KMP算法具体解释(转)
作者:July。
出处:http://blog.csdn.net/v_JULY_v/。
引记
此前一天,一位MS的朋友邀我一起去与他讨论高速排序,红黑树,字典树,B树、后缀树,包含KMP算法,只有在解说KMP算法的时候,言语磕磕碰碰,我想,原因有二:1、博客内的东西不常回想,忘了不少;2、便是我对KMP算法的理解还不够彻底,自不用说解说自如,运用自如了。所以,特再写本篇文章。因为此前,个人已经写过关于KMP算法的两篇文章,所以,本文名为:KMP算法之总结篇。
本文分为例如以下六个部分:
- 第一部分、再次回想普通的BF算法与KMP算法各自的时间复杂度,并两相对比各自的匹配原理;
- 第二部分、通过我此前第二篇文章的引用,用图从头到尾具体阐述KMP算法中的next数组求法,并运用求得的next数组写出KMP算法的源代码;
- 第三部分、KMP算法的两种实现,代码实现一是依据本人关于KMP算法的第二篇文章所写,代码实现二是依据本人的关于KMP算法的第一篇文章所写;
- 第四部分、測试,分别对第三部分的两种实现中next数组的求法进行測试,挖掘其差别之所在;
- 第五部分、KMP完整准确源代码,给出KMP算法的准确的完整源代码;
- 第六步份、一眼看出字符串的next数组各值,通过几个样例,让读者能依据字符串本身一眼推断出其next数组各值。
力求让此文彻底让读者洞穿此KMP算法,全部原理,来龙去脉,让读者搞个通通透透(注意,本文中第二部分及第三部分的代码实现一的字符串下标i 从0開始计算,其他部分如第三部分的代码实现二,第五部分,和第六部分的字符串下标i 皆是从1開始的)。
在看本文之前,你心中如若对前缀和后缀这个两个概念有自己的理解,便最好了。有些东西比方此KMP算法须要我们重复思考,重复求解才行。个人写的关于KMP算法的第二篇文章为:六(续)、从KMP算法一步一步谈到BM算法;第一篇为:六、教你初步了解KMP算法、updated(文末链接)。ok,若有不论什么问题,恳请不吝指正。多谢。
第一部分、KMP算法初解
1、普通字符串匹配BF算法与KMP算法的时间复杂度比較
KMP算法是一种线性时间复杂的字符串匹配算法,它是对BF算法(Brute-Force,最主要的字符串匹配算法的)改进。对于给的原始串S和模式串P,须要从字符串S中找到字符串P出现的位置的索引。
BF算法的时间复杂度O(strlen(S) * strlen(T)),空间复杂度O(1)。
KMP算法的时间复杂度O(strlen(S) + strlen(T)),空间复杂度O(strlen(T))。
2、BF算法与KMP算法的差别
如果如今S串匹配到i位置,T串匹配到j位置。那么总的来说,两种算法的主要差别在于失配的情况下,对![[j]](http://img.t.sinajs.cn/t35/style/images/common/face/ext/normal/af/newj_org.gif) 的值做的处理:
的值做的处理:
BF算法中,假设当前字符匹配成功,即s[i+j] == T[j],令j++,继续匹配下一个字符;假设失配,即S[i + j] != T[j],须要让i++,而且j= 0,即每次匹配失败的情况下,模式串T相对于原始串S向右移动了一位。
而KMP算法中,假设当前字符匹配成功,即S[i]==T[j],令i++,j++,继续匹配下一个字符;假设匹配失败,即S[i] != T[j],须要保持i不变,而且让j = next[j],这里next[j] <=j -1,即模式串T相对于原始串S向右移动了至少1位(移动的实际位数j - next[j] >=1),
同一时候移动之后,i之前的部分(即S[i-j+1 ~ i-1]),和j=next[j]之前的部分(即T[0
~ j-2])仍然相等。显然,相对于BF算法来说,KMP移动很多其它的位数,起到了一个加速的作用!
(失配的特殊情形,令j=next[j]导致j==0的时候,须要将i
++,否则此时没有移动模式串)。
3、BF算法为什么要回溯
首先说一下为什么BF算法要回溯。例如以下两字符串匹配(恰如上面所述:BF算法中,假设当前字符匹配成功,即s[i+j] == T[j],令j++,继续匹配下一个字符):
i+j(j随T中的j++变,而动)
S:aaaacefghij
j++
T:aaac
假设不回溯的话就是从下一位開始比起:
aaaacefghij
aaac
看到上面红颜色的没,假设不回溯的话,那么从a 的下一位c 比起。然而下述这样的情况就漏了(正确的做法当然是要回溯:假设失配,即S[i + j] != T[j],须要让i++,而且j= 0):
aaaacefghij
aaac
所以,BF算法要回溯,其代码例如以下:
- int Index(SString S, SString T, int pos) {
- //返回T在S中第pos个字符之后的位置
- i=pos; j=1;k=0;
- while ( i< = S[0] && j< = T[0] ) {
- if (S[i+k] = = T[j] ) {++k; ++j;} //继续比較兴许字符
- else {i=i+1; j=1; k=0;} //指针回溯到 下一首位,又一次開始
- }
- if(j>T[0]) return i; //子串结束,说明匹配成功
- else return 0;
- }//Index
只是,也有特殊情况能够不回溯,例如以下:
abcdefghij(主串)
abcdefg(模式串)
即(模式串)没有同样的才不须要回溯。
4、KMP
算法思想
普通的字符串匹配算法必需要回溯。但回溯就影响了效率,回溯是由T串本身的性质决定的,是由于T串本身有前后'部分匹配'的性质。像上面所说假设主串为abcdef这种,大没有回溯的必要。
改进的地方也就是这里,我们从T串本身出发,事先就找准了T自身前后部分匹配的位置,那就能够改进算法。
假设不用回溯,那模式串下一个位置从哪里開始呢?
还是上面那个样例,T(模式串)为ababc,假设c失配,那就能够往前移到aba最后一个a的位置,像这样:
...ababd...
ababc
->ababc
这样i不用回溯,j跳到前2个位置,继续匹配的过程,这就是KMP算法所在。这个当T[j]失配后,j 应该往前跳的值就是j的next值,它是由T串本身固有决定的,与S串(主串)无关。
5、next数组的含义
重点来了。以下解释一下next数组的含义,这个也是KMP算法中比較不好理解的一点。
令原始串为: S[i],当中0<=i<=n;模式串为: T[j],当中0<=j<=m。
如果眼下匹配到例如以下位置
S0,S1,S2,...,Si-j,Si-j+1...............,Si-1, Si, Si+1,....,Sn
T0,T1,.....................,Tj-1, Tj, ..........
S和T的绿色部分匹配成功,恰好到Si和Tj的时候失配,如果要保持i不变,同一时候达到让模式串T相对于原始串S右移的话,能够更新j的值,让Si和新的Tj进行匹配,如果新的j用next[j]表示,即让Si和next[j]匹配,显然新的j值要小于之前的j值,模式串才会是右移的效果,也就是说应该有next[j] <= j -1。那新的j值也就是next[j]应该是多少呢?我们观察例如以下的匹配:
1)假设模式串右移1位(从简单的思考起,移动一位会怎么样),即next[j] = j - 1, 即让蓝色的Si和Tj-1匹配 (注:省略号为未匹配部分)
S0,S1,S2,...,Si-j,Si-j+1...............,Si-1, Si, Si+1,....,Sn
T0,T1,.....................,Tj-1, Tj, .......... (T的划线部分和S划线部分相等【1】)
T0,T1,.................Tj-2,Tj-1, ....... (移动后的T的划线部分和S的划线部分相等【2】)
依据【1】【2】能够知道当next[j] =j -1,即模式串右移一位的时候,有T[0 ~ j-2] == T[1 ~ j-1],而这两部分恰好是字符串T[0 ~j-1]的前缀和后缀,也就是说next[j]的值取决于模式串T中j前面部分的前缀和后缀相等部分的长度(好好揣摩这两个keyword概念:前缀、后缀,或者再想想,我的上一篇文章,从Trie树谈到后缀树中,后缀树的概念)。
2)假设模式串右移2位,即next[j] = j - 2, 即让蓝色的Si和Tj-2匹配
S0,S1,...,Si-j,Si-j+1,Si-j+2...............,Si-1, Si, Si+1,....,Sn
T0,T1,T2,.....................,Tj-1, Tj, ..........(T的划线部分和S划线部分相等【3】)
T0,T1,...............,Tj-3,Tj-2,.........(移动后的T的划线部分和S的划线部分相等【4】)
相同依据【3】【4】能够知道当next[j] =j -2,即模式串右移两位的时候,有T[0 ~ j-3] == T[2 ~ j-1]。而这两部分也恰好是字符串T[0 ~j-1]的前缀和后缀,也就是说next[j]的值取决于模式串T中j前面部分的前缀和后缀相等部分的长度。
3)依次类推,能够得到例如以下结论:当发生失配的情况下,j的新值next[j]取决于模式串中T[0 ~ j-1]中前缀和后缀相等部分的长度, 而且next[j]恰好等于这个最大长度。
为此,请再同意我引用上文中的一段原文:“KMP算法中,假设当前字符匹配成功,即S[i]==T[j],令i++,j++,继续匹配下一个字符;假设匹配失败,即S[i] != T[j],须要保持i不变,而且让j = next[j],这里next[j] <=j -1,即模式串T相对于原始串S向右移动了至少1位(移动的实际位数j - next[j] >=1),
同一时候移动之后,i之前的部分(即S[i-j+1 ~ i-1]),和j=next[j]之前的部分(即T[0 ~ j-2])仍然相等。显然,相对于BF算法来说,KMP移动很多其它的位数,起到了一个加速的作用! (失配的特殊情形,令j=next[j]导致j==0的时候,须要将i ++,否则此时没有移动模式串)。”
于此,也就不难理解了我的关于KMP算法的第二篇文章之中:“当匹配到S[i] != P[j]的时候有 S[i-j…i-1] = P[0…j-1]. 假设以下用j_next去匹配,则有P[0…j_next-1] = S[i-j_next…i-1] = P[j-j_next…j-1]。此步骤例如以下图3-1所看到的。
当匹配到S[i] != P[j]时,S[i-j…i-1] = P[0…j-1]:
S: 0 … i-j … i-1 i …
P: 0 … j-1 j …
假设以下用j_next去匹配,则有P[0…j_next-1] = S[i-j_next…i-1] = P[j-j_next…j-1]。
所以在P中有例如以下匹配关系(获得这个匹配关系的意义是用来求next数组):
P: 0 … j-j_next .…j-1_ …
P: 0 … .j_next-1 …
所以,依据上面两个步骤,推出下一匹配位置j_next:
S: 0 … i-j … i-j_next … i-1 i …
P: 0 … j_next-1 j_next …
图3-1 求j-next(最大的值)的三个步骤
以下,我们用变量k来代表求得的j_next的最大值,即k表示这S[i]、P[j]不匹配时P中下一个用来匹配的位置,使得P[0…k-1] = P[j-k…j-1],而我们要尽量找到这个k的最大值。”。
依据上文的【1】与【2】的匹配情况,可得第二篇文章之中所谓的k=1(如aaaa的形式),依据上文的【3】与【4】的匹配情况,k=2(如abab的形式)。
所以,归根究底,KMP算法的本质便是:针对待匹配的模式串的特点,推断它是否有反复的字符,从而找到它的前缀与后缀,进而求出对应的Next数组,终于依据Next数组而进行KMP匹配。接下来,进入本文的第二部分。
第二部分、next数组求法的来龙去脉与KMP算法的源代码
本部分引自个人此前的关于KMP算法的第二篇文章:六之续、由KMP算法谈到BM算法。前面,我们已经知道即不能让P[j]=P[next[j]]成立成立。不能再出现上面那样的情况啊!即不能有这样的情况出现:P[3]=b,而竟也有P[next[3]]=P[1]=b。
正如在第二篇文章中,所提到的那样:“这里读者理解可能有困难的是由于文中,时而next,时而nextval,把他们的思维搞混乱了。事实上next用于表达数组索引,而nextval专用于表达next数组索引下的详细各值,差别细微。至于文中说不同意P=P[next[j]
]出现,是由于已经有P![[3]](http://img.t.sinajs.cn/t35/style/images/common/face/ext/normal/78/three_org.gif "[3]") =b与S
=b与S![[i]](http://img.t.sinajs.cn/t35/style/images/common/face/ext/normal/e6/weiboi_org.gif "[i]") 匹配败,而P[next]=P1=b,若再拿P[1]=b去与S匹配则必败。”--六之续、由KMP算法谈到BM算法。
匹配败,而P[next]=P1=b,若再拿P[1]=b去与S匹配则必败。”--六之续、由KMP算法谈到BM算法。
又恰恰如上文中所述:“模式串T相对于原始串S向右移动了至少1位(移动的实际位数j - next[j] >=1)”。
ok,求next数组的get_nextval函数正确代码例如以下:
- //代码4-1
- //修正后的求next数组各值的函数代码
- void get_nextval(char const* ptrn, int plen, int* nextval)
- {
- int i = 0;
- nextval[i] = -1;
- int j = -1;
- while( i < plen-1 )
- {
- if( j == -1 || ptrn[i] == ptrn[j] ) //循环的if部分
- {
- ++i;
- ++j;
- //修正的地方就发生以下这4行
- if( ptrn[i] != ptrn[j] ) //++i,++j之后,再次推断ptrn[i]与ptrn[j]的关系
- nextval[i] = j; //之前的错误解法就在于整个推断仅仅有这一句。
- else
- nextval[i] = nextval[j];
- }
- else //循环的else部分
- j = nextval[j];
- }
- }
举个样例,举例说明下上述求next数组的方法。
S a b a b a b c
P a b a b c
S[4] != P[4]
那么下一个和S[4]匹配的位置是k=2(也即P[next[4]])。此处的k=2也再次佐证了上文第3节开头处关于为了找到下一个匹配的位置时k的求法。上面的主串与模式串开头4个字符都是“abab”,所以,匹配失效后下一个匹配的位置直接跳两步继续进行匹配。
S a b a b a b c
P a b a b c
匹配成功P的next数组值分别为-1 0 -1 0 2
next数组各值怎么求出来的呢?分下面五步:
- 初始化:i=0,j=-1,nextval[0] = -1。因为j == -1,进入上述循环的if部分,++i得i=1,++j得j=0,且ptrn[i] != ptrn[j](即a!=b)),所以得到第二个next值即nextval[1] = 0;;
- i=1,j=0,进入循环esle部分,j=nextval[j]=nextval[0]=-1;
- 进入循环的if部分,++i,++j,i=2,j=0,因为ptrn[i]=ptrn[j]=a,所以nextval[2]=nextval[0]=-1;
- i=2, j=0, 因为ptrn[i]=ptrn[j],再次进入循环if部分,所以++i=3,++j=1,因为ptrn[i]=ptrn[j]=b,所以nextval[3]=nextval[1]=0;
- i=3,j=1,因为ptrn[i]=ptrn[j]=b,所以++i=4,++j=2,退出循环。
这样上例中模式串的next数组各值终于应该为:
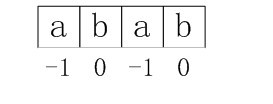
图4-1 正确的next数组各值
next数组求解的详细步骤例如以下:
初始化:nextval[0] = -1,我们得到第一个next值即-1.
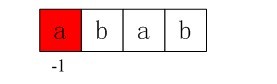
图4-2 初始化第一个next值即-1
i = 0,j = -1,因为j == -1,进入上述循环的if部分,++i得i=1,++j得j=0,且ptrn[i] != ptrn[j](即a!=b)),所以得到第二个next值即nextval[1] = 0;
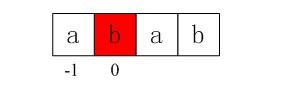
图4-3 第二个next值0
上面我们已经得到,i= 1,j = 0,因为不满足条件j == -1 || ptrn[i] == ptrn[j],所以进入循环的esle部分,得j = nextval[j] = -1;此时,仍满足循环条件,因为i = 1,j = -1,因为j == -1,再次进入循环的if部分,++i得i=2,++j得j=0,因为ptrn[i] == ptrn[j](即ptrn[2]=ptrn[0],也就是说第1个元素和第三个元素都是a),所以进入循环if部分内嵌的else部分,得到nextval[2] = nextval[0] = -1;
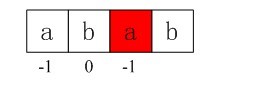
图4-4 第三个next数组元素值-1
i = 2,j = 0,因为ptrn[i] == ptrn[j],进入if部分,++i得i=3,++j得j=1,所以ptrn[i] == ptrn[j](ptrn[3]==ptrn[1],也就是说第2个元素和第4个元素都是b),所以进入循环if部分内嵌的else部分,得到nextval[3] = nextval[1] = 0;
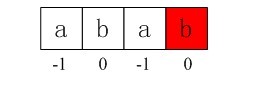
图4-5 第四个数组元素值0
假设你还是没有弄懂上述过程是怎么一回事,请如今拿出一张纸和一支笔出来,一步一步的画下上述过程。相信我,把图画出来了之后,你一定能明确它的。
然后,我留一个问题给读者,为什么上述的next数组要那么求?有什么原理么?
提示:我们从上述字符串abab 各字符的next值-1 0 -1 0,能够看出来,依据求得的next数组值,偷用前缀、后缀的概念,一定能够推断出在abab之中,前缀和后缀同样,即都是ab,反过来,假设一个字符串的前缀和后缀同样,那么依据前缀和后缀依次求得的next各值也是同样的。
- 5、利用求得的next数组各值运用Kmp算法
Ok,next数组各值已经求得,万事俱备,东风也不欠了。接下来,咱们就要应用求得的next值,应用KMP算法来匹配字符串了。还记得KMP算法是怎么一回事吗?容我再次引用下之前的KMP算法的代码,例如以下:
- //代码5-1
- //int kmp_seach(char const*, int, char const*, int, int const*, int pos) KMP模式匹配函数
- //输入:src, slen主串
- //输入:patn, plen模式串
- //输入:nextval KMP算法中的next函数值数组
- int kmp_search(char const* src, int slen, char const* patn, int plen, int const* nextval, int pos)
- {
- int i = pos;
- int j = 0;
- while ( i < slen && j < plen )
- {
- if( j == -1 || src[i] == patn[j] )
- {
- ++i;
- ++j;
- }
- else
- {
- j = nextval[j];
- //当匹配失败的时候直接用p[j_next]与s[i]比較,
- //以下阐述怎么求这个值,即匹配失效后下一次匹配的位置
- }
- }
- if( j >= plen )
- return i-plen;
- else
- return -1;
- }
我们上面已经求得的next值,例如以下:
图5-1 求得的正确的next数组元素各值
下面是匹配过程,分三步:
第一步:主串和模式串例如以下,S[3]与P[3]匹配失败。
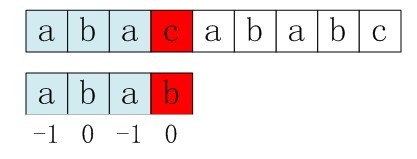
图5-2 第一步,S[3]与P[3]匹配失败
第二步:S[3]保持不变,P的下一个匹配位置是P[next[3]],而next[3]=0,所以P[next[3]]=P[0],即P[0]与S[3]匹配。在P[0]与S[3]处匹配失败。
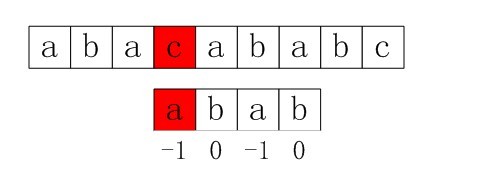
图5-3 第二步,在P[0]与S[3]处匹配失败
第三步:与上文中第3小节末的情况一致。因为上述第三步中,P[0]与S[3]还是不匹配。此时i=3,j=nextval[0]=-1,因为满足条件j==-1,所以进入循环的if部分,++i=4,++j=0,即主串指针下移一个位置,从P[0]与S[4]处開始匹配。最后j==plen,跳出循环,输出结果i-plen=4(即字串第一次出现的位置),匹配成功,算法结束。
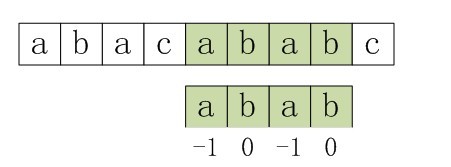
图5-4 第三步,匹配成功,算法结束
所以,综上,总结上述三步为:
- 開始匹配,直到P[3]!=S[3],匹配失败;
- nextval[3]=0,所以P[0]继续与S[3]匹配,再次匹配失败;
- nextval[0]=-1,满足循环if部分条件j==-1,所以,++i,++j,主串指针下移一个位置,从P[0]与S[4]处開始匹配,最后j==plen,跳出循环,输出结果i-plen=4,算法结束。
第三部分、KMP算法的两种实现
代码实现一:
依据上文中第二部分内容的解析,完整写出KMP算法的代码已经不是难事了,例如以下:
- //copyright@2011 binghu and july
- #include "StdAfx.h"
- #include <string>
- #include <iostream>
- using namespace std;
- //代码4-1
- //修正后的求next数组各值的函数代码
- void get_nextval(char const* ptrn, int plen, int* nextval)
- {
- int i = 0; //注,此处与下文的代码实现二不同的是,i是从0開始的(代码实现二i从1開始)
- nextval[i] = -1;
- int j = -1;
- while( i < plen-1 )
- {
- if( j == -1 || ptrn[i] == ptrn[j] ) //循环的if部分
- {
- ++i;
- ++j;
- //修正的地方就发生以下这4行
- if( ptrn[i] != ptrn[j] ) //++i,++j之后,再次推断ptrn[i]与ptrn[j]的关系
- nextval[i] = j; //之前的错误解法就在于整个推断仅仅有这一句。
- else
- nextval[i] = nextval[j];
- }
- else //循环的else部分
- j = nextval[j];
- }
- }
- void print_progress(char const* src, int src_index, char const* pstr, int pstr_index)
- {
- cout<<src_index<<"\t"<<src<<endl;
- cout<<pstr_index<<"\t";
- for( int i = 0; i < src_index-pstr_index; ++i )
- cout<<" ";
- cout<<pstr<<endl;
- cout<<endl;
- }
- //代码5-1
- //int kmp_seach(char const*, int, char const*, int, int const*, int pos) KMP模式匹配函数
- //输入:src, slen主串
- //输入:patn, plen模式串
- //输入:nextval KMP算法中的next函数值数组
- int kmp_search(char const* src, int slen, char const* patn, int plen, int const* nextval, int pos)
- {
- int i = pos;
- int j = 0;
- while ( i < slen && j < plen )
- {
- if( j == -1 || src[i] == patn[j] )
- {
- ++i;
- ++j;
- }
- else
- {
- j = nextval[j];
- //当匹配失败的时候直接用p[j_next]与s[i]比較,
- //以下阐述怎么求这个值,即匹配失效后下一次匹配的位置
- }
- }
- if( j >= plen )
- return i-plen;
- else
- return -1;
- }
- int main()
- {
- std::string src = "aabcabcebafabcabceabcaefabcacdabcab";
- std::string prn = "abac";
- int* nextval = new int[prn.size()];
- //int* next = new int[prn.size()];
- get_nextval(prn.data(), prn.size(), nextval);
- //get_next(prn.data(), prn.size(), next);
- for( int i = 0; i < prn.size(); ++i )
- cout<<nextval[i]<<"\t";
- cout<<endl;
- cout<<"result sub str: "<<src.substr( kmp_search(src.data(), src.size(), prn.data(), prn.size(), nextval, 0) )<<endl;
- system("pause");
- delete[] nextval;
- return 0;
- }
执行结果,例如以下图所看到的:

代码实现二:
再给出代码实现二之前,让我们再次回想下关于KMP算法的第一篇文章中的部分内容:
“第二节、KMP算法
2.1、 覆盖函数(overlay_function)
覆盖函数所表征的是pattern本身的性质,能够让为其表征的是pattern从左開始的全部连续子串的自我覆盖程度。比方例如以下的字串,abaabcaba
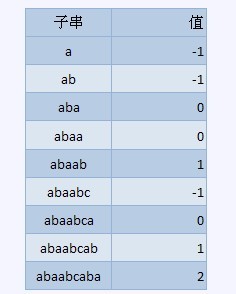
可能上面的图令读者理解起来还是不那么清晰易懂,事实上非常easy,针对字符串abaabcaba
a(-1) b(-1)a(0) a(0) b(1) c(-1) a(0) b(1)a(2)
解释:
- 初始化为-1
- b与a不同为-1
- 与第一个字符a同样为0
- 还是a为0
- 后缀ab与前缀ab两个字符同样为1
- 前面并无前缀c为-1
- 与第一个字符同为0
- 后缀ab前缀ab为1
- 前缀aba后缀aba为2
因为计数是从0始的,因此覆盖函数的值为0说明有1个匹配,对于从0还是从来開始计数是偏好问题,详细请自行调整,当中-1表示没有覆盖,那么何为覆盖呢,以下比較数学的来看一下定义,比方对于序列
a0a1...aj-1 aj
要找到一个k,使它满足
a0a1...ak-1ak=aj-kaj-k+1...aj-1aj
而没有更大的k满足这个条件,就是说要找到尽可能大k,使pattern前k字符与后k字符相匹配,k要尽可能的大,原因是假设有比較大的k存在。
但若我们选择较小的满足条件的k,那么当失配时,我们就会使pattern向右移动的位置变大,而较少的移动位置是存在匹配的,这样我们就会把可能匹配的结果丢失。比方以下的序列,
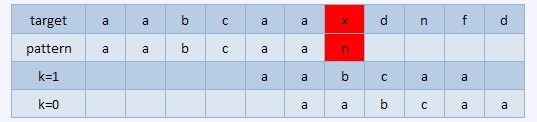
在红色部分失配,正确的结果是k=1的情况,把pattern右移4位,假设选择k=0,右移5位则会产生错误。计算这个overlay函数的方法能够採用递推,能够想象假设对于pattern的前j个字符,假设覆盖函数值为k
a0a1...ak-1ak=aj-kaj-k+1...aj-1aj
则对于pattern的前j+1序列字符,则有例如以下可能
⑴ pattern[k+1]==pattern[j+1] 此时overlay(j+1)=k+1=overlay(j)+1
⑵ pattern[k+1]≠pattern[j+1] 此时仅仅能在pattern前k+1个子符组所的子串中找到对应的overlay函数,h=overlay(k),假设此时pattern[h+1]==pattern[j+1],则overlay(j+1)=h+1否则反复(2)过程.
以下给出一段计算覆盖函数的代码:
- //copyright@ staurman
- //updated@2011 July
- #include "StdAfx.h"
- #include<iostream>
- #include<string>
- using namespace std;
- //solve to the next array
- void compute_overlay(const string& pattern)
- {
- const int pattern_length = pattern.size();
- int *overlay_function = new int[pattern_length];
- int index;
- overlay_function[0] = -1;
- for(int i=1;i<pattern_length;++i)
- //注,与上文代码段一不同的是,此处i是从1開始的,所以,下文中运用俩种方法求出来的next数组各值会有所不同
- {
- index = overlay_function[i-1];
- //store previous fail position k to index;
- while(index>=0 && pattern[i]!=pattern[index+1])
- {
- index = overlay_function[index];
- }
- if(pattern[i]==pattern[index+1])
- {
- overlay_function[i] = index + 1;
- }
- else
- {
- overlay_function[i] = -1;
- }
- }
- for(int i=0;i<pattern_length;++i)
- {
- cout<<overlay_function[i]<<endl;
- }
- delete[] overlay_function;
- }
- //abaabcaba
- int main()
- {
- string pattern = "abaabcaba";
- compute_overlay(pattern);
- system("pause");
- return 0;
- }
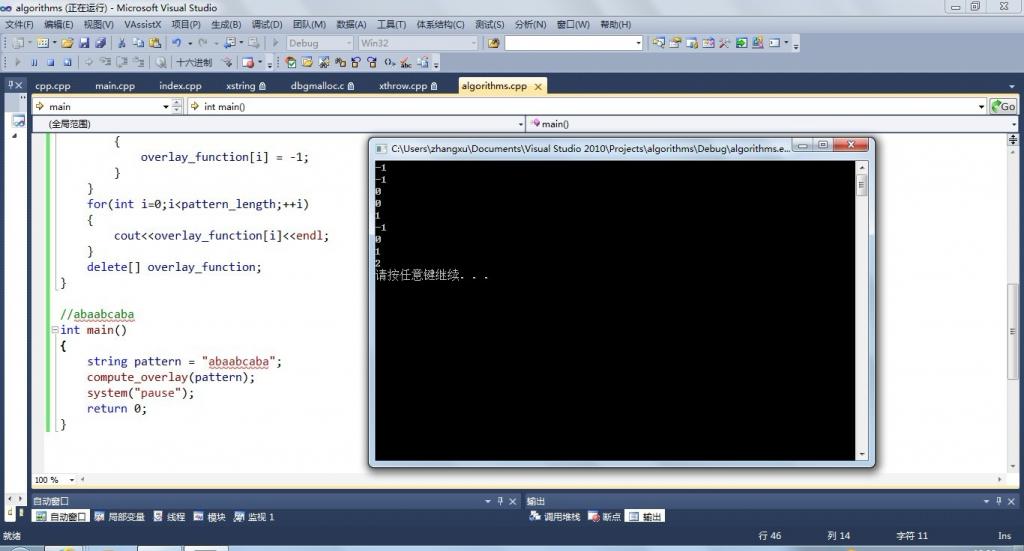
执行结果例如以下所看到的:
2.2、kmp算法
有了覆盖函数,那么实现kmp算法就是非常easy的了,我们的原则还是从左向右匹配,可是当失配发生时,我们不用把target_index向回移动,target_index前面已经匹配过的部分在pattern自身就能体现出来,仅仅要动pattern_index就能够了。
当发生在j长度失配时,仅仅要把pattern向右移动j-overlay(j)长度就能够了。
假设失配时pattern_index==0,相当于pattern第一个字符就不匹配,这时就应该把target_index加1,向右移动1位就能够了。
ok,下图就是KMP算法的过程(红色即是採用KMP算法的运行过程):
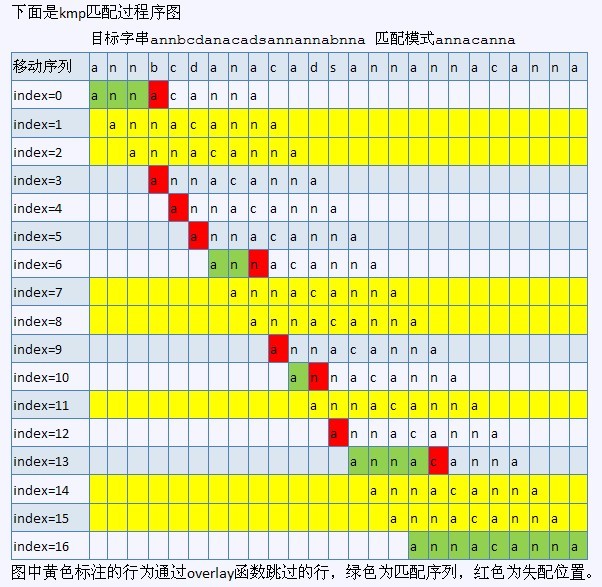
(还有一作者saturnman发现,在上述KMP匹配过程图中,index=8和index=11处画错了。还有,anaven也早已发现,index=3处也画错了。很感谢。但图已无法改动,见谅)
KMP 算法可在O(n+m)时间内完毕所有的串的模式匹配工作。”
OK,以下此前写的关于KMP算法的第一篇文章中的源代码:
- //copyright@ saturnman
- //updated@ 2011 July
- #include "stdafx.h"
- #include<iostream>
- #include<string>
- #include <vector>
- using namespace std;
- int kmp_find(const string& target,const string& pattern)
- {
- const int target_length=target.size();
- const int pattern_length=pattern.size();
- int* overlay_value=new int[pattern_length];
- overlay_value[0]=-1; //remember:next array's first number was -1.
- int index=0;
- //next array
- for (int i=1;i<pattern_length;++i)
- //注,此处的i是从1開始的
- {
- index=overlay_value[i-1];
- while (index>=0 && pattern[index+1]!=pattern[i]) //remember:!=
- {
- index=overlay_value[index];
- }
- if(pattern[index+1] == pattern[i])
- {
- overlay_value[i]=index+1;
- }
- else
- {
- overlay_value[i]=-1;
- }
- }
- //mach algorithm start
- int pattern_index=0;
- int target_index=0;
- while (pattern_index<pattern_length && target_index<target_length)
- {
- if (target[target_index] == pattern[pattern_index])
- {
- ++target_index;
- ++pattern_index;
- }
- else if(pattern_index==0)
- {
- ++target_index;
- }
- else
- {
- pattern_index=overlay_value[pattern_index-1]+1;
- }
- }
- if (pattern_index==pattern_length)
- {
- return target_index-pattern_index;
- }
- else
- {
- return -1;
- }
- delete [] overlay_value;
- }
- int main()
- {
- string sourc="ababc";
- string pattern="abc";
- cout<<kmp_find(sourc,pattern)<<endl;
- system("pause");
- return 0;
- }
因为是abc跟ababc匹配,那么将返回匹配的位置“2”,执行结果如所看到的:
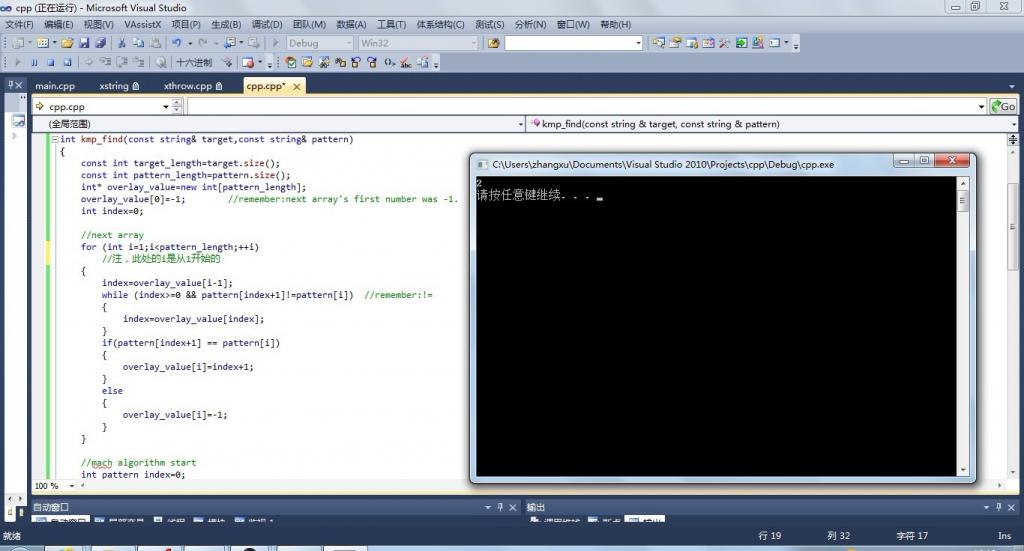
第四部分、測试
针对上文中第三部分的两段代码測试了下,纠结了,两种求next数组的方法对同一个字符串求next数组各值,得到的结果居然不一样,例如以下二图所看到的:
1、两种方法对字符串abab求next数组各值比較: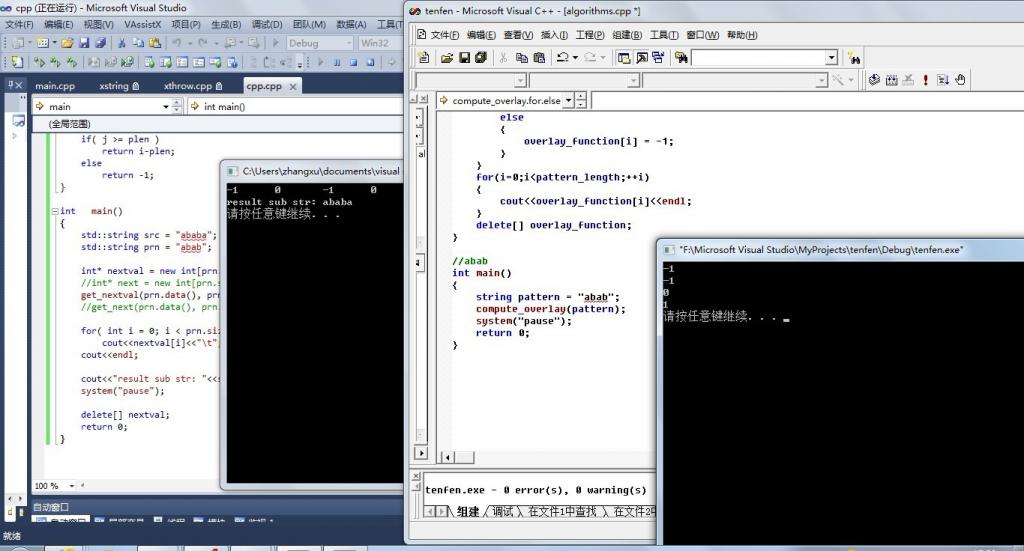
2、两种对字符串abaabcaba求next数组各值比較: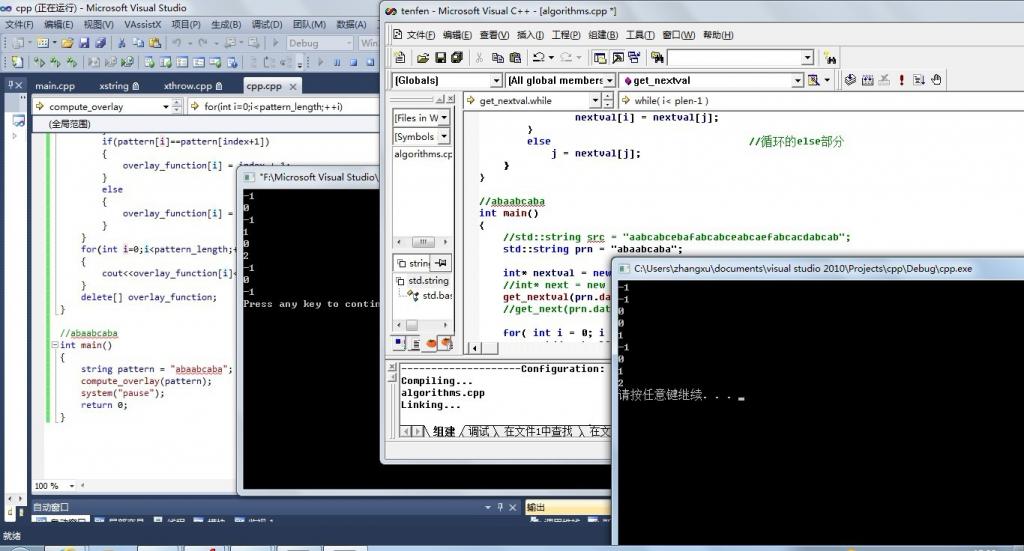
为何会这样呢,事实上非常easy,上文中已经有所说明了,代码实现一的i 是从0開始的,代码实现二的i 是从1開始的。但从终于的执行结果来看,临时还是以代码实现段二为准。
第五部分、KMP完整准确源代码
求next数组各值的方法为:
- //copyright@ staurman
- //updated@2011 July
- #include "StdAfx.h"
- #include<iostream>
- #include<string>
- using namespace std;
- //solve to the next array
- void compute_overlay(const string& pattern)
- {
- const int pattern_length = pattern.size();
- int *overlay_function = new int[pattern_length];
- int index;
- overlay_function[0] = -1;
- for(int i=1;i<pattern_length;++i)
- {
- index = overlay_function[i-1];
- //store previous fail position k to index;
- while(index>=0 && pattern[i]!=pattern[index+1])
- {
- index = overlay_function[index];
- }
- if(pattern[i]==pattern[index+1])
- {
- overlay_function[i] = index + 1;
- }
- else
- {
- overlay_function[i] = -1;
- }
- }
- for(int i=0;i<pattern_length;++i)
- {
- cout<<overlay_function[i]<<endl;
- }
- delete[] overlay_function;
- }
- //abaabcaba
- int main()
- {
- string pattern = "abaabcaba";
- compute_overlay(pattern);
- system("pause");
- return 0;
- }
执行结果入下图所看到的:abab的next数组各值是-1,-1,0,1,而非本文第二部分所述的-1,0,-1,0。为什么呢?难道是搬石头砸了自己的脚?
NO,上文第四部分末已经具体说明,上处代码i 从0開始,本文第二部分代码i 从1開始。
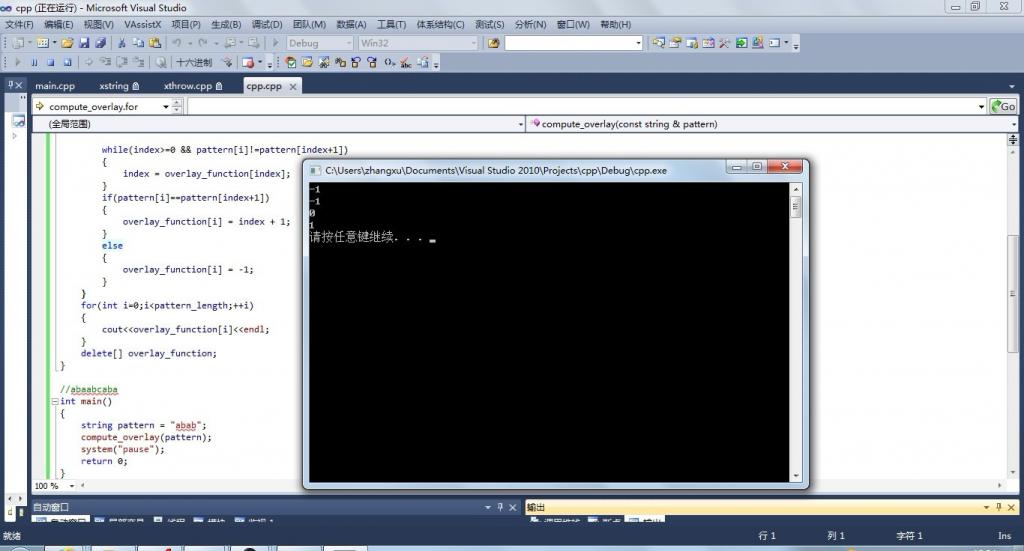
KMP算法完整源代码,例如以下:
- //copyright@ saturnman
- //updated@ 2011 July
- #include "stdafx.h"
- #include<iostream>
- #include<string>
- #include <vector>
- using namespace std;
- int kmp_find(const string& target,const string& pattern)
- {
- const int target_length=target.size();
- const int pattern_length=pattern.size();
- int* overlay_value=new int[pattern_length];
- overlay_value[0]=-1; //remember:next array's first number was -1.
- int index=0;
- //next array
- for (int i=1;i<pattern_length;++i)
- //注,此处的i是从1開始的
- {
- index=overlay_value[i-1];
- while (index>=0 && pattern[index+1]!=pattern[i])
- {
- index=overlay_value[index];
- }
- if(pattern[index+1] == pattern[i])
- {
- overlay_value[i]=index+1;
- }
- else
- {
- overlay_value[i]=-1;
- }
- }
- //mach algorithm start
- int pattern_index=0;
- int target_index=0;
- while (pattern_index<pattern_length && target_index<target_length)
- {
- if (target[target_index] == pattern[pattern_index])
- {
- ++target_index;
- ++pattern_index;
- }
- else if(pattern_index==0)
- {
- ++target_index;
- }
- else
- {
- pattern_index=overlay_value[pattern_index-1]+1;
- }
- }
- if (pattern_index==pattern_length)
- {
- return target_index-pattern_index;
- }
- else
- {
- return -1;
- }
- delete [] overlay_value;
- }
- int main()
- {
- string sourc="ababc";
- string pattern="abc";
- cout<<kmp_find(sourc,pattern)<<endl;
- system("pause");
- return 0;
- }
执行结果例如以下:
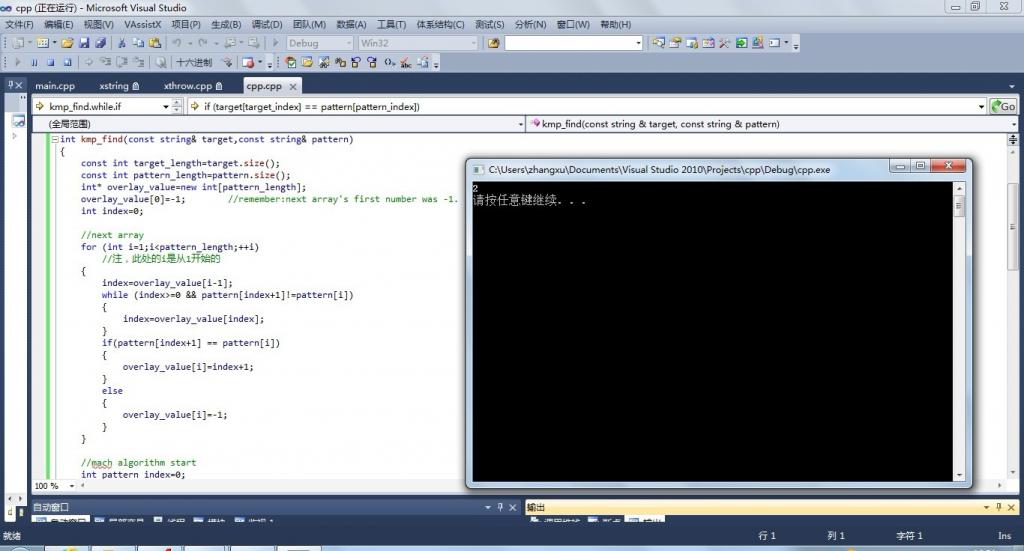
第六部分、一眼看出字符串的next数组各值
上文已经用程序求出了一个字符串的next数组各值,接下来,稍稍演示下,怎样一眼大致推断出next数组各值,以及初步推断某个程序求出的next数组各值是不是正确的。有一点务必注意:下文中的代码所有採代替码实现二,即i是从1開始的。
- 1、对字符串aba求next数组各值,各位能够先猜猜,-1,...,aba中,a初始化为-1,第二个字符b与a不同也为-1,最后一个字符和第一个字符都是a,所以,我猜其next数组各值应该是-1,-1,0,结果也不出所料,例如以下图所看到的:

- 2、字符串“abab”呢,不用猜了,我已经看出来了,当然上文中代码实现一和代码实现二都已经求出来了。假设i 是1開始的话,那么next数组各值将如代码实现二所执行的那样,将是:-1,-1,0,1;
- 3、字符串“abaabcaba”呢,next数组如上第三部分代码实现二所述,为-1,-1,0,0,1,-1,0,1,2;
- 4、字符串“abcdab”呢,next数组各值将是-1,-1,-1,-1,0,1;
- 5、字符串“abcdabc”呢,next数组各值将是-1,-1,-1,-1,0,1,2;
- 6、字符串“abcdabcd”呢,那么next数组各值将是-1,-1,-1,-1,0,1,2,3;

怎么样,看出规律来了没?呵呵,能够用上述第五部分中求next数组的方法自个多试探几次,相信,非常快,你也会跟我一样,不用计算,一眼便能看出某个字符串的next数组各值了。如此便恭喜你,理解了next数组的求法,KMP算法也就算是真真正正彻彻底底的理解了。完。
相关链接
- KMP之第二篇文章:六(续)、从KMP算法一步一步谈到BM算法。
- KMP之第一篇文章:六、教你初步了解KMP算法、updated。
后记
- 语言->数据结构->算法:语言是基础,够啃一辈子,主要的常见的数据结构得了如指掌,最后才是算法。除了算法之外,有很多其它更重要且更值得学习的东西(最重要的是,学习怎样编程)。切勿盲目跟风,找准自己的兴趣点,和领域才是关键。这跟选择职位、与领域并持久做下去,比选择公司更重要一样。选择学什么东西不重要,重要的是你的兴趣。
- 修订这篇文章之时,个人接触KMP都有一年了,学算法也刚好快一年。想想阿,我弄一个KMP,弄了近一年了,到今天才算是真正彻底理解其思想,可想而知,当初创造这个算法的k、m、p三人是何等不易。我想,有不少读者是由于我的出现而想学算法的,但不可急功近利,切勿妄想算法速成。早已说过,学算法先修心。
