数据分析基础笔记 - NumPy和pandas基础
一、NumPy和数组
-
NumPy:用来处理数值型数据
-
N维数组(ndarray)
-
基本概念
- 多维数组,相同类型数据的集合,即所有元素类型必须一致
- [2 3 4 7] 一维数组:与列表的区别在于,一维数组间数据用空格隔开,列表是用逗号
- [[...]] 二维数组:每个元素都是一个一维数组,每一行元素数量一致,行数代表一维数组数量,列数代表一维数组元素数量。直观地识别:最外层有几层括号就是几维
- 属性:
- ndarray.shape 数组形状,输出数组维度的元组,(n行, m列)
- ndarray.ndim 数组维数
- ndarray.size 数组中总的元素数量
- ndarray.dtype 数组元素的类型
-
a = np.array([[1, 2, 3],[4, 5, 6],[7,8,9]]) print(a.shape) print(a.ndim)
print(a.size) print(a.dtype)
-
创建N维数组
- 准备工作
- 安装:在终端中输入 pip install numpy
- 导入:import numpy as np , np为numpy的简写
- 创建数组:使用 np.array() 创建数组,其中任意序列型对象都可以作为参数传入
-
#创建一维数组 import numpy as np arr = np.array([1,2 ,3 ,4, 5]) print(arr)
-
#创建二维数组 import numpy as np arr = np.array([[1,2] ,[3 ,4], [5,6]]) print(arr)
- 创建数组时可以指定类型, a = np.array([[1, 2, 3],[4, 5, 6]], dtype=np.float32)
- 生成元素值为0和1的数组:
- 元素值为0 zero = np.zeros([3, 4])
- 元素值为1 one = np.ones([3, 4])
- 生成对角数组 eyes = np.eye(5, 5) ,这个可以简写为eyes = np.eye(5)
- 生成固定范围数组:
- np.linspace(起始值, 结束值, 步长/间隔)
- np.arange(起始值, 结束值, 步长)
- 准备工作
-
N维数组的计算
- 数组和数的计算:应用到数组的所有元素上面,如arr+2,则arr的每个元素都加2
- 相同形状数组的计算:对应位置上的相应元素进行运算
- 形状修改: a.reshape([n行, m列]) ,注意:在转换形状的时候,要注意数组的元素匹配,只是将形状进行了修改,但并没有将行列进行转换
- 转置操作: a.T
- 数组去重:np.unique(arr)
- 练习:创建一个 3x3 并且值从0到8的矩阵
-
arr = np.arange(9).reshape(3,3) print(arr)
-
统计函数:
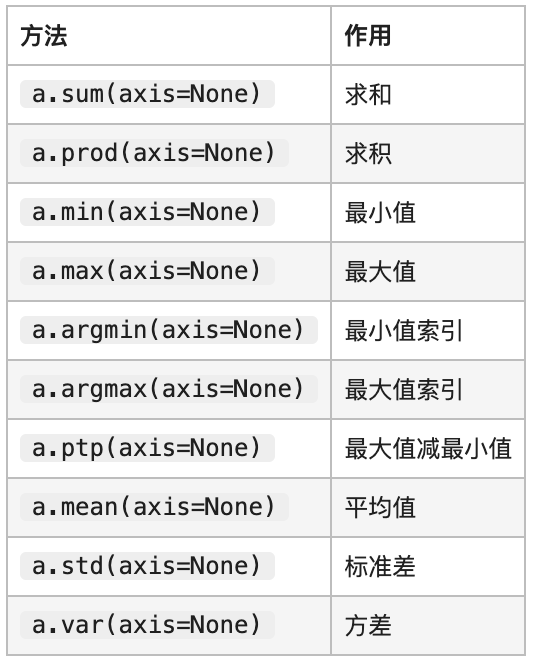
-
练习:创建一个长度为30的随机向量并找到它的平均值
-
import numpy as np Z = np.random.random(30) m = Z.mean() print(m):
-
IO 操作
- np.loadtxt('out.txt')保存文件savetxt 可以将数组写入文件,默认使用科学计数法的形式保存,例如:np.savetxt('out.txt', data)
- 读取文件
-
-
-
Pandas, Series
- 功能:数据的筛选清晰和处理,擅长处理二维数据
- 主要模块:Series,DataFrame
- 安装pandas: pip install pandas
- 导入: import pandas as pd
-
Series:
-
定义
- 序列,pandas模块的一种数据类型,一维带索引的数组对象
-
与字典的区别
- Series有顺序
- 除了通过index进行访问,还可以通过0,1,2这样的位置进行访问
- index可以定义,没有定义则默认从0开始
-
一个Series里的所有值,数据类型都是一样的
-
构造函数
- pd.Series()
- 第一个常用参数data:
- 表示需要传入的数据,如果不传入数据,生成空的Series
- 如果传入的是常量,必须提供索引,如:
s = pd.Series(6, index = ["a","b","c"."d"])
- 第二个常用参数index:定义索引,如果不传入参数,则索引默认从0开始
- 注意:两个传入的列表需要个数一致
- 例: info = pd.Series(GDP, index = city)
-
访问Series的数据的两种方式
- 位置索引访问:基于元素下标访问,如:info[0]
- 索引标签访问:和字典相同,如:info['JS']
-
三种常用属性
- dtype:访问Series对象的dtype属性。返回具体的数据类型,使用方法: info.dtype
- values:访问values,会以数组形式返回Series对象的值
- index:访问index,返回Series的索引
-
-
DataFrame
- 数据框:二维的矩阵数据表,是具有相同index的Series的集合,所以他同一列里的值的数据类型是相同的
-
构造函数
- pd.DataFrame(data, index = city)
- 第一个常用参数:data,如传入的是字典,那么字典中的keys,成为了列索引columns,字典中的values,成了值values
- 第二个常有参数:index,将列表赋值给参数index,如果不传入,就是从0开始
- 注意:在data传入的是列表时,需要在函数内使用参数columns,用于自定义列索引
-
import pandas as pd data = [["May",168],["Tony",178],["Kelvin",180]] rand = [1,2,3] result = pd.DataFrame(data, index = rank, columns = ["name", "score"])
-
属性
- dtypes:访问dtypes,返回每一列数据的数据类型
- values:访问values,以二维数组形式返回Series对象的值
- index:访问index,返回行索引,可以通过index获取index后对其赋值,改变index
- 轴(axis):用来为超过一维的数组定义属性
- 第0轴,垂直向下,即axis = 0
- 第1轴,水平向右,即axis = 1
-
文件读取
-
读取CSV文件
- 必选参数
- pd.read_csv() - 将CSV文件的路径传入函数中,可以得到对应的DataFrame格式的数据
- 导入后的索引(index和columns)默认从0开始,columns默认是原来数据的第一行
- 可选参数
- 防止乱码: encoding="utf-8"
- 指定index:index_col ,将列名作为字符串传入来指定index,例如:index_col="order_id"
- 防止乱码: encoding="utf-8"
- 读取指定列
- usecols - 将包含对应的columns的列表传入该参数,例如:usecols=["payment","items_count"]
- 添加columns
- header=None 表明原数据中没有columns
- names 是将包含columns的列表传入该参数,添加columns
- 例如:
header=None,names=["订单号","用户id","支付金额","商品价格","购买数量","支付时间"]
- 必选参数
-
保存CSV文件
-
to_csv() - 将指定路径作为参数传入
- 注意:如果指定路径的文件已经存在,会覆盖原有文件
- 可选参数:
- index=False 不会将行索引信息写入第一列
- encoding="utf-8-sig" 防止乱码
-
-
读取Excel文件
- 需要先安装xlrd模块 pip install xlrd==1.2.0
- 基本上所有操作都和处理csv文件一致,只需要将csv改为excel
- 特殊情况:因为excel有不同的tab,所以有要指定工作表的情况,使用 sheet_name ,例如: sheet_name="销售订单数据"
-
-
索引和数据筛选
-
列索引
-
访问一列
- data["columns"] ,其中columns就是列索引,最后获取到的是该列对应的Series
- 注意:对得到的数据作修改的话,得到的是新的Series,不会修改原有的。如要修改原有的,则需要再次访问并赋值。
-
访问多列
- data[["columns_1","columns_2",...]] ,其中"columns_1","columns_2"是列索引,最后获得的是对应的DataFrame
- data后面跟着两个中括号,其中外层中括号表示对变量data进行索引,内层中括号代表多列数据
- 注意:和访问一列数据一样,要修改原有的数据,要重新访问赋值
-
-
.loc 属性:按照index值访问行数据
-
访问行数据的格式
- .loc[index的值] 获取单独一行
- .loc[起点index的值:结束index的值] 获取连续几行的数据,注意,这个是左闭右闭
- .loc[[第一个index,第二个index,...]] 获取多行不连续的数据,传入的是index值组成的列表,所以注意,有两对方括号
-
访问某行某个数据的格式
- 有两个参数:index和columns,用逗号隔开
- .loc[index的值, columns的值] 获取单个元素
- .loc[index切片或列表, columns切片或列表] 获取多个元素,例如: data.loc[3515:3518, "payment":"items_count"]
-
根据行索引来确定行数据
-
未指定行索引:通过默认index值访问
-
指定行索引:通过指定index值访问
-
-
.iloc 属性:按照行位置访问行数据
-
格式
- .iloc[index的位置] ,例如:访问第四行,对应的整数索引,即index的位置是3,所以写成 .iloc[3]
- .iloc[index起点位置: index结束位置] ,获取连续几行的数据,使用切片进行访问,例如:访问第1-5行,index是0-4,写做 data.iloc[0:5] ,注意,这里是左闭右开
- .iloc[[index1的位置,index2的位置,...]] 访问多行不连续的数据,将索引值列表传入其中,例如:.iloc[[122,154,179]]
- .iloc[index的位子, columns的位置] 获取某个元素
- .iloc[index位置切片或列表, columns位置切片或列表] 获取多个元素
-
-
布尔索引
- 使用比较运算符,先将数据做比较处理,比如要获取data中价格大于0的数据data["price"]>0 ,这样会得到一个布尔型Series。如果想要保留结果为True对应的行数据,那么就要将表达式作为索引再传入DataFrame对象中data[data["price"]>0]
- 当遇到多个判断条件时,需要用到逻辑运算符与或非&,|,~ 来连接两个判断条件,注意:当有多个判断条件时,每一个判断条件都需要用小括号( )括起来,例如:data[(data["cutdown_price"]>0) & (data["post_fee"]>0)]
-
-
格式转换和时间类型
-
时间类型数据
-
三种形式:
-
具体的时间点 datetime 类型:需要导入模块,按照年、月、日、时、分、秒依次传入数字,至少需要传入年、月、日的参数
-
时间间隔 timedelta 类型,
-
时期 period 类型
-
-
字符转时间函数
-
批量将DataFrame中的数据,转为datetime类型,使用 pd.to_datetime() 函数
-
对于时间类型数据的处理需要先通过后缀.dt进行转化,再进行其他操作,例如: df["pay_time"].dt.year
-
-
时间转字符函数
-
使用 .dt.strftime("%Y-%m") 。将某一列时间类型数据,转换为字符串类型,并变成“年-月”的格式
-
只有在Series和DataFrame中,列索引筛选的数据进行格式转换时,才需要`.dt`
-
-
格式转换函数
-
astype() 参数是需要转化成为的数据类型,例如: df["b"] = df["b"].astype(float)
-
.astype(int)
-
浮点型数据,可以直接使用 .astype(int) 函数,使用后数据将只保留整数部分。
-
字符串数据,仅有当数据是整数数字时,才能使用 .astype(int) 函数,否则将会报错
-
-
.astype(float)
-
字符串数据,当数据是数字(整数,小数都可以)时,可以使用 .astype(float) 函数,否则将会报错。
- 整型数据,可以直接使用 .astype(float)函数,使用后数据将用0补充为一位小数。
-
-
-
-


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本