重学浏览器(2)-进程间的交互
本篇文章我们去探讨下Chrome的内部工作机制,分析下不同的进程和线程是如何处理浏览器的各部分功能。同时深入研究下每个进程和线程在展现网站时是如何沟通的。
首先我们先来看一个简单的例子,在浏览器地址栏输入url,按下回车建,浏览器会向服务器请求数据然后展现界面。
从浏览器进程开始
从第一篇文章中,我们知道了在tab网页之外的所有功能,都是由浏览器进程控制的,浏览器进程中有绘制浏览器的按钮和输入框的UI线程,网络线程来处理网络堆栈从网络中获取数据,存储线程控制文件的权限等。当输入url按下enter键后,UI线程会处理我们的输入。
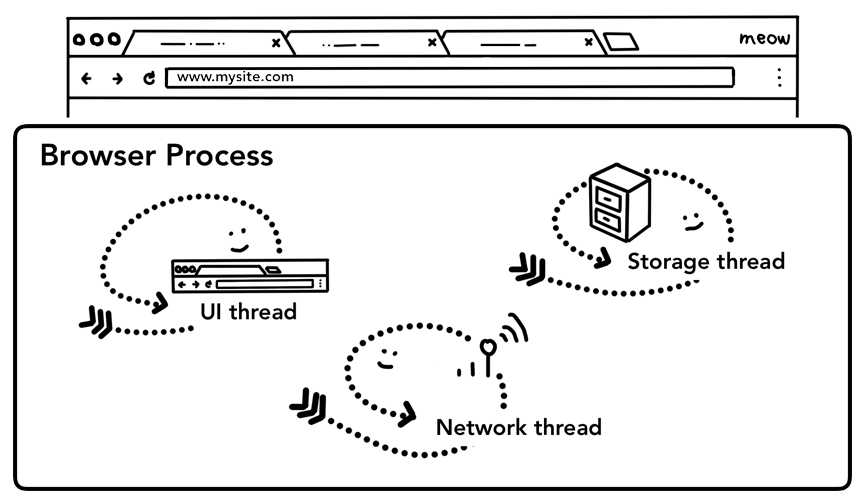
处理地址栏中的输入
用户在地址栏输入之后,UI线程回去判断用户的输入是url还是一个搜索项,因为chrome的地址栏也可以作为一个搜索输入框来使用。所以UI线程需要判断用户的的输入然后决定把用户的输入发送给搜索引擎还是发起网络请求。
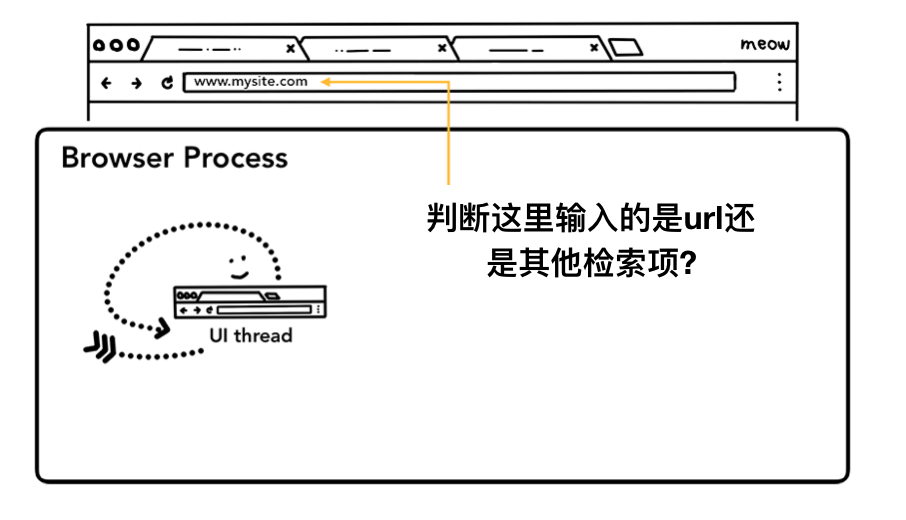
开始导航
当用户敲击enter键, UI线程为了得到网页内容初始化一个网络请求,即UI线程通知网络线程去加载某个网页,这时候浏览器地址栏左边的加载图标会显示出来,同时网络线程会去建立网络链接,这个过程中有着例如DNS解析或者TLS链接建立等过程。
在这个节点,服务端有可能给网络线程返回一个重定向的状态例如HTTP301,这时网络线程会告诉UI线程说:“你的请求被重定向了”,然后UI线程就会初始化另外一个网络请求。
读取响应数据
如果服务端返回的是数据是HTML,网络线程会把数据直接发送给渲染进程(浏览器内核),但是如果是zip文件或者是其他类型的文件,这代表着这是一次下载请求,网络线程会把数据发送给下载管理器。
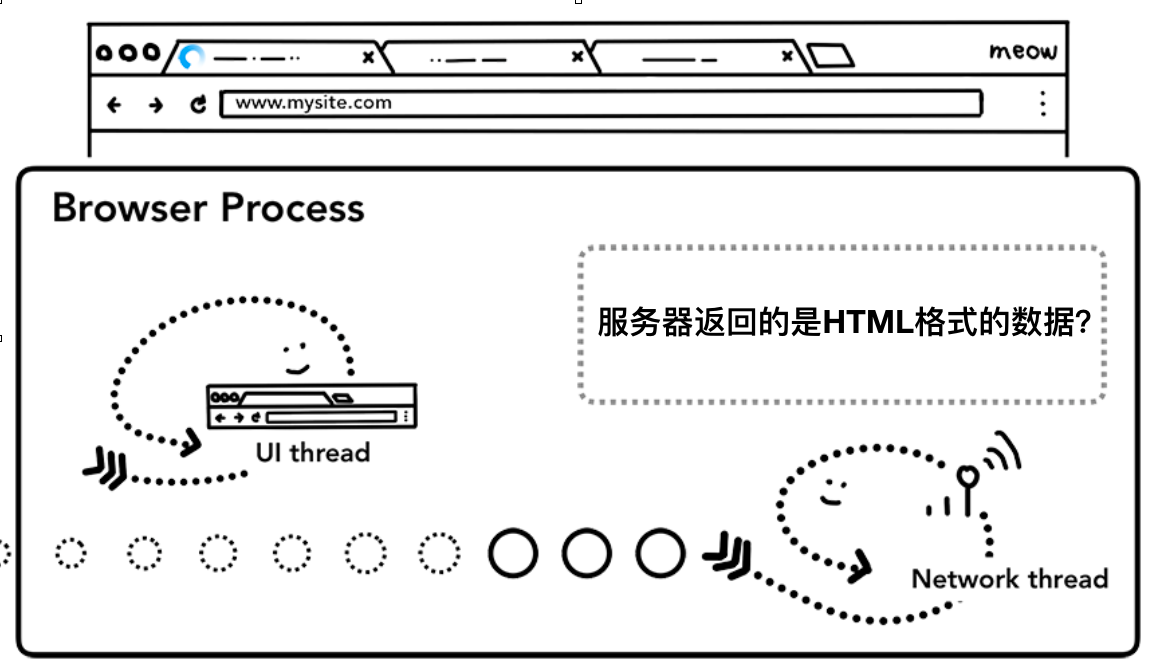
同时这个过程也会发生浏览器的安全检查,如果响应域和返回数据与已知的恶意站点所匹配,网络线程会告诉渲染进程展示一个警告界面,同时为了确保不会把危险的跨域数据发送给渲染进程也会进行CORB检测。
找寻渲染进程
当所有的检查都完成后,网络线程确定浏览器应该导航到对应的请求站点,网络线程告诉UI线程数据已经准备完毕,然后UI线程找到渲染进程继续去渲染界面。
由于网络请求需要几百毫秒才能得到响应返回,浏览器应用了一种用来加速这个过程的优化策略,当UI线程发送一个网络请求给网络线程的同时, UI线程会主动尝试去查找或启动一个渲染进程,这个过程是并行执行的。使用这种方法,如果一切进展顺利的话,当网络线程接收到数据时,渲染进程已经处于待机状态了,当然如果请求被重定向的话则不会用到这个准备好的渲染进程。
提交导航
当返回数据和渲染进程准备好时,浏览器进程会通过IPC通道向渲染进程提交导航,同时传递数据流给渲染进程,一旦浏览器进程确认提交导航已在渲染器进程中发生,导航过程就完成了,文档加载阶段就开始了。
此时,地址栏的状态已经更新,同时tab栏的路由历史记录也被更新,点击前进和后退按钮会进行响应的界面跳转。为了方便在tab页或浏览器窗口关闭后还原浏览器界面,tab页的导航历史记录信息是存储在硬盘上的。
初始加载完成
导航栏的工作完成后,渲染进程会继续加载资源渲染界面,当渲染进程完成界面渲染后,它会通过IPC通道向浏览器进程(这是当页面中包括frame中的onload事件触发后才执行的)。在这时,浏览器进程中的UI线程会停止loading图标的显示。

跳转至另一个页面
简单的导航完成了! 但是如果用户再次将不同的URL放到地址栏会发生什么? 好吧,浏览器进程会执行相同的步骤来导航到不同的站点。 但在它可以做之前,如果他们关心beforeunload事件,它需要检查当前渲染的站点。
当你准备离开或者关闭当前界面时,beforeunload事件会触发一个 “是否离开当前界面?”的弹框,当然,弹框的是有由渲染进程控制的,浏览器进程会向渲染进程询问是否需要触发beforeunload事件。
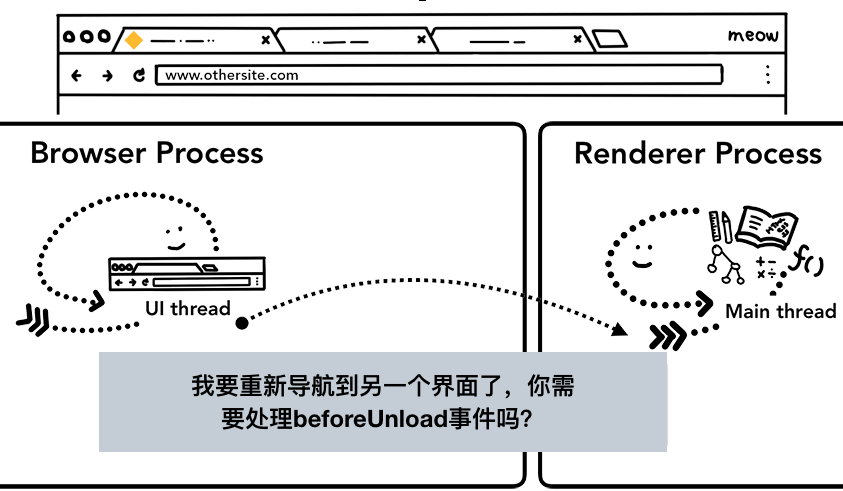
如果跳转是由渲染进程中发起的,例如用户点击了link跳转按钮或者在js中执行window.location=“ https://newsite.com ”,渲染进程会首先去检测beforeunload处理事件,然后,它经历与浏览器进程启动导航的相同过程。 唯一的区别是导航请求从渲染进程启动然后到浏览器进程。
当导航到一个与当前界面不同的新站点时,一个新的渲染进程会被创建用来处理新的导航,老的渲染进程会去处理类似于unload这种事件。对于界面的生命周期,我们可以查看这篇文章。https://developers.google.com/web/updates/2018/07/page-lifecycle-api#overview_of_page_lifecycle_states_and_events

service woker带来的不同
由于浏览器新引入的service worker特性,界面的导航过程发生了一些变化。service worker是在应用代码中编写网络代理的方式,允许web开发者更好的控制本地缓存内容,同时也可以控制界面什么时候向服务请求数据。当service worker 代理资源请求从缓存中获取,就不会向服务器发送请求。
其中最重要的一点是servicer worker是一段运行在渲染进程中的js 代码,所以问题就是,当一个网络请求打进来,浏览器进程是怎么知道这个站点存在service worker 线程呢?
当一个service worker被注册时,将保留service worker的scope作为参考 ,当请求发生时,网络线程根据注册的service worker 的scope 检查该URL,如果为该URL注册了service worker,则UI线程找到渲染进程以执行service worker代码。service worker可以从缓存加载数据,无需从网络请求数据,当然不符合规则时也可以从网络请求新资源。

总结
在这篇文章中,我们研究了界面请求过程中发生的情况以及响应头和客户端JavaScript等Web应用程序代码如何与浏览器交互。 了解了浏览器通过网络获取数据的步骤,可以更容易地理解为什么使用请求预加载等API。 在下一篇文章中,我们将深入探讨浏览器如何评估HTML / CSS / JavaScript以呈现页面。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号