

Hadoop之MapReduce(一)简介及简单案例
简介
Hadoop MapReduce是一个分布式运算编程框架,基于该框架能够容易地编写应用程序,进而处理海量数据的计算。
MapReduce是一种编程模型,用于大规模数据集(大于1TB)的并行运算。概念"Map(映射)"和"Reduce(归约)",是它们的主要思想;Map 负责"分",即把复杂的任务分解为若干个"简单的任务"来并行处理。可以进行拆分的前提是这些小任务可以并行计算,彼此间几乎没有依赖关系。Reduce 负责"合",即对 map 阶段的结果进行全局汇总。
MapReduce的执行流程
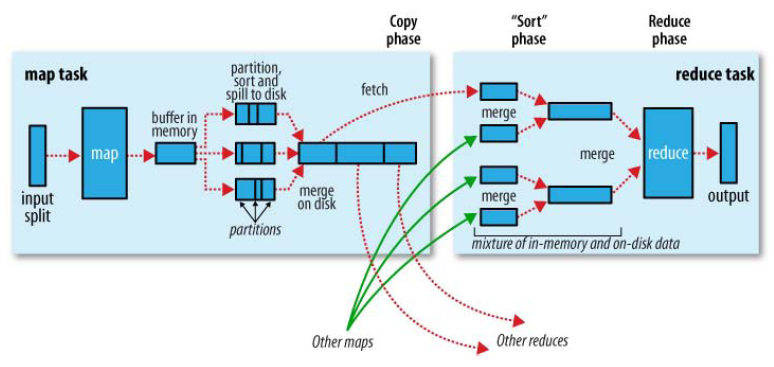
1,由默认读取数据组件TextInputFormat一行一行的读(input)
2,然后做相应的处理(由我们自己编写的Mapper程序做处理),最终context.write出<key,value>到内存缓冲区(图中的buffer in memory)
3,memory缓冲区默认100M,如果满了(或者到了末尾)则spill to disk(溢出到磁盘,最后merge(合并)),如果有分区或者排序的话,这里会分区且排序
4,由我们自己的程序控制一共有几个reduce,每个reduce会去磁盘上拉去属于自己的分区,进而执行我们自己编写的Reducer程序进行处理数据,最终context.write出<key,value>
5,由输出数据组件TextOutPutFomat输出到我们制定的位置(output)
简单示例
需求:在一堆给定的文本文件中统计输出每一个单词出现的总次数
首先,编写Mapper程序(需要继承org.apache.hadoop.mapreduce.Mapper并重写map方法):
package com.zy.hadoop.mr.wordcount; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; import java.io.IOException; /** * TODO 本类就是mr程序map阶段调用的类 也是就maptask * KEYIN :map输入kv中key * 在默认读取数据的组件下TextInputFormat(一行一行读) * key:表示是改行的起始偏移量(光标所在的偏移值) * value:表示的改行内容 * 用long来表示 * <p> * VALUEIN:map输入kv中的value * 在默认读取数据的组件下TextInputFormat(一行一行读) * 表明的是一行内容 所有是String * <p> * KEYOUT:map输出的kv中的key * 在我们的需求中 把单词做为输出的key 所以String * <p> * VALUEOUT:map输出kv中的value * 在我们的需求中 把单词的次数1做为输出的value 所以int * <p> * Long String是jdk自带的数据类型 * 在网络传输序列化中 hadoop认为其及其垃圾 效率不高 所以自己封装了一套 数据类型 包括自己的序列化机制(Writable) * Long----->LongWritable * String--->Text * int------>IntWritable * null----->nullWritable */ public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> { /** * @param key * @param value * @param context TODO 该方法就是map阶段具体业务逻辑实现的所在地方 * map方法调用次数 取决于TextInputFormat如何读数据 * TextInputFormat读取一行数据--->封装成<k,v>--->调用一次map方法 * <p> * hello tom hello alex hello--> <0,hello tom hello alex hello> * alex tom mac apple --> <24,alex tom mac apple> */ @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { //拿其中一行内容转成String String line = value.toString(); //按照分隔符分隔 String[] words = line.split(" "); //遍历数组 单词出现就标记1 for (String word : words) { //使用哦context把map处理完的结果写出去 context.write(new Text(word), new IntWritable(1)); //<hello,1> } } }
然后,编写Reducer类(需要继承org.apache.hadoop.mapreduce.Reducer并重写reduce方法):
package com.zy.hadoop.mr.wordcount; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; import java.io.IOException; /** * TODO 该类就是mr程序reduce阶段运行的类 也就是reducetask * KEYIN: reduce输入的kv中k 也就是map输出kv中的k 是单词 Text * <p> * VALUEIN:reduce输入的kv中v 也就是map输出kv中的v 是次数1 IntWritable * <p> * KEYOUT:reduce输出的kv中k 在本需求中 还是单词 Text * <p> * VALUEOUT:reduce输出的kv中v 在本需求中 是单词的总次数 IntWritable */ public class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable> { @Override protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { //定义一个变量 int count = 0; //遍历values 累计里面的值 for (IntWritable value : values) { count += value.get(); } //输出结果 context.write(key, new IntWritable(count)); } }
最后,编写执行类:
package com.zy.hadoop.mr.wordcount; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; /** * TODO 该类就是mr程序运行的主类 主要用于一些参数的指定拼接 任务的提交 * TODO 比如使用的是哪个mapper 哪个reducer 输入输出的kv是什么 待处理的数据在那 输出结果放哪 */ public class WordCountRunner { public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); //指定mr采用本地模式运行 本地测试用 conf.set("mapreduce.framework.name", "local"); //使用job构建本次mr程序 Job job = Job.getInstance(conf); //指定本次mr程序运行的主类 job.setJarByClass(WordCountRunner.class); //指定本次mr程序的mapper reducer job.setMapperClass(WordCountMapper.class); job.setReducerClass(WordCountReducer.class); //指定本次mr程序map阶段的输出类型 job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(IntWritable.class); //指定本次mr程序reduce阶段的输出类型 job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); //设置使用几个Reduce执行 job.setNumReduceTasks(2); //指定本次mr程序处理的数据目录 输出结果的目录 // FileInputFormat.setInputPaths(job, new Path("/wordcount/input")); // FileOutputFormat.setOutputPath(job, new Path("/wordcount/output")); //本地测试用 FileInputFormat.setInputPaths(job, new Path("D:\\wordcount\\input")); FileOutputFormat.setOutputPath(job, new Path("D:\\wordcount\\output"));//输出的文件夹不能提前创建 否则会报错 //提交本次mr的job //job.submit(); //提交任务 并且追踪打印job的执行情况 boolean b = job.waitForCompletion(true); System.exit(b ? 0 : -1); } }
如果需要将程序提交给YARN集群执行:
1,将程序打成jar包,上传到集群的任意一个节点上
2,用hadoop命令启动:hadoop xxxxx.jar

