
Kettle工具常用操作
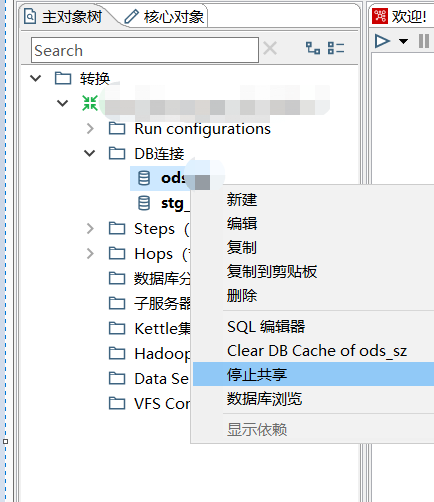
1.设置共享DB连接
设置DB连接共享后,可以避免每次创建转换时,重复创建相同数据源的窘境。
2.Kettle引入自定义java的工具jar包
2.1.编写Java工具类
2.2.将项目打成jar包

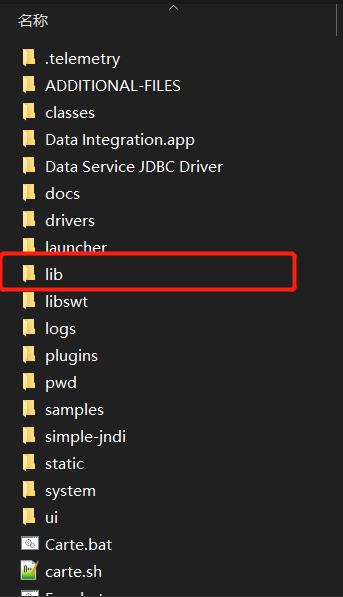
2.3.将jar包拷贝到Kettle的lib目录下,然后启动kettle工具
2.4.kettle创建JavaScript脚本,引入并使用自定义jar包类;
//Script here
var utl = new Packages.com.pga.pky.FormatUtils();
var optTime = utl.char2Date(OPT_TIME);
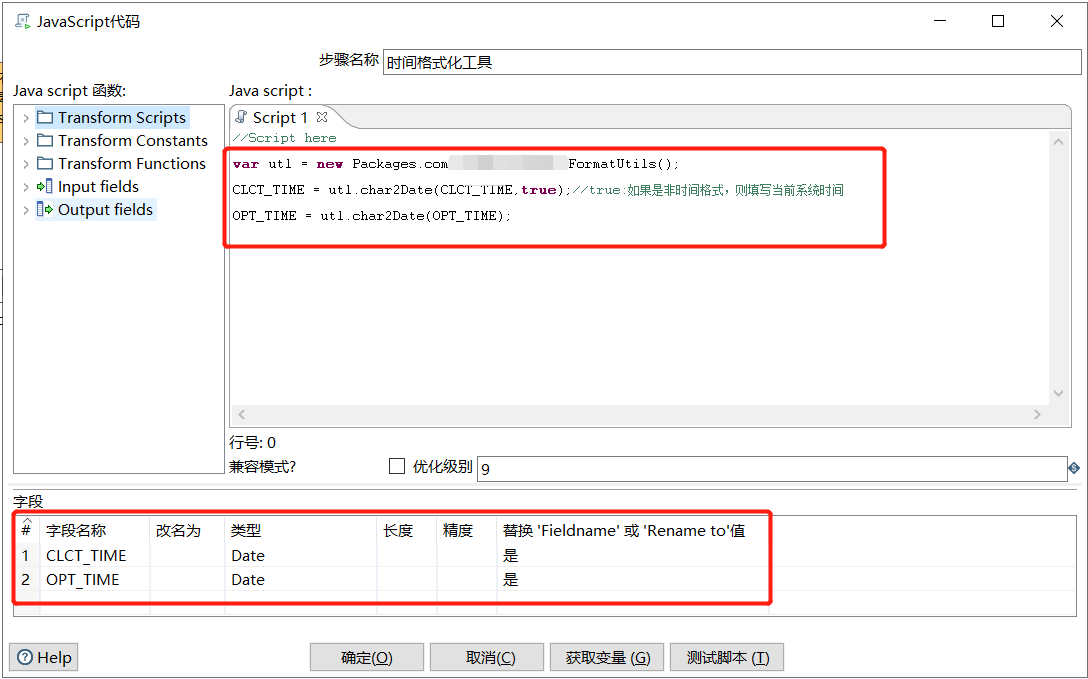
建议使用兼容模式对变量进行取值,赋值操作。(图示没有使用兼容模式)
3.Kettle引入自定义js文件
代码示例如下:
//Script here
//js文件相对于kettle工具根目录的路径
var path =getVariable("Internal.Transformation.Filename.Directory", "相对路径");
LoadScriptFile(path +"/common_Functions.js");
//-----------------------------------------------------------------------------------
var mpType = getVariable("MPTYPE","");
var cycleCount = str2num(getVariable("COLLECT_CYCLE_COUNT","1"));
var prevCycle = str2num(getVariable("CYCLE_PREV_VALUE","0"));
//调用js文件中的方法
var colInfo = initCycleTime(mpType, prevCycle, cycleCount);
var startTime = date2str(colInfo[0], "yyyy-MM-dd HH:mm:ss");
var endTime = date2str(colInfo[1], "yyyy-MM-dd HH:mm:ss");
writeToLog("m","时间:"+startTime+" -> "+endTime);
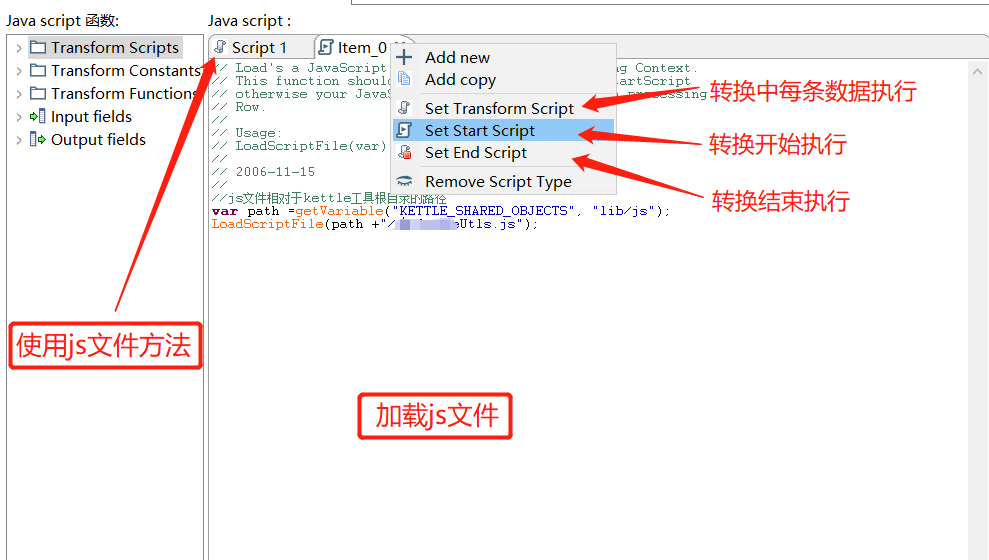
3.1.获取js的路径参数
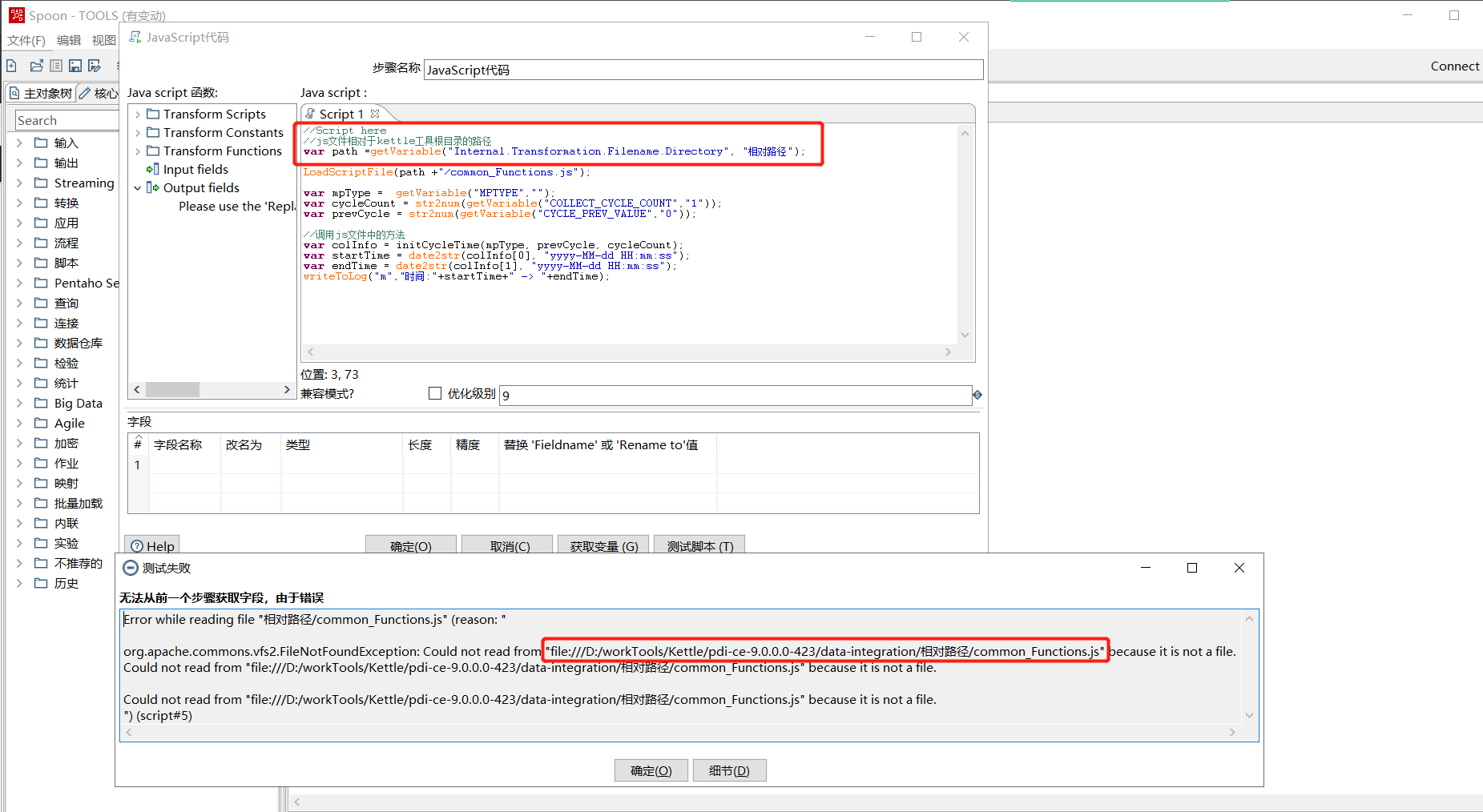
3.2.从StartScript加载文件
注意kettle调用示例:将一个javascript文件加载到实际的运行上下文中。应该从定义的StartScript调用此函数,否则,每次处理都会加载javascript文件行。
4.Linux服务器安装kettle
4.1.kettle程序解压到指定目录即可
#查看jdk版本
java -version
#进入/pdi-ce-7.1.0.0-12/data-integration/目录下
ls -l
#查看*.sh文件是否为可执行状态
#如果为不可执行状态,则执行
chmod +x *.sh
#测试是否赋权成功
./kitchen.sh
./kitchen.sh输出信息如下:
#######################################################################
WARNING: no libwebkitgtk-1.0 detected, some features will be unavailable
Consider installing the package with apt-get or yum.
e.g. 'sudo apt-get install libwebkitgtk-1.0-0'
#######################################################################
OpenJDK 64-Bit Server VM warning: ignoring option MaxPermSize=256m; support was removed in 8.0
Options:
-rep = Repository name
-user = Repository username
-pass = Repository password
-job = The name of the job to launch
-dir = The directory (dont forget the leading /)
-file = The filename (Job XML) to launch
-level = The logging level (Basic, Detailed, Debug, Rowlevel, Error, Minimal, Nothing)
-logfile = The logging file to write to
-listdir = List the directories in the repository
-listjobs = List the jobs in the specified directory
-listrep = List the available repositories
-norep = Do not log into the repository
-version = show the version, revision and build date
-param = Set a named parameter <NAME>=<VALUE>. For example -param:FILE=customers.csv
-listparam = List information concerning the defined parameters in the specified job.
-export = Exports all linked resources of the specified job. The argument is the name of a ZIP file.
-custom = Set a custom plugin specific option as a String value in the job using <NAME>=<Value>, for example: -custom:COLOR=Red
-maxloglines = The maximum number of log lines that are kept internally by Kettle. Set to 0 to keep all rows (default)
-maxlogtimeout = The maximum age (in minutes) of a log line while being kept internally by Kettle. Set to 0 to keep all rows indefinitely (default)
4.2.kettle从资源库获取ETL脚本
#找到安装kettle用户的用户目录
cd ~
#将windows中用户目录下的.kettle(隐藏文件)文件夹拷贝到当前目录(Linux下的用户目录)
ls -a #查看所有文件,包含隐藏文件
#进入.kettle文件夹,修改/查看资源库配置文件repositories.xml
配置文件内容
<?xml version="1.0" encoding="UTF-8"?>
<repositories>
<connection>
.....
</connection>
<repository> <id>KettleFileRepository</id>
<name>fileRepository</name>
<description>filereposity</description>
<read_only>N</read_only>
<hides_hidden_files>N</hides_hidden_files>
<connection>.....</connection>
</repository>
</repositories>
5.启动kettle转换脚本和作业脚本
启动命令语法:
#执行job
sh /opt/kettle/kitchen.sh -rep=资源库名称 -user=(登陆资源库的)用户名 -pass=密码 -dir=脚本所在目录 -job=脚本名 -level=Basic > /opt/kettle/log/etl.log
#执行转换
sh /opt/kettle/pan.sh -rep=资源库名称 -user=(登陆资源库的)用户名 -pass=密码 -dir=脚本所在目录 -trans=脚本名 -level=Basic > /opt/kettle/log/etl.log
参考脚本:
#!/bin/sh
REP='fileRepository'
USER="$1"
PASS="$2"
DIR="$3"
FILE="$4"
TYPE="$5"
if test -e /opt/kettle/log"$DIR"
then
echo '日志目录已存在'
else
mkdir -p /opt/kettle/log"$DIR"
echo '日志目录已创建'
fi
if [ "$TYPE" = "JOB" ] || [ "$TYPE" = "job" ]; then
nohup sh /opt/kettle/pdi-ce-7.1.0.0-12/data-integration/kitchen.sh -rep="$REP" -user="$USER" -pass="$PASS" -dir="$DIR" -job="$FILE" -level=Basic > "/opt/kettle/log$DIR$FILE.log" 2>&1 &
echo '执行:kitchen.sh'
else
nohup sh /opt/kettle/pdi-ce-7.1.0.0-12/data-integration/pan.sh -rep="$REP" -user="$USER" -pass="$PASS" -dir="$DIR" -trans="$FILE" -level=Basic > "/opt/kettle/log$DIR$FILE.log" 2>&1 &
echo '执行:pan.sh'
fi
echo "账号:$USER 密码:$PASS"
echo "目录:$DIR 文件:$FILE 类型:$TYPE"
echo "日志路径:/opt/kettle/log$DIR$FILE.log"
exit
6.提升ETL脚本导入MySQL数据库效率
useServerPrepStmts:如果服务器支持,是否使用服务器端预处理语句 默认值为“true” 调整为“ false”
rewriteBatchedStatements是否批量执行(对于insert,驱动则会把多条sql语句重写成一条风格很酷的sql语句,然后再发出去。 官方文档说,这种insert写法可以提高性能【对delete和update,驱动所做的事就是把多条sql语句累积起来再一次性发出去】)“true”
useCompression压缩数据传输,优化客户端和MySQL服务器之间的通信性能 “true”
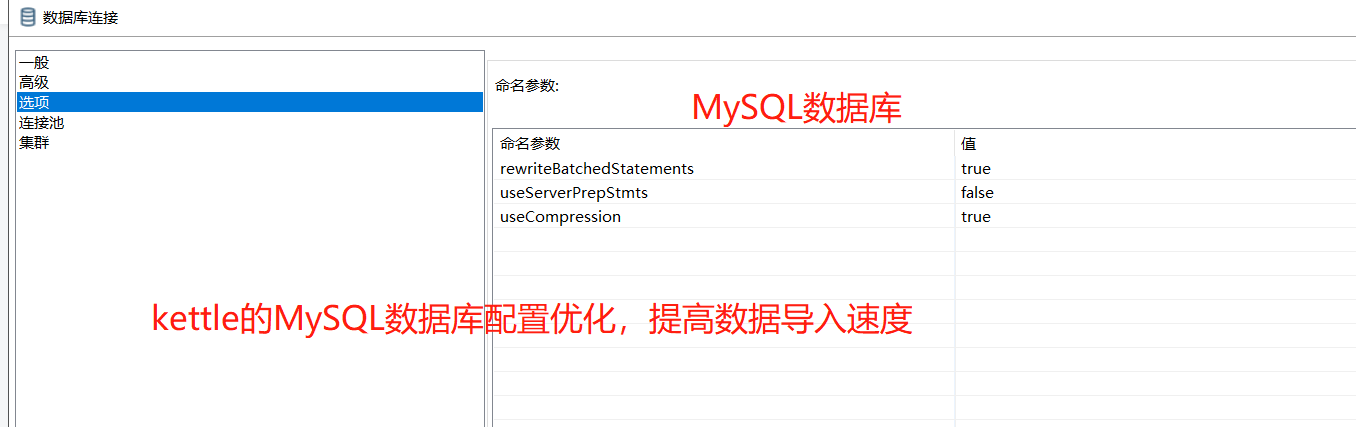
characterEncoding:此处也可以设置字符及编码,用于解决数据库字符集不同造成的中文乱码问题。如:utf8
Kettle日志级别
Kettle的日志级别LogLevel分为以下几个:
- Nothing 没有日志 不显示任何输出
- Error 错误日志 仅仅显示错误信息
- Minimal 最小日志 使用最小的日志
- Basic 基本日志 缺省的日志级别
- Detailed详细日志 给出日志输出的细节
- Debug 调试日志 调试目的,调试输出
- Rowlevel行级日志 打印出每一行记录的信息
大批量数据转换时,将日志级别调整为:Error 错误日志 仅仅显示错误信息 ,也可以提升数据转换速度。
7.js中可以通过getVariable(var, var)获取的变量列举:
内置变量
| 变量 | 描述 |
|---|---|
| Internal.Kettle.Version | 这是kettle的版本号,比如4.0.0 |
| Internal.Kettle.Build.Version | 这是kettle源代码的SVN的修订号 |
| Internal.Kettle.Build.Date | 这是kettle的build日期 |
| Internal.Job.Filename.Directory | 如果使用文件方式运行作业(.kjb),这个变量就是作业文件所在的目录。里用这个变量用户可以指定其它文件 |
| Internal.Job.Filename.Name | 如果使用文件方式运行作业(.kjb),这个变量就是作业文件名 |
| Internal.Job.Name | 当前正在执行的作业的名字 |
| Internal.Transformation.Repository.Directory | 如果使用资源库方式执行转换,这个变量是转换所在资源库目录的路径 |
| Internal.Step.Partition.ID | 如果一个步骤是以分区方式运行的,每个分区都有一个步骤拷贝。这个变量就是步骤拷贝所属的分区ID |
| Internal.Step.Partition.Number | 如果一个步骤是以分区方式运行的,每个分区都有一个步骤拷贝器。这个变量就是步骤拷贝所属的分区编号,分区编号从0到分区个数减1 |
| Internal.Slave.Transformation.Number | 如果转换在子服务器上以集群方式运行,这个变量就是子服务器的名字 |
| Internal.Cluster.Size | 如果转换在子服务器上以集群方式运行,这个变量就是集群中子服务器的个数 |
| Internal.Step.Unique.Number | 这个变量是指定步骤的步骤拷贝的唯一编号。这个变量同样适用于分区和集群环境。取值从0到步骤拷贝个数减1 |
| Internal.Cluster.Master | 若转换以集群方式运行,如果是运行在主服务器上,这个值是Y,如果是运行在子服务器上,这个值是N |
| Internal.Step.Unique.Count | 唯一的步骤拷贝个数。也适用于集群或分区的情况 |
| Internal.Step.Name | 正在执行的步骤的名字 |
| Internal.Step.CopyNr | 本地转换的步骤拷贝号(不考虑集群的情况) |
kettle变量
| 变量 | 描述 |
|---|---|
| KETTLE_SHARED_OBJECTS | 作业和转换的共享对象文件的位置。默认的共享对象文件shared.xml,位于Kettle Home 目录下。设置这个变量可以覆盖默认值 |
| KETTLE_EMPTY_STRING_DIFFERS_FROM_NULL | 如果这个变量设置为Y,空字符串和null是不同的,否则就是相同的(默认) |
| KETTLE_MAX_LOG_SIZE_IN_LINES | kettle初始的最大日志行数。设置为0将保留所有日志行(默认) |
| KETTLE_MAX_LOG_TIMEOUT_IN_MINUTES | kettle中日志行的最长保留时间(单位:分钟)。设置为0将保留所有行(默认) |
| KETTLE_STEP_PERFORMANCE_SNAPSHOT_LIMIT | 内存中的最大步骤性能快照数。设置为0将保留所有快照(默认) |
| KETTLE_PLUGIN_CLASSES | 逗号分隔的类名列表,用来查找插件iandeannotation。参考http://wiki.pentaho.com/display/EAI/How+to+debug+a+Kettle+4+plugin |
| KETTLE_LOG_SIZE_LIMIT | 如果在转换和作业的日志表的配置izhong没有设置“日志行数限制”参数,这类转换和作业将统一使用这个参数作为最大日志行 |
- TRANS:对于转换日志表。
- TRANS_PERFORMANCE:对于性能日志表。
- STEP:对于步骤日志表。
- JOB:对于作业日志表
- JOBENTRY:对于作业项日志表。
- CHANNEL:对于通道日志表。
kettle日志表变量
| 变量 | 描述 |
|---|---|
| KETTLE_…_LOG_DB | 设置日志表使用的数据库连接的名字 |
| KETTLE_…_LOG_SCHEMA | 设置日志表使用的数据库模式名 |
| KETTLE_…_LOG_TABLE | 设置日志表使用的日志表名 |
8.kettle中的参数在SQL脚本中的用法
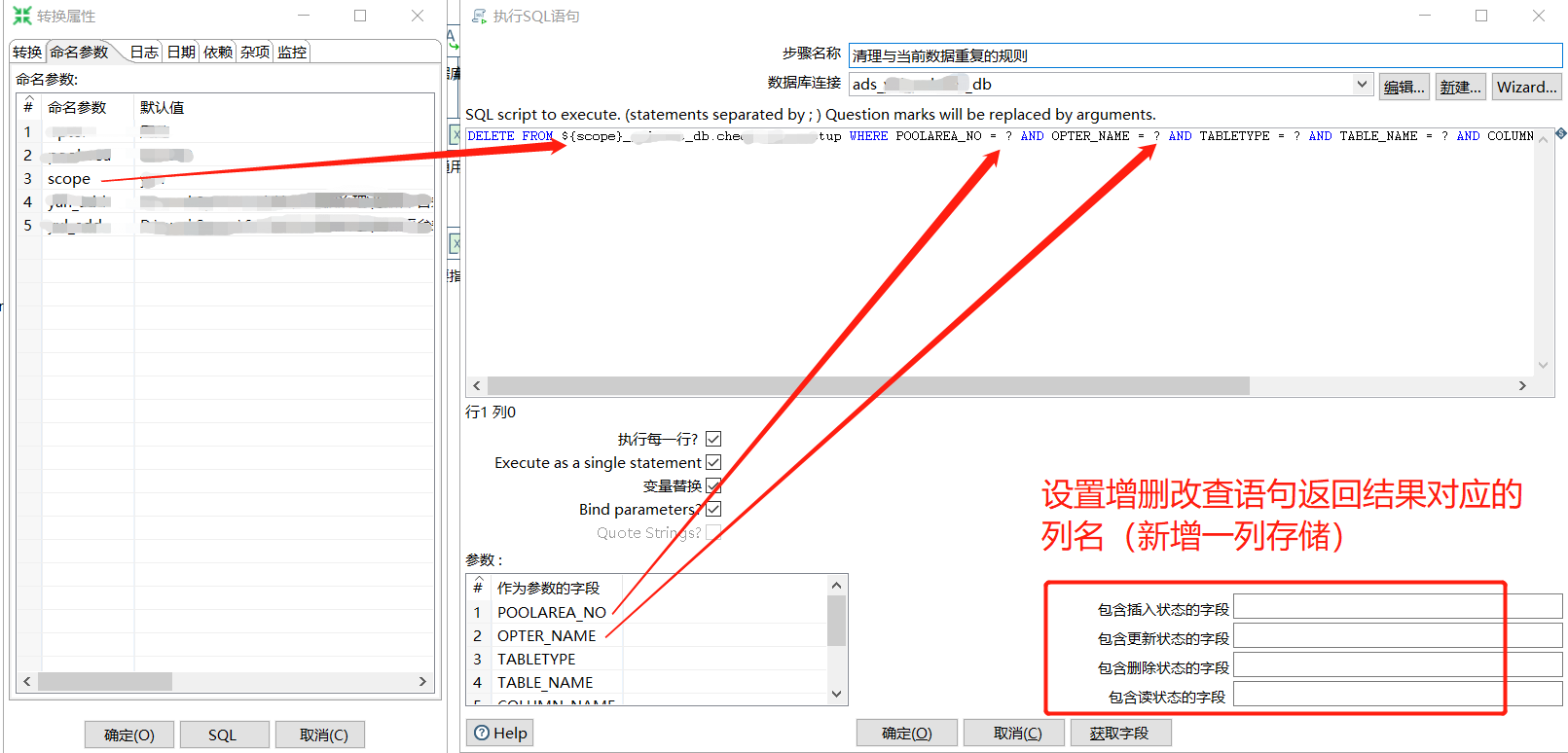
上图中的说明有问题,并不是CRUD的结果,而是语句执行的状态值(具体内容还需继续测试。。。)
9.kettle按条件执行sql脚本的问题
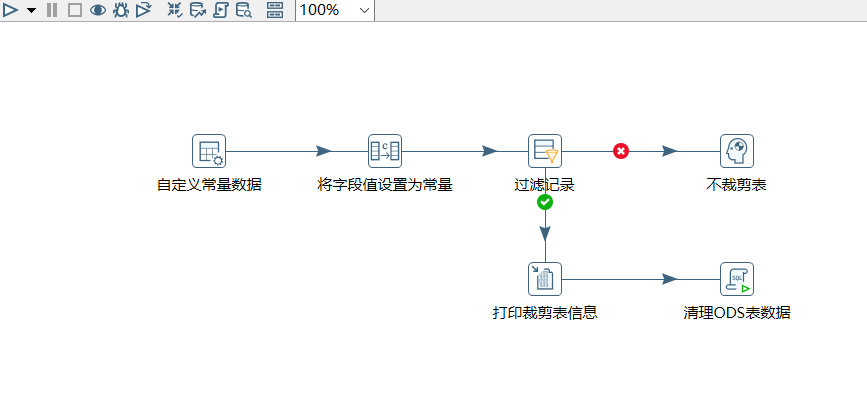
1.现象
在转换脚本中按条件执行sql脚本存在问题,不管是否满足条件sql脚本都会先于过滤组件执行一次。如下图:
2.解决
上述问题可以在job中解决。如下图:
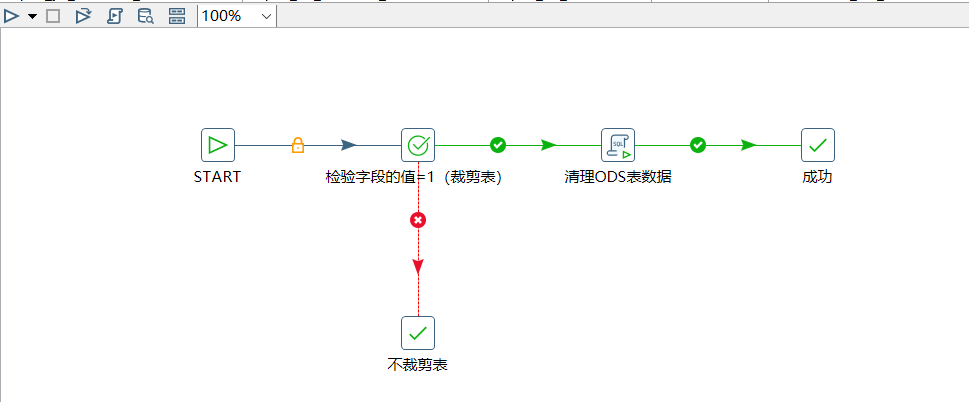
10.kettle的java脚本组件的本地调试
1.java脚本组件中的常用方法
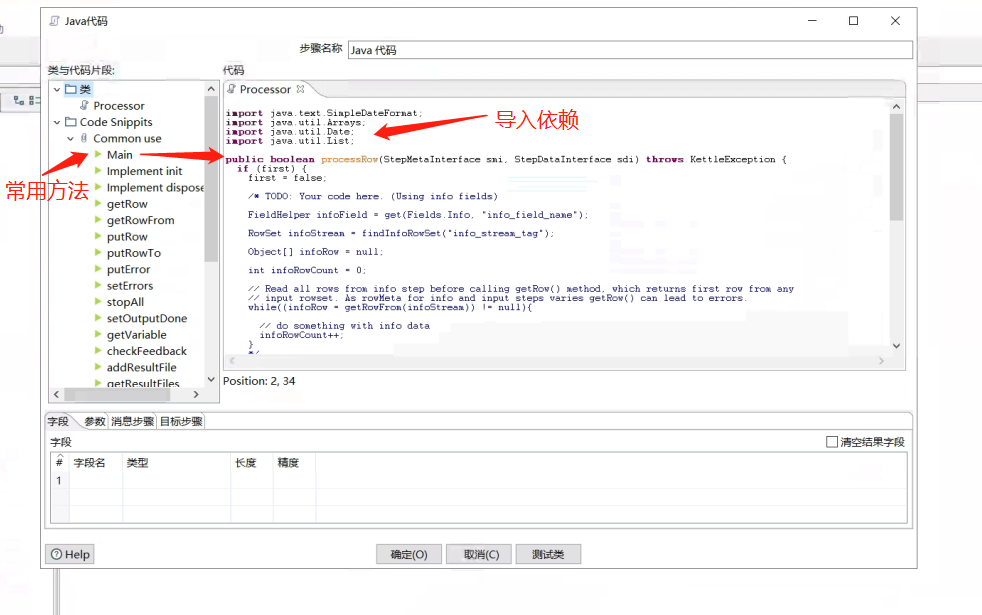
2.组件中的Main方法的本地调试模板
package com.test.java;
import org.pentaho.di.core.exception.KettleException;
import org.pentaho.di.core.exception.KettleStepException;
import org.pentaho.di.trans.step.StepDataInterface;
import org.pentaho.di.trans.step.StepMetaInterface;
import org.pentaho.di.trans.steps.userdefinedjavaclass.TransformClassBase;
import org.pentaho.di.trans.steps.userdefinedjavaclass.UserDefinedJavaClass;
import org.pentaho.di.trans.steps.userdefinedjavaclass.UserDefinedJavaClassData;
import org.pentaho.di.trans.steps.userdefinedjavaclass.UserDefinedJavaClassMeta;
/**
* 〈简述〉<br>
* 〈Kettle的Main方法本地调试〉
*
* @author Howard4
* @create 2021/12/25
* @since 1.0.0
*/
public class KettleMainMethod extends TransformClassBase {
public KettleMainMethod(UserDefinedJavaClass parent, UserDefinedJavaClassMeta meta, UserDefinedJavaClassData data) throws KettleStepException {
super(parent, meta, data);
}
public boolean processRow(StepMetaInterface smi, StepDataInterface sdi) throws KettleException {
if (first) {
first = false;
/* TODO: Your code here. (Using info fields)
FieldHelper infoField = get(Fields.Info, "info_field_name");
RowSet infoStream = findInfoRowSet("info_stream_tag");
Object[] infoRow = null;
int infoRowCount = 0;
// Read all rows from info step before calling getRow() method, which returns first row from any
// input rowset. As rowMeta for info and input steps varies getRow() can lead to errors.
while ((infoRow = getRowFrom(infoStream)) != null) {
// do something with info data
infoRowCount++;
}
*/
}
Object[] r = getRow();
if (r == null) {
setOutputDone();
return false;
}
// It is always safest to call createOutputRow() to ensure that your output row's Object[] is large
// enough to handle any new fields you are creating in this step.
r = createOutputRow(r, data.outputRowMeta.size());
/* TODO: Your code here. (See Sample)
// Get the value from an input field
String foobar = get(Fields.In, "a_fieldname").getString(r);
foobar += "bar";
// Set a value in a new output field
get(Fields.Out, "output_fieldname").setValue(r, foobar);
*/
// Send the row on to the next step.
putRow(data.outputRowMeta, r);
return true;
}
}
3.类中的两个方法
//获得输入端传入的所有字段名、字段类型等信息
List valueMetaList = getInputRowMeta().getValueMetaList();
//获得所有字段的值
Object[] r = getRow();
注意:在java脚本组件中不能使用泛型,所以上述方法并没有使用泛型。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号