
ElasticSearch
1、ElasticSearch概述
- 官网:https://www.elastic.co/cn/
- ElaticSearch,简称es,es是一个开源的高扩展的分布式全文本搜索引擎,它可以近乎实时的存储、检索数据;本身扩展性很好,可以扩展到上百台服务器,处理PB级别的数据。es也使用java开发并使用Lucene作为其核心来实现所有索引和搜索的功能,但是它的目的是通过简单的RESTful API来隐藏Lucene的复杂性,从而让全文搜索变得更简单。
2、下载ElasticSearch
- 镜像下载地址:https://mirrors.huaweicloud.com/elasticsearch/?C=N&O=D
- 下载压缩包解压
- bin 启动目录
- config 配置文件
- log4j2 日志配置文件
- jvm.options java虚拟机相关的配置
- elasticsearch.yml elasticsearch的配置文件
- lib 相关jar包
- modules 功能模块
- plugins 插件
- logs 日志
- 启动,/bin/elasticsearch.bat
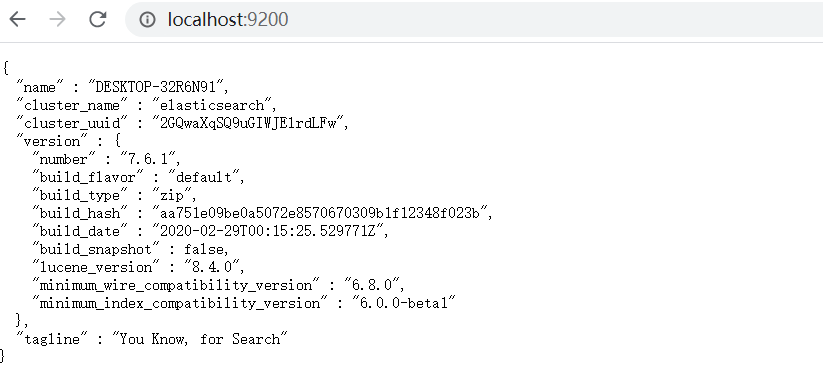
- 访问localhsot:9200
3、安装可视化界面
- github地址:https://github.com/mobz/elasticsearch-head/tree/master
- 安装依赖 npm install
- 启动 npm run start

- 9100端口访问9200端口会出现跨域
- 修改elasticsearch配置跨域
http.cors.enabled: true
http.cors.allow-origin: "*"

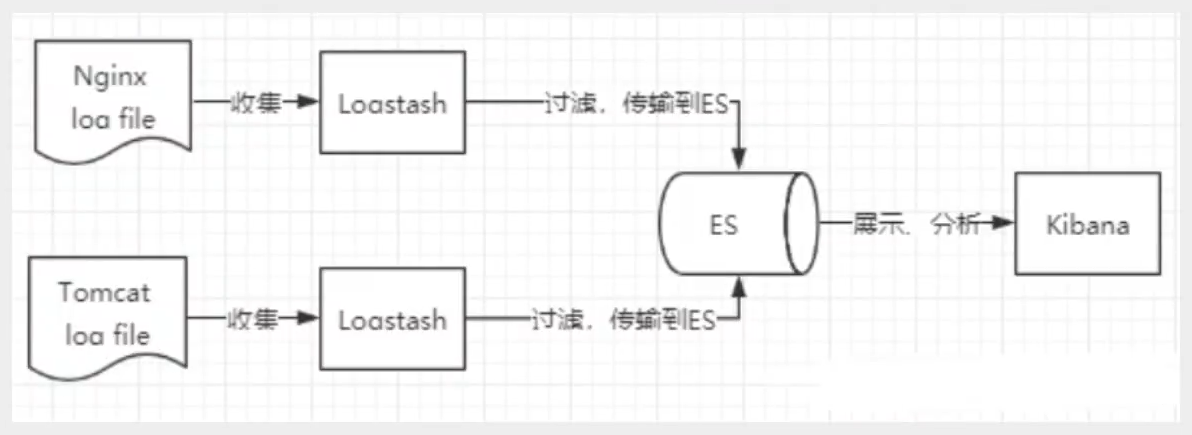
4、ELK
- ELK是ElasticSearch、Logstash、Kibana三大开源框架首字母简称,也被称为Elastic Stack。其中ElasticSearch是一个基于Lucene、分布式、通过Restful方式进行交互的近乎实时搜索框架。Logstash是ELK的中央数据流引擎,用于从不同目标(文件/数据存储/MQ)收集到不同格式数据,经过过滤后支持输出到不同目的地(文件/MQ/redis/elasticsearch等)。Kibana可以将elasticsearch的数据通过友好的页面展示出来,提供实时分析的功能
5、Kibana
- Kibana是一个针对ElasticSearch的开源分析及可视化平台,用来搜索、查看交互存储在ElasticSearch索引中的数据。使用Kibana,可以通过各种图表进行高级数据分析及展示。Kibana让海量数据更容易理解。它操作简单,基于浏览器的用户界面可以快速创建仪表板(dashboard)实时显示动态。设置Kibana简单,无需编码或者额外的基础架构
- 镜像地址:https://mirrors.huaweicloud.com/kibana/?C=N&O=D
- Kibana版本要和ElasticSearch版本一致
- 下载Kibana并解压
- 修改/config/kibana.yml,汉化
i18n.locale: "zh-CN"
- 启动 /bin/kibana.bat
- 访问localhost:5601
6、ES核心概念
- elasticsearch是面向文档
- 关系型数据库和elasticsearch对比
| Relational DB | ElasticSearch |
|---|---|
| 数据库(database) | 索引(indeices) |
| 表(table) | types |
| 行(rows) | documents |
| 字段(columns) | fields |
- 物理设计
- elasticsearch在后台把每个索引划分为多个分片,每个分片可以在集群中的不同服务器间迁移
- 逻辑设计
- 一个索引类型中包含多个文档,当索引一片文档时,可以通过这样的一个顺序找到它:索引->类型->文档ID,通过这个组合就能索引到具体的文档
- 文档
- elasticsearch是面向文档的,意味着索引和搜索数据的最小单位是文档,elasticsearch中,文档有几个重要的属性
- 自我包含:一篇文档同时包含字段和对应的值,也就是同时包含key:value
- 可以是层次型的,一个文档包含子文档,复杂的逻辑实体就是这么来的
- 灵活的结果,文档不依赖预先定义的模式,关系型数据库中,要提前定义字段才能使用,在elasticsearch中,对于字段非常灵活
- elasticsearch是面向文档的,意味着索引和搜索数据的最小单位是文档,elasticsearch中,文档有几个重要的属性
- 类型
- 类型是文档的逻辑容器,就像关系型数据库一样,表格是行的容器。类型中对于字段的定义称为映射
- 索引
- 索引是映射类型的容器,elasticsearch中的索引是一个非常大的文档集合。索引存储了映射类型的字段和其他设置。然后他们被存储到各个分片上
- 物理设计:节点和分片
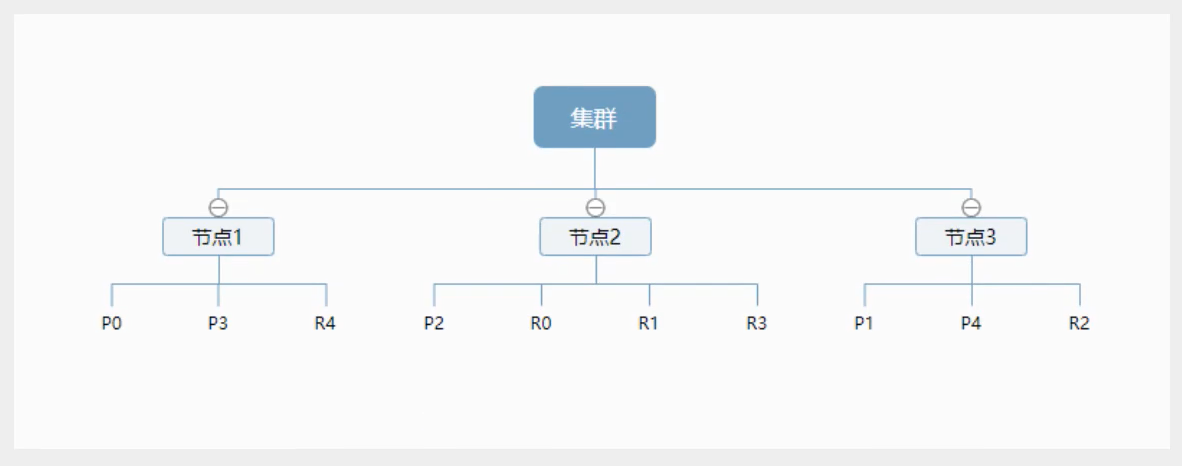
- 一个集群中至少有一个节点,而一个节点就是一个elasticsearch进程,节点可以有多个索引,如果你创建了索引,那么索引将会有5个分片(primary shard,又称主分片)构成的,每一个主分片会有一个副本(replica shard,又称复制分片)
-
上图是一个有3个节点的集群,可以看到主分片和对应的复制分片都不会在同一个节点内,这样有利于某个节点挂掉了,数据也不会丢失,实际上,一个分片是一个Lucene索引,一个包含倒排索引的文件目录,倒排索引的结构使得elasticsearch在不扫描全部文档的情况下,就能告诉你哪些文档包含特定的关键字
-
倒排索引
- elasticsearch使用的是一种称为倒排索引的结构,采用Lucene倒排索引作为底层。这种结构适用于快速的全文搜索,一个索引由文档中所有不重复的列表构成,对于每一个词,都有一个包含他的文档列表。例如,现在有两个文档,每个文档包含如下内容:
Study every day,good good up to forever # 文档1包含的内容
To forever,study every day,good good up # 文档2包含的内容
- 为了创建倒排索引,首先要将每个文档拆分为独立的词(或称为词条或者tokens),然后创建一个包含所有不重复的词条的排序列表,然后列出每个词条出现在那个文档
| trem | doc_1 | doc_2 |
|---|---|---|
| Study | √ | × |
| To | × | × |
| every | √ | √ |
| forever | √ | √ |
| day | √ | √ |
| study | × | √ |
| good | √ | √ |
| to | √ | × |
| up | √ | √ |
- 现在,视图搜索to forever,只需要查看包含每个词条的文档
| trem | doc_1 | doc_2 |
|---|---|---|
| to | √ | × |
| forever | √ | √ |
| total | 2 | 1 |
- 两个文档都匹配,但是第一个文档比第二个文档匹配程度更高,如果没有别的条件,这两个包含关键字的文档都将被返回
7、IK分词器
-
IK分词器
- 即把一段中文或者别的划分成一个个关键字,我们在搜索的时候会把自己的信息进行分词,会把数据库中或者索引库中的数据进行分词,然后进行一个匹配操作,默认的中文分词试讲每个字看成一个词,不符合要求,所以需要安装中文分词器ik来解决这个问题
- IK提供了两个分词算法:ik_smart(最小切分)和ik_max_word(最细腻度划分)
-
下载并解压文件,放入ElasticSearch plugins中
-
重启elasticsearch
- 使用IK分词器
- ik_smart算法
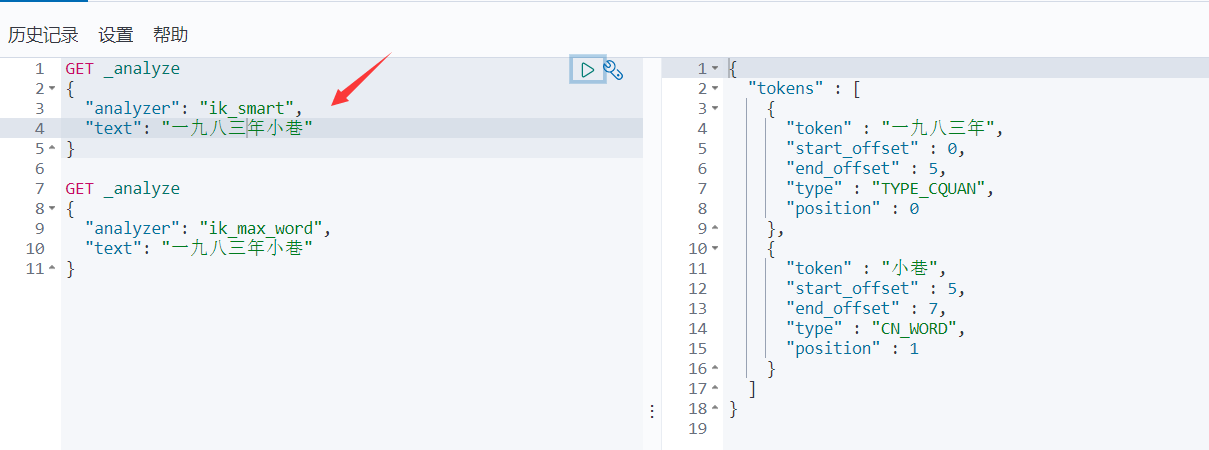
- ik_max_word算法
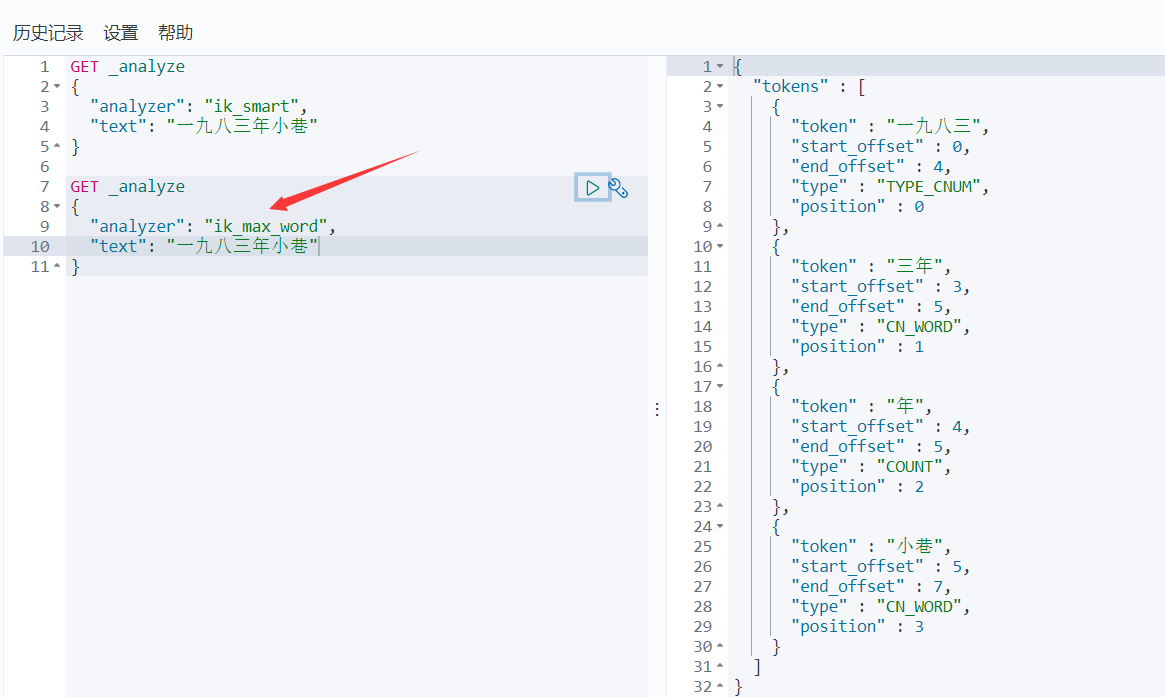
- ik分词器增加自己的配置 \elasticsearch-7.6.1\plugins\ik\config\IKAnalyzer.cfg.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict"></entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords"></entry>
<!--用户可以在这里配置远程扩展字典 -->
<!-- <entry key="remote_ext_dict">words_location</entry> -->
<!--用户可以在这里配置远程扩展停止词字典-->
<!-- <entry key="remote_ext_stopwords">words_location</entry> -->
</properties>
- 配置自己的扩展字典
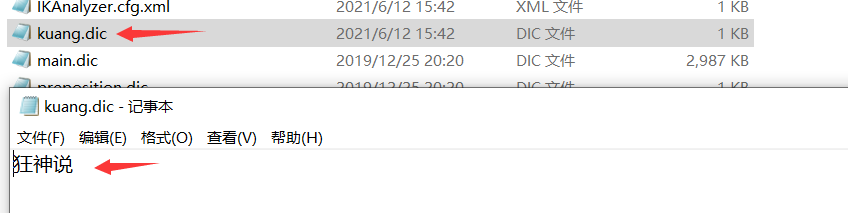
<entry key="ext_dict">kuang.dic</entry>
- 创建kuang.dic文件
-
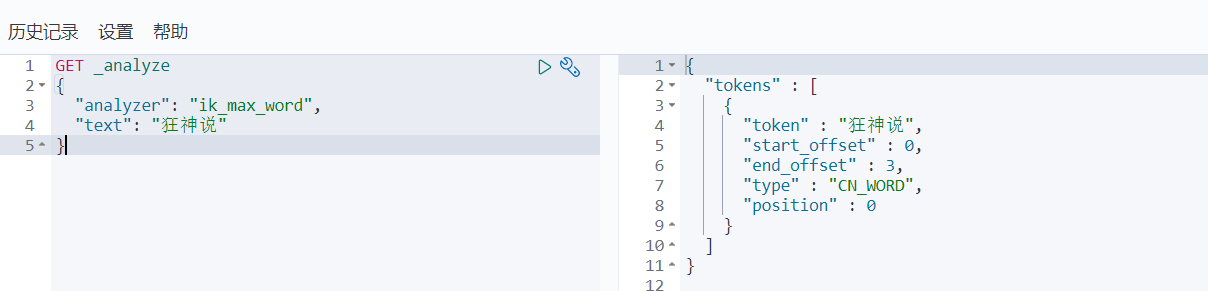
重启elasticsearch,kibana
-
搜索狂神说
8、Rest风格说明
- 基本Rest命令
| method | url地址 | 描述 |
|---|---|---|
| PUT | localhost:9200/索引名称/类型名称/文档id | 创建文档(指定文档id) |
| POST | localhost:9200/索名称/类型名称 | 创建文档(随机文档id) |
| POST | localhost:9200/索引名称/类型名称/文档id/_update | 修改文档 |
| DELETE | localhost:9200/索引名称/类型名称/文档id | 删除文档 |
| GET | localhost:9200/索引名称/类型名称/文档id | 查询文档通过id |
| POST | localhost:9200/索引名称/_search | 查询所有数据 |
- 添加文档
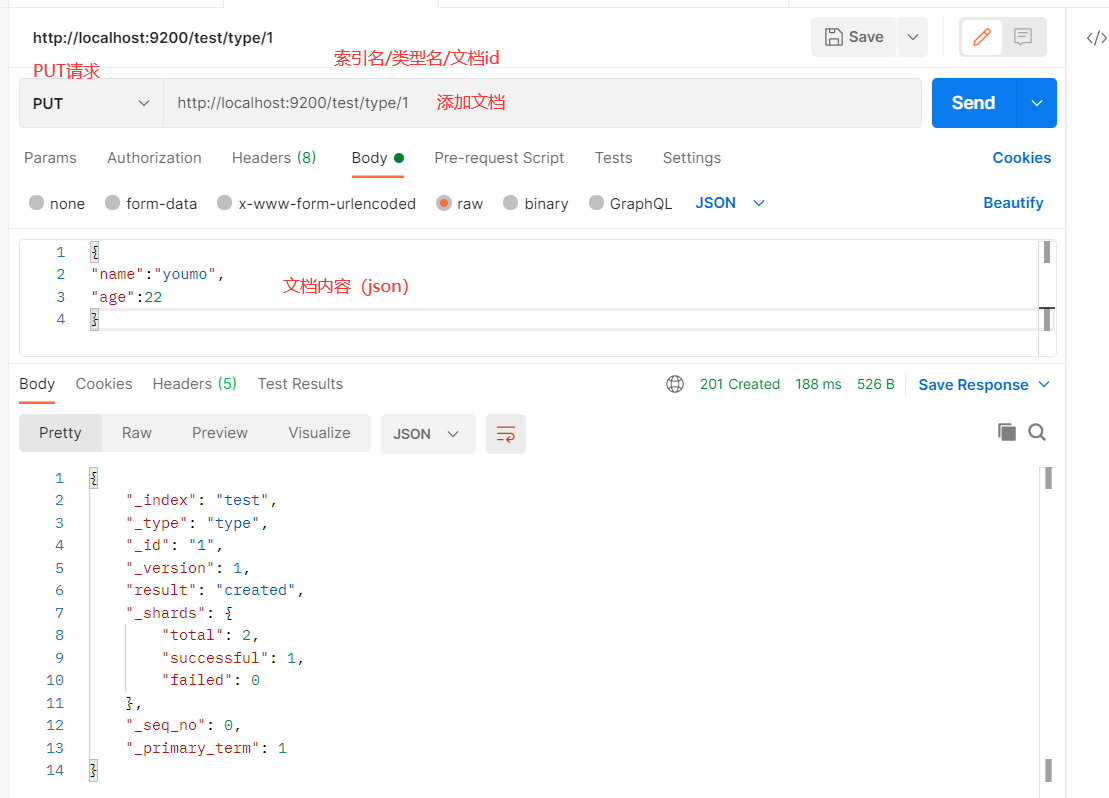
-
字段基本类型
- 字符串类型
- text、keyword
- 数值类型
- long、integer、short、byte、double、float、half、scaled float
- 日期类型
- date
- 布尔类型
- boolean
- 二进制类型
- binary
- ...
- 字符串类型
-
创建索引并设置字段类型,type默认_doc
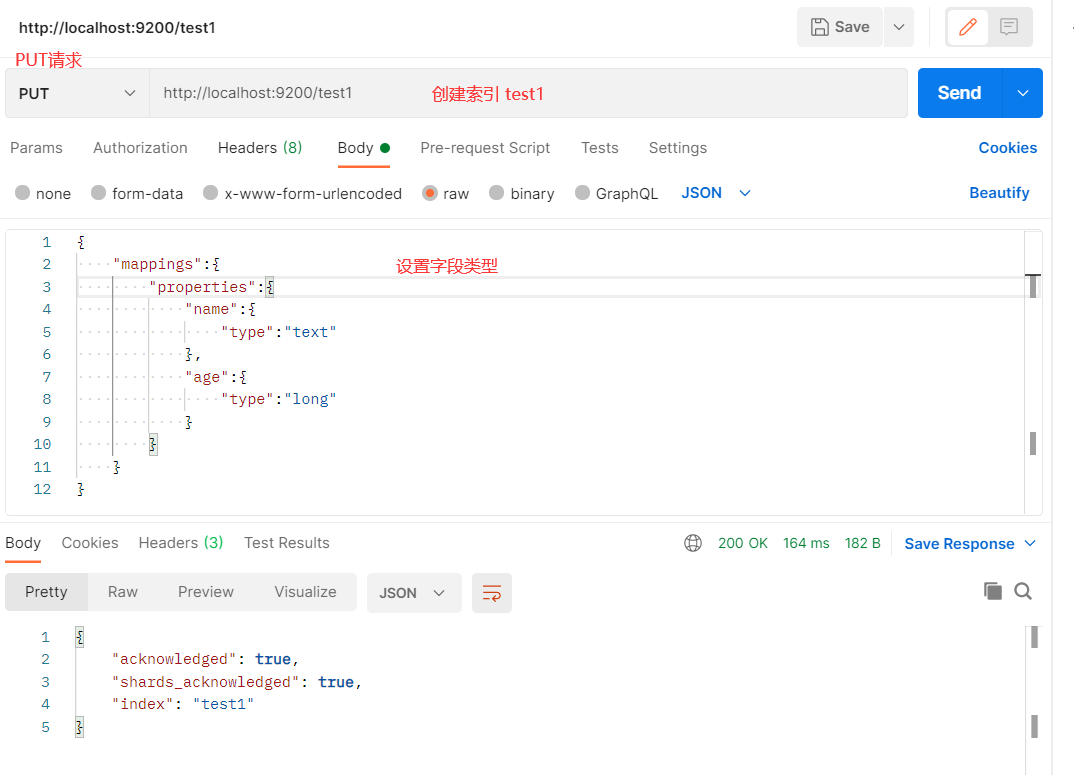
-
通过 _cat/ 可以获得es的当前很多信息
-
修改文档
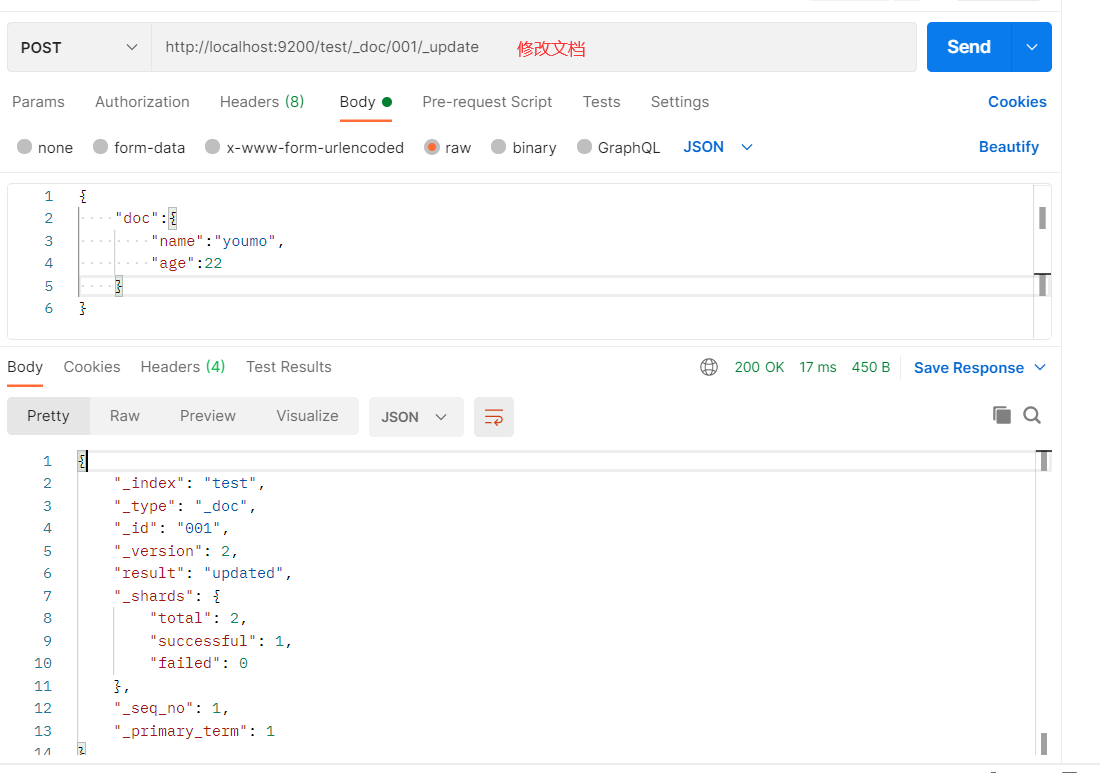
- 查询
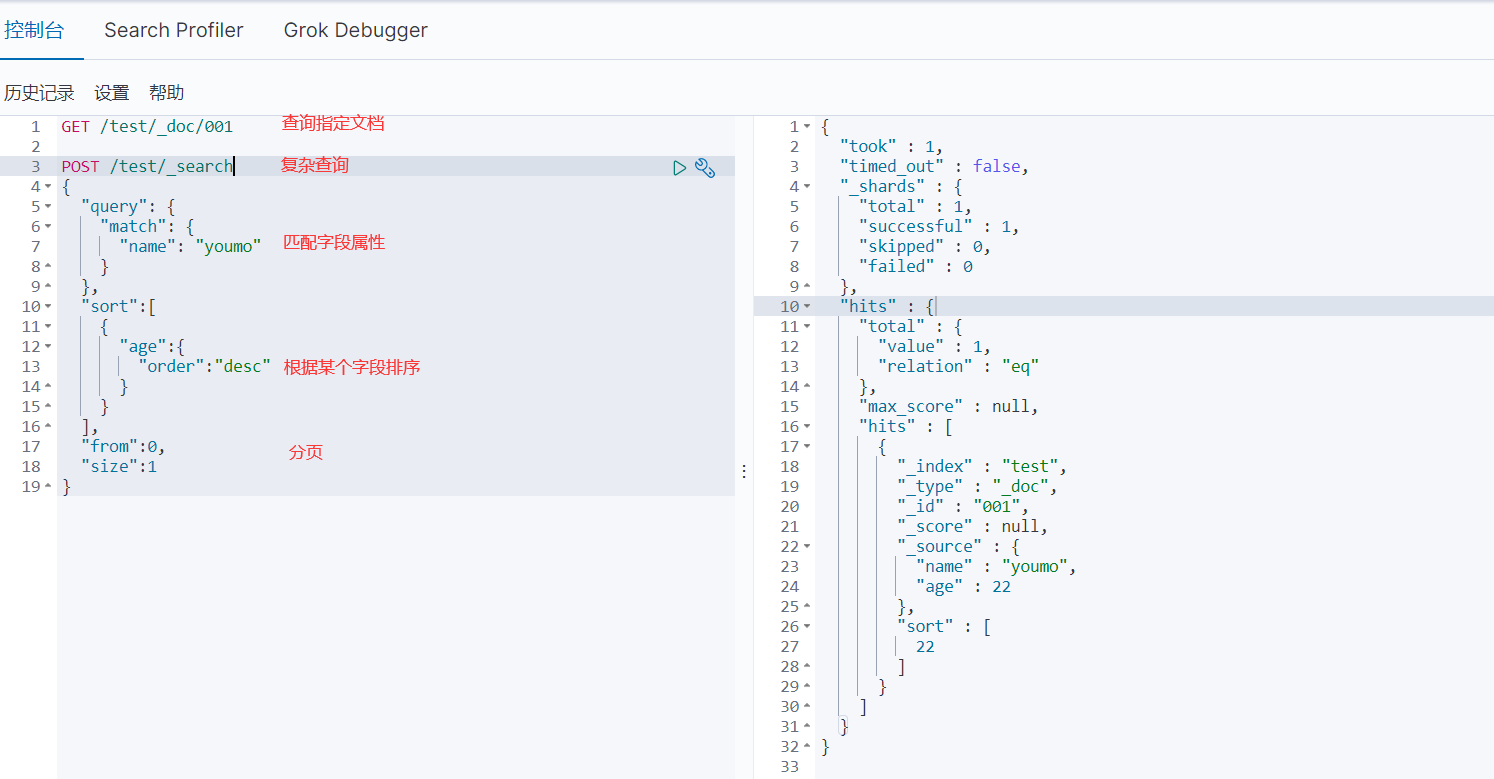
- 多条件查询
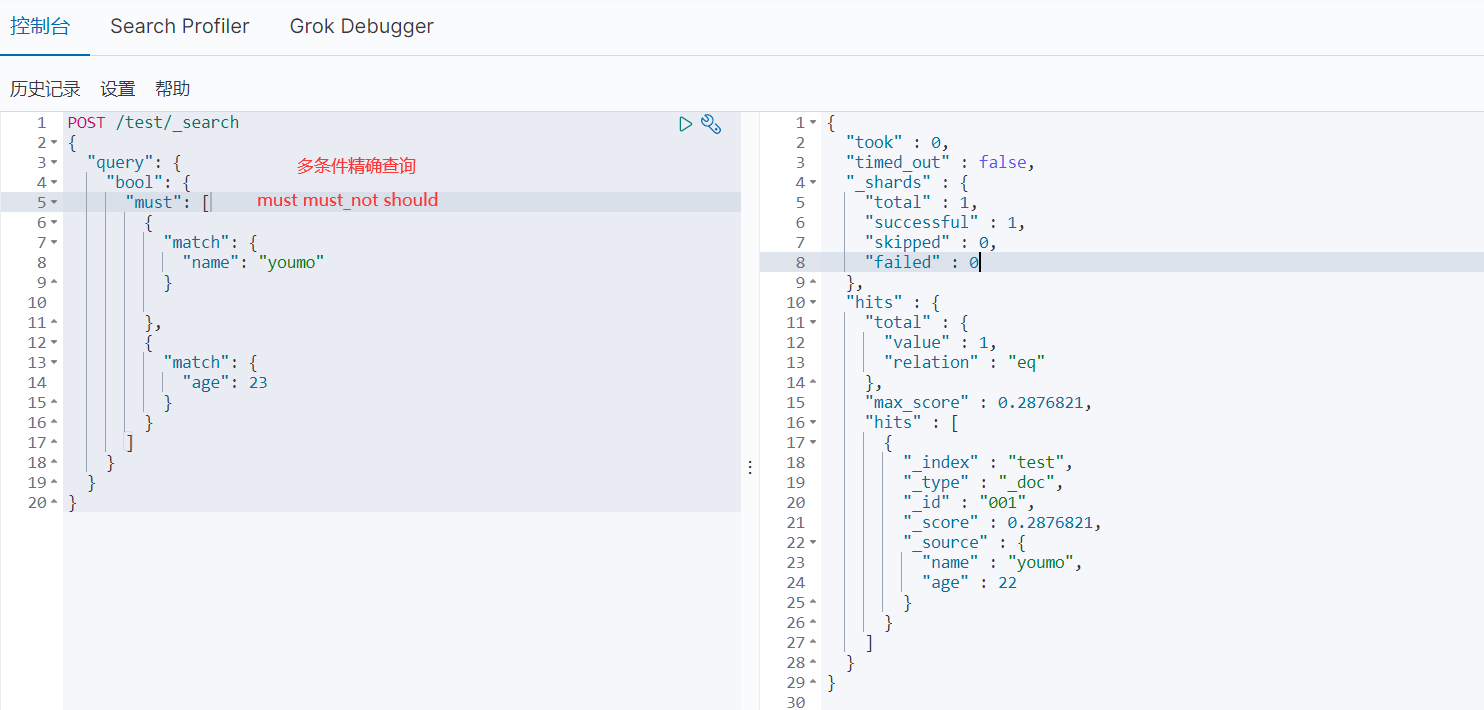
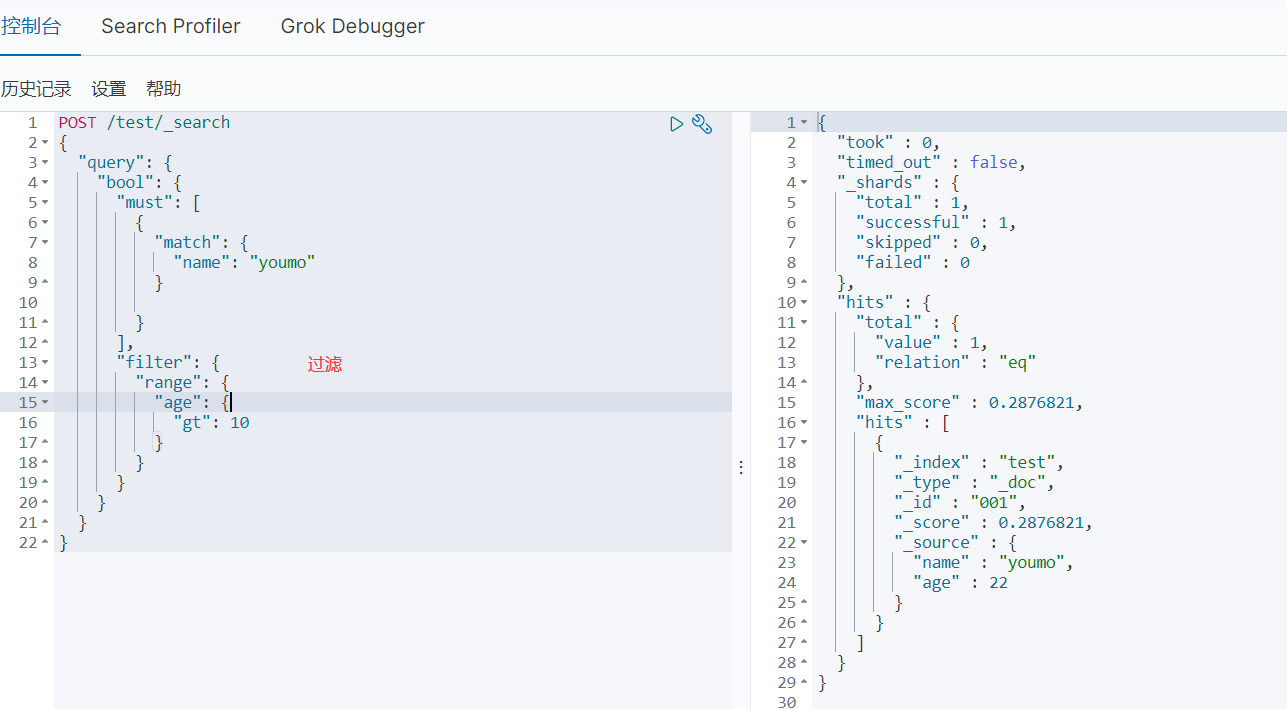
- filter数据过滤
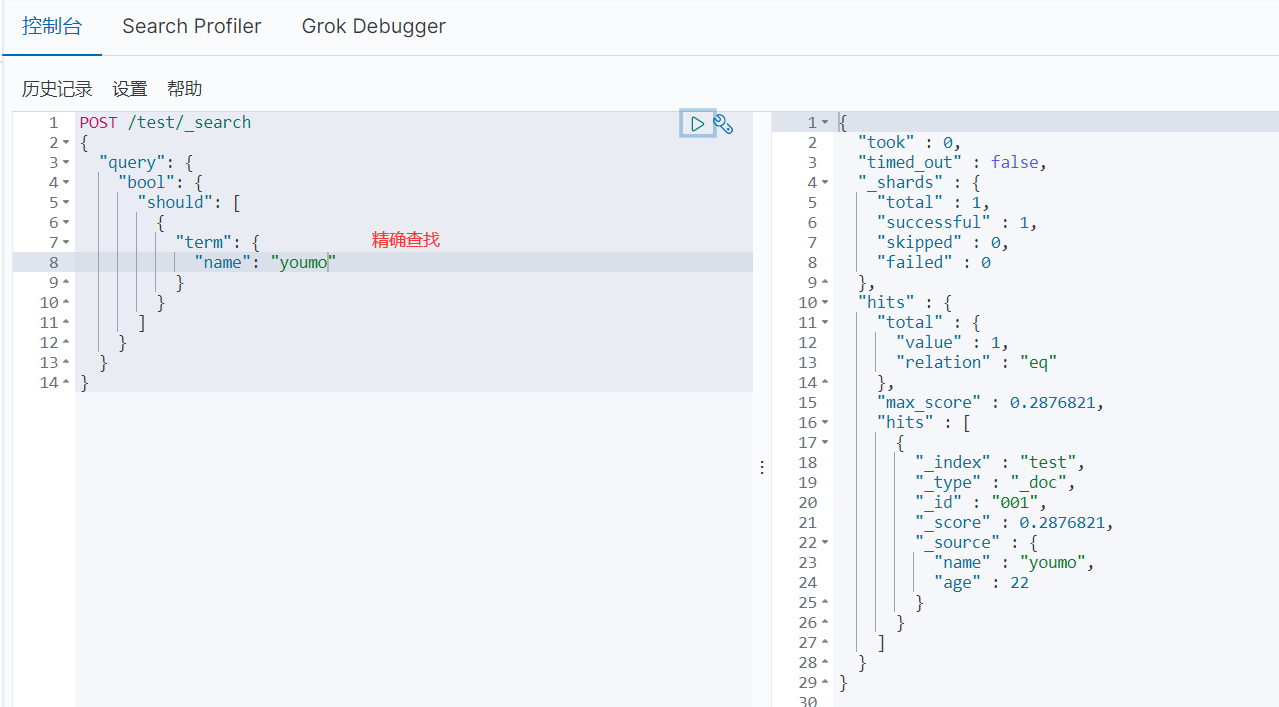
- 精确查询,match在匹配时会对所查找的关键词进行分词,然后按分词匹配查找,而term会直接对关键词进行查找
- 高亮查询
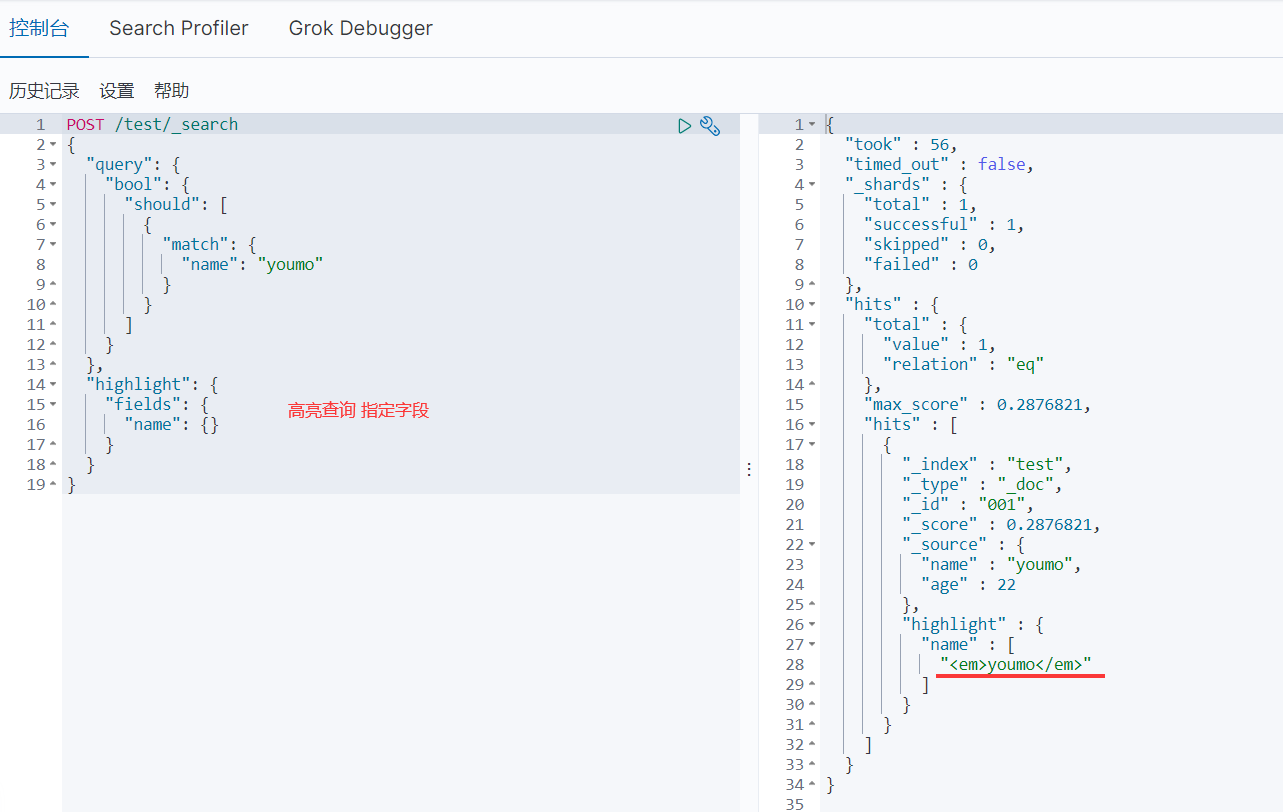
- 自定义高亮
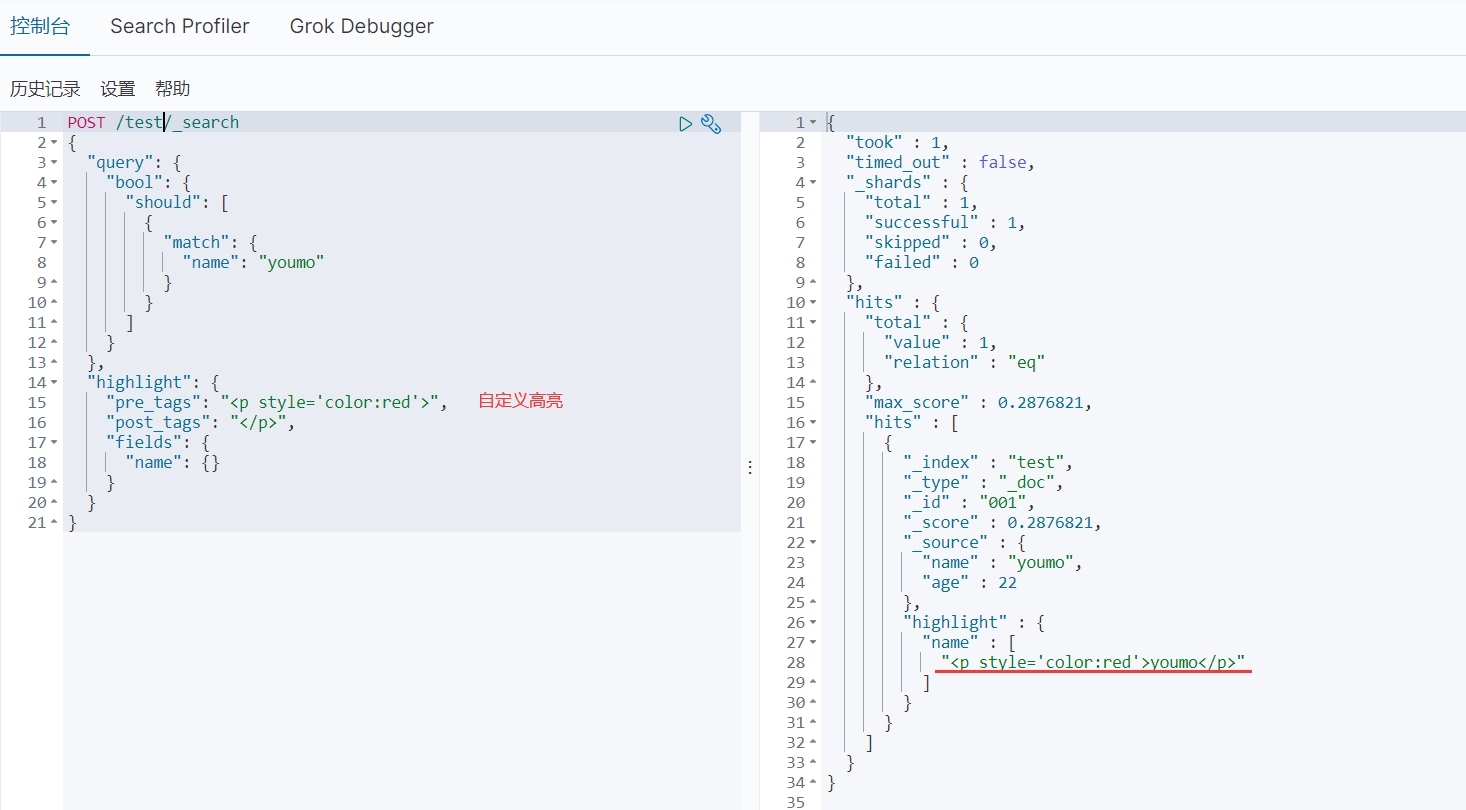
9、SpringBoot集成ES
- maven依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
- 自定义elasticsearch版本,和es服务器版本一致
<properties>
<!--自定义es版本,保证和本地es服务一致-->
<elasticsearch.version>7.6.1</elasticsearch.version>
</properties>
- ES配置文件,常见客户端对象
@Configuration
public class ElasticSearchConfig {
@Bean
public RestHighLevelClient restHighLevelClient(){
RestHighLevelClient client = new RestHighLevelClient(
RestClient.builder(
new HttpHost("127.0.0.1",9200,"http")
)
);
return client;
}
}
- ES测试
@SpringBootTest
class EsApiApplicationTests {
@Autowired
@Qualifier("restHighLevelClient")
private RestHighLevelClient client;
//索引的创建
@Test
void createIndex() throws IOException {
//创建索引请求
CreateIndexRequest request = new CreateIndexRequest("test");
//执行请求 IndicesClient ,请求成功响应CreateIndexResponse对象
CreateIndexResponse createIndexResponse = client.indices().create(request, RequestOptions.DEFAULT);
}
//判断索引是否存在
@Test
void ExistIndex() throws IOException {
//获取索引请求
GetIndexRequest request = new GetIndexRequest("test");
//执行请求
boolean exists = client.indices().exists(request, RequestOptions.DEFAULT);
}
//删除索引
@Test
void deleteIndex() throws IOException{
//删除索引请求
DeleteIndexRequest request = new DeleteIndexRequest("test");
//执行请求
AcknowledgedResponse delete = client.indices().delete(request, RequestOptions.DEFAULT);
}
//添加文档
@Test
void addDocument() throws IOException {
//创建对象
User user = new User("cml", 22);
//创建请求
IndexRequest request = new IndexRequest("test");
//规则 put /test/_doc/1
request.id("1");
//将数据放入请求
IndexRequest source = request.source(JSON.toJSONString(user), XContentType.JSON);
//客户端发送请求,获取响应的结果
IndexResponse indexResponse = client.index(request, RequestOptions.DEFAULT);
}
//获取文档
@Test
void ExistDocument() throws IOException{
//获取文档请求
GetRequest request = new GetRequest("test", "1");
//判断是否存在
boolean exists = client.exists(request, RequestOptions.DEFAULT);
//获取文档内容
GetResponse documentFields = client.get(request, RequestOptions.DEFAULT);
}
//更新文档
@Test
void updateDocument() throws IOException {
//更新文档请求
UpdateRequest request = new UpdateRequest("test", "1");
//创建对象
User user = new User("youmo", 22);
request.doc(JSON.toJSONString(user),XContentType.JSON);
//执行请求
UpdateResponse update = client.update(request, RequestOptions.DEFAULT);
}
//删除文档
@Test
void deleteDocument() throws IOException{
//删除文档请求
DeleteRequest request = new DeleteRequest("test", "1");
//客户端执行请求
DeleteResponse delete = client.delete(request, RequestOptions.DEFAULT);
}
//查询
@Test
void Search() throws IOException {
//搜索请求
SearchRequest request = new SearchRequest("test");
//构建搜索条件
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
//查询条件
TermQueryBuilder termQueryBuilder = QueryBuilders.termQuery("name", "youmo");
sourceBuilder.query(termQueryBuilder);
request.source(sourceBuilder);
//执行搜索
SearchResponse search = client.search(request, RequestOptions.DEFAULT);
}
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号