

常见算法
1、二分查找非递归
/**
*二分查找非递归实现
* @param arr 待查找的数组
* @param target 需要查找的数
* @return 返回对应的下标 -1表示没有找到
*/
public static int binarySearch(int[] arr,int target){
int left = 0;
int right = arr.length-1;
while(left <= right){
int mid = (left+right)/2;
if (arr[mid] == target){
return mid;
}else if(arr[mid] > target){
right = mid -1;
}else{
left = mid +1;
}
}
return -1;
}
2、分治算法
- 字面上解释就是把一个复杂的问题分成两个或者更多的相同或类似的子问题,再把子问题分成更小的子问题...直到最后子问题可以简单的求解,原问题的解即子问题的解的合并。这个技巧是很多高效率算法的基础,如排序算法(快速排序,归并排序),博立叶变换(快速博立叶变换)...
- 分治算法的基本步骤
- 分解:将原问题分解为若干个规模较小,相互独立,与原问题形式相同的子问题
- 解决:将子问题规模较小而容易被解决则直接解,否则递归地解各个子问题
- 合并:将各个子问题的解合并为原问题的解
- 汉诺塔(思路分析)
- 如果只有一个盘,直接从A移动到C
- 如果有n>=2的情况,我们总是可以看作是两个盘,最下面的一个盘,和上面的所有盘
- 把A最上面的所有盘移动到B
- 把A最下面的一个盘移动到C
- 把B的所有盘移动到C
/**
* @param num 盘的数量
* @param a 柱子a
* @param b 柱子b
* @param c 柱子c
*/
public static void hanoiTower(int num,char a,char b ,char c){
//如果只有一个盘
if(num == 1){
System.out.println("第1个盘从"+a+"->"+c);
}else{
//如果我们有num>=2情况,我们总是可以看做是两个盘,上面的所有盘,最下面的一个盘
//1.先把上面的所有盘 A->B
hanoiTower(num -1,a,c,b);
//2.最小面的盘A->C
System.out.println("第"+num+"个盘从"+a+"->"+c);
//3.把B的所有盘移动到C
hanoiTower(num -1,b,a,c);
}
}
3、动态规划
- 背包问题
- 有一个背包,容量为4磅,现有如下物品
| 物品 | 重量 | 价格 |
|---|---|---|
| 吉他 | 1 | 1500 |
| 音响 | 4 | 3000 |
| 电脑 | 3 | 2000 |
- 要求达到的目标为装入背包的总价值最大,并且重量不超出
- 要求装入物品不能重复
- 动态规划(Dynamic Programming)算法的核心思想是:将大问题划分为小问题进行解决,从而一步步获取最优解的处理算法
- 动态规划算法与分治算法类似,其基本思想也是将待求解的问题分成若干个子问题,先求解子问题,然后从这些子问题的解得到原问题的解
- 与分治不同的是,适合于用动态规划求解的问题,经分解得到子问题往往不是互相独立的。(即下一个子阶段的求解是建立在上一个子阶段的解的基础上,进行进一步的求解)
- 动态规划可以通过填表的方式来逐步推进,得到最优解
- 思路分析
- 利用动态规划来解决。每次遍历到的第i个物品,根据w[i]和v[i]来确定是否需要将该物品放入背包中。即对于给定的n个物品,设v[i]、w[i]分别为第i个物品的价值和重量,C为背包的容量。再令v[i][j]表示在前i个物品中能够装入容量为i的背包中的最大价值。
- 背包问题填表过程
| 物品 | 0磅 | 1磅 | 2磅 | 3磅 | 4磅 |
|---|---|---|---|---|---|
| 0 | 0 | 0 | 0 | 0 | |
| 吉他 | 0 | 1500 | 1500 | 1500 | 1500 |
| 音响 | 0 | 1500 | 1500 | 1500 | 3000 |
| 电脑 | 0 | 1500 | 1500 | 2000 | 3500 |
- [1][1]:只能放一把吉他 1500
- [1][2]:只能放一把吉他 1500
- [1][3]:只能放一把吉他 1500
- [1][4]:只能放一把吉他 1500
- [2][1]:容量为1磅,放不进去音响,则放入[1][1]的物品 1500
- [2][2]:容量为2磅,放不进去音响,则放入[1][2]的物品 1500
- [2][3]:容量为3磅,放不进去音响,则放入[1][3]的物品 1500
- [2][4]:容量为4磅,可以放入音响,且音响的价值>[1][4]的价值,则放入音响 3000
- [3][1]:容量为1磅,放不进去电脑,则放入[2][1]的物品 1500
- [3][2]:容量为2磅,放不进去电脑,则放入[2][2]的物品 1500
- [3][3]:容量为3磅,可以放入电脑且无剩余空间,电脑价值>[2][3]放入的价值, 2000
- [3][4]:容量为4磅,可以放入电脑,剩余空间为1磅,则在容量为1磅的里面找价值最大的 2000+1500 = 3500
-
1.v[i][0] = v[0][j] = 0; //表示填入的这张表第一行和第一列都为0
-
2.当 w[i]>j 时:v[i][j] = v[i-1][j] //当准备加入新增的商品的容量大于当前背包的容量时,就直接用上一个单元格的装入策略
-
3.当 w[i]<=j 时:v[i][j] = max
- 当准备加入的新增的商品的容量小于等于当前背包的容量
- v[i-1][j]:上一个单元格的装入的最大值
- v[i]:表示当前商品的价值
- v[i-1][j-w[i]]:装入i-1商品到剩余空间j-w[j]的最大值
-
利用动态规划,打印填表
//动态规划 背包问题
public class KnapsackProblem {
public static void main(String[] args) {
int[] w = {1,4,3}; //物品的重量
int[] val ={1500,3000,2000}; //物品的价值
int m = 4; //背包的容量
int n = val.length; // 物品的个数
//创建二维数组
int[][] v = new int[n+1][m+1];
//初始化第一行和第一列
for (int i =0;i<v.length;i++){
v[i][0] = 0; //将第一列设置为0
}
for (int i =0;i<v[0].length;i++){
v[0][i] = 0; //将第一行设置为0
}
//动态规划处理
for (int i = 1; i< v.length ;i++){
for (int j = 1;j< v[0].length; j++){
if (w[i-1] > j){ //因程序索引是从0开始 w索引需减1
v[i][j] = v[i-1][j];
}else{
//程序索引从0开始 val w 的索引需减1
v[i][j] = Math.max(v[i-1][j],val[i-1]+v[i-1][j-w[i-1]]);
}
}
}
//打印数组
for (int i = 1; i< v.length ;i++){
for (int j = 1;j< v[0].length; j++){
System.out.print(v[i][j] + " ");
}
System.out.println();
}
}
}
- 控制台输出
1500 1500 1500 1500
1500 1500 1500 3000
1500 1500 2000 3500
- 为了记录商品放入背包的情况,需要新建一个二维数组存储物品放入信息,最后遍历数组获取存储情况
//动态规划 背包问题
public class KnapsackProblem {
public static void main(String[] args) {
int[] w = {1,4,3}; //物品的重量
int[] val ={1500,3000,2000}; //物品的价值
int m = 4; //背包的容量
int n = val.length; // 物品的个数
//创建二维数组
int[][] v = new int[n+1][m+1];
//为了记录商品放入的情况,创建二维数组
int[][] path = new int[n+1][m+1];
//初始化第一行和第一列
for (int i =0;i<v.length;i++){
v[i][0] = 0; //将第一列设置为0
}
for (int i =0;i<v[0].length;i++){
v[0][i] = 0; //将第一行设置为0
}
//动态规划处理
for (int i = 1; i< v.length ;i++){
for (int j = 1;j< v[0].length; j++){
if (w[i-1] > j){ //因程序索引是从0开始 w索引需减1
v[i][j] = v[i-1][j];
}else{
//程序索引从0开始 val w 的索引需减1
//v[i][j] = Math.max(v[i-1][j],val[i-1]+v[i-1][j-w[i-1]]);
//为了记录商品存放到背包的情况,不能使用上面公式,需要if-else来体现
if(v[i-1][j] < val[i-1]+v[i-1][j-w[i-1]]){
v[i][j] = val[i-1]+v[i-1][j-w[i-1]];
//把当前的情况记录到path
path[i][j] = 1;
}else{
v[i][j] = v[i-1][j];
}
}
}
}
//输出最后我们放入的那些商品,遍历path
int i = path.length-1;
int j = path[0].length-1;
while(i > 0 && j > 0){
if (path[i][j] == 1){
System.out.printf("第%d个商品放入到背包\n",i);
j = j - w[i-1]; //找到一个存放的商品,则需要减去它本身的容量
}
i--;
}
}
}
- 控制台输出
第3个商品放入到背包
第1个商品放入到背包
4、字符串暴力匹配
//暴力匹配算法实现
public static int violenceMatch(String str1,String str2){
char[] s1 = str1.toCharArray();
char[] s2 = str2.toCharArray();
int s1len = s1.length;
int s2len = s2.length;
int i = 0; //指向s1
int j = 0; //指向s2
while( i< s1len && j < s2len){
if (s1[i] == s2[j]){
i++;
j++;
}else{
i = i-(j-1);
j=0;
}
}
//判断是否匹配成功
if (j == s2len){
return i-j;
}
return -1;
}
5、KMP算法
- KMP算法就是利用之前判断过信息,通过一个next数组,保存模式串中前后最长公共子序列的长度,每次回溯时,通过next数组找到,前面匹配过的位置,省去了大量的时间
- 参考资料:https://www.cnblogs.com/ZuoAndFutureGirl/p/9028287.html
public class KMP {
public static void main(String[] args) {
String str1 = "abcdefg";
String str2 = "ef";
int[] next = kmpNext(str2);
int index = kmpSearch(str1, str2, next);
System.out.println("index="+index);
}
/**
* KMP
* @param str1 源串
* @param str2 子串
* @param next 子串的部分匹配表
* @return -1 没有匹配到,否则返回第一个匹配的位置
*/
public static int kmpSearch(String str1,String str2,int[] next){
for (int i =0,j=0;i<str1.length();i++){
//需要处理str1.charAt(i) != str2.charAt(j)
//KMP算法的核心点
while(j>0 && str1.charAt(i) != str2.charAt(j)) {
j = next[j-1];
}
if (str1.charAt(i) == str2.charAt(j)){
j++;
}
if (j == str2.length()){ //找到了
return i-j+1;
}
}
return -1;
}
//获取到一个字符串(子串)的部分匹配值表
public static int[] kmpNext(String str){
//创建next数组保存部分匹配值
int[] next = new int[str.length()];
next[0] = 0; //如果字符串长度为1 则部分匹配值为0
for (int i =1,j=0;i<str.length();i++){
//当str.charAt(i) != str.charAt(j)时,我们需要从next[j-1]获取新的j
//kmp算法的核心点
while(j>0 && str.charAt(i) != str.charAt(j)){
j = next[j-1];
}
//当str.charAt(i) == str.charAt(j)满足时,部分匹配值+1
if (str.charAt(i) == str.charAt(j)){
j++;
}
next[i] = j;
}
return next;
}
}
6、贪心算法
- 应用场景-集合覆盖问题
- 假设存在下面需要付费的广播台,以及广播台信号可以覆盖的地区。如何选择最少的广播台,让所有的地区都可以接收到信号
| 广播台 | 覆盖地区 |
|---|---|
| K1 | 北京,上海,天津 |
| K2 | 广州,北京,深圳 |
| K3 | 成都,上海,杭州 |
| K4 | 上海,天津 |
| K5 | 杭州,大连 |
- 贪心算法
- 贪心算法是指在对问题进行求解时,在每一秒选择中都采取最好或者最优的选择,从而希望能够导致结果是最好或最优的算法
- 贪心算法所得到的结果不一定是最优的结果,但是都是相对接近最优的结果
- 思路分析
- 遍历所有的广播电台,找到一个覆盖了最多未覆盖的地区的电台(此电台可能包含一些已经覆盖的地区,但没关系)
- 将这个电台加入到一个集合中,想办法把该电台覆盖的地区在下次比较时去掉
- 重复第一步直到覆盖了全部的地区
package cjsf.greedy;
import java.util.*;
//贪心算法
public class GreedyAlgorithm {
public static void main(String[] args) {
//创建广播电台保存到map中
HashMap<String,HashSet<String>> map = new HashMap();
//将各个电台放入map中
HashSet<String> set1 = new HashSet();
set1.add("北京");
set1.add("上海");
set1.add("天津");
map.put("K1",set1);
HashSet<String> set2 = new HashSet();
set2.add("广州");
set2.add("北京");
set2.add("深圳");
map.put("K2",set2);
HashSet<String> set3 = new HashSet();
set3.add("成都");
set3.add("上海");
set3.add("杭州");
map.put("K3",set3);
HashSet<String> set4 = new HashSet();
set4.add("上海");
set4.add("天津");
map.put("K4",set4);
HashSet<String> set5 = new HashSet();
set5.add("杭州");
set5.add("大连");
map.put("K5",set5);
//所有地区
Set allAreas = new HashSet<String>();
allAreas.add("北京");
allAreas.add("上海");
allAreas.add("天津");
allAreas.add("广州");
allAreas.add("成都");
allAreas.add("杭州");
allAreas.add("大连");
//创建一个Arraylist存放选择的电台的集合
List list = new ArrayList<String>();
//用于存储当前电台覆盖地区
Set tempSet = new HashSet<String>();
//用于存储最大电台覆盖地区
Set maxSet = new HashSet<String>();
//定义一个maxKey,在一次遍历过程中,能够覆盖最大未覆盖地区对应的电台的key
String maxKey = null;
while (allAreas.size() !=0 ){ //如果allAreas!=0表示还未覆盖所有地区
//遍历map,取出对应的key
for (String key : map.keySet()){
//当前这个key能够覆盖的地区
HashSet<String> areas = map.get(key);
tempSet.addAll(areas);
//求出tempSet和allAreas集合的交集,交集会赋给tempSet
tempSet.retainAll(allAreas);
//求出最大覆盖了未覆盖地区个数的电台
if (maxKey != null){
maxSet = map.get(maxKey);
maxSet.retainAll(allAreas);
}
//如果当前电台覆盖的未覆盖地区个数大于定义的最大覆盖未覆盖地区个数
//则当前电台为最大覆盖了未覆盖地区个数的电台
if (tempSet.size() > 0 &&
(maxKey == null || tempSet.size() > maxSet.size())){
maxKey = key;
}
tempSet.clear();
}
if (maxKey != null){
list.add(maxKey);
//将maxKey指向的广播电台地区从allAreas去掉
allAreas.removeAll(map.get(maxKey));
}
maxSet.clear();
maxKey = null;
}
for (Object key:list){
System.out.print(key.toString()+" ");
}
}
}
7、普利姆算法
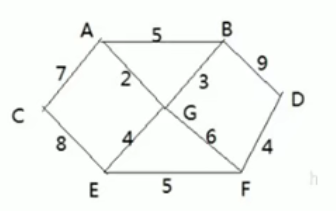
- 有7个村庄(A,B,C,D,E,F,G),现在需要修路把7个村庄连通
- 各个村庄的距离用边线表示(权)
- 问:如何修路保证各个村庄都能连通,并且总的修建公里总里程最短?
- 求解思路
- 就是尽可能的选择少的路线,并且每条路线最小,保证总里程最小
- 修路问题本质就是最小生成树问题,最小生成树(Minimum Cost Spanning Tree),简称MST
- 给定一个带权的无向连通图,如何选取一棵生成树,使树上所有边上权的总和为最小,这叫最小生成树
- N个顶点,一定有N-1条边
- 包含全部顶点
- N-1条边都在图中
- 求最小生成树的算法主要是普利姆算法和克鲁斯卡尔算法
- 普利姆算法
- 普利姆(Prim)算法求最小生成树,也就是在包含n个顶点的连通图中,找出只有(n-1)条边包含所有n个顶点的连通子图,也就是所谓的极小连通子图
- 1.设G=(V,E)是连通图,T=(U,D)是最小生成树,V,U是顶点集合,E,D是边的集合
- 2.若从顶点u开始构造最小生成树,则从集合V中取出顶点u放入集合U中,标记顶点v的visited[u]=1
- 3.若集合U中顶点ui与集合V-U中的顶点vj之间存在边,则寻找这些边中权值最小的边,但不能构成回路,将顶点vj加入到集合U中,将边(ui,vj)加入到集合D中,标记visited[vj]=1
- 4.重复步骤2,直到U与V相等,即所有顶点都被标记为访问过,此时D中有n-1条边
- 普利姆算法求解过程
- 1.从A点开始,
边权值最小 - 2.{A,G}中的节点和没有走过的结点权值最小为<G,B>边
- 3.{A,G,B}对应<G,E>边权值最小
- 4.{A,G,B,E}对应<E,F>边权值最小
- 5.{A,G,B,E,F}对应<F,D>边权值最小
- 6.{A,G,B,E,F,D}对应<A,C>边权值最小
- 7.
- 1.从A点开始,


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· AI 智能体引爆开源社区「GitHub 热点速览」
· 从HTTP原因短语缺失研究HTTP/2和HTTP/3的设计差异
· 三行代码完成国际化适配,妙~啊~