
(重点)Es搜索引擎在数据量很大的情况下,如何提高查询效率?
总结:1、尽量让数据都保留在filesystem os cache文件系统操作缓存里,查询速度是毫秒级的;
2、数据预热(跟前一个一样,也是留在cache里),冷热分离(存在不同的shard分片上)
3、数据写入es的document文件前,在java逻辑里先处理好类似联表的操作,后续直接拿document数据,不要再做查询了
4、分页性能优化:不建议做深度分页,因为性能差速度慢,非要做就用scroll api,一页页翻看,不支持跳页
1、性能优化的杀手锏--》filesystem cache
os cache 操作系统缓存
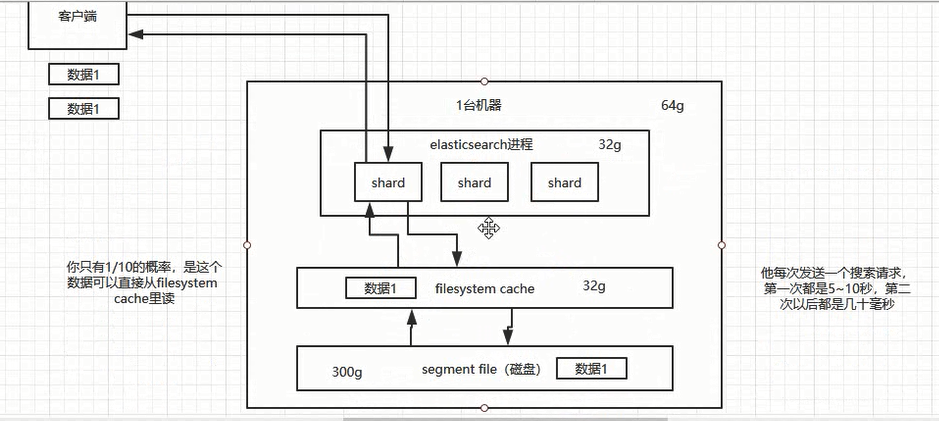
往es里写数据,实际都写到磁盘文件里面去了,磁盘文件里的数据操作系统会自动将里面的数据缓存到os cache里面去
Es的搜索引擎严重依赖于底层的filesystem cache,如果给filesystem cache更多的内存,尽量让内存可以容纳所有的index segment file 索引数据文件,那么搜索的时候基本就是走内存的,性能会非常高
走磁盘一般肯定上秒,搜索性能绝对是秒级别的
走filesystem cache,是走纯内存的,一般来说性能比走磁盘要高一个数量级,基本上说毫秒级的,从几毫秒到几百号秒不等。
解决方案:
(1)归根结底,要让es性能好,最佳的情况下,就是机器的内存至少可以容纳总数据量的一半。最佳情况下生产环境实践经验,最好是用es存少量的数据,要用来搜索的那些索引,内存留给file system cache的就100G,那么控制在100gb以内,相当于所有数据是走内存来搜索,性能很高,一秒以内。
(2)尽量在es里就存储必须用来搜索的数据,比如现在有一份数据,100个字段,其实用来搜索的就只有10个字段,建议是将10个字段的数据存入es,剩下的可以发那个mysql、Hadoop、hbase,都可以,建议es+hbase的架构:
hbase的特点是使用于海量数据的在线存储,就是对hbase可以写入海量数据,不要做复杂的搜索,就是做很简单的一些根据数据ID或者范围进行查询的这么一个操作就可以了。比如从es中根据name和age去搜索,拿到的结果可能就20个doc ID,然后根据doc ID到hbase里去查询每个doc id对应的完整数据,给查出来,在返回给前端。
2、数据预热
对于热点数据,最好做一个专门的缓存预热子系统,就是对于热数据,每隔一段时间就提前访问一下,让数据进入filesystem cache里面去,这样下次别人访问的时候性能会好一些。
3、冷热分离
将冷数据写入一个索引中,热数据写入另一个索引中,这样可以确保热数据在被预热后,尽量让他留在filesystem cache 里,别让冷数据给冲刷掉。

4、document模型设计
Es里面复杂的关联查询,复杂的查询语法,尽量别用,性能一般都不好
在Java系统里写入es数据的时候,就先完成数据关联,再直接写入Es中,搜索的时候就不需要利用es的搜索语法去完成join来搜索了。
此时一个重要的设计就是document的结构模型,写数据之前先设计好document的结构,Java里面做好数据处理后直接写入document,在es里面查询的时候直接就拿整个document出来,不用额外去做类似查询处理了。
5、分页性能优化
Es的分页性能是比较差的,因为你从多个shard查询回的数据都要返回到协调节点上,查回的数据越多,协调节点处理数据(合并、排序等)的时间就越长。比如要查第100页的10条数据,不是说从5个shard上分别查询回2条,而是每个shard都查询1000条数据过来,然后根据需求进行排序、筛选等操作,最后再次分页,拿到里面第100页数据。
翻页越深,shard返回的数据越多,协调节点处理的时间就越长。
解决方案是:(1)不允许深度分页,翻页越深性能越差
(2)类似于微博或者电商,下拉出来一页页的数据,推荐使用scroll api
scroll的原理实际上是保留一个数据快照,在一定时间内,不断下滑翻页的时候,用scroll不断通过游标获取下一页数据,性能很高。
scroll只能一页一页往后翻,不能跳页。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号