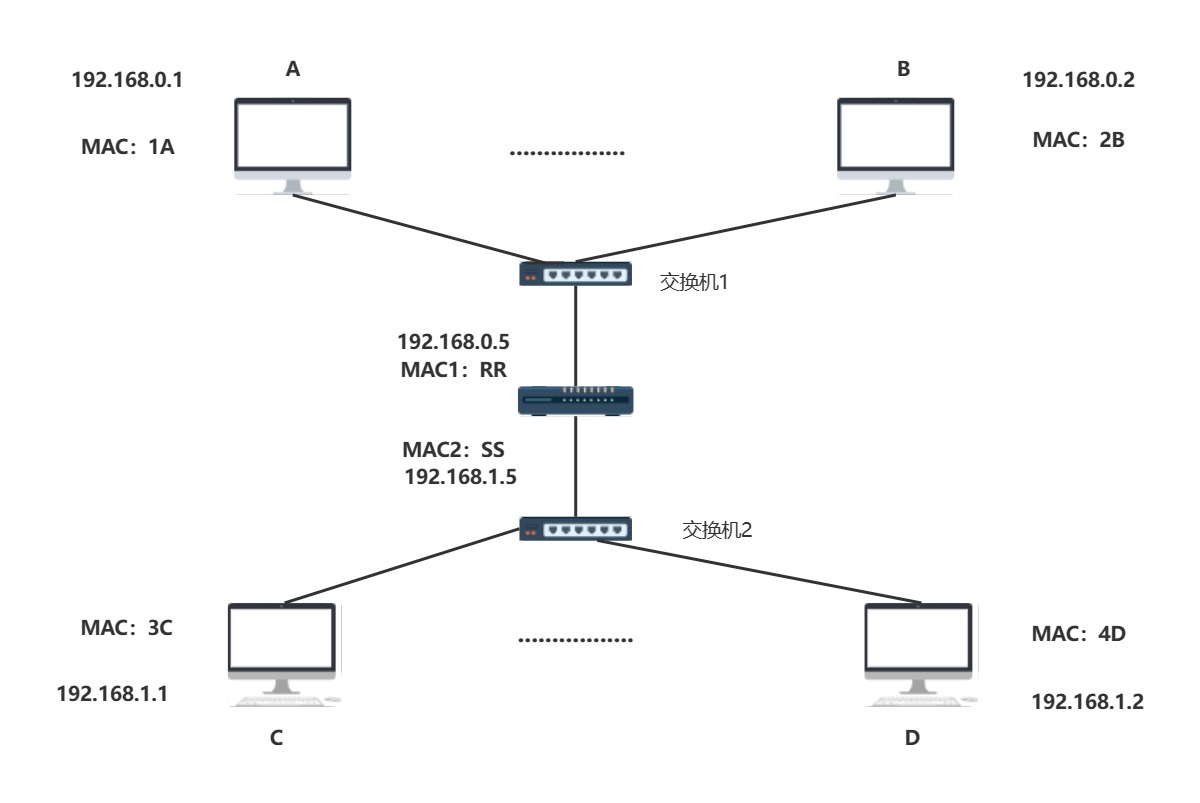
- 前面我们在讨论子网的划分时讨论到,子网掩码/IP地址相关概念,这里便能够明白如果主机A要和主机C通信,会先判断是否在一个子网下,如果不在一个子网下,就会转发给默认网关(也就是图中的192.168.0.5).
默认网关在我们的家庭,学校或者小型网络中,其实就是路由器的LAN接口,通过ipconfig常常就能看到,而通过这个地址常常可以访问路由器后台管理,至于默认网关的地址有没有硬性规定,只要是在同一个子网下,且未被其他主机占用的情况下,自行更改也是可行的
- 试着再度思考一个问题:主机A判断主机C和他已经不属于一个子网的前提下,主机A的IP控制头中目的IP地址会被修改成默认网关的IP地址还是主机C的IP地址?
很多人其实并不能理解主机A和主机C的通信看似是一步完成的,那主机A在知道默认网关的地址的前提下,发送给默认网关也就是我们的路由器,照理说主机A发送的IP头部中 目的IP地址字段不应该填写默认网关的地址吗?
- 那我们试着填写默认网关的IP地址填写到目的地址中
- 传送给路由器,路由器一看目的地址是自身某个端口的ip地址,一下子就懵逼了
- 因此IP控制头中 目的地址的IP地址就是主机C的地址 ,那主机A又是如何确定默认网关呢 ?
这里我们便想到了交换机,他工作于数据链路层,对于网络层的IP数据包等他一概不知,他只需要完成隶属于MAC层的工作任务就行了,前面我们提及到路由器的每个端口也具备每个MAC地址,那我们是否可以将路由器看作另一个主机呢,只不过主机A在将数据交付给路由器后,并没有达到终点,这是因为交换机仅仅完成了数据链路层的工作!!!!他仅仅是确定了路由器某端的某个地址,而路由器也享受来自数据链路层的服务,在主机A并不知道默认网关的MAC地址下,会发送ARP协议数据包,由交换机交付给路由器的某个端口,路由器因此返回给相应的MAC帧,这一个过程十分的重要,他再次体现了网络层次的架构设计非常的巧妙.因此我们可以看到在主机A知道了默认网关的地址情况下,他发送的以太网MAC帧其实是这样的
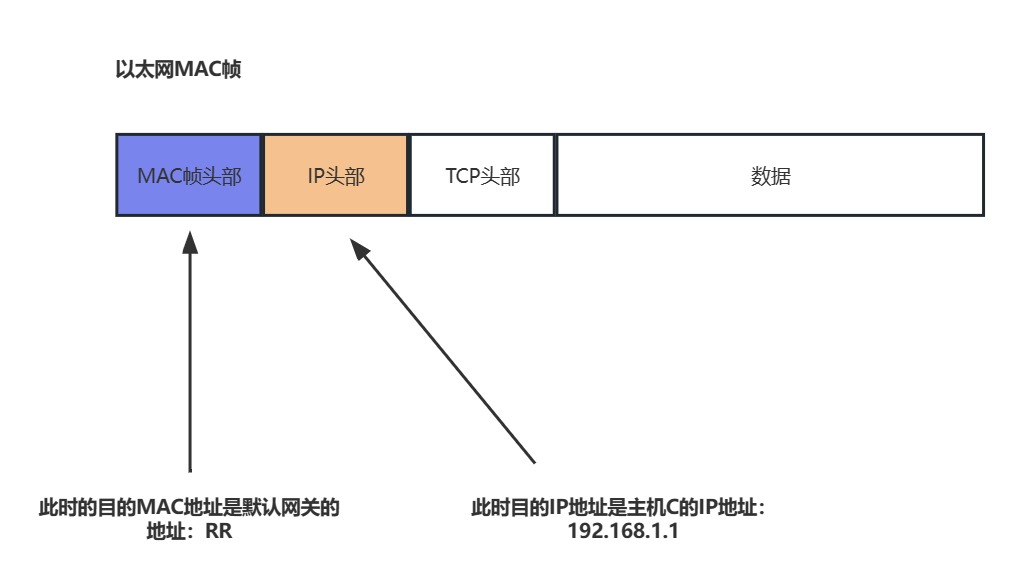
这和我们想象中的认知并不相同,貌似目的MAC地址应当与目的IP地址匹配,甚至不应该是两台主机.
- 路由表里的信息
| 目的地址 | 下一跳 | 端口 |
|---|---|---|
| 192.168.0.1/24 | ~ | 1 |
| 192.168.0.2/24 | ~ | 1 |
| 192.168.1.1/24 | ~ | 2 |
| 192.168.1.2/24 | ~ | 2 |
由于上图只有一个路由器的缘故,所以下一跳并没有记录,如果有多个路由器的时候,下一跳记录的可能就是某个网络节点的IP地址,毕竟路由器并不可能通过一次查找就能直接发送数据到达你想抵达的主机,通常都是由路由和交换机形成链路,通过IP地址和MAC地址的转换寻找到最后的主机
处了路由表的这几列,路由表还存在跃点数这样的字段列,他存储着到达下一跳的距离,由于真实的互联网拓扑结构是复杂的图形结构,所以路由之间的连接,意味着存在可能存在不同的链路到达目的主机,这时候就需要计算跃点选择最佳的路由,因此有着路由算法来进行评估和测量
- 至于路由表中的目的地址,其实是将子网掩码添加了进去:例如192.168.0.1/24 ,子网掩码其实就是255.255.255.0,而目的IP地址则是192.168.0.1,至于路由器如何选项端口进行转发,其实就是判断是否在同一个子网下,然后交付给端口,由端口进行转发。
那如果在路由表中并没有匹配到精准子网的记录呢?
毕竟两台通讯的主机有可能并不仅仅跨1个路由器,路由器是用来划分子网的,并不能准确的知道哪个主机,但路由表同样可以缩小范围,帮助你一步一步最后定位目标子网的位置,这种方式就是最长匹配原则
什么是最长匹配原则:路由器会根据网络前缀最长相同的IP地址进行比对,这意味着越接近目的IP地址的路由表IP地址,他可分配的主机就越接近目的IP地址下的子网IP地址数量,这种思维有点类似一个更大的子网下寻找更小的一个子网,类似我们的乡,镇,县,市,省的感觉。
以下是一个举例:
目的IP地址:192.168.0.100
路由表中IP地址:192.168.0.0/24 | 192.168.0.0/16
根据最长匹配原则会选择192.168.0.0/24
192.168.0.0/24可表示的子网范围 192.168.0.1~192.168.0.254
那如果路由表中匹配不到时该如何选择?
选择默认路由,如同主机一样也具备默认网关,默认路由的子网掩码为0.0.0.0,意味着不需要进行任何匹配,是在被逼无奈之下的选择,由他转发给下一跳的IP地址,当然通常,这个IP地址是由人为进行配置的,所以不正常的配置可能会导致闭环进入死循环.
路由表如果丢弃包时,会怎么做?
会发送ICMP消息告知发送方,在未配置默认路由并找不到相应的网络前缀的时候或者某些防火墙的设置,导致路由器丢包,发送ICMP消息数据包
4.4包的有效期
- TTL字段:表示Time to Live 生存时间,也就是网络包的生存时间,在每经过一次路由器时,便会减1,直至为0,则丢弃此包.
这一机制是为了防止死循环,如果路由器中的配置信息发生混乱,就有可能出现这种情况
4.5包的分片
我们在TCP模块中了解过,TCP包如果超过MSS,就会被切分成TCP段,而IP头部同样有着控制字段来控制成片的信息.
为什么要切片?
答:输入输出端口接受包的情况不一定相同
- 分片的操作过程如下图所示:
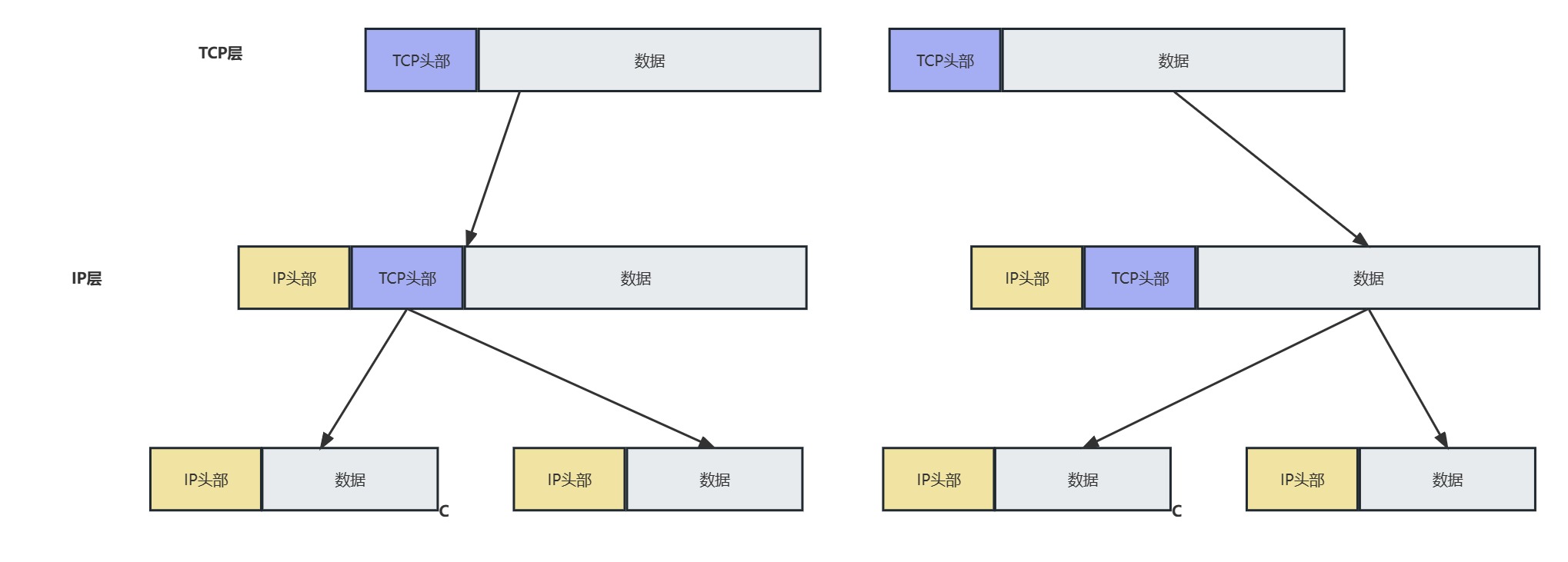
首先,我们需要知道输出端口的MTU,看看这个包需不需要分片直接发送,最大包长度是由端口类型长度决定的
- 之后让我们了解分片的具体实例:
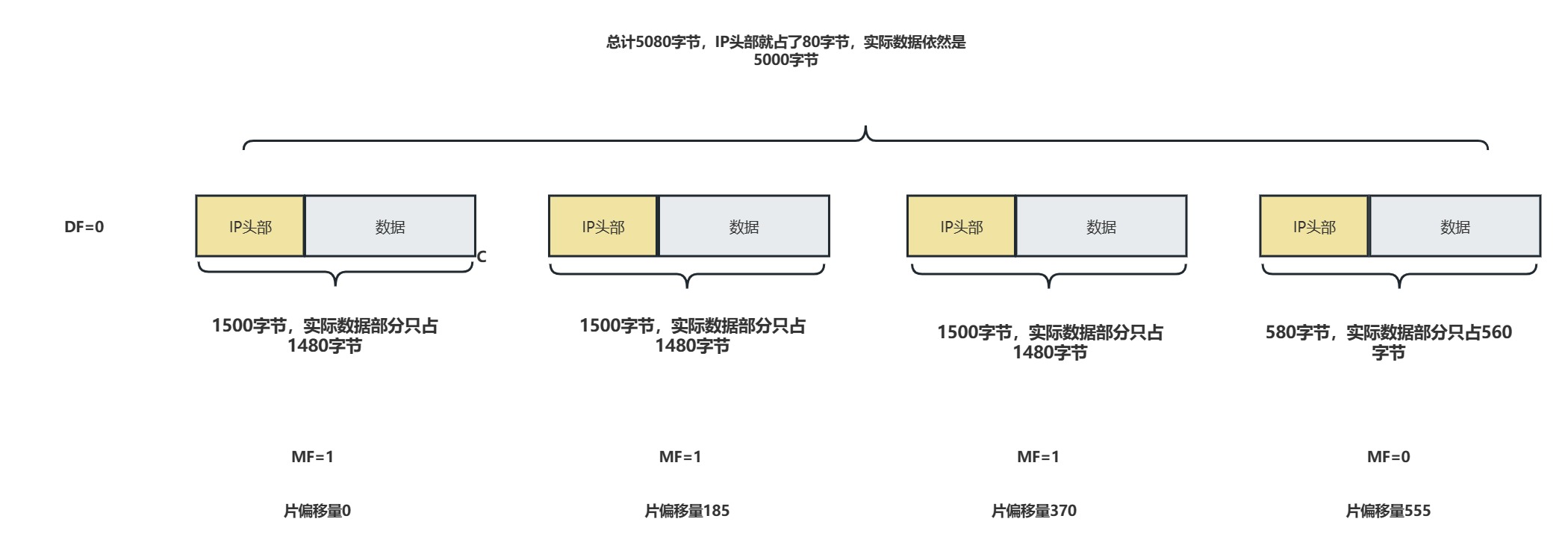
假设有一台发送方主机要发送一个大小为5000字节的数据报给接收方主机,而网络的MTU为1500字节。
- 原始数据报文:发送方主机生成了一个大小为5000字节的原始IP数据报文。
- 分片:由于原始数据报文的大小超过了网络的MTU,发送方主机需要对其进行分片。根据MTU的限制,将原始数据报文分割成多个较小的片段。
- 第一个分片:由于MTU为1500字节,第一个分片大小为1500字节(IP头部 + 数据)。
- 第二个分片:同样大小为1500字节。
- 第三个分片:同样大小为1500字节。
- 第四个分片:剩余的580字节
- 分片信息:每个分片都携带有关分片的信息。
- 第一个分片:片偏移字段设置为0(因为是第一个分片),标志位中DF位为0(允许分片),MF位为1(表示后续还有更多的分片)。
- 第二个分片:片偏移字段设置为185(前一个分片占用了1500字节,因此偏移185 x 8 = 1480字节),标志位中DF位为0,MF位为1。
- 第三个分片:片偏移字段设置为370(前一个分片占用了1500字节,因此偏移370 x 8 = 2960字节),标志位中DF位为0,MF位为1。
- 第四个分片:片偏移字段设置为555(前一个分片占用了1500字节,因此偏移555 x 8 = 4440字节),标志位中DF位为0,MF位为0(表示这是最后一个分片)。
- 传输:发送方主机将这些分片发送到网络上,经过路由器和中间设备的传输,最终到达目标主机。
- 重组:接收方主机接收到分片后,根据IP头部的信息对分片进行重组。接收方使用片偏移字段将不同的分片按顺序组合成原始数据报文。如果MF位为1,表示后续还有更多的分片,接收方主机会等待后续分片的到达。
- 完整数据报文:当所有分片都被接收并正确重组后,接收方主机得到了完整的原始数据报文,即大小为5080字节的数据报文。接收方主机可以继续处理该数据报文,如将其交给上层协议进行进一步处理。
这样,数据包经由IP模块进行分片后就会交付给网卡和我们的路由器,经由他们进行转发
4.6路由器的功能
4.61地址转换(NAT)
正如我们前面所了解的路由器可以根据IP子网的划分,来确定目的主机的所在子网,最后根据子网中的IP地址和MAC地址确定此主机,但是即使是通过不定长的子网划分以及无分类的IP地址分类也只是提高了地址的利用率,减少了地址的浪费,可这并不能阻止计算机大量的发展,因此,每个人都具备不一样的IP地址显然不太可能实现,过不了多久IP地址就会被分配完,因此,为了解决这个问题,关键在于地址的分配方式,就好比我们每个小区都需要用单元号和楼层号房门号来确定,其他小区就不是这样的了吗,例如:A小区的1号单元2楼xx和B小区的1号单元2楼xx,他们虽然不属于同一个小区,但都有同样的一个表现形式,我们将这种表现形式抽离出来就有了我们的*私网地址和公网地址
- 可能那样说还不够直白,也就是A小区1号楼2楼的201用户,和B小区的1号楼2楼的201用户,他们的表现形式都是小区->号->楼->门房号.本质上都是一种类型,我们可不可以用一种形式去同时表现他们,就比如我们的IP地址192.168.0.1.......,这个眼熟的地址现在明白如何由来了吧,因此我们只需要在不同的小区给予相同的IP地址分配就行了,至于是不是非得一栋楼一层楼或者一个门牌号才能分配同一个IP地址,这显得没必要,在要寻找目的主机(用户)时,告知小区的管理者(路由器)即可,因此,我们将这个子网下的这片区域称为内网.
私有地址的规则其实很简单,在内网中可利用作为私有地址的范围仅仅只有这些,大家看到就会觉的很眼熟:
10.0.0.0 ~ 10.255.255.255(CIDR表示为10.0.0.0/8)
172.16.0.0 ~ 172.31.255.255(CIDR表示为172.16.0.0/12)
192.168.0.0 ~ 191.168.255.255(CIDR表示为192.168.0.0/16)
- 尽管这样,确实能节省一部分地址,但也依旧无法完全解决问题,试想一下,如果两个小区这时候需要进行通信,也就是某个内网下需要访问外部设备,如果出现相同的地址,包就无法正常传输.于是,我们是否可以让小区的管理者知道包的走向,是需要传递给外网(公网),还是内网的数据包呢?
于是我们可以将内网划分成两个部分,一个部分用来与互联网通信,另一个部分用来与内网之间的各设备之间进行通信,也就被划分成了内网前端和内网主体(内网主题之间的通信就是我们之前了解过的,而内网前端则需要与互联网通信,要进行地址转换)

4.61地址转换的基本原理
IP地址在数据的传输过程中,是否会发生改变?
现在的答案是:一定会
既然被称之为地址转换,就需要做到IP地址的改变,下面,我们来举例说明:
- 就比如A小区的某用户需要与B小区的某用户进行通信,A小区的用户会将数据托付给A小区的管理者(路由器),管理者会将IP地址和端口号进行改写,将发送方的IP地址从私有地址改写为公有地址,这里的公网地址是地址转换设备的互联网接入端口的地址,与此同时端口号也要进行改写,地址转换设备会随机选择空闲的一个端口.
看一下源IP的变化过程在经由NAT转换之后
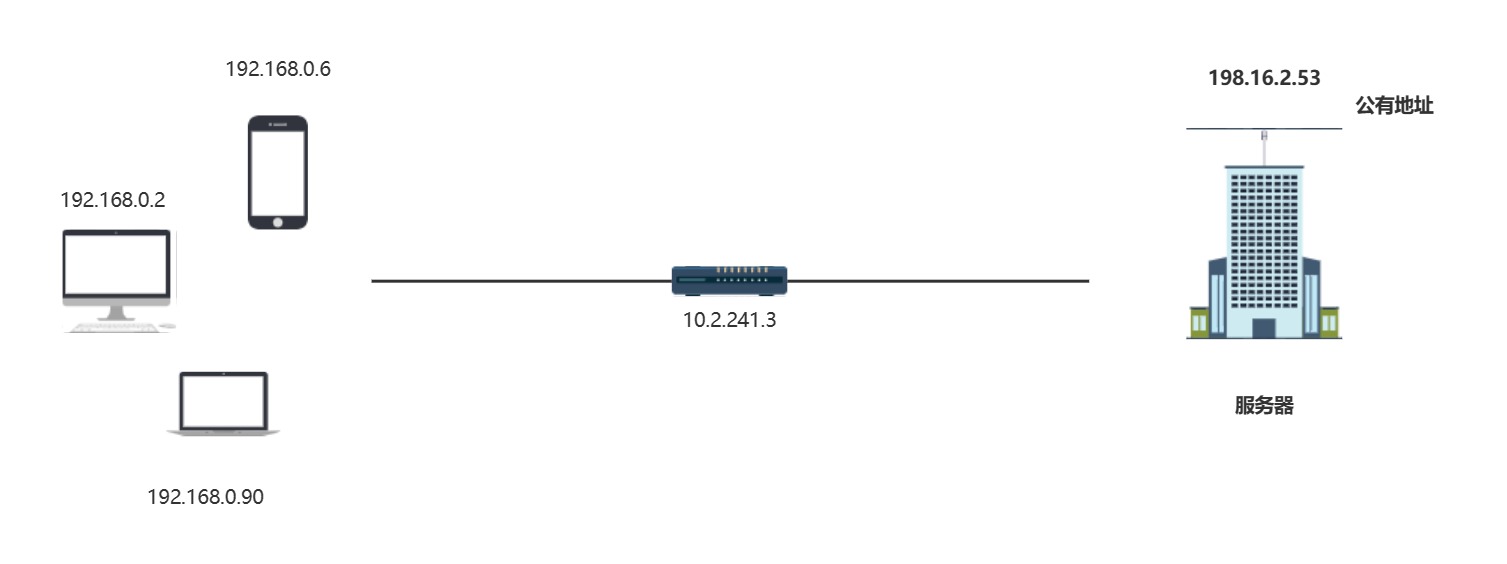
- 来看一下具体的NAT表:
| 公有地址 | 端口号 | 私有地址 | 端口号 |
|---|---|---|---|
| 10.2.241.3 | 5555 | 192.168.0.2 | 890 |
| 10.2.241.3 | 5556 | 192.168.0.6 | 1023 |
| 10.2.241.3 | 5557 | 192.168.0.90 | 4214 |
这样,在发送方发送给路由器后,路由器就会将源发送方的IP地址和端口号进行改写,改写成对应的公有地址和端口号,这个包就能通过路由器进行转发出去(前面我们提及过路由表,是为了确定下一跳的位置,在确定之后,就会进行IP地址的转换)
- 为什么要使用端口号,要去改写端口号?
不同的端口号和公有地址就可以组合出更多的IP映射关系,这样就可以容纳更多的IP地址,端口号是一个16比特的数值,所以其实可以分出几万个端口,这就意味着一个公有地址可以对应几万个私有地址,这样就提高了公用地址的利用率.
- 再度思考一个问题,公有地址是我们看到的真正的公有地址吗?路由器所具备的对外地址也是公有地址吗?
上述举例的路由器公有地址10.2.241.3在前述私有地址规则中,其实他属于私有地址,在这里,路由器的WAN IP(公有地址,一般情况下)也就是对外的这个地址,但是通常情况下,路由器的普遍情况越来越广泛,路由器个个分配真正的公网IP地址显得不可现实,于是,路由器的WAN IP也有可能是私有IP,上述10.2.241.3只不过是为了理解目的IP地址做的假设,现实生活中,路由器的对外WAN IP其实也是私网的IP,只需要对比一下符不符合内网IP的规则即可判断了,这有点类似套娃的感觉,就好比小区里用户很多,但是小区也同样多.
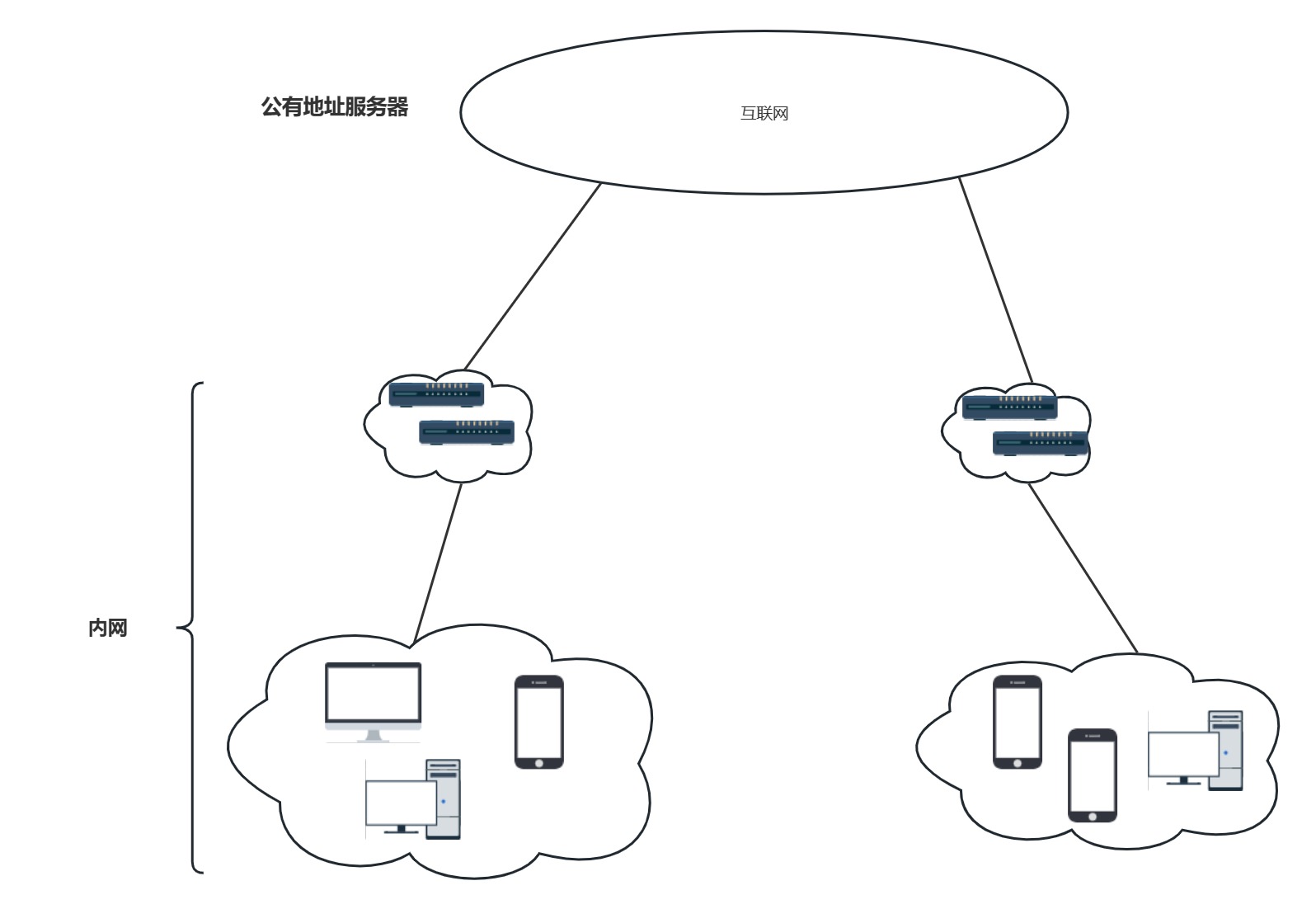
4.62地址转换的安全性
试想一下发送方可以访问其外网的公有IP,但是对于从外网想访问内网的包来说,如果NAT表中没有对应的记录就无法转发,从某种意义上来看,除非主动允许,否则无法从互联网向子网内部发送网络包,这种机制可以防止非法入侵.,至于如果你想实现的话,可以手动去实现添加记录.......

 浙公网安备 33010602011771号
浙公网安备 33010602011771号