Hadoop hdfs api for Eclipse

x01、环境
系统:Centos
应用:hadoop2.6.5+Eclipse版本Kepler Service Release 1
0x2、配置jar包
/opt/modules/hadoop-2.6.5/share/hadoop/hdfs/hadoop-hdfs-2.6.5.jar
/opt/modules/hadoop-2.6.5/share/hadoop/hdfs/lib/*所有jar
/opt/modules/hadoop-2.6.5/share/hadoop/common/hadoop-common-2.6.5.jar
/opt/modules/hadoop-2.6.5/share/hadoop/common/lib/*所有jar
Eclipse下载链接:http://www.eclipse.org/downloads/eclipse-packages/?osType=linux&release=undefined
0x3、前言
HDFS设计的主要目的是对海量数据进行存储,也就是说在其上能够存储很大量文件(可以存储TB级的文件)。HDFS将这些文件分割之后,存储在不同的DataNode上, HDFS 提供了两种访问接口:Shell接口和Java API 接口,对HDFS里面的文件进行操作,具体每个Block放在哪台DataNode上面,对于开发者来说是透明的。

操作hdfs的API的一个流程:
1.如果要访问HDFS,HDFS客户端必须有一份HDFS的配置文件,也就是hdfs-site.xml,从而读取Namenode的信息。
2.每个应用程序也必须拥有访问Hadoop程序的jar文件。
3.操作HDFS,也就是HDFS的读和写,最常用的类FileSystem操作。
我们使用Eclipse Java API 接口
这里可以分为两种一种是windows下一种是linux下,我这里使用的是linux 方便一点不过windows下也差不多,只不过需要修改一些配置。
Eclipse下载完后解压即可用,不用安装啦。
我们把0x2需要的jar包导入进来。
大家看图,我就不多BB了。
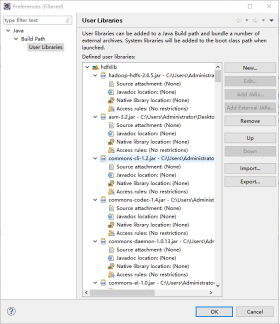
新建一个名字我这里就叫hdfslib
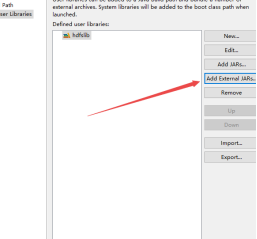
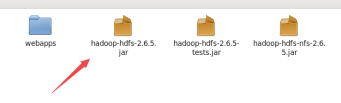
记住还有common和lib。

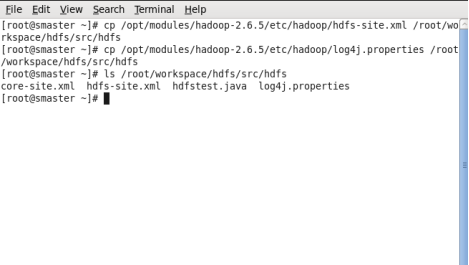
然后我们把hdfs-site.xml、log4j.proerties、core-site.xml三个文件分别拷贝到ecplipse的工作目录src/main里头。
启动hadoop
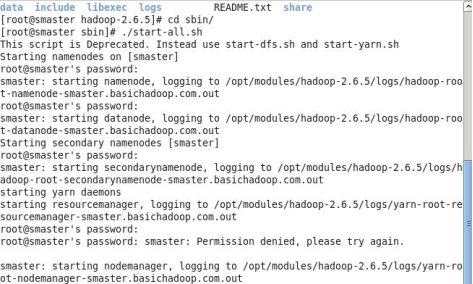
JPS查看一下(这里给大家普及一个小知识,为了从根本上解决旧的MapReduce框架的性能瓶颈,促进Hadoop框架的更长远发展,从0.23.0版本开始,Hadoop的MapReduce框架完全重构,叫做MapReduceV2或者Yarn。基本思想就是将JobTracker两个主要的功能分分离成单独的组件,这两个功能是资源管理和任务调度/监控。新的资源管理器全局管理所有应用程序计算资源的分配。每一个应用的ApplicationMaster负责相应的调度和协调。一个应用程序无非是一个单独的传统的MapReduce任务或者是一个DAG(有向无环图)任务。ResourceManager和每一台机器的阶段管理服务器能够管理用户在哪台机器上的进程并能对计算进行组织。
简单说就是把每JobTracker替换掉了,换了ResourceManager和NedoManager协同工作运行和监控任务。)
如图看到的:
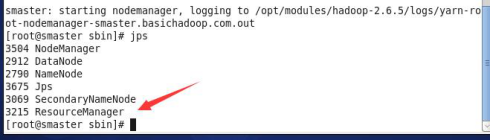
配置完后我们直接打开新建一个项目和类,写个简单的来测试一下。
package hdfs;
import org.apache.hadoop.conf.Configuration;//
public class hdfstest {
public static void main(String[] args){
Configuration conf=new Configuration();//该类的对象封转了客户端或者服务器的配置,初始化一个Configuration来,就是配置文件里头的那个Configuration。
conf.set("fs.defaultFS", "hdfs://smaster:8020"); //这里指向HDFS的地址和端口。
}
}
更详细的一点的介绍。
Configuration:该类的对象封转了客户端或者服务器的配置;
FileSystem:该类的对象是一个文件系统对象,可以用该对象的一些方法来对文件进行操作,通过FileSystem 静态方法 get 获得该对象。
FileSystem fs = FileSystem.get(conf)
get 方法从 conf 中的一个参数 fs.defaultFS 的配置值判断具体是什么类型的文件系统。
如果我们的代码中没有指定 fs.defaultFS,并且工程 classpath下也没有给定相应的配置,conf中的默认值就来自于hadoop的jar包中的core-default.xml ,默认值为file:/// ,则获取的将不是一个DistributedFileSystem 的实例,而是一个本地文件系统的客户端对象。
几乎Hadoop中关于文件操作类基本上全部是在"org.apache.hadoop.fs"包中,这些API能够支持的操作包含:打开文件;读写文件;删除文件等一些操作把这几个API理解透了能实现一般的需求了。
下面提供几个简单的代码栗子给大家入门的朋友理解:
/*
* 上传本地文件
*/
public class CopyFile {
public static void main(String[] args) throws Exception {
Configuration conf=new Configuration();
FileSystem hdfs=FileSystem.get(conf);
Path src =new Path("/");
Path dst =new Path("/");
hdfs.copyFromLocalFile(src, dst);
System.out.println("Upload to"+conf.get("fs.default.name"));
FileStatus files[]=hdfs.listStatus(dst);
for(FileStatus file:files){
System.out.println(file.getPath());
}
}
/*
* 创建HDFS文件
*/
public class CreateFile {
public static void main(String[] args) throws Exception {
Configuration conf=new Configuration();
FileSystem hdfs=FileSystem.get(conf);
byte[] buff="hello hadoop world!\n".getBytes();
Path dfs=new Path("/test");
FSDataOutputStream outputStream=hdfs.create(dfs);
outputStream.write(buff,0,buff.length);
}
}
/*
* 创建HDFS目录
*/
public class CreateDir {
public static void main(String[] args) throws Exception{
Configuration conf=new Configuration();
FileSystem hdfs=FileSystem.get(conf);
Path dfs=new Path("/TestDir");
hdfs.mkdirs(dfs);
}
}
/*
* 删除HDFS的文件
*/
public class DeleteFile {
public static void main(String[] args) throws Exception {
Configuration conf=new Configuration();
FileSystem hdfs=FileSystem.get(conf);
Path delef=new Path("/test1");
boolean isDeleted=hdfs.delete(delef,false);
//递归删除
//boolean isDeleted=hdfs.delete(delef,true);
System.out.println("Delete?"+isDeleted);
}
}
/*
* 获取HDFS目录下的所有文件
*/
public class ListAllFile {
public static void main(String[] args) throws Exception {
Configuration conf=new Configuration();
FileSystem hdfs=FileSystem.get(conf);
Path listf =new Path("/user/hadoop/test");
FileStatus stats[]=hdfs.listStatus(listf);
for(int i = 0; i < stats.length; ++i)
{
System.out.println(stats[i].getPath().toString());
}
hdfs.close();
}
}
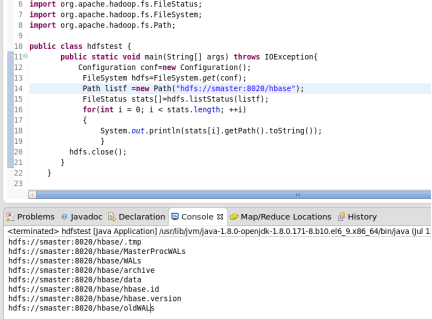
这几个栗子代码都很简单懂一些java基础的很快就能入门操作这些API做HDFS,没有基础的自己搭建环境敲两遍就入门了。
欢迎大家加入交流:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号