SSRF漏洞挖掘经验
SSRF概述
SSRF(Server-Side Request Forgery:服务器端请求伪造) 是一种由攻击者构造形成由服务端发起请求的一个安全漏洞。一般情况下,SSRF攻击的目标是从外网无法访问的内部系统。(正是因为它是由服务端发起的,所以它能够请求到与它相连而与外网隔离的内部系统)
SSRF 形成的原因大都是由于服务端提供了从其他服务器应用获取数据的功能且没有对目标地址做过滤与限制。比如从指定URL地址获取网页文本内容,加载指定地址的图片,下载等等。
SSRF 漏洞的寻找
一、从WEB功能上寻找
我们从上面的概述可以看出,SSRF是由于服务端获取其他服务器的相关信息的功能中形成的,因此我们大可以列举几种在web 应用中常见的从服务端获取其他服务器信息的的功能。
1)分享:通过URL地址分享网页内容
早期分享应用中,为了更好的提供用户体验,WEB应用在分享功能中,通常会获取目标URL地址网页内容中的<tilte></title>标签或者<meta name="description" content=“”/>标签中content的文本内容作为显示以提供更好的用户体验。例如人人网分享功能中:
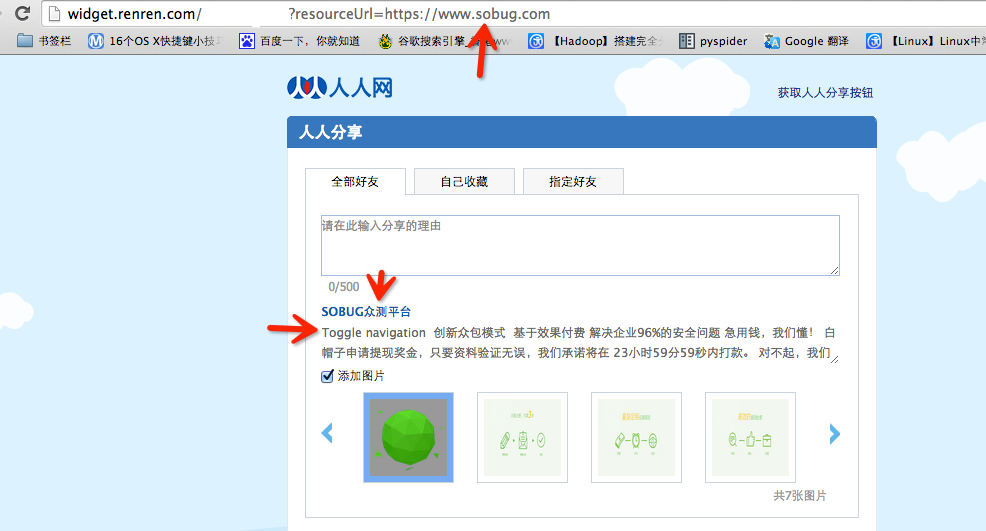
|
1
|
http://widget.renren.com/*****?resourceUrl=https://www.sobug.com |
通过目标URL地址获取了title标签和相关文本内容。而如果在此功能中没有对目标地址的范围做过滤与限制则就存在着SSRF漏洞。
根寻这个功能,我们可以发现许多互联网公司都有着这样的功能,下面是我从百度分享集成的截图如下:
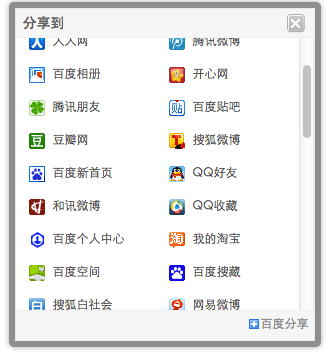
从国内某漏洞提交平台上提交的SSRF漏洞,可以发现包括淘宝、百度、新浪等国内知名公司都曾被发现过分享功能上存在SSRF的漏洞问题。
2)转码服务:通过URL地址把原地址的网页内容调优使其适合手机屏幕浏览
由于手机屏幕大小的关系,直接浏览网页内容的时候会造成许多不便,因此有些公司提供了转码功能,把网页内容通过相关手段转为适合手机屏幕浏览的样式。例如百度、腾讯、搜狗等公司都有提供在线转码服务。
3)在线翻译:通过URL地址翻译对应文本的内容。提供此功能的国内公司有百度、有道等
4)图片加载与下载:通过URL地址加载或下载图片
图片加载远程图片地址此功能用到的地方很多,但大多都是比较隐秘,比如在有些公司中的加载自家图片服务器上的图片用于展示。(此处可能会有人有疑问,为什么加载图片服务器上的图片也会有问题,直接使用img标签不就好了? ,没错是这样,但是开发者为了有更好的用户体验通常对图片做些微小调整例如加水印、压缩等,所以就可能造成SSRF问题)。
5)图片、文章收藏功能
此处的图片、文章收藏中的文章收藏就类似于功能一、分享功能中获取URL地址中title以及文本的内容作为显示,目的还是为了更好的用户体验,而图片收藏就类似于功能四、图片加载。
6)未公开的api实现以及其他调用URL的功能
此处类似的功能有360提供的网站评分,以及有些网站通过api获取远程地址xml文件来加载内容。
在这些功能中除了翻译和转码服务为公共服务,其他功能均有可能在企业应用开发过程中遇到。
二、从URL关键字中寻找
在对功能上存在SSRF漏洞中URL地址特征的观察,通过我一段时间的收集,大致有以下关键字:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
sharewapurllinksrcsourcetargetu3gdisplaysourceURlimageURLdomain... |
如果利用google 语法加上这些关键字去寻找SSRF漏洞,耐心的验证,现在还是可以找到存在的SSRF漏洞。
SSRF 漏洞的验证
1)基本判断(排除法)
例如:
|
1
|
http://www.douban.com/***/service?image=http://www.baidu.com/img/bd_logo1.png |
排除法一:
你可以直接右键图片,在新窗口打开图片,如果是浏览器上URL地址栏是http://www.baidu.com/img/bd_logo1.png,说明不存在SSRF漏洞。
排除法二:
你可以使用burpsuite等抓包工具来判断是否不是SSRF,首先SSRF是由服务端发起的请求,因此在加载图片的时候,是由服务端发起的,所以在我们本地浏览器的请求中就不应该存在图片的请求,在此例子中,如果刷新当前页面,有如下请求,则可判断不是SSRF。(前提设置burpsuite截断图片的请求,默认是放行的)
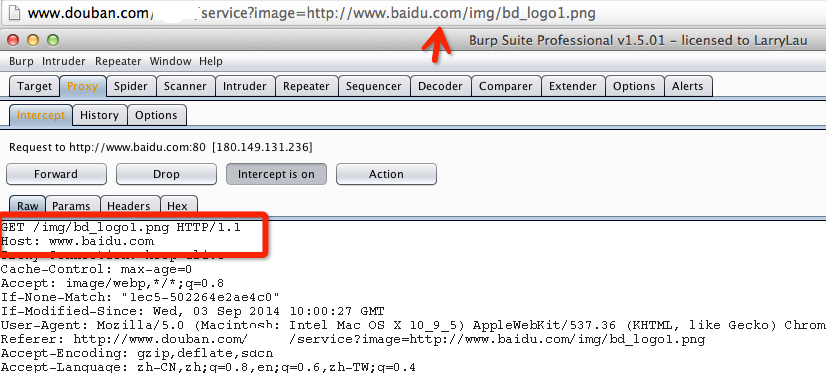
此处说明下,为什么这边用排除法来判断是否存在SSRF,举个例子:

|
1
|
http://read.*******.com/image?imageUrl=http://www.baidu.com/img/bd_logo1.png |
现在大多数修复SSRF的方法基本都是区分内外网来做限制(暂不考虑利用此问题来发起请求,攻击其他网站,从而隐藏攻击者IP,防止此问题就要做请求的地址的白名单了),如果我们请求 :
|
1
|
http://read.******.com/image?imageUrl=http://10.10.10.1/favicon.ico |
而没有内容显示,我们是判断这个点不存在SSRF漏洞,还是http://10.10.10.1/favicon.ico这个地址被过滤了,还是http://10.10.10.1/favicon.ico这个地址的图片文件不存在,如果我们事先不知道http://10.10.10.1/favicon.ico这个地址的文件是否存在的时候是判断不出来是哪个原因的,所以我们采用排除法。
2)实例验证
经过简单的排除验证之后,我们就要验证看看此URL是否可以来请求对应的内网地址。在此例子中,首先我们要获取内网存在HTTP服务且存在favicon.ico文件的地址,才能验证是否是SSRF漏洞。
找存在HTTP服务的内网地址:
一、从漏洞平台中的历史漏洞寻找泄漏的存在web应用内网地址
二、通过二级域名暴力猜解工具模糊猜测内网地址

|
1
|
example:ping xx.xx.com.cn |
可以推测10.215.x.x 此段就有很大的可能: http://10.215.x.x/favicon.ico 存在。
在举一个特殊的例子来说明:
|
1
|
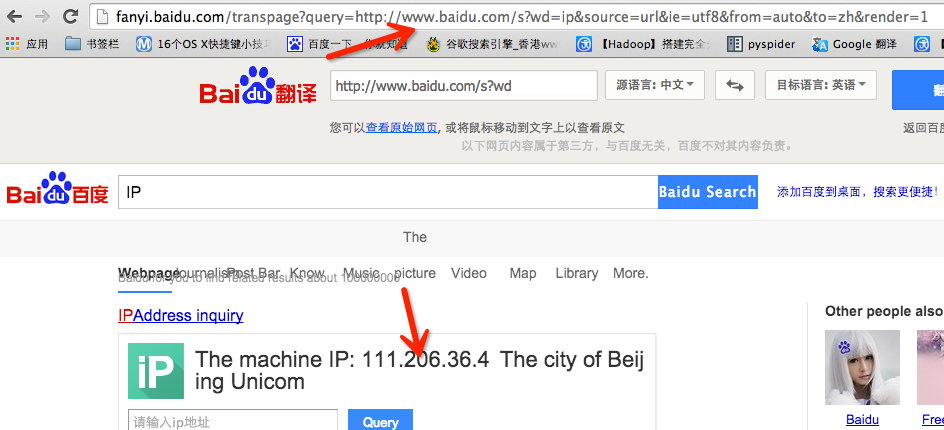
此处得到的IP 不是我所在地址使用的IP,因此可以判断此处是由服务器发起的http://www.baidu.com/s?wd=ip 请求得到的地址,自然是内部逻辑中发起请求的服务器的外网地址(为什么这么说呢,因为发起的请求的不一定是fanyi.baidu.com,而是内部其他服务器),那么此处是不是SSRF,能形成危害吗? 严格来说此处是SSRF,但是百度已经做过了过滤处理,因此形成不了探测内网的危害。
SSRF 漏洞中URL地址过滤的绕过
1)http://www.baidu.com@10.10.10.10与http://10.10.10.10 请求是相同的
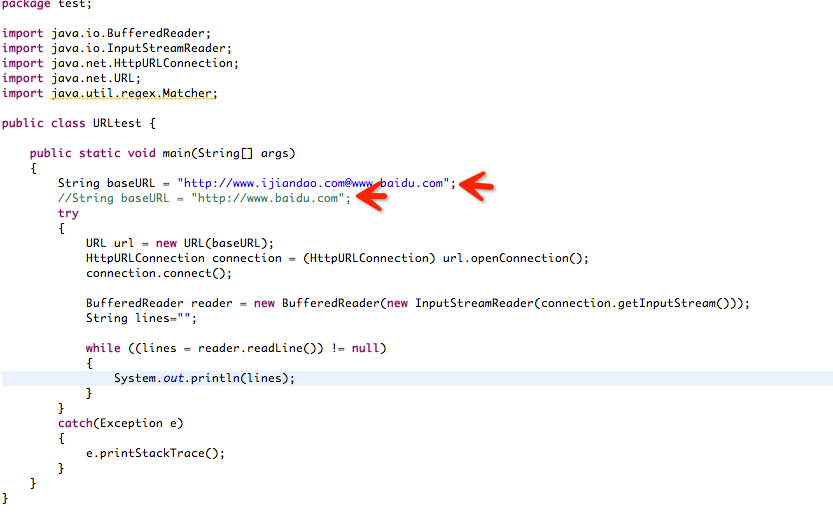
此脚本访问请求得到的内容都是www.baidu.com的内容。
2)ip地址转换成进制来访问
|
1
|
115.239.210.26 = 16373751032 |
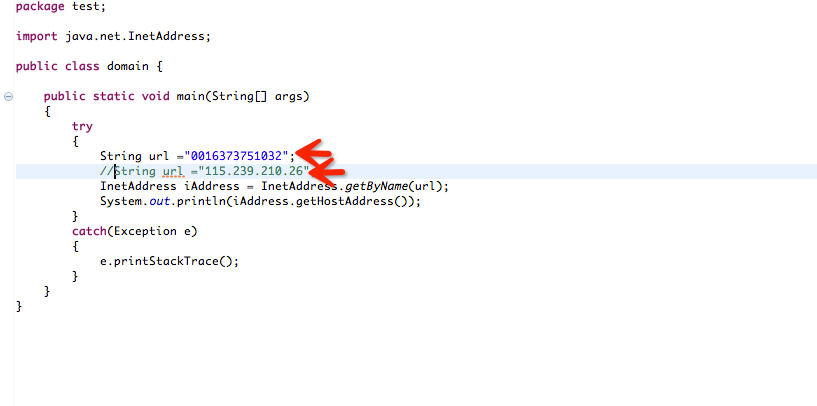
此脚本解析的地址都是 115.239.210.26,也可以使用ping 获取解析地址:
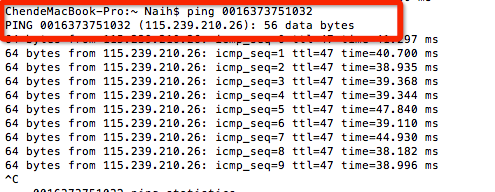
如果WEB服务简单的过滤参数中获取的URL地址,没有判断真正访问的地址,是有可能被此两种方法绕过的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号{kind=link}