

学号 2017-2018-2 《密码与安全新技术》第六周作业
课程:《密码与安全新技术》
班级: 201792
姓名: 刘胜楠
学号:20179214
上课教师:谢四江
上课日期:2018年X月X日
必修/选修: 必修
学习内容
模式识别导论
概念:
模式识别(英语:Pattern Recognition),就是通过计算机用数学技术方法来研究模式的自动处理和判读。我们把环境与客体统称为“模式”。随着计算机技术的发展,人类有可能研究复杂的信息处理过程。信息处理过程的一个重要形式是生命体对环境及客体的识别。对人类来说,特别重要的是对光学信息(通过视觉器官来获得)和声学信息(通过听觉器官来获得)的识别。这是模式识别的两个重要方面。市场上可见到的代表性产品有光学字符识别、语音识别系统。


模式识别的主要方法
根据问题的描述方法
基于知识的模式识别方法:以专家系统为代表,根据人们已知的(从专家那里收集整理得到的)知识,整理出若干描述特征与类别间关系的准则,建立一定的计算机推理系统,再对未知样本决策其类别。
基于数据的模式识别方法:制定描述研究对象的描述特征,收集一定数量的已知样本作为训练集训练一个模式识别机器,再对未知样本预测其类别(主要研究内容)
研究进展
模式识别研究主要集中在两方面,一是研究生物体(包括人)是如何感知对象的,属于认识科学的范畴,二是在给定的任务下,如何用计算机实现模式识别的理论和方法。前者是生理学家、心理学家、生物学家和神经生理学家的研究内容,后者通过数学家、信息学专家和计算机科学工作者近几十年来的努力,已经取得了系统的研究成果。
模式识别
模式识别
应用计算机对一组事件或过程进行辨识和分类,所识别的事件或过程可以是文字、声音、图像等具体对象,也可以是状态、程度等抽象对象。这些对象与数字形式的信息相区别,称为模式信息。
模式识别所分类的类别数目由特定的识别问题决定。有时,开始时无法得知实际的类别数,需要识别系统反复观测被识别对象以后确定。
模式识别与统计学、心理学、语言学、 计算机科学 、生物学、控制论等都有关系。它与 人工智能 、 图像处理 的研究有交叉关系。例如自适应或自组织的模式识别系统包含了人工智能的学习机制;人工智能研究的景物理解、自然语言理解也包含模式识别问题。又如模式识别中的预处理和特征抽取环节应用图像处理的技术;图像处理中的图像分析也应用模式识别的技术。
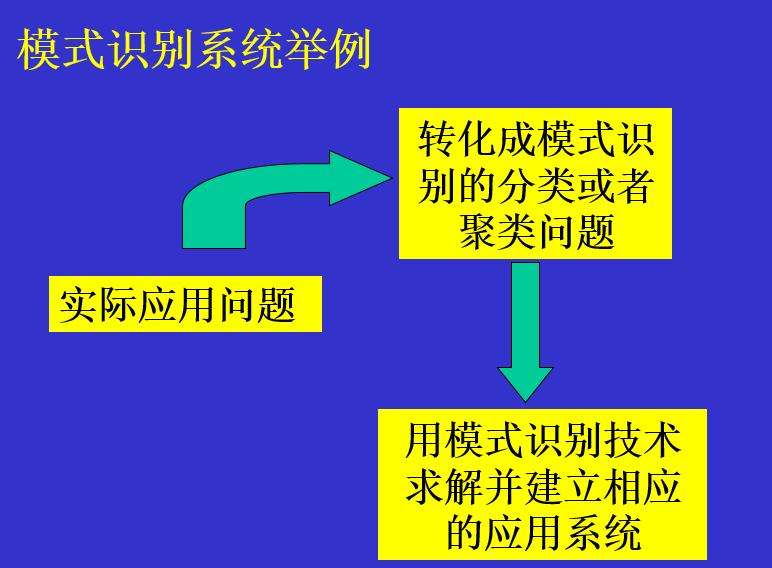

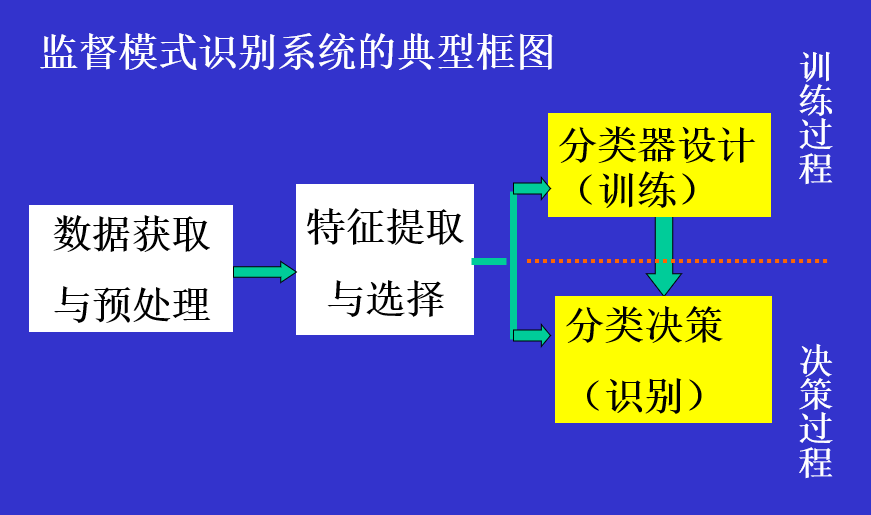
几种常见的算法
- K-Nearest Neighbor
简单来说,K-NN可以看成:有那么一堆你已经知道分类的数据,然后当一个新数据进入的时候,就开始跟训练数据里的每个点求距离,然后挑离这个训练数据最近的K个点看看这几个点属于什么类型,然后用少数服从多数的原则,给新数据归类。一个比较好的介绍k-NN的课件可以见下面链接,图文并茂,我当时一看就懂了
http://courses.cs.tamu.edu/rgutier/cs790_w02/l8.pdf
实际上K-NN本身的运算量是相当大的,因为数据的维数往往不止2维,而且训练数据库越大,所求的样本间距离就越多。就拿我们course project的人脸检测来说,输入向量的维数是1024维(32x32的图,当然我觉得这种方法比较silly),训练数据有上千个,所以每次求距离(这里用的是欧式距离,就是我们最常用的平方和开根号求距法) 这样每个点的归类都要花上上百万次的计算。所以现在比较常用的一种方法就是kd-tree。也就是把整个输入空间划分成很多很多小子区域,然后根据临近的原则把它们组织为树形结构。然后搜索最近K个点的时候就不用全盘比较而只要比较临近几个子区域的训练数据就行了。 - Bayes Classifier 贝叶斯方法一篇比较科普的中文介绍可以见pongba的平凡而神奇的贝叶斯方法: http://mindhacks.cn/2008/09/21/the-magical-bayesian-method/,实际实现一个贝叶斯分类器之后再回头看这篇文章,感觉就很不一样。
在模式识别的实际应用中,贝叶斯方法绝非就是post正比于prior*likelihood这个公式这么简单,一般而言我们都会用正态分布拟合likelihood来实现。
用正态分布拟合是什么意思呢?贝叶斯方法式子的右边有两个量,一个是prior先验概率,这个求起来很简单,就是一大堆数据中求某一类数据占的百分比就可以了,比如300个一堆的数据中A类数据占100个,那么A的先验概率就是1/3。第二个就是likelihood,likelihood可以这么理解:对于每一类的训练数据,我们都用一个multivariate正态分布来拟合它们(即通过求得某一分类训练数据的平均值和协方差矩阵来拟合出一个正态分布),然后当进入一个新的测试数据之后,就分别求取这个数据点在每个类别的正态分布中的大小,然后用这个值乘以原先的prior便是所要求得的后验概率post了。
贝叶斯公式中还有一个evidence,对于初学者来说,可能会一下没法理解为什么在实际运算中它不见了。实则上,evidence只是一个让最后post归一化的东西,而在模式分类中,我们只需要比较不同类别间post的大小,归一化反而增加了它的运算量。当然,在有的地方,这个evidence绝对不能省,比如后文提到的GMM中,需要用到EM迭代,这时候如果不用evidence将post归一化,后果就会很可怕。 - Principle Component Analysis
- Linear Discriminant Analysis
- Non-negative Matrix Factorization
统计模式识别
统计模式识别(statistical approach of pattern recognition)是一种基本的模式识别方法。模式识别是在某些一定量度或观测基础上把待识模式划分到各自的模式类中去。统计模式识别是对模式的统计分类方法,即结合统计概率论的贝叶斯决策系统进行模式识别的技术,又称为决策理论识别方法。
1.统计模式识别基本概念
特征(Feature)
特征是可以用来体现类别之间相互区别的某个或某些数学测度,测度的值称为特征值。
样本(Sample)
被分类或识别的模式个体称为样本,特征值必须由样本的原始数据计算得到。
特征空间(Feature Space)
由所有特征值为变量轴所形成的欧氏空间。
特征向量(Feature Vector)
以所有特征值为其分量的向量。
训练和学习
训练(Training)
对分类器或分类器设计提供一批类别已知的样本(统计学概念),使之可以确定适当的待分类别、待分类别个数、分类决策规则,以及估算错误分类的概率,从而形成可以对未知样本进行分类的分类器。这些类别已知的样本称为训练样本,否则称为未知样本或待分类样本(即识别对象)。
学习(Learning)
学习过程就是指训练过程,但两者的含义和出发点有所不同。训练是被动的,学习是主动的。
学习与感悟
学习哪种模型:针对具体问题选取切实可行的模型与方案
以下列举了各类学习问题中基本的模型,实际应用中的模型多是在这些基本模型上针对具体的业务要求进行了改进。
标注问题的基本模型包括:隐马尔可夫、条件随机场。
回归问题:神经网络、决策回归树、Logistic回归、以及普通的线性回归模型
b) 半监督问题包括1、自我训练模型:首先使用有类标记的数据进行模型的训练,使用模型对未标记的数据进行标记,选取最有把握的标记的样本加入到训练集合中并再次使用训练集合对模型进行训练,用新的模型对未标记的样本进行标记……如此反复。2、协同训练模型:包含多个子模型,每个子模型对已标记的数据进行学习,使用模型对未标记的数据进行标记并将最有把握的标记加入到已标记的数据集中,新的已标号数据集训练另外一个模型,再次对未标记的数据进行标记,供其他模型学习。在该模式下,一个模型是另外一个模型的老师,多个模型互教互学,故有协同训练这一名称了。
c) 非监督学习问题:其中包括聚类模型和关联分析模型。在关联分析问题中,常见的为频繁模型挖掘(发现数据集中频繁出现的子结构)、关联规则挖掘(购物车商品分析中常使用)。聚类问题中主要从四个方面进行聚类挖掘(1)、基于划分的聚类模型:K均值、K中心点,原理主要是基于属性的相似性进行划分(2)基于层次的聚类模型:主要为凝聚聚类及该方法的逆过程(分裂划分),该方法主要用于形成族群的聚类与划分。(3)基于密度的方法:上述(1)(2)方法的缺点主要是在聚类时难于发现具有任意形状的结构,基于密度的方法则可以克服这一缺点,利用高密度联通区域来识别聚类结构(在图像处理OCR识别中可用于对字符图像进行预处理操作)。(4)基于网格的方法。
a) 监督学习的分类问题使用的生成模型(朴素贝叶斯、神经网络),判别模型(K近邻、感知机、决策树、Logistic回归、SVM、boost等)。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号