字符编码、文件的操作模式介绍
 学习内容总结
学习内容总结
今日内容总结
字符编码的历史与应用
字符编码的由来
很久很久以前,有一群人,他们决定用8个可以开合的晶体管来组合成不同的状态,以表示世界上的万物。他们看到8个开关状态是好的,于是他们把这称为"字节"。再后来,他们又做了一些可以处理这些字节的机器,机器开动了,可以用字节来组合出很多状态,状态开始变来变去。他们看到这样是好的,于是它们就这机器称为"计算机"。开始计算机只在美国用。因此,最早只有127个字符被编码到计算机里,也就是大小写英文字母、数字和一些符号,这个编码表被称为ASCII编码,比如大写字母A的编码是65,小写字母z的编码是122。
后来,世界各地的都开始使用计算机,但是很多国家用的不是英文,他们的字母里有许多是ASCII里没有的,为了可以在计算机保存他们的文字,他们决定采用127号之后的空位来表示这些新的字母、符号,还加入了很多画表格时需要用下到的横线、竖线、交叉等形状,一直把序号编到了最后一个状态255。从128到255这一页的字符集被称"扩展字符集"。
等中国人们得到计算机时,已经没有可以利用的字节状态来表示汉字,况且有6000多个常用汉字需要保存呢。但是这难不倒智慧的中国人民,我们不客气地把那些127号之后的奇异符号们直接取消掉,规定:一个小于127的字符的意义与原来相同,但两个大于127的字符连在一起时,就表示一个汉字,前面的一个字节(他称之为高字节)从0xA1用到 0xF7,后面一个字节(低字节)从0xA1到0xFE,这样我们就可以组合出大约7000多个简体汉字了。在这些编码里,我们还把数学符号、罗马希腊的 字母、日文的假名们都编进去了,连在 ASCII 里本来就有的数字、标点、字母都统统重新编了两个字节长的编码,这就是常说的"全角"字符,而原来在127号以下的那些就叫"半角"字符了。后来还是不够用,于是干脆不再要求低字节一定是127号之后的内码,只要第一个字节是大于127就固定表示这是一个汉字的开始,不管后面跟的是不是扩展字符集里的内容。结果扩展之后的编码方案被称为 GBK 标准,GBK 包括了 GB2312 的所有内容,同时又增加了近20000个新的汉字(包括繁体字)和符号。

你可以想得到的是,全世界有上百种语言,日本把日文编到Shift_JIS里,韩国把韩文编到Euc-kr里,各国有各国的标准,就会不可避免地出现冲突,结果就是,在多语言混合的文本中,显示出来会有乱码。因此,Unicode字符集应运而生。Unicode把所有语言都统一到一套编码里,这样就不会再有乱码问题了。
新的问题又出现了:如果统一成Unicode编码,乱码问题从此消失了。但是,如果你写的文本基本上全部是英文的话,用Unicode编码比ASCII编码需要多一倍的存储空间,在存储和传输上就十分不划算。所以,本着节约的精神,又出现了把Unicode编码转化为“可变长编码”的UTF-8编码。UTF-8编码把一个Unicode字符根据不同的数字大小编码成1-6个字节,常用的英文字母被编码成1个字节,汉字通常是3个字节,只有很生僻的字符才会被编码成4-6个字节。如果你要传输的文本包含大量英文字符,用UTF-8编码就能节省空间:
| 字符 | ASCII | Unicode | UTF-8 |
|---|---|---|---|
| A | 01000001 | 00000000 01000001 | 01000001 |
| 中 | x | 01001110 00101101 | 11100100 10111000 10101101 |
从上面的表格还可以发现,UTF-8编码有一个额外的好处,就是ASCII编码实际上可以被看成是UTF-8编码的一部分,所以,大量只支持ASCII编码的历史遗留软件可以在UTF-8编码下继续工作。搞清楚了ASCII、Unicode和UTF-8的关系,我们就可以总结一下现在计算机系统通用的字符编码工作方式:
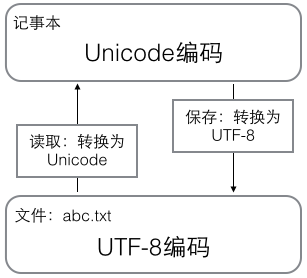
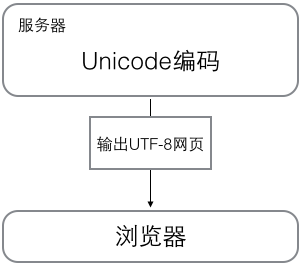
浏览网页的时候,服务器会把动态生成的Unicode内容转换为UTF-8再传输到浏览器:
字符编码的应用
编码与解码:
编码就是将人能看懂的字符编码成计算机能够直接读懂的字符。
解码就是将计算机能够直接看懂的字符解码成人能看懂的字符。代码示例:
a = '1azAZ鸡哥牛逼'
print(a.encode('gbk')) # b'1azAZ\xbc\xa6\xb8\xe7\xc5\xa3\xb1\xc6'
b = b'1azAZ\xbc\xa6\xb8\xe7\xc5\xa3\xb1\xc6' # 1azAZ鸡哥牛逼
print(b.decode('gbk'))
解决乱码的问题,数据当初是以什么编码编的,就以什么编码解就可以了。
在python解释器中,python2是以ASCII码为默认编码的,python3默认的是utf8。所以我们使用的时候,一定要注意在文件头告诉解释器我们指定的编码。代码示例:
# coding:utf8 # 文件头就是在文件的最上方
# -*- coding:utf8 -*- 美化写法
在python2环境中,定义字符串习惯在前面加u:
name = u'jasonNB!'
文件的操作简介
文件就是操作系统暴露给用户可以直接操作硬盘的快捷方式,而我们要学习通过代码来操作文件的流程:1.打开或者创建文件 2.编辑文件内容 3.保存文件内容 4.关闭文件
基本结构语法
文件通过代码操作的使用方法有两种:
# 第一种 但是不推荐使用
a = open(r'a.jpg', 'rb')
print('a') # <_io.BufferedReader name='a.jpg'>
# 第二种 推荐使用
with open(r'a.jpg', 'rb') as a:
print(a) # <_io.BufferedReader name='a.jpg'>
可以使用关键字打开文件,同时写路径时为了防止特殊符号,我们通常如上代码直接加r。而open的用法:
open(文件路径, 文件的操作模式, 文件的编码),文件的路径时必须写的,文件的编码是可以不写的,如果不写的话就默认为你的计算机所用的编码。操作模式是根据自己的需求写的。而接下来我会说一下文件的操作模式。
我们在完成以上操作时,其实都需要执行一句close,也就是关闭文件,因为如果不关闭文件的话,会一直占用我们的内存。但是我们很容易遗忘,所以python为了防止我们遗忘,所以推荐我们使用第二种文件的打开方式。因为这样就相当于我们在结尾加了一个关闭文件的指令。
文件的操作模式
文件的操作模式分三种:
r模式
r模式,也就是文件打开后只读的模式,当我们使用这个模式时,路径必须存在,如果不存在,我们运行会直接报错,而若是存在,则会打开文件,等待读取:
with open(r'a.txt', 'r') as a:
print(a.read()) # jason NB!!!
a.write('NB') # 直接报错 io.UnsupportedOperation: not writable
由上述代码示例来看,只读模式确实只能读取,而不能写入内容。同时.read()方法是一次性读取文件内所有内容:
# 判断具备什么样的能力,这里的readable判断的是具备读的能力 writable是判断具备写的能力了
with open(r'a.txt', 'r') as a:
print(a.readable()) # True
print(a.writable()) # False
w模式
w模式,也就是文件打开后只写的模式,当我们使用这个模式时,我们只能编辑该路径下打开的文件的内容。需要注意的是,如果路径下的文件不存在,w模式会创建一个文件,同时,在w模式下打开的文件,会先被全部清空,再进行你的操作。也就是写入数据是在改文件被清空后操作的。代码示例:
with open(r'b.txt', 'w', encoding='utf8') as b:
b.write('鸡哥NB !!!')
b.write('鸡哥 NB NB !!!')
b.write('鸡哥 NB NB NB !!!')
print(b.read()) # not readable 这就是为什么只读,只写。因为只能进行这样的操作
a模式
a模式,也是文件打开后只写的模式,当我们使用这个模式时,我们只能编辑该路径下打开的文件的内容。需要注意的是,如果路径下的文件不存在,a模式也会创建一个文件,同时,在a模式下打开的文件,不会被清空文件内容,而是在文件末尾等待新内容的添加。代码示例:
with open(r'b.txt', 'a', encoding='utf8') as b:
b.write('NB NB NB !!!')
print(b.read()) # not readable
还有几个需要知道的模式:
1.t模式
t模式就是文本模式,也是默认的模式。写法就是rt,wt,at。也就是说,这后面介绍的模式与前面的读写模式是配合使用的。该模式下只能操作文本文件,该模式必须要指定encoding参数,该模式读写都是以字符串为最小单位
2.b模式
b模式就是二进制模式,可以操作任意类型的文件。写法是rb,wb,ab。该模式下可以操作任意类型的文件,该模式不需要指定encoding参数,该模式读写都是以bytes类型为最小单位
文件的内置方法
其实在前面的案例中,我们已经使用到了文件的内置方法。这里直接开始介绍:
read() 一次性读取文件内容,在小白阶段还可以使用,但是到了后面使用时,因为文件容易过大,容易造成内存溢出。值得注意的是这种方法在执行完后,光标在文件末尾,继续读取没有内容。代码示例:
# read()
with open(r'b.txt', 'r', encoding='utf8') as b:
print(b.read())
print(b.read())
print(b.read())
# 鸡哥NB !!!鸡哥 NB NB !!!鸡哥 NB NB NB !!!NB NB NB !!!NB NB NB !!! 三个打印输出语句只打印了一次,这就是光标在文件末尾,继续读取没有内容的含义
# 所以衍生出了read的一些使用方式
# readline() 一次只读一行
with open(r'b.txt', 'r', encoding='utf8') as b:
print(b.readline()) # 鸡哥NB !!!
print(b.readline()) # 鸡哥 NB NB !!!
# readlines() 结果是一个列表 里面的各个元素是文件的一行行内容
with open(r'b.txt', 'r', encoding='utf8') as b:
print(b.readlines()) # ['鸡哥NB !!!\n', '鸡哥 NB NB !!!\n', '鸡哥 NB NB NB !!!\n', 'NB NB NB !!!\n', 'NB NB NB !!!']
# readable() # 判断当前文件是否可读 已经使用过不再举例
# 支持for循环 推荐使用 一行行读取文件内容,内存中同一时刻只会有一行内容
with open(r'b.txt', 'r', encoding='utf8') as b:
for a in b:
print(a) # 鸡哥NB !!! 鸡哥 NB NB !!! 鸡哥 NB NB NB !!! NB NB NB !!! NB NB NB !!! (空四格代表两次换行)
write() 写入文件内容。代码示例:
# write() 写入文件内容(字符串或者bytes类型)
with open(r'b.txt', 'w', encoding='utf8') as b:
b.write('666') # 只读模式是不能读内容的,再次强调,写入内容之前,改文件内所有的内容都会被清除。同时write的衍生使用方式、
# writelines() 可以将列表中多个元素写入文件
with open(r'b.txt', 'w') as b:
b.writelines(['666', '1', 'jason']) # 写入后内容为 6661jason
# writable() # 判断文件是否可写,与之前的方式一样,判断是否可写,返回True或者False
# flush() 相当于主动按了Ctrl+s,保存的意思
今日作业
# 1.编写一个简易版本的拷贝程序,路径全部自定义
name_route = input('请输入复制文件路径:') # 定义变量名的值为输入内容
name_route_clone = input('请输入复制文件路径:') # 定义变量名的值为输入内容
with open(f'{name_route}', 'rb') as a: # 打开路径为第一次输入内容的文件,用只读的方式定义给a
data = a.read() # 将读取到的a的内容赋值给data
with open(f'{name_route_clone}', 'wb') as b: # 打开路径为第二次输入内容的文件,用只写的方式定义给b
b.write(data) # 将data的内容写入b中
# 2.结合文件编写用户注册登录功能
a = 0
while a < 3:
func = input('输入1注册,输入2登录,输入3退出:')
if func == '1':
user = input('请输入用户名:').strip()
password = input('请输入密码:').strip()
with open(r'D:\PycharmProjects\python2.4\userinfo.txt', 'r', encoding='utf8') as userinfo_data_input:
for i in userinfo_data_input:
if user == i.split('|')[0]:
print('该账号已存在')
break
else:
with open(r'D:\PycharmProjects\python2.4\userinfo.txt', 'a', encoding='utf8') as u:
userdata_input = user + '|' + password + '\n'
u.write(userdata_input)
elif func == '2':
user = input('请输入用户名:').strip()
password = input('请输入密码:').strip()
i = 1
with open(r"D:\PycharmProjects\python2.4\userinfo.txt", 'r') as userinfo_data:
for userdata in userinfo_data:
if user == userdata.split('|')[0] and password == userdata.strip('\n').split('|')[1]:
print('登录成功')
while True:
data = input('请输入内容("输入q退出")')
if data == 'q':
print('账号已退出')
i = 0
a = 4
break
else:
print(data)
else:
a += 1
if i == 1:
print('用户名或密码错误')
if a == 3:
num = input('已错误三次,输入y继续尝试,输入n退出')
if num == 'y':
a = 0
else:
break
else:
print('退出成功')
break


 浙公网安备 33010602011771号
浙公网安备 33010602011771号