干货满满的 Zookeeper 学习笔记
读完《 ZooKeeper : Wait-free coordination for Internet-scale systems 》 论文的一些笔记,记录下来,方便以后查看
在读论文的时候,我看到有关一致性问题的讨论,所以去看了下关于一致性模型的文章,感觉 zookeeper 感觉主要是提供了一种解决方案去解决分布式系统中的一致性问题。
一、分布式系统的“正确性”
在分布式系统中我们想要保证系统的正确性,需要一套规则来进行约束,这一套规则就是一致性模型。
这个时候大家会想,保证正确性不是天经地义的事情吗,计算机执行 1+1 ,返回的结果一定是2呀,只要满足类似这样的正确性 不就是正确性本身的体现吗,为什么在分布式系统中需要有一套规则来描述正确性呢。
因为在单机模型中,我们可以保证寄存器级别的数据操作。这种正确性需要达到操作系统 寄存器级别的数据操作才行,加上CPU-cache 和 DRAM 其实就无法达到这样的正确性了。
因为cpu-cache是异步更新到DRAM的,而多线程场景,不通线程挂在不通的cpu之上,那一号线程的更新不一定立即刷到DRAM,而同时2号线程去读这块内存,可能无法读到新的数据。
而实际情况下,全球级别的分布式系统计算机之间的通信跨洲/跨洋 都是很普遍的,那一次请求需要几十ms以上的延时才能被其他服务器收到,相比于单机服务器几十ns到百ns的访寸或者us级别的读盘来说太长了。这个时候,一台机器写入的数据想要在另一台机器读取,显然很难保证其他机器能够读到新的数据。
所以,我们需要为分布式系统引入正确性模型,来决定当前分布式系统应该对外提现什么样的“正确性”,这个正确性可以和我们的寄存器正确性有歧义。正如,CPU的内存屏障能够为用户提供不同的一致性要求。
目前整理出来的一致性模型,从强到弱大体有以下四种(不同的论文/系统可能有自己的分类,但是较为清晰的划分有以下四种):
- 线性一致性(Linearizability)
- 顺序一致性(Sequential consistency)
- 因果一致性(Casual consistency)
- 最终一致性(Eventual consistency)
二、线性一致性(Linearizability)
线性一致性,顾名思义,对于观察者来说,所有的读和写都在一条单调递增的时间线上串行推进。整个系统对外的表现就是一个原子寄存器,能够很容易得实现CAS(compare and set)操作。
它对读写的要求是 所有的读总能返回最近的写操作的值。
在分布式系统中,这样的正确性,对写的要求就是,写请求需要写入到每一个服务器才算完成,中间有任何一个服务器宕机/网络分区,写都会卡住,整个系统将完全不可用。
在操作系统中,我们的CPU访存想要提供线性一致性引入的内存屏障也会让系统性能受影响。
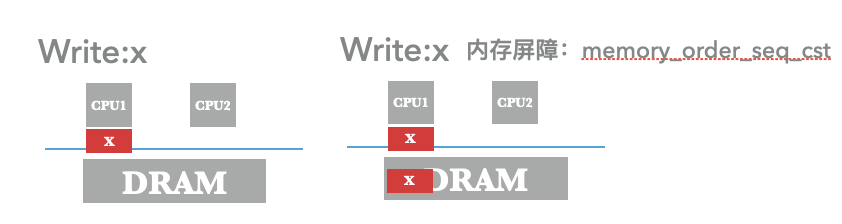
原本的写请求写到cpu-cache就可以返回,等待cpu-cache异步刷内存。但是现在,我们加上memory_order_seq_cst,就需要从cpu-cache同步写入到内存完成才返回。这个时候延时将从几个ns降到接近百ns。
三、顺序一致性(Sequential consistency)
顺序一致性则降低了线性一致性的正确性标准,不要求整个系统(分布式/单机)对外表现的读写都在一个单调递增的时间线上。顺序一致性则只需要保证一个机器上的进程处理读写请求是按照请求定义的顺序发生的即可。
要求如下:
1. 不要求操作按照真实的时间序列发生,对操作进行排序,但是不一定是真实时间线性,因为分布式客户端提交导致(像下图中,读请求下发真正执行的时间原本在写请求 w(b) 之后,但是却可以读到这个写请求之前的数据)
2. 不通进程间的操作执行先后顺序也没有强制要求,但必须是原子的。
3. 单个进程内的操作顺序必须和编码时的时间顺序一致。
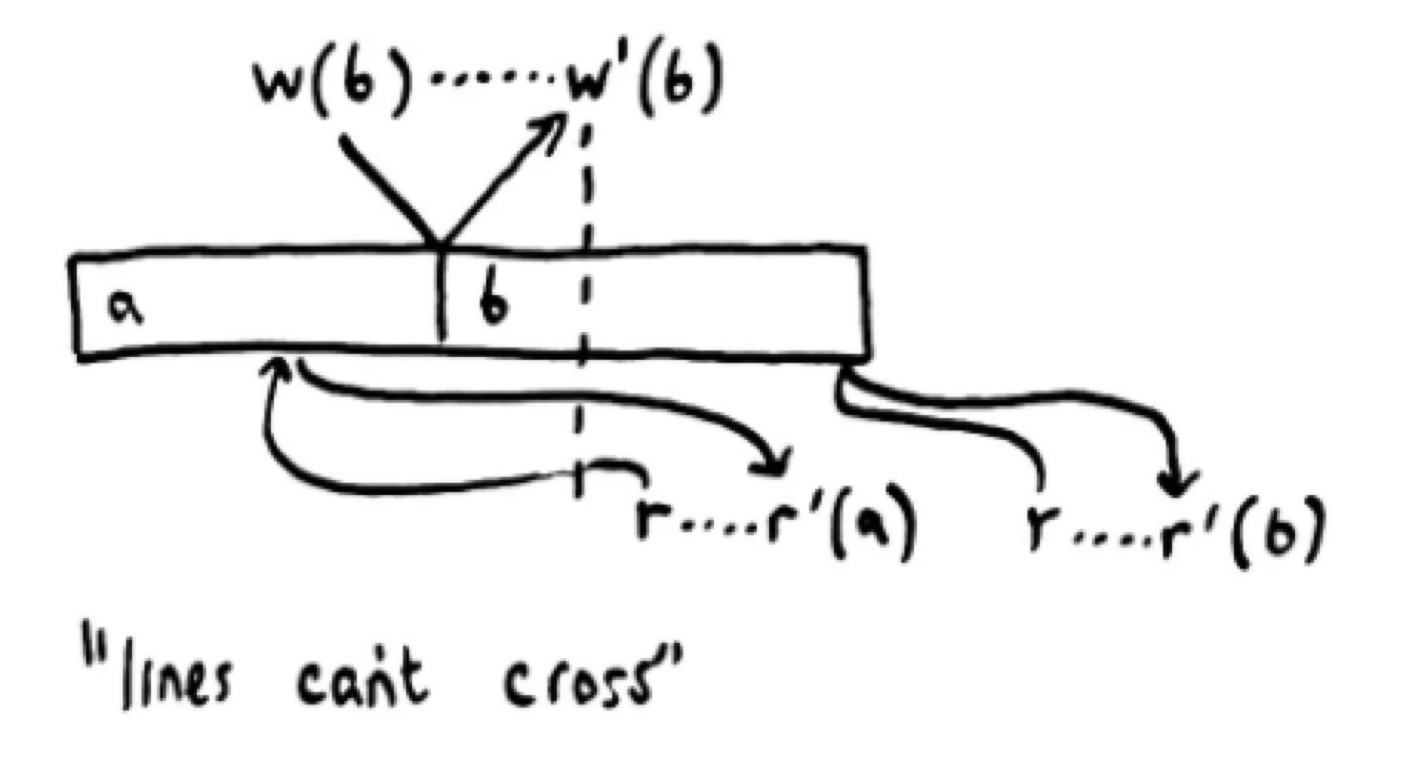
现在的很多分布式系统对外宣称自己是强一致性系统,其实最高的级别也就是到顺序一致性这里。包括很多人讨论的zookeeper + sync 能否提供线性一致性读 问题,其实也只能提供到顺序一致性级别(正如前面说的,操作系统在内存屏障的情况下才能保证线性一致性,实现zookeeper 时每个机器会开内存屏障?显然不可能)
三、因果一致性(Casual consistency)
因果一致性要求 有因果相关的操作必须按照顺序发生。比如先发帖子,再有评论,那么发帖子的操作 x 一定在评论操作 y 之前发生。
因为前面的一致性模型 中对每一个操作都能用一个单一的数值表示(时间),但是在因果一致性模型中,我们会发现每一系列满足因果一致性的操作都是一个集合,我们要确保并发场景下的因果关系,就需要对两个集合进行比较。
这个一致性不要求 整个系统/整个进程 对外拥有一个特定的顺序,所以它所能够容忍的冲突更多,也就是更低的一致性要求,好处也很明显,会对性能比较友好(更高的并发处理)。在因果一致性的系统实现中 需要捕获因果依赖关系,这个操作在数据库系统中会引入一些计算/存储代价,间接增加了系统的复杂度。
业界很少有因果一致性的系统,虽然其能够允许更高的并发,但是引入的额外复杂度会影响大家的选择。 后续的文章会介绍因果一致性系统的经典实现COPS。
四、最终一致性(Eventual consistency)
这里的最终一致性,其实就是弱一致性,保证最终数据会一致,并不保证当前事务对其他的读写操作不会产生影响,系统不会限制用户的任何操作方式,允许每个原子操作的顺序执行任意的重排。
在某一时刻,会保证能够读到对数据的更新,某一时刻这里可以算做是一个量子的混合态,不论什么时候,对外的表现就是只有用户读了,可能才会写入成功 or 没有成功,也就是写入的时机取决于用户什么时候读取,有点像量子态,只有最终读取了才知道存储的数据是不是预期)。
在 zk 中原生支持的是顺序一致性,论文中给出了两个基本的顺序保证:
1. 线性写:所有更新Zookeeper状态的操作是串行的,先来先服务
2. FIFO客户端顺序:来自客户端的所有请求按客户端发送的顺序依次执行
这里提出一个 A-lineariazble 异步线性化的概念,就是会将更新请求进行排序,然后按顺序逐一执行。更新请求是A-linearizable的,Zookeeper在每个副本上本地读取请求。
除此之外,在分布式集群中论文还对两种场景进行了讨论:
1. 当新的leader开始进行改变时,我们不希望其他进程使用正在被改变的配置
2. 如果新的leader在配置被完全更新之前宕机,我们不希望进程使用这个部分新的配置
第一个问题,通过 chuby 这种的分布式协议来处理集群成员变更的时候数据一致性问题,这中可以参考 raft 的集群成员变更的实现,感觉大体上是差不多的。除此之外为了满足第二点,在 zk 中,新的leader可以指定一个路径作为备用 Znode;其他进程只在 Znode 存在时才使用这个配置 新的leader通过删除就绪、更新各种配置 Znode 和创建就绪znode来使配置改变。 所有这些更改都可以流水线化并异步发布以快速更新配置状态。
解决第二点场景,除了 zk 本身的顺序处理配置,和增加临时节点来改变配置外,还可以使用 watch 机制来保证,新配置被读取的时候是真正变更生效后的数据。
我猜测在 zk 的数据的顺序一致性可能参考了 CRAQ 一致性协议。下面主要介绍一下这种链式的数据复制机制。
具体可以参考链接:https://pdos.csail.mit.edu/6.824/papers/cr-osdi04.pdf
五、chain Replication (链式复制)
具体的可以参考这个文章
https://zhuanlan.zhihu.com/p/519927237
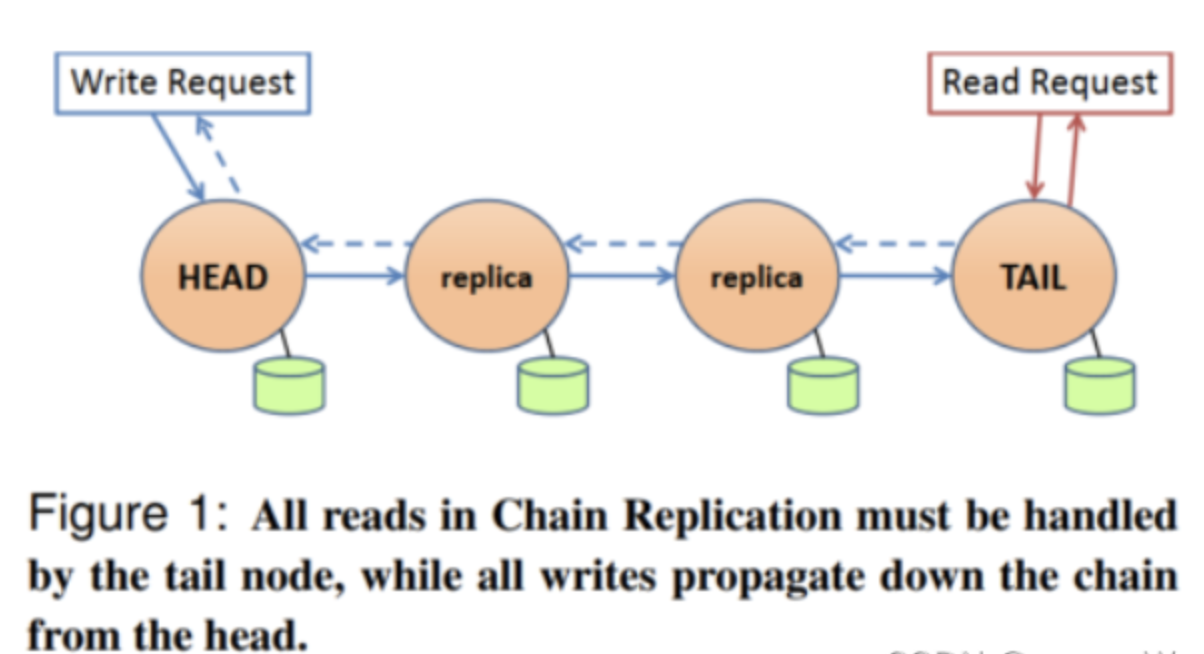
如上图所示,链式复制的思想是在一个分布式集群中,节点之间形成一个链路:
- 对于任何写请求,都从HEAD节点开始写,直到写到TAIL,这个写请求被认为是被整个集群提交。
- 对于任何读请求,都从tail中读取,因为tail中保存了所有已经提交的写请求。可以看出,通过这种机制,链式复制实现了强一致性,在同一时间任意请求集群,总能得到相同的结果。链式复制一致性协议的特点在于:
- 写请求吞吐更高。这个很好理解,传统的主从结构中,master需要将写请求发送给多个replica,这样写的小号很高。但是链式复制中,每个节点只需要将写请求发给自己的下一个节点。
- 读请求成为了瓶颈。因为所有的读请求都是tail节点处理的,因此tail不可避免地会承载非常大的压力。
六、CRAQ 一致性协议
CRAQ对于传统的链式复制做的修改在于:其允许读请求由集群中的任意节点请求,而保持集群的强一致性。CRAQ的精髓思想在于:这个节点之间的链表是双向的,写请求从head→tail实现整个集群的写,然后tail→head通知所有节点集群最近的一致性点。当读请求达到任意节点时,节点首先check自己对于这个请求的对象是不是在上个一致性点之后没有修改,如果没有修改,说明节点存储的内容和tail存储的内容是一致的,可以直接返回,否则就向tail中再请求一次。
CRAQ的工作流程为:
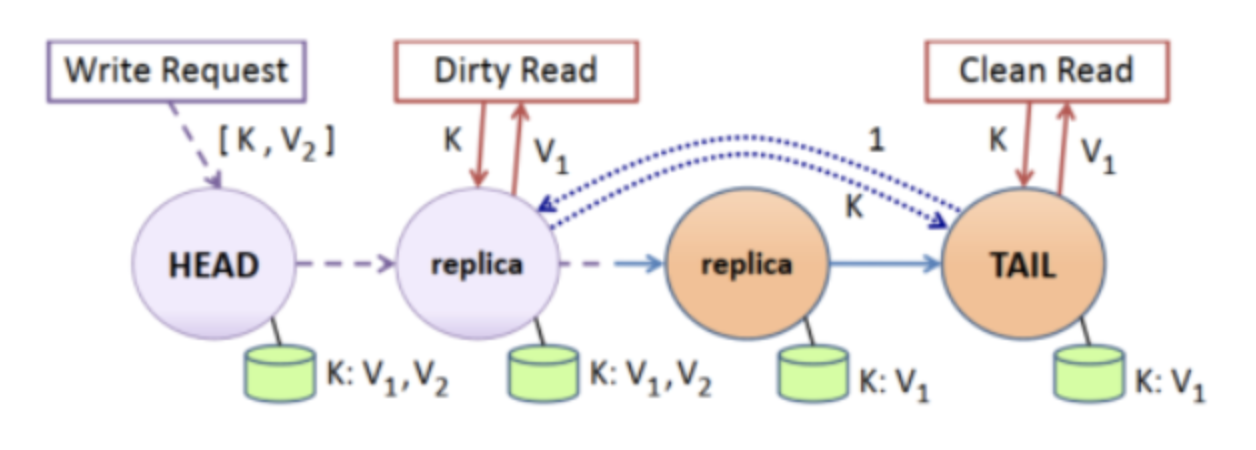
每个节点存储多个版本的对象,一个clean版本代表着最近一次一致性点的对象版本,对于从上个一致性点之后来的每个请求,节点都为对象保存一个dirty版本号和对应的值。
对于写请求:
1. 客户端还是将请求发给head。
2. 当链表中的一个节点收到写请求时,其修改对应的对象值并创建一个对应的dirty版本号
3. 当tail节点收到写请求之后,代表着这个写请求已经在集群中被提交,为这个对象创建clean版本,并沿着链表tail→head的方向发送确认消息,确认这个clean版本。
4. 当链路上的节点收到tail的消息后,其确定这个clean版本为最近的一致性版本,并删除再这个版本之前的所有版本。
对于读请求:
1. 读请求可以发送给链路上的任何节点
2. 节点收到对对象的读请求后,检查这个对象的版本,如果发现对象在我这只有一个clean版本,说明这个对象在上次被tail确认之后没有任何修改,此时我保存的对象和tail保存的对象肯定是一样的,此时就直接给client返回对象的值。
3. 如果节点收到对某个对象读请求之后,发现我这里由对象的一个clean版本和多个dirty版本,说明对象在上次被tail确认之后又被修改了多次。此时节点不能随便返回,因为他不知道集群对这个对象的提交到了哪个版本(可不一定是这个clean版本,因为tail可能已经提交了更新的版本,只是更新版本的确认消息害没传到这个节点),因此此时节点需要向tail询问一个版本号,然后给client返回这个版本号对应的对象的值。
我们在两种不同的场景来讨论CRAQ读请求的吞吐量:
1. 集群中大多数请求是读而不是写:在这种情况下,从non-tail节点中读取的值很有可能就是clean版本,可以直接返回;我们已经说了链式复制的瓶颈是读,因此,在这种场景下集群的吞吐可以随着集群的数量线性扩展。
2. 集群中大多数请求是写而不是读:这种情况下,当读请求到了non-tail节点时,需要频繁向tail节点请求。看起来好像没啥改善,但是请注意,我们只是向tail节点请求版本号,然后根据对象的版本号给client返回自己存储的对象的值。这比传统的链式复制(直接向tail请求对象的值)要轻量很多。
但是需要说明的是,CRAQ还是很有意思的,但是相较于 raft 和 paxos,还是没办法处理脑裂等问题,它只关心数据复制,也是提供了一种很好理解的强一致性协议了。而在设计存储服务中,是使用链式复制和主从复制,这个取决于使用场景和对异常处理的要求来决定。
七、ZK 的基本保证
Zookeeper有两个基本的顺序保证:
1. 线性写:所有更新Zookeeper状态的操作是串行的,先来先服务
2. FIFO客户端顺序:来自客户端的所有请求按客户端发送的顺序依次执行
而这个序列执行的保证我感觉是基于上面的链式复制来进行实现的,并且排序根据排序 atomic broadcast 原子广播协议,ZAB 来实现统一协同。入下图,由 leader 负责协同,进行写请求的序列排序。
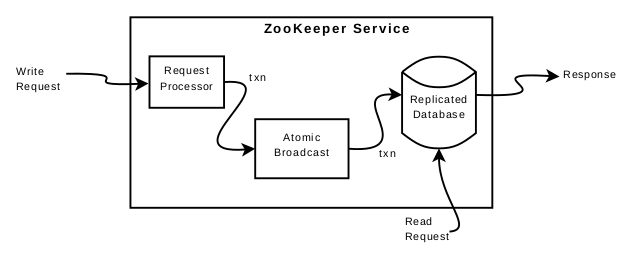
Zookeeper 通过在集群中每台服务器上复制 Zookeeper 数据来提供高可用性 。集群由一个 leader 和 多个 follower 组成 ,leader 负责进行投票的发起和决议、更新系统状态,follower 在选举 leader 的过程中参与投票。
每个服务器都可以连接客户端,客户端连接到一个服务器,建立 Session 。Zookeeper 使用 timeout 来检测 session 是否还在,如果 client 在一定时间内无法与服务器通信,则连接到其他服务器重新建立 session。
一台服务器上的组件构成如上图所示 。client 与 服务器通过 TCP 连接来发送请求。
对于读请求:
- 则直接在该服务器本地读取数据,可能读到过时数据
- 若读请求之前有
sync,则必然读到最新数据
对于写请求:
- 将写请求转发至 leader
- Request Processor 对请求做准备。leader 使用 Atomic Broadcast 将写请求广播给 follower ( 写请求被排序为 zxid ),具体是使用 ZAB ( 一种原子广播协议 )
- leader 得到多数回复之后,将写请求应用到 Replicated Database 中,最后将该写请求应用到所有 follower 上
- 为了可恢复性,强制在写入内存数据库之前将 white-ahead log 写入磁盘,并周期性地为内存数据库生成快照
八、ZK 的数据结构和存储
在ZooKeeper中,节点也称为znode。由于对于程序员来说,对zk的操作主要是对znode的操作,因此,有必要对znode进行深入的了解。
ZooKeeper采用了类似文件系统的的数据模型,其节点构成了一个具有层级关系的树状结构。例如,图1展示了zk节点的层级树状结构。
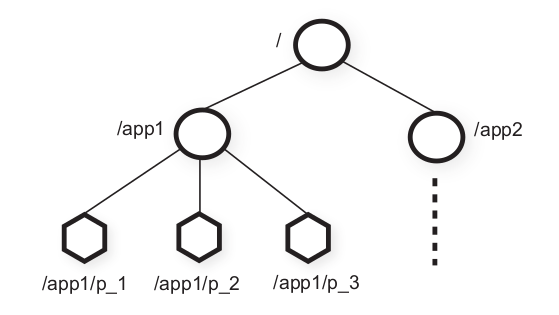
这里可以看做是 mysql 中存储所使用的 b+ 树,zk不同的是用类似文件系统的数据结构来存储元数据,这里的元数据指的是,协调使用的元数据,注意是协调使用。在论文中指出 znode 并不用于通用数据存储,而是用来存储 client 引用的数据( 用于协调的元数据 )。一个 client 可以通过 API 来操纵 znode ,如上图中 app1 实现了一个简单的组成员身份协议:每个 client 进程 pi 在 /app1 下创建了一个 znode pi ,只要该进程正在运行,该节点便会持续存在 。
其实 zk 的底层和 mysql 是一致的,也是根据 log entry 的方式来记录事务,记录数据变更,然后再定期同步到磁盘的,这里就不展开深入了,具体可以参考一下这个文章:https://blog.csdn.net/weixin_43934607/article/details/116378147
节点分为以下几类:
- PERSISTENT:永久节点
- EPHEMERAL:临时节点
- PERSISTENT_SEQUENTIAL:永久节点、序列化
- EPHEMERAL_SEQUENTIAL:临时节点、序列化
持久节点的存活时间不依赖于客户端会话,只有客户端在显式执行删除节点操作时,节点才消失。
临时节点的存活时间依赖于客户端会话,当会话结束,临时节点将会被自动删除(当然也可以手动删除临时节点)。利用临时节点的这一特性,我们可以使用临时节点来进行集群管理,包括发现服务的上下线等。
ZooKeeper规定,临时节点不能拥有子节点。
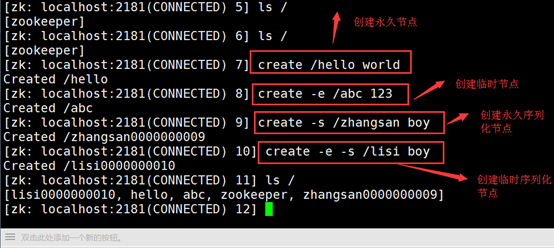
创建永久节点: [zk: localhost:2181(CONNECTED) 3] create/hello world Created /hello 创建临时节点: [zk: localhost:2181(CONNECTED) 5] create -e/abc 123 Created /abc 创建永久序列化节点: [zk: localhost:2181(CONNECTED) 6] create -s/zhangsan boy Created /zhangsan0000000004 创建临时序列化节点: zk: localhost:2181(CONNECTED) 11] create -e-s /lisi boy Created /lisi0000000006
为什么说 znode 上面存储的是一个元数据呢,看看znode里面包含的数据就知道了
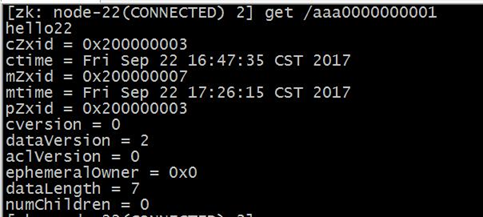
cversion :子节点的版本号。当 znode 的子节点有变化时,cversion 的值就会增加 1。 aclVersion :ACL 的版本号。 cZxid :Znode 创建的事务 id。 mZxid :Znode 被修改的事务 id,即每次对 znode 的修改都会更新 mZxid。 对于 zk 来说,每次的变化都会产生一个唯一的事务 id,zxid(ZooKeeper Transaction Id)。通过 zxid,可以确定更新操作的先后顺序。例如,如果 zxid1小于 zxid2,说明 zxid1 操作先于 zxid2 发生,zxid 对于整个 zk 都是唯一的,即使操作的是不同的 znode。 ctime:节点创建时的时间戳. mtime:节点最新一次更新发生时的时间戳. ephemeralOwner:如果该节点为临时节点, ephemeralOwner 值表示与该节点绑定的 sessionid. 如果不是, ephemeralOwner 值为 0.
版本号
其中版本号,是用来控制数据协同的,保证写操作序列化。对于 znode 来说,均存在三个版本号
- dataVersion 数据版本号,每次对节点进行set操作,dataVersion的值都会增加1(即使设置的是相同的数据)。
- cversion 子节点的版本号。当znode的子节点有变化时,cversion 的值就会增加1。
- aclVersion ACL的版本号,关于znode的ACL(Access Control List,访问控制),可以参考 参考资料1 有关ACL的描述。
以数据版本号来说明zk中版本号的作用。每一个znode都有一个数据版本号,它随着每次数据变化而自增。ZooKeeper提供的一些API例如setData和delete根据版本号有条件地执行。多个客户端对同一个znode进行操作时,版本号的使用就会显得尤为重要。例如,假设客户端C1对znode /config写入一些配置信息,如果另一个客户端C2同时更新了这个znode,此时C1的版本号已经过期,C1调用setData一定不会成功。这正是版本机制有效避免了数据更新时出现的先后顺序问题。在这个例子中,C1在写入数据时使用的版本号无法匹配,使得操作失败。

事务ID
对于zk来说,每次的变化都会产生一个唯一的事务id,zxid(ZooKeeper Transaction Id)。通过zxid,可以确定更新操作的先后顺序。例如,如果zxid1小于zxid2,说明zxid1操作先于zxid2发生。
需要指出的是,zxid对于整个zk都是唯一的,即使操作的是不同的znode。
- cZxid : Znode创建的事务id。
- mZxid :Znode被修改的事务id,即每次对znode的修改都会更新mZxid。
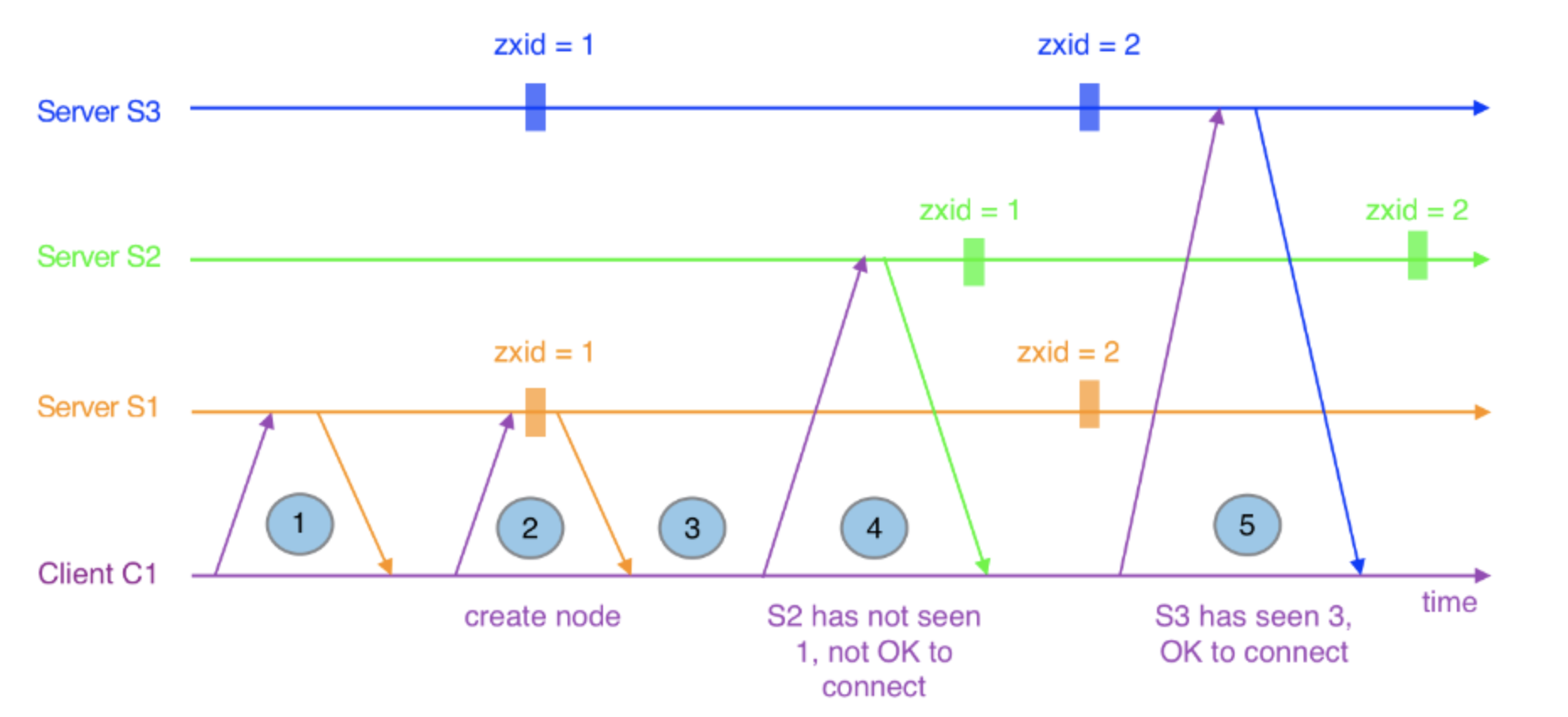
客户端 Clent C1 连接 Server S1 后

在集群模式下,客户端有多个服务器可以连接,当尝试连接到一个不同的服务器时,这个服务器的状态要与最后连接的服务器的状态要保持一致。Zk正是使用zxid来标识这个状态,图3描述了客户端在重连情况下zxid的作用。当客户端因超时与S1断开连接后,客户端开始尝试连接S2,但S2延迟于客户端所识别的状态。然而,S3的状态与客户端所识别的状态一致,所以客户端可以安全连接上S3。
九、原语实现
主要关注一下几个:
互斥锁
client 通过创建 lock znode 来获取锁,若该 znode 已存在,则等待别的 client 释放锁。client 释放锁时即为删除该 znode 。
lock(): while true: if create("lf", ephemeral = true), exit if exists("lf", watch = true) wait for notification unlock(): delete("lf")
由于锁被释放后,会有多个 client 同时争夺该锁,这样就导致了 Herd Effect 。 Herd Effect 就是惊群反应,也就是客户端添加了 watch 标识后,当一个锁释放了资源 lf 节点后,就会造成所有的等待的 client 都收到了通知,然后又全部尝试获取锁 create("lf")。
没有 Herd Effect 的互斥锁
lock(): 1 - n = create(l + "/lock-", EPHEMERAL|SEQUENTIAL) 2 - c = getChildren(l, false) 3 - if n is lowest znode in C, exit ## 如果序号是最新的number,则说明当前 client 优先级最高,可以获取锁 4 - p = znode in C ordered just before n ## 查找当前client序号前一个的 p znode ,并且 watch
5 - if exits(p, true) wait for watch event 6 - goto 2 unlock(): 1 - delete(n)
排队所有请求锁的 client , client a 只 watch 它的前一个 client b 的 znode。当 b 的 znode 删除后,它可能是释放了锁,或者是申请锁的请求被放弃,此时再判断 a 是否是队列中的第一个,若是,则获取锁。释放锁则是简单地删除对应的 znode 。
读写锁
write lock(): 1 - n = create(l + "write-", EPHEMERAL|SEQUENTIAL) 2 - c = getChildren(l, false) 3 - if n is lowest znode in C, exit 4 - p = znode in C ordered just before n 5 - if exits(p, true) wait for event 6 - goto 2 read lock(): 1 - n = create(l + "read-", EPHEMERAL|SEQUENTIAL) 2 - getChildren(l, false) 3 - if no write znodes lower than n in C, exit 4 - p = write znode in C ordered just before n 5 - if exits(p, true) wait for event 6 - goto 3
write lock 和上面的一样,主要是 read lock,读锁会查询是否有比当前 read 的锁更前面的 write 锁还没有被释放,如果有则阻塞一直等待写锁释放。
十、Redis 的分布式锁和 ZK 的不同
redis 也支持分布式锁,可以分为两种加锁方式,下面看一下和 zk 的有什么不同。
第一种,直接加锁,用最普通的实现方式,就是在 redis 里面创建一个 key 加锁
SET mylock 随机值 NX PX 过期时间
当这个锁 key 值不存在的时候才会设置成功,并且有过期时间,超过时间会自动释放。当有多个 client 同时竞争一个锁的时候,只有一个到达并执行的 client 才会申请到,其他的只能自循环不断重复发起请求尝试申请锁,这样对比 ZK,由于没有 watch 机制,所以 redis 的简单实现方式会导致请求方空载,浪费资源算力。
释放锁
if redis.call("get", KEYS[1]) == ARGV[1] then return redis.call("del", KEYS[1]) else return 0 end
利用 lua 脚本,对比传入的随机值是否相等,然后再删除。使用随机值是因为,如果某个 client 获取到了锁,但是阻塞了很长时间才执行完,此时锁可能已经自己释放掉,因为超时时间已过,所以直接删除的话会有问题。另一方面,例如 redis 做了主备,由于主备同步的数据是异步完成的,所以当主 master 服务发生故障,此锁的数据可能还没有被 master 同步到 slave 上,所以当 slave 成为新的主服务时,会丢失这个锁的信息,如果没有使用随机值,也会删掉新 master 中其他 client 新建立的锁。
我们可以看到啊,redis 其实定位就是简单的 k/v storage system,对于系统容错FT方面,还有一致性方面的设计相对 zk 来说是少了很多解决方案的。
第二种方法是,RedLock 算法
这个场景是针对 redis cluster 来说的,例如有 5 个 redis master 实例。然后执行如下步骤获取一把锁:
- 获取当前时间戳,单位是毫秒
- 跟上面的类似,轮流尝试在每个 master 节点上创建锁,过期时间较短,一般就及时毫秒,这种算法就类似其他的分布式大多数一致性保证一样
- 尝试在大多数节点上创建一个锁,比如 5 个节点就要求大多数为 3
- 客户端计算建立好锁的时间,如果建立锁的时间小于超时时间,就算建立成功。但是这个超时时间是一个 magic number,具体要怎么调呢,太长了不行,太慢了怕还没申请到大多数最后一个节点就超时,还有各种网络原因造成的超时等等不确定性。
- 要是锁失败了,就依次删除这个锁
- 只要发现有别的客户端简历了一个分布式锁,你就得不停的轮询尝试获取它。
而 zk 的分布式,得益于自身原句的支持,所以分布式锁的实现也变得很简单。就是某个节点尝试创建临时节点 znode,此时创建成功了就获取了这个锁,这个时候别的客户端来创建就会失败,只能注册一个 watch 来监听这个锁。释放锁就是删除这个锁,一但释放掉就会通知客户端,然后有一个等待着的客户端就可以重新加锁。
十一、ZAB 协议
ZAB(zookeeper atomic broadcast):是一种支持崩溃回复的原子广播协议,是基于 fast paxos 实现的。
ZK 使用单一主进程 Leader 用于处理客户端的所有事务,也就是写请求,这样就可以保证顺序一致性了,当服务器数据发生变更,也就是集群成员变更发生时,集群采用 ZAB 原子广播协议,以事务提交 proposal 的形式广播到所有的副本进程,每一个事务分配一个全局的递增的事务编号xid。
若客户端提交的请求为读请求时,则接受请求的节点直接根据自己保存的数据响应。如果是写请求,且当前节点不是leader,那么该节点就会转发给 leader,leader 会以提案的方式广播此写请求,如果超过半数的节点同意写请求,则写请求就会被提交,leader 会通知所有的订阅者同步数据。
ZAB 把节点分为:
- Leader:leader 在 zk 是唯一的,在同一个 epoch 中只存在一个,主要处理写请求的协同写入,保证了顺序性
- Follower:跟随者,去接收一些 leader 发起的提案,当大多数节点提交后,这个数据达成共识 leader 才能返回
- Observer:观察者,只被动的接收提案,也即是所有的提案已经都是提交的,它没有投票权,即它不参与选举和写请求的投票,所以可以用来处理读请求,节点中 ob 的节点越多,读性能越好
ZAB 的成员状态有如下:
- Election:如果集群没有 leader,那么集群就会进入这个状态,并且尝试选举出一个 leader
- Following:选举完成后,除了 leader 的节点,其他的变成 following
- Leading:选举完成后,成功当选 leader 节点,进入 leading 状态
- Observing:observer 对应的节点状态
ZAB 的运行阶段分为:
- 选举阶段:感觉和 raft 差不多,都是获取大多数选票当选为 leader
- 成员发现:当选举出一个 leader 之后,这个时候的 leader 称之为准leader,所有的 follower 会和准leader协商一个 epoch(任期),使得旧 leader 的提案不能再达成共识
- 数据同步:ZAB也是大多数共识算法,也会存在少数节点的数据不同步,所以 ZAB 会把最新的提案同步给所有的 follower ,让所有的 follower 和 leader 完全数对齐
- 消息广播:当 zk 所有大多数数据都对齐同步后,集群就可以开始对外服务了,这个阶段主要是处理客户端的事务请求,用于提案协商。
ZAB 的事务标识符:也就是整个集群提案的唯一标识,也叫做 zxid,他是由两个部分组成的。一个是 Epoch 周期,也就是每个 leader 的任期,一个是每个 leader 的单调递增的计数器 Counter。zxid = Epoch+Counter。在zk中日志的最终保存磁盘里的文件命名就是 log.zxid,这样可以方便的查找某个 zxid 所在的日志。
成员发现阶段:
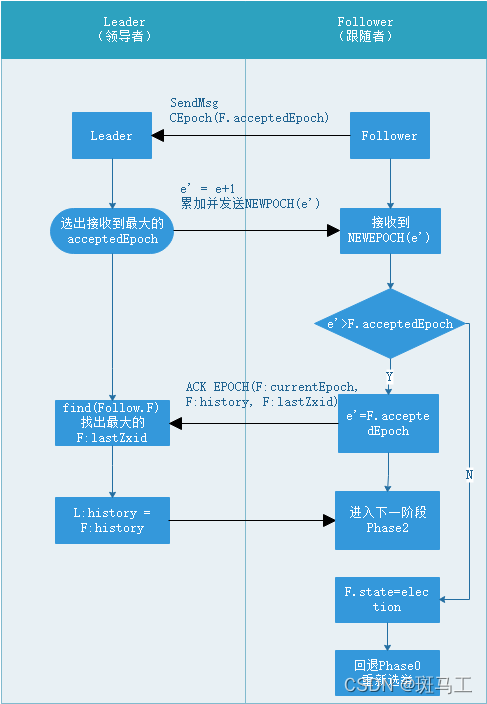
处理过程:
1. Follower 将自己最后处理的事务 Proposal 的 epoch 值发送给 Leader,消息 CEpoch(F.p) , F.p 可以提取出 zxid。
2. 当 Leader 接收到过半的 Follower 的 CEpoch 消息后,Leader 生成 NewEpoch(e') 发送给这些过半的 Follower, e' 是比任何从 CEpoch 消息中收到的 epoch 值都要大。
3. Follower 一旦从 Leader 处收到 NewEpoch(e') 消息,会先做判断,如果 e'<F.acceptedEpoch ,也就是发现自己的任期比 leader 的还要大,并且F.state = election 也就是Looking状态,那么会重新回到Leader选举阶段。
4. Leader 一旦收到了过半的 Follower 的确认消息。它会从这些过半的 Follower 中选取一个 F,并使用它作为初始化事务的集合(用于同步集群数据),然后结束发现阶段。既然要选择需要同步的事务集合,必然要选择事务最全的,所以,须满足epoch 是最大的且 zxid 也是最大的条件。
数据同步阶段
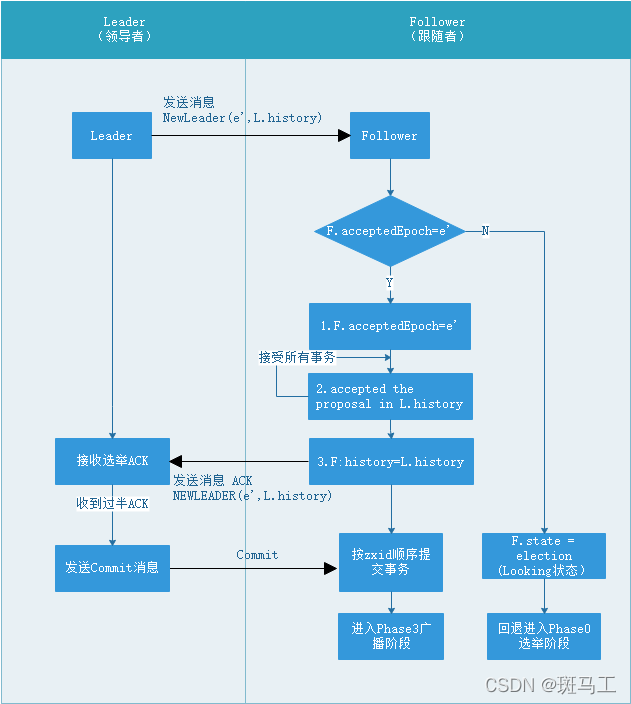
leader向followers主动发起请求,这个阶段follower的数据要被同步为leader从上个阶段收集的数据。
zookeeper leader存两个指标:
- minCommittedLog:leader内存中最小的提交日志
- maxCommittedLog:leader数据库最大的提交日志
leader会结合指标根据每个learner数据状态发送不同的指令,可分为如下情况:
- 回滚:learner数据比leader还新(>minCommittedLog),leader要求learner回滚到同自己相同的水平
- 差异同步:learner数据过时但>=minCommittedLog,leader发送差异数据
- 回滚+差异同步:learner出现了上个epoch的数据(可能是上个朝代的leader)
- 快照全量同步:learner的数据比minCommittedLog小(非常古老了,必须用snapshot同步了)
leader根据数据副本的不同的状态选择性的发送指令和数据,目的就是要让各个副本数据达成一致。 每个数据同步完毕的learner都会返回ack后,由leader将同步的follower加入到forwardingFollowers队列(hashSet)中,也就是说leader维护了每个learner的deadline time、socket对象、对应的阻塞队列(每个learner都有一个)等。
不管leader还是follower,启动都要经过以上阶段。同时节点任何步骤出现失败或超时,节点都会回退到选举阶段。
广播阶段
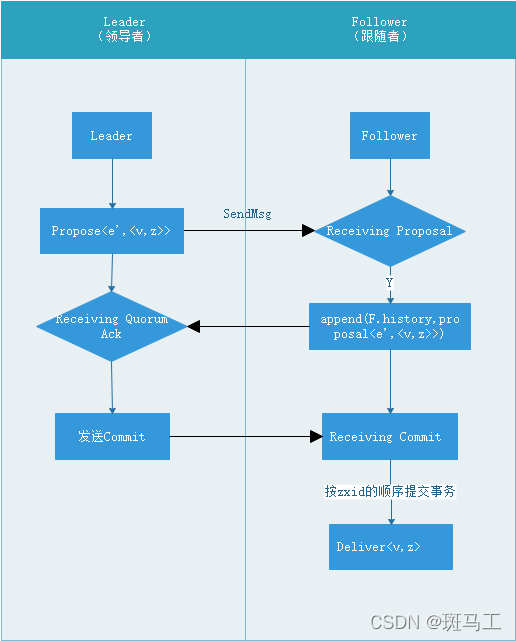
第一个过程 Propose:Leader 收到来自客户端新的事务请求后,会生成对应的事务 Proposal,并根据 zxid 的顺序(递增)向追随自己的所有 Follower 发送 P<e’, <v, z>> ,其中 epoch(z) == e’ 。
第二个过程 Ack:Follower 根据收到消息的次序来处理这些 Proposal,并追加到 H 中去,然后通知给 Leader。
第三个过程 Commit:一旦 Follower 收到来自 Leader 的 Commit 消息,将调用 abdeliver() 提交事务 。 这里是按照zxid的顺序来提交事务。
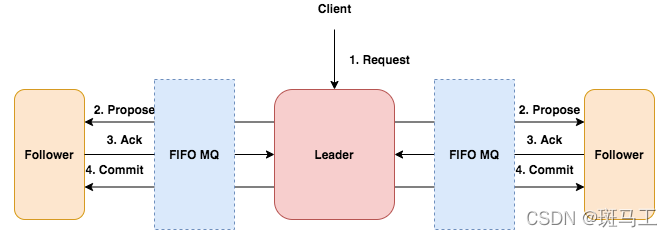
原子广播是一个两阶段提交,流程:
- 节点A接到任何客户端写入请求都要转发到leader
- leader生成zxid,封装请求为proposal发给所有followers的FIFO队列
- follower接到后proposal,先写transactionlog事务日志,然后回复leader ack(3.7.0版本此处新增了异步发送特性zookeeper.learner.asyncSending[1])。
- leader接到半数以上ack后commit,再向所有follower发commit、所有observer发proposal。具体源码:Leader#processAck中,leader先判断上个zxid是否还存在,只有不存在才继续,之后再利用SyncedLearnerTracker#hasAllQuorums判断是否达到半数以上ack,判断半数以上ack有两种实现,一种是分组得分制(QuorumHierarchical)、一种是ack计数制。
- follower接到并执行commit后回复leader ack,这里有一点,如果提交的zxid不是follower最近pending的那个(存储于pendingTxns),也就是第一阶段的事务commit可能在之前网络丢包或绕路了,那follower直接退出。
- 节点A执行后,向客户端返回response
故障检测
发现、同步和广播阶段都没有考虑节点宕机的问题,为了检测失败,Zab提供followers和leader间的周期性心跳 org.apache.zookeeper.server.quorum.Leader#PING
- 如果leader在一段时间内没有收到quorum数量的心跳,它则放弃领导权并进入选举。
- 如果follower在一段时间没有接到leader的心跳,会进入选举状态。
leader对于ping包的构造,主要就是会携带最近发起过proposal的txid,其他不带有任何数据。
崩溃恢复
在zab协议的第一个阶段(1. 选举和发现)中,内含了崩溃恢复的机制,恢复阶段从zab协议的“同步”阶段中集成了很多内容。
崩溃恢复的意义就是追求数据一致性,它保证:
- leader发出过commit的消息,最终会被所有节点commit
- leader没commit的消息会被丢弃
提交提案
原子广播2PC中,第一步leader会发送proposal到follower,半数节点以上ack才进行commit,如果没有半数节点ack呢?或者半数以上节点拒绝了呢?传统数据库2PC会进行回滚,ZooKeeper的话,leader会下台,如果选举后新的leader内存中存在这个未commit的proposal,才会再次尝试提交。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号