神经网络学习-优化算法5
优化算法
本次主要对动量梯度下降算法,RMSprop算法,Adam优化算法的学习进行一个总结,主要对这几个算法的公式和原理进行介绍,对于代码部分可以参考:
https://blog.csdn.net/u013733326/article/details/79907419
mini-batch梯度下井
当一个数据集较大时,比如这个数据集内有100万条不同的数据,面对这种情况,想直接使用梯度下降算法对神经网络进行训练,在没有高性能的CPU和GPU的情况下是难以实现的,所以我们需要对梯度下降算法进行优化,加快梯度下将。面对大数据集的情况,很多时候可以对数据集进行划分,将数据集划分为小数据集,之后对所有的小数据集进行一个梯度下降,这就是mini-batch梯度下降算法。
假设我们有数据集\(X,Y\),\(X\)是(n,m)的矩阵,\(Y\)(1,m)的矩阵,n是数据数据特征数,m是数据条数。对数据进行划分,划分后的结果为:
对于每个数据集我们划分\(n_x\)个数据,整个数据集被划分类b个小数据集,通常\(n_x\)是4的倍数,可以符合计算机的位宽。
具体的代码可以查看下面
for i in range(num_epochs):#进行迭代,下方进行梯度下降
minibatches=random_mini_batch(X,Y,mini_batch_size)#获取划分后的数据
for minibatch in minibatches:
X,Y=minibatch
A,cache=forward_propagation(X,parameters)#进行向前传播
grads=back_propagation(X,Y,cache)#向后传播
parameters=update_parameters(parameters,grads,learning_rate)#跟新参数
动量梯度下降算法
动量梯度算法是基于加权平均数的一种算法,加权平均数主要是用于计算一段时间内的平均值的算法。具体流程如下:
在每一次更新数据时,不用更新梯度,而是更新加权平均数
其中\(\alpha\)表示学习率,\(\beta\)表示加权值,默认为0.9,初始情况下将\(V _{dw}和V_{db}\)都初始化为0。
RMSporp算法
RMSprop的算法,全称是root mean square prop算法,它也可以加速梯度下降,我们来看看它是如何运作的。假设纵轴代表参数b,横轴代表参数W,可能有W1,W2等重要的参数,为了便于理解,使用b和W。具体操作如下:
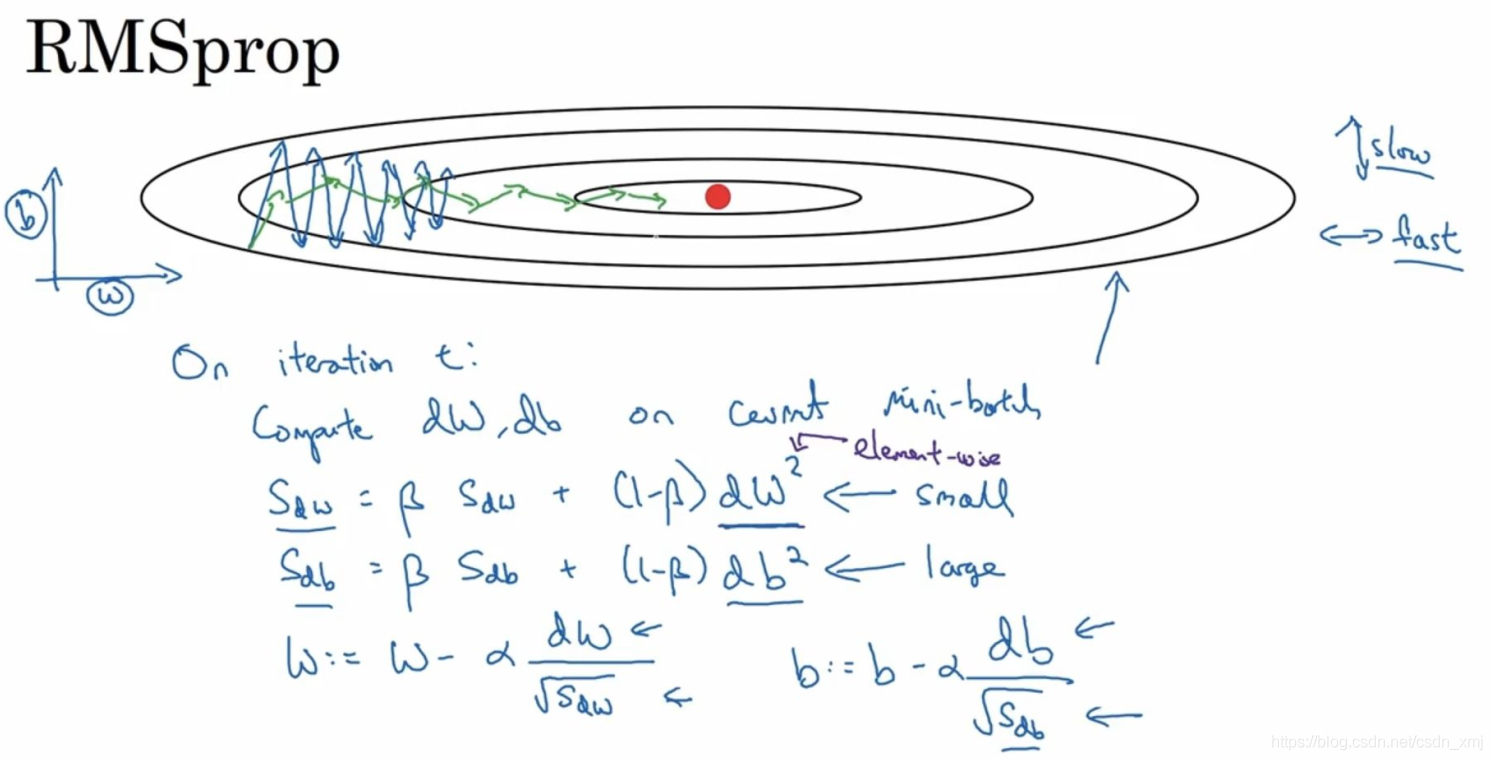
如果你想减缓b方向的学习(纵轴方向),同时加快,至少不减慢横轴方向的学习,RMSprop算法可以实现这一点。在t次迭代中,其权重W和常数项b的更新表达式为:(注意平方是针对整个符号而言的,dW的平方)
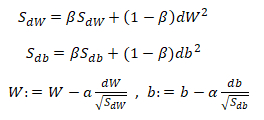
下面解释一下原理。我们希望在横轴(W方向)学习速度快,而在纵轴(b方向)减缓摆动,所以有了S_dW和S_db,所以我们W要除以一个较小的数(S_dW会相对较小),同理b要除以较大的数(S_db较大),这样就可以减缓纵轴上的变化。这些微分中,db较大,dW较小,也可观察函数的倾斜程度,纵轴要大于在横轴,公式处理的结果就是纵轴上的更新要被一个较大的数相除,就能消除摆动,而水平方向的更新则被较小的数相除。
原文链接:https://blog.csdn.net/csdn_xmj/article/details/115135627
Adam算法
Adam优化算法基本上就是将Momentum和RMSprop结合在一起,那么来看看如何使用Adam算法。
之后进行参数修正:
进行参数更新:
这里的\(\beta_1、\beta_2\)是不同的参数,默认0.9,\(\varepsilon\)是个极小值用于保证分母不为0。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号