
大批量数据删除语句的优化
一、场景
有个离奇的场景,Oracle数据库有两张千万级数据量的表A、B。A和B的对应关系为一对多,从A表中删除主键ID不在B表中的数据。
二、SQL优化
-
原删除语句
DELETE FROM A A WHERE A.ID NOT IN ( SELECT T.A_ID FROM B T WHERE T.FLAG = '1' );![]()
执行计划如上图,没有对比就没有伤害,下面对比着看吧。
-
调整两种删除语句,对比执行计划
-
第一种
由于B表中的存储外键,所以有重复的情况,所以这里对not in里面的值的数据量进行去重,减少后约有63000多外键。
DELETE FROM A A WHERE A.ID NOT IN ( SELECT DISTINCT T.A_ID FROM B T WHERE T.FLAG = '1' AND T.A_ID IS NOT NULL )![]()
从执行计划上看,减少not in的数据量是可以减少资源消耗的,尽管不是很多。
-
第二种
not in意味着每条数据都要进行6万多次的对比,这里使用not exists,每条数据进行一次子查询判断是否应该被删除。
DELETE FROM A A WHERE NOT EXISTS ( SELECT 1 FROM B T WHERE T.FLAG = '1' AND T.A_ID = A.ID )![]()
但是很可惜,从执行计划上看上面两种语句的效果是一样的。这里值得注意的是,Oracle的优化器在处理NOT EXISTS时,默认对非主键字段做了去重操作。也就是因为这样,这两种sql在执行计划上是一样的。
第一种每条数据多次循环判断,第二种每条数据都需要扫描索引查询。在测试删除的过程中两种sql都会卡死。。。。
-
-
对sql语句进行了再优化
在sql语句但凡带了NOT、>、<、LIKE都会造成全表(全索引)扫描,如果不能避免全表(全索引)扫描,那么就找找减少全表(全索引)扫描次数的方法。
这里想要精确定位到要删除的数据,就用视图缓存要删除的主键,所以将sql改成这样:
DELETE FROM A T WHERE T.ID = ( SELECT A.ID FROM A A LEFT JOIN B B ON A.ID = B.A_ID AND B.FLAG = '1' WHERE B.A_ID IS NULL AND A.ID = T.ID )![]()
更改后的sql,从执行计划上看已经有非常大的改观了。
可是实际跑起来就是无尽的等待。。。没法了给后面加上
AND ROWNUM < 1000000后,基本上两分钟内会删除结束,每次结束赶紧commit。




三、换个思路
直接上SQL:
CREATE TABLE A_BAK AS
SELECT A.* FROM A A
JOIN (SELECT DISTINCT T.A_ID FROM B T WHERE T.FLAG = '1' AND T.A_ID IS NOT NULL) B
ON A.ID = B.A_ID AND B.FLAG = '1'
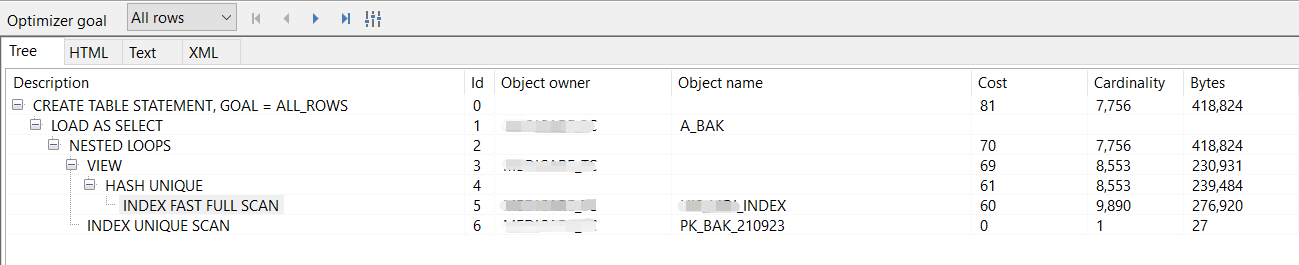
这么多数据要删除,这么难搞,还是重新建表吧。这样B表索引全扫描创建视图,与A表唯一索引循环hash关联,拿到所有不需要删除的数据放到一张新表中。
这个执行计划中,由于oracle优化器的干预,所以是按照先创建视图(结果是个小表),再关联A表(千万数据的大表)。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号