20155322 2017-2018-1《信息安全系统设计基础》第十四周学习总结
2017-2018-1 《信息安全系统设计基础》 20155322 第十四周学习总结
学习要求
找出全书你认为学得最差的一章,深入重新学习一下,要求(期末占5分):
- 总结新的收获
- 给你的结对学习搭档讲解或请教,并获取反馈。参考上面的学习总结模板,把学习过程通过博客(随笔)发表,博客标题“学号 《信息安全系统设计基础》第十四周学习总结”,博客(随笔)要通过作业提交,截至时间本周日 23:59。
学习总结
我学的较差的章节是第四章:处理器系统
我选择这章的原因是:对汇编有一些理解,但是不够深刻,不能将这些抽象的东西化为一些容易理解的模型,故而想继续研究一下
-> Y86-64指令集体系结构
我们知道计算机系统底层硬件只识别机器语言,而处理器就是用来执行一系列指令,每条指令执行某个简单的操作。比如两个数相加,汇编指令 ADD 会被编码为一个或多个字节组成的二进制格式。
这里一个处理器支持的指令和指令的字节级编码称为它的指令集体系结构(Instruction-Set Architecture,ISA)。
而不同的处理器家族,比如Intel IA32、IBM/Freescale PowerPC和AMD处理器家族,都有不同的ISA。不同类型的CPU 有不同的机器指令系统,也就有不同的汇编语言是一样的。不同的处理器,其指令集体系结构也不一样,也就是说一个程序编译成在一种机器上运行,就不能在另外一种机器上运行,如何处理这种兼容性问题呢?ISA 在编译器编写者和处理器设计人之间提供了一个抽象概念层,编译器编写者只需要知道允许哪些指令,以及它们是如何编码的;而处理器设计者必须建造出这些指令的处理器。
ISA:
- 一个处理器支持的指令和指令的字节级编码就是这个处理器的ISA
- ISA包括:指令集、指令集编码、基本数据类型、一组编程规范、寄存器、寻址模式、存储体系、异常事件处理、中断和外部I/O
- ISA在编译器编写者(CPU软件)和处理器设计人员(CPU硬件)之间提供了一个抽象层:
- 处理器设计者:依据ISA来设计处理器
- 处理器使用者(如:写编译器的牛*程序员):依据ISA就知道CPU选用的指令集,就知道自己可以使用哪些指令以及遵循哪些规范
Y86:
Y86指令是不存在的,这是《深入理解计算机系统》的作者受到 IA32指令,也就是“x86”的启发,所假想出来的一种处理器体系结构,与 "x86" 相比,Y86指令集的数据类型、指令和寻址方式都要少一些,字节级编码也比较简单。但是它仍然足够完整,能够写一些简单的处理证书的程序,而设计一个Y86处理器要求我们面对许多处理器设计者同样面临的问题。
- Y86程序可见部分包括:
- 寄存器:8个,每一个寄存器可以存储一个字,也就是一个32位二进制
- 存储器:是一个很大的字节数组,保存着程序和数据,Y86的程序可以使用虚拟地址(类似于数组的下标)来访问存储器,硬件和操作系统会将虚拟地址翻译为实际的地址
- 条件码:一个一位二进制的寄存器,保存着最近的算术或逻辑运算所造成的影响的信息
- PC(程序计数器):是程序计数器,记录当前正在执行的指令的地址
- 程序状态:代表着程序的运行情况。它会指示程序是否正常运行,或者发生了某个特殊事件。
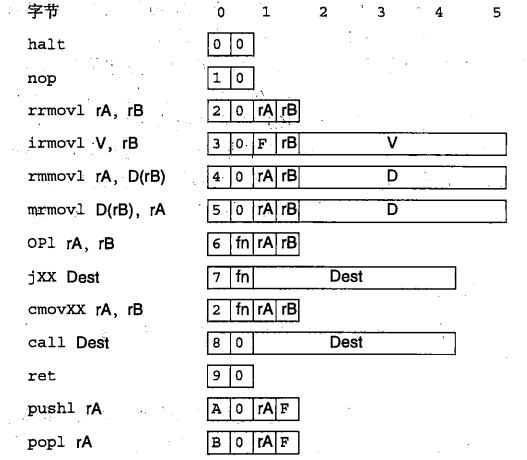
- 指令的描述:
左边是指令的汇编码表示,右边是字节编码。它只包括四字节整数操作。
-
halt :这个指令会停止指令的执行。在IA32中有个与之相当的指令 hlt,不过IA32的应用程序不允许使用这条指令,因为它会导致整个系统暂停运行。而对于Y86来讲,执行 halt 指令会导致处理器停止,并将状态码设置为 HLT。
-
nop:这是一个占位指令,它不做任何事情,后续为了实现流水线,它有一定的作用。
-
xxmovl:这是一系列的数据传送指令,其中r代表寄存器,m代表存储器,i代表立即数。比如rrmovl指令,则代表将一个寄存器的值,赋给另外一个寄存器。
-
OPl:这包括4个整数操作指令,addl、subl、andl和xorl。他们只对寄存器数据进行操作。
-
jXX:包括7个跳转指令,jmp,jle,jl,je,jne,jge,jg。根据分支指令的类型和条件码的设置来选择分支。
-
cmovXX:包括6个条件传送指令,cmovle,cmovl,cmove,cmovne,cmovge和cmovg,只发生在两个寄存器之间,不会将数据传送到存储器。
-
call:指令将返回地址入栈,然后跳到目的地址。
-
ret:call是过程调用,ret是返回。将返回地址入PC,并跳到返回地址。
-
pushl和popl:指令实现了地址的入栈和出栈
指令编码
指令集的一个重要性质就是字节编码必须要有唯一的解释。
每条指令的第一个字节有唯一的代码和功能组合,给定这个字节,我们就可以决定所有其他附加字节的长度和含义。这个性质保证了处理器可以无二义性的执行目标程序代码。即使代码嵌入在程序的其它字节中,只要从序列的第一个字节开始处理,我们仍然可以很容易的确定指令序列。
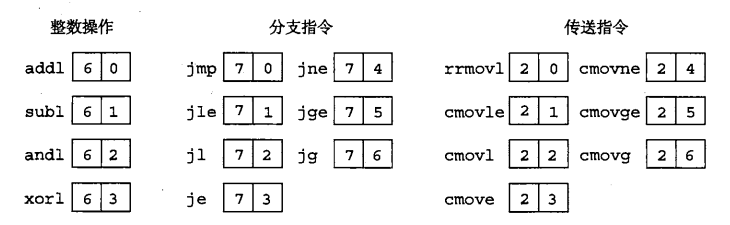
整数操作、条件传送和分支指令的具体编码如下图:
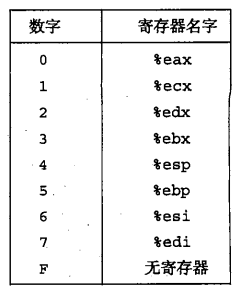
8个程序寄存器对应的标识符ID:
实例:确定指令 rmmovl %esp,0x12345(%edx) 的字节编码:
- rmmovl 的第一个字节是40
- 源寄存器%esp应该编码放在rA字段中,而基址寄存器%edx 应该编码放在 rB 字段中,这两个寄存器的标识符ID分别为4/2
- 最后偏移量编码放在4字节的常数中,我们在0x12345的前面填上0变为4个字节,也就是字节序列 00 01 23 45,写成按字节反序就是 45 23 01 00。
- 所以整个连接起来就是:404245230100
Y86异常
程序员可见的状态中包括stat状态码,它标识了程序执行的状态。这个状态码的可能值如下:

-> 逻辑设计和硬件控制语言HCL
所有的输入和输出都能以一下方式执行:
- 打开文件
- 读写文件
- 关闭文件
我们来了解一下Linux文件和它的类型:
- 普通文件,分为文本文件和二进制文件
- 目录,包含一组链接,里面记录了文件名到文件的映射
- 套接字,通信文件
- 命名通道
- 符号链接
- 字符和块设备
……
目录层次结构中的位置用路径名来指定,包含两种形式:
- 绝对路径名,从根节点开始
- 相对路径名,从当前工作目录开始
-> Y86的顺序实现
进程通过调用open函数来打开或者创建文件:
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
int open(char *filename, int flags, mode_t mode);
一个应用程序通过要求内核来打开文件,内核返回一个小的非负整数(描述符),内核记录有关这个文件的所有的信息,应用程序只需要记住这个描述符。flag参数指明了如何访问这个文件:
-
O_RDONLY: 只读
-
O_WRONLY: 只写
-
O_RDWR: 可读可写
mode参数制定了新文件的访问权限位:
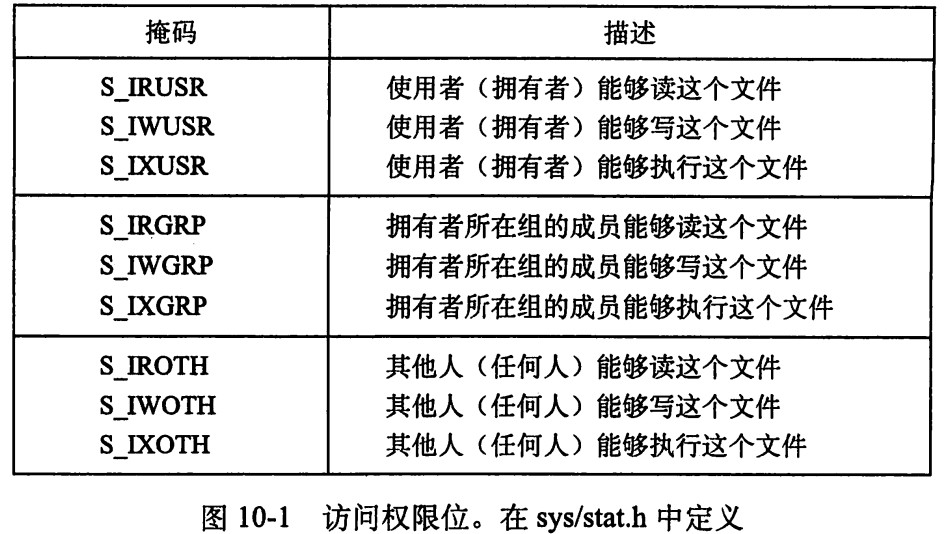
所有文件类型都具有访问权限。每个文件有 9 个访问权限位.
关闭文件会调用close函数:
#include <unistd.h>
int close(int fd);
在系统I/O中读写文件用的系统函数为read()和write()函数来执行。
#include <unistd.h>
ssize_t read(int fd,void * buf,size_t n);
ssize_t write(int fd,void *buf,size_t n);
read函数从描述符为fd的当前文件位置拷贝最多n个字节到存储器位置buf。返回值-1表示一个错误,而返回值0表示EOF。否则,返回值表示的是实际传送的字节数量。而write函数从存储器位置buf拷贝至多n个字节到描述符fd的当前文件位置。返回值要么为-1要么为写入的字节数目。
/* $begin cpstdin */
#include "csapp.h"
int main(void)
{
char c;
while(Read(STDIN_FILENO, &c, 1) != 0)
Write(STDOUT_FILENO, &c, 1);
exit(0);
}
/* $end cpstdin */
关于在文件中定位使用的函数为lseek,在I/O库中使用的函数为fseek。
- 问题:size_t和ssize_t的区别
- 解:前者是unsigned int,而后者是int)
有些情况下,read和write传送的字节比应用程序要求的要少,出现这种情况的原因如下:
- 读时遇到EOF。此时read返回0来发出EOF信号。
- 从终端读文本行。如果打开文件是与终端相关联,那么每个read函数将以此传送一个文本行,返回的不足值等于文本行的大小。
- 读和写网络套接字。可能会出现阻塞现象。
实际上,除了EOF,在读磁盘文件时,将不会遇到不足值,而且在写磁盘文件时,也不会遇到不足值。然而,如果你想创建健壮的网络应用,就必须反复调用read和write处理不足值,直到所有需要的字节都传送完毕。(这一点在网络编程中已经体会到了)
-> 流水线的通用原理
RIO提供了方便、健壮和高效的I/O。提供了两类不同的函数:
- 无缓冲的输入输出函数 直接在存储器和文件之间传送数据,没有应用级缓冲,它们对将二进制数据读写到网络和从网络读写二进制数据尤其有用。
- 带缓冲的输入函数
ssize_t rio_readn(int fd,void *usrbuf,size_t n);
ssize_t rio_writen(int fd,void *usrbuf,size_t n);
对同一个描述符,可以任意交错地调用rio_readn和rio_writen。一个问本行的末尾都有一个换行符,那么像读取一个文本中的行数怎么办,使用read读取换行符这个方法不是很妥当,可以调用一个包装函数(rio_readineb),它从一个内部读缓冲区拷贝一个文本行,当缓冲区为空时,会自动地调用read重新填满缓冲区。也就是说,这些函数都是缓冲区操作而言的。
下面这个例子是通过RIO函数一次一行的从标砖输入复制一个文本文件到标准输出:
#include "csapp.h"
int main(int argc, char **argv)
{
int n;
rio_t rio;
char buf[MAXLINE];
Rio_readinitb(&rio, STDIN_FILENO);
while((n = Rio_readlineb(&rio, buf, MAXLINE)) != 0)
Rio_writen(STDOUT_FILENO, buf, n);
/* $end cpfile */
exit(0);
/* $begin cpfile */
}
-> Y86-64的流水线实现
应用程序能够通过调用stat和fstat函数检索到关于文件的信息(有时也称为文件的元数据)
#include <sys/stat.h>
#include <unistd.h>
int stat(const char *filename,struct stat *buf);
int fstat(int fd,struct stat *buf);
若成功,返回0,若出错则为-1.stat以一个文件名为输入,并且填充buf结构体。fstat函数只不过是以文件描述符而不是文件名作为输入。
struct stat {
#if defined(__ARMEB__)
unsigned short st_dev;
unsigned short __pad1;
#else
unsigned long st_dev;
#endif
unsigned long st_ino;
unsigned short st_mode;
unsigned short st_nlink;
unsigned short st_uid;
unsigned short st_gid;
#if defined(__ARMEB__)
unsigned short st_rdev;
unsigned short __pad2;
#else
unsigned long st_rdev;
#endif
unsigned long st_size;
unsigned long st_blksize;
unsigned long st_blocks;
unsigned long st_atime;
unsigned long st_atime_nsec;
unsigned long st_mtime;
unsigned long st_mtime_nsec;
unsigned long st_ctime;
unsigned long st_ctime_nsec;
unsigned long __unused4;
unsigned long __unused5;
};
其中st_size成员包含了文件的字节大小。st_mode为文件访问许可位。UNIX提供的宏指令根据st_mode成员来确定文件的类型:
- S_ISREG(),这是一个普通文件
- S_ISDIR(),这是一个目录文件
- S_ISSOCK()这是一个网络套接字
运行一下书上的例子:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <sys/stat.h>
#include <sys/types.h>
#include <unistd.h>
int main()
{
int fd,size;
struct stat buf_stat;
memset(&buf_stat,0x00,sizeof(buf_stat));
fd=stat("stat.c",&buf_stat);
printf("%d\n",(int)buf_stat.st_size);
return 0;
}
查询和处理一个文件的 st_mode位:
#include "csapp.h"
int main (int argc, char **argv)
{
struct stat stat;
char *type, *readok;
/* $end statcheck */
if (argc != 2) {
fprintf(stderr, "usage: %s <filename>\n", argv[0]);
exit(0);
}
/* $begin statcheck */
Stat(argv[1], &stat);
if (S_ISREG(stat.st_mode)) /* Determine file type */
type = "regular";
else if (S_ISDIR(stat.st_mode))
type = "directory";
else
type = "other";
if ((stat.st_mode & S_IRUSR)) /* Check read access */
readok = "yes";
else
readok = "no";
printf("type: %s, read: %s\n", type, readok);
exit(0);
}
上周考试错题分析
- 我们用一个十六进制的数表示长度w=4的位模式,把数字解释为补码,关于其加法逆元的论述正确的是()
- A.0x8的加法逆元是-8
- B.0x8的加法逆元是0x8
- C.0x8的加法逆元是8
- D.0xD的加法逆元是3
- E.0xD的加法逆元是0x3
- 分析:我的答案是BDE,正确答案是ABDE,错误原因是忽略的符号。
- Y86-64中()指令没有访存操作.
- A.rrmovl
- B.irmovq
- C.rmmovq
- D.pushq
- E.jXX
- F.ret
- 分析:我的答案是AB,正确答案是ABE,这里我翻书查阅了一下,确实漏了E选项。
- 有关磁盘操作,说法正确的是()
- A.对磁盘扇区的访问时间包括三个部分中,传送时间最小。
- B.磁盘以字节为单位读写数据
- C.磁盘以扇区为单位读写数据
- D.读写头总处于同一柱面
- 分析:我的答案是AC,正确答案是ACD,主要考察的知识点在p409
- 有关RAM的说法,正确的是()
- A.SRAM和DRAM掉电后均无法保存里面的内容。
- B.DRAM将一个bit存在一个双稳态的存储单元中
- C.一般来说,SRAM比DRAM快
- D.SRAM常用来作高速缓存
- E.DRAM将每一个bit存储为对一个电容充电
- F.SRAM需要不断刷新
- G.DRAM被组织为二维数组而不是线性数组
- 分析:我的答案ADEG,但是正确答案是ACDEG,我漏选了C,这个在P400可以查书找到,但是比较隐蔽。
本周结对学习情况
-
结对学习博客
20155302 -
结对学习图片

-
结对学习内容
- 教材第四章、第十一章
学习中遇到的问题
在浏览博客时遇到了一个不错的对于处理器理解的话
- 我们为什么要学习处理器的实现?
- 首先处理器的设计是非常有趣而且重要的,处理器设计包括很多好的工程实践原理,它需要完成复杂的任务,而结构又要尽可能的简单和规则,我们去了解事物是怎样工作的有其内在的价值。
- 处理器是整个计算机能正常工作的重要组成部分,理解处理器如何工作能帮助我们理解整个计算机如何工作。
- 虽然我们不用去设计处理器,但是我们工作的产出很多都是在包含处理器的硬件系统上运行的,了解它能让我们工作更有效率。
代码托管
学习进度条
| 代码行数(新增/累积) | 博客量(新增/累积) | 学习时间(新增/累积) | 重要成长 | |
|---|---|---|---|---|
| 目标 | 5000行 | 30篇 | 400小时 | |
| 第一周 | 0/0 | 1/1 | 10/10 | |
| 第三周 | 200/200 | 2/3 | 10/20 | |
| 第四周 | 100/300 | 1/4 | 10/30 | |
| 第五周 | 200/500 | 3/7 | 10/40 | |
| 第六周 | 500/1000 | 2/9 | 30/70 | |
| 第七周 | 500/1500 | 2/11 | 15/85 | |
| 第八周 | 223/1723 | 3/14 | 15/100 | |
| 第九周 | 783/2506 | 3/17 | 15/115 | |
| 第十周 | 0/2506 | 3/20 | 12/127 | |
| 第十一周 | 620/3126 | 2/22 | 20/147 | |
| 第十二周 | 390/3516 | 2/24 | 17/164 | |
| 第十三周 | 812/4328 | 2/26 | 30/194 | |
| 第十四周 | 228/4556 | 1/27 | 10/204 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号