python自动化测试-D6-学习笔记之三(如何开发接口)
开发接口需要安装flask,是一个web的框架
'''怎么开发接口
mock
1、暂时代替第三方接口
2、辅助测试,用来代替没有开发好的接口
3、查看数据
4、flask是一个web的开发框架'''
'''
写代码都要有目录层级,一个程序一般有以下几个目录
bin 是运行的python文件 start.py 是程序的入口 这个时候,需要通过import来导入python文件,由于我们导入的文件分布在不同目录下,
import导入的逻辑是先找同目录下的文件,同目录下的没有的话,从环境变量里找,由于目录分布太多,不可能一一加到环境变量里,
所以我们先把bin的父目录加到环境变量里
BASE_PATH=os.path.dirname(os.path.dirname(os.path.abspath(__file__))) # __file__ 代表当前文件,这个是用来取父目录的,套两层是为了取到api的目录,abspath是为了让路径分隔符一致
sys.path.insert(0,BASE_PATH) # sys.path是环境变量地址 0是位置,把base_path加到环境变量里
后面所有要调用自己写的python文件,都要写成如下格式:
from lib.XXX import 方法名或者其他
from confing import setting
lib 存放的是代码文件,写的是各个代码的逻辑
conf 放置配置文件,里面建立一个setting.py存配置文件
data
logs
readme.md 是存放程序说明的东西
'''
import flask,json
from tools import op_mysql #用这种方式导入的话,使用的时候,写成op_mysql(sql)
# import tools #这种方式导入的话,使用的时候,需要写成 tools.op_mysql(sql)
app_server = flask.Flask(__name__)# __name__ 代表这个python文件名字,app_server的意思是把app.py的文件作为一个server服务
# 获取表里所有数据的接口
# @app_server.route是装饰器,意味着下面的函数不是一个普通的函数了,已经变成了接口了
# 'get_user'是http://127.0.0.1:8080/ 后面的地址,methods指的是请求方式是get还是post
@app_server.route('/get_user',methods=['get','post'])
def get_all_user():
sql = "select * from bt_stu;"
res = op_mysql(sql)
return res #return的时候只能return一个字符串
@app_server.route('/add_user',methods=['post'])
def add_user(): #这里面不能在写参数了
user_id = flask.request.values.get('id') #这里的参数就是调用接口的时候传入的参数
username = flask.request.values.get('name')
if username and user_id:
sql = "insert into stu VALUES ('%s','%s')"%(user_id,username)
res = op_mysql(sql)
response = {'code':'308','msg':'添加成功'}
else:
response = {'code':'503','msg':'必填参数未填写'}
return json.dumps(response,ensure_ascii=False)
app_server.run(port=8080,debug = True)
开发接口的目录结构如下:
bin -start.py 写的是运行python的文件
lib - main.py 写的是接口的主要逻辑 ,例如上面的 get_user的接口 就放在main里。其他文件是main需要调用的模块
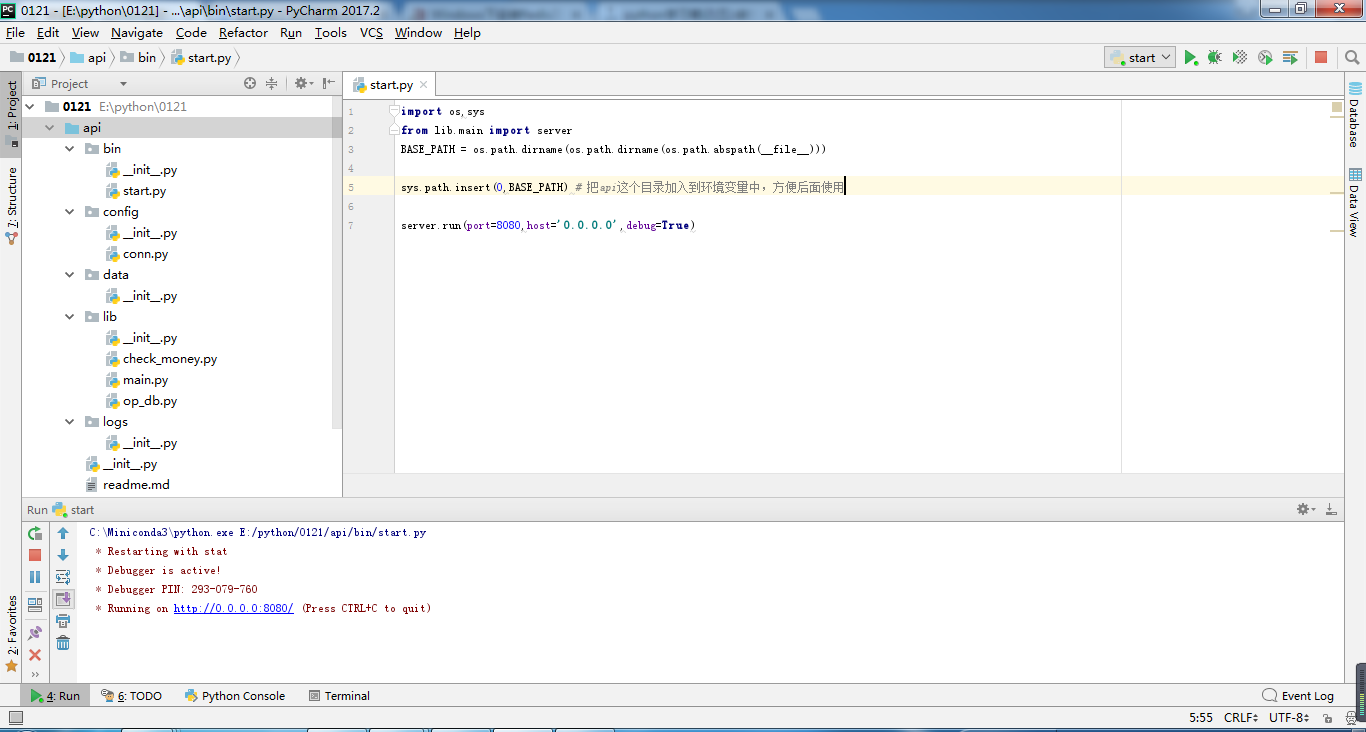
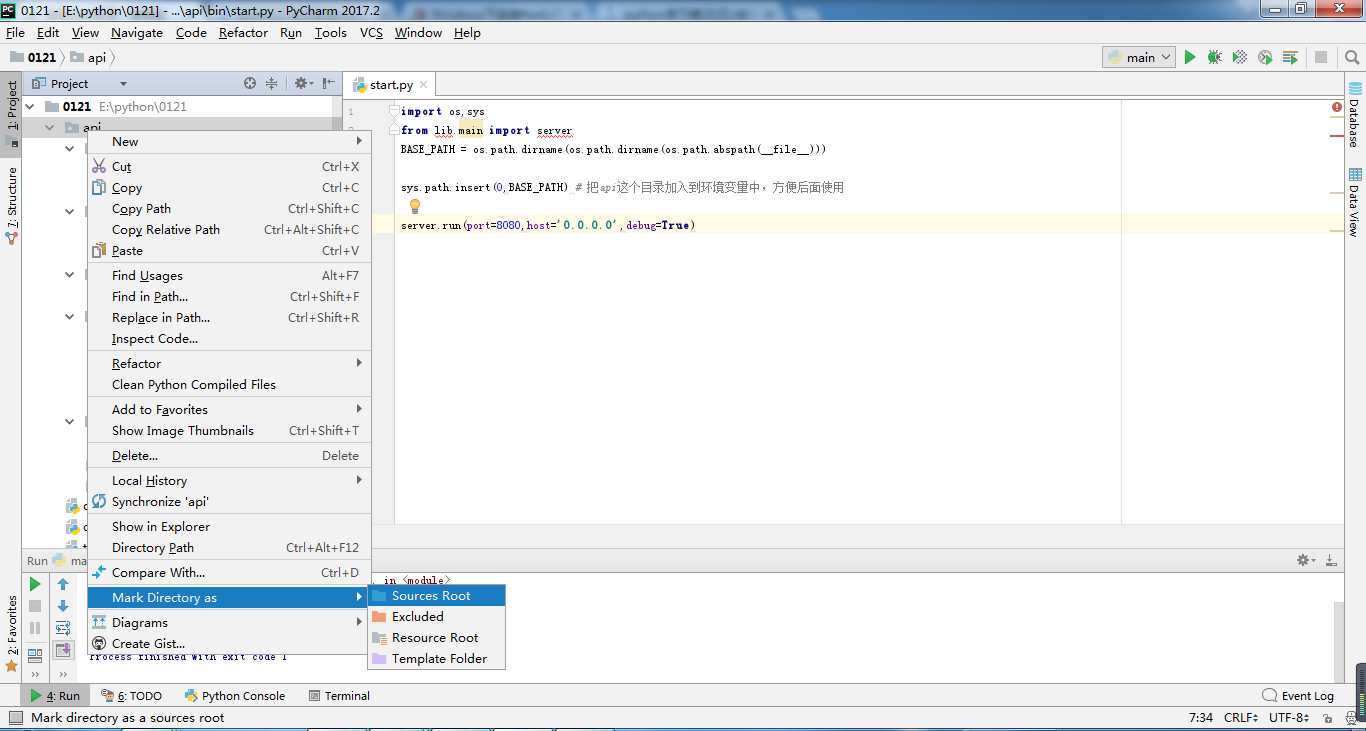
因为pycharm没有那么智能,启动服务之前要在pycharm中把api加到环境变量里,见下图
如果不加到环境变量里,pycharm认不出来导入的包,就会提示错误,如下图的 from lib.…… 其中lib就画红线了
补充:装饰器,生成器。老师博客内容,如下:
一、装饰器
装饰器,这个器就是函数的意思,连起来,就是装饰函数,装饰器本身也是一个函数,它的作用是用来给其他函数添加新功能,比如说,我以前写了很多代码,系统已经上线了,但是性能比较不好,现在想把程序里面每个函数都加一个功能,用来统计每个函数的运行时间是多少,找出来运行比较慢的函数,来优化代码,就需要添加一个新的功能,来统计程序的运行时间,那这样的话,就得修改每个函数了,需要改代码,但是代码特别多,改完了公司倒闭了,这时候装饰器就能排上用场了,它可以不改变原有的函数,原来的函数和原来一模一样,什么都不需要改变,只需要在函数外部加上调用哪个装饰器就可以了。so,装饰器的作用就是不改变原来函数的调用方式,不改变原来函数的代码,给它增加了一个新功能。但是不改变函数,给它增加新功能,那是不可能的,装饰器只不过是偷偷改变了原来的函数而已,而原来的函数不知不觉。
使用装饰器需要了解的知识:
1、函数即变量,这个是什么意思呢,在python里面函数就是一个变量,函数名就是一个变量,这个函数名里面存的是这个函数的内存地址,它把函数体放到内存里,在调用的时候从函数名里面的这个内存地址找到函数体然后运行这个函数。前面的博客说函数的时候,说过函数名后面加上小括号就是调用这个函数,如果只写这个函数名的话,打印一下就是这个函数的内存地址。
|
1
2
3
4
|
def test():
print('nihao')
prinit(test)#打印函数的内存地址
test()#调用函数
|
运行结果:
|
1
2
|
<function test at 0x100699950>
nihao
|
2、高阶函数,高阶函数在上篇博客里面写了,如果函数的入参是一个函数的话,那么这个函数就是一个高阶函数。
3、函数嵌套,函数嵌套,函数嵌套就是在函数里面再定义一个函数,这就是函数嵌套,而不是说在函数里面再调用一个函数。
|
1
2
3
4
|
def test():
def test1():
print('test1')
print('test')
|
了解了上面的这些知识之后,就可以使用装饰器了,下面我写一个简单的装饰器,用来统计函数的运行时间,然后将被统计的函数作为参数传递
|
1
2
3
4
5
6
7
8
9
10
|
import time
def bar():
time.sleep(3)
print('in the bar')
def test1(func):
start_time=time.time()
func()
stop_time = time.time()
print('the func run time is %s' % (stop_time - start_time))
test1(bar)
|
运行结果:
|
1
2
|
in the bar
the func run time is 3.000171661376953
|
但是这样的话,我们每次都要将一个函数作为参数传递给test1函数。改变了函数调用方式,之前执行业务逻辑时,执行运行bar(),但是现在不得不改成test1(bar)。此时就要用到装饰器。我们就来想想办法不修改调用的代码;如果不修改调用代码,也就意味着调用bar()需要产生调用test1(bar)的效果。我们可以想到将test1赋值给bar,但是test1似乎带有一个参数……想办法把参数统一吧!如果test1(bar)不是直接产生调用效果,而是返回一个与foo参数列表一致的函数的话……就很好办了,将test1(bar)的返回值赋值给bar,然后,调用bar()的代码完全不用修改!
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
import time
def timmer(func):
def deco():
start_time=time.time()
func()
stop_time=time.time()
print('the func run time is %s'%(stop_time-start_time))
return deco
def bar():
time.sleep(3)
print('in the bar')
bar=timmer(bar)
bar()
|
运行结果:
|
1
2
|
in the bar
the func run time is 3.000171661376953
|
函数timmer就是装饰器,它把执行真正业务方法的func包裹在函数里面,看起来像bar被timmer装饰了。如果我们要定义函数时使用装饰器,避免使用赋值语句bar=timmer(bar),要用到装饰器的语法糖@,语法糖的意思就是一种语法的简写,它使代码看起来简洁,上面的bar=timmer(bar)和@timmter bar()是一样的。这样写的话,看起来也比较高大上一些。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
import time
def timmer(func):
def deco():
start_time=time.time()
func()
stop_time=time.time()
print('the func run time is %s'%(stop_time-start_time))
return deco
@timmer
def bar():
time.sleep(3)
print('in the bar')
bar()
|
运行结果:
|
1
2
|
in the bar
the func run time is 3.000171661376953
|
这样,我们就提高了程序的可重复利用性,当其他函数需要调用装饰器时,可以直接调用。装饰器在Python使用如此方便都要归因于Python的函数能像普通的对象一样能作为参数传递给其他函数,可以被赋值给其他变量,可以作为返回值,可以被定义在另外一个函数内。
如果要装饰的函数带有参数时,因为你也不知道到底被装饰的函数会传什么参数,所以可以使用可变参数和关键字参数来接收所有的参数,这两种参数也在上一篇博客中写过了。代码如下:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
import time
def timmer(func):
def deco(*arg,**kwarg):
start_time=time.time()
func(*arg,**kwarg)
stop_time=time.time()
print('the func run time is %s'%(stop_time-start_time))
return deco
@timmer
def test1():
time.sleep(1)
print('in the test1')
@timmer
def test2(name,age) :
time.sleep(2)
print('in the test2:',name,age)
test1()
test2('niuniu,18)
|
运行结果:
|
1
2
3
4
|
in the test1
the func run time is 1.0000572204589844
in the test2: niuniu 18
the func run time is 2.0001144409179688
|
下面再用装饰器,写一个实例,判断用户是否登陆,逻辑是这样,运行程序,打印菜单,如果是选择后台管理和添加商品,就判断用户是否登录,如果没有登录的话,让用户登录,如果是查看商品就不需要登录。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
|
import os
def login():
'''
登录函数,登录成功的话,写如user这个文件
:return:
'''
print('login')
username = input('请输入账号')
password = input('请输入密码')
if username =='admin' and password=='123456':
print('登录成功!')
with open('user','a+') as fw:
fw.write(username)
else:
print('账号密码错误!')
#是否登录校验装饰器
def auth(func):
def check(*args,**kwargs):
if os.path.exists('user'):#判断用户文件是否存在
func(*args,**kwargs)#存在的话,调用原来的函数
else:
print('你未登陆!')#不存在的话,调用登录函数
login()
return check
@auth
def admin():
print('welcome!')
def show():
print('show!')
@auth
def add():
print('add product!')
def menu():#打印菜单函数
msg= '''
1 : 后台管理
2 : 查看商品
3 : 添加商品
'''
print(msg)
m = {
"1":admin,
"2":show,
"3":add
}
choice = input('请输入你的选择:').strip()
if choice in m:
m[choice]()#调用对应的函数
else:
print('输入错误!')
menu()
if __name__ == '__main__':
menu()
|
二、生成器
生成器是什么东西呢,可以理解为,生成器也是一个迭代的对象,和list似的,里面存数据,和list不同的是,list在定义的时候数据就已经在内存里面了,而生成器是,你用到这个里面的数据的时候它才会生成,这样就比较省内存,因为是需要这个值的时候,才会在内存里面产生。生成器是按照某种规则生成的一个列表,用到这个列表的中的数据时,才会在内存里生成,但是由于生成器是根据某种规则产生的,必须得知道前一个值是多少,才能知道后面的那个值是多少,所以不能像list那样,直接用索引去取值。
1、 列表生成式,在第二篇博客里面我写了三元运算符,和那个有点像,如果要生成列表[1x1, 2x2, 3x3, ..., 10x10]怎么做?除了循环还可以用一行语句代替循环生成
|
1
2
3
|
list=[x*x for x in range(1,11)]
print(list)
[1, 4, 9, 16, 25, 36, 49, 64, 81, 100]#运行结果
|
这种写法就是Python的列表生成式,写列表生成式时,把要生成的元素 x * x 放到前面,后面跟 for 循环,就可以把list创建出来。
2、生成器:要创建一个generator,有很多种方法。第一种方法很简单,只要把一个列表生成式的[]改成(),就创建了一个generator。
|
1
2
3
|
g=(x*x for x in range(1,11))
print(g)
<generator object <genexpr> at 0x1036ff258>#运行结果
|
创建list和generator的区别仅在于最外层的[]和()。list的元素我们可以一个个打印出,如果要打印generator中的元素需要借助next方法
|
1
2
3
4
5
|
g=(x*x for x in range(1,11))
print(next(g))
print(next(g))
print(next(g))
print(next(g))
|
运行结果:
|
1
2
3
4
|
1
4
9
16
|
但是generator保存的是算法,每次调用next(g),就计算出g的下一个元素的值,直到计算到最后一个元素,没有更多的元素时,抛出StopIteration的错误。可以通过for循环来迭代它,并且不需要关心StopIteration的错误。
|
1
2
3
|
g=(x*x for x in range(1,11))
for i in g:
print(i)
|
运行结果:
|
1
2
3
4
5
6
7
8
9
10
|
1
4
9
16
25
36
49
64
81
100
|
用函数生成generator:generator非常强大。如果推算的算法比较复杂,用类似列表生成式的for循环无法实现的时候,还可以用函数来实现。例如,斐波拉契数列用列表生成式写不出来,但是,用函数把它打印出来却很容易:
|
1
2
3
4
5
6
7
8
|
def fib(max):
n,a,b=0,0,1
while n<max:
print(b)
a,b=b,a+b
n=n+1
return 'done'
f=fib(6)
|
运行结果:
|
1
2
3
4
5
6
|
1
1
2
3
5
8
|
上面的函数和generator仅一步之遥。要把fib函数变成generator,只需要把print(b)改为yield b就可以了:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
def fib(max):
n,a,b=0,0,1
while n<max:
yield b
a,b=b,a+b
n=n+1
return 'done'
x = fib(6)
print(x)
print(x.__next__())
print(x.__next__())
print(x.__next__())
print(x.__next__())
|
三、内置函数
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
print(all([1,2,3,4]))#判断可迭代的对象里面的值是否都为真
print(any([0,1,2,3,4]))#判断可迭代的对象里面的值是否有一个为真
print(bin(10))#十进制转二进制
print(bool('s'))#把一个对象转换成布尔类型
print(bytearray('abcde',encoding='utf-8'))#把字符串变成一个可修改的bytes
print(callable('aa'))#判断传入的对象是否可调用
print(chr(10))#打印数字对应的ascii
print(ord('b'))#打印字符串对应的ascii码
print(dict(a=1,b=2))#转换字典
print(dir(1))#打印传入对象的可调用方法
print(eval('[]'))#执行python代码,只能执行简单的,定义数据类型和运算
print(exec('def a():pass'))#执行python代码
print(filter(lambda x:x>5,[12,3,12,2,1,2,35]))#把后面的迭代对象根据前面的方法筛选
print(map(lambda x:x>5,[1,2,3,4,5,6]))
print(frozenset({1,2,3,3}))#定义一个不可修改的集合
print(globals())#返回程序内所有的变量,返回的是一个字典
print(locals())#返回局部变量
print(hash('aaa'))#把一个字符串哈希成一个数字
print(hex(111))#数字转成16进制
print(max(111,12))#取最大值
print(oct(111))#把数字转换成8进制
print(round(11.11,2))#取几位小数
print(sorted([2,31,34,6,1,23,4]))#排序
dic={1:2,3:4,5:6,7:8}
print(sorted(dic.items()))#按照字典的key排序
print(sorted(dic.items(),key=lambda x:x[1]))#按照字典的value排序
__import__('decorator')#导入一个模块
|

