
浅谈堆-Heap(一)
-
堆排序
排序我们都很熟悉,如冒泡排序、选择排序、希尔排序、归并排序、快速排序等,其实堆也可以用来排序,严格来说这里所说的堆是一种数据结构,排序只是它的应用场景之一
-
Top N的求解
-
优先队列
堆得另一个重要的应用场景就是优先队列
我们知道普通队列是:先进先出
而 优先队列:出队顺序和入队顺序无关;和优先级相关
实际生活中有很多优先队列的场景,如医院看病,急诊病人是最优先的,虽然这一类病人可能比普通病人到的晚,但是他们可能随时有生命危险,需要及时进行治疗. 再比如 操作系统要"同时"执行多个任务,实际上现代操作系统都会将CPU的执行周期划分成非常小的时间片段,每个时间片段只能执行一个任务,究竟要执行哪个任务,是有每个任务的优先级决定的.每个任务都有一个优先级.操作系统动态的每一次选择一个优先级最高的任务执行.要让操作系统动态的选择优先级最高的任务去执行,就需要维护一个优先队列,也就是说所有任务都会进入这个优先队列.
基本实现
首先堆是一颗二叉树,这个二叉树必须满足两个两条件
-
这个二叉树必须是一颗完全二叉树,所谓完全二叉树就是除了最后一层外,其他层的节点的个数必须是最大值,且最后一层的节点都必须集中在左侧.即最后一层从左往右数节点必须是紧挨着的,不能是中间空出一个,右边还有兄弟节点.
-
这个二叉树必须满足 左右子树的节点值必须小于或等于自身的值(大顶堆) 或者 左右子树的节点值必须大于或等于自身的值(小顶堆)
下图分别是一个大顶堆和小顶堆的示例

看到这两颗二叉树,我们首先就能定义出树节点的结构:
1 Class Node { 2 //节点本身的值 3 private Object value; 4 5 private Node left; 6 7 private Node right; 8 9 ....getter and setter 10 11 }
但是这里我们利用完全二叉树的性质用数组来构建这棵树.先从上到下,自左至右的来给树的每一个节点编上号.
以大顶堆为例
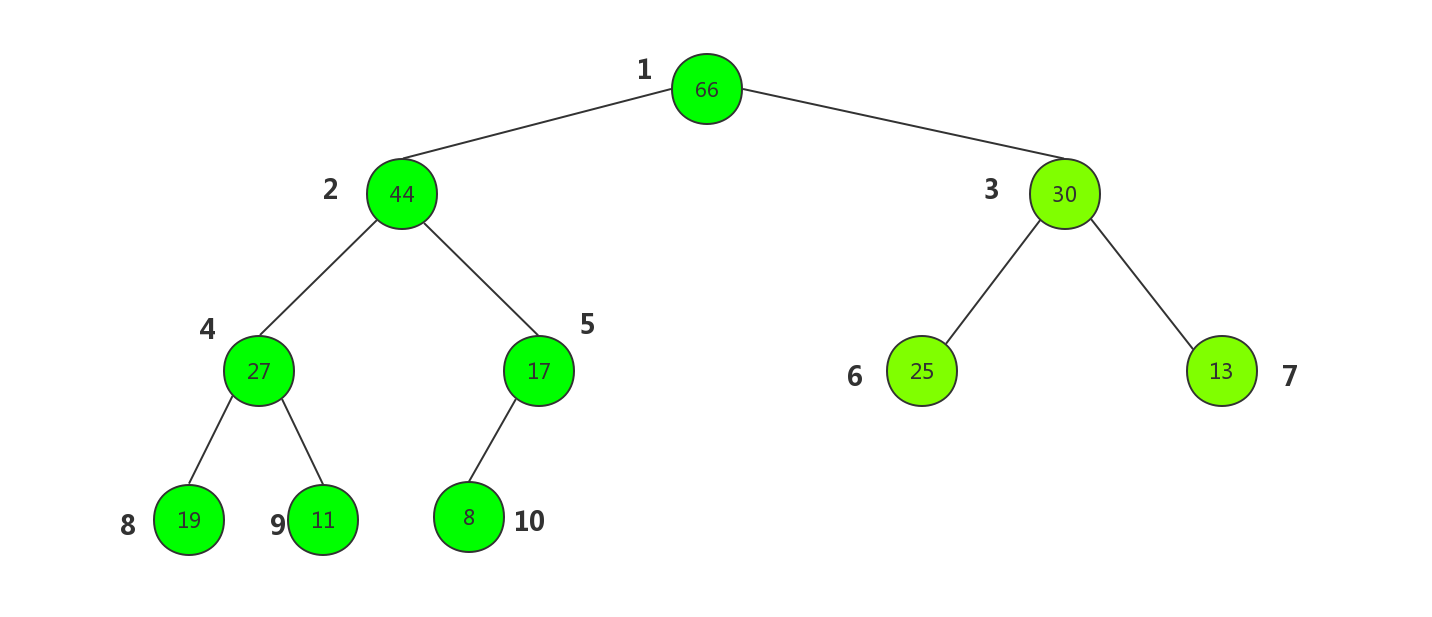
下面来用代码构建一个堆的骨骼


public class MaxHeap { /* * 堆中有多少元素 */ private int count; /* * 存放堆数据的数组 */ private Object[] data; public MaxHeap(int capacity) { /* * 因为序号是从1 开始的,我们不用下标是0的这个位置的数 */ this.data = new Object[capacity + 1]; } /** * 返回堆中有多少数据 * @return */ public int size() { return count; } /** * 堆是否还有元素 * @return */ public boolean isEmpty() { return count == 0; } }
骨骼是构建好了,乍一看堆中存放的数据是一个object类型的数据, 父子节点按节点值 无法比较,这里再调整一下
1 public class MaxHeap<T extends Comparable<T>> { 2 3 /* 4 * 堆中有多少元素 5 */ 6 private int count; 7 8 /* 9 * 存放堆数据的数组 10 */ 11 private Object[] data; 12 13 /** 14 * 堆的容量 15 */ 16 private int capacity; 17 18 /** 19 * @param clazz 堆里放的元素的类型 20 * @param capacity 堆的容量 21 */ 22 public MaxHeap(int capacity) { 23 /* 24 * 因为序号是从1 开始的,我们不用下标是0的这个位置的数 25 */ 26 this.data = new Object[capacity + 1]; 27 this.capacity = capacity; 28 } 29 30 /** 31 * 返回堆中有多少数据 32 * 33 * @return 34 */ 35 public int size() { 36 return count; 37 } 38 39 /** 40 * 堆是否还有元素 41 * 42 * @return 43 */ 44 public boolean isEmpty() { 45 return count == 0; 46 } 47 48 public Object[] getData() { 49 return data; 50 } 51 }
这样骨架算是相对完好了,下面实现向堆中添加数据的过程,首先我们先把上面的二叉树的形式按标号映射成数组的形式如图对比(已经说了0号下标暂时不用)

现在这个大顶堆被映射成数组,所以向堆中插入元素,相当于给数组添加元素,这里我们规定每新插入一个元素就插在当前数组最后面,也即数组最大标 + 1的位置处.对于一颗完全二叉树来说就是插在最后一层的靠左处,如果当前二叉树是一颗满二叉树,则新开辟一层,插在最后一层最左侧.但是这样插入有可能破坏堆的性质. 如插入节点45
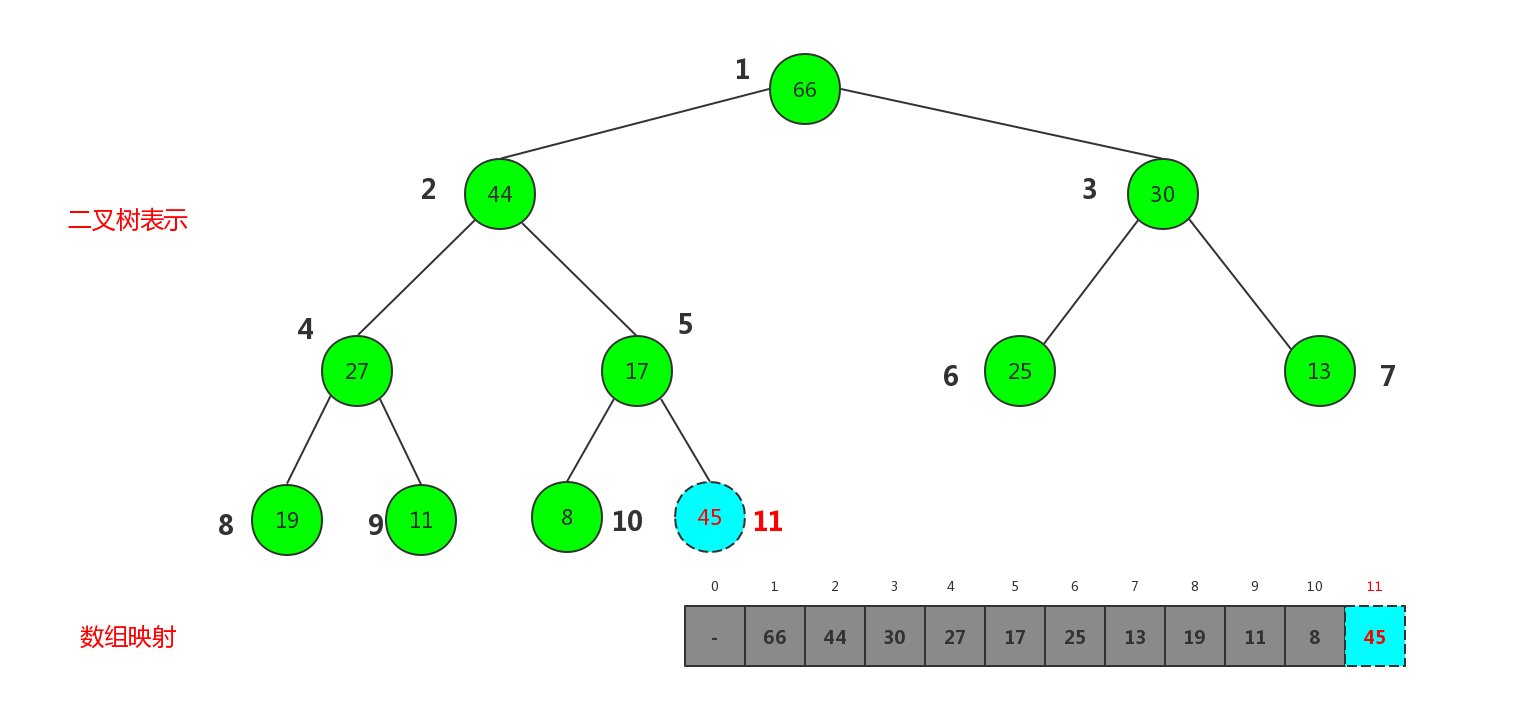
第一次交换:
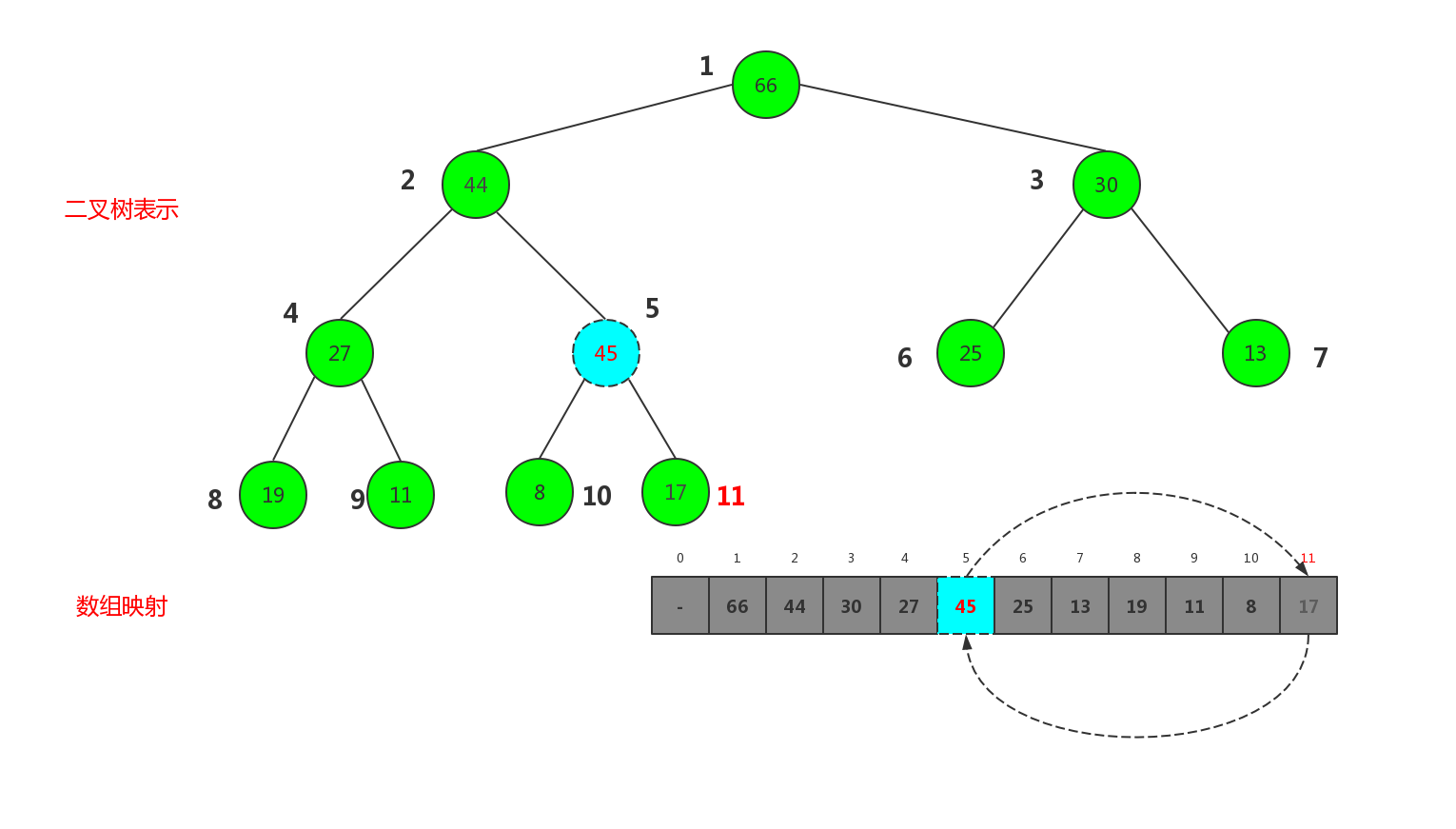
第二次交换:
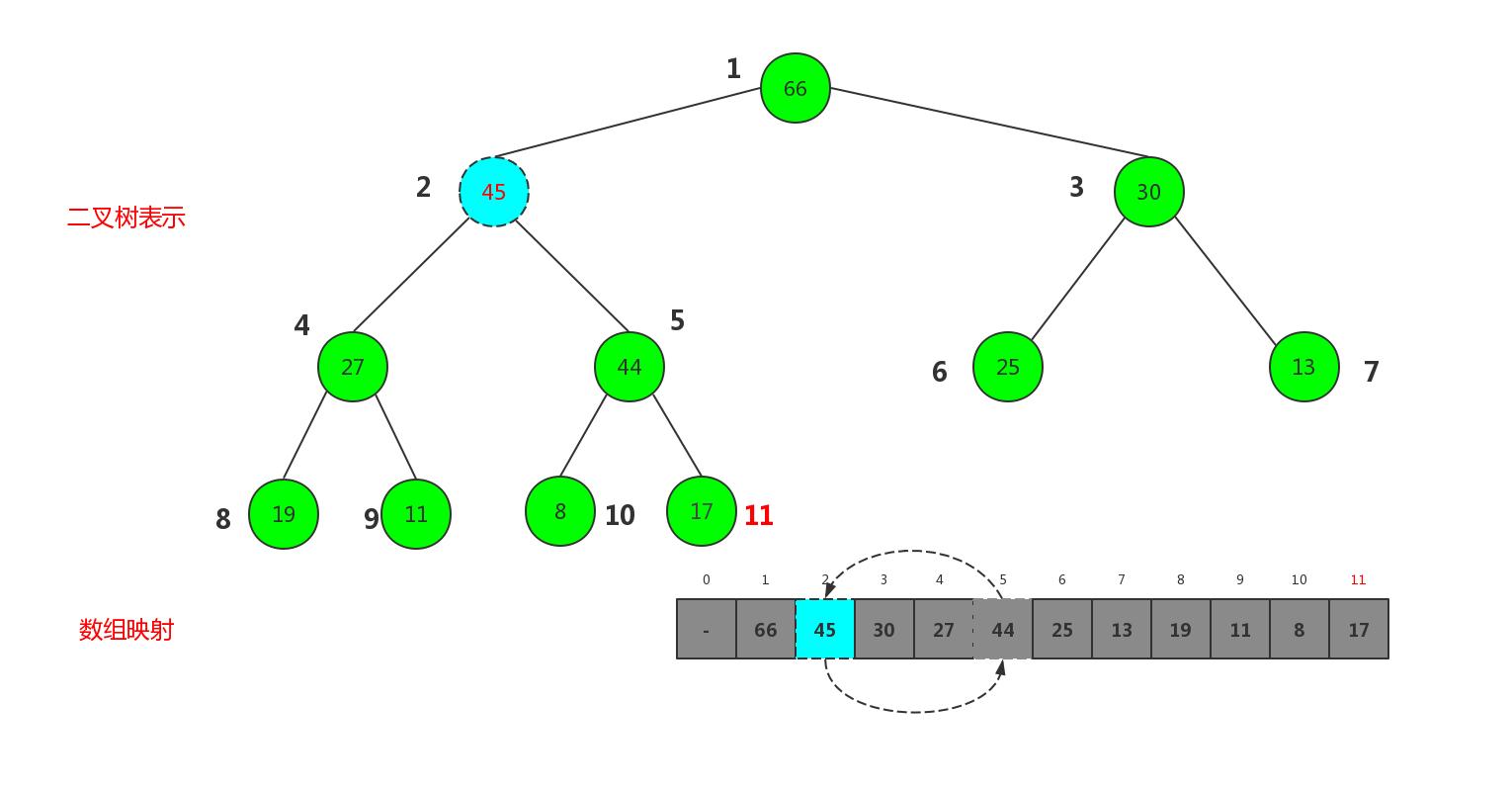
这里我们发现经过两次交换,已经满足了堆的性质,这样我们就完成了一次插入,这个过程,我们发现待插入的元素至底向顶依次向树根上升,我们给这个过程起个名叫shiftUp,用代码实现便是:
1 /** 2 * 插入元素t到堆中 3 * @param t 4 */ 5 public void insert(T t) { 6 //把这个元素插入到数组的尾部,这时堆的性质可能被破坏 7 data[count + 1] = t; 8 //插入一个元素,元素的个数增加1 9 count++; 10 //移动数据,进行shiftUp操作,修正堆 11 shiftUp(count); 12 13 } 14 15 private void shiftUp(int index) { 16 while (index > 1 && ((((T) data[index]). 17 compareTo((T) data[index >> 1]) > 0))) { 18 swap(index, index >>> 1); 19 index >>>= 1; 20 } 21 } 22 23 /** 24 * 这里使用引用交换,防止基本类型值传递 25 * @param index1 26 * @param index2 27 */ 28 private void swap(int index1, int index2) { 29 T tmp = (T) data[index1]; 30 data[index1] = data[index2]; 31 data[index2] = tmp; 32 }
这里有一个隐藏的问题,初始化我们指定了存放数据数组的大小,随着数据不断的添加,总会有数组越界的这一天.具体体现在以上代码 data[count + 1] = t 这一行
1 /** 2 * 插入元素t到堆中 3 * @param t 4 */ 5 public void insert(T t) { 6 //把这个元素插入到数组的尾部,这时堆的性质可能被破坏 7 data[count + 1] = t; //这一行会引发数组越界异常 8 //插入一个元素,元素的个数增加1 9 count++; 10 //移动数据,进行shiftUp操作,修正堆 11 shiftUp(count); 12 13 }
我们可以考虑在插入之前判断一下容量
1 /** 2 * 插入元素t到堆中 3 * @param t 4 */ 5 public void insert(T t) { 6 //插入的方法加入容量限制判断 7 if(count + 1 > capacity) 8 throw new IndexOutOfBoundsException("can't insert a new element..."); 9 //把这个元素插入到数组的尾部,这时堆的性质可能被破坏 10 data[count + 1] = t; //这一行会引发数组越界异常 11 //插入一个元素,元素的个数增加1 12 count++; 13 //移动数据,进行shiftUp操作,修正堆 14 shiftUp(count); 15 16 }
可能上面插入时我们看到有shiftUp这个操作,可能会想到从堆中删除元素是不是shiftDown这个操作. 没错就是shiftDown,只不过是删除堆中元素只能删除根节点元素,对于大顶堆也就是剔除最大的元素.下面我们用图说明一下.

删除掉根节点,那根节点的元素由谁来补呢. 简单,直接剁掉原来数组中最后一个元素,也就是大顶堆中最后一层最后一个元素,摘了补给根节点即可,相应的堆中元素的个数要减一
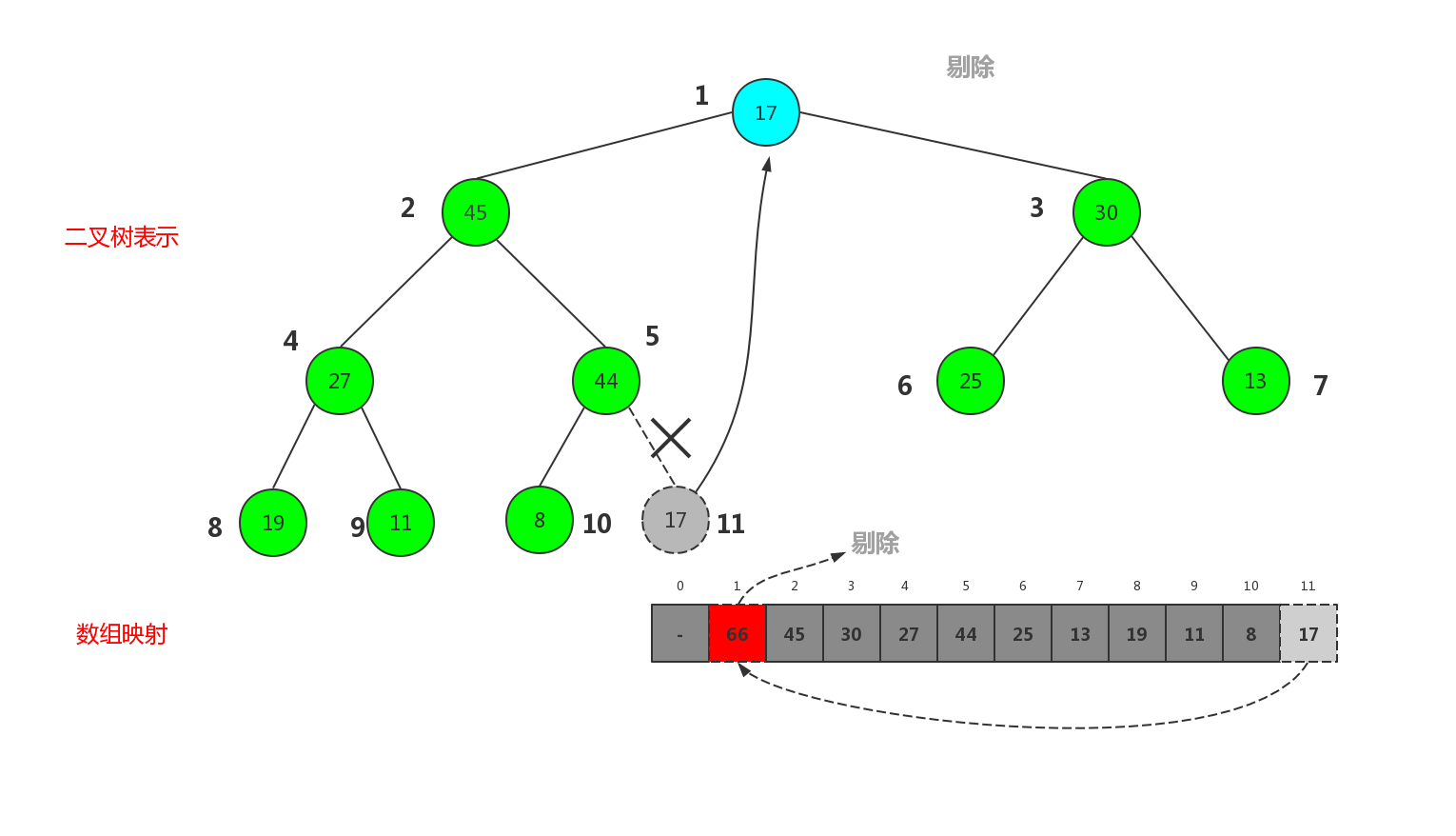
最终我们删除了大顶堆中最大的元素,也就是根节点,堆中序号最大的元素变成了根节点.
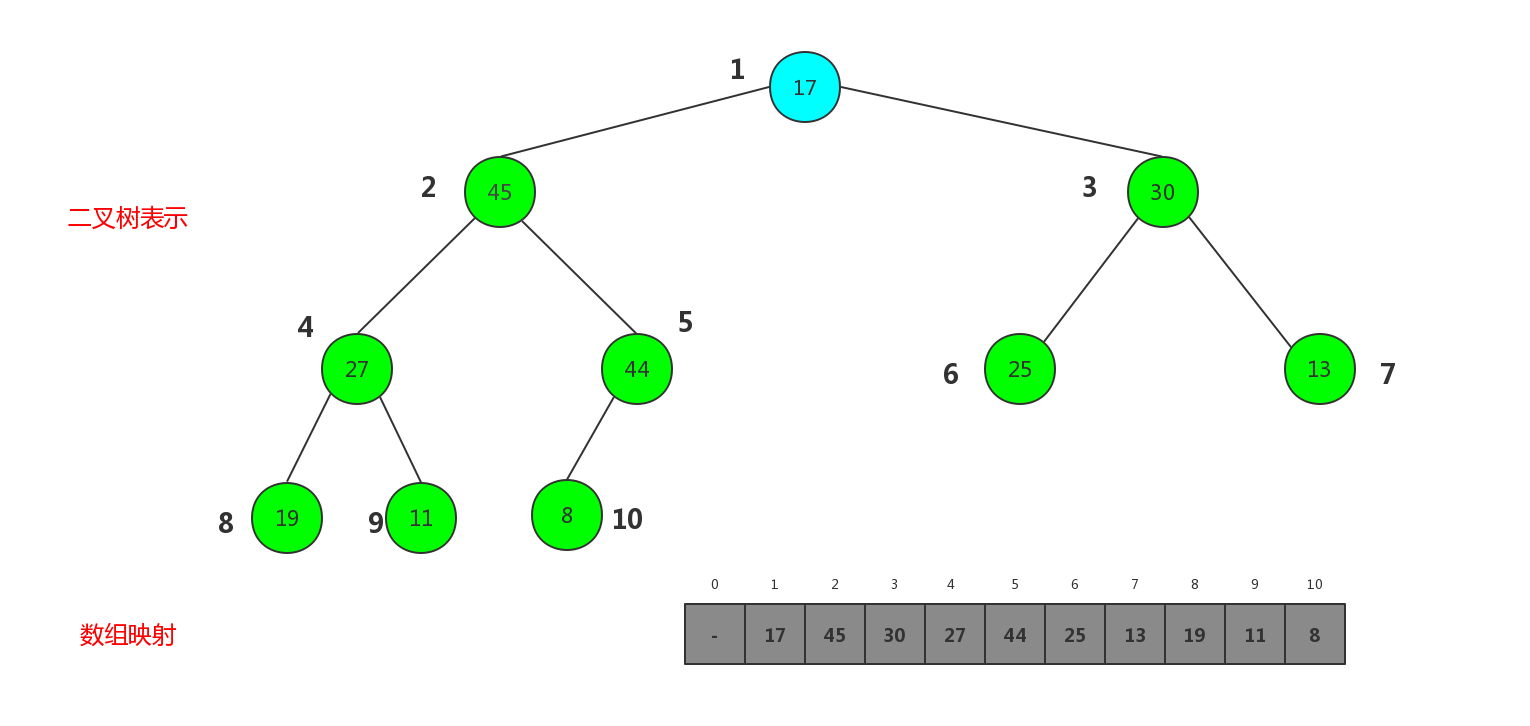
此时整个堆不满足大顶堆的性质,因为根节点17比其子节点小,这时,shiftDown就管用了,只需要把自身与子节点交换即可,可是子节点有两个,与哪个交换呢,如果和右子节点30交换,30变成父节点,比左子节点45小,还是不满足大顶堆的性质.所以应该依次与左子节点最大的那个交换,直至父节点比子节点大才可.所以剔除后新被替换的根节点依次下沉,所以这个过程被称为shiftDown,最终变成
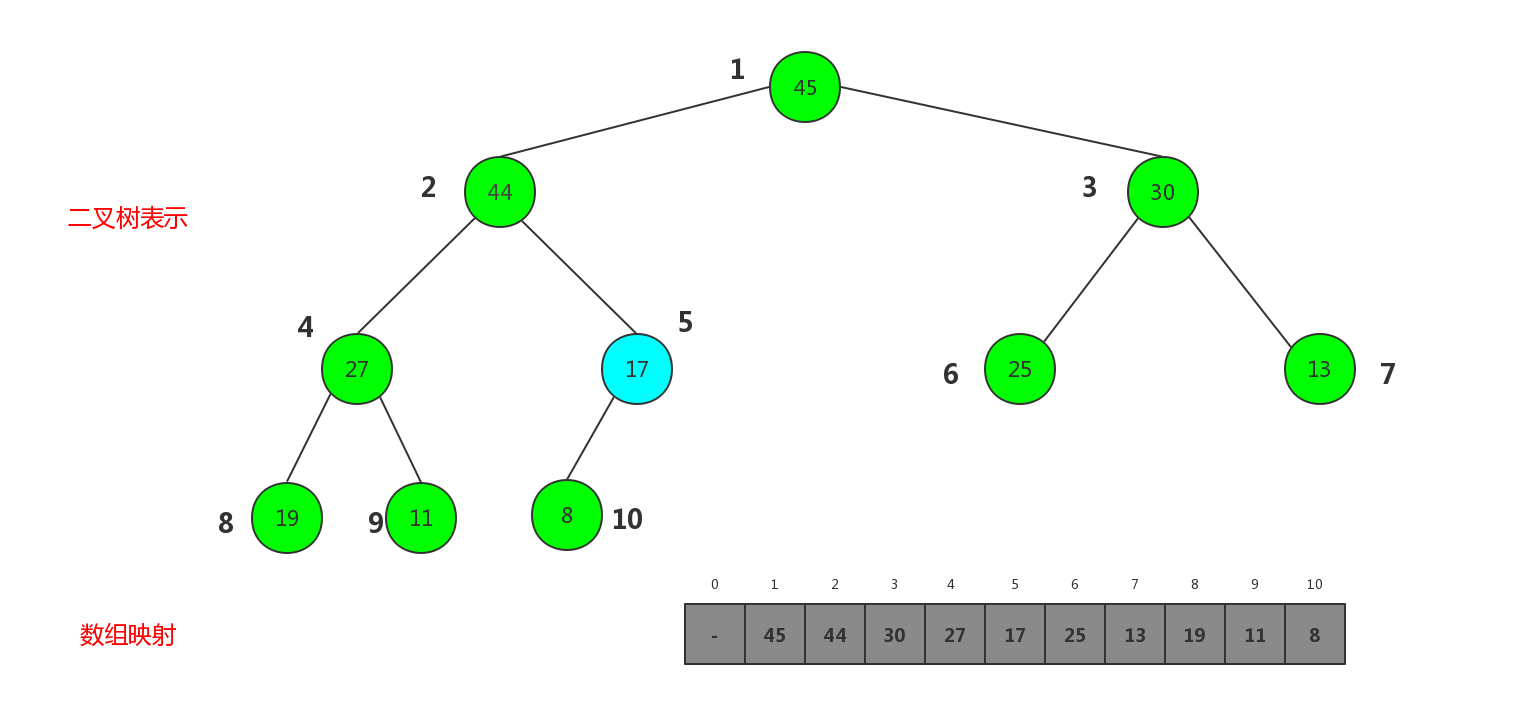
所以移除最大元素的方法实现:
1 /** 2 * 弹出最大的元素并返回 3 * 4 * @return 5 */ 6 public T popMax() { 7 if (count <= 0) 8 throw new IndexOutOfBoundsException("empty heap"); 9 T max = (T) data[1]; 10 //把最后一个元素补给根节点 11 swap(1, count); 12 //补完后元素个数减一 13 count--; 14 //下沉操作 15 shiftDown(1); 16 return max; 17 } 18 19 /** 20 * 下沉 21 * 22 * @param index 23 */ 24 private void shiftDown(int index) { 25 //只要这个index对应的节点有左子节点(完全二叉树中不存在 一个节点只有 右子节点没有左子节点) 26 while (count >= (index << 1)) { 27 //比较左右节点谁大,当前节点跟谁换位置 28 //左子节点的inedx 29 int left = index << 1; 30 //右子节点则是 31 int right = left + 1; 32 //如果右子节点存在,且右子节点比左子节点大,则当前节点与右子节点交换 33 if (right <= count) { 34 //有右子节点 35 if ((((T)data[left]).compareTo((T)data[right]) < 0)) { 36 //左子节点比右子节点小,且节点值比右子节点小 37 if (((T)data[index]).compareTo((T)data[right]) < 0) { 38 swap(index, right); 39 index = right; 40 } else 41 break; 42 43 } else { 44 //左子节点比右子节点大 45 if (((T)data[index]).compareTo((T)data[left]) < 0) { 46 swap(index, left); 47 index = left; 48 } else 49 break; 50 } 51 } else { 52 //右子节点不存在,只有左子节点 53 if (((T)data[index]).compareTo((T)data[left]) < 0) { 54 swap(index, left); 55 index = left; 56 } else 57 //index 的值大于左子节点,终止循环 58 break; 59 } 60 } 61 }
至此,大顶堆的插入和删除最大元素就都实现完了.来写个测试
1 public static void main(String[] args) { 2 MaxHeap<Integer> mh = new MaxHeap<Integer>(Integer.class, 12); 3 mh.insert(66); 4 mh.insert(44); 5 mh.insert(30); 6 mh.insert(27); 7 mh.insert(17); 8 mh.insert(25); 9 mh.insert(13); 10 mh.insert(19); 11 mh.insert(11); 12 mh.insert(8); 13 mh.insert(45); 14 Integer[] data = mh.getData(); 15 for (int i = 1 ; i <= mh.count ; i++ ) { 16 System.err.print(data[i] + " "); 17 } 18 mh.popMax(); 19 for (int i = 1 ; i <= mh.count ; i++ ) { 20 System.err.print(data[i] + " "); 21 } 22 }
思路: 上面我们不断的循环条件是这个index对应的节点有子节点.如果节点堆的性质破坏,最终是要用这个值与其左子节点或者右子节点的值交换,所以我们计算出了左子节点和右子节点的序号.其实不然,我们定义一个抽象的最终要和父节点交换的变量,这个变量可能是左子节点,也可能是右子节点,初始化成左子节点的序号,只有在其左子节点的值小于右子节点,且父节点的值也左子节点,父节点才可能与右子节点,这时让其这个交换的变量加1变成右子节点的序号即可,其他情况则要么和左子节点交换,要么不作交换,跳出循环,所以shiftDown简化成:
1 /** 2 * 下沉 3 * 4 * @param index 5 */ 6 private void shiftDown(int index) { 7 //只要这个index对应的节点有左子节点(完全二叉树中不存在 一个节点只有 右子节点没有左子节点) 8 while (count >= (index << 1)) { 9 //比较左右节点谁大,当前节点跟谁换位置 10 //左子节点的inedx 11 int left = index << 1; 12 //data[index]预交换的index的序号 13 int t = left; 14 //如果右子节点存在,且右子节点比左子节点大,则当前节点可能与右子节点交换 15 if (((t + 1) <= count) && (((T) data[t]).compareTo((T) data[t + 1]) < 0)) 16 t += 1; 17 //如果index序号节点比t序号的节点小,才交换,否则什么也不作, 退出循环 18 if (((T) data[index]).compareTo((T) data[t]) >= 0) 19 break; 20 swap(index, t); 21 index = t; 22 } 23 }
总结
-
首先复习了堆的应用场景,具体的应用场景代码实现留在下一篇.
-
引入堆的概念,性质和大顶堆,小顶堆的概念,实现了大顶堆的元素添加和弹出
-
根据堆的性质和弹出时下沉的规律,优化下沉方法代码.
-
下一篇优化堆的构建,用代码实现其应用场景,如排序, topN问题,优先队列等

 浙公网安备 33010602011771号
浙公网安备 33010602011771号