生产问题之CompletableFuture默认线程池踩坑,请务必自定义线程池
前言
先说结论,没兴趣了解原因的可以只看此处的结论
CompletableFuture是否使用默认线程池的依据,和机器的CPU核心数有关。当CPU核心数-1大于1时,才会使用默认的线程池,否则将会为每个CompletableFuture的任务创建一个新线程去执行。
即,CompletableFuture的默认线程池,只有在双核以上的机器内才会使用。在双核及以下的机器中,会为每个任务创建一个新线程,等于没有使用线程池,且有资源耗尽的风险。
因此建议,在使用CompletableFuture时,务必要自定义线程池。因为即便是用到了默认线程池,池内的核心线程数,也为机器核心数-1。也就意味着假设你是4核机器,那最多也只有3个核心线程,对于CPU密集型的任务来说倒还好,但是我们平常写业务代码,更多的是IO密集型任务,对于IO密集型的任务来说,这其实远远不够用的,会导致大量的IO任务在等待,导致吞吐率大幅度下降,即默认线程池比较适用于CPU密集型任务。
背景
最近接到一个工作任务,由于我们之前的下单接口速度过慢,光是下单接口需要1500ms左右,因此需要做一些优化,在梳理完业务逻辑后,发现有一些可以并行查询或者异步执行的地方。于是打算采用CompletableFuture来做异步优化,提高执行速度。代码示例如下
//查询用户信息
CompletableFuture<JSONObject> userInfoFuture = CompletableFuture
.supplyAsync(() -> proMemberService.queryUserByOpenIdInner(ordOrder.getOpenId()));
//查询积分商品信息
CompletableFuture<JSONObject> integralProInfoFuture = CompletableFuture
.supplyAsync(() -> proInfoService
.getIntegralInfoCache(ordOrderIntegral.getProId()));
//查询会员积分信息
CompletableFuture<Integer> integerFuture = CompletableFuture
.supplyAsync(() -> proMemberService
.getTotalIntegralByOpenId(ordOrder.getOpenId()));
经过
于是一顿操作,优化完毕,执行速度从1500ms下降到300ms左右,在经过本地和测试环境后,上线生产。众所周知,CompletableFuture在没有指定线程池的时候,会使用一个默认的ForkJoinPool线程池,也就是下面这个玩意。
public static ForkJoinPool commonPool() {
// assert common != null : "static init error";
return common;
}
等发了生产之后看日志打印的线程号,却发现了一个极其诡异的事情。明明是同一套代码,生产环境的没有用到默认的线程池。而测试环境和本地环境都使用了默认的ForkJoinPool线程池,
这是测试和本地环境打印的线程日志
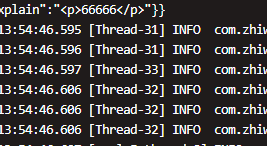
这是生产环境打印的线程日志

从日志打印的线程编号可以看到,测试和本地环境都是从ForkJoinPool中取工作线程,但是生产环境却是为每个任务创建了一个全新的线程。这是一个很危险的行为,假如这是一个并发比较高的接口,并且该接口使用了比较多的CompletableFuture来并行的执行任务。在高并发的时候,为每个任务都创建一个子线程,就会存在线程资源被耗尽的可能性,从而导致服务器崩溃。
那这是为什么呢?明明是同一套代码,在不同的机器上却有不同的线程使用情况。
原因
在带着疑问翻阅了CompletableFuture的源码之后,终于找到了原因:【是否使用默认的ForkJoinPool线程池,和机器的配置有关】
我们点进supplyAsync方法的源码
public static <U> CompletableFuture<U> supplyAsync(Supplier<U> supplier) {
return asyncSupplyStage(asyncPool, supplier);
}
可以看到这里使用了默认使用了一个asyncPool,点进这个asyncPool
//是否使用默认线程池的判断依据
private static final Executor asyncPool = useCommonPool ?
ForkJoinPool.commonPool() : new ThreadPerTaskExecutor();
//useCommonPool的来源
private static final boolean useCommonPool =
(ForkJoinPool.getCommonPoolParallelism() > 1);
其实代码看到这里就很清晰了,CompletableFuture是否使用默认线程池,是根据这个useCommonPool的boolean值来的,如果为true,就使用默认的ForkJoinPool,否则就为每个任务创建一个新线程,也就是这个ThreadPerTaskExecutor,见名知义。
那这个useCommonPool的布尔值什么情况下才为true,也就是什么时候才能使用到默认的线程池呢。即getCommonPoolParallelism()返回的值要大于1,我们继续跟进这个getCommonPoolParallelism()方法
//类顶SMASK常量的值
static final int SMASK = 0xffff;
final int config;
static final ForkJoinPool common;
//该方法返回了一个commonParallelism的值
public static int getCommonPoolParallelism() {
return commonParallelism;
}
//而commonParallelism的值是在一个静态代码块里被初始化的,也就是类加载的时候初始化
static {
//初始化common,这个common即ForkJoinPool自身
common = java.security.AccessController.doPrivileged
(new java.security.PrivilegedAction<ForkJoinPool>() {
public ForkJoinPool run() { return makeCommonPool(); }});
//根据par的值来初始化commonParallelism的值
int par = common.config & SMASK; // report 1 even if threads disabled
commonParallelism = par > 0 ? par : 1;
}
总结一下上面三部分代码,结合在一起看,这部分代码主要是初始化了commonParallelism的值,也就是getCommonPoolParallelism()方法的返回值,这个返回值也决定了是否使用默认线程池。而commonParallelism的值又是通过par的值来确定的,par的值是common来确定的,而common则是在makeCommonPool()这个方法中初始化的。
我们继续跟进makeCommonPool()方法
private static ForkJoinPool makeCommonPool() {
int parallelism = -1;
if (parallelism < 0 && // default 1 less than #cores
//获取机器的cpu核心数 将机器的核心数-1 赋值给parallelism 这一段是是否使用线程池的关键
//同时 parallelism也是ForkJoinPool的核心线程数
(parallelism = Runtime.getRuntime().availableProcessors() - 1) <= 0)
parallelism = 1;
if (parallelism > MAX_CAP)
parallelism = MAX_CAP;
return new ForkJoinPool(parallelism, factory, handler, LIFO_QUEUE,
"ForkJoinPool.commonPool-worker-");
}
//上面的那个构造方法,可以看到把parallelism赋值给了config变量
private ForkJoinPool(int parallelism,
ForkJoinWorkerThreadFactory factory,
UncaughtExceptionHandler handler,
int mode,
String workerNamePrefix) {
this.workerNamePrefix = workerNamePrefix;
this.factory = factory;
this.ueh = handler;
this.config = (parallelism & SMASK) | mode;
long np = (long)(-parallelism); // offset ctl counts
this.ctl = ((np << AC_SHIFT) & AC_MASK) | ((np << TC_SHIFT) & TC_MASK);
}
总结一下上面两段代码,获取机器核心数-1的值,赋值给parallelism变量,再通过构造方法把parallelism的值赋值给config变量。
然后初始化ForkJoinPool的时候。再将config的值赋值给par变量。如果par大于0则将par的值赋给commonParallelism,如果commonParallelism的值大于1的话,useCommonPool的值就为true,就使用默认的线程池,否则就为每个任务创建一个新线程。另外即便是用到了默认线程池,池内的核心线程数,也为机器核心数-1。也就意味着假设你是4核机器,那最多也只有3个核心线程,对于IO密集型的任务来说,这其实远远不够的。
解释
以上就是CompletableFuture中默认线程池使用依据的源码分析了。看完这一系列源码,就能解释文章一开头出现的那个问题。
因为我本地和测试环境机器的核心数是4核的,4减1大于1,所以在本地和测试环境的日志上可以看出,使用了默认的线程池ForkJoinPool,而我们生产环境是双核的机器。2减1不大于1,所以从生产环境的日志看出,是为每个任务都创建了一个新线程。
总结
- 使用CompletableFuture一定要自定义线程池
- CompletableFuture是否使用默认线程池和机器核心数有关,当核心数减1大于1时才会使用默认线程池,否则将为每个任务创建一个新线程去处理
- 即便使用到了默认线程池,池内最大线程数也是核心数减1,对io密集型任务是远远不够的,会令大量任务等待,降低吞吐率
- ForkJoinPool比较适用于CPU密集型的任务,比如说计算。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号